
Noindex или Nofollow? — IPCalc Blog
Ты впадаешь в легкий ступор при виде тегов Noindex и Nofollow? Ты все еще терзаешь себя вопросами, что такое Noindex и что такое и что такое Nofollow? Теперь тебе больше не нужно мучиться! Просто дочитай следующий пост до конца, и ты окончательно определишься в этой странной системе!
Я не буду мучить тебя сложными терминами и заковыристыми html кодами. Я просто расскажу о Noindex и Nofollow так, как вижу их сам. Единственное, что тебе придется вспомнить, так это язык гипертекстовой разметки HTML. Начнем с тега Noindex.
Noindex
Вообще тег Noindex был предложен Яндексом. И на фига он был предложен? Ну, Я решил выделиться и придумать нашу незабугорную альтернативу тегу Nofollow. И зачем ему это надо было? Просто специалисты из Я подумали, что раз у них самый популярный поисковик, то значит и теги должны быть свои, а не всякие там заморские.
[bs_notification type=”info” dismissible=”false”]Кто распознает тег Nofollow:
- Яндекс
- Рамблер
Зачем он нам нужен?
Вообще поисковые системы, при индексировании твоих web-страниц учитывают внешние ссылки, на этих станицах.
Например: чем больше ссылок ведет на твой сайт с других ресурсов, тем больше у тебя рейтинг в поисковиках. И следовательно, больше ссылок на другие ресурсы ведет с твоего сайта, тем больший вес ты передаешь этим сайтам, а значит меньше и вес твоего сайта.
Хочешь посадить свой сайт на диету? Ставь как можно больше внешних ссылок! – Но мы то здесь говорим, как набрать вес, а не похудеть, поэтому с этим надо поосторожнее. А то ведь так понаставишь кучу левых ссылок и под фильтры залетишь, что не есть хорошо.
Так вот, если тебе все-таки хочется поставить ссылки, но ты не хочешь терять вес, а значит не хочешь, что бы Яндекс индексировал эти ссылки ставь тег Nofollow.
Как это делается. Я хочу оставить ссылки на список новостных социальных сетей, но не хочу чтобы они индексировались. Что я делаю? Открываю визуальный редактор, переключаюсь на HTML и нахожу строчки, где у меня стоят ссылки на эти ресурсы.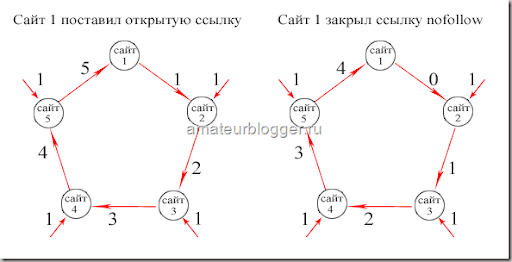 Нашел! Теперь чтобы запретить индексацию этих ссылок мы ставим тег Noindex. Да, забыл сказать, что тег этот должен закрываться.
Нашел! Теперь чтобы запретить индексацию этих ссылок мы ставим тег Noindex. Да, забыл сказать, что тег этот должен закрываться.
Т.е. вот что мы получили:
<noindex> <li><a href="http://zavoevanie.3dn.ru/news/2008-05-09-174″>Завоевание Америки</a> – неудобный интерфейс, но новости публикуются достаточно быстро</li> <li><a href="http://www.news2.ru/">News.ru</a> – очень строгие требования к статьям</li> <li><a href="http://www.newsgrad.com/">NewsGrad</a> – различные тематики, удобный интерфейс</li> <li><a href="http://livepress.ru/">LivePress</a> – есть выбор различных категорий, новость публикуется сразу на главной странице</li> </noindex>
Вот и все, теперь ссылки есть, но они не индексируются!
Мета тег Noindex
Так же есть мета тег Noindex. Отличие его от тега (контейнера) Noindex заключается в том, что он используется на ВСЮ страницу. И прописывается в <head></head> .
И прописывается в <head></head> .
Пример:
<html> <head> <meta content="noindex" /> <title>Интернет заработок и технологии</title> </head>
Вот так вот легко и просто запретить роботам индексировать Всю страницу, поэтому будь осторожен!
С Noindex закончили, переходим к Nofollow.
Nofollow
В принципе Nofollow выполняет те же функции, что и Noindex, но у него есть некоторые отличия. Это забугорный вариант Noindex. Прописывается в HTML код по другому.
Яндекс его не учитывает (также как Google не учитывает Noindex)
Nofollow – прописывается в теге <a></a> атрибутом rel=”Nofollow”.
Пример возьмем все тот же. Нам нужно прописать Nofollow в каждый тег <a>, где хотим запретить индексирование ссылки:
<li><a href=http://zavoevanie.3dn.ru/news/2008-05-09-174 rel="nofollow">Завоевание Америки</a> – неудобный интерфейс, но новости публикуются достаточно быстро</li> <li><a href=http://www.news2.ru/ rel="nofollow">News.ru</a> – очень строгие требования к статьям</li> <li><a href=http://www.newsgrad.com/ rel="nofollow">NewsGrad</a> – различные тематики, удобный интерфейс</li> <li><a href=http://livepress.ru/ rel="nofollow">LivePress</a> – есть выбор различных категорий, новость публикуется сразу на главной странице</li>
 news2.ru/ rel="nofollow">News.ru</a> – очень строгие требования к статьям</li>
<li><a href=http://www.newsgrad.com/ rel="nofollow">NewsGrad</a> – различные тематики, удобный интерфейс</li>
<li><a href=http://livepress.ru/ rel="nofollow">LivePress</a> – есть выбор различных категорий, новость публикуется сразу на главной странице</li>
news2.ru/ rel="nofollow">News.ru</a> – очень строгие требования к статьям</li>
<li><a href=http://www.newsgrad.com/ rel="nofollow">NewsGrad</a> – различные тематики, удобный интерфейс</li>
<li><a href=http://livepress.ru/ rel="nofollow">LivePress</a> – есть выбор различных категорий, новость публикуется сразу на главной странице</li>Вот и все!
Мета тег Nofollow
Также как и с Noindex есть мета тег Nofollow. Предназначение у него такое же, НО область действия опять же на ВСЮ страницу, поэтому с мета тегом Nofollow будь поаккуратнее.
Как он используется:
<html> <head> <meta content="Nofollow" /> <title>Интернет заработок и технологии</title> </head>
Вот мы и разобрались с Noindex и Nofollow. Да, чуть не забыл…
[bs_notification type=”info” dismissible=”false”]Эти теги Noindex и Nofollow можно использовать вместе! [/bs_notification]Вот пример:
<noindex> <li><a href=http://zavoevanie.
 3dn.ru/news/2008-05-09-174 rel="nofollow">Завоевание Америки</a> – неудобный интерфейс, но новости публикуются достаточно быстро</li>
<li><a href=http://www.news2.ru/ rel="nofollow">News.ru</a> – очень строгие требования к статьям</li>
<li><a href=http://www.newsgrad.com/ rel="nofollow">NewsGrad</a> – различные тематики, удобный интерфейс</li>
<li><a href=http://livepress.ru/ rel="nofollow">LivePress</a> – есть выбор различных категорий, новость публикуется сразу на главной странице</li>
</noindex>
3dn.ru/news/2008-05-09-174 rel="nofollow">Завоевание Америки</a> – неудобный интерфейс, но новости публикуются достаточно быстро</li>
<li><a href=http://www.news2.ru/ rel="nofollow">News.ru</a> – очень строгие требования к статьям</li>
<li><a href=http://www.newsgrad.com/ rel="nofollow">NewsGrad</a> – различные тематики, удобный интерфейс</li>
<li><a href=http://livepress.ru/ rel="nofollow">LivePress</a> – есть выбор различных категорий, новость публикуется сразу на главной странице</li>
</noindex>Урок 81. Техническая оптимизация: noindex и nofollow
Для тех, кто уже освоился с работой файла robots.txt, пришло время рассмотреть и несколько других действенных методов ограничения индексации конкретных страниц на вашем сайте. Это вспомогательные методы, которые также хорошо показывают себя при работе веб-мастеров. Речь идет об известном метатеге ROBOTS. Данный метатег может указываться в заголовке страницы. В зависимости от того, какие значения указываются для метатега в атрибуте CONTENT, будет меняться и принцип работы с конкретной страницей.
В зависимости от того, какие значения указываются для метатега в атрибуте CONTENT, будет меняться и принцип работы с конкретной страницей.
На данный момент существует несколько основных значений, которые помогут вам указать нужные действия для поисковых роботов. К ним относятся:
- Nofollow – указание не следовать по ссылкам
- Follow
- Noindex – ограничение индексации определенной станицы
- Index разрешение индексации определенной страницы.
Значения используются специально для того, чтобы уменьшить риск индексации тех страниц, которые вы не считаете готовыми. Потому повторим еще раз – если вы не уверены, что страница на вашем сайте полностью подходит для индексации, то лучше всего запретить её индексирование, используя значения приведенного в этом уроке метатега.
Особенности использования index, follow, noindex и nofollow
Среди веб-мастеров известно, что перечисленные в подзаголовке значения могут как представлять пользу для вашего сайта, так и реальную угрозу для него. За то, будет ли индексироваться страница, и как будет происходить ранжирование, отвечает соответствующий код.
За то, будет ли индексироваться страница, и как будет происходить ранжирование, отвечает соответствующий код.
Рассмотрим несколько наиболее важных вариантов прописывания кода для страницы.
Вариант 1.
<html>
<head>
<meta name=»robots» content=»noindex» >
<title> Эта страница не будет проиндексирована </title>
</head>
Использование такого кода показывает, что индексация страницы запрещена. Поисковой робот не будет учитывать её при оценке вашего сайта и последующем ранжировании.
Вариант 2.
<html>
<head>
<meta name=»robots» content=»nofollow» >
<title>С этой страницы не будет перехода по ссылкам</title>
</head>
Удобный вариант кода, который можно использовать в том случае, если вы хотите запретить переходы по ссылкам со страницы. В этом случае страница будет индексироваться, однако ссылки с неё не будут передавать ссылочный вес.
Помните, что вы всегда можете соединить разные варианты кодов. В этом случае в атрибуте «content» вам просто потребуется указать несколько значений через запятую. Стоит понимать, что на сайте различные ограничения на индексацию нередко вступают в конфликт. Так что если вы видите, что с индексацией конкретной страницы возникают проблемы, это станет для вас хорошим поводом проверить соответствие указанных в этом уроке кодов и значений с тем, что ранее было прописано в robots.txt. Такая проблема часто встречается на возрастных сайтах, которые за время своего существования успели оказаться в работе у различных компаний. Также проблемы могут встречаться и в том случае, если работа с сайтом изначально была построена плохо, и между различными программистами и оптимизатором не было налажено быстрой прямой связи. Проблемы могут возникать и в результате элементарных ошибок и простого недосмотра.
Для того, чтобы проверить текущее состояние кодов на вашем сайте, можно воспользоваться автоматизированными инструментами Яндекс.
В заключении рассказа о полезных кодах для сайта, нельзя не отметить одну интересную функцию. Она заключается в том, что вы можете ограничивать при помощи правильно прописанного кода индексацию как всей страницы, так и отдельных её элементов, которые вы считаете не самыми качественными. Применение тега поможет вам ограничить индексацию неуникального контента на странице. Также вы можете использовать и специальный атрибут rel ссылки со значением «nofollow». Это поможет вам исключить из индексирования определенную гиперссылку.
Зачем нужны все эти ухищрения? Начнем с контента. Нередко бывает так, что на сайте комбинируется уникальный контент и позаимствованный со сторонних ресурсов. К примеру, вы решили взять авторский текст и разнообразить им контент на своем сайте.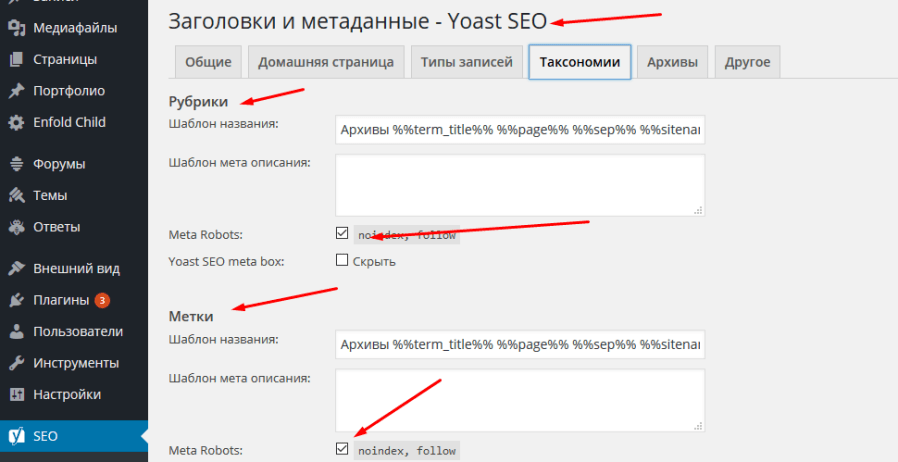 Для того, чтобы поисковая система не воспринимала размещение такого текста как плагиат, вы просто ограничиваете его индексирование.
Для того, чтобы поисковая система не воспринимала размещение такого текста как плагиат, вы просто ограничиваете его индексирование.
Похожим образом обстоят дела и со ссылками. Если вы видите, что на странице слишком много гиперссылок и подозреваете, что это может повлечь за собой санкции со стороны поисковой системы, вы также можете закрыть ссылку от индексации. Это позволяет регулировать индекс цитируемости ресурса и мягко уходить от санкций поисковых систем.
На этом этапе многим читателям может показаться, что мы рассказываем про настоящую панацею от санкций поисковых систем. Однако думать так – не совсем корректно. На самом деле поисковые системы также оценивают количество проставленных пропусков и участков, защищенных от индексации на вашем сайте. Если их слишком много – это может вызвать подозрение со стороны поисковика, а значит и различного рода санкции не заставят себя ждать. Помните, что, как и в других областях, связанных с продвижением сайтов, это очень важная мера.
Основные выводы
Существует немало способов закрыть страницу вашего сайта или отдельный её участок от индексации поисковыми роботами. Если у вас есть подозрение относительно качества страницы или отдельного контента на ней, смело используйте ограничители. Однако всегда следите за тем, чтобы ограничения не вступали в конфликт между собой. Также не стоит забывать и о том, что слишком большое количество ограничений на индексацию на конкретной странице может стать причиной наложения на сайт санкций. Действуйте умеренно и продуманно, и тогда вы получите реальную возможность управлять индексацией определенных разделов вашего сайта.
Урок 80. Техническая оптимизация: файл robots.txt
Оглавление
Урок 82. Техническая оптимизация: карта сайта и sitemap.xml
Различия между nofollow и noindex
Правила noindex и nofollow в ссылках могут улучшить или сломать страницу и то, как она индексируется. Большую часть времени они используются вместе, но иногда они рассматриваются как взаимозаменяемые или полностью неправильно используемые.
Итак, как правильно их использовать и когда?
Обе эти настройки являются атрибутами, которые можно добавить к ссылкам, чтобы помочь поисковым роботам. Итак, во-первых, их определения:
Что такое nofollow?
nofollow показывает, что ссылка не должна использоваться для передачи авторитета или чего-либо еще для ранжирования страницы. Если мы используем пример ссылок, являющихся голосованием или одобрением, то атрибут nofollow убирает это или дает нулевое значение.
Кодируется как внутри ссылки.
через GIPHY
Что такое noindex?
noindex — это атрибут, установленный на уровне страницы, а не ссылки. Он показывает, что страница, на которой он находится, не должна быть отправлена на индексацию. Несмотря на это, страницу по-прежнему можно сканировать и переходить по ссылкам с нее.
Кодируется в заголовке страницы как
Когда их использовать?
Есть много случаев, когда один или оба из них будут использоваться, но в основном они применяются к страницам, которые вы не хотите индексировать или передавать по авторитету. К ним относятся промежуточные сайты, страницы, которые вы хотите сделать более приватными, или альтернативные версии, чтобы избежать дублирования.
Есть нюансы в их использовании, и это часто приводит к неправильному использованию. Я рассмотрю их более подробно ниже.
Когда использовать nofollow
nofollow в большей степени связан со спамом и контролем количества просканированных ссылок на сайты и с них. Это помогает избежать потенциальных штрафов, контролируя количество ссылок между страницами.
Это никоим образом не остановит индексацию страниц, поэтому это не следует рассматривать как защиту от индексации.
Примеры использования
Если у вас есть партнерский веб-сайт, на который вы часто ссылаетесь, например, в нижнем колонтитуле, если вы разработали сайт, дочерняя компания или рекламный партнер. В этом случае вам не нужно будет учитывать каждый экземпляр, так как вы получите тысячи ссылок с одного домена на другой, что потенциально может вызвать проблемы со спамом.
В этом случае вам не нужно будет учитывать каждый экземпляр, так как вы получите тысячи ссылок с одного домена на другой, что потенциально может вызвать проблемы со спамом.
через GIPHY
Однако пользователь захочет видеть и использовать эти ссылки, поэтому этот атрибут nofollow позволяет пользователю делать это, не позволяя сканерам подсчитывать каждую ссылку.
Другим примером является управление путями, по которым идут поисковые роботы, хотя это работает только для определенных поисковых роботов в зависимости от того, как они соблюдают nofollow.
В примере с Google сканер также не будет переходить по ссылке на целевой URL-адрес, поэтому, если вы хотите, чтобы сканеры переходили по ссылкам в заголовке, а не по ссылкам на содержимое тела, вы можете добавить nofollow к ссылкам в теле в вопрос. Это узкоспециализированное использование, но оно может потребоваться на более крупных и сложных сайтах. В таблице ниже представлена информация о том, как поисковые роботы взаимодействуют с nofollow.
В таблице ниже представлена информация о том, как поисковые роботы взаимодействуют с nofollow.
Источник
Когда использовать noindex
noindex возможно проще, но не без сложностей. Если на странице есть тег noindex в заголовке, то страница не должна индексироваться поисковыми системами — например, на промежуточных и разрабатываемых сайтах.
Часто используется в сочетании с директивой disallow в файле robots.txt, чтобы убедиться, что эти страницы недоступны через индекс Google.
Примеры использования
Как уже упоминалось, чаще всего используется на промежуточных сайтах, чтобы убедиться, что эти временные URL-адреса не видны.
Это также может подпадать под дублирование, что является еще одним важным примером. Для архивов, версий для печати и других дубликатов может быть задано значение noindex, чтобы убедиться, что одна страница получает права доступа и видна поисковикам.
через GIPHY
Предостережения
Как и во всем, что связано с SEO, существует множество способов и методов. Ниже приведены несколько примеров предостережений и случаев, когда эти атрибуты могут быть не такими простыми, как кажутся.
Ниже приведены несколько примеров предостережений и случаев, когда эти атрибуты могут быть не такими простыми, как кажутся.
Другие поисковые роботы
Не все поисковые роботы одинаковы, и хотя Google или Bing могут выполнять определенные директивы, это не означает, что это сделают другие. Если вы действительно не хотите, чтобы что-то индексировалось, не делайте это общедоступным. Другие сканеры могут полностью игнорировать все эти директивы.
Альтернативы и Canonicals
Иметь тег noindex из-за альтернативных URL-адресов — это хорошо, но часто есть другие способы справиться с ними. Если у вас дублируется страница из-за языков, то необходим тег hreflang. Точно так же, если у вас есть альтернативы из-за немного отличающегося контента, то канонические теги могут наилучшим образом подойти к вашей ситуации.
Игнорирование директив
noindex иногда игнорируется, и вы можете увидеть такие вещи в Google Search Console, как «Проиндексировано, хотя и заблокировано тегом noindex». По сути, это означает, что, несмотря на тег noindex, Google по какой-то причине считает его достойным индексации. В этом случае вам нужно будет изучить альтернативы или, возможно, удалить тег noindex с этой страницы, чтобы сделать ее более простой.
По сути, это означает, что, несмотря на тег noindex, Google по какой-то причине считает его достойным индексации. В этом случае вам нужно будет изучить альтернативы или, возможно, удалить тег noindex с этой страницы, чтобы сделать ее более простой.
Если вы не уверены, не делайте предположений и делайте то, что считаете лучшим. Свяжитесь с нами и обсудите конкретные услуги SEO, адаптированные к вашим потребностям.
Поделиться этой публикацией
Гэри — наш технический специалист по поисковой оптимизации, который может похвастаться более чем 10-летним опытом работы в отрасли. Обладая глубокими знаниями о миграции сайтов и всех аспектах технического SEO, он является ценным активом для нашей команды. Гэри работал с V&A, Warburtons, NHS и Национальным парком Лейк-Дистрикт. У него также есть страсть к гитарам, будь то игра на них, их модификация или даже их сборка. Гэри появлялся в журналах Startups Magazine, Portsmouth News и Southampton.gov.uk.
Зачем мне SEO?
Гэри Хейнсворт
18 июля 2023
SEO блог
Оптимизация видео на YouTube: овладение SEO для максимальной видимости 2023
SEO-блог
Ежемесячный выпуск цифровых идей
Зарегистрируйтесь сейчас и получить нашу бесплатную ежемесячную электронную почту. Он наполнен нашими любимыми новостями из отрасли, SEO, PPC, социальных сетей и многого другого. И не забывайте — это бесплатно, так почему вы еще не зарегистрировались?
Он наполнен нашими любимыми новостями из отрасли, SEO, PPC, социальных сетей и многого другого. И не забывайте — это бесплатно, так почему вы еще не зарегистрировались?
Вопросы?
Позвоните нам по телефону 0330 353 0300, напишите по адресу [email protected] или заполните контактную форму.
Агентство цифрового маркетинга Хэмпшира
Merlin House 4. Метеоритный путь Lee-on-the-Solent, PO13 9FU, UKLancashire Digital Marketing Agency
Cotton Court Business Center Черч-стрит, Престон Lancashire, PR1 3BY, UKLondon Digital Marketing Agency
Albert House 256 — 260 Старая улица Лондон, EC1V 9DD, Великобритания В отличие от номеров 08, звонки на номера 03 стоят столько же, сколько и на географические номера стационарных телефонов (начиная с 01 и 02), даже с мобильного телефона. Они также обычно включаются в ваши инклюзивные минуты разговоров. Обратите внимание, что мы можем записывать некоторые звонки.
Полное руководство по мета-тегам noindex и nofollow
И рекламодатели, и владельцы веб-сайтов тратят много времени и денег, пытаясь повысить рейтинг своих страниц в результатах поиска Google. Для этого эти страницы должны быть проиндексированы и доступны для поиска. Тем не менее, есть определенные страницы, которые вы не можете индексировать, потому что они не имеют никакой ценности или существуют только для соблюдения правил веб-сайта.
Точно так же Google может переходить или не переходить по этим ссылкам на каждой странице. Они могут привести к некачественным или плохим веб-сайтам, что может повлиять на ваш рейтинг в поисковых системах.
Индексирование необходимого количества веб-страниц для повышения вашего авторитета в результатах поиска не всегда является разумным вариантом, а переход по ссылкам не всегда является хорошей идеей. Вот почему вы должны с осторожностью выбирать, какие страницы не индексировать или индексировать.
Чтобы увеличить трафик, мы по-прежнему хотим, чтобы как можно больше ваших страниц и статей было проиндексировано. Итак, какие страницы должны быть nofollow или noindexed? Давайте отправимся в приключение вместе.
Итак, какие страницы должны быть nofollow или noindexed? Давайте отправимся в приключение вместе.
Что такое страница без индекса?
Термин «без индекса» относится к веб-странице, которая не должна индексироваться поисковыми системами и, следовательно, не должна отображаться на страницах результатов поисковой системы.
Примеры распространенных сценариев отсутствия индексации включают (но не ограничиваются ими):
- Вы не хотите удалять некачественные или «слабые» страницы.
- Страницы, на которые вы не хотите, чтобы посетители попадали в Интернет, потому что они были созданы для других маркетинговых целей, таких как веб-версии маркетинга по электронной почте, целевые сайты социальных сетей.
- Любая веб-страница, которую вы решите скрыть от широкой аудитории, например страница, к которой могут получить доступ только те, у кого есть специальный URL-адрес.
- Форумные страницы, содержащие пользовательский контент.
Этот тег включается в раздел заголовка страницы HTML, чтобы информировать поисковые системы о том, что страницу не следует индексировать. Вставьте метатег robots в следующий раздел страницы:
Вставьте метатег robots в следующий раздел страницы:
. <заголовок> (…) (…)
Добавление атрибута «роботы» к метаимени означает, что этот метатег применим ко всем поисковым роботам. Если вы хотите, чтобы ваши страницы не индексировались определенным поисковым роботом, например Google, внесите следующие изменения в тег:
.Этот тег указывает боту Google игнорировать страницу в результатах поиска. Некоторые поисковые системы, такие как Bing и Ask.com, также показывают это в своих результатах поиска.
Но одновременно можно использовать несколько метатегов robots:
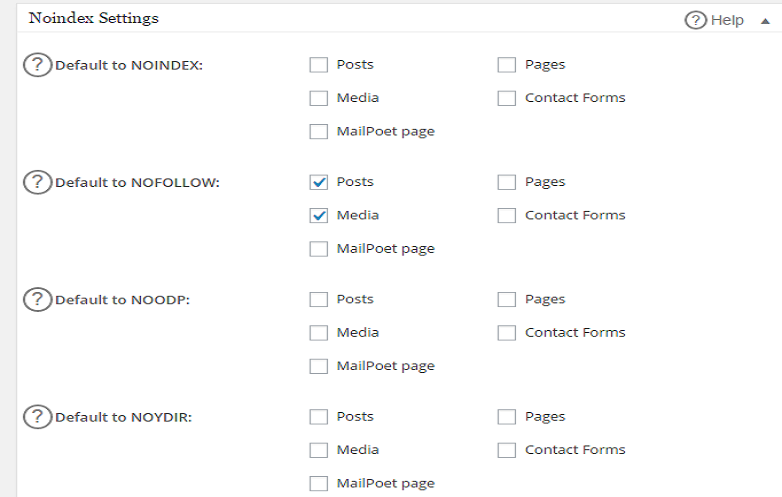
Что такое nofollow URL?
Термин «nofollow» означает, что поисковые роботы не переходят по ссылкам или URL-адресам на веб-сайте.
Вы можете добавить атрибуты nofollow следующими способами:
 com/page» rel=»nofollow»>якорный текст якорный текст
com/page» rel=»nofollow»>якорный текст якорный текстОба атрибута можно добавить в метатег robots.
Что такое метатег роботов?
Метатег robots — это строка кода в разделе заголовка веб-страницы. Он инструктирует поисковые системы о том, как сканировать и индексировать веб-сайт.
Если вы хотите узнать больше о метатеге robots, наше подробное руководство — отличное место для начала.
Итого:
В большинстве случаев метатег robots выглядит так:
метаимя=»роботы» content=»[атрибут1, атрибут2]»>По умолчанию атрибут 1 и атрибут 2 настроены на индексирование, отслеживание, указывая, что текущая страница может быть проиндексирована поисковыми системами и что ссылки на этой странице могут быть пройдены для сканирования страниц, на которые они ссылаются.
attribute1 и attribute2 могут быть noindex, nofollow или их смесью, например index, nofollow.
В чем разница между noindex и nofollow?
И noindex, и nofollow — это метатеги, которые можно прикрепить к исходному HTML-коду веб-страницы. Эти метатеги предназначены для прямого взаимодействия с ботами поисковых систем, которые сканируют веб-страницы.
Тег noindex указывает поисковым системам сканировать, но не индексировать и не отображать страницу в результатах поиска. Настройка по умолчанию для веб-страницы — «индекс». Вы можете изменить атрибут в метатегах робота, если хотите удалить или скрыть веб-сайт от поисковых систем. Это дает вам больше возможностей контролировать, какие страницы появляются в поисковой выдаче.
Атрибут nofollow сообщает поисковым системам, что страницы, на которые вы ссылаетесь, неактуальны. Хотя ссылки важны для SEO, только внешние ссылки с авторитетных и влиятельных веб-сайтов, а также внутренние ссылки могут помочь вашему сайту завоевать репутацию и повысить рейтинг. Рейтинг в поисковых системах практически не зависит от связей nofollow, которые не проходят через PageRank.
Почему вам могут понадобиться страницы без индекса?
Если ваши веб-сайты, записи в блогах и целевые страницы не индексируются и не отслеживаются, существует вероятность потери значительного объема трафика. Вот почему большинство владельцев веб-сайтов не хотят иметь страницы noindex или nofollow. Они постоянно проверяют, сканируют ли поисковые роботы и индексируют ли их веб-страницы.
Существует множество причин, по которым вы не хотите, чтобы эти сайты индексировались Google. Давайте рассмотрим две наиболее важные причины, по которым вам следует защищать свои сайты от индексаторов Google.
1. Избегайте дублирования содержимого.
Часть контента может существовать в нескольких копиях. Разрешить Google индексировать все эти сайты — пустая трата времени.
2. Обеспечьте безопасность секретного контента.
Некоторые страницы нельзя свободно открывать и открывать на страницах поиска Google, если они содержат конфиденциальный контент и продукты. Важно скрыть их от взглядов Google.
Важно скрыть их от взглядов Google.
Почему вам могут понадобиться ссылки nofollow?
Страницы Noindex и URL-адреса nofollow также полезны в некоторых ситуациях. Потому что это может привлечь трафик с других реферальных сайтов. Помимо этого, вы получите следующие преимущества от URL-адресов nofollow:
1. Защитите свой блог от спамеров
Спамеры часто используют страницу комментариев, чтобы оставлять ссылки на свои сайты. Хотя ссылки nofollow не могут устранить спам, они будут препятствовать тому, чтобы спамеры нацеливались на вашу сеть.
Каковы основные мотивы спамеров оставлять ссылки в разделе комментариев вашего блога? Они будут использовать клики ваших клиентов, чтобы увеличить трафик и получить более высокие баллы в Google. При использовании ссылок nofollow их ссылки больше не учитываются при измерении PageRank.
2. Увеличьте количество посетителей вашего веб-сайта
Имейте в виду, что ссылки полезны не только для поисковой оптимизации.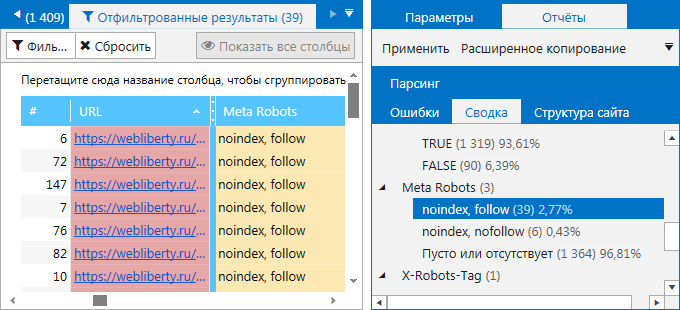 Ссылки nofollow увеличат посещаемость вашего веб-сайта и помогут оптимизировать ваш бизнес, узнаваемость бренда или услуги. Хорошая и качественная ссылка служит центром доступа посетителей к вашему контенту. Если посетитель посчитает ваш контент полезным, он или она поделится им в своем блоге. В результате можно увидеть, что nofollow-ссылки неявно относятся к ссылкам, на которые вы переходите.
Ссылки nofollow увеличат посещаемость вашего веб-сайта и помогут оптимизировать ваш бизнес, узнаваемость бренда или услуги. Хорошая и качественная ссылка служит центром доступа посетителей к вашему контенту. Если посетитель посчитает ваш контент полезным, он или она поделится им в своем блоге. В результате можно увидеть, что nofollow-ссылки неявно относятся к ссылкам, на которые вы переходите.
3. Следите за своими ссылками.
Ссылочный вес — это фактор ранжирования, используемый поисковыми системами для описания прочности ссылок между веб-сайтами. Поскольку мощная страница может делегировать власть ссылкам на своем содержании, вы должны убедиться, что только важные ссылки получают полномочия страницы.
Страницы, которые должны быть помечены как неиндексируемые
Малоценный контент или контент блога, который вы не хотите, чтобы пользователи показывали в результатах поиска, должны быть неиндексированы. Тег noindex сохраняет веб-страницу доступной для вашей аудитории на вашем веб-сайте, но не влияет на авторитетность вашего сайта, и посетители не смогут найти ее с помощью поискового запроса.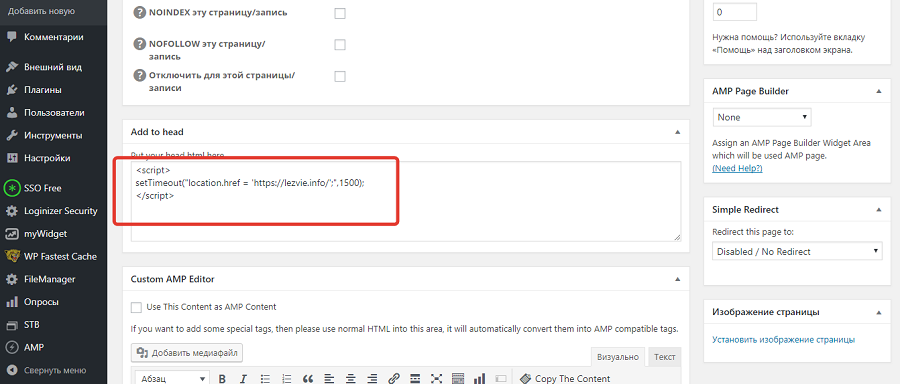
1. Страница авторских архивов в блоге одного автора
Если вы единственный человек, который вносит свой вклад в ваш блог, ваши авторские страницы почти наверняка идентичны домашней странице вашего блога. Это не имеет отношения к Google и может быть распознано как дублированный контент. Вы можете полностью отключить авторский архив, чтобы избежать повторяющегося контента.
Вы не будете индексировать его, если хотите оставить его на своей домашней странице вне результатов поиска, если только по какой-то причине.
2. Стандартные страницы продуктов WooCommerce
Плагин или веб-разработчик могут создать пользовательскую форму публикации, которую вы не хотите индексировать. В результате мы не индексируем стандартные страницы продуктов WooCommerce и вместо этого используем свои собственные. Тип сообщения о продукте также не индексируется.
В том же ключе мы видели решения для электронной коммерции, которые предоставляют размеры и вес в виде настраиваемой почтовой формы. Эти страницы рассматриваются как имеющие некачественный контент. Вы увидите, что эти страницы бесполезны как для посетителей, так и для Google, но их также можно исключить из страниц результатов поиска.
Эти страницы рассматриваются как имеющие некачественный контент. Вы увидите, что эти страницы бесполезны как для посетителей, так и для Google, но их также можно исключить из страниц результатов поиска.
3. Страница благодарности
Настоящая цель страницы — выразить благодарность вашему клиенту, читателю бюллетеня или первому комментатору. Как правило, это небольшие страницы с контентом с опциями дополнительных продаж и обмена в социальных сетях. но эта страница мало полезна для тех, кто ищет факты в Google. Как следствие, некоторые страницы не отображаются в результатах поиска.
Пользователи увидят страницу благодарности только после того, как сделают то, что вы от них хотите. Если посетители могут найти эту страницу через поиск Google, вы не только бесплатно раздаете самый полезный контент, но и рискуете потерять всю аналитику своего сайта.
4. Страницы для администратора и входа в систему
Поскольку администратор и авторизованные пользователи обычно входят в систему через прямые URL-адреса, эти страницы автоматически не индексируются. Исключения могут быть на разных страницах входа, которые поддерживают сообщества, такие как Mediafire и Dropbox.
Исключения могут быть на разных страницах входа, которые поддерживают сообщества, такие как Mediafire и Dropbox.
5. Результаты внутреннего поиска вашего собственного веб-сайта
Когда посетители увидят эту страницу в поисковой выдаче, это испортит их впечатления от поиска. Вместо получения информации они проведут новый поиск. Он может отображаться как виджет поиска Blogger, виджет поиска WordPress или панель поиска продуктов WooCommerce.
Однако ссылки на странице результатов поиска также очень важны, и вы хотите, чтобы Google обратил на них внимание. Для настройки результатов внутреннего поиска необходимо использовать все URL-адреса, а мета-настройка robots должна быть:
.6. Страницы, посвященные профилям сообщества
75% страниц веб-сайта Moz были деиндексированы? Бритни Мюллер ранее обнаружила, что страницы профилей сообщества, содержащие неактивные или спам-аккаунты с плохими обратными ссылками, составляют более 56 процентов проиндексированных страниц. На веб-сайте наблюдалось увеличение трафика, когда они согласились не индексировать URL-адреса профиля группы ниже 200 баллов. Пример демонстрирует важность исключения нерелевантных профилей со страниц результатов поисковой системы.
На веб-сайте наблюдалось увеличение трафика, когда они согласились не индексировать URL-адреса профиля группы ниже 200 баллов. Пример демонстрирует важность исключения нерелевантных профилей со страниц результатов поисковой системы.
7. Страницы с вложениями
Когда вы добавляете файл в WordPress, создается новая вкладка вложения. Google, как и ожидалось, индексирует и отображает эти веб-сайты, которые в основном пусты, но служат иллюстрацией и несколькими словами информации.
Страницы, для которых следует установить статус nofollow
Нет необходимости переходить по всем ссылкам на этих страницах со всеми перечисленными выше примерами. Вы не ожидаете, что они появятся в результатах поиска, но хотите, чтобы Google переходил по ссылкам на странице. Когда можно добавить атрибут nofollow в метатег robots?
Если вы не настроили метатег робота для nofollow страницы, на этой странице не будут переходить по ссылкам. Чтобы различать ссылки и ненадежное содержимое, Google использует nofollow, включая «или», «позже», «оплачено», «реклама». Вероятно, в обычном списке есть несколько сайтов, которые вы хотели бы отслеживать в Google.
Вероятно, в обычном списке есть несколько сайтов, которые вы хотели бы отслеживать в Google.
1. Активные ссылки в комментариях блога
Комментарии в блогах часто содержат активные ссылки, которые бесполезны и могут вести на вредоносные веб-сайты. Вы должны сбалансировать контроль с важными веб-сайтами при размещении ссылок на свой блог. Обратите внимание, что было бы плохо, если бы ваш веб-сайт был связан с ненадежными ссылками или веб-сайтами и индексировался по всем ссылкам вашего контента.
После того, как эта ссылка настроена на «nofollow», без неуместных комментариев, вы можете помочь продвинуть тему. Спамеры больше не будут утруждать себя ссылками в твитах, не давая SEO-ценностей.
2. Рекламные внутренние ссылки
Обычно вы монетизируете свой блог, размещая платную рекламу на его страницах. Вы можете включать логотипы или ссылки на веб-сайты спонсоров и получать компенсацию за реферальный трафик от вашей аудитории. Тем не менее, вы должны сообщить Google, что материалы оплачены и что вы не несете ответственности за любые веб-сайты, к которым подключены. Более того, эти ссылки не влияют на ваш SEO или рейтинг.
Более того, эти ссылки не влияют на ваш SEO или рейтинг.
В этом случае ссылки nofollow, как правило, являются разумным выбором. Предоставляя пользователю полезные URL-адреса и передавая трафик, вы также зарабатываете на этих страницах. Вы можете посмотреть пример ниже.
Twitter3. Подозрительные и манипулятивные ссылки
Google предпочитает веб-сайты с простым навигация и понятные URL-адреса. Это означает, что он сосредоточится на предоставлении полезной информации своим ботам, когда они перемещаются по сети.
Если содержание ссылки не имеет отношения к вашему или поступает из сомнительных источников, вы можете добавить к ней метатег nofollow.
Вы можете сделать это, добавив соответствующие атрибуты rel к вашей ссылке. Например, ссылка на рекламу будет выглядеть так:
пример ссылки.Как добавить метатег noindex и/или nofollow в тему Blogger?
Первым шагом при добавлении тега noindex и/или nofollow является копирование необходимого тега.
Вы можете использовать следующий тег для содержимого noindex:
Вы можете использовать следующий тег для URL-адреса nofollow:
Вы можете использовать следующий тег как для noindex, так и для nofollow:
 И вставьте тег в новую строку в разделе…….
И вставьте тег в новую строку в разделе……. Шаг 4: Теперь сохраните тему Blogger.
Как следствие, поисковая система больше не будет иметь ваш сайт на страницах. Изменив файл robots.txt, вы можете запретить сканирование нескольких страниц.
Что такое robots.txt и как его получить?
Robots.txt — это текстовый файл, который веб-мастера могут использовать для информирования роботов поисковых систем о том, как они хотят сканировать свои страницы и по каким ссылкам переходить.
Файлы robots.txt в основном сообщают программному обеспечению веб-сканирования, разрешено ли ему сканировать определенные разделы веб-сайта.
Вы можете использовать «nofollow» одновременно для разных веб-страниц, просмотрев файл robots.txt своего сайта на панели управления Blogger.
В первую очередь проверьте, есть ли на сайте файл robots.txt. Чтобы узнать это, перейдите на веб-сайт и найдите «robots.txt».
Вот как это должно выглядеть: www. bloggerspice.com/robots.txt
bloggerspice.com/robots.txt
Чтобы добавить коды robots.txt в тему Blogger, выполните следующие действия:
Шаг 1: Войдите в свою учетная запись блоггера
Шаг 2: В панели инструментов Blogger в меню слева нажмите «Настройки», а в разделе «Сканеры и индексирование» нажмите кнопку рядом с «Включить пользовательский файл robots.txt»
Шаг 3: Вы можете добавить любой пользовательский код robots.txt, и для вашего удобства мы добавили несколько кодов robots.txt, которые могут вам понадобиться:
Приведенный ниже код позволит проиндексировать все:
Агент пользователя: * Запретить: или Пользовательский агент: * Позволять: /Код ниже будет запрещать индексирование:
Агент пользователя: * Запретить: /Код ниже будет деиндексировать определенную папку:
Агент пользователя: * Запретить: /папка/Следующий код не позволит роботу Googlebot индексировать папку, за исключением одного конкретного файла внутри нее:
Пользовательский агент: * Запретить: /папка/ Разрешить: /folder1/myfile. html
html В сценариях robots.txt Google и Bing позволяют пользователям использовать подстановочные знаки.
Использование следующего кода для предотвращения доступа к URL-адресам со специальными символами, такими как вопросительный знак:
Агент пользователя: * Запретить: /В robots.txt Google также поддерживает использование noindex.
Используя следующий код для noindex из robots.txt:
Агент пользователя: Googlebot Запретить: /page-uno/ Без индекса: /page-uno/Шаг 4: После добавления кода желания нажмите кнопку « СОХРАНИТЬ ».
Заключение
Вопреки распространенному мнению, теги noindex и nofollow не влияют на видимость вашего сайта в результатах поиска. Задайте себе два вопроса, прежде чем начать беспокоиться о том, как индексировать свои страницы: хотите ли вы, чтобы эта страница отображалась в результатах поиска Google? Должны ли поисковые системы иметь возможность перейти по любой из ссылок на этой странице?
Ответ на первый вопрос «нет» для страниц «спасибо» или «вход», например.