
что это такое, для чего нужен, как его создать, чем грозит отсутствие этого файла
Тематический трафик – альтернативный подход в продвижении бизнеса

Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!

Robots.txt — это текстовый файл, содержащий сведения для поисковых роботов, которые помогают проиндексировать страницы портала.
Больше видео на нашем канале — изучайте интернет-маркетинг с SEMANTICA

Представьте, что вы отправились за сокровищами на остров. У вас есть карта. Там указан маршрут: “Подойти к большому пню. От него сделать 10 шагов на восток, затем дойти до обрыва. Повернуть вправо, найти пещеру”.
Это — указания. Следуя им, вы идете по маршруту и находите клад. Примерно также работает и поисковой бот, когда начинает индексировать сайт или страницу. Он находит файл robots.txt. В нем считывает, какие страницы нужно проиндексировать, а какие — нет. И, следуя этим командам, он обходит портал и добавляет его страницы в индекс.
Для чего нужен robots.txt
Роботы поисковых систем начинают ходить по сайтам и индексировать страницы после того, как сайт загружен на хостинг и прописаны dns. Они делают свою работу вне зависимости от того, есть у вас какие-то технические файлы или нет. Роботс указывает поисковикам, что при обходе веб-сайта нужно учитывать параметры, которые в нем находится.
Отсутствие файла robots.txt может привести к проблемам со скоростью обхода сайта и присутствия мусора в индексе. Некорректная настройка файла чревата исключением из индекса важных частей ресурса и присутствием в выдаче ненужных страниц.Все это, как результат, ведет к проблемам с продвижением.
Рассмотрим подробнее, какие инструкции содержатся в этом файле, как они влияют на поведение бота у вас на сайте.
Как сделать robots.txt
Для начала проверьте, есть ли у вас этот файл.
Введите в адресной строке браузера адрес сайта и через слэш имя файла, например, https://www.xxxxx.ru/robots.txt
Если файл присутствует, то на экране появится список его параметров.

Если файла нет:
- Файл создается в обычном текстом редакторе типо блокнота или Notepad++.
- Нужно задать имя robots, расширение .txt. Внести данные с учетом принятых стандартов оформления.
- Можно проверить на предмет ошибок с помощью сервисов типа вебмастера Яндекса.Там нужно выбрать пункт «Анализ robots.txt» в разделе «Инструменты» и следовать подсказкам.
- Когда файл готов, залейте его в корневой каталог сайта.
Правила настройки
У поисковиков не один робот. Некоторые боты индексируют только текстовый контент, некоторые — только графический. Да и у самих поисковых систем схема работы краулеров может быть разной. При составлении файла это нужно учитывать.
Некоторые из них могут игнорировать часть правил, например, GoogleBot не реагирует на информацию о том, какое зеркало сайта считать главным. Но в целом, они воспринимают и руководствуются файлом.
Синтаксис файла
Параметры документа: имя робота (бота) «User-agent», директивы: разрешающая «Allow» и запрещающая «Disallow».
Сейчас есть две ключевых поисковых системы: Яндекс и Google, соответственно, важно при составлении сайта учитывать требования обеих.
Формат создания записей выглядит следующим образом, обратите внимание на обязательные пробелы и пустые строки.

Директива User-agent
Робот ищет записи, которые начинаются с User-agent, там должны содержаться указания на название поискового робота. Если оно не указано, считается, что доступ ботов неограничен.
Директивы Disallow и Allow
Если нужно запретить индексацию в robots.txt, используют Disallow. С ее помощью ограничивают доступ бота к сайту или некоторым разделам.
Если роботс.тхт не содержит ни одной запрещающей директивы «Disallow», считается, что разрешена индексация всего сайта. Обычно запреты прописываются после каждого бота отдельно.
Вся информация, которая указана после значка #, является комментариями и не считывается машиной.
Allow применяют, чтобы разрешить доступ.
Символ звездочка служит указанием на то, что относится ко всем: User-agent: *.

Такой вариант, наоборот, означает полный запрет индексации для всех.

Запрет на просмотр всего содержимого определенной папки-каталога

Для блокировки одного файла нужно указать его абсолютный путь

Директивы Sitemap, Host

В файл, как правило, добавляют ссылку на «Sitemap» (карту сайта), чтобы облегчить боту ее поиск.
Для Яндекса в директиве Host принято указывать, какое зеркало вы хотите назначить главным. А Гугл, как мы помним, его игнорирует. Если зеркал нет, просто зафиксируйте, как считаете корректным писать имя вашего веб-сайта с www или без.
Директива Clean-param
Ее можно применять, если URL страниц веб-сайта содержат изменяемые параметры, не влияющие на их содержимое (это могут быть id пользователей, рефереров).
Например, в адресе страниц «ref» определяет источник трафика, т.е. указывает на то, откуда на сайт пришел посетитель. Для всех пользователей страница будет одинаковая.

Роботу можно указать на это, и он не будет загружать повторяющуюся информацию. Это снизит загруженность сервера.

Директива Crawl-delay
С помощью нее можно определить, с какой частотой бот будет загружать страницы для анализа. Эта команда применяется, когда сервер перегружен и указывает, что процесс обхода нужно ускорить.

Ошибки robots.txt
- Файл не находится в корневом каталоге. Глубже робот его искать не будет и не учтет.
- Буквы в названии должны быть маленькие латинские.
Ошибка в названии, иногда упускают букву S на конце и пишут robot. - Нельзя использовать кириллические символы в файле robots.txt. Если нужно указать домен на русском языке, используйте формат в специальной кодировке Punycode.
- Это метод преобразования доменных имен в последовательность ASCII-символов. Для этого можно воспользоваться специальными конвертерами.
Выглядит такая кодировка следующим образом:
сайт.рф = xn--80aswg.xn--p1ai
Дополнительную информацию, что закрывать в robots txt и по настройкам в соответствии с требованиями поисковиков Гугл и Яндекс можно найти в справочных документах. Для различных cms также могут быть свои особенности, это следует учесть.
Что такое robots.txt ?
Список вопросов в статье
1) Что такое поисковый робот?
2) Что такое robots.txt?
3) Как создать robots.txt?
4) Что и зачем можно записать в этот файл?
5) Примеры названий роботов
6) Пример готового robots.txt
7) Как проверить работу моего файла?
1. Что такое поисковый робот?
Робот (англ. crawler) хранит список URL, которые он может проиндексировать, и регулярно выкачивает соответствующие им документы. Если при анализе документа робот обнаруживает новую ссылку, он добавляет ее в свой список. Таким образом, любой документ или сайт, на который есть ссылки, может быть найден роботом, а значит, и поиском Яндекса.
2. Что такое robots.txt?
Поисковые роботы ищут на сайтах в первую очередь файл robots.txt. Если у Вас на сайте есть директории, контент и тп, которые бы Вы, например, хотели скрыть от индексации (поисковик не выдавал информацию по ним. Например: админка, другие панели страницы), то должны внимательно изучить инструкцию по работе с данным файлом. robots.txt — это текстовый файл (.txt), который находится в корне (коренвой директории) Вашего сайта. В нём записываются инструкции для поисковых роботов. Эти инструкции могут запрещать к индексации некоторые разделы или страницы на сайте, указывать на правильное «зеркалирование» домена, рекомендовать поисковому роботу соблюдать определенный временной интервал между скачиванием документов с сервера и т.д.
3. Как создать robots.txt?
Создать robots.txt очень просто. Заходим в обычный текстовой редактор (или правая кнопка мыши — создать — текстовой документ), например, Блокнот (Notepad). Далее создаём текстовой файл и переименовываем его в robots.txt .
4. Что и зачем можно записать в файл robots.txt?
Перед тем, как указать команду поисковику, нужно определиться, к какому Боту она будет адресована. Для этого существует команда User-agent
Ниже привёл примеры:
User-agent: * # написанная после этой строки команда будет обращена ко всем поисковым роботам
User-agent: YandexBot # обращение к основному роботу индексации ЯндексаUser-agent: Googlebot # обращение к основному роботу индексации Google
Разрешаем и запрещаем индексацию
Для разрешения и запрета индексации есть две соответствующие команды — Allow (можно) и Disallow (нельзя).
User-agent: *
Disallow: /adminka/ # запрещает всем роботам индексировать директорию adminka, в которой якобы админ-панельUser-agent: YandexBot # команда ниже будет обращена к Яндексу
Disallow: / # запрещаем индексацию всего сайта роботом ЯндексаUser-agent: Googlebot # команда ниже будет обращена к Google
Allow: /images # разрешаем индексировать всё содержимое директории images
Disallow: / # а всё остальное запрещаем
Порядок не важен
User-agent: *
Allow: /images
Disallow: /User-agent: *
# начинающиеся с '/images'
Disallow: /
Allow: /images
# и там, и там разрешено индексировать файлы
Директива Sitemap
Данная команда указывает адрес карты вашего сайта:
Sitemap: http://yoursite.ru/structure/my_sitemaps.xml # Указывает адрес карты сайта
Директива Host
Данная команда вставляется В КОНЦЕ вашего файла и обозначает главное зеркало
1) прописывается В КОНЦЕ вашего файла
2) указывается только один раз. в противном случае принимается только первая строка
3) указывается после Allow или Disallow
Host: www.yoursite.ru # зеркало Вашего сайта#Если www.yoursite.ru главное зеркало сайта, то
#robots.txt для всех сайтов-зеркал выглядит так
User-Agent: *
Disallow: /images
Disallow: /include
Host: www.yoursite.ru# по умолчанию Google игнорирует Host, надо сделать так
User-Agent: * # индексируют все
Disallow: /admin/ # запрещаем индекс админаHost: www.mainsite.ru # указываем главное зеркало
User-Agent: Googlebot # теперь команды для Google
Disallow: /admin/ # запрет для Google
| Внимание! Параметр Host должен состоять из одного корректного имени хоста (соответствовал RFC 952 и не должен быть IP-адресом) и допустимого номера порта. Некорректно составленные строчки ‘Host:’ игнорируются. |
5. Примеры названий роботов
Роботы Яндекса
У Яндекса есть несколько видов роботов, которые решают самые разные задачи: один отвечают за индексацию изображений, другие за индексацию rss данных для сбора данных по блогам, третьи — мультимедийные данные. Самый главный — YandexBot, он индексирует сайт с целью составить общую базу данных по сайту (заголовки, ссылки, текст и тп). Также есть робот для быстрой индексации (индексация новостей и тп).
YandexBot — основной индексирующий робот;
YandexMedia — робот, индексирующий мультимедийные данные;
YandexImages — индексатор Яндекс.Картинок;
YandexCatalog — «простукивалка» Яндекс.Каталога, используется для временного снятие с публикации недоступных сайтов в Каталоге;
YandexDirect — робот Яндекс.Директа, особым образом интерпретирует robots.txt;
YandexBlogs — робот поиска по блогам, индексирующий посты и комментарии;
YandexNews — робот Яндекс.Новостей;
YandexPagechecker — валидатор микроразметки;
YandexMetrika — робот Яндекс.Метрики;
YandexMarket — робот Яндекс.Маркета;
YandexCalendar — робот Яндекс.Календаря.
6. Пример готового robots.txt
Собственно пришли к примеру готового файла. Надеюсь после приведённых выше примеров Вам всё будет понятно.
User-agent: *
Disallow: /admin/
Disallow: /cache/
Disallow: /components/User-agent: Yandex
Disallow: /admin/
Disallow: /cache/
Disallow: /components/
Disallow: /images/
Disallow: /includes/Sitemap: http://yoursite.ru/structure/my_sitemaps.xml
Host: www.yoursite.ru
| Внимание! Если Ваш файл слишком большой и превышает 32 Кб, то он по умолчанию разрешает всё для всех ботов. |
7. Как проверить работу моего файла?
1) Загружаем файл в Яндекс Вебмастер
2) Читаем результаты
Спасибо за внимание! Надеюсь, что материал был полезен!
что это такое, функции, как создать, настроить и проверить, ошибки при заполнении, пример правильно составленного файла robots

Файл robots.txt (индексный файл) – это документ в формате .txt, где указываются инструкции к индексированию веб-сайта/его страниц/разделов и прочих материалов для поисковых роботов. Проще говоря, он включает команды, дающие рекомендации роботам касательно того, какие материалы веб-ресурса можно скачивать и вносить в индекс, а какие – нет.
Индексный файл имеет кодировку UTF-8, и он работает с протоколами http, https и FTP. Robots размещают в корне сайта. Он представляет собой стандартный текстовый документ. А чтобы получить к нему доступ, достаточно перейти по адресу:
http://название_вашего_сайта.ru/robots.txt.
Какие функции выполняет robots.txt?
Он играет важнейшую роль в оптимизации проекта. Если вы не позаботитесь о создании данного файла, то без него нагрузка на сайт со стороны роботов может быть колоссальной. Еще это приведет к очень медленной индексации, а если неправильно настроить документ, то вы и вовсе рискуете потерять ресурс из поисковой выдачи, из-за чего пользователи просто не смогут найти его ни в одной системе.
А также применяя robots.txt, вы можете попросить ботов не сканировать:
- служебные страницы, где находится конфиденциальная информация о посетителях сайта;
- страницы, где указываются поисковые результаты;
- зеркала;
- страницы с разными формами отправки контента.
Очевидно, что без индексного файла вы позволите отправить в поисковую выдачу документы, которые нужно обязательно скрыть от индексирования, потому что в них нет контента, который нес бы хоть какую-то пользу для потенциальных посетителей. А это непременно плохо скажется на вашем ресурсе.
На заметку. Файл robots.txt носит рекомендательный характер для поисковых систем, и если в этом файле вы прописали команду, запрещающую сканировать определенную страницу, имеющую внешнюю ссылку с постороннего ресурса или на самом сайте, она с большой вероятностью все равно может проиндексироваться.
Правильное создание и редактирование robots.txt
Как вы уже поняли, файл robots является обычным документом в формате .txt. Чтобы его создать, не понадобится никаких посторонних программ. Достаточно иметь стандартный Блокнот, который есть на любом компьютере. Создайте новый документ и пропишите в нем соответствующие правила для поисковых роботов (о них мы поговорим немного позже). Затем сохраните его, н
Зачем нужен файл robots.txt
Здравствуйте! В моей жизни было такое время, когда я абсолютно ничего не знал про создание сайтов и уж тем более не догадывался про существование файла robots.txt.

Когда простой интерес перерос в серьезное увлечение, появились силы и желание изучить все тонкости. На форумах можно встретить множество тем, связанных с этим файлом, почему? Все просто: robots.txt регулирует доступ поисковых систем к сайту, управляя индексированием и это очень важно!
Robots.txt — это текстовый файл, предназначенный для ограничения доступа поисковых роботов к разделам и страницам сайта, которые нужно исключить из обхода и результатов выдачи.
Зачем скрывать определенное содержимое сайта? Вряд ли Вы обрадуетесь, если поисковый робот проиндексирует файлы администрирования сайта, в которых могут храниться пароли или другая секретная информация.
Для регулирования доступа существуют различные директивы:
- User-agent — агент пользователя, для которого указаны правила доступа,
- Disallow — запрещает доступ к URL,
- Allow — разрешает доступ к URL,
- Sitemap — указывает путь к карте сайта,
- Crawl-delay — задает интервал сканирования URL (только для Яндекса),
- Clean-param — игнорирует динамические параметры URL (только для Яндекса),
- Host — указывает главное зеркало сайта (только для Яндекса).
Обратите внимание, с 20 марта 2018 года Яндекс официально прекратил поддержку директивы Host. Её можно удалить из robots.txt, а если оставить, то робот её просто игнорирует.
Располагаться файл должен в корневом каталоге сайта. Если у сайта есть поддомены, то для каждого поддомена составляется свой robots.txt.
Всегда нужно помнить о безопасности. Этот файл может посмотреть любой желающий, поэтому не нужно указывать в нем явный путь к административным ресурсам (панелям управления и т.д.). Как говориться, меньше знаешь — крепче спишь. Поэтому, если на страницу нет никаких ссылок и Вы не хотите ее индексировать, то не нужно ее прописывать в роботсе, ее и так никто не найдет, даже роботы-пауки.
Поисковый робот, сканируя сайт, в первую очередь проверяет наличие файла robots.txt на сайте и в дальнейшем при обходе страниц следует его директивам.
Сразу хочу отметить, что поисковые системы по разному относятся к этому файлу. Например, Яндекс безоговорочно следует его правилам и исключает запрещенные страницы из индексирования, в то время как Google воспринимает этот файл как рекомендацию и не более.
Для запрета индексирования страниц возможно применение иных средств:
- редирект или установка пароля на каталог с помощью файла .htaccess,
- мета-тег
noindex(не путать с тегом <noindex> для запрета индексации части текста), - атрибут
rel="nofollow"для ссылок, а также удаление ссылок на лишние страницы.
При этом Google может успешно добавить в поисковую выдачу страницы, запрещенные к индексации, несмотря на все ограничения. Его основной аргумент — если на страницу ссылаются, значит она может появится в результатах поиска. В данном случае рекомендуется не ссылаться на такие страницы, но позвольте, файл robots.txt как раз и предназначен для того, чтобы выкинуть из выдачи такие страницы… На мой взгляд, логика отсутствует 🙄
Удаление страниц из поиска
Если запрещенные страницы все же были проиндексированы, то необходимо воспользоваться Google Search Console и входящим в ее состав инструментом удаления URL-адресов:
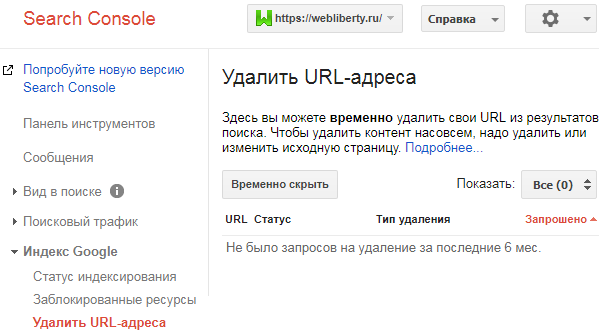
Аналогичный инструмент есть в Яндекс Вебмастере. Подробнее об удалении страниц из индекса поисковых систем читайте в отдельной статье.
Проверка robots.txt
Продолжая тему с Google, можно воспользоваться еще одним инструментом Search Console и проверить файл robots.txt, правильно ли он составлен для запрета индексирования определенных страниц:
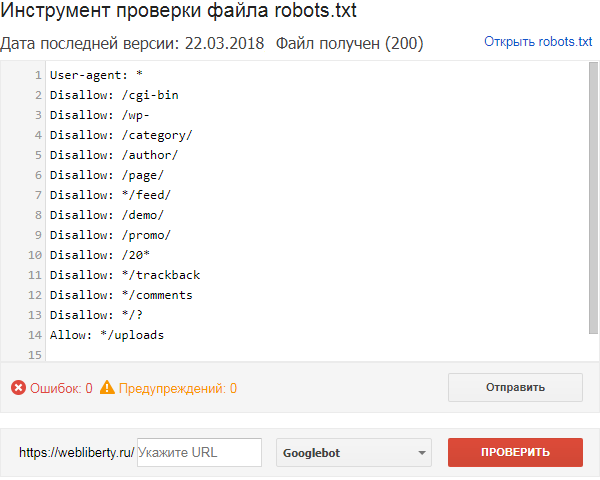
Для этого достаточно ввести в текстовое поле URL-адреса, которые необходимо проверить и нажать кнопку Проверить — в результате проверки выяснится, запрещена данная страница к индексации или же ее содержимое доступно для поисковых роботов.
Дополнительные сведения о проверке доступа поисковых систем к сайту Вы найдете на этой странице.У Яндекса также есть подобный инструмент, находящийся в Вебмастере, проверка осуществляется аналогичным образом:
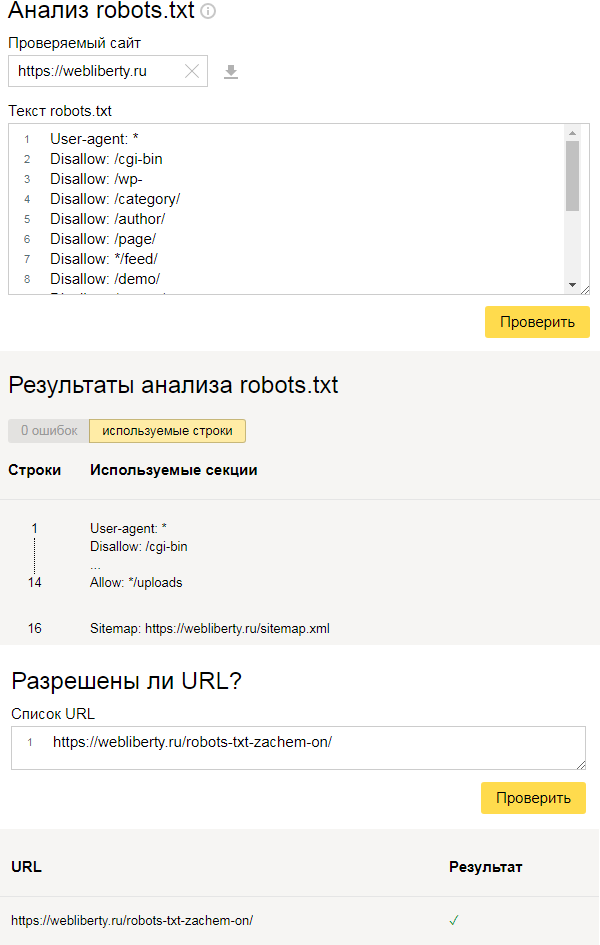
Если Вы не знаете как правильно составить файл, то просто создайте пустой текстовый документ с именем robots.txt, а по мере изучения особенностей CMS и структуры сайта дополните его необходимыми директивами.
О правильном составлении файла robots.txt для WordPress читайте по ссылке. До встречи!
зачем нужен, как создать, что прописать
paveltsarcov | 06.11.2017
Каждый начинающий SEO-специалист при оптимизации сайта сталкивается с необходимостью создания файла robots.txt. О том, какая роль этого файла в SEO-продвижении, как его создавать и использовать пойдет речь в данной статье.
При краулинге сайта поисковый бот сразу ищет файл robots.txt и следует его инструкциям. Сам файл представлен в текстовом формате UTF-8 и находится в корневой папке сайта. Изучив данный файл, поисковый бот сможет определить, какие страницы разрешены для сканирования, а какие нет. Файл роботс тхт позволит поисковику соблюдать рекомендации по извлечению информации с сайта, например, временной интервал кроулинга ресурса.
Для чего robots.txt?
Чтобы закрыть от поисковой системы конфиденциальные файлы, а также контент пользователей, веб-мастера прописывают запрет индексации на отдельные страницы сайта. При прохождении роботом страниц сайта нагружается сервер ресурса. В данном случае от индексации закрываются служебные и непопулярные страницы сайта (под непопулярными подразумеваются страницы с нулевой или же низкой частотой запроса). Также от робота закрывают админку сайта. Поэтому чаще всего роботс.тхт используется для сохранения конфиденциальности в сети и реже для избегания перегрузки сервера.
Важно понимать, что на закрытые от индексации страницы не стоит ставить внешние или внутренние ссылки. Поисковый бот может перейти на страницу через ссылку разрешенной страницы, невзирая на запрет.
Как создать robots.txt?
Создать файл robots.txt можно в любом текстовом редакторе (например, Sublime). Важно заполнить составные параметры, придерживаясь которых бот будет индексировать сайт.

Параметры в robots.txt
User-agent. Параметр указывает название поискового робота, для которого предназначен документ. Основной робот поисковой системы Google – это Googlebot, а бот YandexBot – поисковика Яндекс. Можно открыть доступ всем возможным поисковым роботам, которые попадают на сайт. Для этого после параметра User-agent нужно прописать нужно прописать название бота. Пример: User-agent: Googlebot.
Disallow. Параметр robots.txt: disallow позволяет открывать или закрывать для индексации страницы сайта. Чтобы закрыть весь сайт от сканирования требуется прописать: “/”. А чтобы закрыть отдельную страницу или папку, нужно прописать путь этого каталога после слеша: “Disallow: /home/“. Для открытия всех страниц сайта под индексацию прописывается пробел в параметре. Для закрытия/открытия индексирования определенного типа файлов используется прописывается путь к данному файлу: Disallow: /home/myfile.php.
Allow. В данном параметре прописываются страницы и файлы, которые робот может краулить в первую очередь. Для этого прописывается путь к страницам или файлам: “/ua/gallery/page-1”. Важно помнить, что в параметрах allow и disallow нужно указывать каждый путь к каждой папке и/или странице отдельно по порядку прохождения роботом директорий сайта.
Host. Необходимо прописать адрес сайта, по которому будет переходить робот при индексации. Если при разных адресах доступны одинаковые версии сайта, например, с www и без, то необходимо указать точный адрес. Тогда бот будет индексировать нужный ресурс. Адрес сайта указывается с https://, но если сайт еще не успел перейти на новый формат, то http:// не прописывается. Это выглядит так: Host: www.idg.net.ua.
Sitemap. В данном параметре необходимо указывать путь на карту сайта. Sitemap – это файл, в котором хранятся все страницы сайта. Это необходимо, чтобы робот мог при каждой новой сессии индексации проверять сайт на наличие новых страниц и вносить их в индекс. Пример: Sitemap: http://www.idg.net.ua/sitemap.xml.
Crawl-delay. Используя данный параметр, возможно избежать нагрузки на сервер. Он регламентирует время загрузки страниц сайта при сканировании их роботом. Параметр характеризуется секундами. При индексации страниц поисковый робот будет с точной поочередностью проходить все страницы сайта, не создавая ложную нагрузку на слабый сервер.
Какие результаты получает поисковый робот при работе через robots.txt?
- Запрет на доступ к индексации всех страниц сайта.
- Разрешение на сканирование только избранных страниц.
- Доступ к индексации отдельных страниц сайта.
Результаты прохождения индексации
После того как робот прошелся по разрешенным страницам, результат виден в Webmaster Tools. Если проверка прошла успешно и со страницей все в порядке, то она будет внесена в индекс.
Если к содержимому сайта найдена ошибка, то их необходимо исправить. Причиной может быть долгая загрузка страницы, невозможность перейти по переадресации сайта на другую страницу (неправильно настроен 301 редирект), неверный ответ сервера. В таких случаях в Webmaster Tools можно найти перечень всех ошибок за период сканирования ботом страниц сайта. Это могут быть 404, 505, 503 ошибки.
Тестируем файл robots.txt
Чтобы убедиться в работающем роботс.тхт, необходимо ввести исходный код файла в строку проверки инструментов веб-мастера той поисковой системы, в которой продвигается сайт. При наличии ошибок или неточностей поисковик укажет на причину с детальной инструкцией.
Важно понимать, что файл robots.txt является лишь рекомендацией поисковому роботу по индексации сайта. Как показывает практика, поисковые роботы могут индексировать скрытые страницы, а также различные файлы и код, который относится к front-end части сайта.
Для наглядного примера можно ознакомиться с файлом robots.txt на примере Google: https://www.google.com/robots.txt.