
что это такое, и сколько времени ставить
Есть проблемы с ранжированием, проект не растет, хотите проверить работу своих специалистов по продвижению? Закажите профессиональный аудит в Семантике
Аудит и стратегия продвижения в Семантике
Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
Crawl-delay — директива файла robots.txt, позволяющая задать задержку сканирования страниц для снижения входящей пиковой нагрузки на сервер в момент обхода сайта поисковым роботом.
Больше видео на нашем канале — изучайте интернет-маркетинг с SEMANTICA
Представьте, что в роли сервера сайта выступает директор фирмы, на проверку которой пришла проверяющая служба — поисковый робот.
Сотрудники не могут работать, пока не получат ответ от директора. А он не может им ответить, потому что занят разговором с инспекторами. Чем больше на вашем сайте страниц, тем дольше этот “инспектор” будет проводить допрос, и тем меньше свободного времени будет у сервера на ответы настоящим живым клиентам.
Директива Crawl-delay указывает роботу делать перерывы между “вопросами” к серверу, чтобы в это время он мог отвечать клиентам, не задерживая выполнение внутренних процессов. Поисковый робот после каждого запроса начинает выжидать определенное количество секунд перед следующей страницей по списку.
Как правильно задать директиву Crawl-delay
Правильная конфигурация Crawl-delay даёт возможность существенно разгрузить сервера сайта на время прихода поискового бота, увеличить максимальное количество соединений с живыми клиентами и предотвратить падение сайта при большом наплыве пользователей одновременно с ботами.
Особенность использования директивы
Роботы Google не читают и не учитывают эту директиву в своей работе — для поиска в Гугл время задержки сканирования задается в панели вебмастера поисковой системы
Яндекс активно пользуется Crawl-delay time и всегда учитывает его при обработке сайта. Для поискового бота время директивы является минимальным временем обхода — реальная задержка будет больше или равна ему.
Параметр Crawl-delay, как и все директивы robots.txt, указывается с новой строки через двоеточие. Формат записи — в секундах, допустимы десятичные дроби
Пример:
- Crawl delay: 3 — задержка в три секунды.
- Crawl delay: 0.5 — задержка в половину секунды.
Сколько секунд лучше ставить в Crawl-Delay
В случае, если в момент обхода поисковиками производительность вашего сайта падает, будет полезно попробовать поставить задержку обхода в две-три секунды. Если вам нужно поскорее выгнать бота с сайта, наоборот значение можно уменьшить до одной десятой секунды, что не гарантирует 600 страниц в минуту, но ускорит процесс обработки.
Полезным будет большое значение директивы на слабых тарифах хостингов, чтобы сайт не упал в неподходящий момент. Иногда сервера на небольших тарифах просто не в состоянии обрабатывать в секунду столько запросов, сколько от них требует бот поисковой системы.
После того, как вы внесли директиву в robots.txt. проверьте правильность файла. Воспользуйтесь панелью веб-мастера. В системе Google может возникнуть ошибка о том, что указано неизвестное свойство. Это нормально. На эту директиву смотрят, в основном, только роботы Яндекса.
что это и как использовать
Важно! Сегодня Яндекс уже не следует инструкции Crawl-delay. И теперь скорость обхода регулируется только в Яндекс Вебмастер в разделе «Индексирование — Скорость обхода».
В Google данная директива тоже не используется о чем было сказано в 2017 году в этом видео.
Видео на английском, поэтому вот перевод:
Crawl-delay — это очень давняя директива в Google.
И нужна она была вебмастерам, чтобы указать период между запросами для снижения нагрузки на сервер, которые делает краулер(робот поисковой системы).
Сама по себе идея была хорошей и разумной для того времени. Но дальше стало понятно, что серверы сегодня довольно мощные, так что смыла устанавливать определенный период между запросами попросту нет.
Что же пришло в Google на смену crawl-delay директивы? Робот поисковой системы теперь автоматически регулирует скорость обхода страницы, в зависимости от реакции сервера. Как только она замедлится или появится ошибка, обход может приостановиться.
Итак, учитывая, что замена найдена и успешно нами применяется, поэтому теперь crawl-delay нами не поддерживается. И если мы обнаружим директиву в вашем robots.txt, мы на это укажем.
Стоит также отметить, что на любом сайте обязательно существуют разделы, не нуждающиеся в обходе. Вы можете сообщить нам о них, предоставив информацию в robots.txt с помощью директивы Dissalow.
 И нужна она была вебмастерам, чтобы указать период между запросами для снижения нагрузки на сервер, которые делает краулер(робот поисковой системы).
И нужна она была вебмастерам, чтобы указать период между запросами для снижения нагрузки на сервер, которые делает краулер(робот поисковой системы).Хоть и директива Crawl-delay больше не поддерживается Яндекс и Google, но вдруг вы захотите узнать, как она раньше использовалась в этих поисковых машинах, поэтому ниже мы об этом расскажем.
Crawl-delay в файле robots.txt уменьшает нагрузку на сервер, когда поисковые роботы слишком часто посещают ваш ресурс и перегружают сервер, не давая ему полноценно обрабатывать запросы бота.
Зачастую ее используют владельцы сайтов с более тысячи страниц, так как данная проблема зачастую касается крупных веб-проектов.
Посредством директивы мы просим роботов обходить страницы нашего веб-ресурса не чаще, чем один раз в три, пять и т.п. секунд. То есть, правило задает роботу поисковой системы промежуток времени, измеряющийся в секундах, между концом загрузки одной веб-страницы и началом загрузки последующей.
Есть поисковики, которые работают с форматом дробных чисел, являющихся параметром директивы Crawl-delay.
На заметку.Перед указанием новой скорости обхода ресурса роботами следует узнать, какие страницы они посещают чаще остальных.
Для этого необходимо:
- Просмотреть логи сервера. Свяжитесь с хостинг-провайдером или сотрудником, отвечающим за техническую работу сайта.
- Проанализируйте список URL-адресов в Яндекс.Вебмастере. Сделать это можно в меню Индексирование – Статистика обхода. Не забудьте включить переключатель на “Все страницы”.

Если в результате проверки будет обнаружено, что поисковый бот в основном сканирует служебные страницы, закройте их от индексирования в файле Robots, используя директиву Disallow. Так вы существенно уменьшите количество ненужных посещений роботом.
Чтобы роботы поисковых систем, не всегда придерживающиеся стандарта в ходе чтения robots.txt, учитывали данное правило, его нужно включить в группу, начинающуюся с директивы User-agent, после Disallow и Allow.
Основной бот Яндекса работает с дробными значениями указания Crawl-delay, такими как 0.2 и прочими. Нет стопроцентных гарантий, что робот начнет посещать ваш ресурс 20 раз в секунду, однако обеспечить более быстрое сканирование сайта удастся.
Директива не распознается поисковым ботом, отвечающим за
обход RSS-канала для
создания Турбо-страниц.
На заметку. Максимальное значение директивы для роботов Яндекса – 2.0.
Чтобы выбрать необходимую скорость загрузки страниц веб-сайта, перейдите в меню Скорость обхода сайта.
Примеры:
User-agent: Yandex Crawl-delay: 2.0 # тайм-аут посещения роботом Яндекса – не чаще, чем 1 раз в 2 секунды
User-agent: * Disallow: /search Crawl-delay: 1.0 # тайм-аут посещения всеми роботами – не чаще, чем 1 раз в 1 секунду
Я всегда стараюсь следить за актуальностью информации на сайте, но могу пропустить ошибки, поэтому буду благодарен, если вы на них укажете. Если вы нашли ошибку или опечатку в тексте, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Как настроить задержку сканирования в файле robots.txt
Задержка сканирования в файле robots.txt: что это значит?
Знаете ли вы, что поисковым системам, таким как Google, Yahoo! и Bing, необходимо регулярно сканировать ваш веб-сайт не только для поиска и индексирования вновь созданного контента, но и для того, чтобы они могли обновлять свои системы с учетом любых изменений, внесенных вами на ваш веб-сайт , такие как реструктуризация или удаление контента?
Если вы не знали, теперь знаете! Вы можете сделать это, используя специальную директиву, добавленную в ваш файл robots.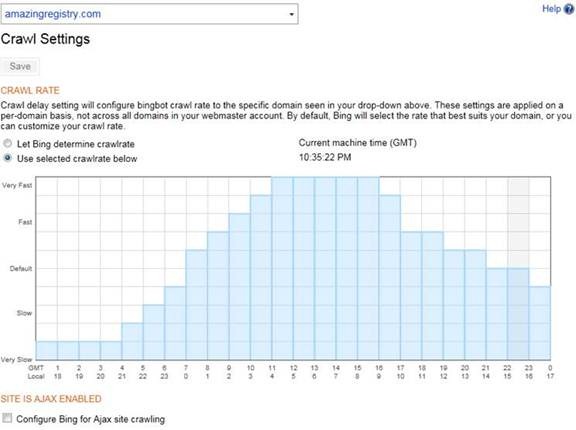 txt.
txt.
Среди множества директив, которые вы можете добавить в файл robots.txt, вы можете добавить те, которые контролируют скорость индексации вашего сайта поисковыми системами. Как правило, большинству владельцев веб-сайтов не нужно настраивать задержку сканирования для своего веб-сайта, но в некоторых случаях это может быть хорошей идеей.
В этой статье базы знаний рассказывается, как создать файл robots.txt, вставить правильную директиву для ограничения скорости сканирования поисковой системы и показать, как управлять этим параметром для поисковых систем, которые не придерживаются этого параметра.
Как создать файл robots.txt в cPanel
Мы будем использовать файловый менеджер cPanel для создания файла. Сначала откройте свою клиентскую зону, чтобы войти на свой клиентский портал. Затем найдите оранжевый значок CP справа от службы, которую вы хотите администрировать.
Поиск вашей cPanel в личном кабинете. После открытия cPanel в области ФАЙЛЫ откройте Диспетчер файлов.
После того, как файловый менеджер откроется, вы захотите найти свою папку public_html (Как найти корневой каталог документа в cPanel). Затем дважды щелкните значок земного шара слева от public_html, чтобы открыть папку.
Если вы дважды щелкните текст «public_html», вы можете непреднамеренно открыть опцию переименования папки. Если это произойдет, просто щелкните пустое пространство под всеми папками и повторите попытку.
Расположение папки public_html в cPanel > Диспетчер файловПосле того, как папка открыта, в зависимости от того, насколько вы продвинулись в разработке своего веб-сайта, у вас могут быть или не быть какие-либо файлы/папки в папке public_html. Не волнуйтесь, если у вас есть файлы/папки, вы все равно можете пройти это руководство и не беспокоиться о том, что это сломает ваш сайт. 🙂
В нашем примере наша папка public_html пуста, за исключением папки cgi-bin.
Почти пустая папка public_html в cPanel > Мы можем легко создать пустой файл robots.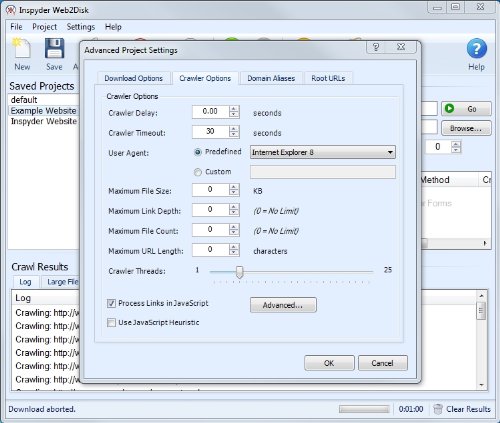 txt из диспетчера файлов. В верхнем левом углу файлового менеджера найдите параметр + Файл рядом с + Папка. Нажмите + Файл, и откроется модальное окно с запросом имени файла +, где вы хотите его создать:
txt из диспетчера файлов. В верхнем левом углу файлового менеджера найдите параметр + Файл рядом с + Папка. Нажмите + Файл, и откроется модальное окно с запросом имени файла +, где вы хотите его создать:
В поле «Новое имя файла» назовите файл robots.txt, затем нажмите «Создать». Новый файл. Вы вернетесь в представление файлового менеджера в папке public_html и увидите, что файл создан.
Новый файл отображается в cPanel > Диспетчер файлов после создания
Как настроить задержку сканирования в файле robots.txt Выход из файлового менеджера.
Чтобы начать редактирование файла, щелкните один раз файл robots.txt, чтобы он был выделен полупрозрачным голубым цветом, как показано ниже:
Выделенный файл robots.txt в cPanel > Файловый менеджер После выбора файл, посмотрите в верхнем меню файлового менеджера. Вверху находятся несколько опций, в том числе «+Файл», «+Папка», «Копировать», «Переместить», «Загрузить» и другие.
Для использования файла robots.txt вы можете игнорировать это и продолжить, нажав «Изменить».
В вашем браузере появится новая вкладка, и вы попадете в нечто, напоминающее текстовый процессор старой школы. Для тех, кто не помнит, это то, на чем люди печатали свои письма до Интернета. 😁
Редактор файлов cPanelВажно отметить, что Google не придерживается настроек задержки сканирования, используемых в файле robots.txt. Мы поговорим о том, как настроить скорость сканирования Google позже. Эти настройки будут работать для Bing, Yahoo! и Яндекс.
Чтобы вставить задержку сканирования, скопируйте приведенный ниже текст и вставьте его в редактор:
Агент пользователя: * Crawl-delay: 1
Это попросит пауков поисковых систем, сканирующих ваш веб-сайт, ждать 1 секунду между каждой просматриваемой страницей. Если вы хотите, чтобы они ждали дольше, вы можете использовать эти две другие настройки:
Если вы хотите, чтобы они ждали дольше, вы можете использовать эти две другие настройки:
User-agent: * Crawl-delay: 5
или
User-agent: * Crawl-delay: 10
Они будут просить поисковые системы ждать 5 или 10 секунд между обходами страниц.
Знаете ли вы, что скорость веб-сайта влияет на SEO и рейтинг Google? Мы используем кэширование LiteSpeed для почти мгновенной доставки контента вашим посетителям. ⚡ Ознакомьтесь с нашими планами веб-хостинга !
Ваш редактор должен выглядеть примерно так, как показано на рисунке ниже, после вставки одного из указанных выше параметров:
Диспетчер файлов cPanel > Редактор с установленными директивами robots.txtПосле ввода данных нажмите синюю кнопку «Сохранить изменения» в правом верхнем углу. . Затем нажмите кнопку «Закрыть» рядом с кнопкой «Сохранить изменения».
Вы вернетесь в диспетчер файлов cPanel, где файл robots.txt был создан и обновлен с помощью этой директивы.
Как изменить скорость сканирования Googlebot
В 2019 году Google объявил, что будет игнорировать определенные директивы в файле robots.txt, и впоследствии обновил свою консоль поиска Google, чтобы дать вам возможность контролировать скорость сканирования.
Чтобы управлять скоростью сканирования ботов Google, войдите в свою консоль поиска Google и в настройках сайта и выберите «Ограничить максимальную скорость сканирования Google», как показано ниже:
Инструменты Google для веб-мастеров > Ограничить скорость сканирования GoogleЕсли вы вносите какие-либо изменения, не забудьте нажать кнопку Сохранить.
И все!
Как настроить задержку сканирования в файле robots.txt
Задержка сканирования в файле robots.txt: что это значит?
Знаете ли вы, что поисковым системам, таким как Google, Yahoo! и Bing, необходимо регулярно сканировать ваш веб-сайт не только для поиска и индексирования вновь созданного контента, но и для того, чтобы они могли обновлять свои системы с учетом любых изменений, внесенных вами на ваш веб-сайт , такие как реструктуризация или удаление контента?
Если вы не знали, теперь знаете! Вы можете сделать это, используя специальную директиву, добавленную в ваш файл robots.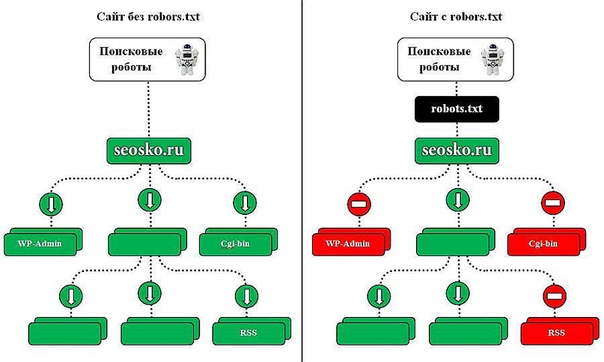 txt.
txt.
Среди многочисленных директив, которые вы можете добавить в файл robots.txt, вы можете добавить те, которые контролируют скорость индексации вашего сайта поисковыми системами. Как правило, большинству владельцев веб-сайтов не нужно настраивать задержку сканирования для своего веб-сайта, но в некоторых случаях это может быть хорошей идеей.
В этой статье базы знаний рассказывается, как создать файл robots.txt, вставить правильную директиву для ограничения скорости сканирования поисковой системы и показать, как управлять этим параметром для поисковых систем, которые не придерживаются этого параметра.
Как создать файл robots.txt в cPanel
Мы будем использовать файловый менеджер cPanel для создания файла. Сначала откройте свою клиентскую зону, чтобы войти на свой клиентский портал. Затем найдите оранжевый значок CP справа от службы, которую вы хотите администрировать.
Поиск вашей cPanel в личном кабинете. После открытия cPanel в области ФАЙЛЫ откройте Диспетчер файлов.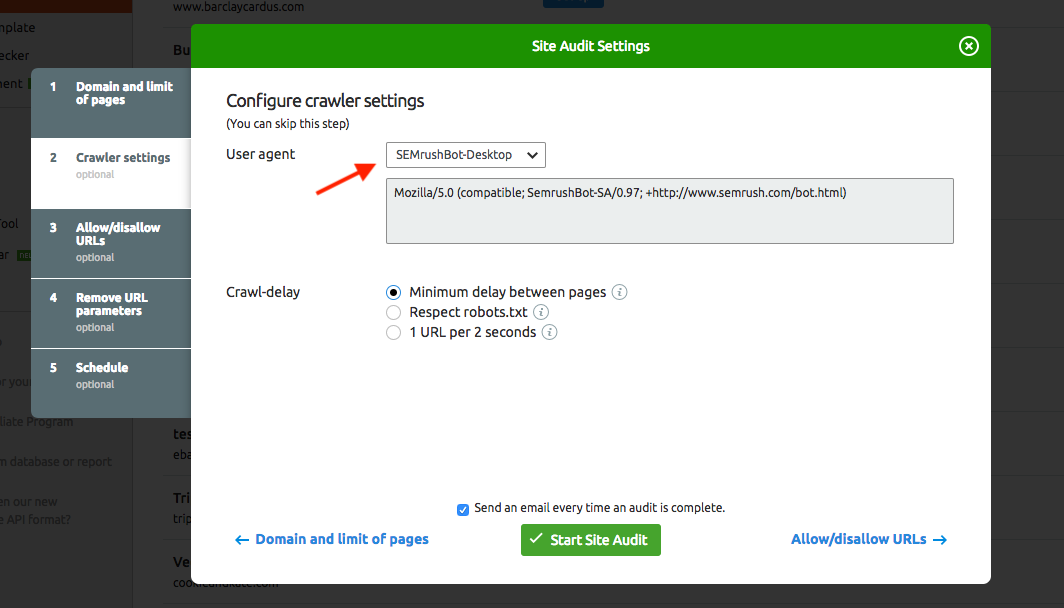
После того, как файловый менеджер откроется, вы захотите найти свою папку public_html (Как найти корневой каталог документа в cPanel). Затем дважды щелкните значок земного шара слева от public_html, чтобы открыть папку.
Если вы дважды щелкните текст «public_html», вы можете непреднамеренно открыть опцию переименования папки. Если это произойдет, просто щелкните пустое пространство под всеми папками и повторите попытку.
Расположение папки public_html в cPanel > Диспетчер файловПосле того, как папка открыта, в зависимости от того, насколько вы продвинулись в разработке своего веб-сайта, у вас могут быть или не быть какие-либо файлы/папки в папке public_html. Не волнуйтесь, если у вас есть файлы/папки, вы все равно можете пройти это руководство и не беспокоиться о том, что это сломает ваш сайт. 🙂
В нашем примере наша папка public_html пуста, за исключением папки cgi-bin.
Почти пустая папка public_html в cPanel > Диспетчер файлов Мы можем легко создать пустой файл robots. txt из диспетчера файлов. В верхнем левом углу файлового менеджера найдите параметр + Файл рядом с + Папка. Нажмите + Файл, и откроется модальное окно с запросом имени файла +, где вы хотите его создать:
txt из диспетчера файлов. В верхнем левом углу файлового менеджера найдите параметр + Файл рядом с + Папка. Нажмите + Файл, и откроется модальное окно с запросом имени файла +, где вы хотите его создать:
В поле «Новое имя файла» назовите файл robots.txt, затем нажмите «Создать». Новый файл. Вы вернетесь в представление файлового менеджера в папке public_html и увидите, что файл создан.
Новый файл отображается в cPanel > Диспетчер файлов после создания
Как настроить задержку сканирования в файле robots.txt Выход из файлового менеджера.
Чтобы начать редактирование файла, щелкните один раз файл robots.txt, чтобы он был выделен полупрозрачным голубым цветом, как показано ниже:
Выделенный файл robots.txt в cPanel > Файловый менеджер После выбора файл, посмотрите в верхнем меню файлового менеджера. Вверху находятся несколько опций, в том числе «+Файл», «+Папка», «Копировать», «Переместить», «Загрузить» и другие. Нам нужно использовать Edit. После того, как вы нажмете «Изменить», появится модальное окно с некоторой информацией.
Нам нужно использовать Edit. После того, как вы нажмете «Изменить», появится модальное окно с некоторой информацией.
Для использования файла robots.txt вы можете игнорировать это и продолжить, нажав «Изменить».
В вашем браузере появится новая вкладка, и вы попадете в нечто, напоминающее текстовый процессор старой школы. Для тех, кто не помнит, это то, на чем люди печатали свои письма до Интернета. 😁
Редактор файлов cPanelВажно отметить, что Google не придерживается настроек задержки сканирования, используемых в файле robots.txt. Мы поговорим о том, как настроить скорость сканирования Google позже. Эти настройки будут работать для Bing, Yahoo! и Яндекс.
Чтобы вставить задержку сканирования, скопируйте приведенный ниже текст и вставьте его в редактор:
Агент пользователя: * Crawl-delay: 1
Это попросит пауков поисковых систем, сканирующих ваш веб-сайт, ждать 1 секунду между каждой просматриваемой страницей. Если вы хотите, чтобы они ждали дольше, вы можете использовать эти две другие настройки:
Если вы хотите, чтобы они ждали дольше, вы можете использовать эти две другие настройки:
User-agent: * Crawl-delay: 5
или
User-agent: * Crawl-delay: 10
Они будут просить поисковые системы ждать 5 или 10 секунд между обходами страниц.
Знаете ли вы, что скорость веб-сайта влияет на SEO и рейтинг Google? Мы используем кэширование LiteSpeed для почти мгновенной доставки контента вашим посетителям. ⚡ Ознакомьтесь с нашими планами веб-хостинга !
Ваш редактор должен выглядеть примерно так, как показано на рисунке ниже, после вставки одного из указанных выше параметров:
Диспетчер файлов cPanel > Редактор с установленными директивами robots.txtПосле ввода данных нажмите синюю кнопку «Сохранить изменения» в правом верхнем углу. . Затем нажмите кнопку «Закрыть» рядом с кнопкой «Сохранить изменения».
Вы вернетесь в диспетчер файлов cPanel, где файл robots.txt был создан и обновлен с помощью этой директивы.