
Индексирование документов архива
Консолидация данных в одном месте
Индексирование документов в результате даёт структурированную базу данных, которую вы можете загрузить в своё стандартное бизнес-приложение, например, 1С или CRM систему, и работать с данными в одном месте без надобности иметь бумагу или скан-копии под рукой.
Интеллектуальное распознавание данных
Индексирование документов осуществляется в большей мере путём автоматического распознавания данных. Для индексирования применяем самообучающиеся нейросети, OCR и другие алгоритмы автоматического распознавания данных и верификации данных, в меньшей мере применяя ручную обработку, что позволяет нам дать вам лучшие сроки и цены.
Заказать консультациюЗачем нужна индексация документов?
Главный смысл индексации документов – в структуризации данных и возможности дальнейшего быстрого поиска документа или данных по нужным параметрам.
Все данные в одном месте
Современные компании работают с разными носителями информации – от классических бумажных документов, до документов с электронной цифровой подписью. Часто не важно какой формат документа использовался, а важно иметь данные, расположенные на этом документе. Индексирование документов позволяет создать базу данных, нужную для работы, загрузить её в одну систему, и работать с данными, не прибегая к поиску бумажных документов.
Часто не важно какой формат документа использовался, а важно иметь данные, расположенные на этом документе. Индексирование документов позволяет создать базу данных, нужную для работы, загрузить её в одну систему, и работать с данными, не прибегая к поиску бумажных документов.
Точные данные под рукой
Независимо от того, где вы находитесь, все документные данные, нужные для работы, могут быть у вас под рукой – например, в вашем смартфоне. При индексировании документов мы сначала сканируем документы, присваивая ID каждой скан-копии и затем проводим индексирование документов, связывая полученные данные со скан-копиями документов так, что по ключевым параметрам вы можете найти и скан-образ документа.
Что нужно знать перед тем, как заказать индексирование документов?
Так как индексирование документов направлено на создание базы полезных данных, перед заказом услуги по индексированию документов нужно определить какие данные вы хотите распознать. Мы можем подсказать вам как определить набор этих данных.
Как выбрать поля для индексации документов
Наиболее частые поля документов для индексации это:
- Дата документа
- Номер документа
- Наименование контрагента
- Реквизиты контрагента
- Сумма документа
Их следует проиндексировать, потому что по ним можно найти точно тот документ, который вам нужен, а также получать данные в комплексе по конкретному клиенту или сделке.
Кроме стандартных вышеперечисленных полей следует добавить те, которыми вы оперируете внутри компании для работы с документами, например:
- Номер филиала, где был подписан документ
- ID/наименование продукта
- Номер сделки
- И т.д.
Как мы осуществляем индексирование документов
Индексирование документов в ОСГ осуществляется через сканирование документов и распознавание данных со скан-образов документов.
Типизация документов
Перед сканированием мы определяем маски типовых документов и настраиваем нейросети для выделения нужных данных. Во время сканирования нейросети определяют место нахождения данных на документе, а система OCR и другие системы автоматического распознавания данных считывают и распознают нужные символы.
Во время сканирования нейросети определяют место нахождения данных на документе, а система OCR и другие системы автоматического распознавания данных считывают и распознают нужные символы.
Абсолютная конфиденциальность
Сервера ОСГ, на которых располагается информация во время индексирования, находятся в закрытой DMZ зоне, которая закрыта по периметру при помощи аппаратных средств Cisco и модуля системы обнаружения вторжений. Визуально данные также защищены – во время ручной индексации операторы видят только фрагмент документа, а не полностью скан-образ.
Ручной ввод
При необходимости человеческого контроля, например, при работе с рукописными документами, мы используем ручной ввод данных. В случае ручного ввода обученные специалисты ОСГ центра обработки данных индексируют документы, работая через специальные приложения ОСГ.
Верификация данных
Все извлечённые данные проходят процедуру верификации через перекрёстную сверку параметров документа, а также через двойной ввод данных в случаях, когда применялась ручная индексация.
Пример индексирования стандартных учётных документов
Клиент определил нужные поля для последующего занесения в 1С:
Результат индексирования документов
| тип документа | счет-фактура |
|---|---|
| номер документа | 6754-12 |
| дата документа | 20.08.2019 |
| контрагент | Про Презентация, ООО |
| ИНН | 8612886004 |
| сумма | 233 400,00 |
| НДС | 42 012,00 |
Этапы услуги индексирования документов
Определение полей документа на индексацию
Перед созданием баз данных поможем вам определить какие поля и в каком формате нужно проиндексировать, чтобы достичь ваших целей по работе с данными.
Сканирование документов
Чтобы захватить и оцифровать данные, необходимо произвести процедуру сканирования документов. Это не задержит процесса – ОСГ может сканировать до 1 млн документов в день.
Интеллектуальное распознавание данных
Применяем нейросети для типизации документов, технологии OCR и другие системы для автоматического распознавания данных быстро и точно. При необходимости применяем ручной ввод данных.
Сделать запрос сейчас
Перейти
Полезные ссылки по индексированию документовСайт ОСГ предоставляет посетителям возможность досконально изучить вопросы управления документами и информацией. Используйте ссылки или посетите наш раздел Руководства и инструкции.
Посетите раздел Инструкций
- Внеофисное хранение документов
- Уничтожение бухгалтерских документов
- Хранение кадровых документов
- Хранение документов в Москве
- Хранение документов в Санкт-Петербурге
- Обратитесь к специалисту ОСГ за консультацией
Узнайте больше о компании
об ОСГ
Получите консультацию ОСГ уже сегодня
Полный спектр услуг по работе с документами. Задайте вопросы консультанту: 8 800 200 10 10
Спасибо! Ваше сообщение было успешно отправлено. Мы ответим вам в ближайшее время.
Мы ответим вам в ближайшее время.
ОСГ Рекордз Менеджмент 8 800 200 10 10.
В какой услуге вы заинтересованы?
Архивная обработка документов
Конфиденциальное уничтожение документов
Электронный архив (е-Архив)
Сканирование документов
Хранение магнитных носителей
Бэкапирование данных
Инвентаризация основных средств
Другое
Как вы узнали об ОСГ? Из поисковой системыПо рекомендацииИз рекламыИз статьи
Я согласен(на) на обработку моих персональных данных
Заполняя поля формы и передавая свои персональные данные, Вы подтверждаете, что ознакомились с Политикой обработки Персональных данных и согласны с ее пунктами, и также выражаете своё согласие предоставить ОСГ Рекордз Менеджмент персональные данные о себе.
Индексация, наукометрия — Университет Лобачевского
Данные становятся информацией, если есть основания считать их достоверными. Абсолютное большинство открытых материалов Интернет (как и многие книги) не проходят независимой экспертизы.
Применительно к научным публикациям оценка достоверности (независимая экспертиза) осуществляется в форме рецензирования (single blind или double blind) на стадии приёмки статьи. Её уровень (симулятивный, формальный, содержательный, профессиональный, жёсткий), главным образом, и определяет научный авторитет журнала. Формализованным измерителем авторитета журнала является цитирование опубликованных в нём статей. Корректный учёт цитирований статьи (научного документа) предполагает наличие представительной по отношению ко всему множеству научных документов базы, которая содержит, как минимум, библиографические данные этих документов (индексирует их).
Наукометрия – это, в сущности, система показателей, построенная на сопоставлении библиографических данных: количества публикаций и их цитирований. Такие формализованные показатели, разумеется, не являются исчерпывающими, но в современной массовой и коммерциализованной науке их важность общепризнана.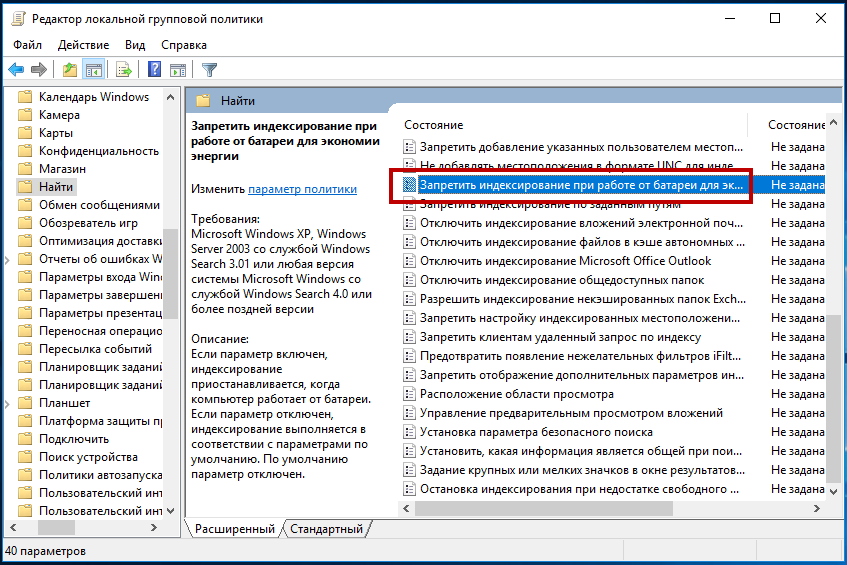
Индексация научных документов, БАЗЫ, наукометрия
|
Научные библиографические базы индексируют некоторое множество источников (оно может быть замкнутым, как в Web of Science Core Collection и Scopus, или открытым, как Google Scolar и РИНЦ). Авторитет таких баз определяется и поддерживается качеством индексируемых ими документов (контента базы). Библиографичеcкие базы не включают полных текстов документов (поэтому не связаны проблемами copyright), а содержат лишь их метаданные (библиографическую запись). Для научной статьи метаданные – это журнал, авторы, название, аннотация, ключевые слова, список цитированных источников. Библиографичеcкие базы сообщают о цитированиях документа или избранной группы документов в ЭТОЙ базе и вычисляют различные наукометрические показатели (статей, авторов, журналов, организаций), связанные с цитированием. |
| Вопрос о значимости того или иного показателя (и, соответственно, той или иной базы) при решении конкретных вопросов относится к сфере административной, а не наукометрической.
Поскольку любая система, будучи формализована алгоритмически (с открытым кодом), в естественных условиях замусоривается и допускает манипуляции (термин predator journals прочно вошёл в мировую практику), необходимы дополнительные меры по отбору источников и их фильтрации (экспертные или алгоритмы с закрытым кодом) для поддержания качества контента. |
|
РИНЦ (общедоступна) – российская библиографическая база, созданная с целью максимально ПОЛНО отразить все публикации РОССИЙСКИХ УЧЁНЫХ. Поэтому (при соблюдении чисто формальных требований при загрузке) входной отбор источников и их фильтрация не проводится. Индексируются более 2600 текущих российских журналов, книги, сборники, труды конференций любого уровня. Данные по публикациям российских учёных в зарубежных журналах экспортируются из Scopus. Наукометрический инструментарий базы по разнообразию выводимых показателей является, пожалуй, беспрецедентным, поскольку строится параллельно на трёх подмножествах контента Научной электронной библиотеки (eLibrary), при этом вычисляется значительное число алгоритмически различных показателей. Показатели периодически пересчитываются 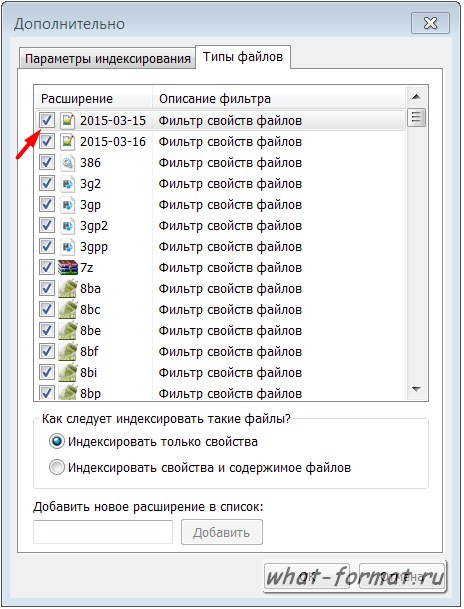 Поскольку требования полноты отражения и качества контента противоречивы, в современных условиях стремительного замусоривания базы (в том числе, с целью «накрутки» показателей) предпринята попытка «приподнять» авторитет базы, выделив при подсчёте показателей упомянутые выше три подмножества контента (три уровня): Поскольку требования полноты отражения и качества контента противоречивы, в современных условиях стремительного замусоривания базы (в том числе, с целью «накрутки» показателей) предпринята попытка «приподнять» авторитет базы, выделив при подсчёте показателей упомянутые выше три подмножества контента (три уровня):
1) весь контент eLibrary, 2) контент РИНЦ (где сохранены все издания, претендующие на научность), 3) ядро РИНЦ. Ядро РИНЦ – на данный момент более 700 российских журналов, первоначально отобранных в 2015 году в результате вполне разумной, хотя и небесспорной (смешанной формализованно-экспертной) процедуры. Причём сделано это с возможностью исключения/дополнения журналов по результатам мониторинга. Все наукометрические показатели вычисляются отдельно по ядру РИНЦ. Авторитет базы (по определению – только внутри страны) и рассчитываемых по ней показателей может выявить лишь время и российская административная практика. Косвенно авторитет базы повышает то, что на её основе формируется отражаемая на портале Web of Science база RSCI (см. ниже). |
|
Авторитетные библиографические базы призваны ответить на три группы вопросов:
В силу международного характера науки для корректного ответа на эти вопросы авторитетная база должна быть полидисциплинарной по содержанию и мировой по охвату. Авторитетность базы не гарантирует отсутствия в ней мусора, шума (или ложной информации). Последнее возможно на уровне отдельных статей (например, отзыв статей, в том числе, из весьма престижных журналов происходит как по инициативе издателей, так и авторов). Но именно в виде исключений, так как качество журналов является в такой базе предметом мониторинга (формализованного и экспертного). |
|
Web of Science Core Collection (доступна в ННГУ), отображаемая на портале Web of Science – исторически первая (идущая от «отца» наукометрии Ю. Гарфилда) авторитетная мировая библиографическая база, обладающая наиболее глубоким архивом и изначально проводившая НАИБОЛЕЕ ЖЁСТКИЙ качественный отбор источников (разумеется, не бесспорный). |
|
При оценке глубины архива базы следует различать собственный и доступный конкретному пользователю архивы. Глубина собственного архива по указанным выше журнальным подбазам – 1970 г. и 1975 г., по конференциям – 1990 г. |
|
Наукометрический инструментарий, относящийся к журналам, выделен на портале Web of Science в отдельный сервис – Journal Citation Reports (недоступен в ННГУ), из которого в базу Web of Science Core Collection по результатам запроса конкретной статьи подгружаются лишь двух- и пятилетние импакт-факторы и квартиль журнала с данной статьёй. Journal Citation Reports – единственная мировая база импакт-факторов научных журналов (исчисляемых, разумеется, на контенте Web of Science Core Collection). Редакции Journal Citation Reports обновляются ежегодно 1 июля и отражают результаты цитирования в статьях предыдущего года издания. |
|
При этом из входящих в Web of Science Core Collection 7 подбаз:
— импакт-факторы вычисляются только для журналов, индексируемых в первых двух подбазах (соответственно, только у этих журналов в JCR есть определённый квартиль). Поисковый инструментарий в базе Web of Science Core Collection – более мощный, чем для других интегрированных на портале Web of Science региональных и национальных баз, среди которых:
Импакт-факторы для входящих в эти базы журналов в Journal Citation Reports не вычисляются, как и для 5 из 7 подбаз в Core Collection. |
|
SCOPUS (доступна в ННГУ) – более молодая авторитетная мировая библиографическая база, индексирующая НАИБОЛЬШЕЕ ЧИСЛО источников. Здесь индексируются научные журналы, выходящие во всех странах мира и по всем областям знания, книги, труды международных конференций. |
|
Scimago Journal & Country Rank (общедоступна) – рейтинговая база журналов (и стран), в которой сходный с импакт-фактором показатель (SJR) рассчитывается на контенте SCOPUS по алгоритму взвешенного цитирования. В соответствии с величиной SJR и предметной областью определяется квартиль журнала. |
|
MEDLINE (доступна в ННГУ) – библиографическая база Национальной медицинской библиотеки США. Отражается на портале Web of Science. Индексирует около 5000 научных журналов из всех стран мира (а также книги) по медицине, живым системам, биофизике и биохимии. Chinese Science Citation Database (CSCD) (недоступна в ННГУ) – первая не англоязычная база, интегрированная на портале Web of Science. Формируется Академией наук КНР и индексирует более 1200 национальных научных журналов по всем отраслям знания с 1989 года. |
|
|
Russian Science Citation Index (RSCI) (доступна в ННГУ) – близкая по контенту к ядру РИНЦ национальная библиографическая база, интегрированная на портале Web of Science с 2015 года (RSCI-2015) и индексирующая входящие в неё журналы с 2005 года.. Библиографические записи даются в двуязычном виде. Поисковые запросы, вводимые прямым набором, могут делаться как в англоязычном, так и в русскоязычном виде. По версии RSCI-2015 в базу входило 653 журнала, отобранных в результате упомянутой выше процедуры для ядра РИНЦ. Обновлённая (после исключения/добавления журналов) версия RSCI-2018 включает 743 журнала (с англоязычными названиями). Русскоязычный список журналов RSCI можно посмотреть здесь. |
 Эти показатели могут отличаться как алгоритмически, например, 2-летний и 5-летний импакт-факторы (в Journal Citation Reports – сервисе на портале Web of Science), CiteScore, SJR и SNIP (в Scopus), g-индекс (в Google Scolar), индекс Хирша и т.д., так и численно для одного и того же алгоритма в силу различия контента, на котором этот алгоритм реализуется (например, импакт-факторы в Journal Citation Reports и в РИНЦ могут отличаться в разы). Поэтому любой наукометрический показатель имеет смысл лишь при указании базы, на которой он вычислен. База может быть общедоступна (например, Google Scolar и РИНЦ) или доступна по подписке (например, Web of Science Core Collection, Scopus).
Эти показатели могут отличаться как алгоритмически, например, 2-летний и 5-летний импакт-факторы (в Journal Citation Reports – сервисе на портале Web of Science), CiteScore, SJR и SNIP (в Scopus), g-индекс (в Google Scolar), индекс Хирша и т.д., так и численно для одного и того же алгоритма в силу различия контента, на котором этот алгоритм реализуется (например, импакт-факторы в Journal Citation Reports и в РИНЦ могут отличаться в разы). Поэтому любой наукометрический показатель имеет смысл лишь при указании базы, на которой он вычислен. База может быть общедоступна (например, Google Scolar и РИНЦ) или доступна по подписке (например, Web of Science Core Collection, Scopus).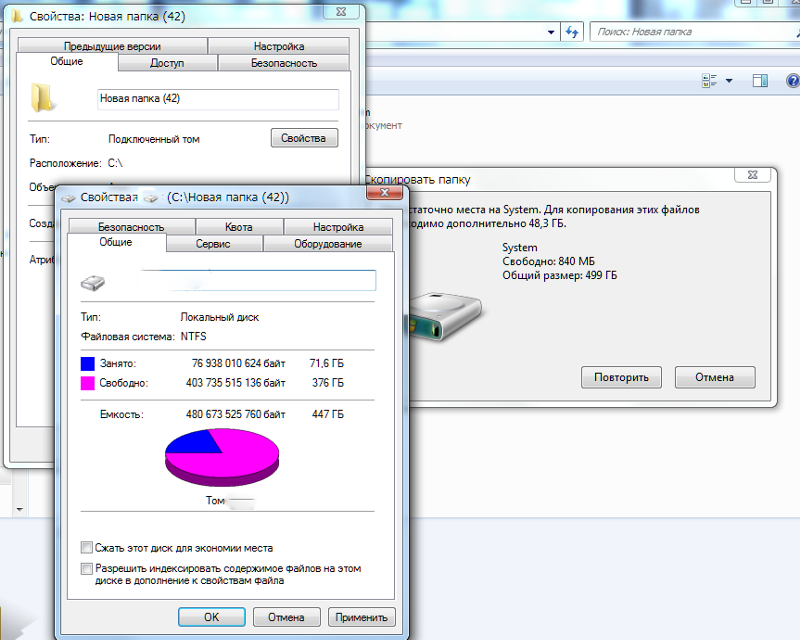 Такие меры применяются в авторитетных библиографических базах при индексации источников (журналов и книг).
Такие меры применяются в авторитетных библиографических базах при индексации источников (журналов и книг).
 Современная авторитетная база (а это коммерческое предприятие) формируется на основе компромиссного разрешения противоречия между качественным отбором источников и объёмом контента базы. Пренебрежение первым ведёт к потере авторитета, сужение контента ведёт к уменьшению востребованности.
Современная авторитетная база (а это коммерческое предприятие) формируется на основе компромиссного разрешения противоречия между качественным отбором источников и объёмом контента базы. Пренебрежение первым ведёт к потере авторитета, сужение контента ведёт к уменьшению востребованности. Она индексирует научные журналы, выходящие во всех странах мира и по всем областям знания. Журналы, не имеющие англоязычных версий (в частности, российские гуманитарные), представлены слабо. База разбита на 7 множеств (3 подбазы журналов, 2 подбазы трудов конференций и 2 подбазы книг по областям знания), поиск по которым можно вести отдельно. С 2015 года в базу было включено восьмое множество — ESCI (Emerging Sources Citation Index) из примерно 5000 журналов (из них – около 100 российских). После этого по числу индексируемых журналов (в том, числе, российских) база приблизилась к Scopus. База идёт по пути расширения контента: в 2018 году в ESCI индексировалось уже около 7000 журналов.
Она индексирует научные журналы, выходящие во всех странах мира и по всем областям знания. Журналы, не имеющие англоязычных версий (в частности, российские гуманитарные), представлены слабо. База разбита на 7 множеств (3 подбазы журналов, 2 подбазы трудов конференций и 2 подбазы книг по областям знания), поиск по которым можно вести отдельно. С 2015 года в базу было включено восьмое множество — ESCI (Emerging Sources Citation Index) из примерно 5000 журналов (из них – около 100 российских). После этого по числу индексируемых журналов (в том, числе, российских) база приблизилась к Scopus. База идёт по пути расширения контента: в 2018 году в ESCI индексировалось уже около 7000 журналов. , по книгам – 2005 г. Глубина же доступного архива определяется условиями подписки. Ясно, что вычисленные на основе собственного и доступного архивов интегральные наукометрические показатели, например, индекса Хирша, могут существенно различаться. В настоящее время в ННГУ (в рамках национальной подписки) доступны архивы с 1970 года.
, по книгам – 2005 г. Глубина же доступного архива определяется условиями подписки. Ясно, что вычисленные на основе собственного и доступного архивов интегральные наукометрические показатели, например, индекса Хирша, могут существенно различаться. В настоящее время в ННГУ (в рамках национальной подписки) доступны архивы с 1970 года. Так, редакция Journal Citation Reports-2017 (действующая до 1 июля 2018 года) отражает результаты цитирования в 2016 году. Такая неизменность показателей данного года повышает их авторитет. Контент, для которого в Journal Citation Reports рассчитываются наукометрические показатели, также расширяется: число журналов, имеющих импакт-факторы, увеличилось в 2017-2018 гг. с 11300 до 13500.
Так, редакция Journal Citation Reports-2017 (действующая до 1 июля 2018 года) отражает результаты цитирования в 2016 году. Такая неизменность показателей данного года повышает их авторитет. Контент, для которого в Journal Citation Reports рассчитываются наукометрические показатели, также расширяется: число журналов, имеющих импакт-факторы, увеличилось в 2017-2018 гг. с 11300 до 13500.
 Неплохо представлены журналы, не имеющие англоязычных версий (в частности, российские). В отличие от Web of Science Core Collection собственный архив при наличии подписки доступен целиком и не делится на подбазы, но его глубина меньше и он довольно «неровный» – сейчас с почти полным охватом по индексируемым журналам это примерно 1980 г. (по значительному числу источников – 1960 г., по единичным – середина XIX в.). Тем не менее имеются отдельные журналы, для которых глубина архива – лишь 1996 г. Вследствие автоматизированной процедуры загрузки данных в базу архивные записи для «старых» статей далеко не всегда полные: в некоторых присутствуют лишь название журнала и статьи с фамилиями авторов. Поэтому поисковый запрос будет выводить на эти статьи лишь по указанным атрибутам. В процессе формирования контента в базу попало некоторое количество мусорных источников (predator journals), которые в последние годы фильтруются (индексация их в Scopus прекращается). Наукометрический инструментарий применительно к журналам представлен показателем прямого цитирования (CiteScore), по алгоритму близкого к импакт-фактору, взвешенного цитирования (SJR) и контент-обусловленного цитирования (SNIP), а также процентилем журнала (по данным SJR).
Неплохо представлены журналы, не имеющие англоязычных версий (в частности, российские). В отличие от Web of Science Core Collection собственный архив при наличии подписки доступен целиком и не делится на подбазы, но его глубина меньше и он довольно «неровный» – сейчас с почти полным охватом по индексируемым журналам это примерно 1980 г. (по значительному числу источников – 1960 г., по единичным – середина XIX в.). Тем не менее имеются отдельные журналы, для которых глубина архива – лишь 1996 г. Вследствие автоматизированной процедуры загрузки данных в базу архивные записи для «старых» статей далеко не всегда полные: в некоторых присутствуют лишь название журнала и статьи с фамилиями авторов. Поэтому поисковый запрос будет выводить на эти статьи лишь по указанным атрибутам. В процессе формирования контента в базу попало некоторое количество мусорных источников (predator journals), которые в последние годы фильтруются (индексация их в Scopus прекращается). Наукометрический инструментарий применительно к журналам представлен показателем прямого цитирования (CiteScore), по алгоритму близкого к импакт-фактору, взвешенного цитирования (SJR) и контент-обусловленного цитирования (SNIP), а также процентилем журнала (по данным SJR). Эти показатели вычисляются для ВСЕХ журналов, включённых в базу, и ежемесячно пересчитываются на меняющемся (загруженном) контенте. Из-за естественного запаздывания загрузки, показатели последних двух лет сравнивать некорректно (особенно в начале года): например, для журнала Chemical Reviews отражаемый базой в феврале 2018 года CiteScore 2016 равен 42,79, тогда как CiteScore 2017 того же журнала показывается равным лишь 15,38 (заметим, что в Journal Citation Reports все выводимые наукометрические показатели разных лет сопоставимы, так как рассчитываются один раз в год).
Эти показатели вычисляются для ВСЕХ журналов, включённых в базу, и ежемесячно пересчитываются на меняющемся (загруженном) контенте. Из-за естественного запаздывания загрузки, показатели последних двух лет сравнивать некорректно (особенно в начале года): например, для журнала Chemical Reviews отражаемый базой в феврале 2018 года CiteScore 2016 равен 42,79, тогда как CiteScore 2017 того же журнала показывается равным лишь 15,38 (заметим, что в Journal Citation Reports все выводимые наукометрические показатели разных лет сопоставимы, так как рассчитываются один раз в год). Естественно, квартили многих журналов отличаются от определяемых Journal Citation Reports (иной контент, иное разбиение на предметные области, иной алгоритм учёта цитирований). Показатель SJR экспортируется и отображается в базе SCOPUS.
Естественно, квартили многих журналов отличаются от определяемых Journal Citation Reports (иной контент, иное разбиение на предметные области, иной алгоритм учёта цитирований). Показатель SJR экспортируется и отображается в базе SCOPUS.
 Предполагается включение в базу журналов из Украины, Беларуси, Молдовы, Казахстана и Армении, в результате чего база из национальной превратится в региональную.
Предполагается включение в базу журналов из Украины, Беларуси, Молдовы, Казахстана и Армении, в результате чего база из национальной превратится в региональную.Нашли ошибку в тексте?
Выделите ее и нажмите Ctrl + Enter
Определение и значение индекса— Merriam-Webster
1 из 2индекс · индекс ˈin-ˌдекс
1
: список (библиографическая информация или цитаты из литературных источников), организованный обычно в алфавитном порядке по некоторым заданным данным (таким как автор, тема или ключевое слово): например,
а
: список элементов (например, тем или имен), рассматриваемых в печатном произведении, с указанием для каждого элемента номера страницы, на которой его можно найти
б
: список публичных компаний и цены их акций
с
: библиографический анализ групп публикаций, которые обычно публикуются периодически
г
: указатель большого пальца
2
а
: число (такое как отношение), полученное из серии наблюдений и используемое в качестве индикатора или меры
конкретно : номер индекса
б
: отношение одного измерения вещи (например, анатомической структуры) к другому измерению
3
а
: устройство (например, стрелка на шкале или гномон солнечных часов), служащее для указания значения или количества
б
: нечто (например, физическое свойство или способ выражения), которое приводит к определенному факту или заключению : индикация
4
множественное число обычно индексы : число, символ или выражение (например, показатель степени), связанное с другим для обозначения математической операции, которую необходимо выполнить, или для указания использования или положения в расположении
3 – это индекс выражения {latex}\sqrt[3]{5}{/latex}, указывающий кубический корень из 5. параграф
параграф
звонили также fist
6
: список ограниченных или запрещенных материалов
конкретно, с заглавной буквы : ранее опубликованный список книг, чтение которых было запрещено или ограничено для католиков церковными властями
index
2 из 2
переходный глагол
1
а
: для обеспечения индекса
б
: для включения в указатель
все упомянутые лица и места тщательно проиндексированы
2
: для использования в качестве указателя
3
: для регулирования (заработная плата, цены, процентные ставки и т. д.) путем индексации3
д.) путем индексации3
глагол
: индексировать что-то
индексатор существительное
Синонимы
Существительное
- рука
- индикатор
- игла
- указатель
глагол
- каталог
- каталог
- зарегистрироваться
- зарегистрироваться
- введите
- вписать
- список
- положить
- запись
- регистр
- график
- slate
Просмотреть все синонимы и антонимы в тезаурусе
Примеры предложений
Существительное
Найдите рецепт картофельного супа в индексе . Картофельный суп указан в разделе «суп» в индексе 9.0184 .
Картотека представляет собой указатель к материалам библиотеки. индекс на шкале
Глагол
Эта поисковая система имеет проиндексировал сотни миллионов веб-сайтов. проиндексировано всех книг в библиотеке по категориям
Узнать больше
Картофельный суп указан в разделе «суп» в индексе 9.0184 .
Картотека представляет собой указатель к материалам библиотеки. индекс на шкале
Глагол
Эта поисковая система имеет проиндексировал сотни миллионов веб-сайтов. проиндексировано всех книг в библиотеке по категориям
Узнать больше
Последние примеры в Интернете
Экономисты ожидали, что индекс вырастет на 1,2% в третьем квартале, согласно консенсус-прогнозу Refinitiv. Тами Лухби, CNN , 28 октября 2022 г.
Индекс Shanghai Composite , индекс , упал на 0,9% до 2938,77 пункта.
Элейн Куртенбах, ajc , 28 октября 2022 г.
Это будет представлять собой самый низкий годовой темп роста прибыли, о котором сообщают индекс с 2020 года.
Челси Дулани, WSJ , 28 октября 2022 г.
Этот индекс поднялся на 5,0% в годовом исчислении, что немного ниже, чем 5,1% в предыдущем отчете.
Бен Кассельман, BostonGlobe.com , 28 октября 2022 г.
После окончания рецессии, вызванной пандемией, индекс резко вырос: компании предлагают более щедрую заработную плату и льготы для привлечения и удержания работников.
Кристофер Ругабер, 9 лет0183 Fortune , 28 октября 2022 г.
Тами Лухби, CNN , 28 октября 2022 г.
Индекс Shanghai Composite , индекс , упал на 0,9% до 2938,77 пункта.
Элейн Куртенбах, ajc , 28 октября 2022 г.
Это будет представлять собой самый низкий годовой темп роста прибыли, о котором сообщают индекс с 2020 года.
Челси Дулани, WSJ , 28 октября 2022 г.
Этот индекс поднялся на 5,0% в годовом исчислении, что немного ниже, чем 5,1% в предыдущем отчете.
Бен Кассельман, BostonGlobe.com , 28 октября 2022 г.
После окончания рецессии, вызванной пандемией, индекс резко вырос: компании предлагают более щедрую заработную плату и льготы для привлечения и удержания работников.
Кристофер Ругабер, 9 лет0183 Fortune , 28 октября 2022 г. После окончания рецессии, вызванной пандемией, индекс резко вырос: компании предлагают более щедрую заработную плату и льготы для привлечения и удержания работников.
Кристофер Ругабер, Chicago Tribune , 28 октября 2022 г.
Индекс Midwest снизился на 8,8% до 80,7 в сентябре, что на 26,7% меньше, чем год назад.
Свапна Венугопал Рамасвами, 9 лет0183 США СЕГОДНЯ , 28 октября 2022 г.
На следующем групповом собрании Джейны раздали 90 183 индексных 90 184 карточек с информацией о женщинах, именами, контактами, медицинскими данными и информацией о том, сколько каждая из них может позволить себе заплатить.
Мишель Мертенс, Smithsonian Magazine , 28 октября 2022 г.
После окончания рецессии, вызванной пандемией, индекс резко вырос: компании предлагают более щедрую заработную плату и льготы для привлечения и удержания работников.
Кристофер Ругабер, Chicago Tribune , 28 октября 2022 г.
Индекс Midwest снизился на 8,8% до 80,7 в сентябре, что на 26,7% меньше, чем год назад.
Свапна Венугопал Рамасвами, 9 лет0183 США СЕГОДНЯ , 28 октября 2022 г.
На следующем групповом собрании Джейны раздали 90 183 индексных 90 184 карточек с информацией о женщинах, именами, контактами, медицинскими данными и информацией о том, сколько каждая из них может позволить себе заплатить.
Мишель Мертенс, Smithsonian Magazine , 28 октября 2022 г.
Штатами, которые не индексируют налоговые категории для инфляции, являются Алабама, Коннектикут, Делавэр, Джорджия, Гавайи, Канзас, Луизиана, Миссисипи, Нью-Джерси, Нью-Йорк, Оклахома, Вирджиния и Западная Вирджиния. Патрик Глисон, Forbes , 16 июня 2022 г.
По мере того как документы накапливались, Поузи установил полки от пола до потолка на складе, примыкающем к офису Newport Aeronautical, и платил людям, которые помогали с файлами и файлами.0183 индекс растущая коллекция. ПРОВОДНАЯ , 19 августа 2022 г.
Таким образом, боты Google могут категорически проиндексировать таких веб-страниц.
Ран Ронен, Forbes , 30 июня 2022 г.
Большинство штатов с дифференцированными ставками подоходного налога индексируют свою шкалу подоходного налога с учетом инфляции.
Патрик Глисон, 9 лет0183 Forbes , 16 июня 2022 г.
В настоящее время 13 штатов не индексируют шкалу подоходного налога с учетом инфляции, в основном в регионах Южной и Средней Атлантики.
Патрик Глисон, Forbes , 16 июня 2022 г.
По мере того как документы накапливались, Поузи установил полки от пола до потолка на складе, примыкающем к офису Newport Aeronautical, и платил людям, которые помогали с файлами и файлами.0183 индекс растущая коллекция. ПРОВОДНАЯ , 19 августа 2022 г.
Таким образом, боты Google могут категорически проиндексировать таких веб-страниц.
Ран Ронен, Forbes , 30 июня 2022 г.
Большинство штатов с дифференцированными ставками подоходного налога индексируют свою шкалу подоходного налога с учетом инфляции.
Патрик Глисон, 9 лет0183 Forbes , 16 июня 2022 г.
В настоящее время 13 штатов не индексируют шкалу подоходного налога с учетом инфляции, в основном в регионах Южной и Средней Атлантики. Адам А. Миллсэп, Forbes , 13 апреля 2022 г.
Записи переписи 1940 года были опубликованы десять лет назад, но федеральное правительство не расшифровало и не проиндексировало имена.
Билл Боуден, 9 лет0183 Арканзас Онлайн , 10 апреля 2022 г.
Конгресс должен в конечном итоге индексировать пособия по безработице по всей стране, но в краткосрочной перспективе штаты должны взять на себя инициативу.
Джонатан Ингрэм, WSJ , 5 января 2022 г.
Первоначальный план был неприемлем для слишком многих членов, но небольшая группа сенаторов работает над предложением цены на определенное количество лекарств.
Лорен Фокс и Фил Маттингли, 9 лет0183 CNN , 26 октября 2021 г.
Узнать больше
Адам А. Миллсэп, Forbes , 13 апреля 2022 г.
Записи переписи 1940 года были опубликованы десять лет назад, но федеральное правительство не расшифровало и не проиндексировало имена.
Билл Боуден, 9 лет0183 Арканзас Онлайн , 10 апреля 2022 г.
Конгресс должен в конечном итоге индексировать пособия по безработице по всей стране, но в краткосрочной перспективе штаты должны взять на себя инициативу.
Джонатан Ингрэм, WSJ , 5 января 2022 г.
Первоначальный план был неприемлем для слишком многих членов, но небольшая группа сенаторов работает над предложением цены на определенное количество лекарств.
Лорен Фокс и Фил Маттингли, 9 лет0183 CNN , 26 октября 2021 г.
Узнать больше
Эти примеры предложений автоматически выбираются из различных онлайн-источников новостей, чтобы отразить текущее использование слова «индекс». Мнения, выраженные в примерах, не отражают точку зрения Merriam-Webster или ее редакторов. Отправьте нам отзыв.
Мнения, выраженные в примерах, не отражают точку зрения Merriam-Webster или ее редакторов. Отправьте нам отзыв.
История слов
Этимология
Существительное
Латинская Indic-, Index , от indicare , чтобы указать
Первое известное использование
Существительное
1561, в значении, определенном в смысле 3A
главный Путешественник во времени
Первое известное использование индекса было в 1561 году
Другие слова того же года набожный
индекс
индексация
Посмотреть другие записи поблизости
Процитировать эту запись «Индекс.
 » Словарь Merriam-Webster.com , Merriam-Webster, https://www.merriam-webster.com/dictionary/index. По состоянию на 9 ноября 2022 г.
» Словарь Merriam-Webster.com , Merriam-Webster, https://www.merriam-webster.com/dictionary/index. По состоянию на 9 ноября 2022 г.Copy Citation
Kids Definition
index 1 из 2
индекс · индекс ˈin-ˌдекс
1
а
: устройство (например, указатель на шкале), используемое для указания значения или количества
б
: то, что приводит человека к тому или иному факту или заключению дает с каждым перечисленным пунктом номер страницы, где его можно найти
3
множественное число обычно индексы : математическая цифра, буква или выражение (как показатель степени 3 в a 3 ), показывающий степень или корень другого
4
: 90 индекс
2 из 2
1
а
: для обеспечения индекса
указатель книга
б
: для включения в индекс
2
: для использования в качестве индекса
индексатор существительное
Медицинское определение
индекс · индекс ˈin-ˌдекс
1
: указательный палец
2
: список (библиографическая информация или ссылки на литературу), организованный обычно в алфавитном порядке по некоторым заданным данным (автор, предмет или ключевое слово) )
Указатель Medicus Национальной медицинской библиотеки США
3
а
: отношение или другое число, полученное из серии наблюдений и используемое в качестве индикатора или меры (как состояния, свойства или явления)
физико-химические показатели мочи, крови и желудочного сока Журнал Американской медицинской ассоциации
б
: отношение одного измерения вещи (как анатомической структуры) к другому измерению
см. головной указатель, черепной указатель
головной указатель, черепной указатель
Юридическое определение
указатель 1 из 2
индекс
: числовая мера или показатель (относительно инфляции или экономических показателей)
см. также индекс потребительских цен
индекс
2 из 2
: для привязки (в качестве заработной платы, ставок или инвестиций) к индексу
по договору заработная плата была проиндексирована с учетом инфляции
Еще от Merriam-Webster on
indexНглиш: Перевод index для испаноязычных
Britannica English: Перевод index Arabics 3 for0. com: Энциклопедическая статья о index
com: Энциклопедическая статья о index
Последнее обновление: 31 октября 2022 г.
Подпишитесь на крупнейший словарь Америки и получите еще тысячи определений и расширенный поиск — без рекламы!
Merriam-Webster без сокращений
Как работает индексирование | Учебное пособие от Chartio
Что делает индексация?
Индексация — это способ привести неупорядоченную таблицу в порядок, максимально повышающий эффективность запроса при поиске.
Если таблица не проиндексирована, порядок строк, скорее всего, не будет различим для запроса как оптимизированного каким-либо образом, и поэтому вашему запросу придется выполнять поиск по строкам линейно. Другими словами, запросы должны будут выполнять поиск по каждой строке, чтобы найти строки, соответствующие условиям. Как вы понимаете, это может занять много времени. Просмотр каждой строки не очень эффективен.
Например, в таблице ниже представлена таблица в вымышленном источнике данных, которая полностью неупорядочена.
| компания_id | шт. | unit_cost |
|---|---|---|
| 10 | 12 | 1,15 |
| 12 | 12 | 1,05 |
| 14 | 18 | 1,31 |
| 18 | 18 | 1,34 |
| 11 | 24 | 1,15 |
| 16 | 12 | 1,31 |
| 10 | 12 | 1,15 |
| 12 | 24 | 1,3 |
| 18 | 6 | 1,34 |
| 18 | 12 | 1,35 |
| 14 | 12 | 1,95 |
| 21 | 18 | 1,36 |
| 12 | 12 | 1,05 |
| 20 | 6 | 1,31 |
| 18 | 18 | 1,34 |
| 11 | 24 | 1,15 |
| 14 | 24 | 1,05 |
Если бы мы выполнили следующий запрос:
SELECT Идентификатор компании, единицы, себестоимость единицы продукции ИЗ index_test КУДА идентификатор_компании = 18
База данных должна будет выполнить поиск по всем 17 строкам в порядке их появления в таблице, сверху вниз, по одной за раз. Таким образом, для поиска всех потенциальных экземпляров
Таким образом, для поиска всех потенциальных экземпляров company_id номер 18, база данных должна просмотреть всю таблицу на наличие всех вхождений 18 в столбце company_id .
Это будет занимать все больше и больше времени по мере увеличения размера таблицы. По мере усложнения данных в конечном итоге может произойти следующее: таблица с одним миллиардом строк соединяется с другой таблицей с одним миллиардом строк; запрос теперь должен выполнять поиск в удвоенном количестве строк, что требует в два раза больше времени.
Вы можете видеть, как это становится проблематичным в нашем вечно насыщенном данными мире. Таблицы увеличиваются в размерах, а время выполнения поиска увеличивается.
Запрос к неиндексированной таблице, если он представлен визуально, будет выглядеть так:
Индексация настраивает столбец, в котором находятся условия поиска, в отсортированном порядке, чтобы помочь оптимизировать производительность запроса.
С индексом в столбце company_id таблица будет, по сути, «выглядеть» так:
| company_id | шт. | unit_cost |
|---|---|---|
| 10 | 12 | 1,15 |
| 10 | 12 | 1,15 |
| 11 | 24 | 1,15 |
| 11 | 24 | 1,15 |
| 12 | 12 | 1,05 |
| 12 | 24 | 1,3 |
| 12 | 12 | 1,05 |
| 14 | 18 | 1,31 |
| 14 | 12 | 1,95 |
| 14 | 24 | 1,05 |
| 16 | 12 | 1,31 |
| 18 | 18 | 1,34 |
| 18 | 6 | 1,34 |
| 18 | 12 | 1,35 |
| 18 | 18 | 1,34 |
| 20 | 6 | 1,31 |
| 21 | 18 | 1,36 |
Теперь база данных может искать company_id номер 18 и возвращать все запрошенные столбцы для этой строки, а затем переходить к следующей строке. Если в следующей строке
Если в следующей строке comapny_id номер также равен 18, тогда он вернет все столбцы, запрошенные в запросе. Если в следующей строке company_id равен 20, запрос прекращает поиск и завершается.
Как работает индексация?
На самом деле таблица базы данных не переупорядочивается каждый раз при изменении условий запроса для оптимизации производительности запроса: это было бы нереалистично. На самом деле происходит то, что индекс заставляет базу данных создавать структуру данных. Тип структуры данных, скорее всего, B-Tree. Несмотря на множество преимуществ B-дерева, основное преимущество для наших целей заключается в том, что его можно сортировать. Когда структура данных отсортирована по порядку, это делает наш поиск более эффективным по очевидным причинам, которые мы указали выше.
Когда индекс создает структуру данных для определенного столбца, важно отметить, что никакой другой столбец не сохраняется в структуре данных. Наша структура данных для приведенной выше таблицы будет содержать только номера company_id . Units и
Units и unit_cost не будут храниться в структуре данных.
Откуда база данных узнает, какие еще поля в таблице нужно вернуть?
Индексы базы данных также будут хранить указатели, которые являются просто справочной информацией о расположении дополнительной информации в памяти. В основном индекс держит company_id и домашний адрес этой конкретной строки на диске памяти. На самом деле индекс будет выглядеть так:
| company_id | указатель |
|---|---|
| 10 | _123 |
| 10 | _129 |
| 11 | _127 |
| 11 | _138 |
| 12 | _124 |
| 12 | _130 |
| 12 | _135 |
| 14 | _125 |
| 14 | _131 |
| 14 | _133 |
| 16 | _128 |
| 18 | _126 |
| 18 | _131 |
| 18 | _132 |
| 18 | _137 |
| 20 | _136 |
| 21 | _134 |
С помощью этого индекса запрос может искать только строки в столбце company_id , которые имеют 18, а затем с помощью указателя можно перейти в таблицу, чтобы найти конкретную строку, в которой находится этот указатель.