
Сравнение сервисов автоматической кластеризации ключевых слов для SEO / Habr
В небольшом SEO-отделе большого контентного проекта, где я работаю, решили увеличить штат. Набирать планировалось людей с небольшим опытом или совсем без опыта. По этой причине было решено создать некий гайд, который бы служил исчерпывающим руководством по написанию новых статей. Руководство получилось действительно подробным и полным, один из его важных блоков – это кластеризация запросов.
Зачем нужны сервисы кластеризации?
В один кластер должны быть объединены только такие запросы, которые имеют хорошие шансы выйти в топ-10 поисковых систем с общей релевантной страницей. То есть, если по двум запросам в выдаче все страницы сайтов разные и нет пересечений, то следует относить их к разным кластерам. Также и наоборот: если два запроса возможно продвинуть на одной статье, то не следует разносить их на разные кластеры, чтобы не писать лишнего – бюджет на контент не резиновый.
Общая схема составления ТЗ на написание SEO-статьи следующая:
- Сбор семантики – статистика поисковых систем, базы семантики, внутренняя статистика проекта;
- Кластеризация автоматическая – сервис или программа для кластеризации по подобию топов;
- «Посткластеризация» ручная – обработка того что не удалось кластеризовать автоматически;
- Приоритезация – определение важности полученных запросов в каждом кластере;
- Оформление ТЗ для копирайтера – лемматизация, LSI и различные указания для написания статей, по статье на каждый кластер.
Вот именно для второго пункта нужно было выбрать самый подходящий сервис автоматической кластеризации. Для этой цели я провел сравнительный анализ самых известных, на мой взгляд, сервисов.
Способы кластеризации
Из способов, которые автоматизированы в каких-то известных сервисах или программах, можно выделить два:
Исходя из задачи – написание SEO-статей, был выбран метод по подобию топов. Поисковая система на трафик с которой мы ориентируемся – Яндекс, поэтому для кластеризации использовался топ-10 Яндекса. У данного метода есть два вида:
- Soft – когда все запросы кластера связаны хотя бы с одним общим (маркерным) запросом;
- Hard – когда каждый запрос связан со всеми запросами в своем кластере;
а также такой параметр как «сила связи» – количество общих URL в поисковой выдаче по запросам.
По рекомендациям создателей сервисов кластеризации для нашего случая был выбран вариант Soft с силой связи 4. Это важный момент, потому что для интернет-магазина, например, следовало бы выбирать другие опции.
Методика сравнения
Суть сравнения сервисов в следующем: выбрать идеально кластеризованный список запросов – эталонное ядро. Сравнить результаты кластеризации каждого сервиса с эталонным.
Важно было хорошо составить такое эталонное ядро. Поскольку у нас контентный проект и большая часть контента – это вопросы и ответы пользователей, то материала для сбора статистики по проекту предостаточно.
Было взято ядро на 2500+ ключевых фраз, которое отслеживается уже много месяцев. Из него выбраны только запросы вышедшие в топ-5 Яндекса. И из них взяты только те которые имеют релевантной страницу одного из широких разделов (категория вопроса, тема вопроса, категория документа, страница с формой «задать вопрос»), а не узкую страницу вопроса с ответами. Запросы были сгруппированы по релевантной странице. Оставлены только группы в которых более чем 4 запроса. В итоге получилось 292 запроса разбитых на 22 кластера.
Забегая вперед скажу, что сравнивались результаты кластеризации по Московской выдаче Яндекса и без геопривязки. Региональная московская выдача показала себя лучше, поэтому далее будем говорить про нее.
Сравнение сервисов
В поиске самых популярных сервисов очень помог доклад Александра Ожгибесова на BDD-2017, к тем, что у него было добавлено еще несколько сервисов, получился такой список:
- Топвизор
- Pixelplus
- Serpstat
- Rush Analytics
- Just Magic
- Key Collector
- MindSerp
- Semparser
- KeyAssort
- coolakov.ru
Первое на что проверялись полученные в результате кластеризации эталонного ядра по этим сервисам группы – это не делает ли сервис слишком широкие группы. А именно не попали ли запросы из разных групп эталонного ядра в один кластер по версии сервиса.
Но только такого сравнения не достаточно. Сервисы делятся на два подхода к некластеризованному остатку фраз:
- сделать для них общую группу «Некластеризованные»;
- сделать для каждой некластеризованной фразы группу из нее одной.
По причине п.2 появилась необходимость смотреть на количество фраз, которые находятся в одной группе эталонного ядра и попали в разные по сервисам.
В сравнении я использовал оба этих параметра в виде соотношения – какой процент фраз от общего количества попал не в свою группу.
Результаты сравнения:
- Топвизор
- разные группы эталона в одной по сервису – 4%
- одна группа эталона в разных по сервису – 7%
- Pixelplus
- разные группы эталона в одной по сервису – 0%
- одна группа эталона в разных по сервису – 7%
- Serpstat
- разные группы эталона в одной по сервису – 0%
- одна группа эталона в разных по сервису – 3%
- Rush Analytics (132 фразы, demo)
- разные группы эталона в одной по сервису – 11%
- одна группа эталона в разных по сервису – 8%
- Just Magic
- разные группы эталона в одной по сервису – 0%
- одна группа эталона в разных по сервису – 9%
- Key Collector
- разные группы эталона в одной по сервису – 12%
- одна группа эталона в разных по сервису – 16%
- MindSerp – не удалось получить демо, не выходят на связь
- Semparser
- разные группы эталона в одной по сервису – 1%
- одна группа эталона в разных по сервису – 3%
- KeyAssort
- разные группы эталона в одной по сервису – 1%
- одна группа эталона в разных по сервису – 1%
- coolakov.ru
- разные группы эталона в одной по сервису – 0%
- одна группа эталона в разных по сервису – 18%
Итоги
В качестве оптимального решения для нашего проекта была выбрана программа KeyAssort – это именно программа, а не онлайн-сервис, лицензия покупается однократно, привязывается к железу.
Неплохие результаты показал популярный онлайн сервис Serpstat, но для нашего случая чуть хуже, а также значительно дороже. Если брать большие объемы запросов в месяц и использовать его только для кластеризации – он не рентабелен. Возможно, если использовать кластеризатор вместе с другими его инструментами, то он и окажется приемлемым по цене.
Самые худшие показатели у программы Key Collector, что все равно не отменяет необходимость ее иметь в своем арсенале для любого сеошника.
Очень удивил сервис MindSerp, через сайт которого я так и не смог получить никакой обратной связи по поводу демо. Если представители этого сервиса прочитают статью, может быть я добавлю в сравнение и его)
habr.com
Латентно-семантическое индексирование. coolakov.ru
Рассмотрим упрощение терм-документной матрицы
Но сперва нам нужно обосновать такую аппроксимацию. Вспомним представление документов и запросов в векторном пространстве, введённое в Разделе 6.3 (страница). Это представление в векторном пространстве имеет множество преимуществ, таких как единообразное обращение к запросам и документам как к векторам, вычисление оценки, основанное на косинусном сходстве, способность взвешивать разные слова по-разному, а также его расширяемость за рамки получения документов с целью кластеризации и классификации. Впрочем, представление в векторном пространстве не умеет справляться с двумя классическими проблемами, возникающими в естественных языках: синонимичность и многозначность. Синонимичность — это случаи, когда два разных слова (например машина и автомобиль) имеют одинаковое значение. Представление в векторном пространстве не имеет связи между синонимичными словами, такими как машина и автомобиль — и размещает их в разных измерениях векторного пространства. Вследствие этого вычисляемое сходство между запросом (например “машина”) и документом , содержащим оба слова “машина” и “автомобиль”, не учитывает реальное сходство, которое увидел бы человек. Многозначность же являет собой случаи, когда одно слово, например “лист”, имеет несколько значений, из-за чего вычисляемое сходство получается выше, чем воспринимаемое человеком. Можем ли мы использовать появление слов в разном контексте (например слово “лист”, встречающееся в документе о деревьях, и в документе о фанере) чтобы уловить латентно-семантические ассоциации между словами и решить эти проблемы?
Даже у набора скромного размера матрица документов и слов C скорее всего будет иметь несколько десятков тысяч строк и столбцов, а также ранг в несколько десятков тысяч. При латентно-семантическом индексировании (иногда называемом латентно-семантическим анализом (ЛСА)) мы используем сингулярное разложение матрицы для создания низкоранговой аппроксимации Ck терм-документной матрицы, со значением k, значительно меньшим оригинального ранга матрицы C. В экспериментальной работе, описываемой ниже в этом разделе, значение k принимается в районе 100. Далее мы присваиваем каждую строку/каждый столбец (соответственно слову/документу) k-мерному пространству; это пространство определяется k собственными векторами (соответственно самым большим собственным значениям) и . Заметим, что матрица Ck сама по себе по-прежнему остаётся матрицей , независимо от k.
Далее мы воспользуемся новым k-мерным представлением LSI также, как сделали с оригинальным представлением — вычислим схожести между векторами. Вектор запросов присваивается своему представлению в пространстве LSI через трансформацию
(244)
Теперь мы можем воспользоваться мерой косинусного сходства как в Разделе 6.3.1 (страница) чтобы вычислить сходство между запросом и документом, между двумя документами или между двумя словами. Отметим, что формула 244 никоим образом не зависит от того, что был запросом; это просто вектор в пространстве слов. Это означает, что если у нас есть LSI-представление набора документов, то новый документ может быть “вложен” в это представление с помощью Формулы 244. Это позволяет нам пошагово добавлять документы в LSI-представление. Разумеется, такое пошаговое добавление не учитывает смежность новых добавленных документов (и даже игнорирует любые новые слова, которые в них содержатся). Вследствие этого качество LSI-представления будет деградировать при добавлении всё новых и новых документов и со временем потребует перевычисления LSI-представления.
Точность аппроксимации Ck в C позволяет нам считать, что относительные значения косинусного сходства сохранены: если запрос находится близко к документу в оригинальном пространстве, то они останутся относительно близки в k-мерном пространстве. Но само по себе это не особенно эффективно, учитывая что разреженный вектор запроса становится плотным вектором запроса в маломерном пространстве. Такие вычисления очень затратны, если сравнивать их с затратами на вычисление в его родном виде.
Рабочий пример. Создадим матрицу документов и слов
|
|
| ||||||
| ship | 1 | 0 | 1 | 0 | 0 | 0 |
|
| boat | 0 | 1 | 0 | 0 | 0 | 0 |
|
| ocean | 1 | 1 | 0 | 0 | 0 | 0 |
|
| voyage | 1 | 0 | 0 | 1 | 1 | 0 |
|
| trip | 0 | 0 | 0 | 1 | 0 | 1 |
|
В результате сингулярного разложения этой матрицы, получаем 3 матрицы, приведённые ниже. Первой идёт , которая в этом примере выглядит так:
|
| 1 | 2 | 3 | 4 | 5 |
|
| ship |
| |||||
| boat | 0.00 | 0.73 |
| |||
| ocean | 0.00 |
| ||||
| voyage | 0.35 | 0.15 | 0.16 |
| ||
| trip | 0.65 | 0.58 |
|
При сингулярном разложении считается матрицей слов сингулярного разложения. Сингулярные значения ∑=
2.16 | 0.00 | 0.00 | 0.00 | 0.00 |
0.00 | 1.59 | 0.00 | 0.00 | 0.00 |
0.00 | 0.00 | 1.28 | 0.00 | 0.00 |
0.00 | 0.00 | 0.00 | 1.00 | 0.00 |
0.00 | 0.00 | 0.00 | 0.00 | 0.39 |
Наконец, у нас есть , которая в контексте матрицы слов и документов известна как сингулярно разложенная матрица документов:
|
|
| ||||||
| 1 |
| ||||||
| 2 | 0.63 | 0.22 | 0.41 |
| |||
| 3 | 0.28 | 0.45 | 0.12 |
| |||
| 4 | 0.00 | 0.00 | 0.58 | 0.00 | 0.58 |
| |
| 5 | 0.29 | 0.63 | 0.19 | 0.41 |
|
“Обнулив” все, кроме двух самых больших сингулярных значений ∑, мы получим ∑2=
2.16 | 0.00 | 0.00 | 0.00 | 0.00 |
0.00 | 1.59 | 0.00 | 0.00 | 0.00 |
0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
На основе этого мы вычисляем С2 =
|
|
| ||||||
| 1 |
| ||||||
| 2 | -0.30 | 1.00 | 0.35 | 0.65 |
| ||
| 3 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
|
| 4 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
|
| 5 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
|
Заметьте, что низкоранговая аппроксимация, в отличие от оригинальной матрицы C, может иметь отрицательные значения. Конец рабочего примера.
Рассмотрение C2 и ∑2 в показывает, что последние три строки обеих матриц были заполнены нулями. Это означает, что результат сингулярного разложения в Формуле 241 может быть вычислен только для первых двух строк в представлениях ∑2 и ; после чего мы можем заменить эти матрицы их усечёнными версиями ∑‘2 и . Например, усечённая матрица документов сингулярного разложения в данном примере выглядит так:
|
| d6 |
| |||||
| 1 |
| ||||||
| 2 | 1.00 | 0.35 | 0.65 |
|
Рисунок 18.3 иллюстрирует документы в в двух измерениях. Отметим, что C2 является плотным относительно C.
Рис. 18.3: Документы из Примера 18.4, спроецированные в двумерном пространстве в .
В общем случае мы можем рассматривать низкоранговую аппроксимацию C к Ck как задачу ограниченной оптимизации: ограничением является то, что Ck имеет максимальный ранг k, мы ищем представление слов и документов, составляющих C с низкой нормой Фробениуса при допустимой погрешности (comprising with low Frobenius norm for the error ). При ужатии (forced to sqeeze) слов/документов в k-мерное пространство, сингулярное разложение сведёт вместе слова, встречающиеся в похожих случаях. Данная логика предполагает, что качество результатов не слишком пострадает от уменьшения мерности, но на деле может стать лучше.
Dumais (1993) и Dumais (1995) проводили эксперименты с LSI на документах и задачах TREC, используя широко применяемый алгоритм Ланцоша для вычисления сингулярного разложения. Во время их работы в ранние 90-е LSI-обработка десятков тысяч документов занимала примерно день на одной машине. В своих экспериментах они достигли точности аналогичной или более высокой среднего уровня участников TREC (median TREC participant). Примерно в 20% тем TREC их система имела наивысшую оценку, и чуть-чуть лучше средней, чем стандартные векторные пространства LSI в 350 измерениях. Вот некоторые выводы об LSI, первоначально сделанные из их работы, и после подтверждённые многими другими экспериментами.
Затраты на вычисление сингулярного разложения велики; на момент написания мы не знаем ни об одном успешном эксперименте с более чем одним миллионом документов. Это было самым большим препятствием для широкого внедрения LSI. Как способ решения, можно построить LSI-представление случайно выбранного подмножества документов в наборе, после чего остальные документы “вкладываются”, как описано в Формуле 244.
При уменьшении k уменьшается и отзывчивость (recall), что ожидаемо.
Что удивительно, значение k порядка ста может увеличить точность в некоторых тестах. Это предполагает, что при подходящем значении k LSI решает задачи синонимичности.
LSI лучше всего работает в случаях, где между запросами и документами малое пересечение.
В экспериментах также задокументированы некоторые режимы, когда LSI не удавалось достичь эффективности более традиционных методов индексирования и оценки. Следует отметить (пожалуй очевидное), что LSI имеет те же два недостатка извлечения из векторного пространства: нет хорошего способа производить исключения (искать документы со словом “немецкая”, но без “овчарка”), и нет способа ввести бинарные условия.
LSI можно рассматривать в качестве мягкой кластеризации, принимая каждое измерение уменьшенного пространства за кластер, а значение, которое документ имеет на этом пространстве — за его частичное членство в этом кластере.
Автор перевода: Максим Евмещенко.
Ссылки по теме
coolakov.ru
Кластеризация запросов — Онлайн сервис от Rush Analytics
Кластеризация ключевых слов – это автоматическое распределение запросов по тематическим кластерам (группам) на основе сходства поисковой выдачи Яндекс или Google. Кластеризация делается для решения следующих задач:
- Чтобы понять какие запросы нужно продвигать вместе и на одну страницу, а какие отдельно
- Чтобы превратить огромное количество запросов семантического ядра из «каши» в понятную и логичную структуру
- Чтобы сразу привязать целые группы запросов к уже существующим страницам на сайте и сделать продвижение максимально эффективным
Данный метод группировки запросов появился на рынке совсем недавно, но уже набрал большую популярность. В чем преимущества данного метода?
Создавая модуль кластеризации в Rush Analytics, мы старались сделать его максимально гибким и удобным, чтобы наше решение подходило для любой задачи и любой тематики, а именно:
- Высокая скорость сбора и группировки запросов. Кластеризация семантического ядра, в зависимости от его объема займет от нескольких секунд до нескольких минут
- Настраиваемая точность группировки – в зависимости от качества выдачи в вашей тематике и других факторов вы можете выбрать соответствующую точность кластеризации – от 3 до 8
- Три алгоритма кластеризации:
А) По Wordstat – вершинами кластера (запросы, к которым будут привязываться остальные) становятся самые частотные запросы. Отлично подходит для информационных тематик.
Б) По маркерам– вы сами выбираете маркерные запросы, которые станут вершинами кластера. Отлично подходит для магазинов с преобладающим товарным спросом.
В) Гибридный алгоритм – маркеры указываются вручную, делается группировка запросов. Для запросов, которые не получилось привязать первым методом, автоматически выбираются вершины кластеров по Wordstat и производится повторная кластеризация. Данный метод позволяет достичь максимальной точности и полноты. Подходит для любых проектов
- Простой и понятный интерфейс, в котором смогут разобраться как новички, так и опытные специалисты.
- Отзывчивая служба поддержки. Если у вас возникнут любые технические проблемы или просто понадобится помощь по любому вопросу кластеризации, сбора подсказок или Wordstat, наша поддержка с удовольствием поможет вам.
www.rush-analytics.ru
6 программ и сервисов для SEO специалиста
1. MS Office Excel
Большую часть работ (сортировку, группировку, анализ и т.п.) вам придется делать в MS Office Excel. У вас должна быть или она или её бесплатный аналог — приложение Calc из пакета Libre Office, функционально ей не уступающий.
2. Составление семантического ядра — KeyKollector
Сложно переоценить важность этого приложения. Оно (или его бесплатная альтернатива «Слово*б») должна быть в арсенале каждого SEO-специалиста.
Продвижение сайта начинается с составления семантического ядра, качественность его сборки определит результат. Это фундамент SEO-кампании, который задействуется на всех этапах продвижения.
К основным возможностям программы можно отнести:
- Сбор ключевых слов и данных по ним из Yandex Wordstat, Google Adwords и Rambler Adstat.
- Сбор поисковых подсказок.
- Анализ данных Яндекс.Метрики, Google Analytics и других популярных сервисов статистики.
- Анализ запросов (конкурентность, сезонность, геозависимость и т.п.).
- Подбор под запросы релевантных страниц.
- Мониторинг позиций сайта.
- Экспорт ключевых слов в такие системы как Sape.
Результаты работы экспортируются в MS Office Excel, что облегчает дальнейшую работу с ядром.
3. Сервисы кластеризации
После того, как вы составили ядро, ключевые фразы нужно правильно сгруппировать. Если ядро небольшое (в пределах 50 фраз), такую работу несложно сделать вручную — например, используя MS Office Excel или Libre Office Calc. Важно понимать принцип группировки: на одной странице нужно собирать фразы, которые отличаются только лексически (набором слов), но не семантически (имеют общий смысл):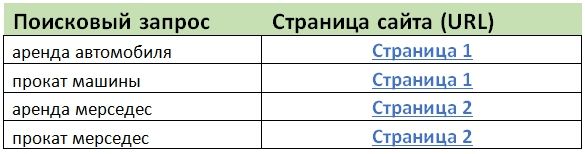
Что делать, если задача кажется нерешаемой из-за недостатка опыта или большого числа запросов? Помогут сервисы кластеризации. Они произведут группировку, изучив сайты в ТОП-10. Результат их работы выглядит так: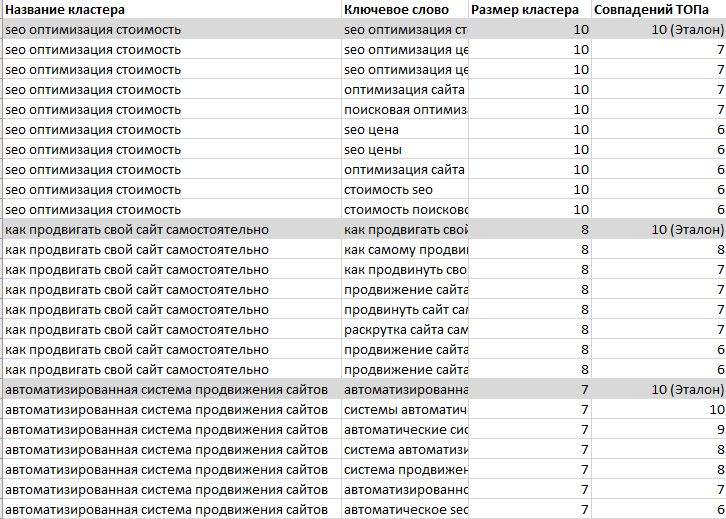
Платные сервисы кластеризации:
- rush-analytics.ru
- just-magic.org
Бесплатные сервисы кластеризации:
- coolakov.ru/tools/razbivka/ (до 500 слов)
Результаты выгружаются в MS Office Excel.
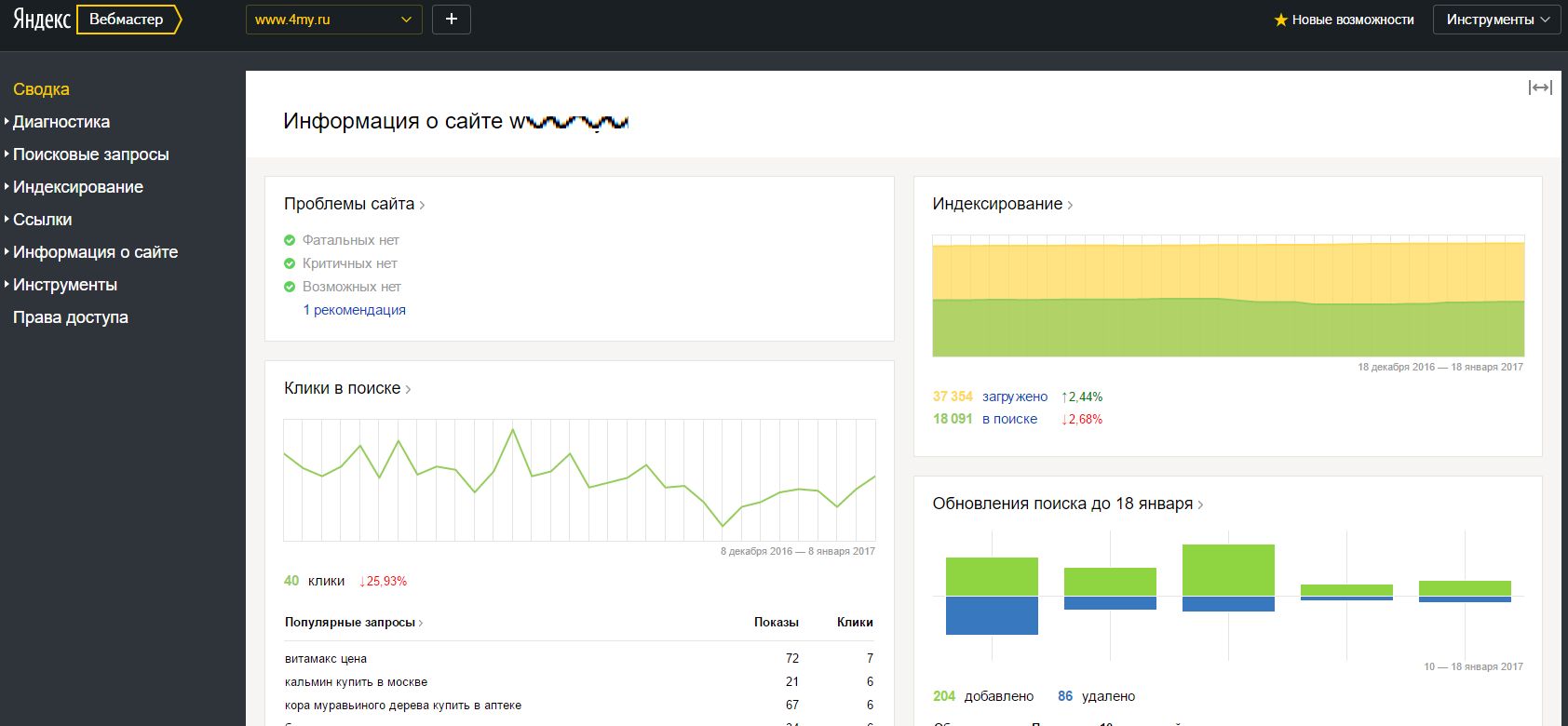
4. Панели Я.Вебмастер и Search Console (Google Webmaster Tools)
Здесь содержится сводная статистика соответствующих поисковых систем, касающаяся вашего сайта: количество проиндексированных страниц, видимость, санкции, внешние ссылки и другая полезная информация.
5. Сбор позиций
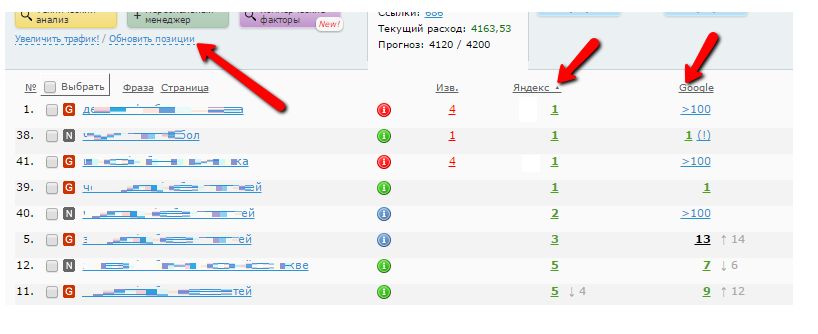
Продвижение сайта имеет целью рост его позиций в выдаче поисковых систем. Наблюдать динамику этого процесса крайне важно для оценки и корректировки выбранной стратегии. Со сбором позиций поможет всё тот же KeyKollector, при условии использования платной версии.
Сервис Wizard.Sape ведёт такой мониторинг бесплатно для любого активного проекта или за небольшую плату, если проект неактивен (не закупаются ссылки):
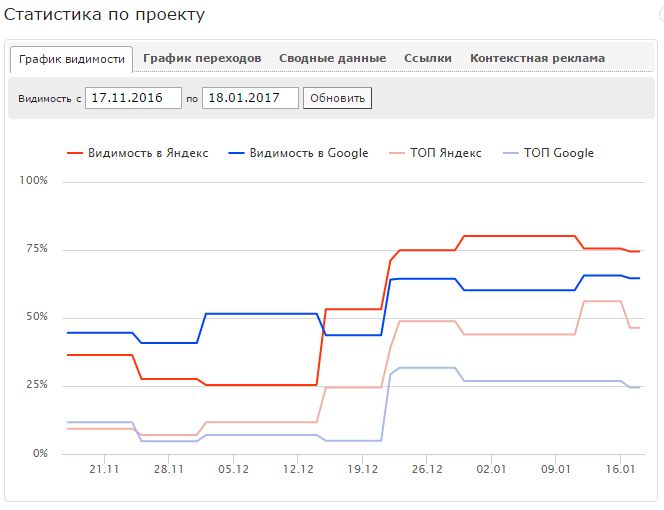
Для наглядности Wizard.Sape строит графики изменения позиций:
И здесь все данные можно выгрузить в MS Office Excel.
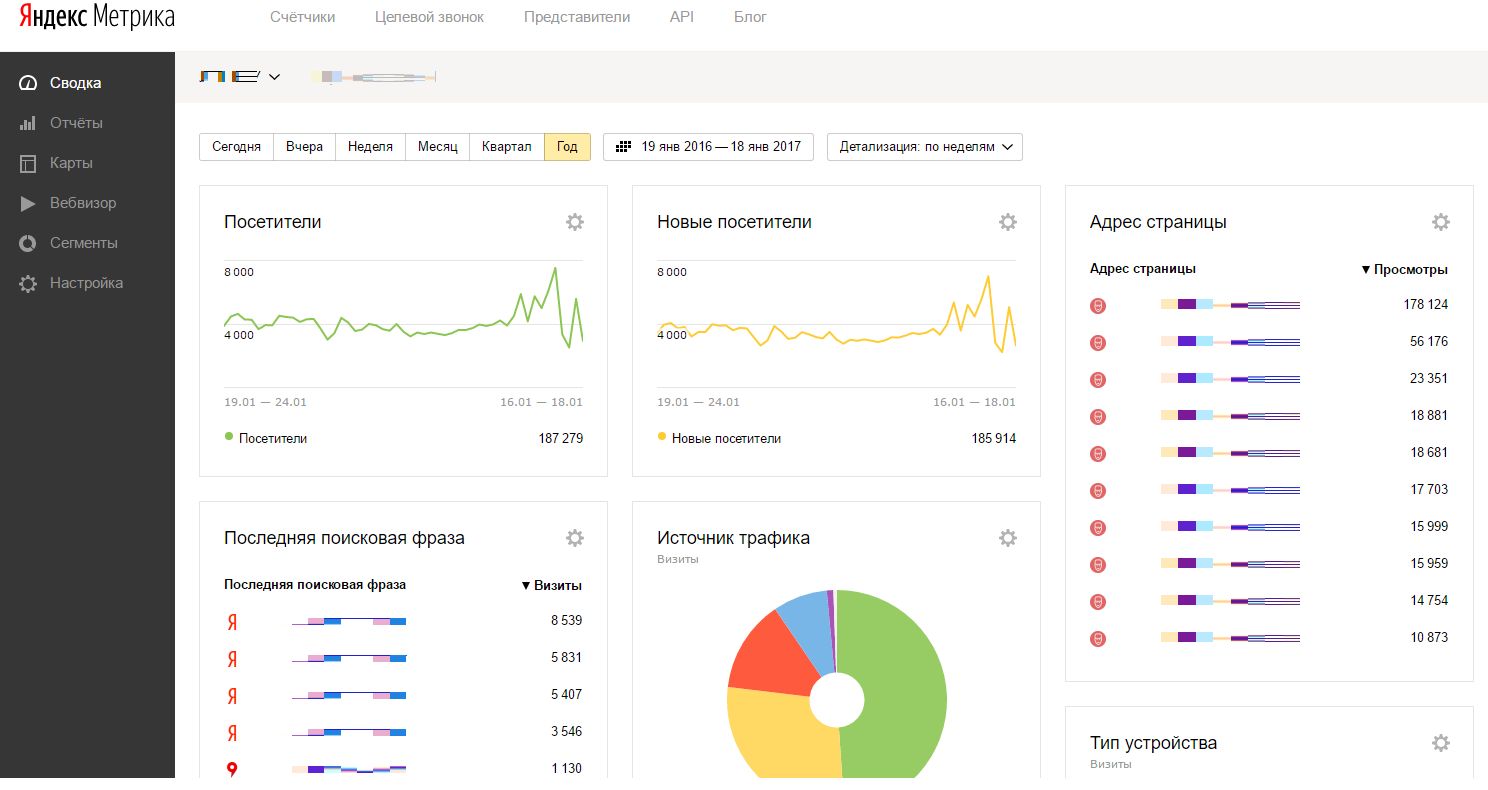
6. Посещаемость сайта
Любые мероприятия по продвижению направлены на рост целевой аудитории сайта. Системы статистики Яндекс.Метрика и Google Analytics помогут понять откуда и сколько посетителей пришло на ваш сайт, и, выявив особенности их поведения, сделать выводы об эффективности кампании по продвижению в целом или её отдельных составляющих.
В этом кратком обзоре, разумеется, перечислены далеко не все существующие инструменты, используемые при продвижении. В частности, мы не остановились на способах отбора ссылочных доноров, изучения их эффективности, анализе сайтов, занимающих высокие позиции и т.п. Но мы выделили самое важное: то, без чего не проводятся работы по продвижению в поисковых системах в рамках нашей компании.
spark.ru
Как использовать инструмент «Группировка запросов по ТОПу» и какие его преимущества?
Инструмент «Группировка запросов по ТОПу выдачи Яндекса и Google» незаменим для формирования файла распределения запросов по URL, построения оптимальной структуры сайта с точки зрения SEO.
Что умеет инструмент?
Основное его предназначение — кластеризация семантического ядра и автоматизация процесса формирования файла распределения.
Кроме того, инструмент имеет следующие полезные функции:
-
Определение текущие позиции сайта по запросам (ТОП-100).
-
Сбор частот запросов: общая и точная.
-
Поиск для каждой фразы наиболее релевантного URL на сайте.
-
Определение количества главных страниц в ТОП-10 выдачи по запросу.
-
Вспомогательная статистика: число запросов в группе, порядковый номер фразы при загрузке.
-
Хранение истории кластеризации предыдущих запросов (до 40 файлов).
Как пользоваться группировкой?
Для определения релевантных страниц нужно ввести доменное имя сайта? список поисковых запросов, который требуется кластеризовать, и поисковую систему.
Далее — выбрать метод обработки, регион, степень группировки, в чек-боксах проставляются необходимые галочки и нажимается кнопка «Проверить».
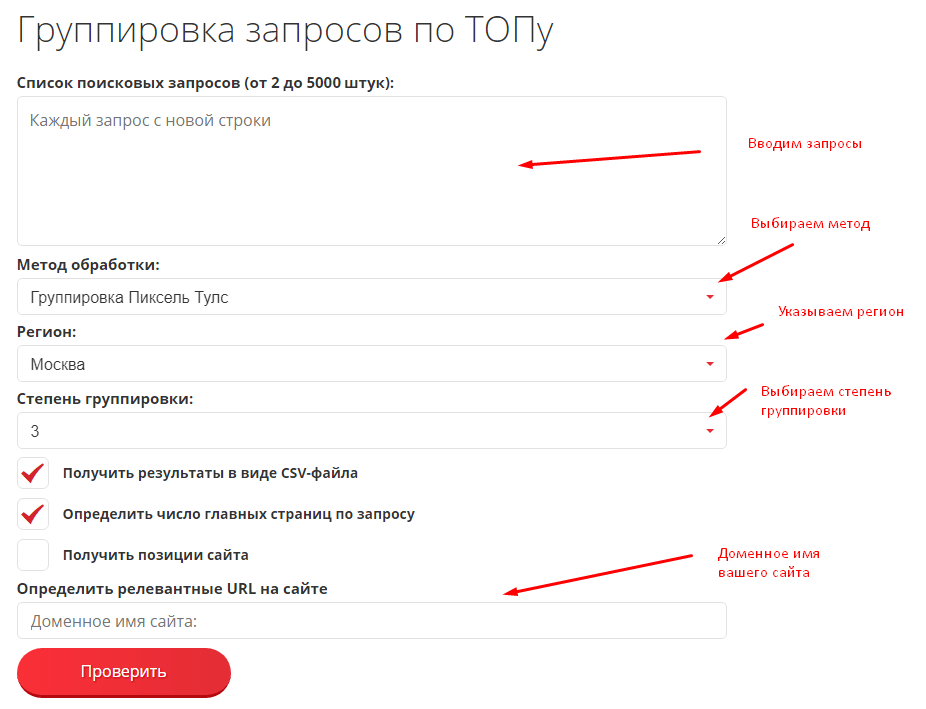
Список поисковых запросов, которые можно кластеризовать по ТОПу за один раз, достаточно велик — до 5000 фраз.
При работе доступно четыре метода кластеризации. Первые три — вполне традиционные и привычные для SEO-специалистов, четвертый — авторская разработка:
-
Сильная связь в группах (так называемый Hard-метод).
-
Средняя связь в группах (Middle).
-
Слабая связь в группах (Soft).
-
Метод «Пиксель Тулс» — уникальный алгоритм, который умеет классифицировать запросы и обеспечивает более точную группировку, так как результаты выдачи по каждому поисковому запросу подвергаются предварительной фильтрации — удалению крупных справочников («Википедия» и прочие из «чёрного списка»), витальных URL, результатов, полученных с помощью алгоритма СПЕКТР и прочих примесей, которые не являются органической выдачей поисковой системы Яндекс и искажают исходные данные.
При продвижении по трафику можно использовать Soft-метод, так как в этом случае не требуется 100% выводимость запросов в группах, а ставка идёт на их количество.
Если же задача вывести максимум запросов в ТОП — рекомендуется использовать метод группировки «Пиксель Тулс».
В инструменте доступно быстрое определение релевантных URL сайта и возможность получения количества главных страниц в выдаче по запросу, что позволяет в дальнейшем скорректировать распределение.
Степень или сила группировки может варьироваться. Рекомендуемая степень равна трем, она введена по умолчанию.
Обычно её достаточно для получения оптимальных результатов. Если группы получаются довольно малочисленные, а список поисковых запросов достаточно обширный — число можно снизить до двух.
Сила / степень — количество одинаковых URL, которые должны встретиться в выдаче по двум запросам, чтобы алгоритм мог ассоциировать их в группу.
Сервис хранит предыдущие результаты в таблице, которую можно скачать в CSV, переименовать, либо удалить.
Как это работает?
Сервис в режиме онлайн производит сканирование результатов выдачи в выбранной поисковой системе, определяет, по каким запросам находятся одинаковые URL-адреса. В методе «Пиксель Тулс» — дополнительно исключает из анализа ресурсы, которые, скорее всего, не соответствуют вашему сайту и ранжируются не по общей формуле релевантности, будут исключены и результаты, найденные с помощью алгоритма «Спектр».
Время обработки зависит от количества поисковых запросов, но в целом, результат получается довольно быстро.
При скачивании в предложенном названии файла указывается метод обработки, сила группировки и дата.
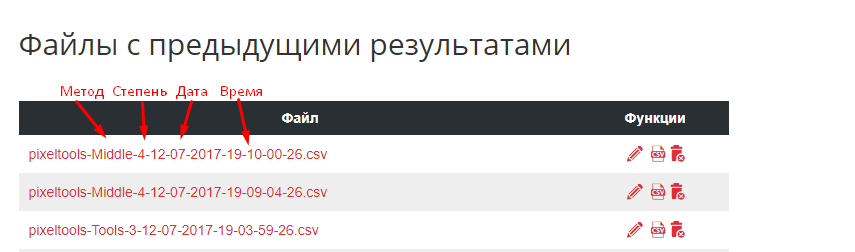
В файле результатов доступна нумерация поисковых запросов в той очередности, в которой они были добавлены, что позволяет в любой момент отсортировать файл как в исходном варианте.
Также в нем присутствуют столбцы «Группа» и «Релевантный URL на сайте». Релевантный документ определяется даже в случаях, когда сайт находится за пределами ТОП-100 результатов выдачи, и он часто является оптимальной посадочной страницей для данной группы запросов.
Дополнительно выводится количество главных страниц в выдаче Яндекса или Google, что позволяет понять, какую страницу лучше продвигать. Если по большому количеству разных запросов много главных страниц в выдаче, то для оптимального продвижения рекомендуется создавать поддомены.

Еще один столбец — текущая позиция вашего сайта, которая показывает, насколько осмысленно менять релевантную страницу по данному поисковому запросу. Если сайт уже в ТОП-3, то понятно, что менять стратегию продвижения на текущий момент нет необходимости.

Столбец «Количество запросов в группе» позволяет быстро понять, какие группы требуется дополнительно разбить, а какие — наоборот, объединить.
Путем простого форматирования в Excel можно преобразовать файл в таблицу и отсортировать по любым интересующим нас свойствам: релевантному URL, количеству главных страниц либо по количеству запросов в группе.
Это позволяет довольно быстро понять, как классифицировать запросы. Например, если два запроса ассоциированы в одну группу, при этом у них разные релевантные страницы и по ним обоим по 9 или даже 10 из 10 главных страниц в выдаче, соответственно, по обоим запросам желательно продвигать именно главную страницу.
С помощью этого инструмента файл оптимального распределения запросов по посадочным страницам формируется буквально в несколько кликов.
Удачи в использовании и онлайн-группировке запросов по ТОПу!
Задайте вопрос или оставьте комментарий
Перейти к инструменту «Группировка запросов по ТОПу»Другие вопросы нашего FAQ
tools.pixelplus.ru
Группировка запросов. Бесплатное тестирование сервиса. [Архив]
Просмотр полной версии : Группировка запросов. Бесплатное тестирование сервиса.
Приветствую.
Предлагаю инструмент для автоматической разбивки кучи запросов на группы для дальнейшего продвижения.
Если вы сторонник байки «один запрос — одна страница», то счастья вам и здоровья.
Если вы знаете, что схожие запросы можно и нужно группировать по страницам, но вручную разребать десятки и сотни запросов лень, то велкам (http://coolakov.ru/tools/razbivka/).
Что и как делает сервис
Вы загружаете в него массив запросов (1 запрос на строку), скрипт проверяет, какие запросы можно группировать, а какие нет, и выводит вам табличку с запросами рассортированным по «кучкам».
Логика основана на выдаче яндекса: если есть в топе какая-либо страничка, которая успешно ранжируется по нескольким запросам, то эти запросы можно объединить в группу.
При группировке большого количества запросов логика пока несовершенна, но для того и выкладываю скрипт: надеюсь, что его тут засрут по самое небалуйся и укажут на кучу косяков в его работе.
http://coolakov.ru/tools/razbivka/
pimandr, Кто писал скрипт? Я надеюсь профи продвижения участвовал в нём? Забил пример и понял, что скрипт уг …
№ Запросы
1 изготовление кошельков кожаных
2 продажа кожаных портмоне
3 портмоне из красной кожи
4 женские кошельки из кожи
5 заказать кожаный кошелек
заказать кожаное портмоне
Стоимость кожаных портмоне
заказать кожаный кошелек
заказать кожаное портмоне
Стоимость кожаных портмоне
И что вас не устраивает? К примеру koffer.ru по 3 этим запросам в топ10 одна и та же страница. Впрочем, это лишь одно общее пересечение у этих 3-х запросов. все остальные пересечения — попарные.
Именно для группировки неявных запросов и предназначен скрипт.
К примеру koffer.ru по 3 этим запросам в топ10 одна и та же страница.
И значит что это правильно? Это правильно если у вас неограниченный бюджет, неправильно группировать запросы исходя из выдачи.
Это значит, что это возможно. К примеру «слоны» и «дирижабли» вы на одной странице никак не продвинете, даже с неограниченным бюджетом.
И, собственно, как я и писал в старпосте, смысл — набрать подобных «косяков», чтобы на их основе подправить логику объединения запросов. Поэтому спасибо вам.
неправильно группировать запросы исходя из выдачи.
Отчасти вы правы. Исходя только из выдачи — нельзя. Но на ее основе делать начальную разбивку — оч даже можно.
Это значит, что это возможно. К примеру «слоны» и «дирижабли» вы на одной странице никак не продвинете, даже с неограниченным бюджетом.
Спорим? Тот факт, что вы это отрицаете, уже говорит о том, что ваш сервис рандом. К тому же вы сами сказали что берете результат из выдачи — это неправильно. Так делают только дилетанты.
Конкретно об этих двух запросах спорить не буду, так как я привел их в качестве примера.
А тот факт, что вы молниеносно делаете столь мудрые выводы, основываясь на десятисекундной проверке, говорит о том, что дискуссия с вами пользы не принесет. Посему предлагаю ее закончить.
Еще раз спасибо за участие.
Я просто вам дал совет, что формирование группы запросов исходя из выдачи — это неправильно 😉 Ни в коем случае не хочу вас упрекать — это ваш сервис и вы вправе использовать любые методы и форумы, а правильные они или нет — решать каждому. Я только высказал свое мнение.
Добавьте красивое скачивание в exel. Сколько максимум можно загрузить запросов в сервис? Группировка происходит на основе пересечения лишь по одному сайту или 2, 3, 4 — какой порог? Куда деваются не распределенные запросы, или таких нет и они идут на одну статью?
Ladycharm
29.04.2014, 00:22
Забил пример и понял, что скрипт уг … Это не страшно, зато ТС на халяву соберёт тонны ключевиков и продвигаемых запросов.С учётом того, что сейчас статистику запросов закрыли и ПС и li.ru — очень даже неплохое решение 🙂
Сколько максимум можно загрузить запросов в сервис? Группировка происходит на основе пересечения лишь по одному сайту или 2, 3, 4 — какой порог? Куда деваются не распределенные запросы, или таких нет и они идут на одну статью?
Порядка 600 обрабатывает без проблем, больше не тестировал.
«Порог пересечения» — 3 сайта. Но об этом я пока еще думаю.
Нераспределенные запросы не группируются с другими и выводятся отдельно.
зато ТС на халяву соберёт тонны ключевиков и продвигаемых запросов.
Какая милая паранойя))
Ну, то есть, версия, конечно, интересная, но до сих пор существует достаточное количество более простых способов набрать тонны ключевиков:)
IBakalov
29.04.2014, 16:32
Идея не плоха, жаль что тест только по вечерам и нет возможности пощупать руками.
pimandr, советую вам посмотреть (если еще не смотрели) вот эту видюху http://vk.com/video-60812546_166591559 там озвучивается идея аналогичная вашей, возможно что-то полезное найдете.
IBakalov, сори, но ограничение по времени связано с недостатком xml запросов на моем аккаунте.
За видео конечно спасибо, но я его уже видел. Да, идея, по сути, та же самая.
CB9TOIIIA
05.05.2014, 22:25
Сегодня воспользовался, вполне адекватно раскидал запросы 🙂
P.S. Если был бы opensource было бы замечательно.
CB9TOIIIA, спасибо.
был бы opensource было бы замечательно
В соседней теме (https://searchengines.guru/showthread.php?t=840356) за аналогичную услугу по 65 коп. за запрос просят. Предложите им, может они на опенсурс согласятся 🙂
burunduk
13.05.2014, 19:15
В соседней теме за аналогичную услугу по 65 коп. за запрос просят
там совершенно другая услуга 😉
burunduk, она значительно шире и полнее — безусловно. но то, что это совершенно другая услуга — не соглашусь.
к тому же, сравнивал выложенную там в качестве примера разбивку с тем, что делает мой скрипт — во многом похоже, во многом — не хуже.
Разница в том, что там это — Услуга. А у меня просто скриптик.
CB9TOIIIA
13.05.2014, 23:19
Попробовал на СЯ из 2500 запросов… не справился сервис, разбил пополам, с 1000 справился, а вот с остальным нет. Ех
CB9TOIIIA, спасибо за тест, на 2к я и сам не проверял еще)
Напиши в личку плиз, обсудим, что делать и как с этим бороться.
Хотя вероятнее всего, просто лимит по XML у меня превысился, поэтому и не обработалось. Ща уже лень проверять.
Но после полуночи можно проверять заново!
burunduk
14.05.2014, 02:33
советую вам посмотреть (если еще не смотрели) вот эту видюху http://vk.com/video-60812546_166591559 там озвучивается идея аналогичная вашей, возможно что-то полезное найдете.
ну может сразу на оригинал ссылку давать (http://seopult.tv/programs/conference/yadro_v_100_tichyach_zaprosov/) 😉
IBakalov
14.05.2014, 10:53
burunduk, я смотрю вы прямо трепетно относитесь к авторству в SEO технологиях 😉
Очень интересная проблема, так как самому приходится разбивать огромные кучи запросов. Уверен если ваш скрипт довести до ума то он будет очень популярен. Как стать зарегистрированным пользователем?
Вы морфологию проверяете (синий пиджак, синие пиджаки)? Если нет, то могу вас подкинуть полезной инфы.
Gavich, спасибо.
Морфологию проверять нет нужды, это решается на стороне яндекса.
Зарегистрироваться пока никак. Не потому, что я жадный, а потому, что лимит XML запросов не слишком велик.
И именно по этой же причине скрипт работает лишь с 8 вечера.
А если дать возможность пользователю вводить свои акаунты и прокси, как в кей коллекторе?
Есть ли возможность указать максимальное количество групп, максимальное количество фраз в группе?
burunduk
14.05.2014, 22:40
IBakalov, а что в этом плохого? 🙂
IBakalov
15.05.2014, 09:49
burunduk, да на самом деле ничего плохого нет 🙂 в прошлый раз вы уследили, что по seohide был дан не верный пруф, сейчас вот тут 🙂 У вас мониторинг настроен? 😉
burunduk
15.05.2014, 13:15
IBakalov, нет, просто читаю, то что может оказаться потенциально интересным 🙂
Прогнал вчера 200 фраз по «skechers» (бренд обуви) по региону Украина. Разбивка поучилась слабенькой. Скорее всего из-за низкой частотности фраз: половина с частотностью 1, 90% до 10. Не отнесло в одну категорию фразы с транслитом-переводом бренда+слово. Думаю проблема в том что довольно мало страниц соответствую данным запросам и текстов как таковых на посадочных страницах нету. Если ваш алгоритм можно обучать на выборках, то могу вам скинуть ручные разбиения.
pimandr, топ10 — это техническое ограничение или есть какой-то умысел?
Планируется ли софт на продажу?
IBakalov
16.05.2014, 11:02
Вот кстати у меня вопрос возник, как будет сгруппировано, если:По [запрос1] в выдаче есть
site1
site2
site3
site4
site5
По [запрос2] в выдаче есть
site3
site4
site5
site6
site7
site8
По [запрос3] в выдаче есть
site6
site7
site8
site9
site10
У 1 и 3 запросов нет пересечений вообще, у 1 и 2 есть три пересечения, у 2 и 3 тоже три, как объединять?
Есть ли возможность указать максимальное количество групп, максимальное количество фраз в группе?
Зачем? Вот вы вводите 10 запросов и хотите чтоб они разбились на 2 группы. А на деле они разбиваются на 4. Как и, главное, зачем они должны биться на 2?
Прогнал вчера 200 фраз по «skechers» (бренд обуви) по региону Украина. Разбивка поучилась слабенькой. Скорее всего из-за низкой частотности фраз: половина с частотностью 1, 90% до 10. Не отнесло в одну категорию фразы с транслитом-переводом бренда+слово. Думаю проблема в том что довольно мало страниц соответствую данным запросам и текстов как таковых на посадочных страницах нету. Если ваш алгоритм можно обучать на выборках, то могу вам скинуть ручные разбиения.
Перепроверил ваши запросы, действительно слабенько. Но дело не в частотности. Суть примерно в том, что когда в одной группе более определенного количества слов, то последующие слова добавляются в группу по слишком жестким критериям. Из-за чего в вашем случае «сапоги скетчерс», «скетчерс купить», «skechers купить» объединились, а вот «сапоги skechers» уже «не влезли» в группу. То есть, дело не в транслите вовсе.
Большое спасибо за пример, он мне очень поможет.
Алгоритм пока не обучаем, пока обучаюсь лишь я:)
У 1 и 3 запросов нет пересечений вообще, у 1 и 2 есть три пересечения, у 2 и 3 тоже три, как объединять?
Над этим вопросом я тоже очень долго заморачивался:) Не знаю, каким должно быть правильное решение, и есть ли оно вообще. Но у меня они объединяются. Я рассуждал так: раз уж 2 пересекается и с 1 и с 3, то оч мала вероятность того, что 1 и 3 окажутся взаимовытесняющими. Мои личные проверки показали, что это более-менее разумно.
Разумеется, в этой логике есть косяки. Примерно по этой причине сер4ер посчитал скрипт уг (https://searchengines.guru/showpost.php?p=12817881&postcount=2)
Если вы предложите какой либо альтернативный способ, как поступать в подобных случаях — с удовольствием поэкспериментирую.
Топ10 — это техническое ограничение или есть какой-то умысел?
Техническое ограничение — топ100. Топ10 — это наиболее приемлемый и достаточный способ объединения. Экспериментировал с топ20 и 50 — преимуществ не увидел, а сложность работы возрастает значительно. Хотя burunduk в этом вопросе со мной наверняка не согласится:)
NikitoZZ
20.06.2014, 15:50
Попробовал, прикольная разбивка.
Особо не тестил, но проверку на пару разбивок сервис прошёл на отлично, мне понравилось!
Спасибо.
searchengines.guru
Сервисы по кластеризации запросов — платные и бесплатные
Кластеризация – обязательная часть процесса составления качественной семантики сайта. Но поскольку ручной процесс занимает много времени, хороший сервис по кластеризации запросов – лучший вариант сделать эту работу максимально быстро.
Лучшие сервисы по кластеризации и группировке запросов
Мы отобрали 5 лучших инструментов, которые помогут вам эффективно сгруппировать ключевые фразы в короткие сроки.
Rush Analytics
Онлайн-сервис Rush Analytics обещает быструю группировку до 10 000 ключей всего за 10 минут. Для веб-мастеров, которые сомневаются в выборе, разработчики предлагают возможность протестировать инструментарий, сгруппировав 100 запросов бесплатно.
Для запуска процесса вам понадобится загрузить список ключей и подобрать тип кластеризации. Все остальное будет сделано за вас.
Topvisor
Чтобы произвести группировку, сначала понадобится импортировать ядро. В отличие от, например, Rush Analytics, здесь невозможно загрузить файл с расширением .xls. Так что все ключи придется предварительно вставить в документ с расширением .txt.

Key collector
По праву является одной из лучших программ для сбора семантики, группировки ключей, и других операций, связанных с продвижением веб-ресурсов в поисковиках. Несмотря на то, что этот сервис кластеризации поисковых запросов полностью платный, его предпочитает подавляющее большинство как опытных, так и начинающих SEO-специалистов.
До начала процесса укажите тип кластеризации, ее точность в графе «Сила по SERP» и поисковую систему, основываясь на ранжировании которой процесс будет производиться. После завершения работы готовые результаты можно экспортировать.

Just-Magic
На этом сайте выполнить группировку можно с помощью инструмента «Кластеризатор» в разделе «Сервисы». К сожалению, разработчики не предоставляют пробной версии либо тестового периода. Поэтому, если вам нужен именно этот сервис кластеризации поисковых запросов, придется купить один из тарифов или оформить подписку. По словам основателей «Just-Magic», подписка намного выгоднее, чем тарифы. Так что если вы планируете пользоваться «Кластеризатором» постоянно, рекомендуем приобрести подписку.
Coolakov.ru
Сайт позиционирует себя, как единственный полностью бесплатный инструментарий для группировки. Работает он, основываясь на ранжировании Yandex.
Несмотря на то, что бесплатные сервисы часто показывают себя не лучшим образом, кластеризация прошла достаточно быстро, а результаты были отличными. Выполнить группировку ключей можно здесь: http://coolakov.ru/tools/razbivka/.

azbuka-seo.ru