
что это такое, как правильно использовать
Nofollow – это атрибут, который прописывается для определенной ссылки или всех ссылок на странице в мета-теге robots с целью запрета поисковым роботам на переход по ним.
Noindex – это атрибут, который закрывает от индексации текст на странице.
То есть, noindex отвечает за контент в документе и запрет на индексацию его, в то время как nofollow – за ссылку.
Правила применения и зачем нужен nofollow?
Как правильно прописать nofollow?
Robots Nofollow
Rel=»Nofollow»
Утекает ли вес ссылки через nofollow?
Стоит ли закрывать внутренние ссылки в nofollow?
Атрибут noindex: что это и чем отличается от nofollow?
Выводы
Правила применения и зачем нужен nofollow?
Чтобы понять, в каких случаях может вообще пригодиться этот атрибут,
рассмотрим, как к нему относятся популярнейшие поисковые системы.
- Яндекс. Когда на вашем ресурсе содержатся разделы, предназначенные специально для обсуждения записей, написания комментариев к статьям или форум, важно следить за тем, какие исходящие ссылки оставляют в них посетители. Желательно модерировать каждый комментарий. Благодаря этому владелец сайта сможет предотвратить размещение различных вредоносных ссылок от спамеров. Хотя поисковик и не учитывает их, спам сильно влияет на репутацию веб-ресурса и к нему может быть применен фильтр. В связи с этим следует проверять все комментарии, и если есть какие-то сомнения относительно качества размещаемой ссылки, пропишите для них атрибут rel=”nofollow”. Сейчас, в измененном руководстве Яндекс, данный текст был удален и осталось только правило применения rel=»nofollow» Руководство Яндекс о nofollow
- Google. Если у вашего сайта есть раздел, где пользователи могут комментировать записи, есть большой риск, что в комментариях появятся ссылки на вредоносные страницы.
 Спамеры «любят» сайты с комментариями без модерации. Атрибут nofollow для спам-ссылок спасет ваш ресурс и сохранит его чистую репутацию в глазах поисковой системы. Если же вы доверяете сайту, на который ссылается посетитель или вы сами ссылаетесь, то нет необходимости прописывать nofollow. Руководство Google о nofollow
Спамеры «любят» сайты с комментариями без модерации. Атрибут nofollow для спам-ссылок спасет ваш ресурс и сохранит его чистую репутацию в глазах поисковой системы. Если же вы доверяете сайту, на который ссылается посетитель или вы сами ссылаетесь, то нет необходимости прописывать nofollow. Руководство Google о nofollow
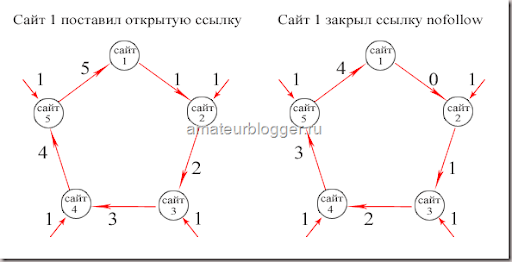 Спамеры «любят» сайты с комментариями без модерации. Атрибут nofollow для спам-ссылок спасет ваш ресурс и сохранит его чистую репутацию в глазах поисковой системы. Если же вы доверяете сайту, на который ссылается посетитель или вы сами ссылаетесь, то нет необходимости прописывать nofollow. Руководство Google о nofollow
Спамеры «любят» сайты с комментариями без модерации. Атрибут nofollow для спам-ссылок спасет ваш ресурс и сохранит его чистую репутацию в глазах поисковой системы. Если же вы доверяете сайту, на который ссылается посетитель или вы сами ссылаетесь, то нет необходимости прописывать nofollow. Руководство Google о nofollowЭти сообщения взяты с официальных сайтов поисковиков. Как видите, в Яндекс и Google написаны аналогичные вещи: значение nofollow нужно использовать в тех случаях, когда вы хотите сообщить ботам о недоверии в отношении сайта, на который ведет ссылка.
Только в Яндекс упор делается, что ссылка с rel=»nofollow» не будет индексироваться поисковой системой, а в Google говорится о том, что робот не будет переходить по такой ссылке.
Рассмотрим более конкретный пример, когда для ссылки требуется прописать запрещающий атрибут:
Материал сомнительного качества. Если вам не нравится содержание страницы, на которую посетитель оставляет ссылку в комментарии, и вы не желаете жертвовать репутацией своего сайта, прописывайте в теги данной ссылки значение rel=”nofollow”.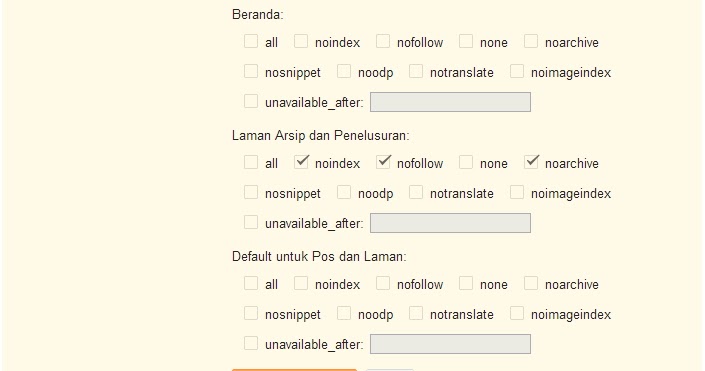 Спамеры, заметив на вашем ресурсе тенденцию, когда к непроверенным ссылкам добавляется блокирующий атрибут, вскоре прекратят попытки навредить сайту. Если же вы видите, что пользователь оставляет ссылку на качественный материал, вручную или автоматически nofollow можно удалить.
Спамеры, заметив на вашем ресурсе тенденцию, когда к непроверенным ссылкам добавляется блокирующий атрибут, вскоре прекратят попытки навредить сайту. Если же вы видите, что пользователь оставляет ссылку на качественный материал, вручную или автоматически nofollow можно удалить.
Как правильно прописать nofollow?
Это сейчас nofollow позволяет управлять каждой ссылкой отдельно, но когда-то данное значение можно было задействовать только в мета-теге, который закрывал от поисковой системы абсолютно все ссылки на странице. И для запрета перехода по отдельным ссылкам вебмастерам приходилось блокировать их URL в robots.txt.
Robots Nofollow
Эти мета-теги так и остались по сей день. Если вы хотите закрыть от индексации все ссылки, содержащиеся на определенной странице, то на этой странице нужно прописать такой код:
<meta name=”robots” content=”nofollow” />
Важно не путать данный тег с двумя нижеприведенными кодами, content=»none» и content=”noindex, nofollow” блокируют доступ ботов ко всей странице, а не только к ее ссылкам. Поэтому, если вы хотите чтобы страницы индексировались, то ни в коем случае не прописывайте для них два вот этих тега:
Поэтому, если вы хотите чтобы страницы индексировались, то ни в коем случае не прописывайте для них два вот этих тега:
<meta name=”robots” content=”none” />
<meta name =”robots” content=”noindex, nofollow” />
Rel=»Nofollow»
Выше мы рассмотрели варианты, как запретить переход поисковых роботов по всем ссылкам на страницах. Но еще можно назначить запрет на переход к конкретной ссылке.
Чтобы запретить для индексации и переход робота по ссылке, к ней надо прописать атрибут rel=”nofollow”, в коде это выглядит так:
<a href=”URL” rel=”nofollow”>анкор гиперссылки</a>
Утекает ли вес ссылки через nofollow?
Хотя Google в своих заявлениях позиционирует применение атрибута nofollow как переход по ссылке. И это подтвердило обращение бывшего главы компании по борьбе с поисковым спамом, Мэтта Катса. Он заявил, что «Google может учитывать ссылки из социальных сетей, даже несмотря на nofollow».
 youtube.com/embed/ofhwPC-5Ub4″ allow=»accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»» frameborder=»0″/>
youtube.com/embed/ofhwPC-5Ub4″ allow=»accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»» frameborder=»0″/>А вот с Яндексом вопрос не явный. Он четко пишет в своей документации, что данный атрибут запрещает индексацию таких ссылок.
А если мы перейдем в описание атрибута robots nofollow, то здесь уже видим запрет на переход, и не слово про индексацию.
Но, раньше можно было это проверить, если применить в поиске такую конструкцию url: ваш урл << inlink:(“анкор ссылки”), и Яндекс нам отображал только те страницы, где содержится наш искомый анкор ссылки. Сейчас же этот метод не работает, поисковая система Яндекс запретила использовать такую конструкцию в поиске. Поэтому можно с большей долью вероятностью сказать, что Яндекс может учитывать такие ссылки, потому что они появляются в Яндекс Вебмастер.
Видно, например, что Яндекс учитывает ссылки с Твиттера, даже если они отдаются через редирект и закрыты nofollow.
В целом можно сказать, что применение данного атрибута для поисковых роботов не всегда является запретом, если особенно сайт авторитетный.
Стоит ли закрывать внутренние ссылки в nofollow?
В прошлом, seo оптимизаторы сильно злоупотребляли rel=»nofollow» тем самым манипулирую передаваемым весом внутри сайта. Поэтому поисковая система Google заявила, что все внутренние ссылки отмеченные rel=»nofollow» будут отдавать вес вникуда https://www.mattcutts.com/blog/pagerank-sculpting/.
То есть со страницы где стоит такая ссылка будет уходить вес, но на страницу на которую стоит ссылка он не будет передаваться, получается он будет обнуляться.
Об этом в видео говорит бывший руководитель поиска в Google. Видео на английском, поэтому включите русские субтитры.
Атрибут noindex: что это и чем отличается от nofollow?
Многие начинающие вебмастера ломают голову, не понимая, чем noindex отличается от nofollow. Все просто:
Все просто:
- nofollow — применяется к ссылкам
- noindex — применяется к тексту
Если вы хотите запретить текст на всей странице сайта для индексации, но при этом учитывать ссылки, на странице нужно прописать следующий код:
<meta name=”robots” content=”noindex, follow: />
Если вы хотите закрыть часть текста, то в Google нет такого атрибута, но в Яндексе это возможно. Тег noindex был внедрен поисковиком Яндекс, так как раньше он не понимал nofollow, а ненужные ссылки нужно было как-то закрывать от роботов.
Но в 2010 году поисковая система начала работать с атрибутом rel=”nofollow”, при этом noindex не исчез, а остался отвечать за скрытие текста. Теперь, если вы хотите закрыть от индексации текст или например анкор ссылки, пропишите команду:
<noindex><a href=”url”>анкор ссылки</a></noindex>
Сама ссылка будет открыта для перехода роботами поисковых систем, не учтется только ее текст (анкор).
Например это удобно было, когда Яндекс ввел новый алгоритм Баден-Баден, который накладывал санкции за seo тексты. Стоило закрыть портянки текста в noindex, и можно было выйти из под этого фильтра, причем не потерять позиции в Google, так как поисковая система Google не учитывает тег <noindex></noindex>.
Выводы
Nofollow отвечает за переход поисковых систем по этим ссылкам, как на всей странице, так и для определенной ссылки. Ранее noindex тоже выполнял аналогичную функцию, но только по отношению к Яндексу, который со временем начал понимать nofollow, в результате чего значением noindex начали закрывать от индексации контент на странице.
Владелец сайта должен грамотно использовать атрибут nofollow и понимать, в каких именно случаях это делать:
- Когда ссылка ведет на веб-ресурсы с некачественным контентом.
- Когда вы размещаете на странице коммерческий контент.
По атрибуту nofollow ссылка может индексироваться и передавать свой вес, если она стоит на качественный ресурс.
Главная задача использования nofollow — помочь указать приоритетные для сканирования ссылки, разделить продающие статьи от информационных, а также защитить сайт от спама, который, если не контролировать, может привести к снижению ранжирования или куда хуже, вылету ресурса из индекса.
Для всех других ситуаций можете смело применять dofollow ссылки, открытые для поисковых роботов. Репутация сайта ничуть не ухудшится, а даже улучшится, если вы будете оставлять ссылки на полезные для вашей целевой аудитории страницы. И никакой вес ваши документы не потеряют, а наоборот даже могут приобрести за счет обратного PageRank.
использование noindex, nofollow, robots и др.
На индексацию веб-страниц можно влиять по-разному. Кроме задания специальных директив в файле robots.txt используются noindex, nofollow, robots и др. элементы в коде веб-страницы.
Тег noindex
Используется для запрета индексации части страницы, но учитывается только
поисковыми роботами Яндекса и Рамблера (Google его игнорирует)
<noindex>то, что нужно скрыть</noindex>
Атрибут rel=»nofollow»
Это атрибут тега <a>.
<a href="http://site.ru" rel="nofollow">Текст ссылки</a>
Это значит, что «закрывать» ссылку нужно так:
<noindex><a href="http://site.ru" rel="nofollow">Текст ссылки</a></noindex>
meta-тег
На странице meta-тег «robots» (как и все meta-теги) находится между тегами <head> и </head>. Он позволяет управлять индексацией всей страницы.
Инструкция для всех роботов:
<meta name="robots" content="значение">
Атрибут content может иметь значение
- noindex — не индексировать
- index -индексировать
- nofollow- не следовать по ссылкам
- follow- следовать по ссылкам
- all — индексировать и следовать по ссылкам
- none — не индексировать и не следовать по ссылкам
- noimageindex — запретить индексирование картинок
- noarchive — запретить выводить ссылку «Сохранено в кэше» (поисковики будут по-прежнему индексировать страницу и выводить ее фрагмент)
- nosnippet — выводить выводить
фрагменты страницы ( это текст, который поисковики показывают под названием страницы в результатах поиска ). При удалении фрагментов удаляются также и сохраненные в кэше страницы.
 При удалении фрагментов удаляются также и сохраненные в кэше страницы.
При удалении фрагментов удаляются также и сохраненные в кэше страницы.Допустимо указывать несколько значений через запятую:
<meta name="robots" content="noindex, nofollow">
Инструкция для робота Google
не индексировать картинки (ссылки будут индексироваться):
<meta name="googlebot" content="noimageindex">
Атрибут alt
Атрибут alt тега <a> задает альтернативный текст для изображения, который отображается в браузере, если не удается показать само изображение
<a href="http://site.ru"><img src="http://www.mysite.ru/image.gif" alt="Мой рисунок"/></a>
Поисковые системы запоминают значение атрибута alt при индексации страницы, но не используют его при ранжировании результатов поиска.
Известно, что Google учитывает текст атрибута alt только тех изображений, которые являются ссылками на другие страницы.
Когда используется зеркало сайта
Для того чтобы в поисковиках не было дублирования страниц с зеркала сайта, следует задать в meta-теге URL абсолютный адрес страницы, а на зеркале – абсолютный адрес страницы основного сайта.
<meta name="URL" content="абсолютный адрес страницы">
Просмотров: 1201
В чем отличия? – Dr. Link Check
В наши дни большинство владельцев веб-сайтов прекрасно осознают важную роль, которую играет высококачественный контент в привлечении внимания Google. С этой целью предприятия и специалисты по цифровому маркетингу тратят все больше времени и ресурсов на то, чтобы веб-сайты обнаруживались роботами поисковых систем и, следовательно, находили их целевые аудитории.
Хотя каждый владелец веб-сайта хочет высокого рейтинга в поисковых системах и соответствующего увеличения трафика, существуют определенные области сайта, которые лучше всего полностью скрыть от поисковых роботов.
Зачем скрывать части вашего сайта от поисковых систем?
Вы можете задаться вопросом, почему поисковые роботы не должны индексировать части вашего веб-сайта. Короче говоря, это действительно может помочь вашему общему рейтингу.
Вот несколько примеров веб-страниц, которые поисковые роботы должны игнорировать:
- Целевые страницы : Очевидно, что целевые страницы очень важны для привлечения потенциальных клиентов и даже прямой продажи продуктов. Однако у вас могут быть определенные целевые страницы, содержащие сезонные предложения или предназначенные для конкретных (платных) рекламных кампаний.
- Страницы благодарности : Как только ваш цифровой маркетинг расширится, ваш веб-сайт, вероятно, будет содержать несколько страниц благодарности, на которые посетители перенаправляются после загрузки лид-магнита или подписки на список рассылки. Вы почти наверняка захотите оградить эти страницы от поисковых роботов, так как они могут показаться скудными по содержанию и интерпретироваться как «спам».
- Загрузка PDF : Продолжая приведенный выше пример, вы также должны убедиться, что любые страницы с раздачами или загрузками и прикрепленные к ним файлы скрыты от вашей аудитории, поскольку вы, конечно же, не хотели бы, чтобы они были легко доступны без сбора сначала адрес электронной почты.
- Страницы входа в систему : Если на вашем сайте есть форум участника или клиентская зона, вы, вероятно, также захотите скрыть эти страницы от поисковых систем.

Как видите, существует множество случаев, когда вам следует активно отговаривать поисковые системы от перечисления определенных разделов вашего сайта. Скрытие этих страниц помогает гарантировать, что ваша домашняя страница и краеугольный контент получат то внимание, которого они заслуживают.
Как скрыть части вашего сайта от поисковых систем?
Так как же заставить роботов поисковых систем закрывать глаза на определенные страницы вашего веб-сайта? Ответ кроется в noindex, nofollow и disallow. Эти инструкции позволяют вам точно определить, как вы хотите, чтобы ваш сайт сканировался поисковыми системами.
Эти инструкции позволяют вам точно определить, как вы хотите, чтобы ваш сайт сканировался поисковыми системами.
Давайте погрузимся и узнаем, как они работают.
Инструкция noindex
Как вы, наверное, можете себе представить, добавление инструкции noindex на веб-страницу указывает поисковой системе «не индексировать» эту конкретную область вашего сайта. Веб-страница по-прежнему будет видна, если пользователь щелкнет ссылку на страницу или введет ее URL-адрес непосредственно в браузере, но она никогда не появится в результатах поиска Google, даже если она содержит ключевые слова, которые ищут пользователи.
Инструкция noindex обычно размещается в разделе HTML-кода страницы в виде метатега:
Также можно изменить метатег, чтобы страницу игнорировали только определенные поисковые системы. Например, если вы хотите скрыть страницу только от Google, разрешив Bing и другим поисковым системам отображать страницу, вы должны изменить код следующим образом:
Немного сложнее настроить и, следовательно, реже использовать доставку инструкции noindex как части заголовков HTTP-ответа сервера:
HTTP/2.
 0 200 OK
…
X-Robots-Tag: noindex
0 200 OK
…
X-Robots-Tag: noindex
В наши дни большинство людей создают сайты с помощью системы управления контентом, такой как WordPress, что означает, что вам не придется возиться со сложным HTML-кодом, чтобы добавить на страницу инструкцию noindex. Самый простой способ добавить noindex — загрузить SEO-плагин, такой как All in One SEO, или популярную альтернативу от Yoast. Эти плагины позволяют вам применить noindex к странице, просто установив флажок.
Инструкция nofollow
Добавление инструкции nofollow на веб-страницу не мешает поисковым системам индексировать ее, но сообщает им, что вы не хотите одобрять какие-либо ссылки с этой страницы. Например, если вы являетесь владельцем крупного веб-сайта с высоким авторитетом и добавляете инструкцию nofollow на страницу, содержащую список рекомендуемых продуктов, компании, на которые вы ссылаетесь, не получат никакого авторитета (или повышения рейтинга) от того, что они указан на вашем сайте.
Даже если вы владелец небольшого веб-сайта, nofollow все равно может быть полезен:
- Если вы представляете креативное агентство, вы можете использовать логотипы других компаний на своих страницах тематических исследований, что может запутать при поиске изображений.
- Если вы блогер, ваш раздел комментариев может содержать ссылки, которые вы не хотите поддерживать.

Даже если ваши страницы содержат только внутренние ссылки на другие области вашего веб-сайта, может быть полезно включить инструкцию nofollow, чтобы помочь поисковым системам понять важность и иерархию страниц вашего сайта. Например, каждая страница вашего сайта может содержать ссылку на вашу страницу «Контакты». Хотя эта страница очень важна, и вы бы хотели, чтобы Google проиндексировал ее, вы можете не захотеть, чтобы поисковая система придавала этой странице больший вес, чем другим частям вашего сайта, только потому, что многие другие ваши страницы ссылаются на нее.
Добавление инструкции nofollow работает точно так же, как добавление инструкции noindex, введенной ранее, и может быть выполнено путем изменения раздела HTML страницы:
Если вы хотите, чтобы только определенные ссылки на странице были помечены как nofollow, вы можете добавить атрибуты rel="nofollow" к HTML-тегам ссылок:
example. com/" rel="nofollow">пример ссылки
Владельцы веб-сайтов WordPress также могут использовать вышеупомянутые плагины All in One SEO или Yoast, чтобы помечать ссылки на странице как nofollow.
Инструкция запрета
Последняя из инструкций, которую мы обсуждаем в этом сообщении блога, — «запретить». Вы можете подумать, что это очень похоже на noindex, но хотя они очень похожи, между ними есть небольшие различия:
- Noindex : поисковые роботы просматривают страницу и любые содержащиеся на ней ссылки, но не добавляют страницу к результатам поиска.
- Nofollow : поисковые роботы добавят страницу в результаты, но будут игнорировать ссылки на странице для ранжирования.
- Disallow : Поисковые роботы вообще не будут просматривать страницу.
Как видите, запрет страницы означает, что вы говорите роботам поисковых систем не сканировать ее всю, что означает, что она вообще бесполезна для SEO. Disallow лучше всего использовать для страниц вашего сайта, которые совершенно не имеют отношения к большинству поисковых пользователей, таких как области входа клиентов или страницы «спасибо».
Disallow лучше всего использовать для страниц вашего сайта, которые совершенно не имеют отношения к большинству поисковых пользователей, таких как области входа клиентов или страницы «спасибо».
В отличие от noindex и nofollow, инструкция disallow не включается в HTML-код страницы или ответ HTTP, а вместо этого включается в отдельный файл с именем «robots.txt».
Файл robots.txt — это простой текстовый файл, который можно создать в любом базовом текстовом редакторе и который находится в корневом каталоге вашего сайта (www.example.com/robots.txt). Вашему сайту не нужен файл robots.txt, чтобы поисковые системы могли его сканировать, но он вам понадобится, если вы хотите использовать директиву disallow для блокировки доступа к определенным страницам. Для этого вы просто перечислите соответствующие части вашего сайта в файле robots.txt следующим образом:
Агент пользователя: * Запретить: /path/to/your/page.html
Владельцы веб-сайтов WordPress могут использовать подключаемый модуль All in One SEO для быстрого создания собственного файла robots.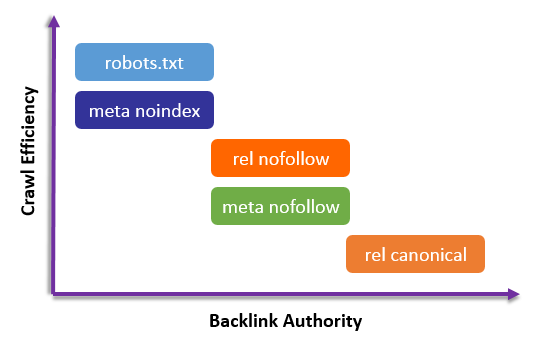 txt без необходимости прямого доступа к базовой файловой структуре системы управления контентом.
txt без необходимости прямого доступа к базовой файловой структуре системы управления контентом.
Как сканировать ваш сайт на наличие инструкций noindex, nofollow и disallow
Знаете ли вы наверняка, какие части вашего сайта помечены как noindex и nofollow или исключены из индексации правилом запрета? Если вы не уверены, вы можете провести инвентаризацию и пересмотреть свои прошлые решения.
Один из способов провести такую инвентаризацию — перейти на сайт www.drlinkcheck.com, ввести URL-адрес домашней страницы вашего сайта и нажать кнопку Начать проверку .
Основная функция Dr. Link Check — выявление неработающих ссылок, но служба также предоставляет подробную информацию о рабочих ссылках.
Отчет о ссылках без индекса
После завершения сканирования вашего сайта переключитесь на отчет Все ссылки и создайте фильтр, чтобы показывать только ссылки на страницы, помеченные как noindex:
- Дважды щелкните «Фильтр» в верхней части отчета, чтобы перевести панель фильтров в текстовый режим.
- Введите NoIndex = true в текстовое поле.
- Нажмите Введите , чтобы применить фильтр.

Теперь у вас есть пользовательский отчет, который показывает страницы, которые содержат тег noindex или имеют HTTP-заголовок noindex X-Robots-Tag.
Отчет о ссылках nofollow
Если вы хотите увидеть все ссылки, помеченные как nofollow, переключитесь на Отчет по всем ссылкам , нажмите Добавить… на панели фильтров и выберите Nofollow/Dofollow в раскрывающемся меню.
Отчет о запрещенных ссылках
По умолчанию сканер Dr. Link Check игнорирует все ссылки, запрещенные правилами, указанными в файле robots.txt сайта. Вы можете изменить это в настройках проекта:
- Откройте меню Account в правом верхнем углу и выберите Project Settings .
- Нажмите Расширенные настройки .
- Установите флажок рядом с Игнорировать robots.txt .
- Нажмите Обновить проект , чтобы сохранить настройки.

Теперь переключите отчет Обзор и нажмите кнопку Повторить проверку , чтобы начать новое сканирование с обновленными настройками.
После завершения сканирования откройте Все ссылки , нажмите Добавить… в разделе фильтра и выберите robots.txt со статусом , чтобы ограничить список ссылками, запрещенными файлом robots.txt вашего веб-сайта.
Подведение итогов
В то время как подавляющее большинство владельцев веб-сайтов гораздо больше заинтересованы в том, чтобы поисковые системы заметили страницы их веб-сайтов, инструкции noindex, nofollow и disallow являются мощными инструментами, помогающими поисковым роботам лучше понимать содержание сайта. , и указывают, какие разделы сайта следует скрыть от пользователей поисковых систем.
Предыдущее сообщениеНовое сообщение
- 12 января 2022 г.
- Последнее обновление: 22 января 2022 г.
- Дэвид
Noindex Nofollow с примерами кода
Noindex Nofollow с примерами кода
В этом уроке мы будем использовать программирование, чтобы попытаться решить головоломку Noindex Nofollow. Это демонстрирует приведенный ниже код.
Другой метод, который описан ниже с примерами кода, может быть использован для решения той же проблемы Noindex Nofollow.
На многочисленных примерах мы видели, как решить проблему Noindex Nofollow.
Что такое noindex не следует?
Вы будете использовать NoIndex при указании поисковой системе не сохранять вашу веб-страницу для отображения в результатах поиска, в то время как вы будете использовать NoFollow при указании сканерам поисковых систем не переходить по ссылкам на вашей странице.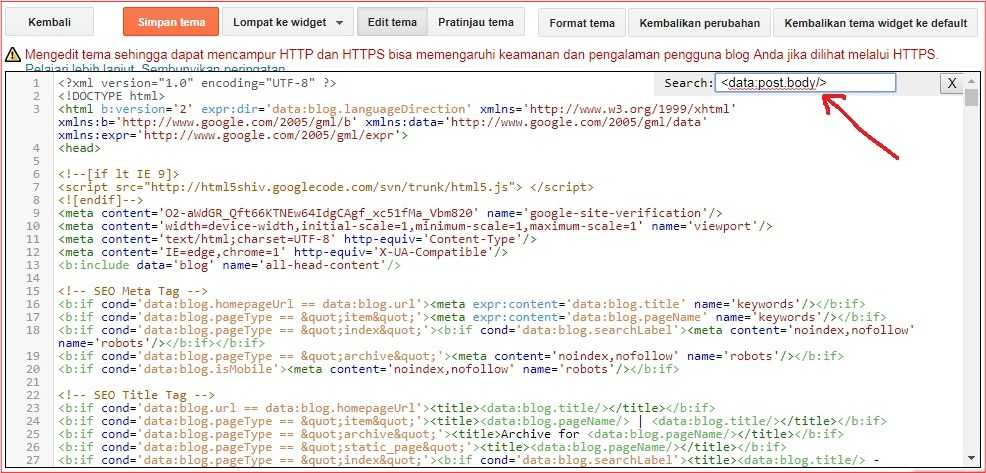
Что такое noindex nofollow в SEO?
В заголовке установлен тег X-Robots-Tag «noindex, nofollow», чтобы показать, что ваш веб-сайт может быть проиндексирован, но никогда не будет отображаться в результатах поиска Google.13 октября 2021 г.
Как установить noindex nofollow?
Теги Nofollow можно добавить в одно из двух мест:
страницы (для nofollow всех ссылок на этой странице): Код ссылки (для nofollow отдельная ссылка): пример страницы26 августа 2022 г.Как найти номер noindex nofollow?
Таким образом, способ проверки на наличие noindex состоит в том, чтобы выполнить оба действия: Проверить X-Robots-Tag, содержащий «noindex» или «none» в ответах HTTP (попробуйте curl -I https://www.example.com, чтобы увидеть как они выглядят) Получите HTML и просканируйте метатеги на наличие «noindex» или «none» в атрибуте содержимого.14 февраля 2017 г.
Как запретить Google сканировать мой сайт?
Вы можете предотвратить появление страницы или другого ресурса в поиске Google, включив в ответ HTTP метатег noindex или заголовок.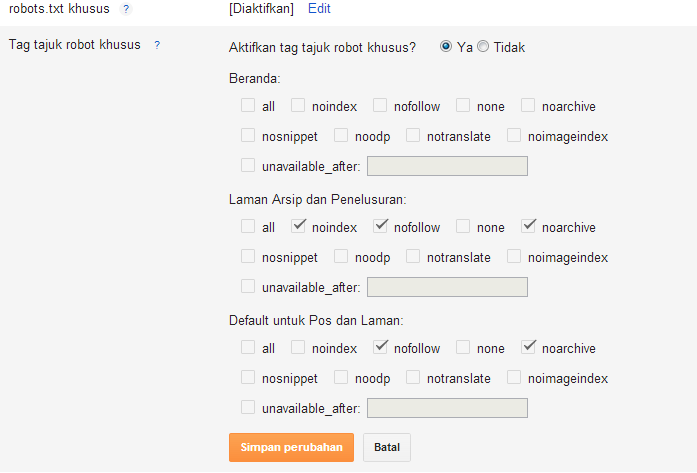 Когда робот Googlebot в следующий раз просканирует эту страницу и увидит тег или заголовок, Google полностью исключит эту страницу из результатов поиска Google, независимо от того, ссылаются ли на нее другие сайты.
Когда робот Googlebot в следующий раз просканирует эту страницу и увидит тег или заголовок, Google полностью исключит эту страницу из результатов поиска Google, независимо от того, ссылаются ли на нее другие сайты.
Как удалить noindex nofollow из WordPress?
Проблема №2: Удаление метатега noindex в WordPress
- Войдите в WordPress.
- Перейдите в «Настройки» → «Чтение».
- Прокрутите страницу вниз, где написано «Видимость для поисковых систем»
- Снимите флажок «Запретить поисковым системам индексировать этот сайт»
- Нажмите кнопку «Сохранить изменения» ниже.
Учитывает ли Google noindex?
В отличие от nofollow, который является подсказкой, атрибут noindex является директивой. Это означает, что Google выполнит просьбу веб-сайта не индексировать определенную страницу. Это единственный способ гарантировать, что веб-страница не попадет в результаты поиска Google.10 января 2022 г.
В чем разница между noindex и robots txt?
Итак, если вы хотите, чтобы содержимое не попадало в результаты поиска, используйте NOINDEX.