
Что такое машинное обучение? – Корпоративное руководство для начинающих специалистов по машинному обучению — AWS
Что такое машинное обучение?
Машинное обучение – это наука о разработке алгоритмов и статистических моделей, которые компьютерные системы используют для выполнения задач без явных инструкций, полагаясь вместо этого на шаблоны и логические выводы. Компьютерные системы используют алгоритмы машинного обучения для обработки больших объемов статистических данных и выявления шаблонов данных. Таким образом, системы могут более точно прогнозировать результаты на основе заданного набора входных данных. Например, специалисты по работе с данными могут обучить медицинское приложение диагностировать рак по рентгеновским изображениям, сохраняя миллионы отсканированных изображений и соответствующие диагнозы.
Почему машинное обучение так важно?
Машинное обучение помогает компаниям стимулировать рост, открывать новые источники дохода и решать сложные проблемы. Данные являются важной движущей силой принятия бизнес-решений, но традиционно компании использовали данные из различных источников, таких как отзывы клиентов, сотрудников и финансов. Исследования в области машинного обучения автоматизируют и оптимизируют этот процесс. Используя ПО, которое анализирует очень большие объемы данных на высокой скорости, компании могут быстрее достигать результатов.
Данные являются важной движущей силой принятия бизнес-решений, но традиционно компании использовали данные из различных источников, таких как отзывы клиентов, сотрудников и финансов. Исследования в области машинного обучения автоматизируют и оптимизируют этот процесс. Используя ПО, которое анализирует очень большие объемы данных на высокой скорости, компании могут быстрее достигать результатов.
Где используется машинное обучение?
Ключевые области использования машинного обучения см. ниже.
Производство
Машинное обучение может поддерживать профилактическое обслуживание, контроль качества и инновационные исследования в производственном секторе. Технология машинного обучения также помогает компаниям улучшать логистические решения, включая активы, цепочки поставок и управление запасами. Например, крупномасштабная компания-производитель 3M использует AWS Machine Learning для инновации шлифовальной бумаги. Алгоритмы машинного обучения позволяют исследователям 3M анализировать, как незначительные изменения формы, размера и ориентации улучшают абразивность и долговечность. Эти предложения влияют на производственный процесс.
Эти предложения влияют на производственный процесс.
Здравоохранение и медико‑биологические разработки
Распространение носимых датчиков и устройств породило значительный объем данных о здоровье. Программы машинного обучения могут анализировать эту информацию и помогать врачам в диагностике и лечении в режиме реального времени. Исследователи машинного обучения разрабатывают решения, которые обнаруживают раковые опухоли и диагностируют глазные заболевания, что значительно влияет на показатели здоровья человека. Например, компания Cambia Health Solutions использовала машинное обучение AWS для поддержки стартапов в области здравоохранения с целью автоматизации и персонализации лечения беременных женщин.
Финансовые услуги
Проекты финансового машинного обучения улучшают аналитику рисков и регулирование. Технология машинного обучения может позволить инвесторам выявлять новые возможности путем анализа движений фондового рынка, оценки хедж-фондов или калибровки финансовых портфелей. Кроме того, это может помочь выявить кредитных клиентов с высоким уровнем риска и смягчить признаки мошенничества. Лидирующий поставщик финансового ПО Intuit использует подсистему AWS Machine Learning, Amazon Textract,чтобы обеспечить более персонализированное управление финансами и помочь конечным пользователям улучшить финансовое положение.
Кроме того, это может помочь выявить кредитных клиентов с высоким уровнем риска и смягчить признаки мошенничества. Лидирующий поставщик финансового ПО Intuit использует подсистему AWS Machine Learning, Amazon Textract,чтобы обеспечить более персонализированное управление финансами и помочь конечным пользователям улучшить финансовое положение.
Розничная торговля
В розничной торговле машинное обучение может использоваться для улучшения обслуживания клиентов, управления запасами, дополнительных продаж и многоканального маркетинга. Например, Amazon Fulfillment (AFT) удалось сократить расходы на инфраструктуру на 40 %, используя модель машинного обучения для выявления неуместных запасов. Это позволяет выполнять обещание Amazon в отношении предоставления клиентам простого доступа к товару и своевременной доставки такого товара, несмотря на обработку миллионов поставок ежегодно.
Мультимедиа и развлечения
Компании в индустрии развлечений обращаются к машинному обучению, чтобы лучше понимать целевую аудиторию и предоставлять иммерсивный персонализированный контент по запросу. Алгоритмы машинного обучения используются для разработки трейлеров и другой рекламы, предоставления потребителям персонализированных рекомендаций по контенту и даже оптимизации производства.
Алгоритмы машинного обучения используются для разработки трейлеров и другой рекламы, предоставления потребителям персонализированных рекомендаций по контенту и даже оптимизации производства.
Например, Disney использует глубокое обучение AWS для архивирования медиатеки. Инструменты машинного обучения AWS автоматически маркируют, описывают и сортируют медиаконтент, позволяя писателям и аниматорам Disney быстро искать персонажей Disney и знакомиться с ними.
Как работает машинное обучение?
Центральной идеей машинного обучения является существующая математическая связь между любой комбинацией входных и выходных данных. Модель машинного обучения не имеет сведений об этой взаимосвязи заранее, но может сгенерировать их, если будет предоставлено достаточное количество наборов данных. Это означает, что каждый алгоритм машинного обучения строится вокруг модифицируемой математической функции. Описание основополагающего принципа см. ниже.
- Мы «обучаем» алгоритм, давая ему следующие комбинации ввода-вывода [input / output (i,o)]: (2,10), (5,19) и (9,31).

- Алгоритм вычисляет соотношение между входом и выходом следующим образом: o = 3 × i + 4.
- Затем мы задаем ввод 7 и просим предсказать результат. Алгоритм может автоматически определить выход как 25.

Хотя это базовое понимание, машинное обучение фокусируется на том принципе, что все сложные точки данных могут быть математически связаны компьютерными системами, если у них достаточно данных и вычислительной мощности для обработки этих данных. Следовательно, точность выходных данных прямо пропорциональна величине входных данных.
Какие типы алгоритмов машинного обучения существуют?
Алгоритмы можно разделить на четыре стиля обучения в зависимости от ожидаемого результата и типа ввода.
- Машинное обучение с учителем
- Машинное обучение без учителя
- Машинное обучение с частичным привлечением учителя
- Машинное обучение с подкреплением
1.
 Машинное обучение с учителем
Машинное обучение с учителемСпециалисты по работе с данными предоставляют алгоритмам помеченные и определенные обучающие данные для оценки корреляций. Демонстрационные данные определяют как входные данные, так и выходные данные алгоритма. Например, изображения рукописных цифр аннотируются, чтобы указать, какому числу они соответствуют. Система обучения с учителем может распознавать кластеры пикселей и фигур, связанных с каждым числом, при наличии достаточного количества примеров. Со временем система распознает написанные от руки цифры, стабильно различая числа 9 и 4 или 6 и 8.
Сильные стороны машинного обучения с учителем – простота и легкость структуры. Такая система полезна при прогнозировании возможного ограниченного набора результатов, разделении данных на категории или объединении результатов двух других алгоритмов машинного обучения. Однако маркировка миллионов немаркированных наборов данных является сложной задачей. Давайте рассмотрим это подробнее.
Что такое маркировка данных?
Маркировка данных – это процесс категоризации входных данных с соответствующими им определенными выходными значениями. Помеченные обучающие данные необходимы для обучения с учителем. Например, миллионы изображений яблок и бананов должны быть помечены словами «яблоко» или «банан». Затем приложения машинного обучения могли бы использовать эти обучающие данные, чтобы угадывать название фрукта по изображению фрукта. Однако маркировка миллионов новых данных может быть трудоемкой и сложной задачей. Сервисы коллективной работы, такие как Amazon Mechanical Turk, могут в некоторой степени преодолеть это ограничение алгоритмов обучения с учителем. Эти сервисы обеспечивают доступ к большому количеству доступным рабочим ресурсам по всему миру, что упрощает сбор данных.
Помеченные обучающие данные необходимы для обучения с учителем. Например, миллионы изображений яблок и бананов должны быть помечены словами «яблоко» или «банан». Затем приложения машинного обучения могли бы использовать эти обучающие данные, чтобы угадывать название фрукта по изображению фрукта. Однако маркировка миллионов новых данных может быть трудоемкой и сложной задачей. Сервисы коллективной работы, такие как Amazon Mechanical Turk, могут в некоторой степени преодолеть это ограничение алгоритмов обучения с учителем. Эти сервисы обеспечивают доступ к большому количеству доступным рабочим ресурсам по всему миру, что упрощает сбор данных.
2. Машинное обучение без учителя
Алгоритмы обучения без учителя обучаются на неразмеченных данных. Такие алгоритмы просматривают новые данные, пытаясь установить значимые связи между входными и заранее определенными выходными данными. Они могут выявлять закономерности и классифицировать данные. Например, алгоритмы без учителя могут группировать новостные статьи с разных новостных веб-сайтов в общие категории, такие как спорт, криминал и т. д. Они могут использовать обработку естественного языка для понимания смысла и эмоций в статье. В розничной торговле обучение без учителя поможет найти закономерности в покупках клиентов и предоставить результаты анализа данных, такие как: покупатель, скорее всего, купит хлеб, если также купит масло.
д. Они могут использовать обработку естественного языка для понимания смысла и эмоций в статье. В розничной торговле обучение без учителя поможет найти закономерности в покупках клиентов и предоставить результаты анализа данных, такие как: покупатель, скорее всего, купит хлеб, если также купит масло.
Обучение без учителя полезно для распознавания образов, обнаружения аномалий и автоматического группирования данных по категориям. Поскольку обучающие данные не требуют маркировки, настройка проста. Эти алгоритмы также можно использовать для автоматической очистки и обработки данных для дальнейшего моделирования. Ограничение этого метода состоит в том, что он не может дать точных прогнозов. Кроме того, он не может самостоятельно выделять конкретные типы выходных данных.
3. Машинное обучение с частичным привлечением учителя
Как следует из названия, этот метод сочетает в себе обучение с учителем и без него. Этот метод основан на использовании небольшого количества размеченных данных и большого количества неразмеченных данных для обучения систем. Сначала размеченные данные используются для частичного обучения алгоритма машинного обучения. После этого частично обученный алгоритм сам размечает неразмеченные данные. Этот процесс называется псевдомаркировкой. Затем модель переобучается на результирующем наборе данных без явного программирования.
Сначала размеченные данные используются для частичного обучения алгоритма машинного обучения. После этого частично обученный алгоритм сам размечает неразмеченные данные. Этот процесс называется псевдомаркировкой. Затем модель переобучается на результирующем наборе данных без явного программирования.
Преимущество этого метода в том, что вам не требуются большие объемы размеченных данных. Это удобно при работе с такими данными, как длинные документы, чтение и маркировка которых отнимает слишком много времени у человека.
4. Обучение с подкреплением
Обучение с подкреплением – это метод, в котором значения вознаграждения привязаны к различным шагам, которые должен пройти алгоритм. Таким образом, цель модели – накопить как можно больше призовых баллов и в конечном итоге достичь конечной цели. Большая часть практического применения обучения с подкреплением за последнее десятилетие была связана с видеоиграми. Передовые алгоритмы обучения с подкреплением добились впечатляющих результатов в классических и современных играх, часто значительно превосходя ручные аналоги.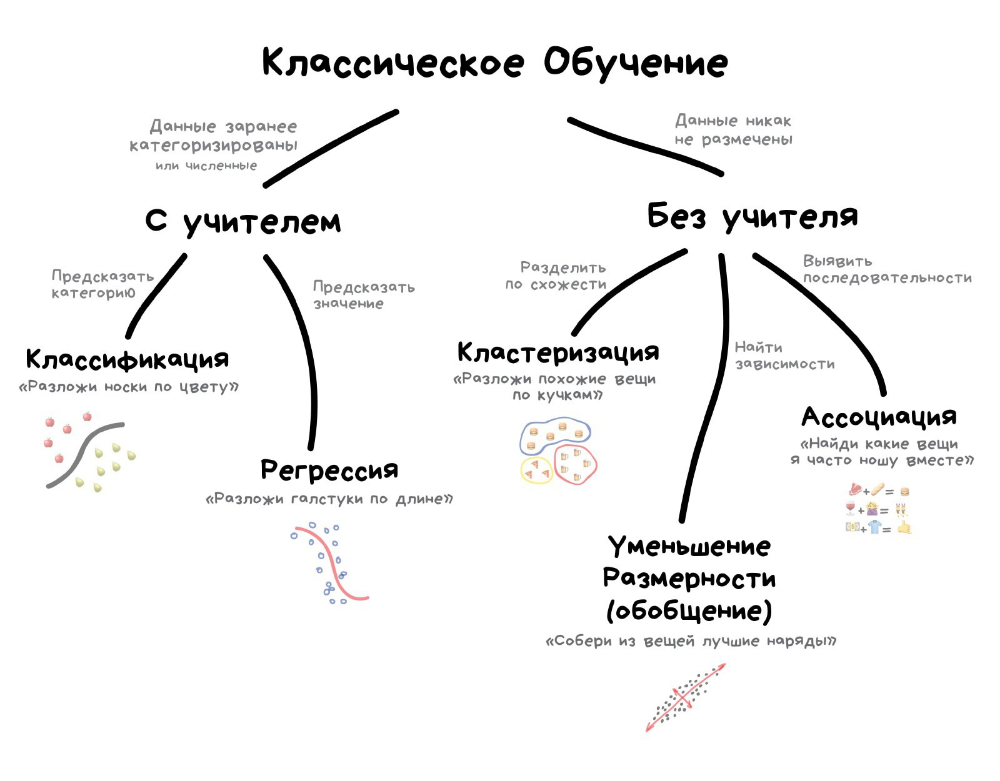
Хотя этот метод лучше всего работает в неопределенных и сложных средах данных, он редко применяется в бизнес-контексте. Это неэффективно для четко определенных задач, и предвзятость разработчиков может повлиять на результаты. Поскольку специалист по работе с данными разрабатывает награды, они могут влиять на результаты.
Являются ли модели машинного обучения детерминированными?
Если выход системы предсказуем, то говорят, что она детерминирована. Большинство программных приложений предсказуемо реагируют на действия пользователя, поэтому можно сказать: что «если пользователь делает то-то, он получает то-то». Однако алгоритмы машинного обучения учатся на основе наблюдения и опыта. Поэтому они носят вероятностный характер. Утверждение теперь меняется на следующее: «если пользователь делает это, есть вероятность X %, что произойдет это».
В машинном обучении детерминизм – это стратегия, используемая при применении методов обучения, описанных выше. Любой из методов обучения (с учителем, без учителя и т. д.) можно сделать детерминированным в зависимости от желаемых бизнес-результатов. Вопрос исследования, поиск данных, структура и решения по хранению определяют, будет ли принята детерминированная или недетерминированная стратегия.
д.) можно сделать детерминированным в зависимости от желаемых бизнес-результатов. Вопрос исследования, поиск данных, структура и решения по хранению определяют, будет ли принята детерминированная или недетерминированная стратегия.
Детерминированный и вероятностный подходы
Детерминированный подход фокусируется на точности и объеме собранных данных, поэтому эффективность важнее неопределенности. С другой стороны, недетерминированный (или вероятностный) процесс предназначен для управления фактором случайности. Встроенные инструменты интегрированы в алгоритмы машинного обучения, чтобы помочь количественно определить, идентифицировать и измерить неопределенность во время обучения и наблюдения.
Что такое глубокое обучение?
Глубокое обучение – это метод машинного обучения, который моделируется мозгом человека. Алгоритмы глубокого обучения анализируют данные с логической структурой, аналогичной той, которую используют люди. Глубокое обучение использует интеллектуальные системы, называемые искусственными нейронными сетями, для обработки информации слоями. Данные проходят от входного слоя через несколько «глубоких» скрытых слоев нейронной сети, прежде чем попасть на выходной слой. Дополнительные скрытые слои поддерживают обучение, которое намного эффективнее, чем стандартные модели машинного обучения.
Данные проходят от входного слоя через несколько «глубоких» скрытых слоев нейронной сети, прежде чем попасть на выходной слой. Дополнительные скрытые слои поддерживают обучение, которое намного эффективнее, чем стандартные модели машинного обучения.
Что такое искусственная нейронная сеть?
Слои глубокого обучения представляют собой узлы искусственной нейронной сети (ИНС), которые работают как нейроны человеческого мозга. Узлы могут представлять собой комбинацию аппаратного и программного обеспечения. Каждый уровень в алгоритме глубокого обучения состоит из узлов ИНС. Каждый узел или искусственный нейрон соединяется с другим и имеет связанный с ним номер значения и пороговый номер. Узел отправляет номер своего значения в качестве входных данных узлу следующего слоя при активации. Он активируется, только если его выход превышает указанное пороговое значение. В противном случае никакие данные не передаются.
Что такое машинное зрение?
Компьютерное зрение – это реальное применение глубокого обучения. Точно так же, как искусственный интеллект позволяет компьютерам думать, компьютерное зрение позволяет им видеть, наблюдать и реагировать. Самоуправляемые автомобили используют компьютерное зрение, чтобы «читать» дорожные знаки. Камера автомобиля делает снимок знака. Это фото отправляется алгоритму глубокого обучения в машине. Первый скрытый слой обнаруживает края, следующий различает цвета, а третий слой идентифицирует детали алфавита на знаке. Алгоритм предсказывает, что на знаке написано СТОП, и автомобиль ответит срабатыванием тормозного механизма.
Точно так же, как искусственный интеллект позволяет компьютерам думать, компьютерное зрение позволяет им видеть, наблюдать и реагировать. Самоуправляемые автомобили используют компьютерное зрение, чтобы «читать» дорожные знаки. Камера автомобиля делает снимок знака. Это фото отправляется алгоритму глубокого обучения в машине. Первый скрытый слой обнаруживает края, следующий различает цвета, а третий слой идентифицирует детали алфавита на знаке. Алгоритм предсказывает, что на знаке написано СТОП, и автомобиль ответит срабатыванием тормозного механизма.
Машинное обучение и глубокое обучение – это одно и то же?
Глубокое обучение – это часть машинного обучения. Алгоритмы глубокого обучения можно рассматривать как непростую и математически сложную эволюцию алгоритмов машинного обучения.
Машинное обучение и искусственный интеллект – это одно и то же?
Короткий ответ: нет. Хотя термины «машинное обучение» и «искусственный интеллект» (ИИ) могут использоваться взаимозаменяемо, это не одно и то же. Искусственный интеллект – это общий термин для различных стратегий и методов, используемых для того, чтобы сделать машины более похожими на людей. ИИ включает в себя все, от умных помощников, таких как Alexa, до роботов-пылесосов и беспилотных автомобилей. Машинное обучение – одна из многих других ветвей искусственного интеллекта. Хотя машинное обучение – это ИИ, все действия ИИ нельзя назвать машинным обучением.
Искусственный интеллект – это общий термин для различных стратегий и методов, используемых для того, чтобы сделать машины более похожими на людей. ИИ включает в себя все, от умных помощников, таких как Alexa, до роботов-пылесосов и беспилотных автомобилей. Машинное обучение – одна из многих других ветвей искусственного интеллекта. Хотя машинное обучение – это ИИ, все действия ИИ нельзя назвать машинным обучением.
Машинное обучение и наука о данных – это одно и то же?
Нет, машинное обучение и наука о данных – это не одно и то же. Наука о данных – это область исследования, в которой используется научный подход для извлечения смысла и понимания из данных. Специалисты по работе с данными используют ряд инструментов для анализа данных, и машинное обучение является одним из таких инструментов. Специалисты по работе с данными понимают общую картину данных, таких как бизнес-модель, предметная область и сбор данных, в то время как машинное обучение — это вычислительный процесс, который работает только с необработанными данными.
Каковы преимущества и недостатки машинного обучения?
Мы предлагаем вашему вниманию возможности и ограничения машинного обучения.
Преимущества моделей машинного обучения:
- определение тенденций и закономерностей данных, которые может упустить человек;
- работа без вмешательства человека после настройки; например, машинное обучение в ПО для кибербезопасности может постоянно отслеживать и выявлять нарушения в сетевом трафике без участия администратора;
- результаты могут стать более точными с течением времени;
- обработка различных форматов данных в динамических, больших объемов и сложных сред данных.
Недостатки моделей машинного обучения:
- исходная подготовка является дорогостоящим и трудоемким процессом; трудоемкая реализация в отсутствии достаточного объема данных;
- ресурсоемкий процесс, требующий больших первоначальных инвестиций, если оборудование устанавливается собственными силами;
- без помощи специалиста может быть сложно правильно интерпретировать результаты и устранить неопределенность.

Как Amazon может содействовать машинному обучению?
AWS предоставляет машинное обучение в руки каждого разработчика, специалиста по данным и бизнес-пользователя. Сервисы Amazon Machine Learning предоставляют высокопроизводительную, экономически эффективную и масштабируемую инфраструктуру для удовлетворения потребностей бизнеса.
Работа только началась?
Овладейте машинным обучением с нашей помощью, используя учебные устройства: AWS DeepRacer, AWS DeepComposer и AWS DeepLens.
Архив данных уже существует?
Используйте маркировку данных Amazon SageMaker для встроенных рабочих процессов маркировки данных, поддерживающих видео, изображения и текст.
Системы машинного обучения уже имеются?
Используйте Amazon SageMaker Clarify для обнаружения смещений, а также Amazon SageMaker Debugger для мониторинга и оптимизации продуктивности.
Хотите внедрить глубокое обучение?
Используйте распределенное обучение Amazon SageMaker для автоматического обучения больших моделей глубокого обучения. Чтобы начать машинное обучение уже сегодня, зарегистрируйте бесплатный аккаунт!
Чтобы начать машинное обучение уже сегодня, зарегистрируйте бесплатный аккаунт!
Что такое машинное обучение и как оно работает
1. Классическое обучение
Это простейшие алгоритмы, которые являются прямыми наследниками вычислительных машин 1950-х годов. Они изначально решали формальные задачи — такие, как поиск закономерностей в расчетах и вычисление траектории объектов. Сегодня алгоритмы на базе классического обучения — самые распространенные. Именно они формируют блок рекомендаций на многих платформах.
Так выглядит блок рекомендаций в YouTube
Но классическое обучение тоже бывает разным:
Обучение с учителем — когда у машины есть некий учитель, который знает, какой ответ правильный. Это значит, что исходные данные уже размечены (отсортированы) нужным образом, и машине остается лишь определить объект с нужным признаком или вычислить результат.
Такие модели используют в спам-фильтрах, распознавании языков и рукописного текста, выявлении мошеннических операций, расчете финансовых показателей, скоринге при выдаче кредита. В медицинской диагностике классификация помогает выявлять аномалии — то есть возможные признаки заболеваний на снимках пациентов.
В медицинской диагностике классификация помогает выявлять аномалии — то есть возможные признаки заболеваний на снимках пациентов.
Обучение без учителя — когда машина сама должна найти среди хаотичных данных верное решение и отсортировать объекты по неизвестным признакам. Например, определить, где на фото собака.
Эта модель возникла в 1990-х годах и на практике используется гораздо реже. Ее применяют для данных, которые просто невозможно разметить из-за их колоссального объема. Такие алгоритмы применяют для риск-менеджмента, сжатия изображений, объединения близких точек на карте, сегментации рынка, прогноза акций и распродаж в ретейле, мерчендайзинга. По такому принципу работает алгоритм iPhoto, который находит на фотографиях лица (не зная, чьи они) и объединяет их в альбомы.
2. Обучение с подкреплением
Это более сложный вид обучения, где ИИ нужно не просто анализировать данные, а действовать самостоятельно в реальной среде — будь то улица, дом или видеоигра. Задача робота — свести ошибки к минимуму, за что он получает возможность продолжать работу без препятствий и сбоев.
Задача робота — свести ошибки к минимуму, за что он получает возможность продолжать работу без препятствий и сбоев.
Нейросеть играет в Mario
Обучение с подкреплением инженеры используют для беспилотников, роботов-пылесосов, торговли на фондовом рынке, управления ресурсами компании. Именно так алгоритму AlphaGo удалось обыграть чемпиона по игре Го: просчитать все возможные комбинации, как в шахматах, здесь было невозможно.
Как создавался AlphaGo от DeepMind
3. Ансамбли
Это группы алгоритмов, которые используют сразу несколько методов машинного обучения и исправляют ошибки друг друга. Их получают тремя способами:
- Стекинг — когда разные алгоритмы обучают по отдельности, а потом передают их результаты на вход последнему, который и принимает решение;
- Беггинг — когда один алгоритм многократно обучают на случайных выборках, а потом усредняют ответы;
- Бустинг — когда алгоритмы обучают последовательно, при этом каждый обращает особое внимание на ошибки предыдущего.

Ансамбли работают в поисковых системах, компьютерном зрении, распознавании лиц и других объектов.
Как работает алгоритм «Яндекса» CatBoost
4. Нейросети и глубокое обучение
Самый сложный уровень обучения ИИ. Нейросети моделируют работу человеческого мозга, который состоит из нейронов, постоянно формирующих между собой новые связи. Очень условно можно определить их как сеть со множеством входов и одним выходом. Нейроны образуют слои, через которые последовательно проходит сигнал. Все это соединено нейронными связями — каналами, по которым передаются данные. У каждого канала свой «вес» — параметр, который влияет на данные, которые он передает.
ИИ собирает данные со всех входов, оценивая их вес по заданным параметрами, затем выполняет нужное действие и выдает результат. Сначала он получается случайным, но затем через множество циклов становится все более точным. Хорошо обученная нейросеть работает, как обычный алгоритм или точнее.
Настоящим прорывом в этой области стало глубокое обучение, которое обучает нейросети на нескольких уровнях абстракций.
Как устроена нейросеть
Здесь используют две главных архитектуры:
- Сверточные нейросети первыми научились распознавать неразмеченные изображения — самые сложные объекты для ИИ. Для этого они разбивают их на блоки, определяют в каждом доминирующие линии и сравнивают с другими изображениями нужного объекта;
- Рекуррентные нейросети отвечают за распознавание текста и речи. Они выявляют в них последовательности и связывают каждую единицу — букву или звук — с остальными.
Как работает глубокое обучение в беспилотниках
Нейросети с глубоким обучением требуют огромных массивов данных и технических ресурсов. Именно они лежат в основе машинного перевода, чат-ботов и голосовых помощников, создают музыку и дипфейки, обрабатывают фото и видео.
Как обучается нейросеть
Что такое машинное обучение? | IBM
По мере развития технологии машинного обучения она, безусловно, облегчала нашу жизнь. Однако внедрение машинного обучения в бизнес также вызвало ряд этических опасений в отношении технологий ИИ. Вот некоторые из них:
Вот некоторые из них:
Технологическая сингулярность
Хотя эта тема привлекает большое внимание общественности, многих исследователей не волнует идея о том, что в ближайшем будущем ИИ превзойдет человеческий интеллект. Технологическую сингулярность также называют сильным ИИ или сверхразумом. Философ Ник Бострум определяет сверхинтеллект как «любой интеллект, который значительно превосходит лучший человеческий мозг практически во всех областях, включая научное творчество, общую мудрость и социальные навыки». Несмотря на то, что сверхразум не является неизбежным в обществе, идея о нем поднимает некоторые интересные вопросы, поскольку мы рассматриваем использование автономных систем, таких как беспилотные автомобили. Нереально думать, что беспилотный автомобиль никогда не попадет в аварию, но кто несет ответственность в таких обстоятельствах? Должны ли мы по-прежнему разрабатывать автономные транспортные средства, или мы ограничим эту технологию полуавтономными транспортными средствами, которые помогают людям безопасно управлять автомобилем? Жюри еще не пришло к этому, но именно такие этические дебаты происходят по мере развития новой инновационной технологии искусственного интеллекта.
Воздействие ИИ на рабочие места
Хотя общественное мнение об искусственном интеллекте во многом связано с потерей рабочих мест, эту озабоченность, вероятно, следует переформулировать. Мы видим, что с появлением каждой прорывной новой технологии меняется рыночный спрос на конкретные должности. Например, когда мы смотрим на автомобильную промышленность, многие производители, такие как GM, переключаются на производство электромобилей, чтобы соответствовать экологическим инициативам. Энергетика не исчезает, но источник энергии переходит от экономии топлива к электричеству.
Подобным образом искусственный интеллект сместит спрос на рабочие места в другие области. Потребуются люди, которые помогут управлять системами ИИ. По-прежнему потребуются люди для решения более сложных проблем в отраслях, на которые, скорее всего, повлияет изменение спроса на рабочие места, например, в сфере обслуживания клиентов. Самая большая проблема с искусственным интеллектом и его влиянием на рынок труда будет заключаться в том, чтобы помочь людям перейти к новым востребованным ролям.
Конфиденциальность
Конфиденциальность, как правило, обсуждается в контексте конфиденциальности данных, защиты данных и безопасности данных. Эти опасения позволили политикам добиться большего прогресса в последние годы. Например, в 2016 году было принято законодательство GDPR для защиты персональных данных людей в Европейском союзе и Европейской экономической зоне, что дало людям больший контроль над своими данными. В Соединенных Штатах отдельные штаты разрабатывают политики, такие как Калифорнийский закон о конфиденциальности потребителей (CCPA), который был принят в 2018 году и требует от компаний информировать потребителей о сборе их данных. Такое законодательство вынудило компании переосмыслить то, как они хранят и используют информацию, позволяющую установить личность (PII). В результате инвестиции в безопасность становятся все более приоритетными для предприятий, поскольку они стремятся устранить любые уязвимости и возможности для наблюдения, взлома и кибератак.
Предвзятость и дискриминация
Случаи предвзятости и дискриминации в ряде систем машинного обучения подняли много этических вопросов, касающихся использования искусственного интеллекта. Как мы можем защититься от предвзятости и дискриминации, когда сами обучающие данные могут быть сгенерированы предвзятыми человеческими процессами? В то время как компании, как правило, имеют хорошие намерения в отношении своих усилий по автоматизации, Reuters (ссылка находится за пределами IBM)) подчеркивает некоторые непредвиденные последствия включения ИИ в практику найма. Стремясь автоматизировать и упростить процесс, Amazon непреднамеренно дискриминировала кандидатов на технические должности по полу, и в конечном итоге компании пришлось отказаться от проекта. Harvard Business Review (ссылка находится за пределами IBM) поднимает и другие острые вопросы об использовании ИИ при приеме на работу, например, какие данные вы должны иметь возможность использовать при оценке кандидата на роль.
Предвзятость и дискриминация не ограничиваются работой отдела кадров; их можно найти в ряде приложений, от программного обеспечения для распознавания лиц до алгоритмов социальных сетей.
По мере того, как компании все больше осознают риски, связанные с ИИ, они также становятся более активными в обсуждении этики и ценностей ИИ. Например, IBM прекратила выпуск своих продуктов общего назначения для распознавания и анализа лиц. Генеральный директор IBM Арвинд Кришна написал: «IBM решительно выступает против и не будет мириться с использованием любых технологий, включая технологии распознавания лиц, предлагаемые другими поставщиками, для массового наблюдения, расового профилирования, нарушений основных прав и свобод человека или любых целей, которые несовместимы с с нашими ценностями и принципами доверия и прозрачности».
Подотчетность
Поскольку не существует серьезного законодательства, регулирующего практику ИИ, нет и реального механизма обеспечения соблюдения этических норм ИИ. Нынешние стимулы для компаний быть этичными — это негативные последствия неэтичной системы искусственного интеллекта для прибыли. Чтобы восполнить этот пробел, в рамках сотрудничества между специалистами по этике и исследователями возникли этические рамки для управления созданием и распространением моделей ИИ в обществе. Однако на данный момент они служат только ориентиром. Некоторые исследования (ссылка находится за пределами IBM) (PDF, 1 МБ) показывают, что сочетание распределенной ответственности и отсутствия предвидения возможных последствий не способствует предотвращению вреда обществу.
Нынешние стимулы для компаний быть этичными — это негативные последствия неэтичной системы искусственного интеллекта для прибыли. Чтобы восполнить этот пробел, в рамках сотрудничества между специалистами по этике и исследователями возникли этические рамки для управления созданием и распространением моделей ИИ в обществе. Однако на данный момент они служат только ориентиром. Некоторые исследования (ссылка находится за пределами IBM) (PDF, 1 МБ) показывают, что сочетание распределенной ответственности и отсутствия предвидения возможных последствий не способствует предотвращению вреда обществу.
Узнайте больше о позиции IBM в отношении этики ИИ.
Что такое машинное обучение? | IBM
По мере развития технологии машинного обучения она, безусловно, облегчала нашу жизнь. Однако внедрение машинного обучения в бизнес также вызвало ряд этических опасений в отношении технологий ИИ. Вот некоторые из них:
Технологическая сингулярность
Хотя эта тема привлекает большое внимание общественности, многих исследователей не волнует идея о том, что в ближайшем будущем ИИ превзойдет человеческий интеллект. Технологическую сингулярность также называют сильным ИИ или сверхразумом. Философ Ник Бострум определяет сверхинтеллект как «любой интеллект, который значительно превосходит лучший человеческий мозг практически во всех областях, включая научное творчество, общую мудрость и социальные навыки». Несмотря на то, что сверхразум не является неизбежным в обществе, идея о нем поднимает некоторые интересные вопросы, поскольку мы рассматриваем использование автономных систем, таких как беспилотные автомобили. Нереально думать, что беспилотный автомобиль никогда не попадет в аварию, но кто несет ответственность в таких обстоятельствах? Должны ли мы по-прежнему разрабатывать автономные транспортные средства, или мы ограничим эту технологию полуавтономными транспортными средствами, которые помогают людям безопасно управлять автомобилем? Жюри еще не пришло к этому, но именно такие этические дебаты происходят по мере развития новой инновационной технологии искусственного интеллекта.
Технологическую сингулярность также называют сильным ИИ или сверхразумом. Философ Ник Бострум определяет сверхинтеллект как «любой интеллект, который значительно превосходит лучший человеческий мозг практически во всех областях, включая научное творчество, общую мудрость и социальные навыки». Несмотря на то, что сверхразум не является неизбежным в обществе, идея о нем поднимает некоторые интересные вопросы, поскольку мы рассматриваем использование автономных систем, таких как беспилотные автомобили. Нереально думать, что беспилотный автомобиль никогда не попадет в аварию, но кто несет ответственность в таких обстоятельствах? Должны ли мы по-прежнему разрабатывать автономные транспортные средства, или мы ограничим эту технологию полуавтономными транспортными средствами, которые помогают людям безопасно управлять автомобилем? Жюри еще не пришло к этому, но именно такие этические дебаты происходят по мере развития новой инновационной технологии искусственного интеллекта.
Воздействие ИИ на рабочие места
Хотя общественное мнение об искусственном интеллекте во многом связано с потерей рабочих мест, эту озабоченность, вероятно, следует переформулировать. Мы видим, что с появлением каждой прорывной новой технологии меняется рыночный спрос на конкретные должности. Например, когда мы смотрим на автомобильную промышленность, многие производители, такие как GM, переключаются на производство электромобилей, чтобы соответствовать экологическим инициативам. Энергетика не исчезает, но источник энергии переходит от экономии топлива к электричеству.
Мы видим, что с появлением каждой прорывной новой технологии меняется рыночный спрос на конкретные должности. Например, когда мы смотрим на автомобильную промышленность, многие производители, такие как GM, переключаются на производство электромобилей, чтобы соответствовать экологическим инициативам. Энергетика не исчезает, но источник энергии переходит от экономии топлива к электричеству.
Подобным образом искусственный интеллект сместит спрос на рабочие места в другие области. Потребуются люди, которые помогут управлять системами ИИ. По-прежнему потребуются люди для решения более сложных проблем в отраслях, на которые, скорее всего, повлияет изменение спроса на рабочие места, например, в сфере обслуживания клиентов. Самая большая проблема с искусственным интеллектом и его влиянием на рынок труда будет заключаться в том, чтобы помочь людям перейти к новым востребованным ролям.
Конфиденциальность
Конфиденциальность, как правило, обсуждается в контексте конфиденциальности данных, защиты данных и безопасности данных. Эти опасения позволили политикам добиться большего прогресса в последние годы. Например, в 2016 году было принято законодательство GDPR для защиты персональных данных людей в Европейском союзе и Европейской экономической зоне, что дало людям больший контроль над своими данными. В Соединенных Штатах отдельные штаты разрабатывают политики, такие как Калифорнийский закон о конфиденциальности потребителей (CCPA), который был принят в 2018 году и требует от компаний информировать потребителей о сборе их данных. Такое законодательство вынудило компании переосмыслить то, как они хранят и используют информацию, позволяющую установить личность (PII). В результате инвестиции в безопасность становятся все более приоритетными для предприятий, поскольку они стремятся устранить любые уязвимости и возможности для наблюдения, взлома и кибератак.
Эти опасения позволили политикам добиться большего прогресса в последние годы. Например, в 2016 году было принято законодательство GDPR для защиты персональных данных людей в Европейском союзе и Европейской экономической зоне, что дало людям больший контроль над своими данными. В Соединенных Штатах отдельные штаты разрабатывают политики, такие как Калифорнийский закон о конфиденциальности потребителей (CCPA), который был принят в 2018 году и требует от компаний информировать потребителей о сборе их данных. Такое законодательство вынудило компании переосмыслить то, как они хранят и используют информацию, позволяющую установить личность (PII). В результате инвестиции в безопасность становятся все более приоритетными для предприятий, поскольку они стремятся устранить любые уязвимости и возможности для наблюдения, взлома и кибератак.
Предвзятость и дискриминация
Случаи предвзятости и дискриминации в ряде систем машинного обучения подняли много этических вопросов, касающихся использования искусственного интеллекта. Как мы можем защититься от предвзятости и дискриминации, когда сами обучающие данные могут быть сгенерированы предвзятыми человеческими процессами? В то время как компании, как правило, имеют хорошие намерения в отношении своих усилий по автоматизации, Reuters (ссылка находится за пределами IBM)) подчеркивает некоторые непредвиденные последствия включения ИИ в практику найма. Стремясь автоматизировать и упростить процесс, Amazon непреднамеренно дискриминировала кандидатов на технические должности по полу, и в конечном итоге компании пришлось отказаться от проекта. Harvard Business Review (ссылка находится за пределами IBM) поднимает и другие острые вопросы об использовании ИИ при приеме на работу, например, какие данные вы должны иметь возможность использовать при оценке кандидата на роль.
Как мы можем защититься от предвзятости и дискриминации, когда сами обучающие данные могут быть сгенерированы предвзятыми человеческими процессами? В то время как компании, как правило, имеют хорошие намерения в отношении своих усилий по автоматизации, Reuters (ссылка находится за пределами IBM)) подчеркивает некоторые непредвиденные последствия включения ИИ в практику найма. Стремясь автоматизировать и упростить процесс, Amazon непреднамеренно дискриминировала кандидатов на технические должности по полу, и в конечном итоге компании пришлось отказаться от проекта. Harvard Business Review (ссылка находится за пределами IBM) поднимает и другие острые вопросы об использовании ИИ при приеме на работу, например, какие данные вы должны иметь возможность использовать при оценке кандидата на роль.
Предвзятость и дискриминация не ограничиваются работой отдела кадров; их можно найти в ряде приложений, от программного обеспечения для распознавания лиц до алгоритмов социальных сетей.
По мере того, как компании все больше осознают риски, связанные с ИИ, они также становятся более активными в обсуждении этики и ценностей ИИ. Например, IBM прекратила выпуск своих продуктов общего назначения для распознавания и анализа лиц. Генеральный директор IBM Арвинд Кришна написал: «IBM решительно выступает против и не будет мириться с использованием любых технологий, включая технологии распознавания лиц, предлагаемые другими поставщиками, для массового наблюдения, расового профилирования, нарушений основных прав и свобод человека или любых целей, которые несовместимы с с нашими ценностями и принципами доверия и прозрачности».
Например, IBM прекратила выпуск своих продуктов общего назначения для распознавания и анализа лиц. Генеральный директор IBM Арвинд Кришна написал: «IBM решительно выступает против и не будет мириться с использованием любых технологий, включая технологии распознавания лиц, предлагаемые другими поставщиками, для массового наблюдения, расового профилирования, нарушений основных прав и свобод человека или любых целей, которые несовместимы с с нашими ценностями и принципами доверия и прозрачности».
Подотчетность
Поскольку не существует серьезного законодательства, регулирующего практику ИИ, нет и реального механизма обеспечения соблюдения этических норм ИИ. Нынешние стимулы для компаний быть этичными — это негативные последствия неэтичной системы искусственного интеллекта для прибыли. Чтобы восполнить этот пробел, в рамках сотрудничества между специалистами по этике и исследователями возникли этические рамки для управления созданием и распространением моделей ИИ в обществе.