
Базы данных
Понятие о базах данных
Одной из важнейших областей применения компьютеров является переработка и хранение больших объемов информации в различных сферах деятельности человека: в экономике, банковском деле, торговле, транспорте, медицине, науке и т.д.
Существующие современные информационные системы характеризуются огромными объемами хранимых и обрабатываемых данных, сложной организацией, необходимостью удовлетворять разнообразные требования многочисленных пользователей.
Информационная система — это система, которая реализует автоматизированный сбор, обработку и манипулирование данными и включает технические средства обработки данных, программное обеспечение и обслуживающий персонал.
Цель любой информационной системы — обработка данных об объектах реального мира. Основой информационной системы является база данных. В широком смысле слова база данных — это совокупность сведений о конкретных объектах реального мира в какой-либо предметной области. Под предметной областью принято понимать часть реального мира, подлежащего изучению для организации управления его объектами и, в конечном счете, автоматизации, например, предприятие, вуз и т. д.
Создавая базу данных, пользователь стремится упорядочить информацию по различным признакам и быстро производить выборку с произвольным сочетанием признаков. При этом очень важно выбрать правильную модель данных. Модель данных — это формализованное представление основных категорий восприятия реального мира, представленных его объектами, связями, свойствами, а также их взаимодействиями.
База данных — это информационная модель, позволяющая упорядоченно хранить данные о группе объектов, обладающих одинаковым набором свойств.
Информация в базах данных хранится в упорядоченном виде. Так, в записной книжке все записи упорядочены по алфавиту, а в библиотечном каталоге либо по алфавиту (алфавитный каталог), либо в соответствии с областью знания (предметный каталог).
Система программ, позволяющая создавать БД, обновлять хранимую в ней информацию, обеспечивающая удобный доступ к ней с целью просмотра и поиска, называется системой управления базами данных (СУБД).
Типы баз данных
Группу связанных между собой элементов данных называют обычно записью. Известны три основных типа организации данных и связей между ними: иерархический (в виде дерева), сетевой и реляционный.
Иерархическая БД
В иерархической БД существует упорядоченность элементов в записи, один элемент считается главным, остальные — подчиненными. Данные в записи упорядочены в определенную последовательность, как ступеньки лестницы, и поиск данных может осуществляться лишь последовательным «спуском» со ступеньки на ступеньку. Поиск какого-либо элемента данных в такой системе может оказаться довольно трудоемким из-за необходимости последовательно проходить несколько предшествующих иерархических уровней. Иерархическую БД образует каталог файлов, хранимых на диске; дерево каталогов, доступное для просмотра в Norton Соmmander, — наглядная демонстрация структуры такой БД и поиска в ней нужного элемента (при работе в операционной системе МS-DOS). Такой же базой данных является родовое генеалогическое дерево.
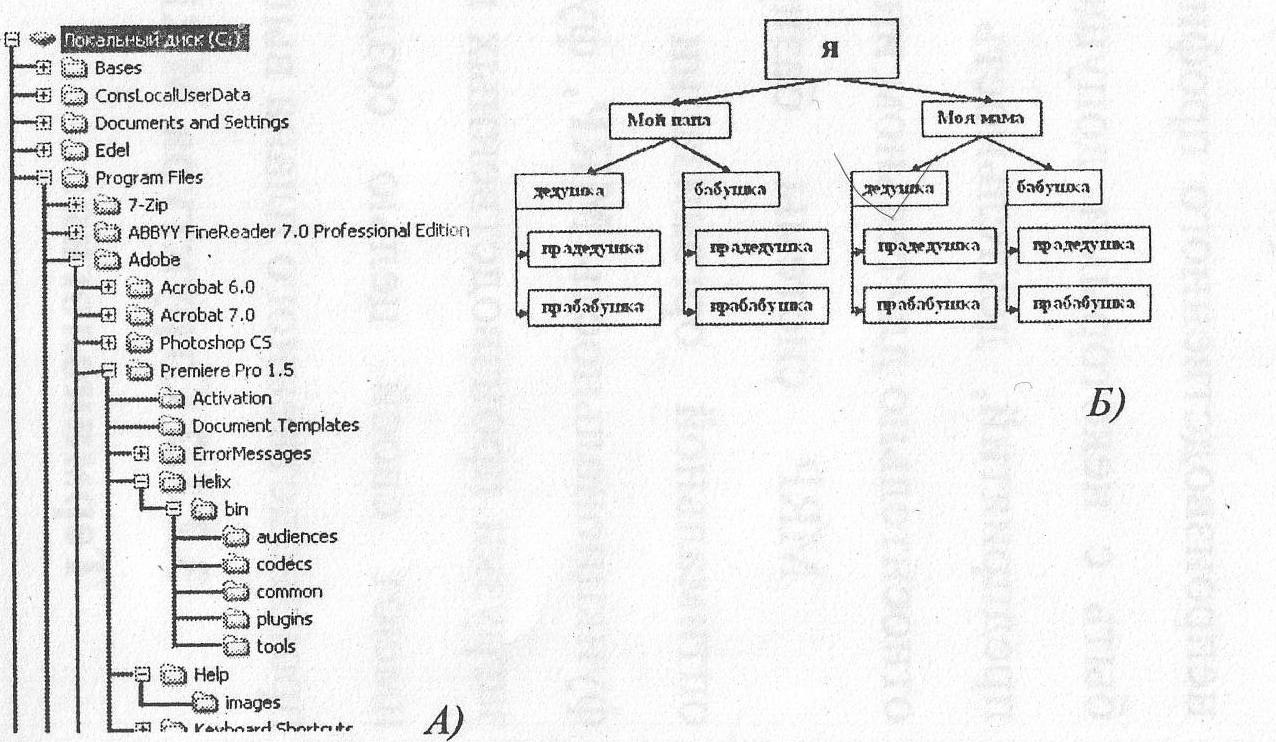
Рисунок 1. Иерархическая модель базы данных
Сетевая БД
Эта база данных отличается большей гибкостью, так как в ней существует возможность устанавливать дополнительно к вертикальным иерархическим связям горизонтальные связи. Это облегчает процесс поиска требуемых элементов данных, так как уже не требует обязательного прохождения всех предшествующих ступеней.
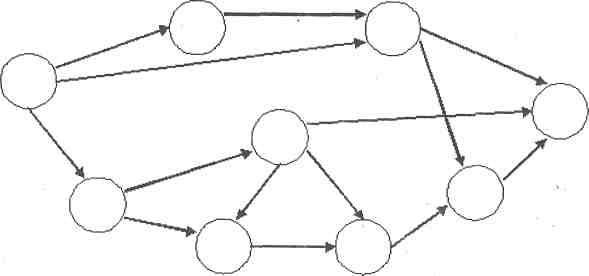
Рисунок 2. Сетевая модель базы данных
Реляционная БД
Наиболее распространенным способом организации данных является третий, к которому можно свести как иерархический, так и сетевой — реляционный (англ. relation — отношение, связь). В реляционной БД под записью понимается строка прямоугольной таблицы. Элементы записи образуют столбцы этой таблицы (поля). Все элементы в столбце имеют одинаковый тип (числовой, символьный), а каждый столбец — неповторяющееся имя. Одинаковые строки в таблице отсутствуют. Преимущество таких БД—наглядность и понятность организации данных, скорость поиска нужной информации. Примером реляционной БД служит таблица на странице классного журнала, в которой записью является строка с данными о конкретном ученике, а имена полей (столбцов) указывают, какие данные о каждом ученике должны быть записаны в ячейках таблицы.
Совокупность БД и программы СУБД образует информационно-поисковую систему, называемую банком данных.
1. По технологии обработки данных базы данных делятся на централизованные и распределенные. Централизованная база данных хранится в памяти одной вычислительной системы. Если эта вычислительная система является компонентом сети ЭВМ, возможен распределенный доступ к такой базе. Этот способ использования баз данных часто применяют в локальных сетях ПК. Распределенная база данных состоит из нескольких, возможно, пересекающихся или даже дублирующих друг друга частей, хранимых в различных ЭВМ вычислительной сети. Работа с такой базой осуществляется с помощью системы управления распределенной базой данных (СУРБД).

Рис. 3. Реляционная модель базы данных
2. По способу доступа к данным базы данных делятся на базы данных с локальным доступом и базы данных с удаленным (сетевым доступом). Системы централизованных баз данных с сетевым доступом предполагают различные архитектуры таких систем: файл-сервер; клиент-сервер.
Файл-сервер
Архитектура систем БД с сетевым доступом предполагает выделение одной из машин сети в качестве центральной (сервер файлов). На такой машине хранится совместно используемая централизованная БД. Все другие машины сети выполняют функции рабочих станций, с помощью которых поддерживается доступ пользовательской системы к централизованной базе данных. Файлы базы данных в соответствии с пользовательскими запросами передаются на рабочие станции, где в основном и производится обработка. При большой интенсивности доступа к одним и тем же данным производительность такой информационной системы падает. Пользователи могут создавать также на рабочих станциях локальные БД, которые используются ими монопольно. Схема обработки информации по принципу файл-сервер изображена на рисунке.
Клиент-сервер
В отличие от предыдущей системы, центральная машина (сервер базы данных), помимо хранения централизованной базы данных, должна обеспечивать выполнение основного объема обработки данных. Запрос на использование данных, выдаваемый клиентом (рабочей станцией), приводит к поиску и извлечению данных на сервере. Извлеченные данные транспортируются по сети от сервера к клиенту. Спецификой архитектуры клиент-сервер является использование языка – запросов SQL.
База данных — Википедия. Что такое База данных
Ба́за да́нных — представленная в объективной форме совокупность самостоятельных материалов (статей, расчётов, нормативных актов, судебных решений и иных подобных материалов), систематизированных таким образом, чтобы эти материалы могли быть найдены и обработаны с помощью электронной вычислительной машины (ЭВМ)
[1]. Схема базы данных движка Mediawiki
Схема базы данных движка MediawikiМногие специалисты указывают на распространённую ошибку, состоящую в некорректном использовании термина «база данных» вместо термина «система управления базами данных», и указывают на необходимость различения этих понятий[2].
Проблемы определения
В литературе предлагается множество определений понятия «база данных», отражающих скорее субъективное мнение тех или иных авторов, однако общепризнанная единая формулировка отсутствует.
Определения из международных стандартов и национальных стандартов, разработанных на основе международных:
- База данных — совокупность данных, хранимых в соответствии со схемой данных, манипулирование которыми выполняют в соответствии с правилами средств моделирования данных.
- База данных — совокупность данных, организованных в соответствии с концептуальной структурой, описывающей характеристики этих данных и взаимоотношения между ними, которая поддерживает одну или более областей применения[6].
Определения из авторитетных монографий:
- База данных — организованная в соответствии с определёнными правилами и поддерживаемая в памяти компьютера совокупность данных, характеризующая актуальное состояние некоторой предметной области и используемая для удовлетворения информационных потребностей пользователей[7].
- База данных — некоторый набор перманентных (постоянно хранимых) данных, используемых прикладными программными системами какого-либо предприятия[8].
- База данных — совместно используемый набор логически связанных данных (и описание этих данных), предназначенный для удовлетворения информационных потребностей организации [9].
В определениях наиболее часто (явно или неявно) присутствуют следующие отличительные признаки[10]:
- БД хранится и обрабатывается в вычислительной системе.
Таким образом, любые внекомпьютерные хранилища информации (архивы, библиотеки, картотеки и т. п.) базами данных не являются. - Данные в БД логически структурированы (систематизированы) с целью обеспечения возможности их эффективного поиска и обработки в вычислительной системе.
Структурированность подразумевает явное выделение составных частей (элементов), связей между ними, а также типизацию элементов и связей, при которой с типом элемента (связи) соотносится определённая семантика и допустимые операции[11]. - БД включает схему, или метаданные, описывающие логическую структуру БД в формальном виде (в соответствии с некоторой метамоделью).
В соответствии с ГОСТ Р ИСО МЭК ТО 10032-2007, «постоянные данные в среде базы данных включают в себя схему и базу данных. Схема включает в себя описания содержания, структуры и ограничений целостности, используемые для создания и поддержки базы данных. База данных включает в себя набор постоянных данных, определённых с помощью схемы. Система управления данными использует определения данных в схеме для обеспечения доступа и управления доступом к данным в базе данных»
Из перечисленных признаков только первый является строгим, а другие допускают различные трактовки и различные степени оценки. Можно лишь установить некоторую степень соответствия требованиям к БД.
В такой ситуации не последнюю роль играет общепринятая практика. В соответствии с ней, например, не называют базами данных файловые архивы, Интернет-порталы или электронные таблицы, несмотря на то, что они в некоторой степени обладают признаками БД. Принято считать, что эта степень в большинстве случаев недостаточна (хотя могут быть исключения).
История
История возникновения и развития технологий баз данных может рассматриваться как в широком, так и в узком аспекте.
В широком смысле понятие истории баз данных обобщается до истории любых средств, с помощью которых человечество хранило и обрабатывало данные. В таком контексте упоминаются, например, средства учёта царской казны и налогов в древнем Шумере (4000 г. до н. э.)[12], узелковая письменность инков — кипу, клинописи, содержащие документы Ассирийского царства и т. п. Следует помнить, что недостатком этого подхода является размывание понятия «база данных» и фактическое его слияние с понятиями «архив» и даже «письменность».
История баз данных в узком смысле рассматривает базы данных в традиционном (современном) понимании. Эта история начинается с 1955 года, когда появилось программируемое оборудование обработки записей. Программное обеспечение этого времени поддерживало модель обработки записей на основе файлов. Для хранения данных использовались перфокарты[12].
Оперативные сетевые базы данных появились в середине 1960-х. Операции над оперативными базами данных обрабатывались в интерактивном режиме с помощью терминалов. Простые индексно-последовательные организации записей быстро развились к более мощной модели записей, ориентированной на наборы. За руководство работой Data Base Task Group (DBTG), разработавшей стандартный язык описания данных и манипулирования данными, Чарльз Бахман получил Тьюринговскую премию.
В это же время в сообществе баз данных Кобол была проработана концепция схем баз данных и концепция независимости данных.
Следующий важный этап связан с появлением в начале 1970-х реляционной модели данных, благодаря работам Эдгара Кодда. Работы Кодда открыли путь к тесной связи прикладной технологии баз данных с математикой и логикой. За свой вклад в теорию и практику Эдгар Ф. Кодд также получил премию Тьюринга.
Сам термин база данных (англ. database) появился в начале 1960-х годов, и был введён в употребление на симпозиумах, организованных компанией SDC в 1964 и 1965 годах, хотя понимался сначала в довольно узком смысле, в контексте систем искусственного интеллекта. В широкое употребление в современном понимании термин вошёл лишь в 1970-е годы[13].
Виды баз данных
Существует огромное количество разновидностей баз данных, отличающихся по различным критериям. Например, в «Энциклопедии технологий баз данных»[7], по материалам которой написан данный раздел, определяются свыше 50 видов БД.
Основные классификации приведены ниже.
Классификация по модели данных
Примеры:
Классификация по среде постоянного хранения
- Во вторичной памяти, или традиционная (англ. conventional database): средой постоянного хранения является периферийная энергонезависимая память (вторичная память) — как правило жёсткий диск.
В оперативную память СУБД помещает лишь кэш и данные для текущей обработки. - В оперативной памяти (англ. in-memory database, memory-resident database, main memory database): все данные на стадии исполнения находятся в оперативной памяти.
- В третичной памяти (англ. tertiary database): средой постоянного хранения является отсоединяемое от сервера устройство массового хранения (третичная память), как правило на основе магнитных лент или оптических дисков.
Во вторичной памяти сервера хранится лишь каталог данных третичной памяти, файловый кэш и данные для текущей обработки; загрузка же самих данных требует специальной процедуры.
Классификация по содержимому
Примеры:
Классификация по степени распределённости
- Централизованная, или сосредоточенная (англ. centralized database): БД, полностью поддерживаемая на одном компьютере.
- Распределённая БД (англ. distributed database) — составные части которой размещаются в различных узлах компьютерной сети в соответствии с каким-либо критерием.
- Неоднородная (англ. heterogeneous distributed database): фрагменты распределённой БД в разных узлах сети поддерживаются средствами более одной СУБД.
- Однородная (англ. homogeneous distributed database): фрагменты распределённой БД в разных узлах сети поддерживаются средствами одной и той же СУБД.
- Фрагментированная, или секционированная (англ. partitioned database): методом распределения данных является фрагментирование (партиционирование, секционирование), вертикальное или горизонтальное.
- Тиражированная (англ. replicated database): методом распределения данных является тиражирование (репликация).
Другие виды БД
- Пространственная (англ. spatial database): БД, в которой поддерживаются пространственные свойства сущностей предметной области. Такие БД широко используются в геоинформационных системах.
- Временная, или темпоральная (англ. temporal database): БД, в которой поддерживается какой-либо аспект времени, не считая времени, определяемого пользователем.
- Пространственно-временная (англ. spatial-temporal database) БД: БД, в которой одновременно поддерживается одно или более измерений в аспектах как пространства, так и времени.
- Циклическая (англ. round-robin database): БД, объём хранимых данных которой не меняется со временем, поскольку в процессе сохранения новых данных они заменяют более старые данные. Одни и те же ячейки для данных используются циклически.
Сверхбольшие базы данных
Сверхбольшая база данных (англ. Very Large Database, VLDB) — это база данных, которая занимает чрезвычайно большой объём на устройстве физического хранения. Термин подразумевает максимально возможные объёмы БД, которые определяются последними достижениями в технологиях физического хранения данных и в технологиях программного оперирования данными.
Количественное определение понятия «чрезвычайно большой объём» меняется во времени. Так, в 1997 году самой большой в мире была текстовая база данных Knight Ridder’s DIALOG объёмом 7 терабайт[14]. В 2001 году самой большой считалась база данных объёмом 10,5 терабайт, в 2003 году — объёмом 25 терабайт[15]. В 2005 году самыми крупными в мире считались базы данных с объёмом хранилища порядка сотни терабайт[16]. В 2006 году поисковая машина Google использовала базу данных объёмом 850 терабайт[17].
К 2010 году считалось, что объём сверхбольшой базы данных должен измеряться по меньшей мере петабайтами[16].
В 2011 году компания Facebook хранила данные в кластере из 2 тыс. узлов суммарной ёмкостью 21 петабайт[18]; к концу 2012 года объём данных Facebook достиг 100 петабайт[19], а в 2014 году — 300 петабайт[20].
К 2014 году по косвенным оценкам компания Google хранила на своих серверах до 10—15 эксабайт данных в совокупности[21].
По некоторым оценкам, к 2025 году генетики будут располагать данными о геномах от 100 миллионов до 2 миллиардов человек, и для хранения подобного объёма данных потребуется от 2 до 40 эксабайт[22].
В целом, по оценкам компании IDC, суммарный объём данных «цифровой вселенной» удваивается каждые два года и изменится от 4,4 зеттабайта в 2013 году до 44 зеттабайт в 2020 году[23].
Исследования в области хранения и обработки сверхбольших баз данных VLDB всегда находятся на острие теории и практики баз данных. В частности, с 1975 года проходит ежегодная конференция International Conference on Very Large Data Bases («Международная конференция по сверхбольшим базам данных»). Большинство исследований проводится под эгидой некоммерческой организации VLDB Endowment (Фонд целевого капитала «VLDB»), которая обеспечивает продвижение научных работ и обмен информацией в области сверхбольших БД и смежных областях.
См. также
Примечания
- ↑ Гражданский кодекс РФ, ст. 1260
- ↑ «Следует отметить, что термин база данных часто используется даже тогда, когда на самом деле подразумевается СУБД. […]Такое обращение с терминами предосудительно». — К. Дж. Дейт. Введение в системы баз данных. — 8-е изд. — М.: «Вильямс», 2006, стр. 50.
«Этот термин (база данных) часто ошибочно используется вместо термина ‘система управления базами данных’». — Когаловский М. Р. Энциклопедия технологий баз данных. — М.: Финансы и статистика, 2002., стр. 460.
«Среди непрофессионалов […] путаница возникает при использовании терминов „база данных“ и „система управления базами данных“. […] Мы будем строго разделять эти термины». — Кузнецов С. Д. Основы баз данных: учебное пособие. — 2-е издание, испр. — М.: Интернет-Университет Информационных Технологий; БИНОМ. Лаборатория знаний, 2007, стр. 19. - ↑ 1 2 ГОСТ Р ИСО МЭК ТО 10032-2007: Эталонная модель управления данными (идентичен ISO/IEC TR 10032:2003 Information technology — Reference model of data management)
- ↑ ГОСТ 33707-2016 (ISO/IEC 2382:2015) Информационные технологии (ИТ). Словарь
- ↑ ISO/IEC TR 10032:2003 — Information technology — Reference Model of Data Management (англ.). www.iso.org. Проверено 9 июля 2018.
- ↑ ISO/IEC 2382:2015 — Information technology — Vocabulary (англ.). www.iso.org. Проверено 9 июля 2018.
- ↑ 1 2 Когаловский М. Р., 2002.
- ↑ Дейт К. Дж., 2005.
- ↑ Коннолли Т., Бегг К., 2003.
- ↑ Мирошниченко Е. А. К формальному определению понятия «база данных» // Пробл. информатики. 2011. № 2. С. 83-87.
- ↑ Важно понимать, что структурированность базы данных оценивается не на уровне физического хранения (на котором все данные представлены совокупностями битов или байтов), а на уровне некоторой логической модели данных.
- ↑ 1 2 Грей, Дж. Управление данными: прошлое, настоящее и будущее
- ↑ Haigh T. How Data Got its Base: Information Storage Software in the 1950s and 1960s // IEEE Annals of the History of Computing. — 2009. — #4 October-December
- ↑ Very Large Database
- ↑ Riedewald M., Agrawal D., Abbadi A. Dynamic Multidimensional Data Cubes for Interactive Analysis of Massive Datasets // In: Encyclopedia of Information Science and Technology, First Edition, Idea Group Inc., 2005. ISBN 9781591405535
- ↑ 1 2 «Экстремальные» базы данных: Самые большие и самые быстрые, 2010 г.
- ↑ Alex Chitu. How Much Data Does Google Store?, 2006
- ↑ Shvachko, Konstantin. Apache Hadoop. The Scalability Update (англ.). — 2011. — Vol. 36, no. 3. — P. 7—13. — ISSN 1044-6397.
- ↑ Josh Constine. How Big Is Facebook’s Data? // TechCrunch, 23.08.2012
- ↑ Wiener, J., Bronson N. Facebook’s Top Open Data Problems, 22.10.2014
- ↑ Colin Carson. How Much Data Does Google Store? Архивная копия от 15 сентября 2016 на Wayback Machine, 2014
- ↑ Ася Горина. Увеличивающийся объем генетических данных стал проблемой для науки
- ↑ Executive Summary: Data Growth, Business Opportunities, and the IT Imperatives
Литература
- Когаловский М. Р. Энциклопедия технологий баз данных. — М.: Финансы и статистика, 2002. — 800 с. — ISBN 5-279-02276-4.
- Кузнецов С. Д. Основы баз данных. — 2-е изд. — М.: Интернет-университет информационных технологий; БИНОМ. Лаборатория знаний, 2007. — 484 с. — ISBN 978-5-94774-736-2.
- Дейт К. Дж. Введение в системы баз данных = Introduction to Database Systems. — 8-е изд. — М.: Вильямс, 2005. — 1328 с. — ISBN 5-8459-0788-8 (рус.) 0-321-19784-4 (англ.).
- Коннолли Т., Бегг К. Базы данных. Проектирование, реализация и сопровождение. Теория и практика = Database Systems: A Practical Approach to Design, Implementation, and Management. — 3-е изд. — М.: Вильямс, 2003. — 1436 с. — ISBN 0-201-70857-4.
- Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы баз данных. Полный курс = Database Systems: The Complete Book. — Вильямс, 2003. — 1088 с. — ISBN 5-8459-0384-X.
- Date, C. J. Date on Database: Writings 2000–2006. — Apress, 2006. — 566 с. — ISBN 978-1-59059-746-0, 1-59059-746-X.
- Date, C. J. Database in Depth. — O’Reilly, 2005. — 240 с. — ISBN 0-596-10012-4.
- Beynon-Davies P. (2004). Database Systems 3rd Edition. Palgrave, Basingstoke, UK. ISBN 1-4039-1601-2
Ссылки
Система управления базами данных — Википедия
Материал из Википедии — свободной энциклопедии
Систе́ма управле́ния ба́зами да́нных, сокр. СУБД (англ. Database Management System, сокр. DBMS) — совокупность программных и лингвистических средств общего или специального назначения, обеспечивающих управление созданием и использованием баз данных[1].
СУБД — комплекс программ, позволяющих создать базу данных (БД) и манипулировать данными (вставлять, обновлять, удалять и выбирать). Система обеспечивает безопасность, надёжность хранения и целостность данных, а также предоставляет средства для администрирования БД[2].
Обычно современная СУБД содержит следующие компоненты:
- ядро, которое отвечает за управление данными во внешней и оперативной памяти и журнализацию;
- процессор языка базы данных, обеспечивающий оптимизацию запросов на извлечение и изменение данных и создание, как правило, машинно-независимого исполняемого внутреннего кода;
- подсистему поддержки времени исполнения, которая интерпретирует программы манипуляции данными, создающие пользовательский интерфейс с СУБД;
- сервисные программы (внешние утилиты), обеспечивающие ряд дополнительных возможностей по обслуживанию информационной системы.
- По модели данных
Примеры:
- По степени распределённости
- Локальные СУБД (все части локальной СУБД размещаются на одном компьютере)
- Распределённые СУБД (части СУБД могут размещаться не только на одном, но на двух и более компьютерах).
- По способу доступа к БД
- В файл-серверных СУБД файлы данных располагаются централизованно на файл-сервере. СУБД располагается на каждом клиентском компьютере (рабочей станции). Доступ СУБД к данным осуществляется через локальную сеть. Синхронизация чтений и обновлений осуществляется посредством файловых блокировок.
- Преимуществом этой архитектуры является низкая нагрузка на процессор файлового сервера.
- Недостатки: потенциально высокая загрузка локальной сети; затруднённость или невозможность централизованного управления; затруднённость или невозможность обеспечения таких важных характеристик, как высокая надёжность, высокая доступность и высокая безопасность. Применяются чаще всего в локальных приложениях, которые используют функции управления БД; в системах с низкой интенсивностью обработки данных и низкими пиковыми нагрузками на БД.
- На данный момент файл-серверная технология считается устаревшей, а её использование в крупных информационных системах — недостатком[3].
- Примеры: Microsoft Access, Paradox, dBase, FoxPro, Visual FoxPro.
- Клиент-серверная СУБД располагается на сервере вместе с БД и осуществляет доступ к БД непосредственно, в монопольном режиме. Все клиентские запросы на обработку данных обрабатываются клиент-серверной СУБД централизованно.
- Недостаток клиент-серверных СУБД состоит в повышенных требованиях к серверу.
- Достоинства: потенциально более низкая загрузка локальной сети; удобство централизованного управления; удобство обеспечения таких важных характеристик, как высокая надёжность, высокая доступность и высокая безопасность.
- Примеры: Oracle Database, Firebird, Interbase, IBM DB2, Informix, MS SQL Server, Sybase Adaptive Server Enterprise, PostgreSQL, MySQL, Caché, ЛИНТЕР.
- Встраиваемая СУБД — СУБД, которая может поставляться как составная часть некоторого программного продукта, не требуя процедуры самостоятельной установки. Встраиваемая СУБД предназначена для локального хранения данных своего приложения и не рассчитана на коллективное использование в сети.
- Физически встраиваемая СУБД чаще всего реализована в виде подключаемой библиотеки. Доступ к данным со стороны приложения может происходить через SQL либо через специальные программные интерфейсы.
- Примеры: OpenEdge, SQLite, BerkeleyDB, Firebird Embedded, Microsoft SQL Server Compact, ЛИНТЕР.
- СУБД с непосредственной записью
В таких СУБД все изменённые блоки данных незамедлительно записываются во внешнюю память при поступлении сигнала подтверждения любой транзакции. Такая стратегия используется только при высокой эффективности внешней памяти.
- СУБД с отложенной записью
В таких СУБД изменения аккумулируются в буферах внешней памяти до наступления любого из следующих событий:
- Контрольная точка.
- Нехватка пространства во внешней памяти, отведенного под журнал. СУБД создаёт контрольную точку и начинает писать журнал сначала, затирая предыдущую информацию.
- Останов. СУБД ждёт, когда всё содержимое всех буферов внешней памяти будет перенесено во внешнюю память, после чего делает отметки, что останов базы данных выполнен корректно.
- Нехватка оперативной памяти для буферов внешней памяти.
Такая стратегия позволяет избежать частого обмена с внешней памятью и значительно увеличить эффективность работы СУБД.
Таблица (база данных) — Википедия
Материал из Википедии — свободной энциклопедии
Таблица — это совокупность связанных данных, хранящихся в структурированном виде в базе данных. Она состоит из столбцов и строк.
В реляционных базах данных и плоских файлах баз данных, таблица — это набор элементов данных (значений), использующий модель вертикальных столбцов (имеющих уникальное имя) и горизонтальных строк. Ячейка — место, где строка и столбец пересекаются.[1] Таблица содержит определенное число столбцов, но может иметь любое количество строк.[2] Каждая строка однозначно определяется одним или несколькими уникальными значениями, которые принимают её ячейки из определенного подмножества столбцов. Подмножество столбцов, которое уникально идентифицирует строку, называется первичным ключом.
«Таблица» — это ещё один термин для «отношения»; разница между ними в том, что таблица обычно представляет собой мультимножество (набор) строк, тогда как отношение представляет собой множество и не допускает дубликатов. Помимо обычных данных, таблицы, как правило, имеют связанные с ними метаданные, такие как ограничения, относящиеся к таблицам в целом или к значениям в определенных столбцах.
Данные в таблицах не обязательно физически хранятся в базе данных. Представления также функционируют, как реляционные таблицы, но их данные вычисляются во время выполнения запроса. Внешние таблицы (например, в СУБД Informix[3] или Oracle,[4][5]) также можно рассматривать как представления.
С точки зрения реляционных моделей баз данных, таблицы можно считать удобным представлением отношения, но эти два понятия не являются строго эквивалентными. Например, в SQL таблицы в принципе могут содержать повторяющиеся строки, в то время как истинное отношение не может содержать одинаковые кортежи. Аналогичным образом, представление в виде таблицы подразумевает конкретный порядок для строк и столбцов, в то время как в отношениях они неупорядочены. Однако система баз данных гарантирует определенный порядок строк при выдаче таблицы, только если ORDER BY параметр указывается в операторе SELECT, который запрашивает таблицу.
Отношение можно также представить в виде N-мерного графика, где n — количество атрибутов (столбцов таблицы). Например, отношение с двумя атрибутами и тремя значениями можно представить как таблицу из двух столбцов и трех строк, или как двумерный график с тремя точками. Представления таблиц и графиков эквивалентны только в том случае, если порядок строк не важен, а в таблице нет повторяющихся строк.
Иерархические базы данных[править | править код]
В нереляционных системах, иерархических баз данных, отдаленный аналог таблицы представляет собой структурированный файл, представляющий строки таблицы в каждой строке файла и каждый столбец в строке. Эта структура предполагает, что строка может иметь повторяющиеся данные, как правило, в дочерних сегментах данных. Данные хранятся в последовательности физических записей.
Электронные таблицы[править | править код]
В отличие от электронных таблиц, в таблицах баз данных тип данных столбца обычно определяется схемой, описывающей таблицу. Некоторые SQL системы, например СУБД SQLite, менее строги к определению типов столбцов.
Понятие и назначение базы данных. Примеры и классификация баз данных
 Без баз данных (БД) практически невозможно себе представить работу современных информационных технологий. В этой статье мы рассмотрим назначение и понятие базы данных, поговорим о том, что же такое база данных, и какая база вам лучше подойдёт. Узнаем, какие существуют типы и виды баз данных и какие из них встречаются сегодня чаще. Также поговорим о структуре иерархических баз данных, упомянем сетевые базы данных, уделим пристальное внимание реляционным базам данных.
Без баз данных (БД) практически невозможно себе представить работу современных информационных технологий. В этой статье мы рассмотрим назначение и понятие базы данных, поговорим о том, что же такое база данных, и какая база вам лучше подойдёт. Узнаем, какие существуют типы и виды баз данных и какие из них встречаются сегодня чаще. Также поговорим о структуре иерархических баз данных, упомянем сетевые базы данных, уделим пристальное внимание реляционным базам данных.
Напоследок рассмотрим особенности проектирования БД и их назначение на примере СУБД MySQL, т. к. эта система управления является, по сути, математической моделью реляционных баз данных. Итак, поехали!
База данных: назначение, понятие, классификация
В нашей статье мы не будем углубляться в математические теории и законы, описывающие базы данных, т. к. подробности всегда можно узнать из специализированной литературы. Но принципы работы БД, особенности управления, терминологию, устройство, назначение, а также такое понятие, как классификация баз данных, сегодня должен знать каждый, кто так или иначе сталкивается с ИТ-сферой, а уж тем более в ней работает.
Итак, самое простое определение баз данных звучит следующим образом: база данных — это упорядоченное хранение информации в систематизированном виде. При этом виды упорядочивания, хранения, систематизации и управления могут быть разные. И каждый из них отвечает определённым требованиям либо предназначен для выполнения определённых действий.
Типы и виды баз данных, классификация
Существует достаточно много типов и видов баз данных, поэтому описывать их все в данной публикации мы не будем. Однако самые распространённые всё же упомянем.
Важно понять, что, говоря о данных, мы подразумеваем определенную информацию, например, о товаре в интернет-магазине. И в этих данных содержатся конкретные параметры и свойства. Однако лучше всего рассматривать БД на конкретных примерах.
Иерархическая база данных, структура иерархических данных
Когда речь идёт о хранении иерархических данных, каждый объект хранит информацию в виде определенной сущности, и у каждой сущности могут быть родительские и дочерние элементы, а у дочерних, в свою очередь, тоже могут быть дочерние элементы. Таким образом, можно сказать, что это данные, которые подлежат строгой иерархии (представьте себе своеобразное дерево).
Простой пример иерархических данных — документ в формате XML либо файловая система компьютера.
Нельзя не упомянуть и то, что базы данных этого вида оптимизированы под чтение информации. При такой структуре данные можно быстро выбирать из нужной области, отдавая запрашиваемую информацию пользователям. Например, компьютер легко работает с конкретной папкой либо файлом, которые, по сути, можно назвать объектами структуры иерархических данных. Но когда нужно перебрать всю информацию, это может занять время (если вернуться к вышеописанному примеру, то проверка антивирусом всех уголков нашего компьютера выполняется не так быстро, как хотелось бы).  На рисунке представлена классическая структура иерархической базы данных. Вверху находится родитель (его ещё называют корневым элементом), ниже размещены дочерние элементы. Элементы с данными, находящиеся на одном уровне, можно назвать братьями либо соседними элементами. БД данной категории бывают с разным количеством уровней и разной степени вложенности.
На рисунке представлена классическая структура иерархической базы данных. Вверху находится родитель (его ещё называют корневым элементом), ниже размещены дочерние элементы. Элементы с данными, находящиеся на одном уровне, можно назвать братьями либо соседними элементами. БД данной категории бывают с разным количеством уровней и разной степени вложенности.
Сетевые базы данных, структура сетевых данных
В каком-то смысле сетевые базы данных — это своеобразная модификация иерархических баз данных. Разница заключается в том, что в структуре иерархических данных у дочернего элемента бывает лишь один потомок (к каждому элементу, расположенному ниже, идёт лишь одна стрелочка с элемента, размещённого выше). А вот в сетевых базах данных у дочернего элемента бывает несколько предков (элементов, находящихся выше него). Для наглядного понимания структуры сетевых данных смотрите очередной рисунок:  Следует отметить, что сетевые базы данных имеют примерно те же характеристики, что и иерархические данные. Однако в рамках этой статьи мы не будем углубляться в особенности управления сетевыми и иерархическими данными, а лучше подробнее поговорим о реляционных базах данных.
Следует отметить, что сетевые базы данных имеют примерно те же характеристики, что и иерархические данные. Однако в рамках этой статьи мы не будем углубляться в особенности управления сетевыми и иерархическими данными, а лучше подробнее поговорим о реляционных базах данных.
Реляционные базы данных, структура реляционных данных
Реляционные базы данных сегодня распространены очень широко, поэтому в сети можно найти огромное количество материалов на соответствующую тему разного уровня сложности. Кроме того, их проходят на уроках информатики, плюс эти БД хорошо описываются в математике. Структуру данных впервые подробно описал математик Эдгар Франк Кодд (умер в 2003 году), сделав это ещё в 80-х гг. прошлого века. В результате его работ и была создана программная реализация. Реляционные БД стали активно развиваться, поэтому сегодня каждый, кто знаком с базами данных, знает реляционные БД.
Особенности реляционных данных
Главная особенность — все объекты хранятся в виде набора 2-мерных таблиц. Каждая таблица включает в себя набор столбцов, где указываются следующие параметры: — название; — тип данных (число, строка и т. д.).
Вторая важная особенность заключается в том, что число столбцов фиксировано. Это значит, что структура БД известна заранее, при этом количество рядов либо строк данных практически не ограничено. Грубо говоря, строки в реляционных БД — есть объекты, хранимые в базе.
По большему счёту, БД — это абстрактное понятие, а в случае с реляционной структурой таблица — есть не более чем удобный способ хранения информации. Причём набор таблиц превращается в базу данных тогда, когда он связан логически. А чтобы этим всем управлять, используют СУБД. Классический пример СУБД — система управления MySQL. Иными словами, СУБД MySQL — есть программное воплощение математических идей.
Проектирование баз данных
Проектирование — самая трудная задача при работе с данными. Оно заключается не только в том, чтобы создать таблицу, указав наименование столбцов и тип данных. Это гораздо более сложный процесс, требующий специализированных знаний и умений. Говоря о типах баз данных в столбцах, подразумевается, например, способ их записи, который бывает символьный (строковый), числовой, календарный, NULL.
Основная сложность заключается в том, что мощность наших компьютеров ограничена. И пока данных мало, таблиц и строк тоже немного, поэтому машина обрабатывает информацию достаточно быстро. Но с течением времени информации становится всё больше, что может стать причиной снижения быстродействия. Работа машины будет замедляться, времени на обработку запросов потребуется всё больше. Добавить новую запись в таблицу не станет проблемой для реляционной СУБД, а вот выборка данных может превратиться в весьма ресурсоёмкую операцию. Хотя, многое будет зависеть и от настроек СУБД.
Требования к проектированию БД
О видах и особенностях реляционных БД мы уже поговорили. Теперь давайте подробнее обсудим сложности их проектирования. В данном случае этот процесс начинается с постановки задач, исходя из нужных требований, особенностей использования, недостатков либо достоинств той либо иной системы управления. В случае с СУБД MySQL необходимо правильно составить общую структуру.
Требования обычно следующие: 1. База данных должна быть относительно простой в плане обработки информации. 2. Она должна быть максимально компактной и неизбыточной настолько, насколько это возможно без ущерба для функциональности.
Возможны и другие требования, причём нередко они противоречат друг другу. Именно поэтому важно найти оптимальный баланс с точки зрения архитектуры, учитывая назначение конечного продукта.
Так как проектирование — важнейший процесс, им занимается проектировщик. Обычно к работе привлекают профессиональных администраторов серверов либо архитекторов БД, имеющих большой практический опыт. Нужно четко понимать, что проектируется и какие результаты должны получиться на выходе. Это бывает непросто, так как, если речь идёт о серьёзных проектах, готовая структура может включать в себя десятки и сотни таблиц, которые бывают связаны друг с другом как простыми, так и замысловатыми способами.
Результат проектирования — диаграмма или схема. Это подробное схематическое описание, в котором указываются, какие данные будут храниться, сколько столбцов в таблице, тип столбцов в таблице, как связаны таблицы между собой и многое другое. При правильном и грамотном проектировании система будет работать стабильно и без сбоев. В обратном случае ожидайте проблем, так как нет ничего хуже, чем ошибиться на этапе построения архитектуры проекта.
Если вы хотите овладеть базами данных на высоком профессиональном уровне, записывайтесь на соответствующий курс в OTUS. Практикующие эксперты научат вас особенностям управления БД и тому, как эффективно взаимодействовать с любой реляционной СУБД, используя для этого язык структурированных запросов SQL.
Модели баз данных | Системы управления базами данных
СУБД используют различные модели данных. Самые старые системы можно разделить на иерархические и сетевые базы данных — это пререляционные модели.
В иерархической модели элементы организованы в структуры, связанные между собой иерархическими или древовидными связями. Родительский элемент может иметь несколько дочерних элементов. Но у дочернего элемента может быть только один предок.
«Система управления информацией» (Information Management System) компании IMB — пример иерархической СУБД.
Иерархическая модель организует данные в форме дерева с иерархией родительских и дочерних сегментов. Такая модель подразумевает возможность существования одинаковых (преимущественно дочерних) элементов. Данные здесь хранятся в серии записей с прикреплёнными к ним полями значений. Модель собирает вместе все экземпляры определённой записи в виде «типов записей» — они эквивалентны таблицам в реляционной модели, а отдельные записи — столбцам таблицы. Для создания связей между типами записей иерархическая модель использует отношения типа «родитель-потомок» вида 1:N. Это достигается путём использования древовидной структуры — она «позаимствована» из математики, как и теория множеств, используемая в реляционной модели.
Рассмотрим в качестве примера иерархической модели данных организацию, хранящую информацию о своём работнике: имя, номер сотрудника, отдел и зарплату. Организация также может хранить информацию о его детях, их имена и даты рождения.
Данные о сотруднике и его детях формируют иерархическую структуру, где информация о сотруднике – это родительский элемент, а информация о детях — дочерний элемент. Если у сотрудника три ребёнка, то с родительским элементом будут связаны три дочерних. В иерархической базе данных отношение «родитель-потомок» — это отношение «один ко многим». То есть у дочернего элемента не может быть больше одного предка.
Иерархические БД были популярны, начиная с конца 1960-х годов, когда компания IBM представила свою СУБД «Система управления информацией. Иерархическая схема состоит из типов записей и типов «родитель-потомок»:
- Запись — это набор значений полей.
- Записи одного типа группируются в типы записей.
- Отношения «родитель-потомок» — это отношения вида 1:N между двумя типами записей.
- Схема иерархической базы данных состоит из нескольких иерархических схем.
В сетевой модели данных у родительского элемента может быть несколько потомков, а у дочернего элемента — несколько предков. Записи в такой модели связаны списками с указателями. IDMS («Интегрированная система управления данными») от компании Computer Associates international Inc. — пример сетевой СУБД.
Иерархическая модель структурирует данные в виде древа записей, где есть один родительский элемент и несколько дочерних. Сетевая модель позволяет иметь несколько предков и потомков, формирующих решётчатую структуру.
Сетевая модель позволяет более естественно моделировать отношения между элементами. И хотя эта модель широко применялась на практике, она так и не стала доминантной по двум основным причинам. Во-первых, компания IBM решила не отказываться от иерархической модели в расширениях для своих продуктов, таких как IMS и DL/I. Во-вторых, через некоторое время её сменила реляционная модель, предлагавшая более высокоуровневый, декларативный интерфейс.
Популярность сетевой модели совпала с популярностью иерархической модели. Некоторые данные намного естественнее моделировать с несколькими предками для одного дочернего элемента. Сетевая модель как раз и позволяла моделировать отношения «многие ко многим». Её стандарты были формально определены в 1971 году на конференции по языкам систем обработки данных (CODASYL).
Основной элемент сетевой модели данных — набор, который состоит из типа «запись-владелец», имени набора и типа «запись-член». Запись подчинённого уровня («запись-член») может выполнять свою роль в нескольких наборах. Соответственно, поддерживается концепция нескольких родительских элементов.
Запись старшего уровня («запись-владелец») также может быть «членом» или «владельцем» в других наборах. Модель данных — это простая сеть, связи, типы пересечения записей (в IDMS они называются junction records, то есть «перекрёстные записи). А также наборы, которые могут их объединять. Таким образом, полная сеть представлена несколькими парными наборами.
В каждом из них один тип записи является «владельцем» (от него отходит «стрелка» связи), и один или более типов записи являются «членами» (на них указывает «стрелка»). Обычно в наборе существует отношение 1:М, но разрешено и отношение 1:1. Сетевая модель данных CODASYL основана на математической теории множеств.
Известные сетевые базы данных:
- TurboIMAGE;
- IDMS;
- Встроенная RDM;
- Серверная RDM.
В реляционной модели, в отличие от иерархической или сетевой, не существует физических отношений. Вся информация хранится в виде таблиц (отношений), состоящих из рядов и столбцов. А данные двух таблиц связаны общими столбцами, а не физическими ссылками или указателями. Для манипуляций с рядами данных существуют специальные операторы.
В отличие от двух других типов СУБД, в реляционных моделях данных нет необходимости просматривать все указатели, что облегчает выполнение запросов на выборку информации по сравнению с сетевыми и иерархическими СУБД. Это одна из основных причин, почему реляционная модель оказалась более удобна. Распространённые реляционные СУБД: Oracle, Sybase, DB2, Ingres, Informix и MS-SQL Server.
«В реляционной модели, как объекты, так и их отношения представлены только таблицами, и ничем более».
РСУБД — реляционная система управления базами данных, основанная на реляционной модели Э. Ф. Кодда. Она позволяет определять структурные аспекты данных, обработки отношений и их целостности. В такой базе информационное наполнение и отношения внутри него представлены в виде таблиц — наборов записей с общими полями.
Реляционные таблицы обладают следующими свойствами:
- Все значения атомарны.
- Каждый ряд уникален.
- Порядок столбцов не важен.
- Порядок рядов не важен.
- У каждого столбца есть своё уникальное имя.
Некоторые поля могут быть определены как ключевые. Это значит, что для ускорения поиска конкретных значений будет использоваться индексация. Когда поля двух различных таблиц получают данные из одного набора, можно использовать оператор JOIN для выбора связанных записей двух таблиц, сопоставив значения полей.
Часто у полей будет одно и то же имя в обеих таблицах. Например, таблица «Заказы» может содержать пары «ID-покупателя» и «код-товара». А в таблице «Товар» могут быть пары «код-товара» и «цена». Поэтому чтобы рассчитать чек для определённого покупателя, необходимо суммировать цену всех купленных им товаров, использовав JOIN в полях «код-товара» этих двух таблиц. Такие действия можно расширить до объединения нескольких полей в нескольких таблицах.
Поскольку отношения здесь определяются только временем поиска, реляционные базы данных классифицируются как динамические системы.
Первая модель данных, иерархическая, имеет древовидную структуру («родитель-потомок»), и поддерживает только отношения типа «один к одному» или «один ко многим». Эта модель позволяет быстро получать данные, но не отличается гибкостью. Иногда роль элемента (родителя или потомка) неясна и не подходит для иерархической модели.
Вторая, сетевая модель данных, имеет более гибкую структуру, чем иерархическая, и поддерживает отношения «многие ко многим». Но быстро становится слишком сложной и неудобной для управления.
Третья модель — реляционная — более гибкая, чем иерархическая и проще для управления, чем сетевая. Реляционная модель сегодня используется чаще всего.
Объект в реляционной модели определяется как позиция информации, хранимой в базе данных. Объект может быть осязаемым или неосязаемым. Примером осязаемого объекта может быть сотрудник организации, а примером неосязаемой сущности — учётная запись покупателя. Объекты определяются атрибутами — информационным отображением свойств объекта. Эти атрибуты также известны как столбцы, а группа столбцов — как ряд. Ряд также можно определить как экземпляр объекта.
Объекты связываются отношениями, основные типы которых можно определить следующим образом:
В этом виде отношений один объект связан с другим. Например, Менеджер -> Отдел.
У каждого менеджера может быть только один отдел, и наоборот.
В моделях данных отношение одного объекта с несколькими. Например, Сотрудник -> Отдел.
Каждый сотрудник может быть только в одном отделе, но в самом отделе может быть больше одного сотрудника.
В заданный момент времени объект может быть связан с любым другим. Например, Сотрудник -> Проект.
Сотрудник может участвовать в нескольких проектах, и каждый проект может объединять несколько сотрудников.
В реляционной модели объекты и их отношения представлены двухмерным массивом или таблицей.
Каждая таблица представляет объект.
Каждая таблица состоит из рядов и столбцов.
Отношения между объектами представлены столбцами.
Каждый столбец представляет атрибут объекта.
Значения столбцов выбираются из области или набора всех возможных значений.
Столбцы, которые используются для связи объектов, называются ключевыми. Есть два типа ключей — первичные и внешние.
Первичные служат для однозначного определения объекта. Внешний ключ — это первичный ключ одного объекта, существующий как атрибут в другой таблице.
Преимущества реляционной модели данных:
- Простота использования.
- Гибкость.
- Независимость данных.
- Безопасность.
- Простота практического применения.
- Слияние данных.
- Целостность данных.
Недостатки:
- Избыточность данных.
- Низкая производительность.
В последнее время на рынке СУБД появились продукты, представленные объектными и объектно-ориентированной моделью данных, такие как Gem Stone и Versant ОСУБД. Также производятся исследования в области многомерных и логических моделей данных.
Особенности объектно-ориентированных систем управления базами данных (ООСУБД):
- При интеграции возможностей базы данных с объектно-ориентированным языком программирования получается объектно-ориентированная СУБД.
- ООСУБД представляет данные как объекты одного или нескольких языков программирования.
- Такая система должна отвечать двум критериям: являться СУБД и должна быть объектно-ориентированной. То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.
- ООСУБД дают возможность моделирования данных в виде объектов.
А также поддержку классов объектов и наследование свойств и методов классов подклассами и их объектами.
На данный момент не существует общепринятого стандарта ООСУБД. Считается, что подобные модели данных находится на ранней стадии развития.
Примеры ООСУБД:
- D Gemstone;
- IRS;
- ORION;
- ONTOS.
Применение ООСУБД:
- В конструкторских и рассредоточенных базах данных, телекоммуникации, а также в таких научных областях, как физика высоких энергий и молекулярная биология.
- Используются в специализированных областях финансового сектора.
- Во встроенных системах, пакетном программном обеспечении и системах реального времени, чтобы у пользователей была возможность создавать объекты по своему выбору.
Данная публикация представляет собой перевод статьи «Types of Database Models | Database Management System» , подготовленной дружной командой проекта Интернет-технологии.ру
Базы данных: какие бывают | WebShake.RU

В статье рассказывается о роли баз данных в современных реалиях и сформировано определение. Помимо этого, указываются виды баз данных и их классификация на основе структуры хранения данных. MySQL как эталонная СУБД для хранения данных в интернет-пространстве.
Ещё до появления информационных технологий у людей возникала необходимость в упорядоченном хранении тех или иных данных. Для удобства их разделяли по определённому признаку, объединяли в группы, создавали иерархическое представление и применяли множество других способов.
С развитием компьютерной техники и интернета большинство методов, которые ранее использовались в библиотеках и архивах, были взяты за основу для хранения данных уже на носителях информации. В случае с интернет-пространствам данные хранятся на конкретном носителе, который присутствует в серверной машине. Сервер под размещение базы данных можно заказать у Rackstore тут.
База данных с точки зрения информатики — это хранение информации в упорядоченном виде, следуя определённой, заранее установленной разработчиком, системе.
Выделяются следующие виды баз данных по структуре:
- иерархические;
- сетевые;
- реляционные;
Рассмотрим каждый из них.
Иерархическая база данных
Под иерархической понимается такая база данных, в которой хранение данных и их структурирование осуществляется по принципу разделения элементов на родительские и дочерние. Преимуществом таких баз является лёгкость в чтении запрашиваемой информации и её быстрое предоставление пользователю.
Компьютер способен быстро ориентироваться в ней. Иерархический принцип взят за основу в структурировании файлов и папок в операционной системе Windows, а реестр хранит информацию о параметрах работы тех или иных приложений в структурированном иерархическим способом виде.
Все интернет-ресурсы также построены по иерархическому принципу, так как при его использовании ориентироваться в рамках сайта очень легко.
В качестве примера можно привести базу данных на языке XML, содержащую в себе очерки о состоянии сельского хозяйства в регионах России. В этом случае родительским элементом выступит государство, далее пойдёт разделение на субъекты, а в рамках субъектов будет своё разветвление. В данном случае от верхнего элемента к нижнему идёт строго одно обращение.
Сетевая база данных
Под сетевой базой данных понимается модифицированная иерархическая. Её особенность заключается в том, что элементы могут быть связаны с друг другом в нарушение иерархии. То есть дочерний элемент одновременно может иметь несколько предков.
В этом случае также примером выступает база данных на основе языка XML.
Реляционная база данных
Под данным типом баз данных понимается их представление в рамках двумерной таблицы. Она имеет несколько столбцов, в которых устанавливаются такие параметры, как, например, тип вводимых данных (текст, число, дата и др.).
Таблица здесь является способом хранения введённых в неё данных и способна реагировать на любые обращения со стороны СУБД. Главная проблема в работе с реляционными базами данных состоит в их правильном проектировании.
Во время проектирования базы данных следует учесть следующие два фактора:
- база данных должна быть компактной и не содержать избыточных компонентов;
- обработка базы данных должны происходить просто.
Проблема в том, что эти факторы друг другу противоречат. А ведь проектирование — важнейший момент при составлении базы данных и дальнейшей работе с ней. Заниматься им рекомендуется администратору сервера, обладающему определённым опытом.
В крупных проектах задействовано множество таблиц, которых может быть более сотни. При этом обойтись без них невозможно, если человек имеет дело с важным и сложным проектом.
Перед составлением таблицы следует составить диаграмму или схему, в которой содержится информация о видах хранимой информации, а также о типе данных, который лучше всего подойдёт для таких целей.
СУБД
Система управления базами данных — это термин, который не нужно расшифровывать. Она представляет собой встраивыемый модуль или полноценную программу, которая способна работать с данными и вносить изменения в базы.
Существует две модели СУБД — реляционная и безсхемная. О том, что такое реляционные базы данных, уже рассказано выше. Безсхемные СУБД основанные на принципах неструктурированного подхода избавляют программиста от проблем реляционной модели, в число которых входит низкая производительность и трудное масштабирование данных в горизонтальном формате.
Неструктурированные базы данных (NoSQL) создают структуру по ходу и убирают необходимость в создании жёстко определённых связей между данными. Здесь можно экспериментировать с разными способами доступа к тем или иным видам данных.
К реляционным базам данных относятся:
- SQLite;
- MySQL;
- PostgreSQL.
Из них наиболее распространённой является база данных MySQL, но остальные тоже имеют популярность и с ними можно столкнуться.
Принцип работы таких систем заключается в слежении за строгой структурой данных, которая представлена в виде комплекса таблиц. В свою очередь внутри таблицы есть ячейки и поля, которыми также управляет MySQL.
По принципу NoSQL работает база данных MongoDB. Они хранят все данные как единое целое в одной базе. При этом данные могут быть и одиночным объектом, но в то же время любой запрос не останется без ответа.
Каждая NoSQL имеет собственную систему запросов, что требует дополнительного изучения данной системы.
Сравнение SQL и NoSQL
- Если SQL-системы основаны исключительно на строгом представлении данных, то NoSQL-системы предоставляют свободу и способны работать с любым типом данных.
- SQL-системы стандартизированы, за счёт чего запросы формируются с использованием языка SQL. В то же время NoSQL-системы базируются на специфической для каждой из них технологии, что является недостатком.
- Масштабируемость. Обе СУБД способны обеспечить вертикальное масштабирование, то есть увеличить объём системных ресурсов на обработку данных. При этом NoSQL, будучи более новой разновидностью баз данных, позволяет применять простые методы горизонтального масштабирования.
- В плане надёжности SQL обладает уверенным лидерством.
- У SQL-баз есть качественная техническая поддержка за счёт их продолжительной истории, в то время как NoSQL-системы весьма молоды и и решить какую-либо проблему сложнее.
- Хранение данных и доступ к их структурам в рамках реляционных систем лучше всего происходит в SQL-системах.
Таким образом, хоть NoSQL и является стремительно развивающейся разновидностью систем управления базами данных, однако на данном этапе рекомендуется остановить свой выбор на SQL.
Надёжность SQL-систем, особенно MySQL, подтверждается временем и массовостью. Сегодня любой уважающий себя ресурс использует для хранения данных именно систему MySQL.
