
Продвижение сайта, повышаем траст

Не секрет, что основное направление продвижения сайта это его «затачивание» под поисковые системы. Но тенденции поисковых систем меняются из года в год. Временами поисковики «штормит», после того как они меняют свои алгоритмы, а владельцы сайтов с ужасом замечают падение ТИЦ, вслед за которым приходит снижение поискового трафика. Но вот вы приходите к специалисту по SEO и он заверяет, что беспокоится не о чём, ведь сейчас активное продвижение по НЧ и ВЧ запросам стоит далеко не на первом месте и работает только в комплексе с другими методами продвижения. Насколько слова специалиста далеки от истины?
Рекомендуем: Как раскрутить Инстаграм?
Как продвинуть свой сайт?
Вы ищите самые актуальные методы продвижения сайта, которые дадут вам преимущество на фоне конкурентов? Но предложений по продвижению так много, что вы растерялись и не знаете, с чего начать?
Что такое Majestic?
Majestic это крупнейшая ссылочная база данных на планете, которая выявляет взаимосвязи между сайтами, то есть показывает, как связаны друг с другом все веб-сайты в сети Интернет. По заверениям создателей Majestic, никакой другой сайт, никакая другая поисковая система не позволяет получить столь детальную информацию о том, как соткана сеть. В сервисе Majestic есть своя метрика значений траста, которая называется Trust Flow и Citation Flow. Как специалист по продвижению, подтверждаю влияние траста на позиции сайта и его трафик.Но что даёт «продвижение под Majestic» рядовому владельцу сайта? Чем это лучше покупки ссылок на сайтах с высоким ТИЦ?
Всё очень просто! Траст помогает сайту не только быть более устойчивым к различным поисковым апдейтам Google и Яндекса, но и лучше ранжироваться!
Почему стоит обратить внимание на траст своего сайта?
Первая причина заключается в том, что траст является спасательным кругом от штормов поисковых систем и обновлений их алгоритмов. Поисковики не понижают сайты, которым доверяют — эта истина известна профессиональным SEO-шникам.
Вторая причина, из-за которой стоит улучшить траст, это негативное SEO. То есть, если ваш сайт обладает низким уровнем доверия поисковых систем, тогда он беззащитен против попыток конкурентов выкинуть его из ТОП запросов с помощью купленных ссылок.
Третья причина заключается в том, что продвигая траст, в базе данных Majestic увеличивается частота ссылок на ваш сайт. Робот Majestic, собирая и обрабатывая ссылки, будет чаще встречать в ссылочной базе имя вашего сайта, что благоприятно скажется на доверии.
Можно ли продвигать сайт покупными ссылками?
Насколько достоверно купленные ссылки могут помочь сайту выйти в лидеры по запросам? Казалось бы, покупай как можно больше «жирных» анкорных ссылок и наблюдай поднятие позиций! Всё не так однозначно, как кажется на первый взгляд. Покупные ссылки это падающий тренд, поскольку поисковики могут понижать сайт на выдаче, если благодаря своим алгоритмам точно знают, что на ресурсах, где находятся ссылки на данный сайт, размещают покупные ссылки. Причём размещают ссылки не обязательно владельцы ресурсов, это делают многочисленные фрилансеры и специалисты по SEO-продвижению. На крупных российских порталах размещаются купленные на биржах (как правило анкорные) ссылки, обычно встраиваемые в тематические статьи. Именно за такие действия вы платите деньги при «стандартной» внешней SEO-оптимизации. Разговоры о том, что это повышает ТИЦ и вреда от единичных «жирных» ссылок не будет, постепенно теряют актуальность уже сегодня. И если пока создаётся впечатление, что для большинства сайтов покупные ссылки продолжают работать, то, скажем через год, политика поисковых систем может ужесточиться и сайт с определённым количеством покупных ссылок окажется под санкциями со всеми вытекающими. Уже сейчас специалисты по SEO говорят, что поисковые системы прекрасно знают сайты, на которых публикуются купленные ссылки (и статьи), поэтому лично я ни за какие комиссионные не стану размещать покупные ссылки через биржи. На мой взгляд, в настоящее время это совершенно неоправданный риск, несмотря на то что биржи ссылок продолжают работать. Более того, большинство покупаемых на биржах ссылок являются «вечными», поэтому, если в будущем ваш сайт попадёт под санкции поисковых систем и вы попросите удалить купленные ссылки, скорее всего, владельцы ресурсов со ссылками ответят вам отказом, ведь в противном случае к ним применят санкции биржи ссылок, которые выступают гарантом «вечности» перед покупателем.
Что такое TrustRank и как повысить доверие к своему сайту?
Что такое CF и TF?
Знание механизма доверия позволяет достаточно просто определить качество сайта в ссылочном плане. То есть, нужно найти, на каком уровне вложенности он находится от авторитетных ресурсов.
С этим великолепно справляется Majestic SEO с помощью показателей Citation Flow и Trust Flow. Следует оговориться, что показатели не являются уникальными и есть в других подобных сервисах, например, в Open Site Explorer от SeoMoz (mozRank & mozTrust).
Citation Flow (CF) это аналог нормированного PageRank (скрытый индекс Google, зависящий от количества внешних ссылок на сайт), вычисленного по базе имеющихся в Majestic сайтов.
Trust Flow (TF) это аналог TrustRank (классический фильтр поисковых систем, впервые описанный Yahoo, представляющий собой сложную технику анализа связей сайта и его ссылок), нормированное значение от 0 до 100.
Для оценки нормированного рейтинга сайта обычно используется формула:
где первое слагаемое — это нормированная абсолютная разница между показателями траста и цитирования, второе слагаемое — это относительная разница и последнее — нормированная величина траста.
Какими способами можно быстро повысить траст и не упадёт ли он в будущем?
Прокачка траста относится к внешним методам оптимизации SEO. Быстрая прокачка осуществляется через размещение преимущественно безанкорных ссылок на сайтах с высоким (для быстрого роста) и средним (для оптимизации и поддержки) уровнем доверия в сети. Продвижение проводится через специализированные иностранные сервисы, для работы с которыми покупаются достаточно дорогие подписные абонементы. Ссылки размещаются на сайтах по всему миру с игнорированием или осторожным затрагиванием российского сегмента.
Поисковые системы периодически обновляют в кэше информацию по трасту для сайтов, выводимых в поиске. Таким образом, траст, наряду с другими факторами (ТИЦ, PR, скорость обновления страниц, социальная активность и т.д.), является в настоящий момент одним из ключевых элементов при ранжировании сайта в поисковых системах, который нельзя игнорировать.
Будут ли уменьшаться показатели траста с течением времени? Да, но в большинстве случаев, за счёт большой безанкорной ссылочной массы в среднем доверительном сегменте сети, изменения будут постепенными. А если периодически повторять грамотное наращивание ссылок, то траст будет неизменно расти, либо колебаться возле некоторых усреднённых и уникальных для каждого сайта значений.
Сколько стоит «прокачка» траста? Через сколько повысится траст сайта?
Продвижение сайта занимает около месяца, поскольку работа идёт взвешенно, а первые результаты появятся не раньше трёх-четырёх недель.
Эффективность работы зависит от тематики и возраста сайта, его обновляемости и текущей раскрученности. Не стоит поднимать траст, если сайт новый и совершенно «голый». Дайте ему поработать несколько недель или лучше месяцев. Чем больше на сайте статей (страниц, товаров и т.д.), чем чаще он обновляется, тем легче он поддаётся продвижению.
Цена работы колеблется от 50 до 200 долларов (цена в долларах, поскольку продвижение идёт через иностранные сервисы) и это далеко не предел, особенно для сайтов с практически нулевым трастом. Если вы найдёте дешевле, то результат может быть неоднозначным, а иногда и прямо противоположный ожидаемому. В среднем 100-150 долларов — небольшие в общем-то деньги за то, что SEO-шник повысит доверие к вашему сайту и познакомит его с уважаемыми (преимущественно иностранными) ресурсами сети Интернет.
Пример повышения траста (превращаем обычный сайт в трастовый)*


* Для каждого сайта повышение показателей уникально. Работа считается выполненной, если CF или TF увеличится хотя бы на единицу.
Выводы
Прокачка траста Majestic — это тренд, актуальный сегодня!
Забудьте на время про покупку ссылок и размещение статей на сторонних ресурсах, вложите средства в прокачку траста хотя бы на один месяц! Высокий траст — это весьма важный показатель не только сегодня, но и в ближайшей перспективе! Доверие в сети — сейчас один из главных показателей сайта!
Теперь вы знаете немного про траст и доверие, поэтому у вас меньше шансов отдать свой проект в руки непрофессиональным SEO-шникам. Будьте бдительны, осторожны и мудры при продвижении своего сайта и тогда его ждут высокие позиции в поисковых системах и качественный трафик.
.tf — Википедия. Что такое .tf
Материал из Википедии — свободной энциклопедии .tf (фр. Territoire des Terres australes et antarctiques françaises) — национальный домен верхнего уровня Французских Южных и Антарктических территорий. Доступна регистрация имен второго уровня. Владельцами доменных имён могут стать физические, юридические лица (только резиденты Франции), а также международные организации. Управляется компанией AFNIC.[1][2]Национальный домен TF используется как национальный домен верхнего уровня в стандартах административно-территориального деления территории государства ISO 3166 — (ISO 3166-1, ISO 3166-2, ISO 3166-2:TF) в качестве кода Alpha2, образующего основу геокода административно-территориального деления Французских Южных и Антарктических территорий.
Также домен TF используется в качестве дополнительного двухбуквенного геокода Французских Южных и Антарктических территорий как административно-территориальной единицы административно-территориального деления Франции.[4]
Требования к регистрируемым доменам
Домены, регистрируемые в доменной зоне .tf, должны соответствовать требованиям, предъявляемым регистратором к доменам второго уровня[5][6].
- Минимальная длина имени — 3 символа.
- Максимальная длина имени, учитывая домен первого, второго уровня — .tf, не более 63 символов.
- Имя домена может состоять из букв латинского алфавита (a-z), цифр (0-9) и тире (—, -).
- Имя домена может содержать символы расширенной кодировки (à, á, â, ã, ä, å, æ, ç, è, é, ê, ë, ì, í, î, ï, ñ, ò, ó, ô, õ, ö, oe, ù, ú, û, ü, ý, ÿ, ß).
- Имя домена не может начинаться или заканчиваться символом тире (минусом) (—, -).
- Имя домена не может содержать последовательность двух тире (минусов) подряд ( — -, — -, — —, — —).
- Имя домена не может начинаться с последовательности символов — (x n — -).
Зарезервированные имена
Зарезервированные имена доменов[7]
- Совпадающих с названиями государств — 246 имён.
- Связанных с понятиями криминала — 207 имён.
- Связанных с религией и вероисповеданием — 144 имени.
- Совпадающих с названиями международных организаций — 40 имён.
- Совпадающих с названиями интернет-организаций — 17 имён.
- Совпадающих с названиями интернет-форматов, протоколов, файлов и т. п. — 84 имени.
- Совпадающих с определениями преступных деяний — 263 имени.
- Связанных с профессиональной деятельностью, регулируемой государством, — 110 имён.
- Связанных с названиями государственных органов, должностей, и т. п. — 233 имени.
- Связанных с определениями государственных структур, и т. п. — 62 имени.
- Связанных с половой ориентацией — 60 имён.
- Совпадающих с именами доменов верхнего уровня — 24 имени.
- Совпадающих с названиями регионов, департаментов, административно-территориальных единиц Франции, зарезервировано списочно.[8]
Домены 1 уровня
Домены второго уровня, условия использования, требования, регламентированные пользователи.
| Домен | Регламентированные пользователи |
|---|---|
| .tf | Основной домен первого уровня. |
См. также
Ссылки
Примечания
TF*IDF — это… Что такое TF*IDF?
TF-IDF (от англ. TF — term frequency, IDF — inverse document frequency) — статистическая мера, используемая для оценки важности слова в контексте документа, являющегося частью коллекции документов или корпуса. Вес некоторого слова пропорционален количеству употребления этого слова в документе, и обратно пропорционален частоте употребления слова в других документах коллекции.
Мера TF-IDF часто используется в задачах анализа текстов и информационного поиска, например, как один из критериев релевантности документа поисковому запросу, при расчёте меры близости документов при кластеризации.
Структура формулы
TF (term frequency — частота слова) — отношение числа вхождения некоторого слова к общему количеству слов документа. Таким образом, оценивается важность слова ti в пределах отдельного документа.
 ,
,
где ni есть число рассматриваемых употреблений слова, а в знаменателе — общее число словоупотреблений.
IDF (inverse document frequency — обратная частота документа) — инверсия частоты, с которой некоторое слово встречается в документах коллекции. Учёт IDF уменьшает вес широкоупотребительных слов.
 ,[1]
,[1]
где
- |D| — количество документов в корпусе;
 — количество документов, в которых встречается ti (когда ).
— количество документов, в которых встречается ti (когда ).
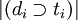 — количество документов, в которых встречается ti (когда
— количество документов, в которых встречается ti (когда  ).
).Таким образом, мера TF-IDF является произведением двух сомножителей: TF и IDF.
Большой вес в TF-IDF получат слова с высокой частотой в пределах конкретного документа и с низкой частотой употреблений в других документах.
Числовое применение
Существуют различные формулы, основанные на методе TF-IDF. Они отличаются коэффициентами, нормировками, использованием логарифмированных шкал. В частности, поисковая система Яндекс долгое время использовала нормировку по самому частотному термину в документе[1].
Одной из наиболее популярных формул является формула BM25[2].
Пример
Если документ содержит 100 слов и слово[2] «заяц» встречается в нём 3 раза, то частота слова (TF) для слова «заяц» в документе будет 0,03 (3/100). Одним из вариантов вычисления частоты документа (IDF) определяется как количество документов содержащих слово «заяц», разделенное на количество всех документов. Таким образом, если «заяц» содержится в 1000 документов из 10 000 000 документов, то частота документа (DF) будет равной 0,0001 (1000/10000000). Для расчета окончательного значения веса слова необходимо разделить TF на DF (или умножить на IDF). В данном примере, TF-IDF вес для слова «заяц» в коллекции документов будет 300 (0,03/0,0001).
Применение в модели векторного пространства
Мера TF-IDF часто используется для представлении документов коллекции в виде числовых векторов, отражающих важность использования каждого слова из некоторого набора слов (количество слов набора определяет размерность вектора) в каждом документе. Подобная модель называется векторной моделью (VSM) и даёт возможность сравнивать тексты, сравнивая представляющие их вектора в какой либо метрике (евклидово расстояние, косинусная мера, манхэттенское расстояние, расстояние Чебышева и др.), т. е. производя кластерный анализ.
Примечания
- ↑ В некоторых вариантах формулы не используется логарифмирование.
- ↑ Обычно перед анализом документа слова приводятся морфологическим анализатором к нормальной форме.
Литература
- Дж Солтон. Динамические библиотечно-поисковые системы. М.: — Мир, 1979.
- Salton, G. and McGill, M. J. 1983 Introduction to modern information retrieval. McGraw-Hill, ISBN 0-07-054484-0.
- Salton, G., Fox, E. A. and Wu, H. 1983 Extended Boolean information retrieval. Commun. ACM 26, 1022—1036.
- Salton, G. and Buckley, C. 1988 Term-weighting approaches in automatic text retrieval. Information Processing & Management 24(5): 513—523
- Федоровский А.Н, Костин М. Ю. Mail.ru на РОМИП-2005 // в сб. «Труды РОМИП’2005» Труды третьего российского семинара по оценке методов информационного поиска. Под ред. И. С. Некрестьянова, стр. 106—124, Санкт-Петербург: НИИ Химии СПбГУ, 2005.
- М. В. Губин. Модели и методы представления текстового документа в системах информационного поиска
См. также
Ссылки
Wikimedia Foundation. 2010.
Tf·idf — это… Что такое Tf·idf?
TF-IDF (от англ. TF — term frequency, IDF — inverse document frequency) — статистическая мера, используемая для оценки важности слова в контексте документа, являющегося частью коллекции документов или корпуса. Вес некоторого слова пропорционален количеству употребления этого слова в документе, и обратно пропорционален частоте употребления слова в других документах коллекции.
Мера TF-IDF часто используется в задачах анализа текстов и информационного поиска, например, как один из критериев релевантности документа поисковому запросу, при расчёте меры близости документов при кластеризации.
Структура формулы
TF (term frequency — частота слова) — отношение числа вхождения некоторого слова к общему количеству слов документа. Таким образом, оценивается важность слова ti в пределах отдельного документа.
,
где ni есть число рассматриваемых употреблений слова, а в знаменателе — общее число словоупотреблений.
IDF (inverse document frequency — обратная частота документа) — инверсия частоты, с которой некоторое слово встречается в документах коллекции. Учёт IDF уменьшает вес широкоупотребительных слов.
,[1]
где
- |D| — количество документов в корпусе;
- — количество документов, в которых встречается ti (когда ).
Таким образом, мера TF-IDF является произведением двух сомножителей: TF и IDF.
Большой вес в TF-IDF получат слова с высокой частотой в пределах конкретного документа и с низкой частотой употреблений в других документах.
Числовое применение
Существуют различные формулы, основанные на методе TF-IDF. Они отличаются коэффициентами, нормировками, использованием логарифмированных шкал. В частности, поисковая система Яндекс долгое время использовала нормировку по самому частотному термину в документе[1].
Одной из наиболее популярных формул является формула BM25[2].
Пример
Если документ содержит 100 слов и слово[2] «заяц» встречается в нём 3 раза, то частота слова (TF) для слова «заяц» в документе будет 0,03 (3/100). Одним из вариантов вычисления частоты документа (IDF) определяется как количество документов содержащих слово «заяц», разделенное на количество всех документов. Таким образом, если «заяц» содержится в 1000 документов из 10 000 000 документов, то частота документа (DF) будет равной 0,0001 (1000/10000000). Для расчета окончательного значения веса слова необходимо разделить TF на DF (или умножить на IDF). В данном примере, TF-IDF вес для слова «заяц» в коллекции документов будет 300 (0,03/0,0001).
Применение в модели векторного пространства
Мера TF-IDF часто используется для представлении документов коллекции в виде числовых векторов, отражающих важность использования каждого слова из некоторого набора слов (количество слов набора определяет размерность вектора) в каждом документе. Подобная модель называется векторной моделью (VSM) и даёт возможность сравнивать тексты, сравнивая представляющие их вектора в какой либо метрике (евклидово расстояние, косинусная мера, манхэттенское расстояние, расстояние Чебышева и др.), т. е. производя кластерный анализ.
Примечания
- ↑ В некоторых вариантах формулы не используется логарифмирование.
- ↑ Обычно перед анализом документа слова приводятся морфологическим анализатором к нормальной форме.
Литература
- Дж Солтон. Динамические библиотечно-поисковые системы. М.: — Мир, 1979.
- Salton, G. and McGill, M. J. 1983 Introduction to modern information retrieval. McGraw-Hill, ISBN 0-07-054484-0.
- Salton, G., Fox, E. A. and Wu, H. 1983 Extended Boolean information retrieval. Commun. ACM 26, 1022—1036.
- Salton, G. and Buckley, C. 1988 Term-weighting approaches in automatic text retrieval. Information Processing & Management 24(5): 513—523
- Федоровский А.Н, Костин М. Ю. Mail.ru на РОМИП-2005 // в сб. «Труды РОМИП’2005» Труды третьего российского семинара по оценке методов информационного поиска. Под ред. И. С. Некрестьянова, стр. 106—124, Санкт-Петербург: НИИ Химии СПбГУ, 2005.
- М. В. Губин. Модели и методы представления текстового документа в системах информационного поиска
См. также
Ссылки
Wikimedia Foundation. 2010.
Что такое TF CF — Полезные статьи
TF — Trust Flow
CF — Citation Flow
Что означает индекс TF и CF
Trust Flow & Citation FlowTrust Flow (Поток Доверия) – это качественная метрика, обозначаемая по шкале от 0 до 100. Она является товарным знаком Majestic. Вручную просмотрев Интернет, Majestic собрал многие пользующиеся доверием «начальные» сайты. Этот процесс лежит в основе метрики Trust Flow (Потока Доверия) Majestic. Сайты, тесно связанные ссылками с пользующимися доверием «начальными» сайтами, обладают более высоким баллом, а сайты с сомнительными ссылками имеют значительно меньший балл.
// можно использовать для оценки уровня ранжирования в поисковой системе, чем больше ссылок на сайт с трастовых сайтов тем больше бал,а значит поисковая система выводит сайт выше в поисковой выдаче.
Citation Flow (Поток Цитирования) является товарным знаком Majestic. Поток Цитирования – это значение от 0 до 100, помогающее определить долю ссылок или «силу», которой обладает веб-сайт или ссылка. Поток Цитирования используется в сочетании с Trust Flow (Потоком Доверия). Совместно Поток Цитирования и Поток Доверия формируют алгоритм метрик потока Majestic.
Поток Цитирования является эволюционным скачком по сравнению с нашей старой метрикой ACRank и предсказывает возможную влиятельность URL, исходя из того, на скольких сайтах имеются ссылки на него. Сейчас не все создаваемые ссылки равнозначны, и поскольку сильная ссылка будет относительно больше влиять на URL, итеративная математическая логика Потока Цитирования гораздо лучше старой метрики ACRank.
// Citation Flow можно использовать для определения качественных ссылок и для определения уровня авторитетности сайта.Также для оценки конкуренции в ТОПе.
idf — это… Что такое Tf-idf?
TF-IDF (от англ. TF — term frequency, IDF — inverse document frequency) — статистическая мера, используемая для оценки важности слова в контексте документа, являющегося частью коллекции документов или корпуса. Вес некоторого слова пропорционален количеству употребления этого слова в документе, и обратно пропорционален частоте употребления слова в других документах коллекции.
Мера TF-IDF часто используется в задачах анализа текстов и информационного поиска, например, как один из критериев релевантности документа поисковому запросу, при расчёте меры близости документов при кластеризации.
Структура формулы
TF (term frequency — частота слова) — отношение числа вхождения некоторого слова к общему количеству слов документа. Таким образом, оценивается важность слова ti в пределах отдельного документа.
,
где ni есть число рассматриваемых употреблений слова, а в знаменателе — общее число словоупотреблений.
IDF (inverse document frequency — обратная частота документа) — инверсия частоты, с которой некоторое слово встречается в документах коллекции. Учёт IDF уменьшает вес широкоупотребительных слов.
,[1]
где
- |D| — количество документов в корпусе;
- — количество документов, в которых встречается ti (когда ).
Таким образом, мера TF-IDF является произведением двух сомножителей: TF и IDF.
Большой вес в TF-IDF получат слова с высокой частотой в пределах конкретного документа и с низкой частотой употреблений в других документах.
Числовое применение
Существуют различные формулы, основанные на методе TF-IDF. Они отличаются коэффициентами, нормировками, использованием логарифмированных шкал. В частности, поисковая система Яндекс долгое время использовала нормировку по самому частотному термину в документе[1].
Одной из наиболее популярных формул является формула BM25[2].
Пример
Если документ содержит 100 слов и слово[2] «заяц» встречается в нём 3 раза, то частота слова (TF) для слова «заяц» в документе будет 0,03 (3/100). Одним из вариантов вычисления частоты документа (IDF) определяется как количество документов содержащих слово «заяц», разделенное на количество всех документов. Таким образом, если «заяц» содержится в 1000 документов из 10 000 000 документов, то частота документа (DF) будет равной 0,0001 (1000/10000000). Для расчета окончательного значения веса слова необходимо разделить TF на DF (или умножить на IDF). В данном примере, TF-IDF вес для слова «заяц» в коллекции документов будет 300 (0,03/0,0001).
Применение в модели векторного пространства
Мера TF-IDF часто используется для представлении документов коллекции в виде числовых векторов, отражающих важность использования каждого слова из некоторого набора слов (количество слов набора определяет размерность вектора) в каждом документе. Подобная модель называется векторной моделью (VSM) и даёт возможность сравнивать тексты, сравнивая представляющие их вектора в какой либо метрике (евклидово расстояние, косинусная мера, манхэттенское расстояние, расстояние Чебышева и др.), т. е. производя кластерный анализ.
Примечания
- ↑ В некоторых вариантах формулы не используется логарифмирование.
- ↑ Обычно перед анализом документа слова приводятся морфологическим анализатором к нормальной форме.
Литература
- Дж Солтон. Динамические библиотечно-поисковые системы. М.: — Мир, 1979.
- Salton, G. and McGill, M. J. 1983 Introduction to modern information retrieval. McGraw-Hill, ISBN 0-07-054484-0.
- Salton, G., Fox, E. A. and Wu, H. 1983 Extended Boolean information retrieval. Commun. ACM 26, 1022—1036.
- Salton, G. and Buckley, C. 1988 Term-weighting approaches in automatic text retrieval. Information Processing & Management 24(5): 513—523
- Федоровский А.Н, Костин М. Ю. Mail.ru на РОМИП-2005 // в сб. «Труды РОМИП’2005» Труды третьего российского семинара по оценке методов информационного поиска. Под ред. И. С. Некрестьянова, стр. 106—124, Санкт-Петербург: НИИ Химии СПбГУ, 2005.
- М. В. Губин. Модели и методы представления текстового документа в системах информационного поиска
См. также
Ссылки
Wikimedia Foundation. 2010.
TF1 — Википедия. Что такое TF1
TF1 — частный общефранцузский телеканал, контролируемый холдингом Groupe TF1, большая часть которого принадлежит конгломерату Bouygues. Средняя доля рынка канала — 24 %, что делает его наиболее популярным домашним телеканалом. Канал является крупнейшим Европейским телеканалом по размеру его аудитории. Штаб-квартира находится в Париже.
История
Телевидение Радио PTT (1935 — 1939)
25 апреля 1935 г. PTT на средних волнах запустило телеканал Телевидение Радио PTT (Radio-PTT Vision). В июле 1938 г. вещание Телевидение Радио PTT было переведено со средних волн на ультракороткие.
NR TV (1939 — 1945)
В 1939 г. радиовещание и телевидение были выведены из PTT в отдельное государственное предприятие «Национальное радиовещание» (Radiodiffusion nationale), телеканал «Телевидение Радио PTT» стал называться «Телевидение Национального радиовещания» (Radiodiffusion nationale Télévision).
RTF TV 1 (1945 — 1964)
23 марта 1945 г. «Национальное радиовещание» стало называться «Французское радиовещание» (Radiodiffusion française, RDF), телеканал стал называться Телевидение Французского радиовещания, в том же году стала выходить в эфир информационная программа «Télé-Journal». 9 февраля 1949 г. RDF было переименовано в «Французское радиовещание и телевидение» (Radiodiffusion-télévision française, RTF), телеканал стал называться Телевидение RTF, «Télé-Journal» была переименована в «Journal télévisé de la RTF». В 1950-1965 гг. вещание телеканала стало доступно во всей Франции (в Нор-паде-Кале и Пикардии в 1950 году, в Эльзасе в 1953, в Провансе и на Корсике, в регионе Рона-Альпы в 1954, Пиринеи-Юг, Лангедок-Руссильон в 1961, в Аквитании в 1962, в Бретани и Землях Луары, Нормандии, Центре в 1964, Латарингии, Шампани, Пуату-Шаранте, Лимузене, Бургунди и Франш-Конте в 1965 году). 21 декабря 1963 года после запуска RTF своего второго канала, канал RTF стал называться Телевидение RTF 1 (RTF Télévision 1), «Journal télévisé de la RTF» была переименована в «Actualités télévisées».
ORTF TV 1 (1964 — 1975)
27 июня 1964 г. RTF была реорганизована во Управление Французского радиовещания и телевидения (Office de radiodiffusion-télévision française, ORTF), канал «Телевидение RTF 1» был переименован в «Телевидение ORTF 1» (ORTF Télévision 1). В 1965 году «Actualités télévisées» была переименована в «Télé-Soir», ещё через четыре года — «Information Première», в 1972 года в «24 heures sur la Une», в 1975 году «Information télévisée 1».
TF 1 (c 1975)
1 января 1975 года ORTF была разделена на TF 1, Antenne 2″, France Régions 3 и Radio France, «Телевидение ORTF 1» было переименовано в «TF 1», «Information télévisée 1» была переименована в «TF1 Actualités», а в 1981 году в «Journal de 20 heures».
В 1987 году «TF 1» был приватизирован.
Рейтинг
| 1976 | 1977 | 1978 | 1979 | 1980 | 1981 | 1982 | 1983 | 1984 | 1985 | 1986 | 1987 | 1988 | 1989 | 1990 | 1991 | 1992 | 1993 | 1994 | 1995 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 45.4% | 50.4% | 50.4% | 46.8% | 47.3% | 46.3% | 42.3% | 37.9% | 39.1% | 38.6% | 38.2% | 42.1% | 44.8% | 41.0% | 41.9% | 42.1% | 41.0% | 41.0% | 39.5% | 37.3% |
| Январь | Февраль | Март | Апрель | Май | Июнь | Июль | Август | Сентябрь | Октябрь | Ноябрь | Декабрь | Год | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1996 | 35.6% | 33.1% | 35.6% | 35.0% | 35.1% | 33.7% | 34.0% | 35.4% | |||||
| 1997 | 34.6% | 35.6% | 34.5% | 34.9% | 35.3% | 35.7% | 32.8% | 35.8% | 34.8% | 34.9% | 34.2% | 37.0% | 35.0% |
| 1998 | 34.1% | 34.0% | 35.2% | 35.6% | 35.2% | 34.8% | 34.7% | 36.4% | 37.2% | 36.1% | 35.2% | 35.3% | 35.3% |
| 1999 | 34.9% | 36.5% | 35.6% | 35.9% | 34.2% | 35.1% | 33.0% | 34.7% | 34.7% | 36.1% | 35.2% | 35.2% | 35.1% |
| 2000 | 33.9% | 33.9% | 32.6% | 33.4% | 34.4% | 34.1% | 33.2% | 33.5% | 31.8% | 33.8% | 33.2% | 33.0% | 33.4% |
| 2001 | 33.8% | 33.3% | 33.6% | 32.5% | 31.8% | 31.8% | 31.3% | 33.7% | 33.6% | 32.0% | 32.0% | 32.8% | 32.7% |
| 2002 | 33.5% | 31.9% | 31.9% | 31.1% | 31.9% | 34.5% | 31.2% | 34.2% | 32.4% | 33.2% | 33.2% | 32.9% | 32.7% |
| 2003 | 31.9% | 31.3% | 31.8% | 30.5% | 31.1% | 31.6% | 31.1% | 31.3% | 31.4% | 32.4% | 30.8% | 32.2% | 31.5% |
| 2004 | 32.7% | 31.8% | 31.8% | 32.5% | 33.0% | 32.2% | 31.1% | 30.1% | 32.0% | 32.0% | 31.1% | 31.4% | 31.8% |
| 2005 | 32.2% | 32.1% | 32.7% | 31.4% | 31.7% | 31.2% | 32.6% | 34.5% | 33.4% | 33.4% | 31.5% | 31.9% | 32.3% |
| 2006 | 32.0% | 30.2% | 31.5% | 31.9% | 31.2% | 32.8% | 33.8% | 32.8% | 31.3% | 31.7% | 30.2% | 30.7% | 31.6% |
| 2007 | 30.7% | 31.0% | 31.0% | 30.3% | 31.4% | 30.5% | 30.2% | 31.6% | 31.8% | 31.8% | 29.3% | 28.9% | 30.7% |
| 2008 | 28.0% | 27.5% | 28.0% | 27.2% | 27.2% | 27.5% | 27.1% | 27.7% | 28.0% | 26.2% | 26.1% | 26.2% | 27.2% |
| 2009 | 26.7% | 26.2% | 26.7% | 26.3% | 25.5% | 25.9% | 25.7% | 26.7% | 26.6% | 26.2% | 25.8% | 24.8% | 26.1% |
| 2010 | 25.1% | 25.1% | 25.1% | 24.3% | 24.0% | 25.1% | 23.9% | 24.0% | 24.1% | 24.7% | 24.3% | 24.6% | 24.5% |
| 2011 | 24.0% | 23.9% | 24.5% | 23.2% | 23.6% | 23.3% | 22.8% | 23.4% | 24.1% | 24.5% | 23.0% | 23.3% | 23.7% |
| 2012 | 22.3% | 22.6% | 23.6% | 22.6% | 22.9% | 22.2% | 21.8% | 21.3% | 23% | 23.4% | 23.3% | 23.1% | 22.7% |
| 2013 | 23.3% | 23.2% | 23.9% | 22.6% | 22.2% | 21.9% | 21.4% | 22.2% | 23.4% |