
Noindex\ SEO словарь веб студии Муравейник
Автор статьи
Андрей Буйлов
Подробнее об авторе
Noindex — это либо тег Яндекса, который запрещает индексирование какого-либо куска текста, либо метатег страницы, который учитывается поисковой системой для запрета на индексацию всей страницы.
Чтобы в Яндексе запретить индексацию определенной части документа, ее обрамляют постановкой <noindex> перед и </ noindex> после этого куска текста или кода. Таким образом поисковой системе рекомендуется не проводить индексацию данной части.
К этой процедуре прибегают в случае, если важна валидация кода. То есть, когда проходитесь по коду валидатором, который «говорит», что на сайте столько-то страниц, в том числе noindex, — валидатор не знает такого, потому что он придуман Яндексом исключительно для своих нужд.
Раньше noindex можно было действительно закрывать куски текста, и Яндекс его не учитывал никогда. Некоторое время этот метод использовался для ухода от фильтра Баден-Баден, который штрафует как раз за тексты там, где они не очень к месту. И когда мы встретили этот фильтр, то, конечно, в первую очередь на документах или сайтах, которые попали под этот фильтр, стали просто обрамлять тексты noindex. И действительно, они первое время выходили из-под этого фильтра.
Но впоследствии эта махинация была Яндексом раскрыта: текст никуда не ушел, он остался тем же спамом, но не передавался для индексации. Соответственно Яндекс продолжил на эти страницы накладывать фильтр, и тексты пришлось удалять. Поэтому эта схема до сих пор работает, но уже не так однозначно как ранее и не для всех задач.
Второй вариант noindex — это метатег, то есть использование в robots или в метатеге с названием поисковой системы, мы можем запретить индексацию всего документа. Например, мы по какой-то причине не хотим прописывать запрет на индексацию в robots.txt. Это какой-то вид страниц, которых у нас на сайте сотни или тысячи. И тогда нам удобнее попросить программиста просто дописывать robots noindex для того, чтобы определенный тип страниц не индексировался.
Например, у вас есть страницы фильтров в каталоге или страницы для печати, которые нам для индексации не нужны, это будут дубли той же самой исходной страницы. И тогда программист прописывает, для каких страниц выводится метатег, и они не будут индексироваться.
Аналогичным образом можно закрыть куски текста не для всех поисковых систем, а для одной, например, указав в нейме Яндекс. И тогда для Гугла эта страница будет индексироваться, а для Яндекса не будет.
Что такое Noindex? — webfocus.
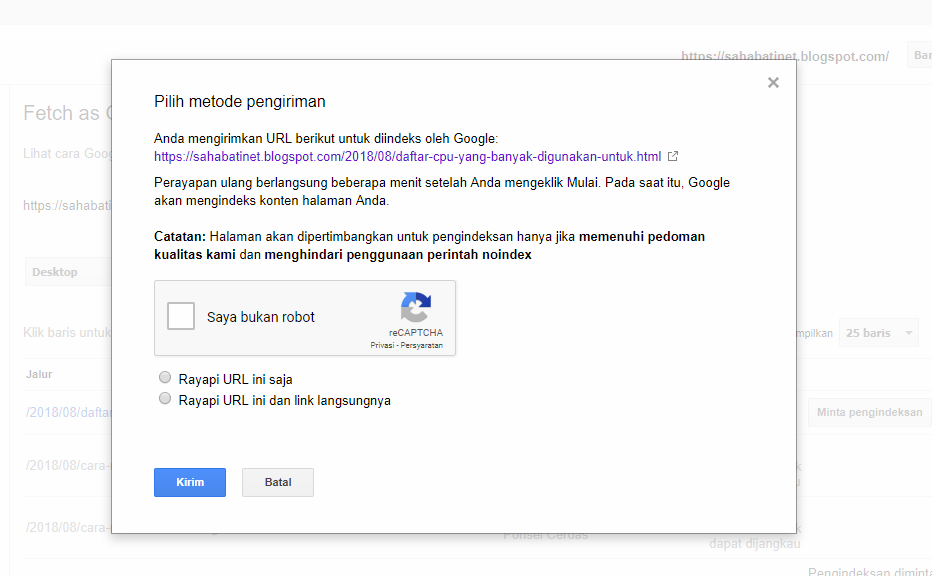 by
by
Noindex
Noindex
Noindex – особый тег, не дающий поисковым системам индексировать какую-то часть текста на странице интернет-ресурса. Указанная потребность может возникнуть, когда хочется скрыть от поисковика несущественную для индексирования информацию, из-за которой вся площадка может попасть под санкции. Все сведения между соответствующими открывающим и закрывающим тегами скрываются от поисковых систем.
Другие термины из категории «Техническое SEO»
- Robots.txt
- Кодовая таблица
- URL
- Зеркало сайта
- FTP
Введите имя
Введите телефон
Введите e-mail
О проекте
Дизайн
ПродвижениеВеб-разработка
Опишите вашу задачу
Нажимая кнопку, я соглашаюсь
на обработку персональных данных
впечатления
Отзывы клиентов
Все отзывы Непременно ознакомьтесь с тем, что пишут о нашей компании клиенты. Мнение тех, кто платит свои деньги, стоит
дорого! Рады, что выбрали верный вектор развития. Работали и с директорами заводов, и с ИП. Найдем
продуктивный язык и с читателем.
Мнение тех, кто платит свои деньги, стоит
дорого! Рады, что выбрали верный вектор развития. Работали и с директорами заводов, и с ИП. Найдем
продуктивный язык и с читателем.
О.Д. Тетерина
Говорим спасибо, настоящим специалистам Web Focus, которые восстановили работу по контекстной рекламе.
Как никогда, оперативность и ответственность в подходе дала столь быстрые результаты – работа с
продвижением возобновлена, сайту оказывают полную техническую поддержку, поток входящих клиентов
остается
на уровне, несмотря на короткие сроки сотрудничества. Ценовая политика и уровень обслуживания
соответствуют заявленному уровню компании. Говорим спасибо, настоящим специалистам Web Focus, которые восстановили работу по контекстной рекламе.
Как никогда, оперативность и ответственность в подходе дала столь быстрые результаты – работа с
продвижением возобновлена, сайту оказывают полную техническую поддержку, поток входящих клиентов
остается
на уровне, несмотря на короткие сроки сотрудничества.
01.02.2021
С. А. Зазерская
Выражаю признательность компании «Веб Фокус» за плодотворное сотрудничество при создании совершенно новой стратегии продвижения. Наши опасения не только в снижении позиций сайта, но и количестве входящий обращений оказались напрасными. Молодые и креативные сотрудники новый подход в продвижении наших услуг, и не остановились на продвижении с помощью контекстной рекламы и SEO, предложив использовать наружную рекламу…
12.06.2020
“АЛК++Компании”
«АЛК++Компани» выражает благодарность, принимавшей участие в разработке нашего сайта. Отдельно стоит
отметить помощь программиста Владимира, за творческий подход к решению нетривиальных задач и строгое
соблюдение сроков проекта. Он смог разработать новый модуль, который позволяет удобно производить поиск
необходимых планировок квартир для наших покупателей. Мы готовы рекомендовать Web Focus…
Он смог разработать новый модуль, который позволяет удобно производить поиск
необходимых планировок квартир для наших покупателей. Мы готовы рекомендовать Web Focus…
25.02.2021
Н.Е. Кривонос
Рекомендуем компанию «Веб Фокус» как компетентного, надежного и отзывчивого делового партнера и надеемся на дальнейшее сотрудничество.Техническое обслуживание и рекламу доверили «Веб Фокус»! Профессионализм, точное выполнение договорных обязательств и адекватная стоимость. Дня нас предложили индивидуальную стратегию продвижения нашего сайта. В частности, составили семантическое ядро, настроили расширенные….
01.03.2021
Noindex check — бесплатные инструменты SEO
Получили ли вы электронное письмо от Google Search Console (GSC) с текстом «Проиндексировано, но заблокировано robots. txt», тогда вот небольшая помощь о том, что происходит и как это исправить .
txt», тогда вот небольшая помощь о том, что происходит и как это исправить .
Что такое «Проиндексировано, но заблокировано robots.txt»:
Получили ли вы электронное письмо от Google Search Console (GSC), в котором говорится: «Проиндексировано, но заблокировано robots.txt», тогда вот небольшая помощь о том, что происходит и как это исправить.
Вот скриншот уведомления:
Это сообщение означает, что Google проиндексировал ваши URL-адреса, но обнаружил указание игнорировать их в вашем файле robots.txt.
Это означает, что они не будут отображаться в результатах, и это может повлиять на их способность ранжироваться во всех SERP (страницах результатов поисковой системы). В этой части вы узнаете, как решить эту проблему и можно ли просто игнорировать ее. Ниже показано, что может показать отчет об индексировании Google Search Console с указанным количеством URL. Возможно, показанные фрагменты неоптимальны, например:
Что такое файл robots.
 txt?
txt?Файл robots.txt находится в каталоге вашего веб-сайта и является вторым файлом, который боты читают при сканировании вашего веб-сайта. Он предлагает некоторые инструкции для ботов, таких как бот Google, относительно того, какие файлы они должны и не должны просматривать.
Почему я получаю это уведомление?
Сообщение «Проиндексировано, но заблокировано robots.txt» может отображаться по нескольким причинам.
Ниже приведены наиболее распространенные:
Преднамеренный
Это, конечно, не проблема, если файл robots.txt содержит директивы от вас или разработчика для блокировки страниц, дублирования или ненужных страниц / страниц категорий.
Неверный формат URL-адреса
Эта проблема также может возникнуть из-за URL-адреса, который на самом деле не является страницей. Например, вам нужно знать, к какому разрешению приводится приведенный ниже URL. https://www.siteguru.co/?s=seo+academy Если это страница, содержащая жизненно важную информацию, которую вы действительно хотите, чтобы ваши пользователи видели, необходимо изменить URL-адрес. Это возможно в системах управления контентом (CMS), таких как WordPress, где вы можете изменить ярлык страницы. Нет необходимости исправлять эту проблему, если страница не важна и URL-адрес является поисковым запросом из вашего блога. Вы также можете удалить страницу.
Это возможно в системах управления контентом (CMS), таких как WordPress, где вы можете изменить ярлык страницы. Нет необходимости исправлять эту проблему, если страница не важна и URL-адрес является поисковым запросом из вашего блога. Вы также можете удалить страницу.
Страницы, которые необходимо проиндексировать
Есть довольно много причин, по которым страницы, которые должны быть проиндексированы, не индексируются. Вот почему:Правило в файле robots.txt
В вашем файле robots.txt может быть директива, запрещающая индексацию страниц, которые действительно должны быть проиндексированы, например, категорий и тегов. Помните, что категории и теги — это настоящие URL-адреса на вашем веб-сайте.
Вы указываете роботу Googlebot цепочку переадресации
Боты, такие как Googlebot, просматривают все ссылки, которые им попадаются, и делают все возможное, чтобы прочитать их для индексации. Тем не менее, если вы настроите многогранную, длинную, глубокую переадресацию или если страница будет просто недоступна, гуглбот перестанет искать.
Правильно реализована каноническая ссылка
Канонический тег размещается в заголовке HTML и сообщает роботу Googlebot, какая страница является предпочтительной и канонической в случае дублирования контента. Бонус! Каждая страница должна иметь канонический тег. Например, если у вас есть страница, переведенная на испанский язык, вы сами сделаете каноническим URL-адрес на испанском языке и захотите вернуть страницу к канонической версии на английском языке по умолчанию.
Страницы, которые не должны быть проиндексированы
Опять же, существует довольно много причин, по которым страницы, которые не должны быть проиндексированы, индексируются. Но почему?
Безиндексная директива
Noindex означает, что веб-страница не должна быть проиндексирована. Страница с этой директивой будет просканирована, но не проиндексирована. В файле robots.txt убедитесь, что:
- Существует не более одного блока «агент пользователя».
- Строка «запретить» не сразу следует за строкой «агент пользователя».

- Невидимые символы Unicode удалены. Вы можете сделать это, запустив файл robots.txt в текстовом редакторе, который преобразует кодировки.

Страницы, на которые ведут ссылки с других веб-сайтов
Страницы, на которые есть ссылки с других сайтов, могут быть проиндексированы, даже если они запрещены в robots.txt. Когда это происходит, в результатах поиска отображаются только якорный текст и URL-адрес. Вот скриншот того, как эти URL-адреса отображаются в поисковой выдаче. источник изображения Веб-мастера StackExchange Эта проблема (блокировка robots.txt) может быть решена следующим образом:
- Пароль для защиты файлов на вашем сервере.
- Удаление страниц из robots.txt или добавление следующего метатега для их блокировки:
Старые URL-адреса
Предположим, вы создали новый веб-сайт или даже новый контент и включили правило «noindex» в robots. txt для предотвращения индексации. Или недавно подписались на GSC, есть способы исправить проблему, заблокированную robots.txt:
txt для предотвращения индексации. Или недавно подписались на GSC, есть способы исправить проблему, заблокированную robots.txt:
- Дайте Google время удалить старые URL из индекса. Обычно Google удаляет URL-адреса, если они продолжают возвращать ошибки 404. Не рекомендуется использовать плагины для перенаправления ошибок 404, поскольку они могут вызвать проблемы, которые могут привести к тому, что GSC отправит вам уведомление «заблокировано robots.txt».
- 301 перенаправить старые URL-адреса на текущие
Проверьте, есть ли у вас файл robots.txt
GSC также может отправлять вам эти уведомления, даже если у вас нет файла robots.txt. CMS, например WordPress, может уже создать файл robots.txt, плагины также могут создавать файлы robots.txt. Перезапись виртуальных файлов robots.txt вашими собственными файлами robots.txt. Это может привести к проблемам с GSC.
Как решить эту проблему?
Использование директивы, разрешающей роботам поисковых систем сканировать ваш веб-сайт, — это единственный способ, с помощью которого боты определят, какие URL индексировать, а какие игнорировать.
Вот директива, позволяющая всем ботам сканировать ваш сайт:
Агент пользователя: * Запретить: /
Это означает «ничего не запрещать».
Вот шаги, чтобы определить, какие страницы вы хотите запретить:
1. Вы можете либо просмотреть все страницы, либо экспортировать список URL-адресов из любого инструмента SEO-аудита, который может предоставить все страницы вашего сайта, в нашем случае, мы использовали аудит SiteGuru:
2. Определите URL-адреса, которые вы не хотите индексировать в поисковой выдаче, и добавьте их в файл robots.txt:
User-agent: *
Disallow: /page-you-want-to-disallow/
Disallow: / more-page-you-want-to-disallow/
Disallow: /another-page-you-want-to-disallow/
аудит, и вы должны увидеть «без индекса» рядом со страницами:
4. Если вы все еще получаете уведомление, проверьте, какие страницы могли ссылаться на запрещенные страницы, и удалите ссылку. Консоль поиска Google не предоставляет вам, где все страницы связаны с неиндексированным URL-адресом, но вы можете использовать инструмент SEO, такой как SiteGuru, чтобы определить, какие URL-адреса ссылаются на неиндексированную страницу:
Что запретит robots.
 txt?
txt?- Запретить сканирование всего веб-сайта. Имейте в виду, что в некоторых случаях URL-адреса с веб-сайта могут быть проиндексированы, даже если они не были просканированы. Обратите внимание, что это не соответствует различным поисковым роботам AdsBot, имена которых должны быть указаны явно.
- Запретите сканирование каталога и его содержимого, указав после имени каталога косую черту. Помните, что вы не должны использовать robots.txt для блокировки доступа к частному контенту — вместо этого используйте надлежащую аутентификацию. Это связано с тем, что любой может просматривать файл robots.txt, а запрещенные им URL-адреса могут по-прежнему индексироваться без сканирования.
- Запретить сканирование всего сайта, но показывать рекламу AdSense на этих страницах, запретить все поисковые роботы, кроме Mediapartners-Google. Эта реализация защищает ваши страницы от результатов поиска, но поисковый робот Mediapartners-Google по-прежнему может анализировать их, чтобы решить, какую рекламу показывать посетителям вашего сайта.
User-agent: *
Disallow: /tags/
В приведенном выше примере запрещены все страницы, следующие по пути /tags/:
https://www.example.com/tags/coffee
 Эта реализация защищает ваши страницы от результатов поиска, но поисковый робот Mediapartners-Google по-прежнему может анализировать их, чтобы решить, какую рекламу показывать посетителям вашего сайта.
Эта реализация защищает ваши страницы от результатов поиска, но поисковый робот Mediapartners-Google по-прежнему может анализировать их, чтобы решить, какую рекламу показывать посетителям вашего сайта.➤ Что такое Noindex на веб-странице
Tabla de Contenido
Что это такое, важность и примеры
Что такое noindex на веб-странице
Noindex — это значение, используемое в метатеге robots HTML код URL для предотвращения индексации страницы поисковыми системами, такими как Google, Bing или Yahoo.
Google понимает тег noindex как директиву. Поэтому, если он ее найдет, он не покажет эту страницу пользователям на своих страницах результатов.
Аналогом noindex является «index», который явно разрешает индексирование, хотя его использование не обязательно, поскольку поисковые системы интерпретируют отсутствие тега как зеленый свет для индексации содержимого.
Почему важна директива noindex
Тег noindex позволяет решить, следует ли включать конкретный URL в индекс поисковой системы или нет.
Таким образом, noindex — отличный ресурс, который позволяет нам контролировать индексацию каждой отдельной страницы с минимальными усилиями,
Noindex — отличный ресурс, который позволяет нам без особых усилий контролировать индексацию каждой отдельной страницы.
Именно по этой причине эта директива является одним из любимых инструментов оптимизации всех оптимизаторов.
Как реализовать тег noindex
Существует два способа реализации тега noindex: с помощью метатега в HTML страницы или с помощью заголовка ответа HTTP.
Оба варианта дают одинаковый результат, поэтому выберите тот, который лучше всего подходит для вашего веб-сайта и типа вашего контента.
Тег
Чтобы большинство поисковых систем не индексировали страницу вашего сайта, вы можете включить следующий метатег в раздел
страницы:Вот пример синтаксиса тега noindex:
Кроме того, мы также можем запретить индексацию страницы для определенного бота.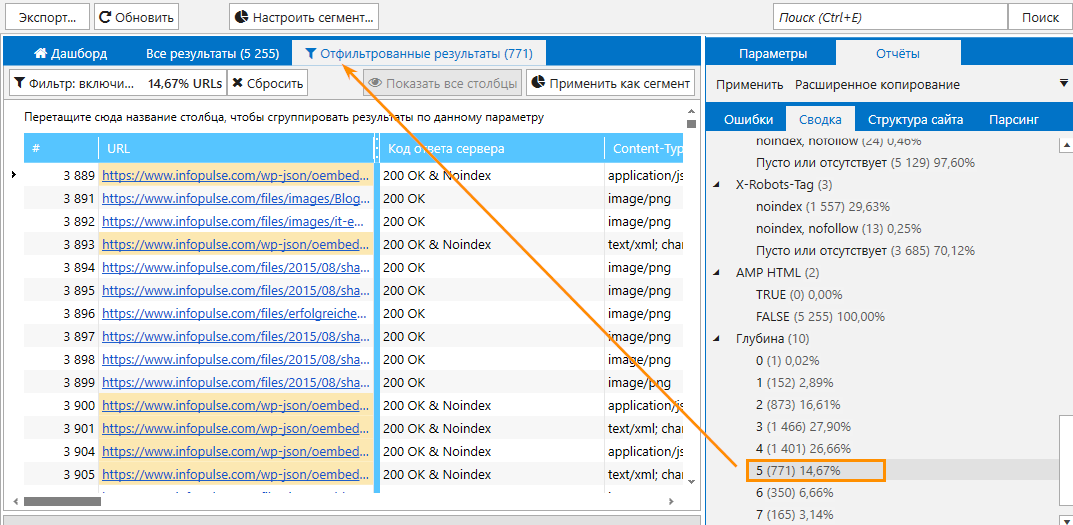
Вот несколько примеров:
Заголовок ответа HTTP
Вместо использования метатега вы также можете включить заголовок X-Robots-Tag в ответ HTTP вашей страницы со значениями noindex или none. Этот заголовок ответа полезен для ресурсов, отличных от HTML, таких как PDF-файлы, изображения и видео.
Вот пример того, как будет выглядеть ответ HTTP с заголовком X-Robots-Tag
HTTP/1.1 200 OK Content-Type: text/html X-Robots-Tag: noindex Página no indexable Esta página no debería сер indexada пор лос моторес де búsqueda.
Когда использовать тег Noindex
Общая рекомендация по применению этой директивы очень проста:
- Используйте метатег noindex роботов для содержимого, не представляющего особой ценности для пользователя.
Это может быть очень субъективно, поэтому вот несколько примеров контента или страниц, которые вы не должны индексировать:
- Страницы авторов
- Результаты внутреннего поиска
- Страницы с ограниченным доступом
- Определенные типы (настраиваемых) записей, созданных плагинами
- Некоторые страницы категорий или тегов
Это укажет поисковым системам не индексировать страницу. Вы также можете использовать тег canonical, чтобы сообщить поисковым системам, какая основная версия страницы содержит дублированный контент.
Вы также можете использовать тег canonical, чтобы сообщить поисковым системам, какая основная версия страницы содержит дублированный контент.
В зависимости от типа веб-сайта или страницы, которой вы управляете, вы должны применять тот или иной критерий, но всегда, чтобы быть уверенным, спросите себя, имеет ли рассматриваемая страница ценность для пользователя.
Noindex vs Disallow
Очень важно подчеркнуть, что тег noindex на странице не мешает поисковым роботам полностью сканировать этот URL.
Он только не позволяет им отображать его пользователям в результатах поиска.
Следовательно,
Если мы хотим предотвратить сканирование и индексацию страницы поисковой системой, мы должны прибегнуть к использованию файла robots.txt.
В частности, директива «Запретить».
Таким образом мы предотвращаем сканирование страницы и ее последующую индексацию (хотя это не всегда достигается).
В любом случае, если вы хотите обеспечить выполнение обеих директив, вы можете совместить запрет с noindex в robots. txt, добавив обе директивы в файл robots.txt:
txt, добавив обе директивы в файл robots.txt:
Disallow: /example-page- 1/
Noindex: /example-page-1/
ПРЕДУПРЕЖДЕНИЕ : Noindex (страница) + Disallow: нельзя сочетать с noindex на странице, потому что страница заблокирована и поэтому поисковые системы не будут ее сканировать, чтобы не знать чтобы оставить страницу вне индекса.
В заключение:
Метатег «noindex» — очень полезный ресурс для контроля дублированного контента, похожего или неполноценного контента. То есть весь контент малоценен для пользователя и, следовательно, может создать для нас проблемы с позиционированием.
Правильное использование этой директивы вместе с другими метатегами nofollow, follow и robots.txt жизненно важно для оптимизации индексации и возможности сканирования нашего веб-сайта. Знание того, как и когда использовать этот тег noindex, необходимо для облегчения работы поисковых систем.
Важно: Google всегда придерживается директивы noindex, а тег index считается только рекомендацией.
Ссылки и рекомендуемое чтение:
- Блокировать поиск Индексация с «noindex» | Центр поиска Google | Документация |. (с. ф.). Разработчики Google. https://developers.google.com/search/docs/crawling-indexing/block-indexing
- Спецификации метатегов роботов | Центр поиска Google | Документация |. (с. ф.-б). Разработчики Google. https://developers.google.com/search/docs/crawling-indexing/robots-meta-tag
Часто задаваемые вопросы
Что такое мета-роботы noindex?
Мета-noindex веб-страницы для роботов является одним из основных атрибутов, позволяющих контролировать ее появление в результатах поиска. Если вы хотите научиться использовать его на своем веб-сайте, избежать ошибок и облегчить работу Google, вам необходимо полностью освоить эту концепцию.
Какой эффект имеет тег noindex?
Тег noindex указывает поисковым системам не включать страницу в результаты поиска.