
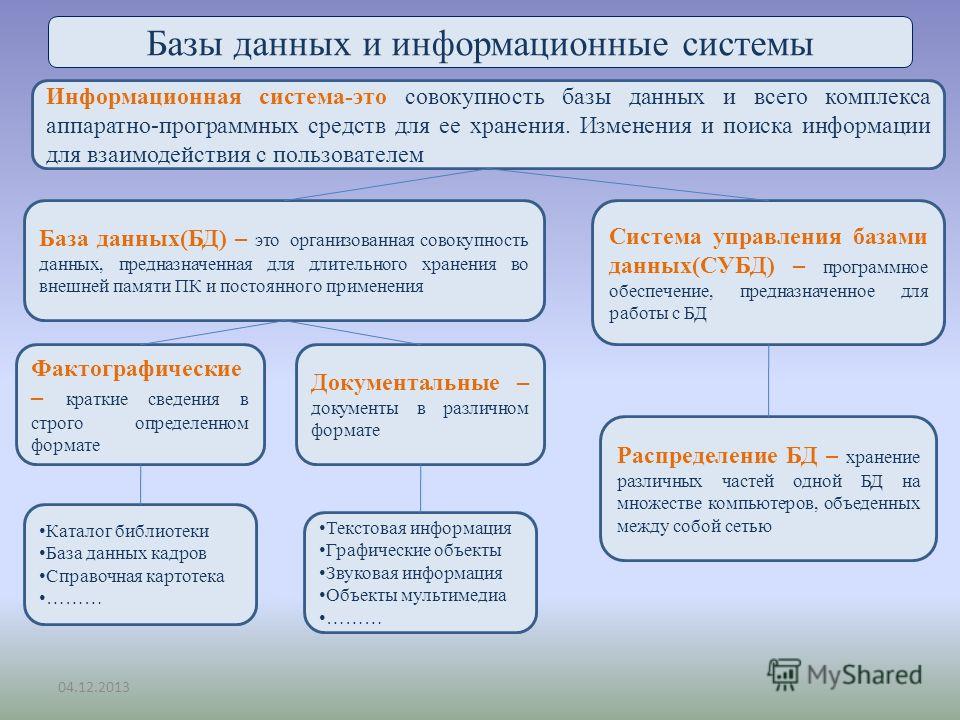
Что такое база данных | Oracle СНГ
База данных — определение
База данных — это упорядоченный набор структурированной информации или данных, которые обычно хранятся в электронном виде в компьютерной системе. База данных обычно управляется системой управления базами данных (СУБД). Данные вместе с СУБД, а также приложения, которые с ними связаны, называются системой баз данных, или, для краткости, просто базой данных.
Данные в наиболее распространенных типах современных баз данных обычно хранятся в виде строк и столбцов формирующих таблицу. Этими данными можно легко управлять, изменять, обновлять, контролировать и упорядочивать. В большинстве баз данных для записи и запросов данных используется язык структурированных запросов (SQL).
Подробнее о СУБД Oracle Database
Что такое язык структурированных запросов (SQL)?
SQL — это язык программирования, используемый в большинстве реляционных баз данных для запросов, обработки и определения данных, а также контроля доступа. SQL был разработан в IBM в 1970-х годах. Со временем у стандарта SQL ANSI появились многочисленные расширения разработанные такими компаниями как IBM, Oracle и Microsoft. Хотя в настоящее время SQL все еще широко используется, начали появляться новые языки программирования запросов.
SQL был разработан в IBM в 1970-х годах. Со временем у стандарта SQL ANSI появились многочисленные расширения разработанные такими компаниями как IBM, Oracle и Microsoft. Хотя в настоящее время SQL все еще широко используется, начали появляться новые языки программирования запросов.
Эволюция базы данных
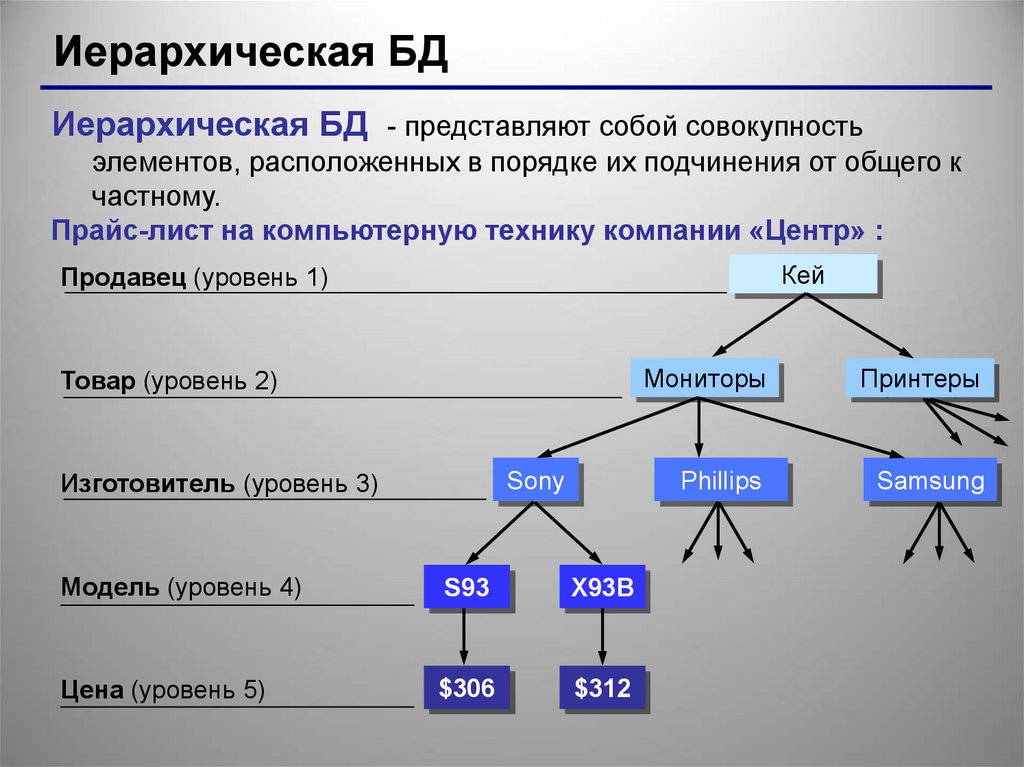
Базы данных значительно изменились с момента их появления в начале 1960-х годов. Исходными системами, которые использовались для хранения и обработки данных, были навигационные базы данных – например, иерархические базы данных (которые опирались на древовидную модель и допускали только отношение «один-ко-многим») и базы данных с сетевой структурой (более гибкая модель, допускающая множественные отношения). Несмотря на простоту, эти ранние системы были негибкими. В 1980-х годах стали популярными реляционные базы данных, в 1990-х годах за ними последовали объектно-ориентированные базы данных. Совсем недавно вследствие роста Интернета и возникновения необходимости анализа неструктурированных данных появились базы данных NoSQL.
В чем заключается различие между базой данных и электронной таблицей?
Базы данных и электронные таблицы (в частности, Microsoft Excel) предоставляют удобные способы хранения информации. Основные различия между ними заключаются в следующем.
- Способ хранения и обработки данных
- Полномочия доступа к данным
- Объем хранения данных
Электронные таблицы изначально разрабатывались для одного пользователя, и их свойства отражают это. Они отлично подходят для одного пользователя или небольшого числа пользователей, которым не нужно производить сложные операции с данными. С другой стороны, базы данных предназначены для хранения гораздо больших наборов упорядоченной информации иногда огромных объемов. Базы данных дают возможность множеству пользователей в одно и то же время быстро и безопасно получать доступ к данным и запрашивать их, используя развитую логику и язык запросов.
Типы баз данных
Существует множество различных типов баз данных. Выбор наилучшей базы данных для конкретной компании зависит от того, как она намеревается использовать данные.
- Реляционные базы данных стали преобладать в 1980-х годах. Данные в реляционной базе организованы в виде таблиц, состоящих из столбцов и строк. Реляционная СУБД обеспечивает быстрый и эффективный доступ к структурированной информации.
- Информация в объектно-ориентированной базе данных представлена в форме объекта, как в объектно-ориентированном программировании.
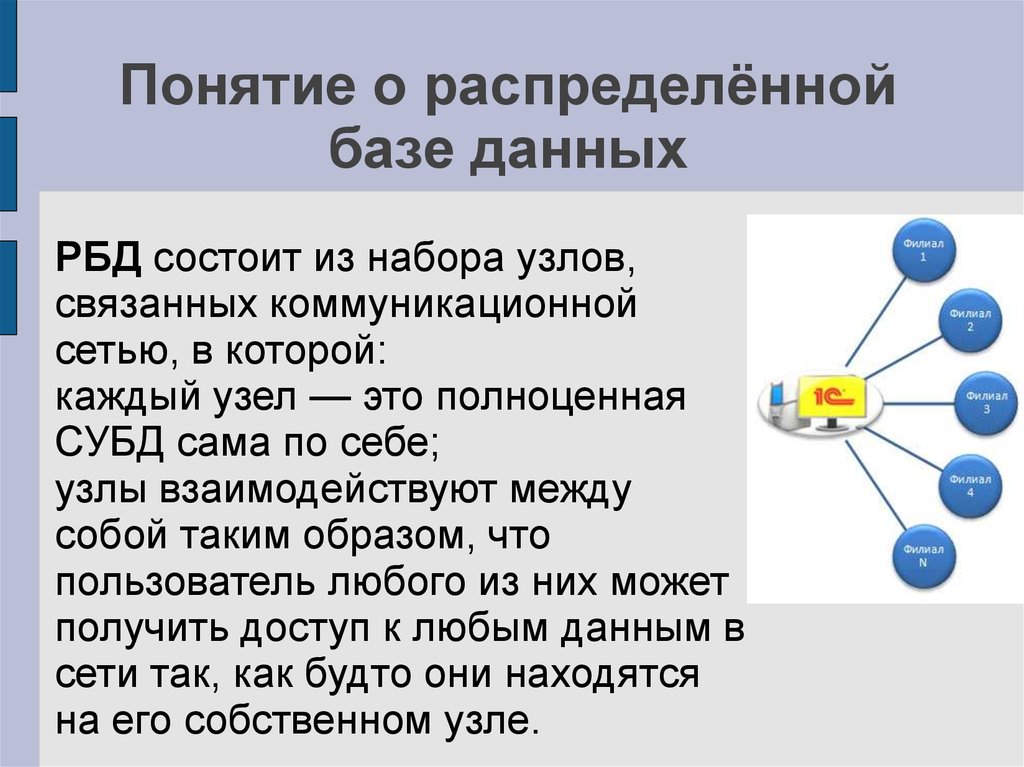
- Распределенная база данных состоит из двух или более частей, расположенных на разных серверах. Такая база данных может храниться на нескольких компьютерах.
- Будучи централизованным репозиторием для данных, хранилище данных представляет собой тип базы данных, специально предназначенной для быстрого выполнения запросов и анализа.

- База данных NoSQL, или нереляционная база данных, дает возможность хранить и обрабатывать неструктурированные или слабоструктурированные данные (в отличие от реляционной базы данных, задающей структуру содержащихся в ней данных). Популярность баз данных NoSQL растет по мере распространения и усложнения веб-приложений.
- Графовая база данных хранит данные в контексте сущностей и связей между сущностями.
- Базы данных OLTP. База данных OLTP — это база данных предназначенная для выполнения бизнес-транзакций, выполняемых множеством пользователей.
Реляционные базы данных
Объектно-ориентированные базы данных
Распределенные базы данных
Хранилища данных

Oracle NoSQL Database
Графовые базы данных
Это лишь некоторые из десятков типов баз данных, используемых в настоящее время. Другие, менее распространенные базы данных, предназначены для очень специфических научных, финансовых и иных задач. Помимо появления новых типов, базы данных развиваются в абсолютно новых направлениях — изменяются подходы к разработке технологий, происходят значительные сдвиги, такие как внедрение облачных технологий и автоматизации.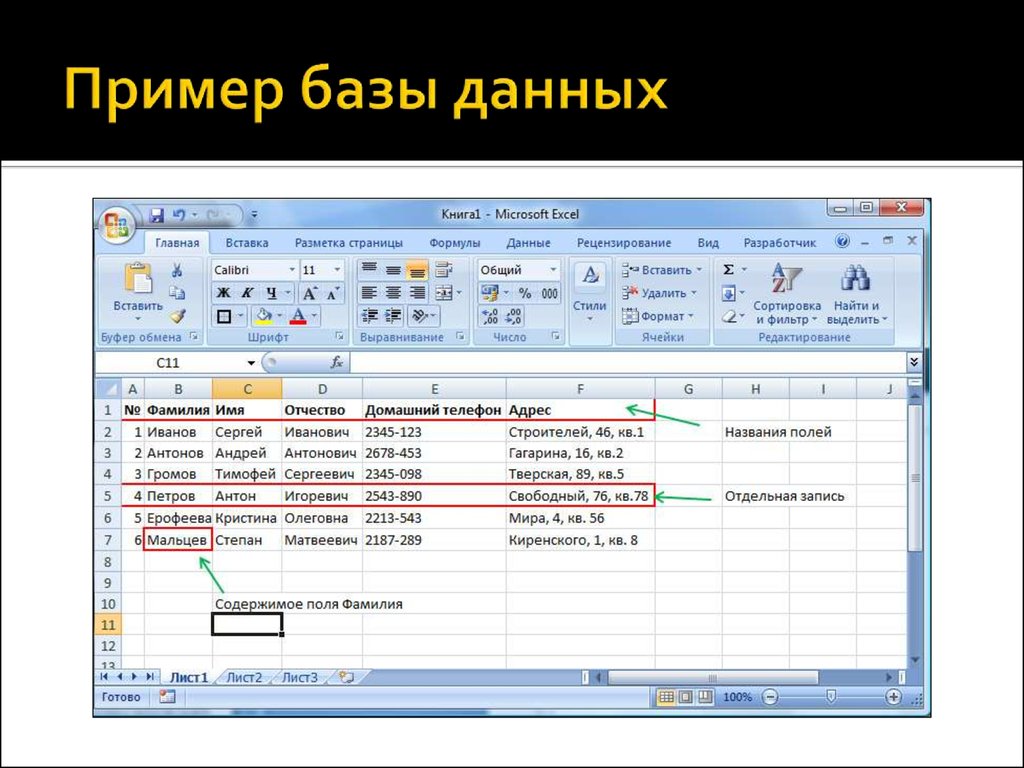
- Такие базы данных имеют открытый исходный код и могут управляться средствами как SQL, так и NoSQL.
- Облачная база данных представляет собой набор структурированных или неструктурированных данных, размещенный на частной, публичной или гибридной платформе облачных вычислений. Существует два типа моделей облачных баз данных: традиционная база данных и база данных как услуга (DBaaS). В модели DBaaS административные задачи и обслуживание выполняются поставщиком облачных услуг.
- Многомодельная база данных объединяет разные типы моделей баз данных в единую интегрированную серверную СУБД. Это означает, что она может содержать различные типы данных.
- Базы данных документов предназначены для хранения, извлечения и обработки документоориентированной информации и предоставляют современный способ хранения данных в формате JSON, а не в виде строк и столбцов.
- Самоуправляемые базы данных (также называемые автономными) — это новейшие и самые революционные облачные базы данных, которые используют машинное обучение для автоматизации настройки, защиты, резервного копирования, обновления и других стандартных задач обслуживания, обычно выполняемых администраторами баз данных.
Базы данных с открытым исходным кодом
Облачные базы данных
Многомодельные базы данных
Документные базы данных/JSON
Автономные базы данных
Подробнее об автономных базах данных
Что такое программное обеспечение базы данных?
Программное обеспечение базы данных используется для создания, редактирования и обслуживания файлов и записей базы данных, что упрощает создание файлов и записей, ввод данных, редактирование, обновление и отчетность. Программное обеспечение также помогает хранить данных, осуществлять резервное копирование и формировать отчетность, предоставлять управление множественным доступом и поддерживать безопасность. Сегодня надежная безопасность базы данных особенно важна, поскольку случаи кражи данных значительно участились. Программное обеспечение для баз данных иногда называют системой управления базами данных (СУБД).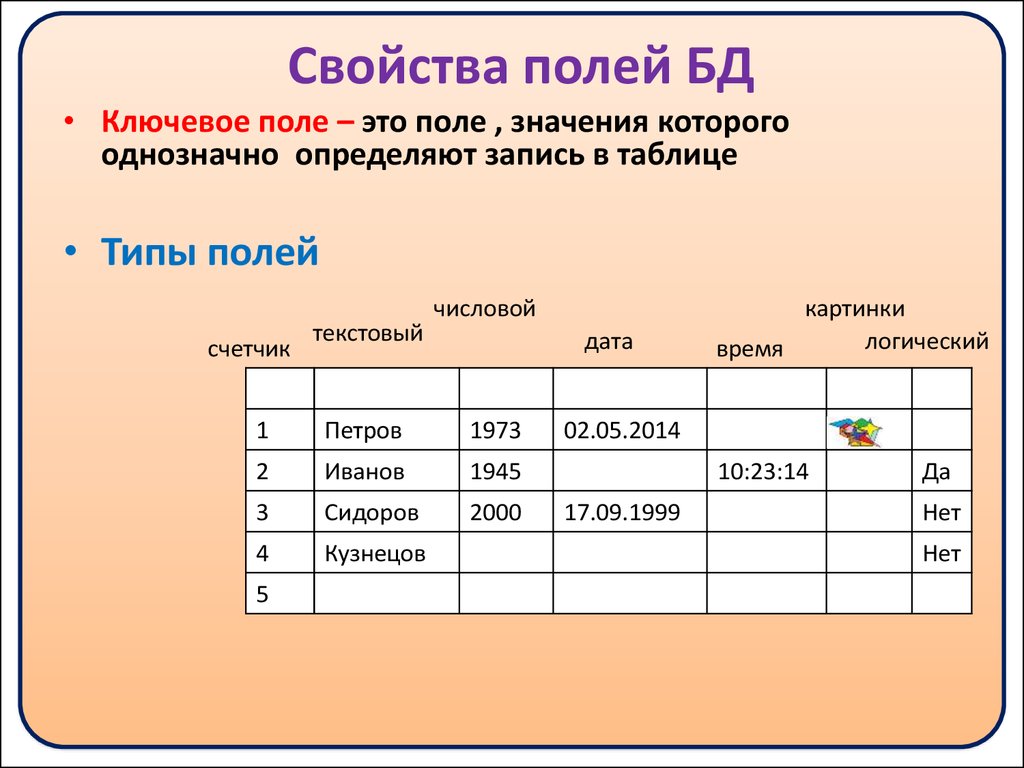
Программное обеспечение баз данных упрощает управление данными, помогая пользователям хранить данные в структурированной форме, а затем получать к ним доступ. Обычно программа имеет графический интерфейс, помогающий создавать данные и управлять ими, и в некоторых случаях пользователи могут создавать собственные базы данных с помощью такого ПО.
Что такое система управления базами данных (DBMS)?
Для базы данных обычно требуется комплексное программное обеспечение, которое называется системой управления базами данных (СУБД). СУБД служит интерфейсом между базой данных и пользователями или программами, предоставляя пользователям возможность получать и обновлять информацию, а также управлять ее упорядочением и оптимизацией. СУБД обеспечивает контроль и управление данными, позволяя выполнять различные административные операции, такие как мониторинг производительности, настройка, а также резервное копирование и восстановление.
В качестве примеров популярного программного обеспечения для управления базами данных, или СУБД, можно назвать MySQL, Microsoft Access, Microsoft SQL Server, FileMaker Pro, СУБД Oracle Database и dBASE.
Что такое база данных MySQL?
MySQL — это реляционная система управления базами данных с открытым исходным кодом на основе языка SQL. Она была разработана и оптимизирована для веб-приложений и может работать на многих платформах. Она обладает всеми возможностями которые требуются веб-разработчикам. База данных MySQL предназначена для обработки миллионов запросов и тысяч транзакций, поэтому ее часто выбирают компании электронной коммерции, которым требуется управлять большим количеством денежных переводов. Гибкость по мере необходимости — основная характеристика MySQL.
Многие ведущие веб-сайты и веб-приложения используют СУБД MySQL, в том числе Airbnb, Uber, LinkedIn, Facebook, Twitter и YouTube.
Подробнее о MySQL
Использование баз данных для повышения производительности бизнеса и улучшения процесса принятия решений
Обширный сбор данных из Интернета вещей меняет действительность и производственный сектор по всему миру: современные компании имеют доступ к большему количеству данных, чем когда-либо прежде.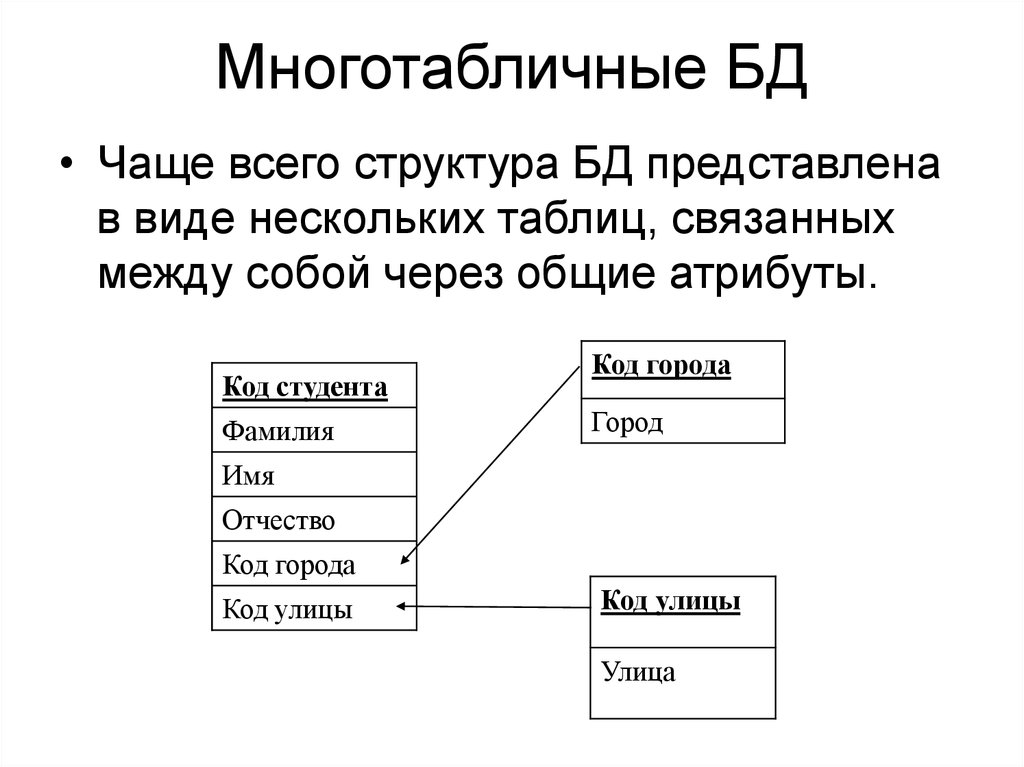
Автономная база данных способна значительно расширить эти возможности. Автономные базы данных автоматизируют дорогостоящие и длительные ручные процедуры, благодаря чему бизнес-пользователи могут сосредоточиться на работе со своими данными. За счет возможностей создания и использования баз данных пользователи приобретают контроль и автономию, поддерживая при этом важные стандарты безопасности.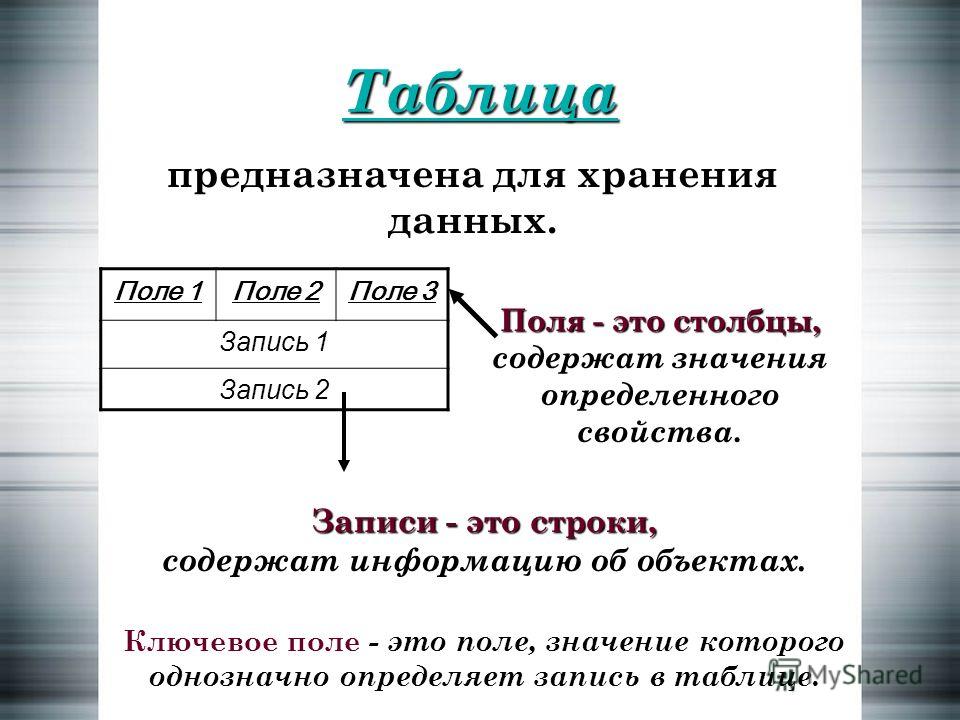
Задачи для баз данных
Современные крупные корпоративные базы данных нередко поддерживают очень сложные запросы, и предполагается, что они должны предоставлять почти мгновенные ответы на них. В результате администраторы баз данных вынуждены применять самые разные методы для повышения производительности. Вот некоторые из наиболее распространенных вызовов, с которыми они сталкиваются.
- Значительно возросшие объемы данных. Стремительный рост данных от датчиков, подключенных приборов и десятков других источников заставляет администраторов искать способы эффективного управления и упорядочивания данных своих компаний.
- Обеспечение безопасности данных. В наши дни регулярно случаются утечки данных и хакеры становятся все более изобретательными. Сейчас как никогда важно обеспечить защиту данных, но в то же время их легкую доступность для пользователей.
- Удовлетворение растущих потребностей. В современной, динамичной бизнес-среде компаниям необходим доступ к данным в режиме реального времени – для своевременного принятия решений и использования новых возможностей.
- Управление и обслуживание базы данных и инфраструктуры. Администраторы базы данных должны осуществлять постоянный мониторинг базы данных на наличие проблем, выполнять профилактическое обслуживание, а также устанавливать обновления и исправления программного обеспечения. Но базы данных становятся все более сложными, объемы данных растут, и компании сталкиваются с необходимостью привлечения дополнительных специалистов для мониторинга и настройки баз данных.
- Устранение границ масштабируемости. Если бизнес хочет выжить, он должен развиваться, и возможности управления данными должны расти вместе с ним. Но администраторам баз данных очень сложно предугадать, какие мощности потребуются компании, особенно при использовании локальных баз данных.
- Соблюдение требований к размещению данных, суверенитету данных и времени ожидания. Для одних компаний предпочтительнее, чтобы базы данных работали в локальной среде. В таких случаях идеальным вариантом являются готовые системы, настроенные и оптимизированные для размещения баз данных. При использовании Oracle Exadata заказчики достигают высокой доступности, повышают производительность и снижают затраты до 40 %.
 При использовании Oracle Exadata заказчики достигают высокой доступности, повышают производительность и снижают затраты до 40 %.
При использовании Oracle Exadata заказчики достигают высокой доступности, повышают производительность и снижают затраты до 40 %.Решение всех этих задач может занимать много времени и отвлекать администраторов баз данных от решения стратегических задач.
Как автономные технологии улучшают управление базами данных
Автономные базы данных — это модель будущего, представляющая исключительный интерес для компаний, которые хотят использовать лучшую из имеющихся технологий баз данных, при этом не сталкиваясь с проблемами при запуске и эксплуатации этой технологии.
Автономные базы данных используют облачные технологии и машинное обучение для автоматизации множества стандартных задач управления базами данных, таких как настройка, защита, резервное копирование, обновление и другие повседневные задачи администрирования. Благодаря автоматизации этой рутины администраторы баз данных могут сосредоточиться на более стратегической работе. Возможности самоуправления, самозащиты и самовосстановления автономных баз данных могут радикально изменить способы управления и защиты данных, улучшая эффективность, снижая затраты и повышая безопасность.
Будущее баз данных и автономных баз данных
О выходе первой автономной базы данных было объявлено в конце 2017 года, и многие независимые отраслевые аналитики быстро оценили возможности этой технологии и ее потенциальное воздействие на обработку данных.
Дополнительные продукты
- Oracle Autonomous Database
- СУБД Oracle Database
- Oracle Exadata
- Oracle Autonomous Data Warehouse
Что такое База Данных (БД) / Хабр
База данных — это место для хранения данных. Используется в том числе в клиент-серверной архитектуре. Это все интернет-магазины, сайты кинотеатров или авиабилетов… Вы делаете заказ, а система сохраняет ваши данные в базе.
В этот статье я на простых примерах расскажу, что такое база данных и как она выглядит. А потом поясню некоторые термины из конкретной (реляционной) базы. Те, с которыми вы почти наверняка столкнетесь на работе.
Статья рассчитана на начинающих тестировщиков или аналитиков, то есть тех, кто будет работать с базой, но не на супер-глубоком уровне.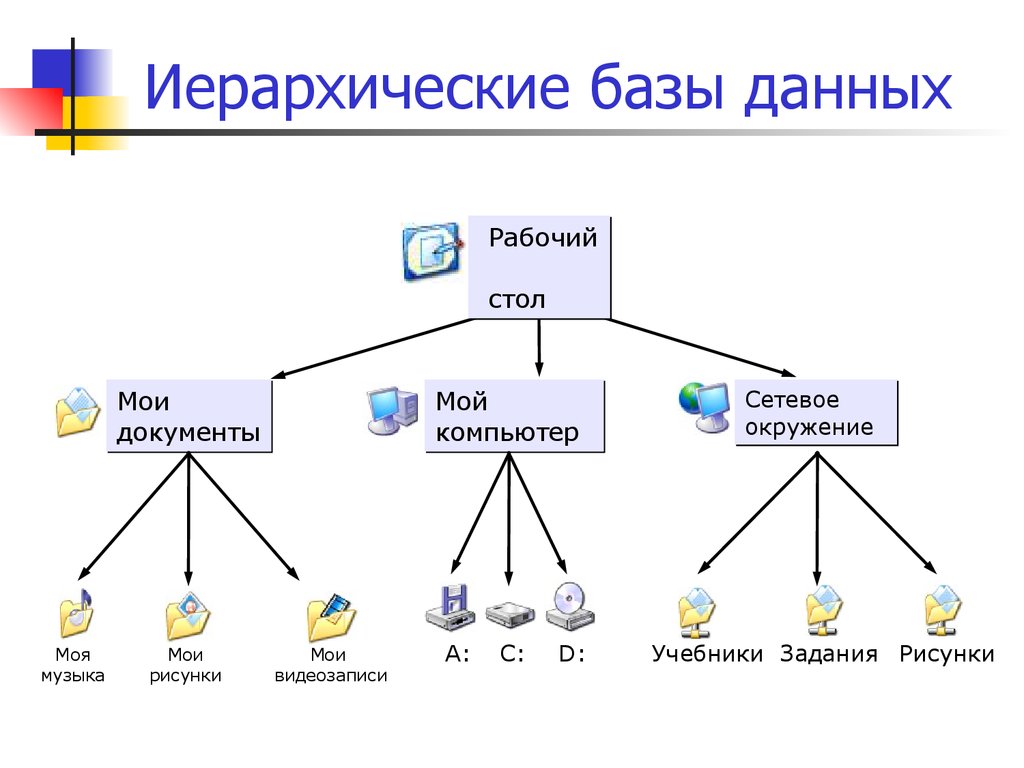 Она для тех, кто только входит в мир ИТ, и многого не знает. Она объясняет, что это за звено в клиент-серверной архитектуре такое, и зачем оно нужно.
Она для тех, кто только входит в мир ИТ, и многого не знает. Она объясняет, что это за звено в клиент-серверной архитектуре такое, и зачем оно нужно.
Содержание
Что такое база данных
Как она выглядит
Как получить информацию из базы
Как связать данные между собой
Зачем в базе индексы
Что делать, если запрос к БД тормозит
Преимущества базы данных
Что знать для собеседования
Статьи и книги по теме
Резюме
Что такое база данных
База данных — хранилище, куда приложение складывает свои данные. Если приложение небольшое, отдельная база не нужна. Но потом это становится удобнее и выгоднее с точки зрения памяти.
Катя решила открыть свой магазинчик. Она нашла хорошую марку обуви, которую «днем с огнем» не сыскать в ее городе. Заказала оптовую партию и стала потихоньку распродавать через знакомых.
 Пришлось освободить половину шкафа под коробки, но вроде всё поместилось.
Пришлось освободить половину шкафа под коробки, но вроде всё поместилось.Обувь хорошая, в розницу заказывать в других местах невыгодно — и вот уже у Кати есть постоянные клиенты, которые приводят друзей. Как только какая-то пара заканчивается, Катя делает новый заказ.
Но покупатели хотят новинок, разных размеров. Да и самих покупателей становится все больше и больше. В шкаф коробки уже не влезают!
Теперь, если покупатель просит определенную пару, Катьке сложно её найти. Пока коробок было мало, она помнила наизусть, где что лежит. А теперь уже нет, да и все попытки организовать систему провалились. Места мало, да и детки любят с коробками поиграть.
Тогда Катька решила арендовать складское помещение. И вот теперь красота! Не надо теснить своих домашних, дома чисто и свободно! И на складе место есть, появилась система — тут босоножки, тут сапоги…
Чем больше объемы производства, тем больше нужно места.
 Если в начале пути склад не нужен, всё поместится дома, то потом это будет оправданно.
Если в начале пути склад не нужен, всё поместится дома, то потом это будет оправданно.То же самое и в приложениях. Если приложение маленькое, то все данные можно хранить в памяти. Но учтите, что это память на вашем компьютере, вашем телефоне. И чем больше данных туда пихать, тем медленнее будет работать программа.
Место в памяти ограничено. Поэтому когда данных много, их нужно куда-то сложить. Можно писать в файлики, а можно сохранять информацию в базу данных (сокращенно БД). Выбор за вами. А точнее, за вашим разработчиком.
Как она выглядит
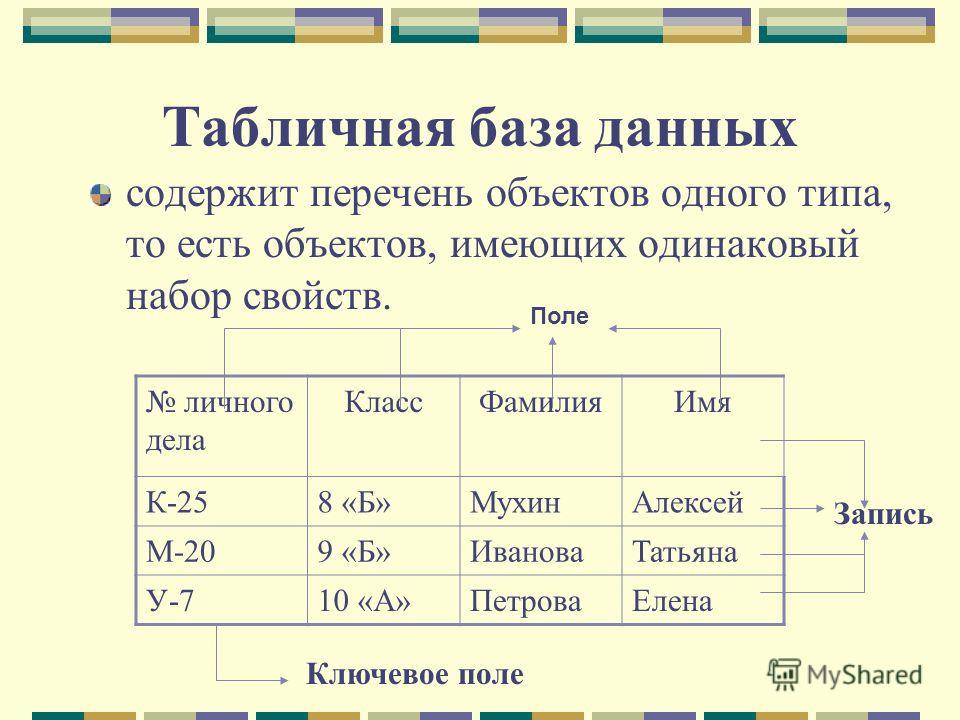
Да примерно как excel-табличка! Есть колонки с заголовками, и информация внутри:
Это называется реляционная база данных — набор таблиц, хранящихся в одном пространстве.
Что за пространство? Ну вот представьте, что вы храните все данные в excel. Можно запихать всю-всю-всю информацию в одну огро-о-о-о-мную таблицу, но это неудобно. Обычно табличек несколько: тут информация по клиентам, там по заказам, а тут по адресам. Эти таблицы удобно хранить в одном месте, поэтому кладем их в отдельную папочку:
Эти таблицы удобно хранить в одном месте, поэтому кладем их в отдельную папочку:
Так вот пространство внутри базы данных — это та же самая папочка в винде. Место, куда мы сложили свои таблички, чтобы они все были в одном месте.
Пример базы OracleЦель та же — выделить отдельное место, чтобы у вас не была одна большая свалка:
Хранение данных в виде табличек — это не единственно возможный вариант. Вот вам для примера запись из таблицы в системе Users. Там используется MongoDB база данных, она не реляционная. Поэтому вместо таблички «словно в excel» каждая запись хранится в виде объекта, вот так:
А еще есть файловые базы — когда у вас вся информация хранится в файликах. Да-да, простых текстовых файликах!
Почитать о разных видах баз данных можно в википедии. Я не буду в этой статье углубляться в эту тему, потому что моя задача — объяснить «что это вообще такое» для ребят, которые базу в глаза не видели. А на работе они скорее всего столкнутся именно с реляционной базой данных, поэтому о ней и речь.
Да, базы бывают разные. Классификацию можно изучить, можно выучить. Но по факту от начинающего тестировщика обычно нужно уметь достать информацию из реляционной БД («обычно» != «всегда», если что).
Как получить информацию из базы
Нужно записать свой запрос в понятном для базы виде — на SQL. SQL (Structured Query Language) — язык общения с базой данных. В нем есть ключевые слова, которые помогут вам сделать выборку:
select — выбери мне такие-то колонки…
from — из такой-то таблицы базы…
where — такую-то информацию…
Например, я хочу получить информацию по клиенту «Назина Ольга». Составляю в уме ТЗ:
Дай мне информацию по клиенту, у которого ФИО = «Назина Ольга»
Переделываю в SQL:
select * from clients where name = 'Назина Ольга';
В дословном переводе:
select -- выбери мне * -- все колонки (можно выбирать конкретные, а можно сразу все) from clients -- из таблицы clients where name = 'Назина Ольга'; -- где поле name имеет значение 'Назина Ольга'
См также:
Комментарии в Oracle/PLSQL — мой перевод остается работающим запросом, потому что я убрала «лишнее» в комментарии
Если бы у меня была не база данных, а простые excel-файлики, то же действие было бы:
Открыть файл с нужными данными (clients)
Поставить фильтр на колонку «ФИО» — «Назина Ольга».

То есть нам в любом случае надо знать название таблицы, где лежат данные, и название колонки, по которой фильтруем. Это не что-то страшное, что есть только в базе данных. То же самое есть в простом экселе.
Бывают запросы и сложнее — когда надо достать данные не из одной таблицы, а из разных. В базе это будет выглядеть даже лучше, чем в эксельке. В экселе вам нужно открыть 1-2-3 таблицы и смотреть в каждую. Неудобно.
А в базе данных вы внутри запроса SQL указываете, какие колонки из каких таблиц вам нужны. И результат запроса их отрисовывает. Скажем, мы хотим увидеть заказ, который сделал клиент, ФИО клиента, и его номер телефона. И всё это в разных таблицах! А мы написали запрос и увидели то, что нам надо:
id_order | order (таблица order) | fio (таблица client) | phone (таблица contacts) |
1 | Пицца «Маргарита» | Иванова Мария | +7 (926) 555-33-44 |
2 | Комбо набор 1 | Петров Павел | +7 (926) 555-22-33 |
И пусть в таблице клиентов у нас будет 30 колонок, а в таблице заказов 50, в результате выборки мы видим ровно 4 запрошенные.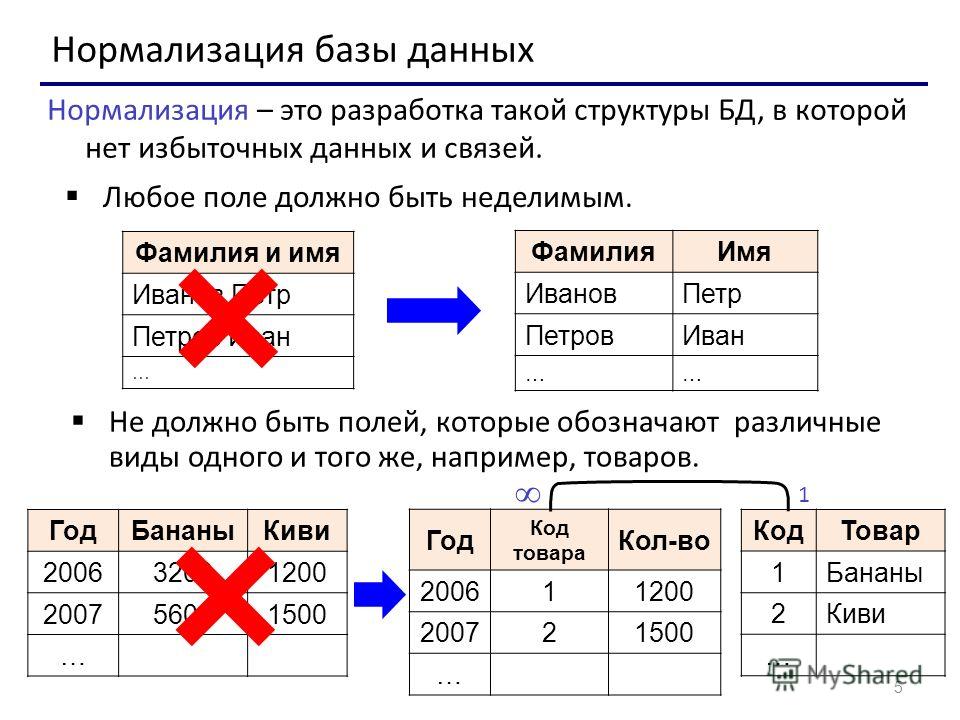 Удобно, ничего лишнего!
Удобно, ничего лишнего!
Конечно, написать такой запрос будет немного сложнее обычного селекта. Это уже select join, почитать о нем можно тут. И я рекомендую вам его изучить, потому что он входит в «базовое знание sql», которое требуется на собеседованиях.
Результаты выборки можно группировать, сортировать — это следующий уровень сложности. См раздел «статьи и книги по теме» для получения большей информации.
Как связать данные между собой
Вот например, у нас есть интернет-магазин по доставке пиццы. Так выглядит его база данных:
last_name | first_name | birthdate | VIP |
Иванов | Иван | 01.02.1977 | true |
Петрова | Мария | 02.04.1989 | false |
Сидоров | Павел | 03. | false |
Иванов | Вася | 04.04.1987 | false |
Ромашкина | Алина | 16.11.2000 | true |
 02.1991
02.1991В таблице «orders» лежат данные по заказам. Что заказали (пиццу, суши, роллы), когда, насколько довольны доставкой?
order | addr | date | time |
Пицца «Маргарита» | ул Ленина, д5 | 05.05.2020 | 06:00 |
Роллы «Филадельфия» и «Канада» | Студеный пр-д, д 10 | 15.08.2020 | 10:15 |
Пицца 35 см, роллы комбо 1 | Заревый, д10 | 08.09.2020 | 07:13 |
Пицца с сосиками по краям | Турчанинов, 6 | 08. | 08:00 |
Комбо набор 3, обед №4 | Яблочная ул, 20 | 08.09.2020 | 08:30 |
 09.2020
09.2020Но как понять, где чей был заказ? Сколько раз заказывал Вася, а сколько Алина?
Тут есть несколько вариантов:
1. Запихать все данные в одну таблицу: тут и заказы, и информация по клиентам… В целом удобно, открыл табличку и сразу видишь — ага, это Васин заказ, а это Машин.
Но есть минусы:
Таблица все растет и растет, в итоге получается просто огромной! А когда данных много, легкость чтения пропадает, придется листать до нужной колонки.
Поиск будет работать медленнее. Чем меньше информации в таблице, тем быстрее поиск. Когда у нас много строк, количество колонок становится существенным.
Много дублей — один человек может сделать хоть сотню заказов. И вся информация по нему будет продублирована сто раз. Неоптимальненько!
Чтобы избежать дублей, таблицы принято разделять:
Но надо при этом их как-то связать между собой, мы ведь всё еще хотим знать, чей конкретно был заказ. Для связи таблиц используется foreign key, внешний ключ.
Для связи таблиц используется foreign key, внешний ключ.
Нам надо у заказа сделать отметку о клиенте. Значит, таблица «orders» будет ссылаться на таблицу «clients». Ключ можно поставить на любую колонку таблицы (в некоторых базах колонка должна быть уникальной, сначала её нужно такой указать). Какую бы выбрать?
Можно ссылаться на имя. А что, миленько, в таблице заказов будем сразу имя видеть! Но минуточку… А если у нас два клиента Ивана? Или три Маши? Десять Саш… Ну вы поняли =) И как тогда разобраться, где какой клиент? Не подходит!
Можно вешать foreign key на несколько колонок. Например, на фамилию + имя, или фамилию + имя + отчество. Но ведь и ФИО бывают неуникальные! Что тогда? Можно добавить в связку дату рождения. Тогда шанс ошибиться будет минимален, хотя и такие ребята существуют. И чем больше клиентов у вас будет, тем больше шанс встретить дубликат.
А можно не усложнять! Вместо того, чтобы делать внешний ключ на 10 колонок, лучше создать в таблице клиентов primary key, первичный ключ. Первичный ключ отвечает за то, чтобы каждое значение в поле было уникальным, никаких дублей. При попытке добавить в таблицу запись с неуникальным первичным ключом получаешь ошибку:
Первичный ключ отвечает за то, чтобы каждое значение в поле было уникальным, никаких дублей. При попытке добавить в таблицу запись с неуникальным первичным ключом получаешь ошибку:
Вот на него и нужно ссылаться! Обычно таким ключом является ID, идентификатор записи. Его можно сделать автоинкрементальным — это значит, что он генерируется сам по алгоритму «прошлое значение + 1».
Например, у нас гостиница для котиков. Это когда хозяева едут в отпуск, а котика оставить не с кем — оставляем в гостинице!
Есть таблица постояльцев:
ID | name | year |
1 | Барсик | 2 |
2 | Пупсик | 1 |
Тут привозят еще одного Барсика. Добавляем его в таблицу:
— Имя Барсик, 5 лет! (мы не указываем ID)
Система добавляет:
ID | name | year |
1 | Барсик | 2 |
2 | Пупсик | 1 |
3 | Барсик | 5 |
ID сгенерился автоматически.
Теперь, если в другой таблице надо будет сослаться на котика, мы будем делать это именно через уникальный идентификатор. Например, у нас есть таблица комнат для постояльцев, куда мы заносим информацию о том, кто там живет:
 Последнее значение было 2, значит, новый Барсик получил номер 3. Обратите внимание — Барсиков уже два, но их легко различить, ведь у них разные идентификаторы!
Последнее значение было 2, значит, новый Барсик получил номер 3. Обратите внимание — Барсиков уже два, но их легко различить, ведь у них разные идентификаторы!id_room | square | id_cat (ссылка на id в таблице котиков) |
1 | 5 | 1 |
2 | 10 | 2 |
3 | 10 |
|
Мы видим, что в первой комнате живет котик с id = 1, а во второй — с id = 2. В третьей комнате пока никто не живет. Так, благодаря связке таблиц, мы всегда можем понять, что именно за котофей там проживает.
Итак, теперь мы знаем, что идентификатор лучше делать первичным ключом, дабы обеспечить его уникальность. Можно сделать поле автоинкрементальным, чтобы оно заполнялось само. Так и поступим в таблице клиентов:
Можно сделать поле автоинкрементальным, чтобы оно заполнялось само. Так и поступим в таблице клиентов:
И в таблице заказов! «id_order» пусть генерится сам и всегда будет уникален. А еще в таблицу заказов мы добавим колонку «id_client» и повесим на нее foreign key, ссылку на «id_client» в таблице клиентов.
Ключей может быть несколько. Одна таблица может ссылаться на несколько других. Скажем, в заказе мы ссылаемся на клиента и поставщика.
И наоборот, несколько таблиц могут ссылаться на одну и ту же колонку текущей таблицы. ID клиента мы можем указывать в таблице адресов, телефонов, email адресов, документов, заказов… Ограничений на это нет.
Зачем в базе индексы
Давайте представим, что у нас есть табличка excel. Если она небольшая (пара строк, пара колонок), то найти нужную ячейку не составит труда:
Открыли файлик — открывается моментально (если нет проблем с жестким диском)
Нажали «Ctrl + F», ввели запрос — тут же нашли результат.

Но что, если у нас сотни колонок и миллионы строк в файлике? Тогда начинаются тормоза. Файл открывается долго, в поиск значение ввели и система подвисла, обрабатывая результат…
Всё то же самое и в базе данных. Если табличка маленькая, любой запрос к ней отработает моментально. Если же таблица будет большая и с кучей данных, то результата запроса можно ждать минут по 15. А иногда и пару часов!
Если вы заранее знаете, что данных в базе будет много, нужно продумать основные сценарии поиска. И на колонки, по которым будете искать, нужно повесить индексы.
Индекс — это как алфавитный указатель в библиотеке. Вот представьте, заходите вы в библиотеку и хотите найти «Преступление и наказание» Достоевского. А все книги стоят «от балды», никакого порядка. Чтобы найти нужную, надо обойти все стелажи и просмотреть все полки!
Совсем другое дело, если книги отсортированы по авторам. А внутри автора — по названию. Тогда найти нужную книгу будет легко!
Индекс играет ту же роль для базы данных. Если повесить его на колонку таблицы, поиск по ней пойдет быстрее!
Если повесить его на колонку таблицы, поиск по ней пойдет быстрее!
А можно повесить индекс на несколько нужных колонок (автор + название). Тут главное — не забывать порядок поиска в индексе. Если у нас индекс сначала по автору, а потом по названию, он будет бесполезен для поиска по названию, придется все равно пересматривать все книги. Поэтому, если нам часто нужно искать по названию и почти никогда — только по автору, имеет смысл поменять порядок в индексе — сначала название, потом автор.
Что делать, если запрос к БД тормозит
Если мы говорим о тестировщиках (а статья написана в первую очередь для них), то тут есть 2 варианта:
Вы работаете с базой напрямую, составляете запросы к ней. И эти запросы работают медленно.
Медленно работает система, но уже поняли, что тормозит выборка из БД (например, увидели в логах).
Первый вариант мы разбирать не будем. Потому что это не про базу, а про SQL. И, если вы работаете с базой, то должны уметь писать сложные запросы, применять хинты там, где нужно, и так далее. Это не тема базовой статьи.
Это не тема базовой статьи.
А вот что делать во втором случае? Это не задача тестировщика — разбираться в том, почему запрос работает медленно. Этим занимаются DBA (администраторы баз данных) или разработчики.
Зато задача тестировщика — предоставить разработчику всю нужную информацию. Иногда её можно запросить у заказчика и его админов, а иногда нужно достать самому. Обычно для этого нужно:
Получить план запроса
Пересобрать статистику и проверить, продолжает ли тормозить
План запроса
Смотрите, когда вы выполняете любой запрос, что делает система:
Строит план выполнения запроса (как ей кажется, оптимальный)
Выполняет его
Посмотреть план можно через ключевые слова. В Oracle это EXPLAIN PLAN:
EXPLAIN PLAN FOR -- построй мне план для... SELECT last_name FROM employees; -- вот такого запроса!
А если вы работаете через графический интерфейс, то там обычно можно просто выделить запрос и нажать горячую клавишу. Выглядит ответ примерно так:
Выглядит ответ примерно так:
Сверху на картинке идёт запрос. А снизу — план его выполнения. Нас сейчас не сильно волнует, что значит информация из первых колонок (то, как именно запрос обходит базу, в данном случае фулл-скан по таблице), нас интересует последняя колонка, «COST». Это стоимость запроса — 857 ms.
А теперь изменим запрос, сделав выборку по одному конкретному человеку по колонке с индексом:
Оп, цена запроса уже 5 ms. Это, на минуточку, в 170 раз быстрее!
И это простейший запрос на тестовой базе. В реальной базе данных будет сильно больше, поэтому проход таблицы по индексированной колонке существенно сократит время выполнения запроса.
Вот пример плана чуть более сложного запроса, когда мы делаем выборку из двух таблиц:
Вы не обязаны понимать, «что тут вообще происходит», но вам нужно уметь получать этот план. Пригодится.
Допустим, поступает жалоба от заказчика — клиент открывает карточку в вебе, а она открывается минуту. Что-то где-то тормозит! Но что и где? Начинаем разбираться. Причины бывают разные:
Что-то где-то тормозит! Но что и где? Начинаем разбираться. Причины бывают разные:
Тормозит на уровне БД — тут или сам запрос долго отрабатывает, или статистику давно не пересобирали, или диски подыхают.
Тормозит на уровне приложения — тогда надо копаться внутри кода функции «открыть карточку», что она там делает, получив ответ от Базы (и снова есть вариант «подыхают диски, на которых установлено ПО»).
Тормозит на уровне сети — сервер приложения и сервер БД обычно размещают на разных машинах. Значит, есть общение между ними по интернету. А интернет может тупить.
Если есть подозрение, что тормозит сам select, разработчик попросит прислать план его выполнения на реальной базе. Конечно, если «с той стороны» грамотные админы, они это сделают сами. Но иногда это нужно уметь вам. Например, если вас отправили в банк разбираться на месте, что пошло не так. Вы проверяете разные гипотезы и собираете информацию для разработчика.
Собираете план, сохраняете в файлик и прикладываете в задачу в джире. Или отправляете по почте.
У меня бывало, что именно так находился баг — на тестовой базе запрос идет по правильному пути, а на боевой — нет. И на боевой идет не по индексам, что сильно его тормозит. Тут уже дальше разработчик думает, почему так получилось и как именно это исправить.
Статистика в БД
Именно статистика позволяет базе данных выбрать оптимальный план выполнения запроса. Почему вообще возникают проблемы вида «на тестовой базе один план, на боевой другой»?
Да потому, что один и тот же запрос можно выполнить несколькими способами. Например, у нас есть таблица клиентов и таблица телефонов, и мы пишем такой запрос:
Найди мне всех клиентов, созданных в этом году,
У которых оператор связи в телефоне — Мегафон
Как можно выполнить запрос? Можно сначала обойти таблицу клиентов и поискать тех, кто создан в этом году. А потом уже для них проверять телефоны. Можно наоборот, проверить все телефоны на оператора и потом уже для связанных клиентов проверять дату создания.
А потом уже для них проверять телефоны. Можно наоборот, проверить все телефоны на оператора и потом уже для связанных клиентов проверять дату создания.
Какой вариант будет лучше? Никто не скажет без данных по таблицам. Может, у нас мало клиентов, но кучи телефонов (база перекупщиков), тогда быстрее будет начать с клиентов. А может, у нас миллионы клиентов, но всего пара сотен телефонов, тогда мы начнем с них.
Так вот, в статистике по БД хранится в том числе информация о распределении данных и характеристики хранения таблиц и индексов. И когда вы запускаете запрос, база (а точнее, оптимизатор внутри нее) строит возможные планы выполнения. Для каждого плана рассчитывает примерное время выполнения, а потом выбирает лучшее.
Время же он рассчитывает, ориентируясь на статистику:
Именно поэтому просто пересбор статистики иногда убирает проблему «у нас тут тормозит». Прилетело в таблицу много данных, а статистика об этом не знает, и чешет по таблице через фуллскан, считая, что информации там мало.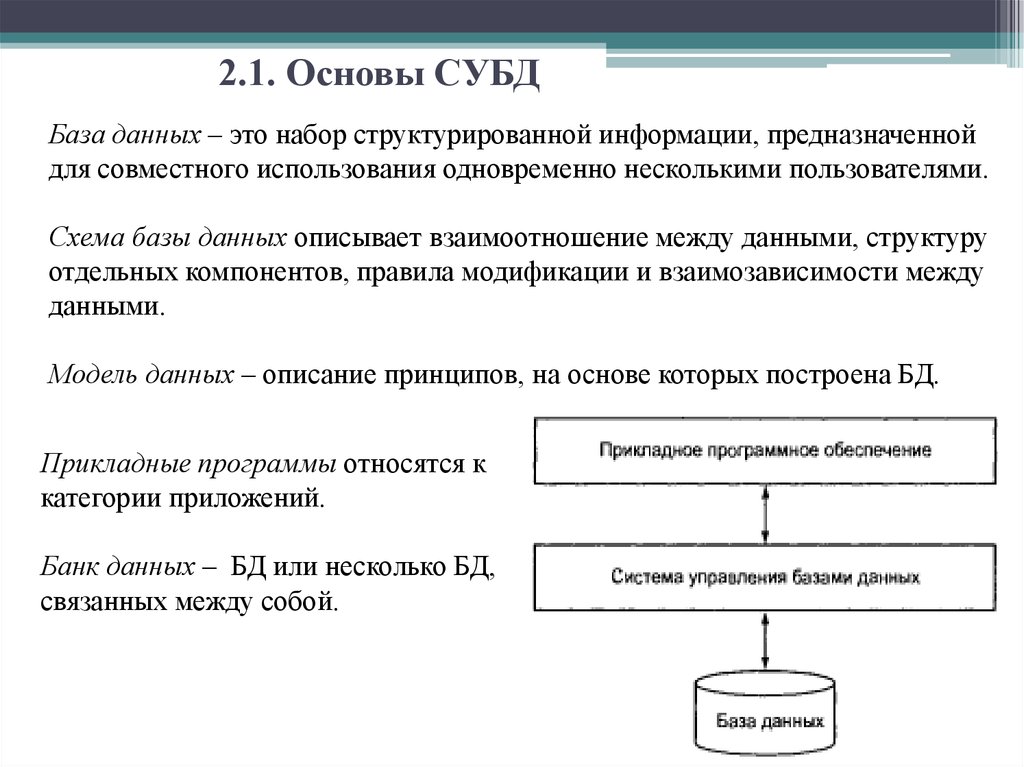
См также:
Ручной и автоматический сбор статистики оптимизатора в базе данных Oracle
Практические методы оптимизации запросов в Apache Spark — подробнее об оптимизации запросов, в том числе и про индексы
Преимущества реляционных баз данных
Почему используют реляционную базу данных:
Она поддерживают требования ACID (по крайней мере транзакционная БД)
Это единый синтаксис SQL, который используется повсеместно
Требования ACID
ACID — это аббревиатура из требований, которые обеспечивают сохранность ваших данных:
Atomicity — Атомарность
Consistency — Согласованность
Isolation — Изолированность
Durability — Надёжность
Если база данных не поддерживает их, то могут быть печальные последствия из серии «Деньги с одного счета ушли, на другой не пришли? Ну сорян, бывает».
См также:
Требования ACID на простом языке — подробнее об этих требованиях
Единый синтаксис SQL
Я спросила знакомого разработчика:
— Ну и что, что единый синтаксис? В чем его плюшка то?
Ответ прекрасен, так что делюсь с вами:
— Почему в школе все преподают на русском? Почему не каждый свой язык? Одна школа — один, другая — другой. А ещё лучше не школа, а для каждого человека. Почему вавилонскую башню недостроили?
Как разработчик пишет код? Написал, проверил на коленке. Если не работает — думает, почему. Если непонятно, идет гуглить похожие ошибки. А что проще нагуглить? Ошибку распространенной БД, или сделанный на коленке костыль для работы с файлами? Вот то-то и оно…
Что знать для собеседования
Для начала я хочу уточнить, что я сама тестировщик. И мои статьи в первую очередь для тестировщиков ))
Зато тестировщика спрашивают про SQL. Вот вам обсуждение из чатика выпускников, пригодится для повторения материала:
— В вакансии написано: уметь составлять простые SQL запросы. А простые это какие в народном понимании?
А простые это какие в народном понимании?
— (inner, outer) join, select, insert, update, create, последнее время популярны индексы, group by, having, distinct.
SQL выходит за рамки данной статьи, здесь я лишь пояснила, что это вообще такое. А дальше читайте статьи / книги из следующего раздела, или гуглите каждое слово из цитаты выше.
Статьи и книги по теме
База данных
Википедия
Какие бывают базы данных
Базы данных. Виды и типы баз данных. Структура реляционных баз данных. Проектирование баз данных. Сетевые и иерархические базы данных.
SQL
Книги:
Изучаем SQL. Линн Бейли — Обожаю эту линейку книг, серию Head First O`Reilly. И всем рекомендую)) Просто и доступно даже о сложном пишут.
Статьи:
Как изучить основы SQL за 2 дня
Полезные запросы
Тренажеры:
http://www.sql-ex.ru/ — Бесплатный тренажер для практики
Ресурсы и инструменты для практики с базами данных | SQL
Задачка по SQL. Найти объединенные данные
Найти объединенные данные
Резюме
База данных — это место для хранения данных. Они бывают самых разных видов, даже файловые! Но самые распространенные — реляционные базы данных, где данные хранятся в виде таблиц.
Если посмотреть на информацию о таблице в БД, мы можем увидеть ее ключи и индексы. Что это такое:
1. PK — primary key, первичный ключ. Гарантирует уникальность данных, часто используется для колонки с ID. Если ключ наложен на одну колонку — каждое значение в ячейках этой колонки уникальное. Если на несколько — комбинации строк по колонкам уникальны.
2. FK — foreign key, внешний ключ. Нужен для связки двух таблиц в разных соотношениях (1:1, 1:N, N:N). Этот ключ указываем в «дочерней» таблице, то есть в той, которая ссылается на родительскую (в таблице с данными по лицевому счету отсылка на client_id из таблицы клиентов).
3. Индекс. Нужен для ускорения выборки из таблицы.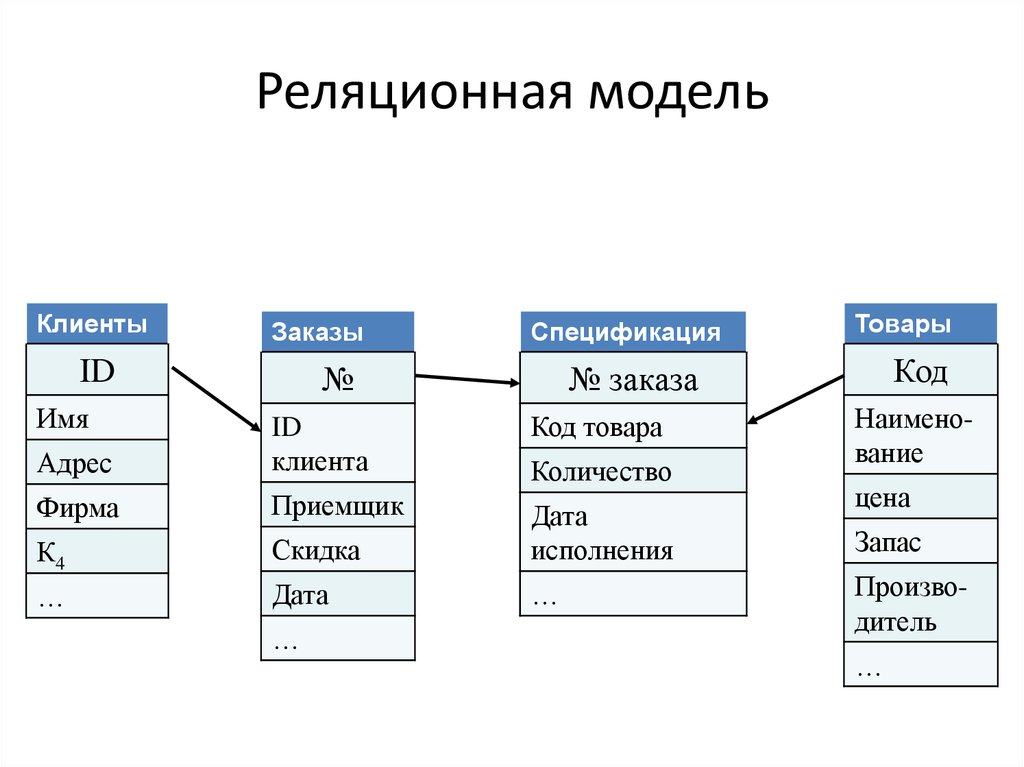
Транзакционные базы данных выполняют требования ACID:
Atomicity — Атомарность
Consistency — Согласованность
Isolation — Изолированность
Durability — Надежность
См также:
Что такое транзакция
И за это их выбирают разработчики. Мы получаем не просто хранилище данных. Наши данные защищены от неприятностей типа отключения электричества на середине бизнес-операции (с одного счета деньги списать, на другой записать). А еще по ним можно быстро искать, ведь разработчики баз данных оптимизируют свои приложения для этого.
Поэтому логика приложения — отдельно, база — отдельно. Так и получается клиент-серверная архитектура =)
См также:
Клиент-серверная архитектура в картинках
Чтобы достать данные из базы, надо написать запрос к ней на языке SQL (Structured Query Language).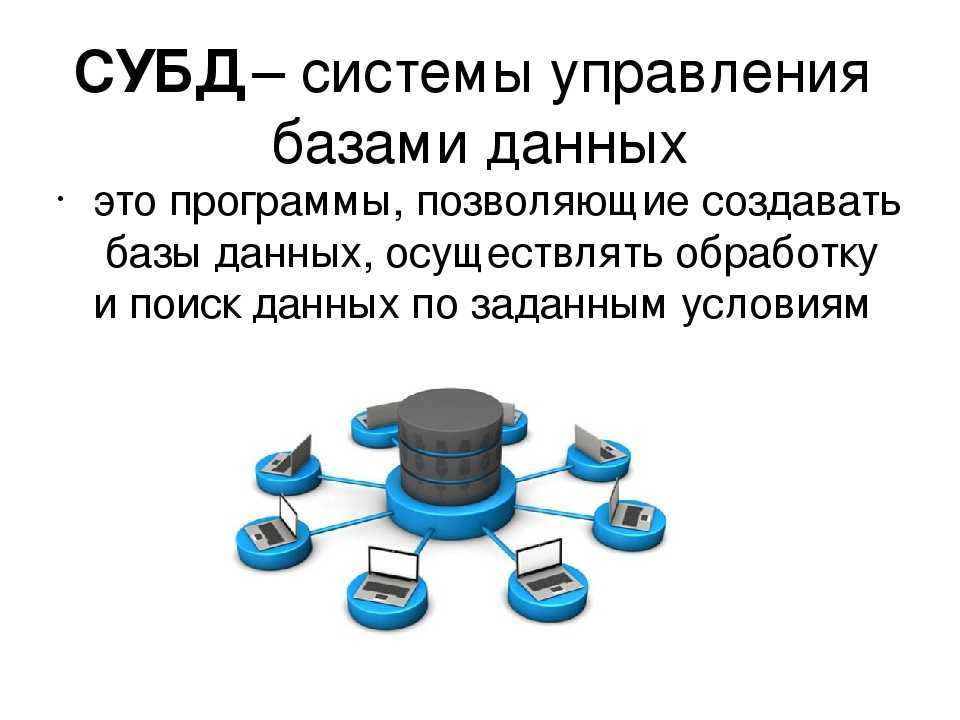 Разработчики пишут SQL-запросы внутри кода приложения. А тестировщики используют SQL для:
Разработчики пишут SQL-запросы внутри кода приложения. А тестировщики используют SQL для:
Поиска по базе — правильно ли данные сохранились? В нужные таблицы легли? Это select-запросы.
Подготовки тестовых данных — а что, если это значение будет пустое? А что, если у меня будет 2 лицевых счета на одной карточке? Можно готовить данные через графический интерфейс, но намного быстрее отправить несколько запросов в базу. Когда есть к ней доступ и вы знаете SQL =)
План-минимум для изучения: select, join, insert, update, create, delete, group by, having, distinct.
PS — больше полезных статей ищите в моем блоге по метке «полезное». А полезные видео — на моем youtube-канале
Так вот, тестировщика на собеседовании не будут спрашивать про базы данных. Разработчика ещё могут спросить, а вас то зачем? Вполне достаточно понимания, что это вообще такое. И про ключи могут спросить — что такое primary или foreign key, зачем они вообще нужны.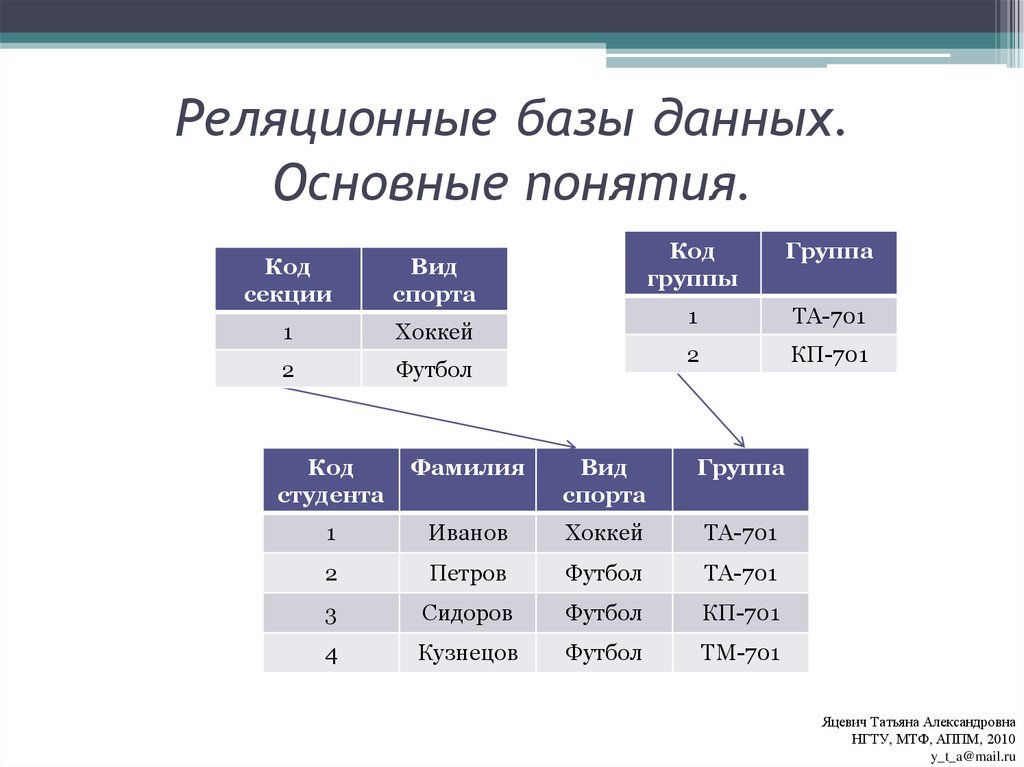
Что такое базы данных? | Microsoft Azure
Определения, типы и примеры баз данных
Что такое базы данных?
В самом широком определении база данных — это любой набор взаимосвязанной информации. Когда вы пишете список покупок на листе бумаги, вы создаете небольшой аналог базы данных. Но каково определение базы данных в информатике? В этом контексте база данных представляет собой информацию, которая хранится в виде данных в компьютерной системе, наподобие перечня товаров в местном продуктовом магазине.
Для чего используются базы данных?
Базы данных используются для хранения и упорядочения данных, чтобы упростить управление ими и доступ к ним. Так как набор таких данных растет и работа с ними усложняется, становится гораздо труднее организовать их, а также обеспечить их доступность и безопасность. Для этого используются системы управления базами данных (СУБД), которые включают в себя слой средств управления.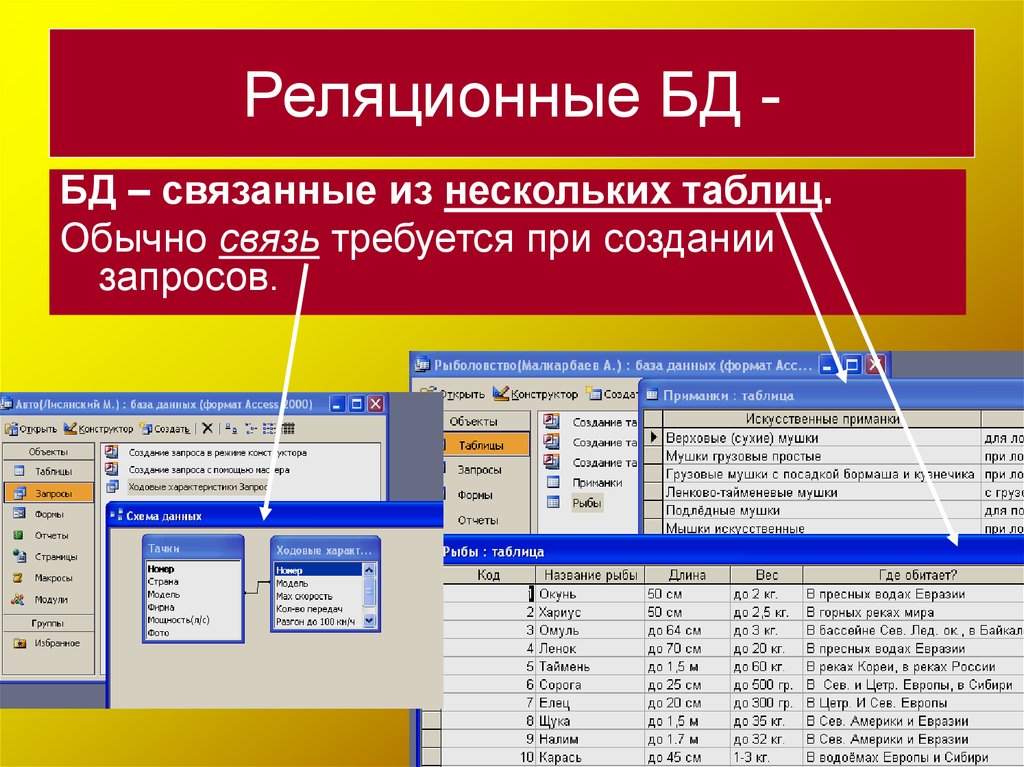
Что такое данные?
Данные — это любая записываемая и хранимая информация об отдельном человеке, месте, предмете или объекте — это называется сущностью, — а также атрибуты этой сущности.
Например, если вы собираете и сохраняете информацию о местных ресторанах, каждый такой ресторан является одной сущностью, а его название, адрес и рабочие часы представляют собой атрибуты этой сущности. Вся информация, которую вы собираете и сохраняете о любимых ресторанах, — это данные.
Типы баз данных
В целом базы данных делятся на реляционные и нереляционные. Реляционные базы данных хорошо структурированы и поддерживают язык SQL (Structured Query Language). Нереляционные базы данных отличаются большим разнообразием и поддерживают различные структуры данных. Так как многие нереляционные базы данных не используют язык SQL, их часто называют базами данных NoSQL.
Типы структур данных
Структуры таблиц — это структуры реляционных баз данных, в которых данные упорядочены в строки и столбцы, где строки содержат данные о сущности, а столбцы — атрибуты сущностей.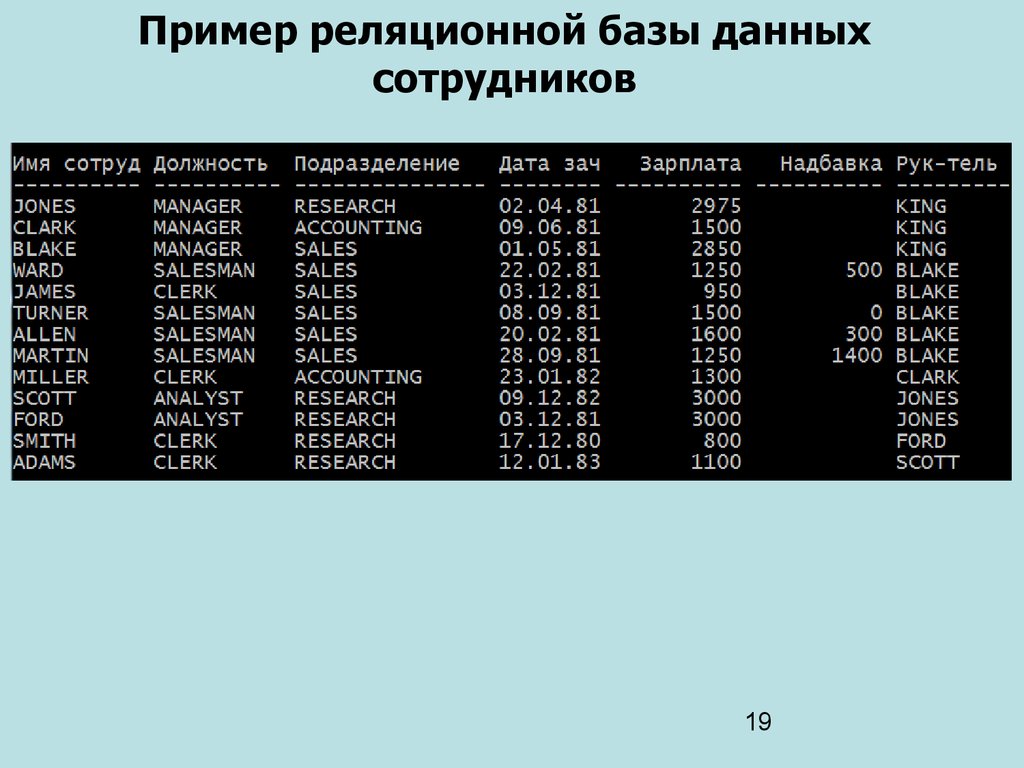 В широких таблицах или хранилищах широких столбцов используются разреженные столбцы с пустыми атрибутами, что позволяет значительно увеличить общее количество столбцов в таблице. Так как некоторые области являются пустыми, широкие таблицы — это пример нереляционной структуры данных.
В широких таблицах или хранилищах широких столбцов используются разреженные столбцы с пустыми атрибутами, что позволяет значительно увеличить общее количество столбцов в таблице. Так как некоторые области являются пустыми, широкие таблицы — это пример нереляционной структуры данных.
В линейных структурах элементы объединяются в последовательность.
Массив
Связанный список
Двоичное дерево
В древовидных структурах элементы упорядочены в виде иерархической базы данных узлов со связями »родительский элемент — дочерний элемент», которые исходят от одного корневого узла.
Граф
В графовой структуре элементы упорядочены в виде неиерархической сети узлов со сложными связями между ними.
Хэш-таблица
В структурах на основе хэша ключи сопоставляются со значениями с помощью хэш-функций, которые связывают соответствующие данные, назначая индексы хэш-таблицам.
Документоориентированные базы данных
В документоориентированной базе данных большие объемы информации об одной сущности объединены в один объект (документ), отделенный от других объектов. Объекты необязательно должны быть сопоставлены друг с другом. Это позволяет изменить один такой объект, не затрагивая другие.
Реляционные базы данных
В реляционной базе данных (наиболее распространенный тип) данные упорядочены в таблицы, содержащие сведения о каждой сущности и представляющие предварительно определенные категории в виде строк и столбцов. Эти структурированные данные являются эффективными и гибкими в контексте доступа.
Примеры реляционных баз данных: SQL Server, Azure SQL, MySQL, PostgreSQL и MariaDB.
Нереляционные базы данных
В нереляционных базах данных хранятся неструктурированные или полуструктурированные данные. В них не используются таблицы со столбцами и строками, как в реляционных базах данных. Вместо этого используется модель хранилища, оптимизированная в соответствии с конкретными требованиями типов хранимых данных. Нереляционные базы данных позволяют быстро обращаться к большим наборам распределенных данных, обновлять их и анализировать.
Нереляционные базы данных позволяют быстро обращаться к большим наборам распределенных данных, обновлять их и анализировать.
Примеры нереляционных баз данных: MongoDB, Azure Cosmos DB, DocumentDB, Cassandra, Couchbase, HBase, Redis и Neo4j.
Некоторые нереляционные базы данных называют базами данных NoSQL. Термин NoSQL применяется к хранилищам данных, которые не используют SQL или используют не только SQL для запросов. Вместо этого базы данных NoSQL используют другие языки и конструкции для запроса данных. Многие базы данных NoSQL поддерживают SQL-совместимые запросы, но способ их выполнения обычно отличается от используемого традиционной реляционной базой данных для такого же SQL-запроса.
Для одного из типов нереляционной базы данных — базы данных объектов — используется объектно-ориентированное программирование. Объекты кодируются с данными о состоянии (фактические данные), которые хранятся в поле или переменной, и поведении, которые можно отобразить с помощью метода или функции. Объекты могут храниться в постоянном хранилище, а также считываться и сопоставляться напрямую без использования API или какого-либо средства. Это обеспечивает более быстрый доступ к данным и более высокую производительность. При этом базы данных объектов не так популярны, как другие типы баз данных, и их обслуживание может оказаться сложной задачей.
Объекты могут храниться в постоянном хранилище, а также считываться и сопоставляться напрямую без использования API или какого-либо средства. Это обеспечивает более быстрый доступ к данным и более высокую производительность. При этом базы данных объектов не так популярны, как другие типы баз данных, и их обслуживание может оказаться сложной задачей.
Выполняющиеся в памяти базы данных и кэши
Все данные в выполняющихся в памяти базах данных хранятся на оперативном запоминающем устройстве (ОЗУ). При отправке запроса к такой базе данных или ее обновлении вы осуществляете доступ к основной памяти напрямую. При этом диск не задействуется. Данные загружаются быстро, так как доступ к основной памяти (которая расположена рядом с процессором на системной плате) осуществляется гораздо быстрее, чем доступ к диску.
Выполняющиеся в памяти базы данных обычно используются для хранения копий часто используемых сведений, таких как данные о цене или наличии товара. Такой процесс называется кэшированием. Копия кэшируемых данных сохраняется во временном расположении, поэтому они загружаются быстрее при следующем запросе. Узнайте больше о кэшировании.
Копия кэшируемых данных сохраняется во временном расположении, поэтому они загружаются быстрее при следующем запросе. Узнайте больше о кэшировании.
Примеры баз данных
Базы данных могут показаться чем-то загадочным, но большинство из нас взаимодействуют с ними каждый день. Вот некоторые распространенные примеры реляционных баз данных, баз данных NoSQL и выполняющихся в памяти баз данных:
Финансовые транзакции
Банки используют базы данных для отслеживания транзакций клиентов — от запросов данных о балансе до перевода средств между счетами. Эти транзакции должны выполняться практически мгновенно, а данные из огромных объемов транзакций всегда должны быть актуальными. Поэтому банки используют веб-системы обработки транзакций, созданные на основе реляционных баз данных, которые могут обрабатывать большое количество запросов от клиентов, а также обеспечить частое изменение данных из транзакций и малое время отклика.
Каталоги для электронной коммерции
Если у вас есть веб-сайт электронной коммерции, каталог продуктов будет содержать отдельные продукты со своим набором атрибутов. В документоориентированной базе данных, например нереляционной базе данных, используются отдельные документы для описания всех атрибутов одного продукта. Вы можете изменять атрибуты в документе, не затрагивая другие продукты. Выполняющиеся в памяти базы данных обычно используются для кэширования часто используемых данных электронной коммерции, например данных о наличии товара и его цене, чтобы ускорить получение данных и снизить нагрузку на базу данных.
В документоориентированной базе данных, например нереляционной базе данных, используются отдельные документы для описания всех атрибутов одного продукта. Вы можете изменять атрибуты в документе, не затрагивая другие продукты. Выполняющиеся в памяти базы данных обычно используются для кэширования часто используемых данных электронной коммерции, например данных о наличии товара и его цене, чтобы ускорить получение данных и снизить нагрузку на базу данных.
Социальные сети
При присоединении к социальным сетям ваша информация добавляется в нереляционную базу данных всех пользователей этой сети. Когда вы общаетесь с другими пользователями этой сети, вы становитесь частью графа социальной сети. Поэтому вы можете видеть отфильтрованный список друзей и рабочих контактов, а также находить новых людей, связанных с этими друзьями и контактами.
Персонализированные результаты поиска
Нереляционные базы данных используются для персонализации в сети. Этот процесс стал настолько распространенным, что вы можете даже не замечать его. При бронировании авиабилета на туристическом веб-сайте вам также будут предлагаться варианты для бронирования отелей и аренды автомобилей. База данных веб-сайта содержит огромный объем неструктурированной информации (сведения о перелете, предпочтения в путешествиях, данные о предыдущем бронировании отелей и аренды автомобилей), которая используется для предоставления персонализированных предложений, чтобы сэкономить ваше время и деньги, а также минимизировать усилия. Выполняющиеся в памяти базы данных точно так же используются как хранилище данных сеансов для эффективного хранения временных данных пользователей, таких как параметры поиска или данные корзины, при использовании приложения.
При бронировании авиабилета на туристическом веб-сайте вам также будут предлагаться варианты для бронирования отелей и аренды автомобилей. База данных веб-сайта содержит огромный объем неструктурированной информации (сведения о перелете, предпочтения в путешествиях, данные о предыдущем бронировании отелей и аренды автомобилей), которая используется для предоставления персонализированных предложений, чтобы сэкономить ваше время и деньги, а также минимизировать усилия. Выполняющиеся в памяти базы данных точно так же используются как хранилище данных сеансов для эффективного хранения временных данных пользователей, таких как параметры поиска или данные корзины, при использовании приложения.
Бизнес-аналитика
Если организациям нужно получить полезные сведения из собственных данных, для управления аналитикой они могут использовать реляционные базы данных. Например, служба технической поддержки может отслеживать проблемы клиентов по различным характеристикам, включая тип проблемы, время решения проблемы и качество обслуживания клиентов. В реляционной базе данных, использующей структуру таблицы, данные о проблемах клиентов будут одновременно упорядочиваться только по двумя измерениям. Но в аналитической веб-системе обработки специалисты службы поддержки могут одновременно просматривать несколько таблиц, что позволяет реализовать многомерный анализ для быстрой обработки больших объемов данных.
В реляционной базе данных, использующей структуру таблицы, данные о проблемах клиентов будут одновременно упорядочиваться только по двумя измерениям. Но в аналитической веб-системе обработки специалисты службы поддержки могут одновременно просматривать несколько таблиц, что позволяет реализовать многомерный анализ для быстрой обработки больших объемов данных.
Системы управления базами данных
Для управления данными администраторы баз данных используют системы управления базами данных (СУБД), особенно при работе с большими данными. Большие данные — это огромные объемы структурированных и неструктурированных данных, которые система часто получает в реальном или почти реальном времени. СУБД также помогает управлять данными, которые используются в нескольких приложениях, или данными, находящимися в нескольких расположениях.
Разные системы управления предлагают разные уровни организации, масштабируемости и применения. При выборе СУБД учитывается не только тип упорядочиваемых данных и способ доступа к ним, но и место расположения данных, тип архитектуры базы данных и способ масштабирования.
Где расположены ваши данных: в облаке, локально или в обеих средах?
В локальных базах данных данные размещаются на частном оборудовании на месте (часто называется частным облаком). Чтобы увеличить объем данных, администраторы баз данных должны убедиться, что на локальных серверах достаточно свободного места, или же расширить инфраструктуру, добавив оборудование для создания нужного пространства.
В облачных базах данных структурированные или неструктурированные данные расположены на частной, общедоступной или гибридной платформе облачных вычислений (т. е. на платформе, объединяющей частное и общедоступное облачное хранилище). Так как облачные базы данных предназначены для виртуализованной среды, они обеспечивают высокий уровень масштабируемости и доступности. Они также помогают снизить затраты, так как вам не нужно покупать много оборудования и вы будете платить только за используемое хранилище.
Ваша база данных имеет централизованную, распределенную или федеративную архитектуру?
В централизованной базе данных все данные находятся в одной системе. Эта единая система — точка доступа для всех пользователей.
Эта единая система — точка доступа для всех пользователей.
Распределенная база данных может охватывать реляционные и нереляционные базы данных. В распределенных базах данных данные хранятся в нескольких физических расположениях — на нескольких локальных компьютерах или в сети взаимосвязанных компьютеров.
В федеративной базе данных несколько отдельных баз данных, работающих на независимых серверах, объединены в один большой объект. Блокчейн — это один из видов федеративной базы данных для безопасного управления реестрами финансовых операций и другими записями транзакций.
Какое масштабирование вы будете использовать при увеличении объема данных: вертикальное или горизонтальное?
Вертикальное увеличение (или уменьшение) масштаба — это процесс добавления ресурсов (например, памяти или более мощных ЦП) для существующего сервера.
Горизонтальное увеличение (или уменьшение) масштаба реализуется путем добавления (удаления) компьютеров в пуле ресурсов.
В отличие от вертикального масштабирования, горизонтальное масштабирование позволяет продлить жизненный цикл существующего оборудования, выполнить модернизацию без привязки к поставщику, сократить затраты и создать долгосрочные перспективы в контексте гибкости.
Базы данных Azure
Упростите операции с данными, используя полностью управляемые базы данных, которые позволяют автоматизировать возможности масштабирования, управления доступом и защиты. Доступны реляционные базы данных, базы данных NoSQL и выполняющиеся в памяти базы данных, которые работают на основе защищаемых ядер и ядер с открытым кодом.
Знакомство с семейством баз данных Azure SQL
Объедините все решения SQL в портфель без ущерба для совместимости. Переносите, модернизируйте и развертывайте приложения удобным для вас способом из пограничной среды в облако с помощью знакомой технологии SQL Server.
Уверенное масштабирование с использованием Базы данных Azure для PostgreSQL
База данных Azure для PostgreSQL позволяет быстро и уверенно масштабировать рабочую нагрузку, обеспечивая высокий уровень доступности, оптимизацию производительности на основе ИИ и повышенный уровень защиты.
Подробнее об Azure PostgreSQL
Создание высокопроизводительных приложений с использованием Azure Cosmos DB
Azure Cosmos DB — это полностью управляемая база данных NoSQL с открытыми API и гарантированной скоростью для любого масштаба.
Подробнее об Azure Cosmos DB
Эффективная обработка больших объемов трафика с помощью Кэша Azure для Redis
Кэш Azure для Redis позволяет одновременно и практически мгновенно обрабатывать запросы тысяч пользователей, добавляя слой быстрого кэширования в архитектуру приложения.
Подробнее о Кэше Azure для Redis
Что такое NoSQL? | Нереляционные базы данных, модели данных с гибкой схемой | AWS
Высокопроизводительные нереляционные базы данных с гибкими моделями данных
Базы данных NoSQL специально созданы для определенных моделей данных и обладают гибкими схемами, что позволяет разрабатывать современные приложения. Базы данных NoSQL получили широкое распространение в связи с простотой разработки, функциональностью и производительностью при любых масштабах. Ресурсы, представленные на этой странице, помогут разобраться с базами данных NoSQL и начать работу с ними.
Базы данных NoSQL получили широкое распространение в связи с простотой разработки, функциональностью и производительностью при любых масштабах. Ресурсы, представленные на этой странице, помогут разобраться с базами данных NoSQL и начать работу с ними.
Базы данных в AWS: подходящий инструмент для подходящей работы
Базы данных NoSQL используют разнообразные модели данных для доступа к данным и управления ими. Базы данных таких типов оптимизированы для приложений, которые работают с большим объемом данных, нуждаются в низкой задержке и гибких моделях данных. Все это достигается путем смягчения жестких требований к непротиворечивости данных, характерных для других типов БД.
Рассмотрим пример моделирования схемы для простой базы данных книг.
- В реляционной базе данных запись о книге часто разделяется на несколько частей (или «нормализуется») и хранится в отдельных таблицах, отношения между которыми определяются ограничениями первичных и внешних ключей. В этом примере в таблице «Книги» имеются столбцы «ISBN», «Название книги» и «Номер издания», в таблице «Авторы» – столбцы «ИД автора» и «Имя автора», а в таблице «Автор–ISBN» – столбцы «Автор» и «ISBN». Реляционная модель создана таким образом, чтобы обеспечить целостность ссылочных данных между таблицами в базе данных. Данные нормализованы для снижения избыточности и в целом оптимизированы для хранения.
 В этом примере в таблице «Книги» имеются столбцы «ISBN», «Название книги» и «Номер издания», в таблице «Авторы» – столбцы «ИД автора» и «Имя автора», а в таблице «Автор–ISBN» – столбцы «Автор» и «ISBN». Реляционная модель создана таким образом, чтобы обеспечить целостность ссылочных данных между таблицами в базе данных. Данные нормализованы для снижения избыточности и в целом оптимизированы для хранения.
В этом примере в таблице «Книги» имеются столбцы «ISBN», «Название книги» и «Номер издания», в таблице «Авторы» – столбцы «ИД автора» и «Имя автора», а в таблице «Автор–ISBN» – столбцы «Автор» и «ISBN». Реляционная модель создана таким образом, чтобы обеспечить целостность ссылочных данных между таблицами в базе данных. Данные нормализованы для снижения избыточности и в целом оптимизированы для хранения.- В базе данных NoSQL запись о книге обычно хранится как документ JSON. Для каждой книги, или элемента, значения «ISBN», «Название книги», «Номер издания», «Имя автора и «ИД автора» хранятся в качестве атрибутов в едином документе. В такой модели данные оптимизированы для интуитивно понятной разработки и горизонтальной масштабируемости.
Базы данных NoSQL хорошо подходят для многих современных приложений, например мобильных, игровых, интернет‑приложений, когда требуются гибкие масштабируемые базы данных с высокой производительностью и широкими функциональными возможностями, способные обеспечивать максимальное удобство использования.
- Гибкость. Как правило, базы данных NoSQL предлагают гибкие схемы, что позволяет осуществлять разработку быстрее и обеспечивает возможность поэтапной реализации. Благодаря использованию гибких моделей данных БД NoSQL хорошо подходят для частично структурированных и неструктурированных данных.
- Масштабируемость. Базы данных NoSQL рассчитаны на масштабирование с использованием распределенных кластеров аппаратного обеспечения, а не путем добавления дорогих надежных серверов. Некоторые поставщики облачных услуг проводят эти операции в фоновом режиме, обеспечивая полностью управляемый сервис.
- Высокая производительность. Базы данных NoSQL оптимизированы для конкретных моделей данных и шаблонов доступа, что позволяет достичь более высокой производительности по сравнению с реляционными базами данных.
- Широкие функциональные возможности. Базы данных NoSQL предоставляют API и типы данных с широкой функциональностью, которые специально разработаны для соответствующих моделей данных.

БД на основе пар «ключ‑значение». Базы данных с использованием пар «ключ‑значение» поддерживают высокую разделяемость и обеспечивают беспрецедентное горизонтальное масштабирование, недостижимое при использовании других типов БД. Хорошими примерами использования для баз данных типа «ключ‑значение» являются игровые, рекламные приложения и приложения IoT. Amazon DynamoDB обеспечивает стабильную работу БД с задержкой не более нескольких миллисекунд при любом масштабе. Такая устойчивая производительность послужила основной причиной переноса Snapchat Stories в сервис DynamoDB, поскольку эта возможность Snapchat связана с самой большой нагрузкой на запись в хранилище.
Документ В коде приложения данные часто представлены как объект или документ в формате, подобном JSON, поскольку для разработчиков это эффективная и интуитивная модель данных. Документные базы данных позволяют разработчикам хранить и запрашивать данные в БД с помощью той же документной модели, которую они используют в коде приложения.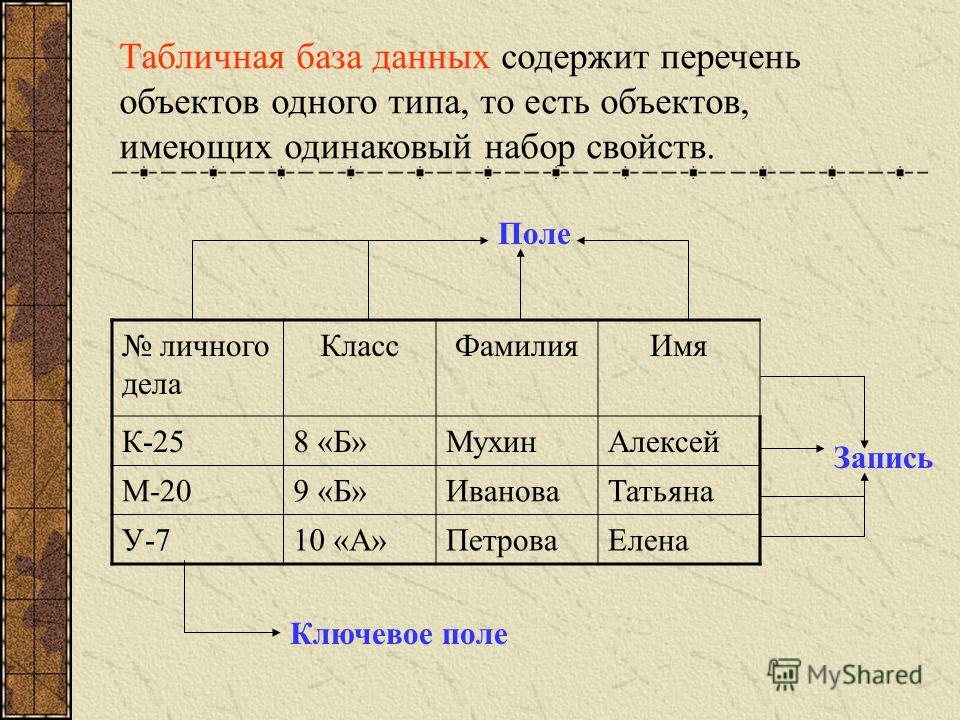 Гибкий, полуструктурированный, иерархический характер документов и документных баз данных позволяет им развиваться в соответствии с потребностями приложений. Документная модель хорошо работает в каталогах, пользовательских профилях и системах управления контентом, где каждый документ уникален и изменяется со временем. Amazon DocumentDB (совместимая с MongoDB) и MongoDB — распространенные документные базы данных, которые предоставляют функциональные и интуитивно понятные API для гибкой разработки.
Гибкий, полуструктурированный, иерархический характер документов и документных баз данных позволяет им развиваться в соответствии с потребностями приложений. Документная модель хорошо работает в каталогах, пользовательских профилях и системах управления контентом, где каждый документ уникален и изменяется со временем. Amazon DocumentDB (совместимая с MongoDB) и MongoDB — распространенные документные базы данных, которые предоставляют функциональные и интуитивно понятные API для гибкой разработки.
Графовые БД. Графовые базы данных упрощают разработку и запуск приложений, работающих с наборами сложносвязанных данных. Типичные примеры использования графовых баз данных – социальные сети, сервисы рекомендаций, системы выявления мошенничества и графы знаний. Amazon Neptune – это полностью управляемый сервис графовых баз данных. Neptune поддерживает модель Property Graph и Resource Description Framework (RDF), предоставляя на выбор два графовых API: TinkerPop и RDF / SPARQL. К числу распространенных графовых БД относятся Neo4j и Giraph.
К числу распространенных графовых БД относятся Neo4j и Giraph.
БД в памяти. Часто в игровых и рекламных приложениях используются таблицы лидеров, хранение сессий и аналитика в реальном времени. Такие возможности требуют отклика в пределах нескольких микросекунд, при этом резкое возрастание трафика возможно в любой момент. Amazon MemoryDB для Redis – это совместимый с Redis надежный сервис базы данных в памяти, который уменьшает задержку чтения до миллисекунд и обеспечивает надежность в нескольких зонах доступности. MemoryDB специально создана для обеспечения сверхвысокой производительности и надежности, поэтому ее можно использовать как основную базу данных для современных приложений на базе микросервисов. Amazon ElastiCache – это полностью управляемый сервис кэширования в памяти, совместимый с Redis и Memcached для обслуживания рабочих нагрузок с низкой задержкой и высокой пропускной способностью. Такие клиенты, как Tinder, которым требуется, чтобы их приложения давали отклик в режиме реального времени, пользуются системами хранения данных в памяти, а не на диске. Еще одним примером специально разработанного хранилища данных является Amazon DynamoDB Accelerator (DAX). DAX позволяет DynamoDB считывать данные в несколько раз быстрее.
Еще одним примером специально разработанного хранилища данных является Amazon DynamoDB Accelerator (DAX). DAX позволяет DynamoDB считывать данные в несколько раз быстрее.
Поисковые БД. Многие приложения формируют журналы, чтобы разработчикам было проще выявлять и устранять неполадки. Сервис Amazon OpenSearch – специально разработанный сервис для визуализации и аналитики автоматически генерируемых потоков данных в режиме, близком к реальному времени, путем индексирования, агрегации частично структурированных журналов и метрик и поиска по ним. Кроме того, сервис Amazon OpenSearch – это мощный, высокопроизводительный сервис для полнотекстового поиска. Компания Expedia задействует более 150 доменов сервиса Amazon OpenSearch, 30 ТБ данных и 30 миллиардов документов для разнообразных особо важных примеров использования – от операционного мониторинга и устранения неисправностей до отслеживания стека распределенных приложений и оптимизации затрат.
В течение десятилетий центральное место в разработке приложений занимала реляционная модель данных, которая использовалась в реляционных базах данных, таких как Oracle, DB2, SQL Server, MySQL и PostgreSQL. Но в середине – конце 2000‑х годов заметное распространение стали получать и другие модели данных. Для обозначения появившихся классов БД и моделей данных был введен термин «NoSQL». Часто «NoSQL» используется в качестве синонима к термину «нереляционный».
Но в середине – конце 2000‑х годов заметное распространение стали получать и другие модели данных. Для обозначения появившихся классов БД и моделей данных был введен термин «NoSQL». Часто «NoSQL» используется в качестве синонима к термину «нереляционный».
Существует множество типов БД NoSQL с различными особенностями, но в таблице ниже приведены основные отличия баз данных NoSQL от SQL.
Начало работы с NoSQL
В следующей таблице приведено сравнение терминологии некоторых баз данных NoSQL с терминологией баз данных SQL.
| SQL | MongoDB | DynamoDB | Cassandra | Couchbase |
|---|---|---|---|---|
| Таблица | Коллекция | Таблица | Таблица | Корзина данных |
| Ряд | Документ | Элемент | Ряд | Документ |
| Столбец | Поле | Атрибут | Столбец | Поле |
| Первичный ключ | ObjectId | Первичный ключ | Первичный ключ | ИД документа |
| Индекс | Индекс | Вторичный индекс | Индекс | Индекс |
| Представление | Представление | Глобальный вторичный индекс | Материализованное представление | Представление |
| Вложенная таблица или объект | Встроенный документ | Карта | Карта | Карта |
| Массив | Массив | Список | Список | Список |
| Список |
| Список |
| Первичный ключ |
Начать работу с DynamoDB очень просто.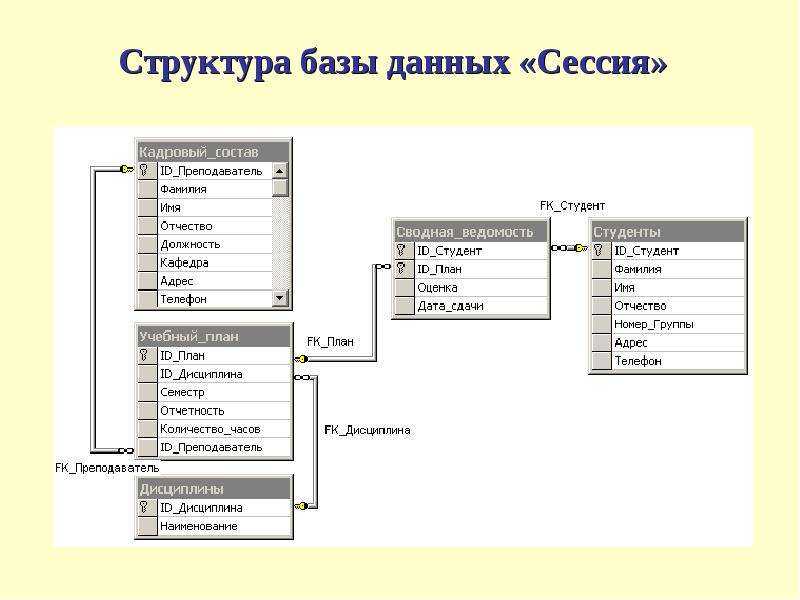 Страница по началу работы с DynamoDB поможет создать первую таблицу за несколько щелчков мышью. Можно загрузить техническое описание AWS, чтобы изучить рекомендации по миграции рабочих нагрузок из реляционной системы управления базой данных (РСУБД) в DynamoDB.
Страница по началу работы с DynamoDB поможет создать первую таблицу за несколько щелчков мышью. Можно загрузить техническое описание AWS, чтобы изучить рекомендации по миграции рабочих нагрузок из реляционной системы управления базой данных (РСУБД) в DynamoDB.
Начать работу с Amazon DynamoDB
What is Amazon DynamoDB?
Вход в Консоль
Подробнее об AWS
- Что такое AWS?
- Что такое облачные вычисления?
- Инклюзивность, многообразие и равенство AWS
- Что такое DevOps?
- Что такое контейнер?
- Что такое озеро данных?
- Безопасность облака AWS
- Новые возможности
- Блоги
- Пресс‑релизы
Ресурсы для работы с AWS
- Начало работы
- Обучение и сертификация
- Портфолио решений AWS
- Центр архитектурных решений
- Вопросы и ответы по продуктам и техническим темам
- Отчеты аналитиков
- Партнерская сеть AWS
Разработчики на AWS
- Центр разработчика
- Пакеты SDK и инструментарий
- . NET на AWS
- Python на AWS
- Java на AWS
- PHP на AWS
- JavaScript на AWS
 NET на AWS
NET на AWSПоддержка
- Связаться с нами
- Работа в AWS
- Обратиться в службу поддержки
- Центр знаний
- AWS re:Post
- Обзор AWS Support
- Юридическая информация
Amazon.com – работодатель равных возможностей. Мы предоставляем равные права представителям меньшинств, женщинам, лицам с ограниченными возможностями, ветеранам боевых действий и представителям любых гендерных групп любой сексуальной ориентации независимо от их возраста.
Поддержка AWS для Internet Explorer заканчивается 07/31/2022. Поддерживаемые браузеры: Chrome, Firefox, Edge и Safari. Подробнее »
Что такое реляционная база данных? – Amazon Web Services (AWS)
Реляционная база данных – это набор данных с предопределенными связями между ними. Эти данные организованны в виде набора таблиц, состоящих из столбцов и строк. В таблицах хранится информация об объектах, представленных в базе данных. В каждом столбце таблицы хранится определенный тип данных, в каждой ячейке – значение атрибута. Каждая стока таблицы представляет собой набор связанных значений, относящихся к одному объекту или сущности. Каждая строка в таблице может быть помечена уникальным идентификатором, называемым первичным ключом, а строки из нескольких таблиц могут быть связаны с помощью внешних ключей. К этим данным можно получить доступ многими способами, и при этом реорганизовывать таблицы БД не требуется.
Эти данные организованны в виде набора таблиц, состоящих из столбцов и строк. В таблицах хранится информация об объектах, представленных в базе данных. В каждом столбце таблицы хранится определенный тип данных, в каждой ячейке – значение атрибута. Каждая стока таблицы представляет собой набор связанных значений, относящихся к одному объекту или сущности. Каждая строка в таблице может быть помечена уникальным идентификатором, называемым первичным ключом, а строки из нескольких таблиц могут быть связаны с помощью внешних ключей. К этим данным можно получить доступ многими способами, и при этом реорганизовывать таблицы БД не требуется.
6:44
Understanding Amazon Relational Database Service (RDS)SQL (Structured Query Language) – основной интерфейс работы с реляционными базами данных. SQL стал стандартом Национального института стандартов США (ANSI) в 1986 году. Стандарт ANSI SQL поддерживается всеми популярными ядрами реляционных БД. Некоторые из ядер также включают расширения стандарта ANSI SQL, поддерживающие специфичный для этих ядер функционал. SQL используется для добавления, обновления и удаления строк данных, извлечения наборов данных для обработки транзакций и аналитических приложений, а также для управления всеми аспектами работы базы данных.
Некоторые из ядер также включают расширения стандарта ANSI SQL, поддерживающие специфичный для этих ядер функционал. SQL используется для добавления, обновления и удаления строк данных, извлечения наборов данных для обработки транзакций и аналитических приложений, а также для управления всеми аспектами работы базы данных.
Целостность данных
Целостность данных – это полнота, точность и единообразие данных. Для поддержания целостности данных в реляционных БД используется ряд инструментов. В их число входят первичные ключи, внешние ключи, ограничения «Not NULL», «Unique», «Default» и «Check». Эти ограничения целостности позволяют применять практические правила к данным в таблицах и гарантировать точность и надежность данных. Большинство ядер БД также поддерживает интеграцию пользовательского кода, который выполняется в ответ на определенные операции в БД.
Транзакции
Транзакция в базе данных – это один или несколько операторов SQL, выполненных в виде последовательности операций, представляющих собой единую логическую задачу. Транзакция представляет собой неделимое действие, то есть она должна быть выполнена как единое целое и либо должна быть записана в базу данных целиком, либо не должен быть записан ни один из ее компонентов. В терминологии реляционных баз данных транзакция завершается либо действием COMMIT, либо ROLLBACK. Каждая транзакция рассматривается как внутренне связный, надежный и независимый от других транзакций элемент.
Транзакция представляет собой неделимое действие, то есть она должна быть выполнена как единое целое и либо должна быть записана в базу данных целиком, либо не должен быть записан ни один из ее компонентов. В терминологии реляционных баз данных транзакция завершается либо действием COMMIT, либо ROLLBACK. Каждая транзакция рассматривается как внутренне связный, надежный и независимый от других транзакций элемент.
Соответствие требованиям ACID
Для соблюдения целостности данных все транзакции в БД должны соответствовать требованиям ACID, то есть быть атомарными, единообразными, изолированными и надежными.
Атомарность – это условие, при котором либо транзакция успешно выполняется целиком, либо, если какая-либо из ее частей не выполняется, вся транзакция отменяется. Единообразие – это условие, при котором данные, записываемые в базу данных в рамках транзакции, должны соответствовать всем правилам и ограничениям, включая ограничения целостности, каскады и триггеры. Изолированность необходима для контроля над согласованностью и гарантирует базовую независимость каждой транзакции. Надежность подразумевает, что все внесенные в базу данных изменения на момент успешного завершения транзакции считаются постоянными.
Изолированность необходима для контроля над согласованностью и гарантирует базовую независимость каждой транзакции. Надежность подразумевает, что все внесенные в базу данных изменения на момент успешного завершения транзакции считаются постоянными.
Amazon Aurora
Amazon Aurora – это совместимое с MySQL и PostgreSQL ядро реляционной БД, совмещающее в себе скорость и доступность сложных коммерческих БД с простотой и экономичностью баз данных с открытым исходным кодом. Производительность Amazon Aurora в пять раз выше, чем производительность MySQL. Сервис обеспечивает безопасность, доступность и надежность на уровне коммерческой базы данных, а стоит в десять раз меньше. Подробнее »
Oracle
С помощью Amazon RDS можно за считаные минуты выполнить экономичное развертывание различных версий баз данных Oracle с настраиваемой мощностью аппаратных ресурсов. Поддерживается использование уже приобретенных лицензий Oracle и почасовая оплата использования лицензий.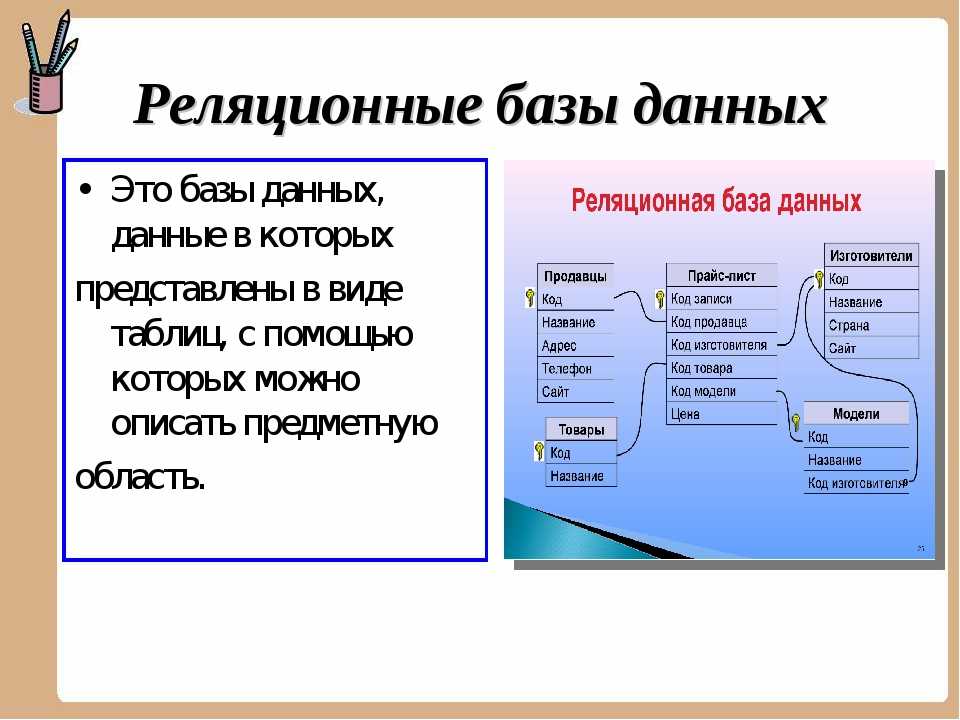 RDS берет на себя решение таких трудоемких задач по управлению базой данных, как выделение ресурсов, создание резервных копий, обновление ПО, мониторинг и масштабирование аппаратных ресурсов, что позволяет пользователям сосредоточиться на разработке приложений. Подробнее »
RDS берет на себя решение таких трудоемких задач по управлению базой данных, как выделение ресурсов, создание резервных копий, обновление ПО, мониторинг и масштабирование аппаратных ресурсов, что позволяет пользователям сосредоточиться на разработке приложений. Подробнее »
Microsoft SQL Server
Amazon RDS for SQL Server упрощает настройку, эксплуатацию и масштабирование SQL Server в облаке. Поддерживается развертывание разных версий SQL Server, включая Express, Web, Standard и Enterprise. Amazon RDS for SQL Server обеспечивает непосредственный доступ к встроенным возможностям SQL Server, поэтому существующие приложения и инструменты будут работать без изменений. Подробнее »
MySQL – это СУБД с открытым исходным кодом, используемая для многих интернет-приложений. Amazon RDS для MySQL предоставляет доступ к возможностям уже знакомого движка БД MySQL. Это означает, что код, приложения и инструменты, которые применяются с существующими базами данных, можно использовать с сервисом Amazon RDS без каких-либо изменений. Подробнее »
Подробнее »
PostgreSQL
PostgreSQL – это мощная объектно-реляционная СУБД корпоративного класса с отрытым исходным кодом, ориентированная на соответствие стандартам и возможность расширения. PostgreSQL отличается широким набором мощных функций и выполняет сохраненные процедуры более чем на 12 языках, включая Java, Perl, Python, Ruby, Tcl, C/C++ и собственный язык PL/pgSQL, аналог PL/SQL от Oracle. Подробнее »
MariaDB
MariaDB – это совместимое с MySQL ядро БД, ответвление MySQL, разработанное под руководством разработчиков оригинальной версии MySQL. Amazon RDS упрощает настройку, эксплуатацию и масштабирование развертываний MariaDB в облаке. С помощью Amazon RDS можно всего за несколько минут выполнить экономичное развертывание масштабируемых баз данных MariaDB с возможностью настройки объема аппаратных ресурсов. Подробнее »
Начать работу с Amazon RDS очень просто. Воспользуйтесь нашим Руководством по началу работы для создания первого инстанса Amazon RDS с помощью нескольких щелчков мышью.
Поддержка AWS для Internet Explorer заканчивается 07/31/2022. Поддерживаемые браузеры: Chrome, Firefox, Edge и Safari. Подробнее »
БАЗА ДАННЫХ • Большая российская энциклопедия
БА́ЗА ДА́ННЫХ, объективная форма представления и организации совокупности данных (статей и др.), систематизированных таким образом, чтобы эти данные могли быть найдены и обработаны ЭВМ. Центральным понятием теории Б. д. является модель данных (МД), под которой понимается совокупность правил структурирования данных в Б. д., допустимых операций над ними и ограничений целостности, которым они должны удовлетворять. Целостность Б. д. – свойство Б. д., означающее, что она содержит полную и непротиворечивую информацию, необходимую для корректного функционирования приложений.
Различают осн. типы МД: иерархические, сетевые, реляционные, объектные.
Иерархическая МД представляет собой древовидный граф (см. Графов теория), вершины которого состоят из записей определённых типов и связей между ними, причём один тип записи определяется как корневой, а остальные связаны с ним или друг с другом отношением «один-ко-многим». Иерархич. Б. д. – совокупность таких древовидных графов. Сетевая МД представляет собой граф общего вида, вершинами которого являются данные разных типов, простые (атомарные) или составные записи, а дугами – связи между этими данными. Записи – участники связей – соединяются в список, который называется набором. Наиболее известная версия – МД CODASYL (Conference on Data System Languages – Конференция по языкам систем обработки данных). Сетевая Б. д. состоит из набора записей и набора связей между этими записями. Реляционная МД представляет собой набор таблиц, называемых отношениями. Т. к. в реляционной МД можно организовать очень большое число связей, значит. часть которых избыточна, то такая МД устанавливает четыре формы (варианта) нормализации отношений. Отношения включают атрибуты и кортежи, составляющие соответственно столбцы и строки таблицы. Множество значений атрибутов называется доменом. Реляционная МД послужила основой стандарта языка реляционной Б. д. SQL (Structured Query Language – Язык структурированных запросов). Объектная МД основана на понятии объекта, т. е. сущности, обладающей состоянием и поведением. Состояние объекта определяется совокупностью его атрибутов, а поведение – совокупностью операций, допустимых для объекта. Между объектами устанавливаются связи. Объекты типизируются, причём обычно предусматривается возможность связи между типами объектов. Объектная МД представлена в стандарте ODMG (Object Database Management Group – Группа управления объектно-ориентированными базами данных).
Т. к. в реляционной МД можно организовать очень большое число связей, значит. часть которых избыточна, то такая МД устанавливает четыре формы (варианта) нормализации отношений. Отношения включают атрибуты и кортежи, составляющие соответственно столбцы и строки таблицы. Множество значений атрибутов называется доменом. Реляционная МД послужила основой стандарта языка реляционной Б. д. SQL (Structured Query Language – Язык структурированных запросов). Объектная МД основана на понятии объекта, т. е. сущности, обладающей состоянием и поведением. Состояние объекта определяется совокупностью его атрибутов, а поведение – совокупностью операций, допустимых для объекта. Между объектами устанавливаются связи. Объекты типизируются, причём обычно предусматривается возможность связи между типами объектов. Объектная МД представлена в стандарте ODMG (Object Database Management Group – Группа управления объектно-ориентированными базами данных).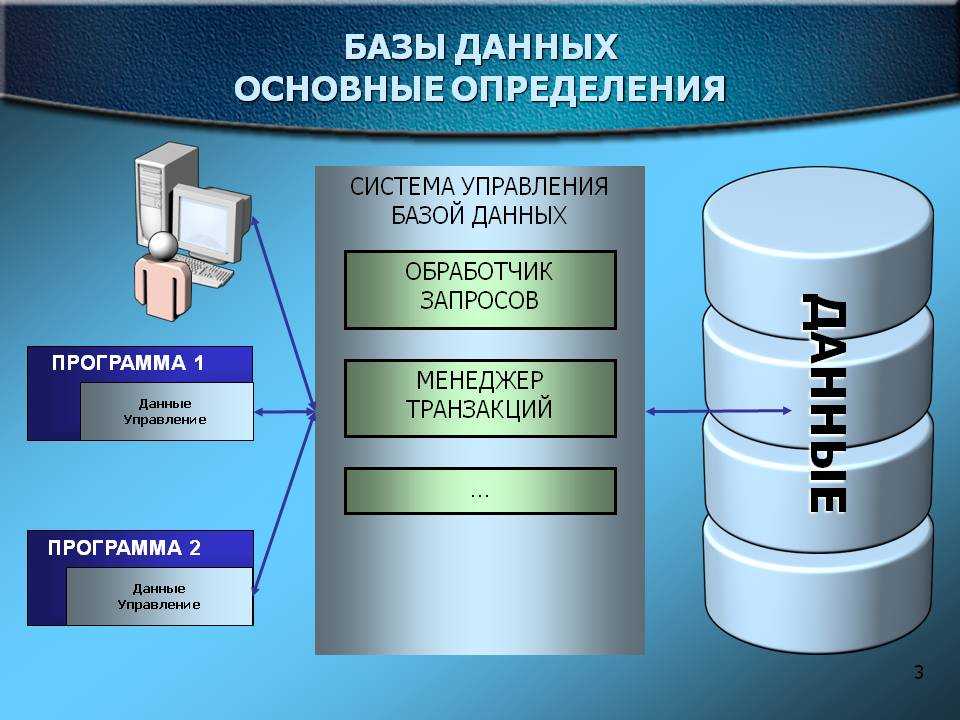
По применяемой МД различают Б. д.: иерархические, сетевые, реляционные, объектные, а также смешанные (объектно-реляционные и т. п.). В кон. 1990-хгг. появился новый вид Б. д., предназначенный для хранения и обработки XML-документов (XML-документ представляет собой обычный текстовый файл, в котором при помощи спец. маркеров создаются элементы данных, последовательность и вложенность которых определяют структуру документа и его содержание). По принципу организации в телекоммуникац. среде различают Б. д. локальные, с сетевым доступом, распределённые, фрагментированные, централизованные, тиражированные и мобильные; по способу отображения предметной области выделяют Б. д. предметные, интегрир., концептуальные, внешние и внутр.; по характеру использования – встроенные (служебные) и общедоступные, предназначенные для внешнего использования; по режиму доступа – открытые и конфиденциальные. Б. д. используются в рамках банков данных.
Б. д. используются в рамках банков данных.
Для создания и использования Б. д. важное значение имеет понятие «метаданные». Это сведения о данных, хранящихся в базе, описывающие их структуру, состав, формат представления, методы доступа, полномочия пользователя или администратора и др. Метаданные подразделяют на системные и пользовательские. Первые предназначены для поддержки системных функций, среди них осн. роль играют схемы Б. д. Вторые описывают свойства данных, представляющие интерес для конечных пользователей, прежде всего для поиска в Б. д. В состав метаданных входят информационно-поисковые языки, определяющие возможности и качество поиска в базе данных.
Осн. параметрами Б. д. принято считать её физич. или логич. объёмы. Физич. объём Б. д. выражается в байтах и производных величинах (килобайтах, мегабайтах и др. ), логич. объём определяется числом записей (объектов, документов), представленных в Б. д. Однако оба параметра являются нестрогими, поэтому сравнивать по объёму можно только Б. д. с одинаковой структурой. Средний объём общедоступных Б. д. составляет ок. 1 млн. записей, объём одной записи для текстовых Б. д. варьируется в пределах 200–2000 слов. Объёмы крупнейших Б. д. составляют десятки терабайт, или десятки млрд. записей. Важный показатель качества Б. д. и эффективности вложенных в них средств – число пользователей или запросов к Б. д., однако этот показатель применим только к общедоступным базам данных.
), логич. объём определяется числом записей (объектов, документов), представленных в Б. д. Однако оба параметра являются нестрогими, поэтому сравнивать по объёму можно только Б. д. с одинаковой структурой. Средний объём общедоступных Б. д. составляет ок. 1 млн. записей, объём одной записи для текстовых Б. д. варьируется в пределах 200–2000 слов. Объёмы крупнейших Б. д. составляют десятки терабайт, или десятки млрд. записей. Важный показатель качества Б. д. и эффективности вложенных в них средств – число пользователей или запросов к Б. д., однако этот показатель применим только к общедоступным базам данных.
Термин «Б. д.» введён в 1963 на первом симпозиуме, посвящённом проблеме организации данных, состоявшемся в г. Санта-Моника (Калифорния, США). Значит. влияние на развитие технологий Б. д. оказали достижения в смежных областях – операционных системах, языках и технологиях программирования. Фундам. разработками первого периода стали сетевая МД Комитета CODASYL (фактически первый стандарт в области Б. д.), иерархич. МД с языком DL-1 (Data Language 1), разработанная компанией IBM, и реляционная МД Э. Кодда (он же ввёл само понятие «модель данных»). В этот же период появились первые коммерч. системы управления базами данных (СУБД). В 1970-х гг. сформировалась наука о Б. д., была разработана технология Б. д., началось индустриальное произ-во СУБД. Создана теория реляционных Б. д. и основанные на ней технологии реляционных СУБД, которые с 1980-х гг. доминируют на мировом рынке. Коммерч. СУБД этого класса разработаны для всех аппаратных средств вычислит. техники, включая персональные компьютеры. Пик разработок языков программирования Б. д. пришёлся на кон. 1980-х гг., среди которых наибольшее распространение получил объектный язык С++.
Фундам. разработками первого периода стали сетевая МД Комитета CODASYL (фактически первый стандарт в области Б. д.), иерархич. МД с языком DL-1 (Data Language 1), разработанная компанией IBM, и реляционная МД Э. Кодда (он же ввёл само понятие «модель данных»). В этот же период появились первые коммерч. системы управления базами данных (СУБД). В 1970-х гг. сформировалась наука о Б. д., была разработана технология Б. д., началось индустриальное произ-во СУБД. Создана теория реляционных Б. д. и основанные на ней технологии реляционных СУБД, которые с 1980-х гг. доминируют на мировом рынке. Коммерч. СУБД этого класса разработаны для всех аппаратных средств вычислит. техники, включая персональные компьютеры. Пик разработок языков программирования Б. д. пришёлся на кон. 1980-х гг., среди которых наибольшее распространение получил объектный язык С++.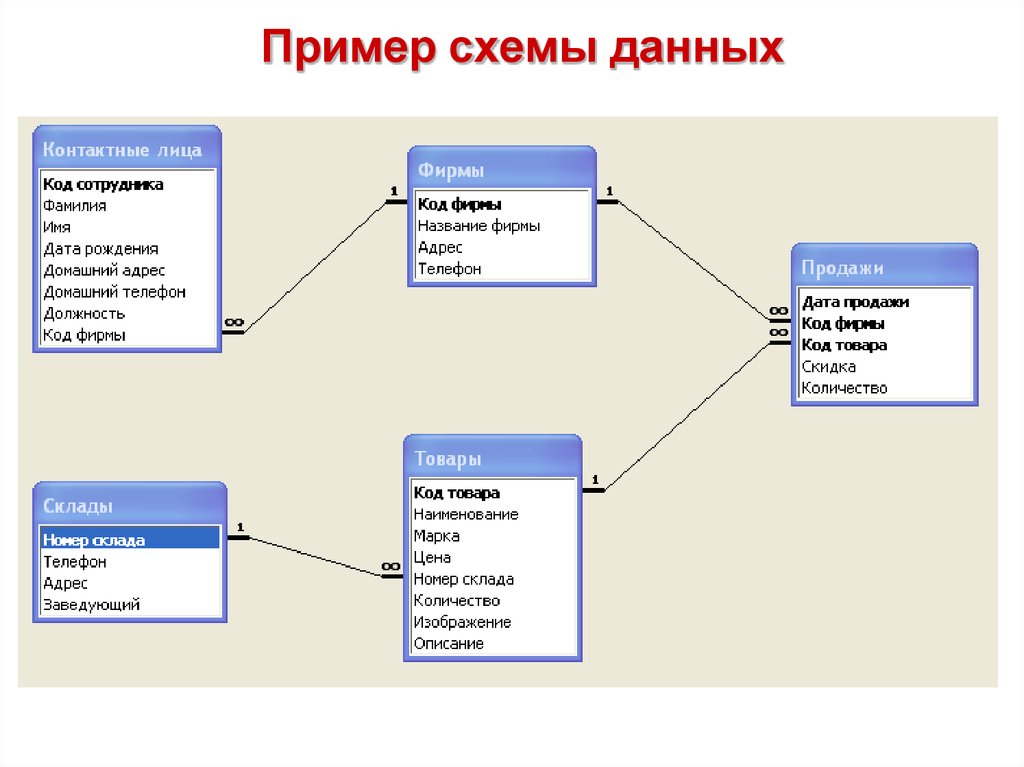 С сер. 1990-х гг. активизировалось развитие стандартов и технологий объектных Б. д., это связано в т. ч. с появлением языков программирования Java и UML (Unified Modeling Language – Унифицированный язык моделирования). В 1999 принят Стандарт SQL. В кон. 1990-х гг. появились базовые технологии управления данными для систем поддержки принятия решений: интерактивная аналитич. обработка данных (OLAP – On-line Analytical Processing), технологии хранилищ данных (Data Warehousing), технологии глубинного анализа данных (Data Mining). Созданы спец. технологии для очень больших Б. д., ориентированных на терабайты и даже петабайты информации. В 1990-е гг. в связи с созданием открытой распределённой неоднородной гипермедийной информац. системы World Wide Web (Всемирная паутина, или WWW, W3, Web), использующей коммуникац. среду Интернет, происходит активное взаимодействие технологий Б.
С сер. 1990-х гг. активизировалось развитие стандартов и технологий объектных Б. д., это связано в т. ч. с появлением языков программирования Java и UML (Unified Modeling Language – Унифицированный язык моделирования). В 1999 принят Стандарт SQL. В кон. 1990-х гг. появились базовые технологии управления данными для систем поддержки принятия решений: интерактивная аналитич. обработка данных (OLAP – On-line Analytical Processing), технологии хранилищ данных (Data Warehousing), технологии глубинного анализа данных (Data Mining). Созданы спец. технологии для очень больших Б. д., ориентированных на терабайты и даже петабайты информации. В 1990-е гг. в связи с созданием открытой распределённой неоднородной гипермедийной информац. системы World Wide Web (Всемирная паутина, или WWW, W3, Web), использующей коммуникац. среду Интернет, происходит активное взаимодействие технологий Б.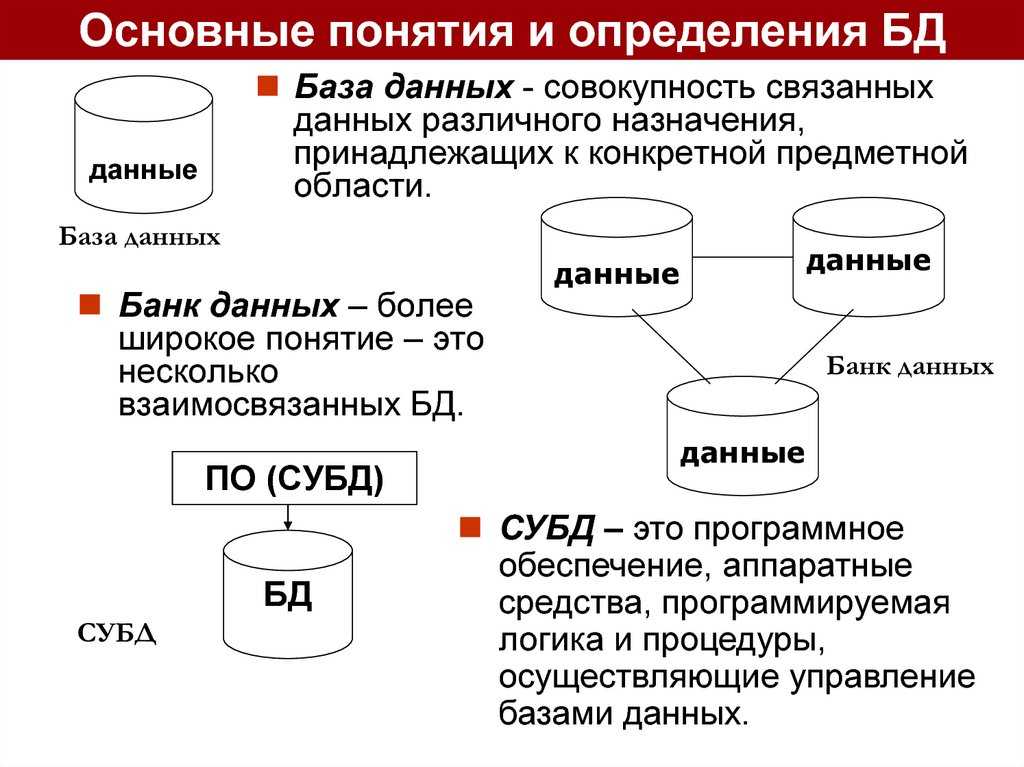 д. и технологий WWW, среди которых наибольшее значение для Б. д. имеет расширенный язык разметки XML (Extensible Markup Language – Расширяемый язык разметки). С кон. 1990-х гг. на базе технологий WWW ведутся многочисл. исследования, связанные с интеграцией информац. ресурсов, в т. ч. неоднородных.
д. и технологий WWW, среди которых наибольшее значение для Б. д. имеет расширенный язык разметки XML (Extensible Markup Language – Расширяемый язык разметки). С кон. 1990-х гг. на базе технологий WWW ведутся многочисл. исследования, связанные с интеграцией информац. ресурсов, в т. ч. неоднородных.
Б. д. – информац. продукт, который можно приобрести либо непосредственно на разл. носителях (чаще всего на оптич. дисках типа CD-ROM), либо через Интернет или по др. протоколам, оплатив услуги по доступу к Б. д. По содержанию выделяют Б. д. библиографические, реферативные, новостные, правовые, словарные, биографические, адресно-справочные, Б. д. о пром. продукции, химич. соединениях и минералах, динамич. ряды статистич. и демографич. данных и др. До сер. 1980-х гг. доминировали Б. д. научно-технич. информации, затем резко возросло значение Б. д. коммерч. и деловой информации, в т. ч. биржевой и финансовой.
д. коммерч. и деловой информации, в т. ч. биржевой и финансовой.
Б. д. – важнейший вид информационных ресурсов, количество, качество и характер использования которых во многом определяют уровень развития страны как информационного общества. Поэтому создание и использование Б. д. в развитых странах, включая Россию, является объектом правового регулирования (см. Информационное право).
Что такое база данных | Оракул
База данных определена
База данных представляет собой организованный набор структурированной информации или данных, обычно хранящихся в электронном виде в компьютерной системе. База данных обычно управляется системой управления базами данных (СУБД). Вместе данные и СУБД вместе со связанными с ними приложениями называются системой баз данных, часто сокращенной до просто базы данных.
Данные в наиболее распространенных типах баз данных, работающих сегодня, обычно моделируются в виде строк и столбцов в ряде таблиц, чтобы сделать обработку и запросы данных более эффективными. Затем к данным можно легко получить доступ, управлять ими, изменять, обновлять, контролировать и организовывать. Большинство баз данных используют язык структурированных запросов (SQL) для записи и запроса данных.
Затем к данным можно легко получить доступ, управлять ими, изменять, обновлять, контролировать и организовывать. Большинство баз данных используют язык структурированных запросов (SQL) для записи и запроса данных.
Узнайте больше о базе данных Oracle
Что такое язык структурированных запросов (SQL)?
SQL — это язык программирования, используемый почти всеми реляционными базами данных для запросов, обработки и определения данных, а также для обеспечения контроля доступа. SQL был впервые разработан в IBM в 1970-х годах с Oracle в качестве основного участника, что привело к внедрению стандарта SQL ANSI. SQL стимулировал множество расширений от таких компаний, как IBM, Oracle и Microsoft. Хотя SQL по-прежнему широко используется сегодня, начинают появляться новые языки программирования.
Эволюция базы данных
Базы данных претерпели значительные изменения с момента их создания в начале 1960-х годов. Навигационные базы данных, такие как иерархическая база данных (которая опиралась на древовидную модель и допускала только отношения «один ко многим») и сетевая база данных (более гибкая модель, допускающая множественные отношения), были первоначальными системами, используемыми для хранения данных.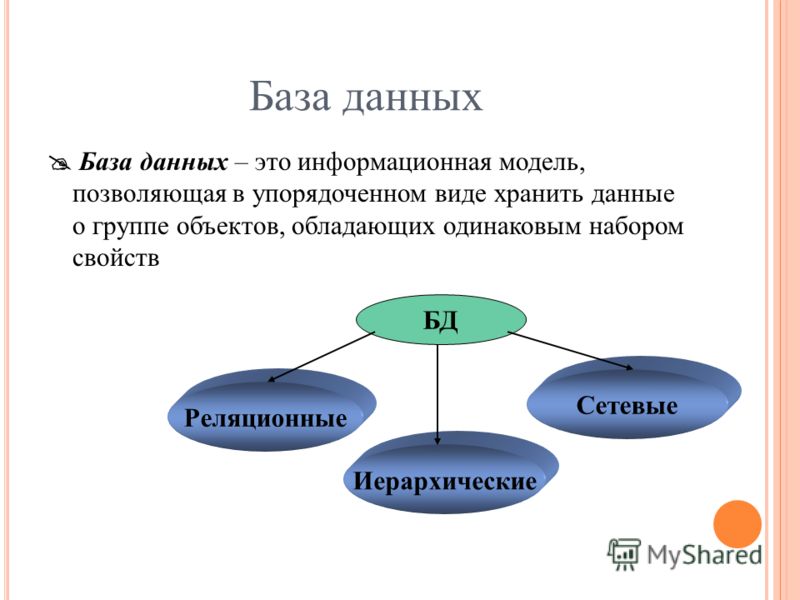 и манипулировать данными. Несмотря на простоту, эти ранние системы были негибкими. В 1980-х годах стали популярными реляционные базы данных, за которыми в 1919 году последовали объектно-ориентированные базы данных.90-е. Совсем недавно базы данных NoSQL появились как ответ на рост Интернета и потребность в более высокой скорости и обработке неструктурированных данных. Сегодня облачные базы данных и автономные базы данных открывают новые горизонты в том, что касается сбора, хранения, управления и использования данных.
и манипулировать данными. Несмотря на простоту, эти ранние системы были негибкими. В 1980-х годах стали популярными реляционные базы данных, за которыми в 1919 году последовали объектно-ориентированные базы данных.90-е. Совсем недавно базы данных NoSQL появились как ответ на рост Интернета и потребность в более высокой скорости и обработке неструктурированных данных. Сегодня облачные базы данных и автономные базы данных открывают новые горизонты в том, что касается сбора, хранения, управления и использования данных.
В чем разница между базой данных и электронной таблицей?
Базы данных и электронные таблицы (например, Microsoft Excel) — удобные способы хранения информации. Основные различия между ними:
- Как данные хранятся и обрабатываются
- Кто может получить доступ к данным
- Сколько данных можно хранить
Электронные таблицы изначально разрабатывались для одного пользователя, и их характеристики отражают это. Они отлично подходят для одного пользователя или небольшого количества пользователей, которым не нужно выполнять множество невероятно сложных манипуляций с данными. Базы данных, с другой стороны, предназначены для хранения гораздо больших коллекций организованной информации — иногда огромных объемов. Базы данных позволяют нескольким пользователям одновременно быстро и безопасно получать доступ к данным и запрашивать их, используя очень сложную логику и язык.
Базы данных, с другой стороны, предназначены для хранения гораздо больших коллекций организованной информации — иногда огромных объемов. Базы данных позволяют нескольким пользователям одновременно быстро и безопасно получать доступ к данным и запрашивать их, используя очень сложную логику и язык.
Типы баз данных
Существует множество различных типов баз данных. Лучшая база данных для конкретной организации зависит от того, как организация намерена использовать данные.
- Реляционные базы данных стали доминирующими в 1980-х годах. Элементы в реляционной базе данных организованы как набор таблиц со столбцами и строками. Технология реляционных баз данных обеспечивает наиболее эффективный и гибкий способ доступа к структурированной информации.
- Информация в объектно-ориентированной базе данных представлена в виде объектов, как и в объектно-ориентированном программировании.
- Распределенная база данных состоит из двух или более файлов, расположенных на разных сайтах. База данных может храниться на нескольких компьютерах, расположенных в одном физическом месте или разбросанных по разным сетям.
- Центральное хранилище данных, хранилище данных — это тип базы данных, специально разработанный для быстрого запроса и анализа.
- NoSQL, или нереляционная база данных, позволяет хранить и обрабатывать неструктурированные и полуструктурированные данные (в отличие от реляционной базы данных, которая определяет, как должны быть составлены все данные, вставленные в базу данных). Базы данных NoSQL становились популярными по мере того, как веб-приложения становились все более распространенными и сложными.
- База данных графа хранит данные с точки зрения сущностей и отношений между сущностями.
- Базы данных OLTP. База данных OLTP — это быстрая аналитическая база данных, предназначенная для большого количества транзакций, выполняемых несколькими пользователями.
Реляционные базы данных
Объектно-ориентированные базы данных

Распределенные базы данных
Хранилища данных
баз данных NoSQL
Графовые базы данных
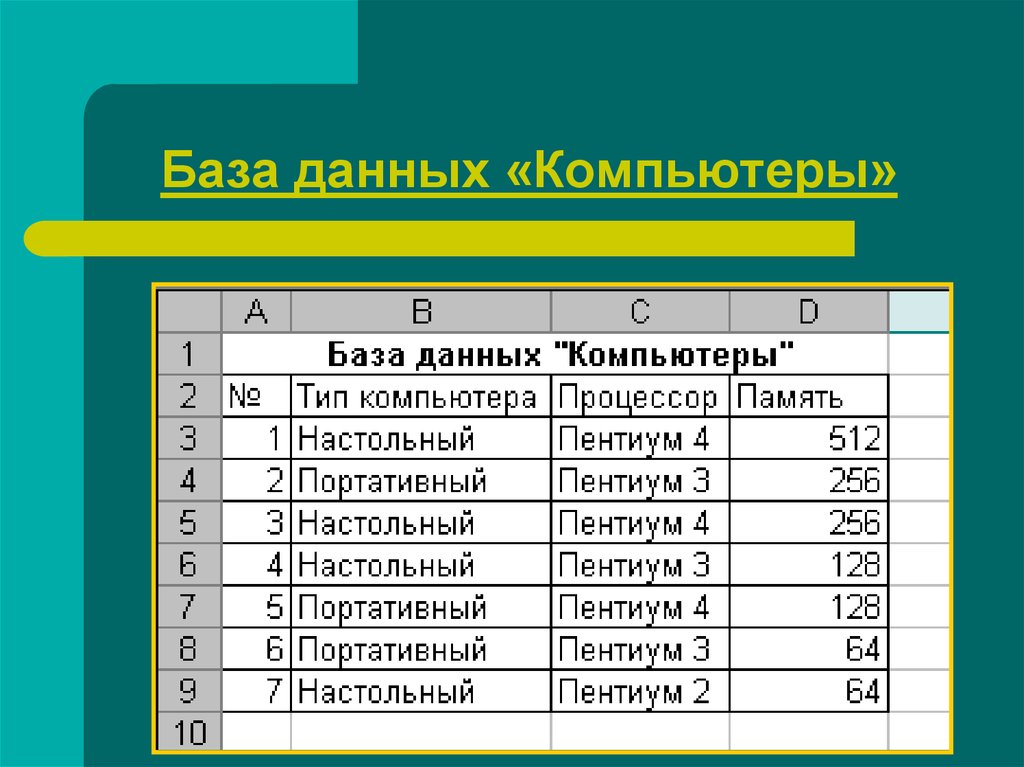 База данных OLTP — это быстрая аналитическая база данных, предназначенная для большого количества транзакций, выполняемых несколькими пользователями.
База данных OLTP — это быстрая аналитическая база данных, предназначенная для большого количества транзакций, выполняемых несколькими пользователями.Это лишь некоторые из нескольких десятков типов баз данных, используемых сегодня. Другие, менее распространенные базы данных предназначены для очень специфических научных, финансовых или других функций. В дополнение к различным типам баз данных, изменения в подходах к разработке технологий и значительные достижения, такие как облачные технологии и автоматизация, продвигают базы данных в совершенно новых направлениях. Некоторые из последних баз данных включают
- Система базы данных с открытым исходным кодом — это система, исходный код которой является открытым исходным кодом; такие базы данных могут быть базами данных SQL или NoSQL.
- Облачная база данных — это набор данных, структурированных или неструктурированных, который находится на частной, общедоступной или гибридной платформе облачных вычислений. Существует два типа моделей облачных баз данных: традиционная и база данных как услуга (DBaaS). При использовании DBaaS административные задачи и обслуживание выполняются поставщиком услуг.
- Базы данных с несколькими моделями объединяют различные типы моделей баз данных в единую интегрированную серверную часть. Это означает, что они могут вмещать различные типы данных.
- Разработанные для хранения, извлечения и управления информацией, ориентированной на документы, базы данных документов представляют собой современный способ хранения данных в формате JSON, а не в строках и столбцах.
- Новейший и самый инновационный тип базы данных, самоуправляемые базы данных (также известные как автономные базы данных) основаны на облаке и используют машинное обучение для автоматизации настройки базы данных, обеспечения безопасности, резервного копирования, обновления и других рутинных задач управления, традиционно выполняемых администраторами баз данных. .
Базы данных с открытым исходным кодом
Облачные базы данных
 Существует два типа моделей облачных баз данных: традиционная и база данных как услуга (DBaaS). При использовании DBaaS административные задачи и обслуживание выполняются поставщиком услуг.
Существует два типа моделей облачных баз данных: традиционная и база данных как услуга (DBaaS). При использовании DBaaS административные задачи и обслуживание выполняются поставщиком услуг.База данных мультимоделей
База данных документов/JSON
Самоуправляемые базы данных
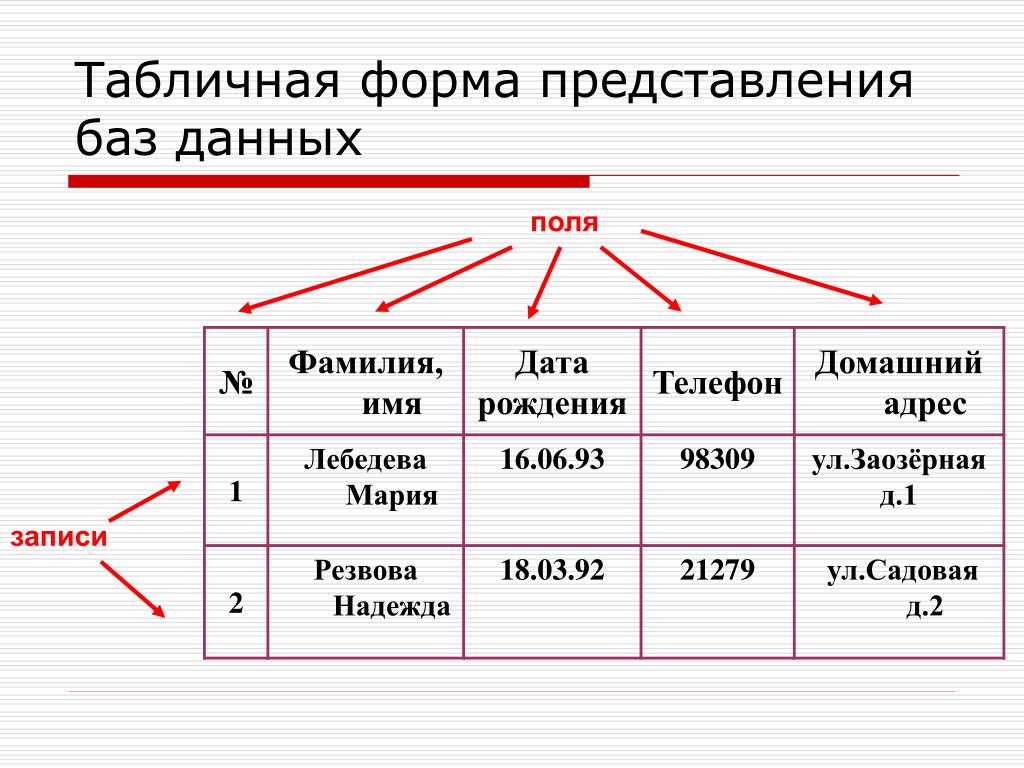 .
.Узнайте больше о беспилотных базах данных
Что такое программное обеспечение базы данных?
Программное обеспечение базы данных используется для создания, редактирования и обслуживания файлов и записей базы данных, что упрощает создание файлов и записей, ввод данных, редактирование данных, обновление и создание отчетов. Программное обеспечение также обрабатывает хранение данных, резервное копирование и отчетность, управление множественным доступом и безопасность. Надежная защита баз данных особенно важна сегодня, поскольку кражи данных становятся все более частыми. Программное обеспечение баз данных иногда также называют «системой управления базами данных» (СУБД).
Программное обеспечение базы данных упрощает управление данными, позволяя пользователям хранить данные в структурированной форме, а затем получать к ним доступ. Обычно он имеет графический интерфейс, помогающий создавать данные и управлять ими, а в некоторых случаях пользователи могут создавать свои собственные базы данных с помощью программного обеспечения баз данных.
Что такое система управления базами данных (СУБД)?
Для базы данных обычно требуется комплексное программное обеспечение базы данных, известное как система управления базами данных (СУБД). СУБД служит интерфейсом между базой данных и ее конечными пользователями или программами, позволяя пользователям извлекать, обновлять и управлять тем, как информация организована и оптимизирована. СУБД также облегчает контроль и управление базами данных, позволяя выполнять различные административные операции, такие как мониторинг производительности, настройка, резервное копирование и восстановление.
Некоторые примеры популярного программного обеспечения баз данных или СУБД включают MySQL, Microsoft Access, Microsoft SQL Server, FileMaker Pro, Oracle Database и dBASE.
Что такое база данных MySQL?
MySQL — это система управления реляционными базами данных с открытым исходным кодом, основанная на SQL. Он был разработан и оптимизирован для веб-приложений и может работать на любой платформе. По мере появления в Интернете новых и различных требований MySQL стала предпочтительной платформой для веб-разработчиков и веб-приложений. Поскольку он предназначен для обработки миллионов запросов и тысяч транзакций, MySQL является популярным выбором для предприятий электронной коммерции, которым необходимо управлять несколькими денежными переводами. Гибкость по запросу — основная особенность MySQL.
По мере появления в Интернете новых и различных требований MySQL стала предпочтительной платформой для веб-разработчиков и веб-приложений. Поскольку он предназначен для обработки миллионов запросов и тысяч транзакций, MySQL является популярным выбором для предприятий электронной коммерции, которым необходимо управлять несколькими денежными переводами. Гибкость по запросу — основная особенность MySQL.
MySQL — это СУБД, стоящая за некоторыми ведущими веб-сайтами и веб-приложениями в мире, включая Airbnb, Uber, LinkedIn, Facebook, Twitter и YouTube.
Узнайте больше о MySQL
Использование баз данных для повышения эффективности бизнеса и принятия решений
Благодаря массовому сбору данных из Интернета вещей, преобразующему жизнь и промышленность по всему миру, сегодня предприятия имеют доступ к большему количеству данных, чем когда-либо прежде. Дальновидные организации теперь могут использовать базы данных, чтобы выйти за рамки базового хранения данных и транзакций для анализа огромных объемов данных из нескольких систем. Используя базу данных и другие инструменты для вычислений и бизнес-аналитики, организации теперь могут использовать собранные данные для более эффективной работы, обеспечения более эффективного принятия решений и повышения гибкости и масштабируемости. Оптимизация доступа и пропускной способности к данным имеет решающее значение для современного бизнеса, поскольку объем данных, которые необходимо отслеживать, увеличивается. Крайне важно иметь платформу, которая может обеспечить производительность, масштабируемость и гибкость, необходимые компаниям по мере их роста с течением времени.
Используя базу данных и другие инструменты для вычислений и бизнес-аналитики, организации теперь могут использовать собранные данные для более эффективной работы, обеспечения более эффективного принятия решений и повышения гибкости и масштабируемости. Оптимизация доступа и пропускной способности к данным имеет решающее значение для современного бизнеса, поскольку объем данных, которые необходимо отслеживать, увеличивается. Крайне важно иметь платформу, которая может обеспечить производительность, масштабируемость и гибкость, необходимые компаниям по мере их роста с течением времени.
База данных самоуправляемых машин способна значительно расширить эти возможности. Поскольку самоуправляемые базы данных автоматизируют дорогостоящие и трудоемкие ручные процессы, они освобождают бизнес-пользователей для более активной работы со своими данными. Имея прямой контроль над созданием и использованием баз данных, пользователи получают контроль и автономию, сохраняя при этом важные стандарты безопасности.
Проблемы с базой данных
Современные базы данных крупных предприятий часто поддерживают очень сложные запросы, и ожидается, что ответы на эти запросы будут практически мгновенными. В результате администраторам баз данных постоянно приходится использовать самые разные методы для повышения производительности. Некоторые общие проблемы, с которыми они сталкиваются, включают:
- Поглощение значительного увеличения объема данных. Взрыв данных, поступающих от датчиков, подключенных машин и десятков других источников, заставляет администраторов баз данных изо всех сил пытаться эффективно управлять данными своих компаний и организовывать их.
- Обеспечение безопасности данных. В наши дни утечки данных происходят повсюду, и хакеры становятся все более изобретательными. Как никогда важно обеспечить безопасность данных, а также легкий доступ для пользователей.
- Идти в ногу со временем. В современной быстро меняющейся бизнес-среде компаниям необходим доступ к своим данным в режиме реального времени, чтобы поддерживать своевременное принятие решений и использовать новые возможности.
- Управление и обслуживание базы данных и инфраструктуры. Администраторы базы данных должны постоянно следить за базой данных на наличие проблем и выполнять профилактическое обслуживание, а также применять обновления и исправления программного обеспечения. По мере усложнения баз данных и роста объемов данных компании сталкиваются с расходами на наем дополнительных специалистов для мониторинга и настройки своих баз данных.
- Снятие ограничений на масштабируемость. Бизнес должен расти, если он хочет выжить, и его управление данными должно расти вместе с ним. Но администраторам баз данных очень сложно предсказать, какая емкость потребуется компании, особенно если речь идет о локальных базах данных.
- Обеспечение резидентности данных, суверенитета данных или требований к задержке. В некоторых организациях есть варианты использования, которые лучше подходят для локального запуска. В таких случаях идеально подходят спроектированные системы, предварительно сконфигурированные и предварительно оптимизированные для работы с базой данных. Согласно недавнему анализу Wikibon (PDF), заказчики получают более высокую доступность, более высокую производительность и до 40% более низкую стоимость с Oracle Exadata.

 Согласно недавнему анализу Wikibon (PDF), заказчики получают более высокую доступность, более высокую производительность и до 40% более низкую стоимость с Oracle Exadata.
Согласно недавнему анализу Wikibon (PDF), заказчики получают более высокую доступность, более высокую производительность и до 40% более низкую стоимость с Oracle Exadata.Решение всех этих проблем может занять много времени и помешать администраторам баз данных выполнять более важные стратегические функции.
Как автономные технологии улучшают управление базами данных
Автономные базы данных — это волна будущего, и они предлагают интригующую возможность для организаций, которые хотят использовать наилучшую доступную технологию баз данных без головной боли, связанной с запуском и эксплуатацией этой технологии.
Автономные базы данных используют облачные технологии и машинное обучение для автоматизации многих рутинных задач, необходимых для управления базами данных, таких как настройка, безопасность, резервное копирование, обновления и другие рутинные задачи управления. Благодаря автоматизации этих утомительных задач администраторы баз данных освобождаются для выполнения более важной стратегической работы. Возможности самостоятельного управления, самозащиты и самовосстановления самоуправляемых баз данных способны произвести революцию в том, как компании управляют своими данными и защищают их, обеспечивая преимущества в производительности, снижение затрат и повышение безопасности.
Возможности самостоятельного управления, самозащиты и самовосстановления самоуправляемых баз данных способны произвести революцию в том, как компании управляют своими данными и защищают их, обеспечивая преимущества в производительности, снижение затрат и повышение безопасности.
Будущее баз данных и автономных баз данных
О первой автономной базе данных было объявлено в конце 2017 года, и несколько независимых отраслевых аналитиков быстро оценили эту технологию и ее потенциальное влияние на вычисления.
В отчете Wikibon 2021 (PDF) высоко оценена технология автономных баз данных, в которой говорится: «У Oracle, безусловно, лучшая платформа облачных баз данных уровня 1… Wikibon считает, что у Oracle самая мощная платформа облачных баз данных с автономной базой данных».
А в отчете KuppingerCole 2021 Leadership Compass (PDF) говорится: «Автономная база данных Oracle, которая полностью автоматизирует процессы подготовки, управления, настройки и обновления экземпляров базы данных без простоев, не только значительно повышает безопасность и соответствие требованиям конфиденциальных данных, хранящихся в Oracle Databases, но является убедительным аргументом в пользу переноса этих данных в Oracle Cloud.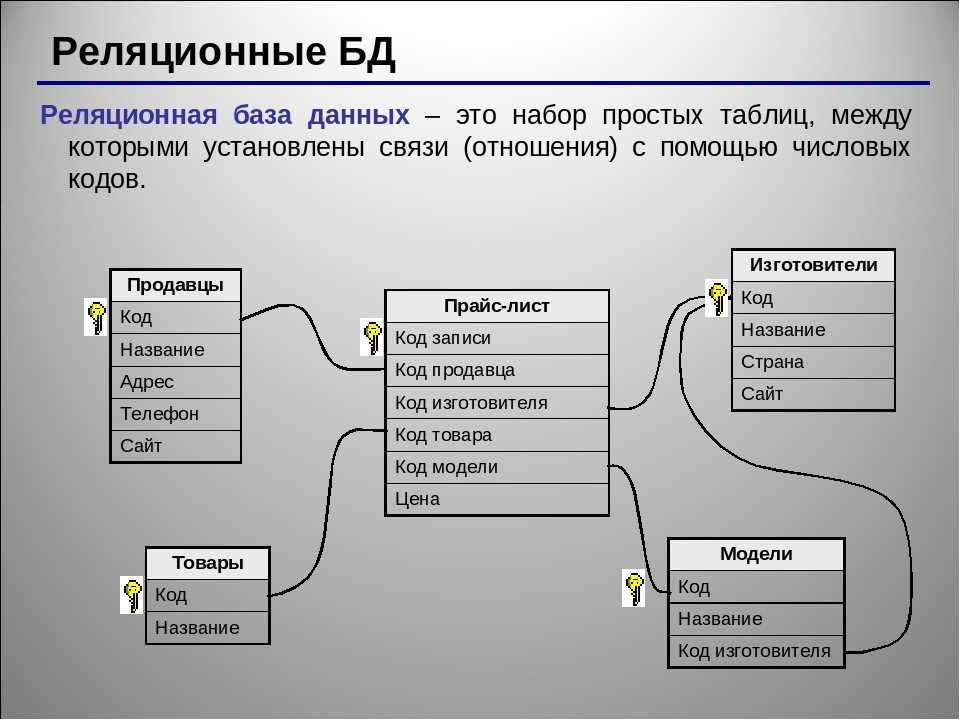 » Поскольку Oracle Autonomous Database построена на высокодоступной и масштабируемой архитектуре Oracle Exadata, развертывание базы данных можно легко масштабировать по мере роста потребностей.
» Поскольку Oracle Autonomous Database построена на высокодоступной и масштабируемой архитектуре Oracle Exadata, развертывание базы данных можно легко масштабировать по мере роста потребностей.
Связанные продукты
- Автономная база данных Oracle
- База данных Oracle
- Oracle Exadata
- Автономное хранилище данных Oracle
Что такое база данных? Определение из SearchDataManagement
По
- Бен Луткевич, Технический писатель
- Адам Хьюз
База данных — это информация, настроенная для легкого доступа, управления и обновления. Компьютерные базы данных обычно хранят совокупность записей данных или файлов, содержащих такую информацию, как транзакции продаж, данные о клиентах, финансовые показатели и информацию о продуктах.
Базы данных используются для хранения, обслуживания и доступа к любым данным. Они собирают информацию о людях, местах или вещах. Эта информация собирается в одном месте, чтобы ее можно было наблюдать и анализировать. Базы данных можно рассматривать как организованный набор информации.
Для чего используются базы данных?Компании используют данные, хранящиеся в базах данных, для принятия обоснованных бизнес-решений. Некоторые из способов, которыми организации используют базы данных, включают следующее:
- Улучшить бизнес-процессы. Компании собирают данные о бизнес-процессах, таких как продажи, обработка заказов и обслуживание клиентов. Они анализируют эти данные, чтобы улучшить эти процессы, расширить свой бизнес и увеличить доход.
- Следите за клиентами. Базы данных часто хранят информацию о людях, таких как клиенты или пользователи. Например, платформы социальных сетей используют базы данных для хранения информации о пользователях, такой как имена, адреса электронной почты и поведение пользователей. Данные используются для рекомендации контента пользователям и улучшения взаимодействия с пользователем.
- Защита личной медицинской информации. Поставщики медицинских услуг используют базы данных для безопасного хранения личных данных о состоянии здоровья, чтобы информировать и улучшать уход за пациентами.
- Хранить личные данные. Базы данных также могут использоваться для хранения личной информации. Например, личное облачное хранилище доступно для отдельных пользователей для хранения мультимедиа, например фотографий, в управляемом облаке.
 Данные используются для рекомендации контента пользователям и улучшения взаимодействия с пользователем.
Данные используются для рекомендации контента пользователям и улучшения взаимодействия с пользователем. Базы данных впервые были созданы в 1960-х годах. Эти ранние базы данных представляли собой сетевые модели, в которых каждая запись связана со многими первичными и вторичными записями. Иерархические базы данных также были среди ранних моделей. У них есть древовидные схемы с корневым каталогом записей, связанным с несколькими подкаталогами.
Реляционные базы данных были разработаны в 1970-х годах. Затем в 1980-х годах появились объектно-ориентированные базы данных. Сегодня мы используем язык структурированных запросов (SQL), NoSQL и облачные базы данных.
Э. Ф. Кодд создал реляционную базу данных, работая в IBM. Он стал стандартом для систем баз данных благодаря своей логической схеме или способу организации. Использование логической схемы отделяет реляционную базу данных от физического хранилища.
Реляционная база данных в сочетании с ростом Интернета, начавшимся в середине 1990-х годов привело к быстрому распространению баз данных. Многие бизнес-приложения и потребительские приложения полагаются на базы данных.
Существует множество типов баз данных. Их можно классифицировать по типу контента: библиографические, полнотекстовые, числовые и изображения. В вычислительной технике базы данных часто классифицируют на основе используемого ими организационного подхода.
Некоторые из основных организационных баз данных включают следующее:
Относительный. Этот табличный подход определяет данные, чтобы их можно было реорганизовать и получить к ним доступ разными способами. Реляционные базы данных состоят из таблиц. Данные помещаются в предопределенные категории в этих таблицах. В каждой таблице есть столбцы по крайней мере с одной категорией данных и строки, содержащие определенные экземпляры данных для категорий, определенных в столбцах. Информация в реляционной базе данных о конкретном клиенте организована в строки, столбцы и таблицы. Они индексируются, чтобы упростить поиск с использованием запросов SQL или NoSQL.
Реляционные базы данных используют SQL в интерфейсах пользователя и прикладных программ. Новую категорию данных можно легко добавить в реляционную базу данных без изменения существующих приложений. Система управления реляционными базами данных (RDBMS) используется для хранения, управления, запроса и извлечения данных в реляционной базе данных.
Как правило, РСУБД дает пользователям возможность контролировать доступ для чтения/записи, определять создание отчетов и анализировать использование. Некоторые базы данных предлагают атомарность, непротиворечивость, изоляцию и устойчивость или соответствие ACID, чтобы гарантировать непротиворечивость данных и завершение транзакций.
Распространяется. Эта база данных хранит записи или файлы в нескольких физических местах. Обработка данных также распределена и реплицируется в разных частях сети.
Распределенные базы данных могут быть однородными, когда все физические местоположения имеют одно и то же базовое оборудование и работают с одними и теми же операционными системами и приложениями баз данных. Они также могут быть неоднородными. В этих случаях аппаратное обеспечение, ОС и приложения базы данных могут различаться в разных местах.
Облако. Эти базы данных создаются в общедоступном, частном или гибридном облаке для виртуализированной среды. С пользователей взимается плата в зависимости от объема используемого хранилища и полосы пропускания. Они также обеспечивают масштабируемость по запросу и высокую доступность . Эти базы данных могут работать с приложениями, развернутыми как программное обеспечение как услуга.
NoSQL. Базы данных NoSQL хороши при работе с большими коллекциями распределенных данных. Они могут решать проблемы с производительностью больших данных лучше, чем реляционные базы данных. Они также хорошо анализируют большие наборы неструктурированных данных и данные на виртуальных серверах в облаке. Эти базы данных также можно назвать нереляционными базами данных.
Объектно-ориентированный. Эти базы данных содержат данные, созданные с использованием языков объектно-ориентированного программирования . Они сосредоточены на организации объектов, а не на действиях и данных, а не на логике. Например, запись данных изображения будет объектом данных, а не буквенно-цифровым значением.
График. Эти базы данных относятся к типу базы данных NoSQL. Они хранят, отображают и запрашивают отношения, используя концепции теории графов. Базы данных графов состоят из узлов и ребер. Узлы являются сущностями и соединяют узлы.
Эти базы данных часто используются для анализа взаимосвязей. Базы данных Graph часто используются для анализа данных о клиентах, когда они взаимодействуют с бизнесом на веб-страницах и в социальных сетях.
Graph используют для аналитики SPARQL, язык декларативного программирования и протокол. SPARQL может выполнять всю аналитику, которую может выполнять SQL, а также может использоваться для семантического анализа или изучения взаимосвязей. Это делает его полезным для выполнения аналитики наборов данных, которые содержат как структурированные, так и неструктурированные данные. SPARQL позволяет пользователям выполнять аналитику информации, хранящейся в реляционной базе данных, а также отношений друзей-другов, PageRank и кратчайшего пути.
Сравните графовые и реляционные базы данных. Каковы компоненты базы данных?Хотя различные типы баз данных различаются по схеме, структуре данных и наиболее подходящим для них типам данных, все они состоят из одних и тех же пяти основных компонентов.
- Оборудование. Это физическое устройство, на котором работает программное обеспечение базы данных. Аппаратное обеспечение базы данных включает компьютеры, серверы и жесткие диски.
- Программное обеспечение. Программное обеспечение или приложение базы данных предоставляет пользователям контроль над базой данных. Программное обеспечение системы управления базами данных (СУБД) используется для управления и контроля баз данных.
- Данные. Это необработанная информация, которую хранит база данных. Администраторы базы данных организуют данные, чтобы сделать их более значимыми.
- Язык доступа к данным. Это язык программирования, управляющий базой данных. Язык программирования и СУБД должны работать вместе. Одним из наиболее распространенных языков баз данных является SQL.
- Процедуры. Эти правила определяют, как работает база данных и как она обрабатывает данные.
Настройка, эксплуатация и обслуживание базы данных сопряжены с некоторыми общими проблемами, такими как следующие:
- Защита данных требуется, поскольку данные являются ценным деловым активом. Для защиты хранилищ данных требуется квалифицированный персонал по кибербезопасности, что может быть дорогостоящим.
- Целостность данных гарантирует, что данные заслуживают доверия. Добиться целостности данных не всегда просто, потому что это означает, что доступ к базам данных должен быть предоставлен только тем, кто имеет право работать с ними.
- Производительность базы данных требует регулярного обновления и обслуживания базы данных. Без надлежащей поддержки функциональность базы данных может снизиться по мере изменения технологии, поддерживающей базу данных, или данных, которые она содержит.
- Интеграция базы данных также может быть сложной. Это может включать интеграцию источников данных из различных типов баз данных и структур в единую базу данных или в озера данных и хранилища данных.
Что такое система управления базами данных?СУБД позволяет пользователям создавать базу данных и управлять ею. Он также помогает пользователям создавать, читать, обновлять и удалять данные в базе данных, а также помогает с функциями ведения журнала и аудита.
СУБД обеспечивает физическую и логическую независимость от данных. Пользователям и приложениям не нужно знать ни физическое, ни логическое расположение данных. СУБД также может ограничивать и контролировать доступ к базе данных и предоставлять различные представления одной и той же схемы базы данных нескольким пользователям.
Узнайте больше о современном состоянии управления данными и о том, как в него вписываются базы данных.
Последнее обновление: сентябрь 2021 г.
Продолжить чтение О базе данных (БД)- В чем разница между СУБД и РСУБД?
- Как тщательно спланировать миграцию базы данных в облако
- Основные рекомендации по миграции баз данных в облако для предприятий
- Как выбрать правильную архитектуру базы данных IoT
- Как правильно выбрать базу данных
Оценка различных типов продуктов СУБД
Автор: Крейг Маллинз
система управления базами данных (СУБД)
Автор: Крейг Маллинз
SQL, NoSQL и NewSQL: как они сравниваются?
Автор: Крейг Маллинз
денормализация
Автор: Гэвин Райт
ПоискБизнесАналитика
- Qlik представляет пару новых интеграций с Databricks
Один предназначен для того, чтобы совместные пользователи могли легко вводить данные в домики на озере, а другой предназначен для того, чтобы потенциальные пользователи могли .
.. - SAS и Microsoft сделали Viya доступной на Azure Marketplace
Поставщики стремятся продать аналитическую платформу новой аудитории клиентов самообслуживания, которые смогут быстро развернуть …
- Starburst добавляет инструменты для расширения возможностей сетки данных
Поставщик добавил функции совместного использования продуктов данных и наборов данных, а также расширенные возможности управления, направленные на обеспечение …
ПоискAWS
- AWS Control Tower стремится упростить управление несколькими учетными записями
Многие организации изо всех сил пытаются управлять своей огромной коллекцией учетных записей AWS, но Control Tower может помочь. Услуга автоматизирует…
- Разбираем модель ценообразования Amazon EKS
В модели ценообразования Amazon EKS есть несколько важных переменных.
Покопайтесь в цифрах, чтобы убедиться, что вы развернули службу… - Сравните EKS и самоуправляемый Kubernetes на AWS
Пользователи AWS сталкиваются с выбором при развертывании Kubernetes: запускать его самостоятельно на EC2 или позволить Amazon выполнять тяжелую работу с помощью EKS. См…
SearchContentManagement
- 6 лучших практик управления информацией о продуктах
Системы PIM поддерживают точные данные о продуктах по каналам. Для успешного внедрения руководителям предприятий следует определить…
- 7 распространенных угроз безопасности обмена файлами
ИТ-администраторы должны понимать основные риски безопасности при обмене файлами и что делать, чтобы они не создавали уязвимостей …
- Как создать контент-стратегию электронной коммерции для увеличения продаж
Стратегия контента, включающая автоматизированную CMS, полезную информацию о продукте и визуальные эффекты, может привлечь внимание клиентов к вашему .
..
ПоискOracle
- Oracle ставит перед собой высокие национальные цели в области ЭУЗ с приобретением Cerner
Приобретя Cerner, Oracle нацелилась на создание национальной анонимной базы данных пациентов — дорога, заполненная …
- Благодаря Cerner Oracle Cloud Infrastructure получает импульс
Oracle планирует приобрести Cerner в рамках сделки на сумму около 30 миллиардов долларов. Второй по величине поставщик электронных медицинских карт в США может вдохнуть новую жизнь в …
- Верховный суд встал на сторону Google в иске о нарушении авторских прав на Oracle API
Верховный суд постановил 6-2, что API-интерфейсы Java, используемые в телефонах Android, не подпадают под действие американского закона об авторском праве, положив конец …
ПоискSAP
- Сантандер присоединяется к SAP MBC, чтобы внедрить финансы в процессы
SAP Multi-Bank Connectivity добавил Santander Bank в свой список партнеров, чтобы помочь компаниям упростить внедрение .
.. - В 50 лет SAP оказалась на очередном распутье
За свою 50-летнюю историю компания SAP вывела бизнес и технологические тренды на вершину индустрии ERP, но сейчас она находится на перепутье …
- Сторонняя поддержка SAP обеспечивает гибкость миграции
Сторонние поставщики услуг поддержки заявляют, что они могут обеспечить большую гибкость при меньших затратах, но клиенты должны подумать…
Что такое база данных? Определение, значение, типы с примером
Прежде чем мы узнаем о базе данных, давайте разберемся —
Что такое данные?
Проще говоря, данные могут быть фактами, относящимися к любому рассматриваемому объекту. Например, ваше имя, возраст, рост, вес и т. д. — это некоторые данные, относящиеся к вам. Картинка, изображение, файл, pdf и т. д. также могут считаться данными.
Что такое база данных?
База данных представляет собой систематизированный набор данных. Они поддерживают электронное хранение и обработку данных. Базы данных упрощают управление данными.
Давайте обсудим пример с базой данных. Онлайновый телефонный справочник использует базу данных для хранения данных о людях, телефонных номерах и других контактных данных. Ваш поставщик электроэнергии использует базу данных для управления выставлением счетов, проблемами, связанными с клиентами, обработкой данных о неисправностях и т. д.
Возьмем также Facebook. Он должен хранить, обрабатывать и представлять данные, связанные с участниками, их друзьями, действиями участников, сообщениями, рекламой и многим другим. Мы можем предоставить бесчисленное количество примеров использования баз данных.
Типы баз данных
Вот несколько популярных типов баз данных.
Распределенные базы данных:
Распределенная база данных — это тип базы данных, который содержит данные из общей базы данных и информацию, полученную локальными компьютерами. В системе баз данных этого типа данные не находятся в одном месте и распределены по разным организациям.
Реляционные базы данных:
Этот тип базы данных определяет отношения базы данных в виде таблиц. Ее также называют реляционной СУБД, которая является самым популярным типом СУБД на рынке. Пример базы данных системы RDBMS включает базу данных MySQL, Oracle и Microsoft SQL Server.
Объектно-ориентированные базы данных:
Этот тип компьютерной базы данных поддерживает хранение всех типов данных. Данные хранятся в виде объектов. Объекты, которые должны храниться в базе данных, имеют атрибуты и методы, которые определяют, что делать с данными. PostgreSQL является примером объектно-ориентированной реляционной СУБД.
Централизованная база данных:
Это централизованное место, и пользователи с разным опытом могут получить доступ к этим данным. Базы данных компьютеров этого типа хранят прикладные процедуры, которые помогают пользователям получать доступ к данным даже из удаленного места.
Базы данных с открытым исходным кодом:
В таких базах данных хранится информация, связанная с операциями. Он в основном используется в области маркетинга, отношений с сотрудниками, обслуживания клиентов, баз данных.
Облачные базы данных:
Облачная база данных — это база данных, оптимизированная или созданная для такой виртуализированной среды. Есть так много преимуществ облачной базы данных, некоторые из которых могут оплачиваться за емкость хранилища и пропускную способность. Он также предлагает масштабируемость по требованию наряду с высокой доступностью.
Хранилища данных:
Хранилище данных должно способствовать единой версии правды для компании для принятия решений и прогнозирования. Хранилище данных — это информационная система, которая содержит исторические и коммутативные данные из одного или нескольких источников. Концепция хранилища данных упрощает процесс отчетности и анализа в организации.
Базы данных NoSQL:
База данных NoSQL используется для больших наборов распределенных данных. Есть несколько проблем производительности больших данных, которые эффективно решаются реляционными базами данных. Этот тип компьютерной базы данных очень эффективен при анализе неструктурированных данных большого размера.
Базы данных графов:
База данных, ориентированная на графы, использует теорию графов для хранения, отображения и запросов взаимосвязей. Такие компьютерные базы данных в основном используются для анализа взаимосвязей. Например, организация может использовать графовую базу данных для сбора данных о клиентах из социальных сетей.
Базы данных OLTP:
OLTP — еще один тип базы данных, способный выполнять быструю обработку запросов и поддерживать целостность данных в средах с множественным доступом.
Персональная база данных:
Персональная база данных используется для хранения данных, хранящихся на персональных компьютерах, которые меньше по размеру и легко управляемы. Данные в основном используются одним и тем же отделом компании и доступны небольшой группе людей.
Мультимодальная база данных:
Мультимодальная база данных — это тип платформы обработки данных, которая поддерживает несколько моделей данных, определяющих, как определенные знания и информация в базе данных должны быть организованы и организованы.
База данных документов/JSON:
В базе данных, ориентированной на документы, данные хранятся в коллекциях документов, обычно с использованием форматов XML, JSON, BSON. Одна запись может хранить столько данных, сколько вы хотите, в любом типе данных (или типах), который вы предпочитаете.
Иерархическая:
Этот тип СУБД использует отношения «родитель-потомок» для хранения данных. Его структура похожа на дерево с узлами, представляющими записи, и ветвями, представляющими поля. Реестр Windows, используемый в Windows XP, является примером иерархической базы данных.
Сетевая СУБД:
Этот тип СУБД поддерживает отношения «многие ко многим». Обычно это приводит к сложной структуре базы данных. RDM Server является примером системы управления базами данных, реализующей сетевую модель.
Компоненты базы данных
База данных состоит из пяти основных компонентов:
Аппаратное обеспечение:
Аппаратное обеспечение состоит из физических электронных устройств, таких как компьютеры, устройства ввода-вывода, устройства хранения и т. д. Это обеспечивает интерфейс между компьютерами и реальным миром. системы.
Программное обеспечение:
Это набор программ, используемых для управления и контроля всей базы данных. Это включает в себя само программное обеспечение базы данных, операционную систему, сетевое программное обеспечение, используемое для обмена данными между пользователями, и прикладные программы для доступа к данным в базе данных.
Данные:
Данные — это необработанный и неорганизованный факт, который необходимо обработать, чтобы сделать его значимым. Данные могут быть простыми и в то же время неорганизованными, если они не организованы. Как правило, данные включают факты, наблюдения, восприятия, числа, символы, символы, изображения и т. д.
Процедура:
Процедура представляет собой набор инструкций и правил, которые помогут вам использовать СУБД. Это проектирование и запуск базы данных с использованием документированных методов, что позволяет вам направлять пользователей, которые работают с ней и управляют ею.
Язык доступа к базе данных:
Язык доступа к базе данных используется для доступа к данным в базе данных и из нее, ввода новых данных, обновления уже существующих данных или извлечения необходимых данных из СУБД. Пользователь пишет определенные команды на языке доступа к базе данных и отправляет их в базу данных.
Что такое система управления базами данных (СУБД)?
Система управления базами данных (СУБД) представляет собой набор программ, которые позволяют пользователям получать доступ к базам данных, манипулировать данными, составлять отчеты и представлять данные. Это также помогает контролировать доступ к базе данных. Системы управления базами данных не являются новой концепцией и как таковые были впервые реализованы в 1960-х годах.
Интегрированное хранилище данных (IDS) Чарльза Бахмана считается первой СУБД в истории. С базой данных времени технологии сильно развились, в то время как использование и ожидаемые функциональные возможности баз данных значительно увеличились.
История системы управления базами данных
Вот важные вехи истории:
- 1960 – Чарльз Бахман разработал первую систему СУБД.
- 1970 – Кодд представил Систему управления информацией IBM (IMS).
- 1976 г. — Питер Чен придумал и определил модель отношения сущности, также известную как модель ER.
- 1980 — Реляционная модель становится широко распространенным компонентом базы данных.
- 1985 – Разработка объектно-ориентированной СУБД.
- 1990 – Включение объектной ориентации в реляционные СУБД.
- 1991 г. — Microsoft выпускает MS Access, персональную СУБД, которая вытесняет все другие продукты для персональных СУБД.
- 1995 г. — Первые приложения для работы с базами данных в Интернете.
- 1997 г. — XML применяется для обработки базы данных. Многие поставщики начинают интегрировать XML в продукты СУБД.
Преимущества СУБД
- СУБД предлагает множество методов для хранения и извлечения данных. СУБД
- служит эффективным обработчиком для балансировки потребностей нескольких приложений, использующих одни и те же данные.
- Единые процедуры администрирования данных.
- Разработчики приложений никогда не знакомились с деталями представления и хранения данных.
- СУБД использует различные мощные функции для эффективного хранения и извлечения данных.
- Обеспечивает целостность и безопасность данных.
- В СУБД предусмотрены ограничения целостности для получения высокого уровня защиты от запрещенного доступа к данным.
- СУБД планирует одновременный доступ к данным таким образом, что только один пользователь может получить доступ к одним и тем же данным в любой момент времени.
- Сокращение времени разработки приложений.
Недостатки СУБД
СУБД может предложить множество преимуществ, но у нее есть определенные недостатки-
- Стоимость аппаратного и программного обеспечения СУБД довольно высока, что увеличивает бюджет вашей организации.
- Большинство систем управления базами данных часто представляют собой сложные системы, поэтому требуется обучение пользователей работе с СУБД.
- В некоторых организациях все данные объединены в единую базу данных, которая может быть повреждена из-за сбоя электропитания или повреждения базы данных на носителе.
- Использование одной и той же программы одновременно многими пользователями иногда приводит к потере некоторых данных.
- СУБД не может выполнять сложные вычисления.
Резюме
- Определение базы данных или значения базы данных: База данных представляет собой систематизированный набор данных. Они поддерживают электронное хранение и обработку данных. Базы данных упрощают управление данными.
- СУБД расшифровывается как Система управления базами данных .
- У нас есть четыре основных типа СУБД, а именно иерархическая, сетевая, реляционная и объектно-ориентированная
- Наиболее широко используемой СУБД является реляционная модель, сохраняющая данные в табличных форматах. Он использует SQL в качестве стандартного языка запросов .
Что такое база данных? Типы, примеры и преимущества
Обновлено 26.07.22 654 Views
Ниже перечислены некоторые темы, которые помогут вам глубже и проще понять концепцию баз данных. Сначала мы начнем с изучения данных.
- Что такое данные?
- Что такое база данных?
- Evolution of database
- Components of database
- Applications of Database
- Types of Databases
- Database Architecture
- Advantages of Databases
- Database Languages
- Система управления базами данных
- Примеры баз данных
- Преимущества системы управления базами данных
- Недостатки системы управления базами данных
- Заключение
Дальновидные предприятия используют базы данных в своих интересах, выходя за рамки базовых требований к хранению данных и транзакций и анализируя свои данные из нескольких систем.
Данные — это не что иное, как информация, которая собирается в различных форматах, таких как числа, текст, мультимедиа и другие. В контексте вычислений данные могут быть преобразованы в двоичную цифровую форму, что обеспечивает гибкость перемещения и эффективную обработку. Например, Intellipaat может располагать такими данными, как имена, возраст и образовательная квалификация своих студентов, сведения о различных курсах, которые он предлагает, и т. д.
Термин «данные» может использоваться как в единственном, так и во множественном числе. Время от времени мы сталкиваемся с термином необработанные данные. Это не что иное, как данные в самом простом цифровом формате. На заре своего существования, когда важность данных начала набирать обороты, такие термины, как «электронная обработка данных» или просто «обработка данных», стали широко использоваться в ИТ-индустрии.
По мере того, как данные росли в геометрической прогрессии с годами, продолжали расти и единицы измерения данных. PwC упомянула, что в 2019 году было сгенерировано 4,4 ZB (зеттабайта) данных.Мировой. С другой стороны, IDC предсказывала, что к 2025 году он вырастет до 175 ZB. Для организации всех этих данных быстро возникли базы данных, системы управления базами данных (СУБД) и системы управления реляционными базами данных (RDBMS).
Вы можете зарегистрироваться на курс MySQL , предлагаемый Intellipaat.
Что такое база данных? База данных представляет собой систематизированный или организованный набор связанной информации, которая хранится таким образом, чтобы к ней можно было легко получить доступ, получить ее, управлять ею и обновлять. Именно здесь хранятся все данные, очень похожие на библиотеку, в которой хранится широкий спектр книг разных жанров. Думайте о данных как о книгах.
В базе данных вы можете организовать данные в строках и столбцах в виде таблицы. Индексация данных позволяет легко находить и извлекать их снова по мере необходимости. Многие веб-сайты во всемирной паутине управляются с помощью баз данных. Чтобы создать базу данных, чтобы данные были доступны пользователям только через один набор программ, используются обработчики базы данных.
MySQL, SQL Server, MongoDB, Oracle Database, PostgreSQL, Informix, Sybase и т. д. — все это примеры разных баз данных. Эти современные базы данных управляются СУБД. Язык структурированных запросов, или более известный как SQL, используется для работы с данными в базе данных.
База данных обычно представляет собой цилиндрическую структуру.
Эволюция базы данныхБаза данных началась с файловой системы около 50 лет назад. В свое время она прошла через поколения эволюции.
- Базы данных были впервые представлены в 1968 году как базы данных на основе плоских файлов.
- Затем появилась иерархическая база данных, которая просуществовала до 1980 года. На ней была основана первая база данных IBM, IMS (система управления информацией).
- Чарльз Бахман разработал первую сетевую модель данных, названную Integrated Data Store (IDS). Она была представлена в начале 1960-х годов и стандартизирована в 1971 году.
- В 1970 году была представлена реляционная база данных.
- Сегодня наступила эра реляционных баз данных и управления базами данных.
- Аппаратное обеспечение: физические электронные устройства, такие как устройства хранения данных, устройства ввода/вывода и многое другое. Он может действовать как интерфейс между компьютерами и реальными системами.
- Программное обеспечение: Программы для управления и контроля всей базы данных. Сама СУБД является программным обеспечением. Операционная система, прикладные программы базы данных, которые обеспечивают доступ к данным в СУБД, сетевое программное обеспечение, которое совместно использует данные, и т. д. — все это примеры.
- Данные: это информация, которая собирается, хранится, используется и обрабатывается СУБД, например, фактические данные, рабочие данные и метаданные.
- Процедура: Это специальный набор инструкций и правил по использованию базы данных для проектирования и запуска СУБД, а также для обучения пользователей тому, как с ней работать и управлять ею.
- Язык доступа к базе данных: помогает экспортировать данные в базу данных и получать к ней доступ. Чтобы ввести новые данные или обновить или получить данные из базы данных, вы можете написать команды на языке доступа к базе данных. Затем СУБД отображает результаты в удобочитаемой форме.
Д. База данных может находиться в одном физическом месте на нескольких компьютерах или разбросана по разным сетям.Чтобы узнать больше о базах данных, посетите наш блог Сравнение технологий баз данных с Apache Hadoop .
Архитектура баз данныхАрхитектура баз данных на предприятиях и в организациях включает применение языков программирования для разработки программного обеспечения. В основном это включает в себя проектирование, внедрение, разработку и обслуживание компьютерных программ, которые хранят и управляют данными для бизнеса.
Архитектура определяет структуру СУБД. Архитектура может быть одноуровневой или многоуровневой, например одноуровневая, двухуровневая, трехуровневая, многоуровневая и т. д.
Преимущества баз данных- Минимальная избыточность данных Повышенная безопасность данных
- Повышенная согласованность
- Уменьшение количества ошибок обновления
- Снижение затрат на ввод, хранение и извлечение данных
- Улучшенный доступ к данным с использованием хост-языков и языков запросов
- Более высокая целостность данных из прикладных программ
СУБД предоставляет пользователям соответствующий язык для выполнения запросов к базам данных и обновлений. По сути, он создает и поддерживает базу данных. Некоторыми примерами языков баз данных являются SQL, Oracle, dBase, MS Access, FoxPro и т. д. Языки баз данных обычно делятся на язык определения данных (DDL), язык управления данными (DCL), язык манипулирования данными (DML) и язык управления транзакциями ( ТКЛ).
Язык определения данных (DDL): помогает определять данные и их связь с другими типами данных и создает базы данных, файлы, таблицы и словари данных в базах данных
Язык управления данными (DCL): контролирует доступ к данным и базе данных
Язык манипулирования данными (DML): поддерживает основные операции манипулирования данными, такие как разрешение пользователям вставлять, извлекать, обновлять и удалять данные из базы данных
Язык управления транзакциями (TCL): управляет изменениями в базе данных, сделанными оператором DML
Система управления базами данных Система управления базами данных или СУБД — это тип программного обеспечения, помогающего управлять базой данных. Он используется для поиска и хранения информации в базе данных. Он может быть изменен в соответствии с потребностями пользователя. Это добавляет уровень безопасности к базе данных.
Получите 100% повышение!
Осваивайте самые востребованные навыки прямо сейчас!
Примеры базы данныхНесколько примеров базы данных:
- Microsoft SQL Server — SQL Server, разработанный Microsoft, представляет собой систему управления реляционными базами данных. Он построен на SQL, стандартном языке запросов для систем управления базами данных.
- База данных Oracle. Разработанная корпорацией Oracle, база данных Oracle основана на мультимодельной СУБД. Он широко используется при обработке онлайн-транзакций.
- MySQL. Основанная на языке структурированных запросов (SQL), MySQL представляет собой систему управления реляционными базами данных. Он используется на платформах электронной коммерции, хранилищах данных и т. Д. Он широко используется в качестве системы управления веб-базами данных.
- IBM Db2 — Db2 — это система управления реляционными базами данных, разработанная IBM. Он предназначен для эффективного анализа, хранения и извлечения данных.
- PostgreSQL — система управления реляционными базами данных с открытым исходным кодом, Postgre может использоваться бесплатно. Он широко используется для хранения данных.
- Данные хранятся более аккуратно и, следовательно, можно хранить больше данных.
- СУБД — это высоконадежная платформа, поэтому конфиденциальные данные и данные с высокой степенью риска также могут безопасно храниться и получать к ним доступ.
- СУБД делает обработку данных очень простой.
- Несогласованность данных значительно снижается благодаря хорошо спроектированной СУБД.
- Доступ к данным возможен быстро.
- Обслуживание программного и аппаратного обеспечения, необходимого для СУБД, обычно дорого.
- Чем больше данных загружается в СУБД, тем больше места на диске она занимает.
- Использование СУБД может показаться очень сложным для человека, не имеющего технического образования.
- Поскольку все данные хранятся в одной СУБД, в случае сбоя программного обеспечения могут быть потеряны все данные организации.
С помощью баз данных и других инструментов бизнес-аналитики и вычислительных средств специалисты в организациях могут использовать организованные данные для улучшения и повышения эффективности принятия решений, повышения гибкости и масштабируемости. Различные типы баз данных, а также изменения в подходах к технологиям, достижения в области автоматизации и облачных вычислений заставляют базы данных двигаться в новых направлениях.
Расписание курсов
Поговорите с нашим консультантом по курсам прямо сейчас!
SQL для науки о данных — изучите основы SQL для данных.
..Обновлено: 26 мая 2022 г.
Что такое NoSQL?
Обновлено: 17 сентября 2022 г.
Оптимизация SQL-запросов: советы и методы
Обновлено: 29 июля 2022 г.
Spark SQL — функции и примеры
Обновлено: 13 июня 2022 г.
Сертификация SQL Server
Обновлено: 08 января 2022 г.
Ассоциированные курсы
Учебник по SQL для начинающих
Обновлено: 26 июля 2022 г.
Учебное пособие по PL/SQL — изучите Oracle PL/SQL на опыте…
Обновлено: 16 июня 2022 г.
Учебное пособие по Oracle DBA: изучите Oracle DBA на опыте…
Обновлено: 22 апреля 2022 г.
Учебное пособие по Couchbase — изучите Couchbase у эксперта…
Обновлено: 22 апреля 2022 г.
Учебное пособие по Cassandra — Изучите Cassandra от эксперта…
Обновлено: 18 августа 2022 г.
Учебное пособие по MongoDB — изучите MongoDB у экспертов
Обновлено: 20 апреля 2022 г.
Все учебники
Подпишитесь на нашу рассылку
Подпишитесь на нашу еженедельную рассылку, чтобы получать последние новости, обновления и удивительные предложения прямо на ваш почтовый ящик.
Что такое база данных — Глоссарий ИТ
- SolarWinds использует файлы cookie на своих веб-сайтах, чтобы сделать вашу работу в Интернете проще и лучше. Используя наш веб-сайт, вы даете согласие на использование нами файлов cookie. Для получения дополнительной информации о файлах cookie см. нашу Политику использования файлов cookie. Продолжать
Ресурсы
Базы данных
Отслеживайте, анализируйте и оптимизируйте производительность кроссплатформенной базы данных.
- Определение базы данных
- Типы баз данных
- Что такое система управления базами данных (СУБД)?
- Какие существуют типы СУБД?
- Преимущества использования СУБД
- Какие существуют типы архитектуры базы данных?
- Что делает последовательность операций с базой данных транзакцией?
- Как использование СУБД может улучшить эффективность бизнеса и процесс принятия решений?
- Определение базы данных
Определение базы данных
База данных — это набор важных для бизнеса данных, организованный таким образом, чтобы соответствующая информация была легкодоступной и управляемой.
Основной целью создания базы данных является хранение, управление и быстрое извлечение большого объема информации. - Типы баз данных
Типы баз данных
Существует два основных типа баз данных, известных как реляционные и нереляционные базы данных:
- Реляционная база данных: Реляционные базы данных определяют отношения между объектами. Запросы в реляционной базе данных выполняются с использованием языка структурированных запросов (SQL), специально разработанного для управления данными в реляционной базе данных. Она также известна как система управления реляционными базами данных (RDBMS) или база данных SQL.
- Нереляционная база данных: В отличие от реляционной базы данных, где данные организованы в таблицы и строки, нереляционная база данных использует модель хранения, оптимизированную в зависимости от типа сохраняемых данных. Она также известна как база данных NoSQL.
- Что такое система управления базами данных (СУБД)?
Что такое система управления базами данных (СУБД)?
Система управления базами данных (СУБД) — это программное обеспечение, используемое для хранения, управления и извлечения данных из базы данных и состоящее из программ, созданных для приема запросов на извлечение данных и отображения определенных данных. Примеры СУБД включают MySQL, PostgreSQL, Oracle, ASE, RDS и SQL Server.
- Какие существуют типы СУБД?
Какие существуют типы СУБД?
Ниже перечислены некоторые популярные типы баз данных:
- Распределенная база данных: В этой системе баз данных информация не централизована в одном месте, а распределена по нескольким местоположениям
- Объектно-ориентированная база данных: Объектно-ориентированная база данных — это база данных, в которой данные хранятся как объекты. Эти объекты включают атрибуты и методы, определяющие использование данных.
- Централизованная база данных: Централизованная база данных хранит данные в одном месте, чтобы пользователям было проще получать к ним доступ и управлять ими. В основном он хранит процедуры, позволяющие пользователям получать доступ к данным в любое время, даже из удаленного места. Пользователи могут использовать эту систему баз данных.
- Облачная база данных: Облачная база данных может быть разработана специально для виртуализированной среды. Существует несколько преимуществ использования облачной базы данных, в том числе большой объем хранилища данных, высокая пропускная способность, высокая доступность и масштабируемость по требованию.
- Иерархическая база данных: Иерархическая база данных использует отношения родитель-потомок для хранения важных данных. Он организован в виде древовидной структуры, где узлы представляют записи, а ветви — поля.
- База данных графов: база данных, использующая структуры графов для семантических запросов с ребрами, узлами и свойствами для хранения данных.
- Преимущества использования СУБД
Преимущества использования СУБД
Система управления базами данных предназначена для помощи в организации данных для обеспечения плавных и эффективных операций, таких как категоризация и структура данных. Система управления базами данных может позволить пользователям удалять устаревшие данные, обновлять текущие данные и легче включать новые данные. Например, с помощью языка запросов SQL или через пользовательский интерфейс СУБД может упростить пользователям способ обновления, доступа и обработки данных, хранящихся в базе данных.
Помимо поддержки лучшего управления данными, существуют и другие преимущества использования СУБД, в том числе улучшенная видимость: в то время как некоторые решения СУБД предлагают базовые функции хранения данных и транзакций, другие системы управления базами данных могут помочь вам более легко находить данные, полученные из нескольких баз данных, сохраняя данные в централизованное расположение.
- Какие существуют типы архитектуры базы данных?
Какие существуют типы архитектуры базы данных?
Архитектура СУБД помогает пользователям понять различные компоненты базы данных. Существует три основных типа архитектуры СУБД:
- Одноуровневая архитектура: В одноуровневой архитектуре база данных легко доступна для предоставления информации непосредственно авторизованным пользователям.
- Двухуровневая архитектура: И серверная машина, состоящая из системы баз данных, и клиентская машина, состоящая из приложения СУБД, подключены через сетевое соединение.
- Трехуровневая архитектура: В трехуровневой архитектуре есть дополнительный уровень. Сервер и клиент не могут общаться напрямую для получения конкретной информации.
- Одноуровневая архитектура: В одноуровневой архитектуре база данных легко доступна для предоставления информации непосредственно авторизованным пользователям.
- Что делает последовательность операций с базой данных транзакцией?
Что делает последовательность операций с базой данных транзакцией?
Транзакция в базе данных определяется как логическая или атомарная единица работы, состоящая из одного или нескольких запросов SQL для выполнения задачи.
Транзакция может включать в себя несколько операторов SQL, которые откатываются, если один запрос не может выполнить запрос. - Как использование СУБД может улучшить эффективность бизнеса и процесс принятия решений?
Как использование СУБД может улучшить эффективность бизнеса и процесс принятия решений?
Организация может использовать СУБД для обеспечения возможности доступа и обработки больших объемов важных для бизнеса данных. Предприятия могут использовать системы управления базами данных для упрощения обмена данными, что может помочь в информировании различных операций. С помощью надежной СУБД организации могут более эффективно обрабатывать большие объемы данных и принимать более быстрые и обоснованные бизнес-решения.
Представлено в этом ресурсе
Как то, что вы видите? Попробуйте продукты.
Анализатор производительности базы данных
Мониторинг и оптимизация нескольких платформ СУБД никогда не были проще
СКАЧАТЬ БЕСПЛАТНУЮ ПРОБНУЮ ПРОБНУЮ ВЕРСИЮ Полная функциональность в течение 14 дней ССЫЛКА НА ПРОБНУЮ ПРОБНУЮ ЭЛЕКТРОННУЮ ПОЧТУ Полная функциональность в течение 14 дней
Монитор производительности базы данных
Мониторинг производительности базы данных и оптимизация для традиционных баз данных, баз данных с открытым исходным кодом и облачных баз данных.
НАЧАТЬ БЕСПЛАТНУЮ ПРОБНУЮ ПРОБНУЮ ВЕРСИЮ Полная функциональность в течение 14 дней НАЧАТЬ БЕСПЛАТНУЮ ПРОБНУЮ ПРОБНУЮ ВЕРСИЮ Полная функциональность в течение 14 дней
Мы Geekbuilt. ®
Разработанный сетевыми и системными инженерами, которые знают, что нужно для управления современными динамичными ИТ-средами, SolarWinds тесно связан с ИТ-сообществом.
Результат? Эффективные, доступные и простые в использовании продукты для управления ИТ.
Законные документы Конфиденциальность Права на конфиденциальность в Калифорнии Информация о безопасности Документация и информация об удалении Центр доверия Политика раскрытия информации
© 2022 SolarWinds Worldwide, LLC. Все права защищены.
Что такое база данных — javatpoint
следующий → ← предыдущая Что такое данные?Данные — это набор отдельных небольших единиц информации. Его можно использовать в различных формах, таких как текст, числа, мультимедиа, байты и т. д. Его можно хранить на листах бумаги или в электронной памяти и т. д. Слово «данные» произошло от слова «датум», что означает «единая часть информации». В вычислительной технике данные — это информация, которую можно преобразовать в форму для эффективного перемещения и обработки. Данные взаимозаменяемы. Что такое база данных?База данных представляет собой организованный набор данных, так что к ним можно легко получить доступ и управлять ими. Вы можете организовать данные в таблицы, строки, столбцы и проиндексировать их, чтобы упростить поиск нужной информации. Обработчики базы данных создают базу данных таким образом, что только один набор программного обеспечения обеспечивает доступ к данным для всех пользователей. Основной целью базы данных является обработка большого объема информации путем хранения, извлечения и управления данными. В настоящее время во всемирной паутине существует множество динамических веб-сайтов, которые управляются через базы данных. Доступно множество баз данных , таких как MySQL, Sybase, Oracle, MongoDB, Informix, PostgreSQL, SQL Server и т. д. Современные базы данных управляются системой управления базами данных (СУБД). SQL или язык структурированных запросов используется для работы с данными, хранящимися в базе данных. SQL зависит от реляционной алгебры и реляционного исчисления кортежей. Цилиндрическая структура используется для отображения образа базы данных. Эволюция баз данныхБаза данных завершила более чем 50-летний путь эволюции от системы с плоскими файлами к реляционным и объектно-реляционным системам. Он прошел через несколько поколений. ЭволюцияФайловый В 1968 году была введена файловая база данных. В файловых базах данных данные хранились в плоском файле. Одним из основных преимуществ является то, что файловая система имеет различные методы доступа, например, последовательный, индексированный и случайный. Требуется обширное программирование на языке третьего поколения, таком как COBOL, BASIC. Иерархическая модель данных1968-1980 годы были эпохой иерархической базы данных. Выдающаяся иерархическая модель базы данных была первой СУБД IBM. Она называлась IMS (система управления информацией). В этой модели файлы связаны родительским/дочерним образом. На приведенной ниже диаграмме представлена иерархическая модель данных. Маленький круг представляет объекты. Как и файловая система, эта модель также имела некоторые ограничения, такие как сложная реализация, отсутствие структурной независимости, неспособность легко обрабатывать отношения «многие-многие» и т. д. Сетевая модель данных Чарльз Бахман разработал первую СУБД в Honeywell под названием Integrated Data Store (IDS). В этой модели файлы связаны как владельцы и члены, как и в общей сетевой модели. Сетевая модель данных идентифицировала следующие компоненты:
Эта модель также имела некоторые ограничения, такие как сложность системы и сложность проектирования и обслуживания. Реляционная база данных1970 — настоящее время: Это эпоха реляционных баз данных и управления базами данных. В 1970 году реляционная модель была предложена Э. Ф. Коддом. Модель реляционной базы данных имеет два основных термина: экземпляр и схема. Экземпляр представляет собой таблицу со строками или столбцами Схема определяет структуру, такую как имя отношения, тип каждого столбца и имя. В этой модели используются некоторые математические концепции, такие как теория множеств и логика предикатов. Первое приложение для работы с базами данных в Интернете было создано в 1995 году. В эпоху реляционных баз данных было введено гораздо больше моделей, таких как объектно-ориентированная модель, объектно-реляционная модель и т. д. Облачная база данныхОблачная база данныхпозволяет хранить, управлять и извлекать структурированные и неструктурированные данные через облачную платформу. Эти данные доступны через Интернет. Облачные базы данных также называют базой данных как услугой (DBaaS), поскольку они предлагаются как управляемая услуга. Некоторые лучшие облачные варианты:
Преимущества облачной базы данных Снижение затрат Как правило, компании-провайдеру не нужно вкладывать средства в базы данных. Автоматизированный Облачные базы данныхобогащены различными автоматизированными процессами, такими как восстановление, отработка отказа и автоматическое масштабирование. Повышенная доступность Вы можете получить доступ к своей облачной базе данных из любого места и в любое время. Все, что вам нужно, это просто подключение к Интернету. База данных NoSQLБаза данных NoSQL — это подход к разработке таких баз данных, которые могут поддерживать широкий спектр моделей данных. NoSQL означает «не только SQL». Это альтернатива традиционным реляционным базам данных, в которых данные размещаются в таблицах, а схема данных идеально разрабатывается до создания базы данных. Базы данныхNoSQL полезны для большого набора распределенных данных. Некоторые примеры системы баз данных NoSQL с их категорией:
Преимущество NoSQLВысокая масштабируемость Благодаря масштабируемости NoSQL может обрабатывать большие объемы данных. Высокая доступность NoSQL поддерживает автоматическую репликацию. Автоматическая репликация делает его высокодоступным, поскольку в случае любого сбоя данные реплицируются в предыдущее согласованное состояние. Недостаток NoSQLОткрытый код NoSQL — это база данных с открытым исходным кодом, поэтому для NoSQL пока нет надежного стандарта. Проблема управления Управление данными в NoSQL намного сложнее, чем в реляционных базах данных. Это очень сложно установить и еще более беспокойно управлять ежедневно. Графический интерфейс недоступен Инструменты с графическим интерфейсом для базы данных NoSQL не так легко доступны на рынке. Резервное копирование Backup — большое слабое место для баз данных NoSQL. Объектно-ориентированные базы данныхОбъектно-ориентированные базы данных содержат данные в виде объектов и классов. Объекты — это сущности реального мира, а типы — это коллекции объектов. Объектно-ориентированная база данных представляет собой комбинацию функций реляционной модели с объектно-ориентированными принципами. Это альтернативная реализация реляционной модели. Объектно-ориентированные базы данных содержат правила объектно-ориентированного программирования. Объектно-ориентированная система управления базами данных представляет собой гибридное приложение. Объектно-ориентированная модель базы данных содержит следующие свойства. Свойства объектно-ориентированного программирования
Свойства реляционной базы данных
Графические базы данных База данных графа — это база данных NoSQL. Базы данных графов удобны для поиска взаимосвязей между данными, поскольку они подчеркивают взаимосвязь между релевантными данными. Базы данных Graph очень полезны, когда база данных содержит сложные отношения и динамическую схему. Он в основном используется в управлении цепочкой поставок , определяя источник IP-телефонии . СУБД (система управления базами данных)Система управления базой данных — это программное обеспечение, которое используется для хранения и извлечения базы данных. Например, Oracle, MySQL и т. д.; это некоторые популярные инструменты СУБД.
Преимущество СУБДРезервирование управления Он хранит все данные в одном файле базы данных, поэтому он может контролировать избыточность данных. Обмен данными Авторизованный пользователь может обмениваться данными между несколькими пользователями. Резервное копирование Обеспечивает резервное копирование и подсистему восстановления. Эта система восстановления автоматически создает данные после сбоя системы и восстанавливает данные при необходимости. Несколько пользовательских интерфейсов Предоставляет различные типы пользовательских интерфейсов, такие как графический интерфейс, интерфейсы приложений. Недостаток СУБДРазмер Занимает много места на диске и памяти для эффективной работы. Стоимость СУБД требует высокоскоростного процессора данных и большего объема памяти для запуска программного обеспечения СУБД, поэтому она является дорогостоящей. Сложность СУБД создает дополнительные сложности и требования. РСУБД (система управления реляционными базами данных)Слово РСУБД обозначается как «система управления реляционными базами данных». Он представлен в виде таблицы, содержащей строки и столбцы. РСУБД основана на реляционной модели; он был введен Э. Ф. Коддом. Реляционная база данных содержит следующие компоненты:
РСУБД — это табличная СУБД, обеспечивающая безопасность, целостность, точность и непротиворечивость данных. |