
Как использовать WordStat
«Как использовать WordStat»
У каждого сервиса есть свои особенности. На примере ВОРДСТАТ, я поясню это. Но точно такие же особенности есть в любом другом сервисе. Поэтому, когда к вам приходят какие-то данные, всегда анализируйте их: откуда они взялись, насколько эти данные чисты, на какой выборке они собранны, и насколько им можно доверять.
— Это важно, иначе можно куда-то сместиться, и чего-то не того насчитать.
Если вы в Яндекс просто наберёте в Вордстат «детские велосипеды», то Яндекс вам скажет, что такие запросы задают 154 тысячи раз в месяц. Но это на самом деле не совсем так, то есть, смысл этой цифры немножко другой, и это важно понимать. Это значит : 154 тысячи раз какие-то запросы, в которых присутствует словосочетание : «детский» и «велосипед» в любых словоформах с любым порядком слов в любых регионах.
А дальше, если мы начнём использовать специальные операторы — кавычки, это откинуть подзапросы.
Восклицательные знаки позволяют нам исключить слова в иной словоформе. То есть, «детскими велосипедами » сюда уже не попадёт. И регион — Москва и Область. Таким образом, мы из 154 тысяч, через кавычки мы получим 5 тысяч, с восклицательными знаками 2600, с регионов 913. То есть, цифра изменилась примерно в 150 раз при правильном использовании сервиса. Вот эта цифра +- отражает реалии. Поэтому мы понимаем, что при оценке могли ошибиться легко на три порядка.
В 2010-м году выпустил исследование о поиске в Интернете, там очень важные цифры прозвучали, — что основной поток запросов — уникальные. Отсюда вывод — нет смысла упираться в небольшой набор поисковых запросов. — Неважно, чем вы торгуете. Если вы выбрали 40 и менее запросов, — это очень мало. — Это значит вы не проработали тот поисковый спрос, который существует. Поэтому старайтесь собрать наиболее большое количество запросов. Иначе вы просто не попадаете в большую часть аудитории.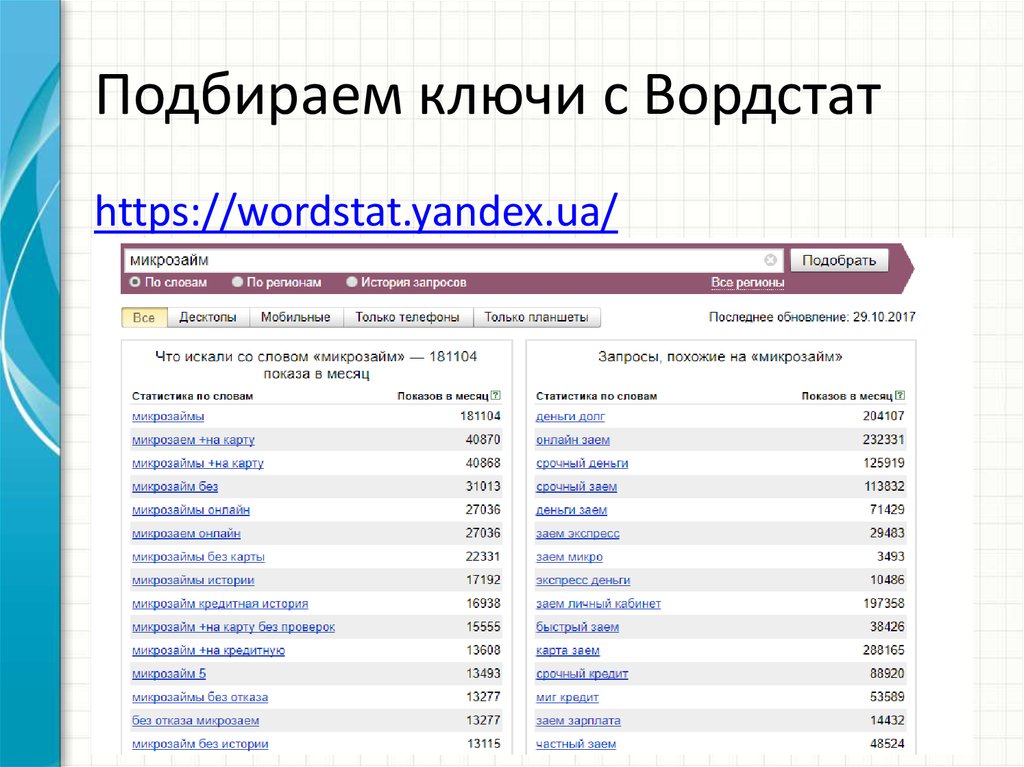
Я сказал, что можно собирать запросы, по которым видны ваши конкуренты. В результате такого сбора может получится вот это. Для этого вы сначала отбираете некоторое количество конкурентов, желательно, чтобы они были нишевыми. Откуда это требование? Ну, допустим, OZON продаёт не только книги, но, и, например, книги. Но, если, например, мы начнём рассматривать его как конкурента и собирать поисковые запросы по нему, то мы, понятное дело, начнём получать выдачу, которая совсем нерелевантно нашему запросу.
Правильнее работать с нишевыми конкурентами, ассортимент которых максимально приближён к нашему. И он может быть уже, но не должен быть шире. Таким образом, лучше два десятка, три десятка мелких нишевых конкурентов, чем гигантов, типа OZON, Юлмарт.
Из полученной сводки нужно будет откинуть некоторые запросы. То есть, запросы, которые проходят только по одному конкуренту, лучше откинуть, потому что эти запросы могут быть витальные.
Часто люди так ищут — «беговая дорожка спортмастер».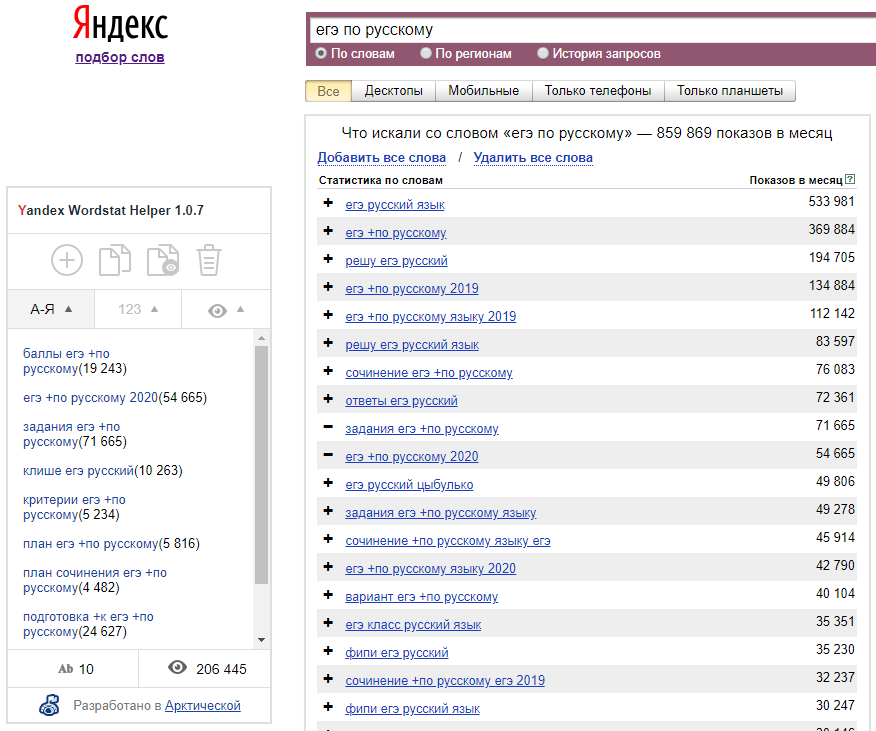 — Это то, что вам нужно, но не совсем, потому что имеется ввиду конкретный магазин. Человек не купит по подобному запросу в другом магазине. Соответственно, откажитесь от этих уникальных запросов, и ваших запросов станет меньше, но они станут более чистыми; и станут релевантны вашей поисковой нише.
— Это то, что вам нужно, но не совсем, потому что имеется ввиду конкретный магазин. Человек не купит по подобному запросу в другом магазине. Соответственно, откажитесь от этих уникальных запросов, и ваших запросов станет меньше, но они станут более чистыми; и станут релевантны вашей поисковой нише.
Есть ещё одна история, которую можно применить. — поискать запросы, в выдаче по которым встретились маркёры.
Сейчас появилось множество сервисов, которые как-то наблюдают за пользователем. Понятно, что это наблюдение не персонифицированное.
Сервисы не пытаются собрать приватную информацию, но поисковые запросы могут собирать. Мы ищем поисковые запросы, в выдаче по которым встретились маркёры, которые считаем ценными.
Ну, например, если это свадебная компания, то ищем «свадьба» или «свадебный». от так будет выглядеть выдача по запросу, а точнее по маркёру ГАЗОНОКОСИЛКИ. — Часть этих запросов понятна, 4-ый, 5-ый пункт. Мы видим тут и явно названия и бренды газонокосилок, а непонятные буквы на английском; — это явно кто-то забыл раскладку переключить.
Цифры вверху — это артикулы. И , как мы видим, они очень разные. Люди могут набирать их по-разному, с пробелами, с дефисами. Мы никогда не угадаем, как они это делают. Делают они это исключительно разными способами.
Я недавно для задач внутри сайтового поиска собирал большие словари по синонимом брендов, и чего я там только не встречается. Даже те бренды, которые на слуху могут гут написать как СУНСУНГИ или что-то ещё. Казалось бы, они очень популярны, на растяжках и в рекламе постоянно, но вот люди умудряются в названиях ошибиться.
Но наша с вами задача как аналитиков — знание это принять и использовать.
Бензокосилки Хузгварна. Вот если бы мы пошли в статистику запросов к поисковым системам, и набрали бы там запрос ГАЗОНОКОСИЛКИ, то мы вот этот запрос не нашли бы, как и, собственно, другие. Бензокосилки — не то же самое, что газонокосилки, значит мы этот запрос пропустили бы. Ну и, смотрите: газоно — пробел— косилки. ТАк тоже можно спросить, почему нет? А также КОСИЛКА ДЛЯ ТРАВЫ РУЧНАЯ БЕНЗИНОВАЯ, МЕХАНИЧЕСКАЯ РУЧНАЯ СЕНОКОСИЛКА и так далее.
Такой способ поможет найти большое количество разных запросов. — Это и есть наша цель — понять, что хотят люди.
Это взято НЕ из статистики сайта, а найдено с помощью специальных сервисов, которые берут информацию из поисковых систем, которым люди задают запросы. И в ответах поисковой машины на эти запросы можно поискать необходимое слово, такое, как ГАЗОНОКОСИЛКИ. И найти запросы, которые привели к такой поисковой выдаче. Я в конце могу назвать какие-то сервисы, если хотите. Они меняются, их много.
Хочу заметить, что пробелы и дефисы — это разные запросы.
Вопрос сейчас прозвучал такой: какая частотность запроса нужна, чтобы мы использовали его? — Мой совет использовать разные запросы и не фокусироваться только на самых частотных. Наоборот, лучше сфокусироваться на менее частотных запросах. Они, на мой взгляд, наиболее досягаемые для вас.
ВОЗМОЖНЫЕ СПОСОБЫ КЛАСТЕРИЗАЦИИ.
Представьте себе, что вы собрали огромное количество запросов; далее их нужно разложить на частотные слова, используя поисковые словари или сходство поисковой выдачи. Смысл этих двух способов прост. Частотные словари — это когда вы из всех запросов выделяете отдельные слова, и смотрите — какие чаще там встретились.
Смысл этих двух способов прост. Частотные словари — это когда вы из всех запросов выделяете отдельные слова, и смотрите — какие чаще там встретились.
Например, если у вас большое количество запросов про газонокосилки, то такими словами будут ГАЗОНОКОСИЛКА, ЭЛЕКТРИЧЕСКАЯ, БЕНЗИНОВАЯ, БОШ, ГАРДЕНА… — Это, по сути, определители кластеров. Ну, вы понимаете, что у нас есть бренды, типы и так далее.
Через сходство в поисковой выдаче — способ немного сложнее, но тоже доступный. — Вы задаёте запрос в поисковую машину, и считаете, что запросы похожи, если выдачи по ним похожи.
Например, если вы вобьёте в поисковик СОТОВЫЙ ТЕЛЕФОН или МОБИЛЬНЫЙ ТЕЛЕФОН, то увидите выдачу примерно одинаковую.— Эти запросы можно считать сходными, хотя формально эти запросы очень разные. Хотя они содержат разные слова, и нет формальных признаков считать их одинаковыми.
Большая история про то, что нужно пользователям. Если мы упираемся в задачи пользователя, то нам нужно уже на сайте его удовлетворить.
— Это совершенно нетривиальная задача. Когда-нибудь я расскажу это в отдельной лекции под названием «Наши ошибки». — Их много. Мы пробовали разные варианты, и очень часто ошибались.
Как вы думаете, человеку, который собирается купить ноутбук, что может быть самым главным в процессе выбора на первом этапе? Если он попал на сайт ноутбуков, на что он в первую очередь обратит внимание? — Да-да-да. — Цены, характеристики, диагональ монитора… — Это всё очень хорошо, и неправильно.
В первую очередь, давайте не будем забывать про то, что то, как он выглядит, играет важную роль. Ведь нынешний покупатель ноутбуков — это не тот покупатель ноутбуков, который был 10-15 лет назад. — Это просто обычный человек, не айтишник, которому ноутбук нужен для работы.
Поэтому нужно, чтобы ноутбук выглядел как-то адекватно его представлениям, а дальше он уже надеется на то, что он найдёт необходимые характеристики, которые плюс-минус все одинаковые, и всё будет нормально работать.
— Вот такая психология современного покупателя.
Мы, конечно, ошибались, когда писали характеристики. Когда мы поменяли выдачу и стали показывать картинки крупно, конверсия заметно выросла.
Людям нравится сначала выбрать красивую картинку, а потом решить, какие характеристики ему понадобятся. — Это всё уже технические детали.
И таких нюансов сотни и тысячи, именно поэтому я вас прошу не доверять мнению экспертов, а просто стараться проверять.
Ну, вот, смотрите, откуда можно взять опыт и восприятие пользователя?
— Можно взять его из устойчивых n-грамм из отзывов.из отзывов.
— Что это такое? — Звучит очень страшно, а по факту очень просто.
— Берём все отзывы, которые пишут люди в категории «холодильники» или пылесосы, делим их на словосочетания, и смотрим — какие словосочетания самые частотные, самые популярные, и делаем выводы о том, что, если люди это обсуждают в отзывах, то, наверное, это важная штука.
И вот, что может получиться:
Допустим, функциональность: регулятор крепости кофе, долго держит заряд, лоток для овощей;
Сочетаемость: есть все разъёмы, со всеми форматами;
Коммуникабельность: инструкция для сборки на русском языке, интуитивно понятный интерфейс;
Условия использования: на мокром льду, за МКАДом, при недостаточном освещении; — Ну это явно про шины!
Опыт использования: лежит в руке, приятный на ощупь, совсем не шумный, крепится к стеклу. — Пользователи со стажем поймут, что это про телефон. А, если посмотреть на это с другой стороны медали…Что вам говорят бренды, которые пытаются продавать телефоны, они говорят про диагональ экрана, мегапиксели. А пользователю вот это нужно.
— Пользователи со стажем поймут, что это про телефон. А, если посмотреть на это с другой стороны медали…Что вам говорят бренды, которые пытаются продавать телефоны, они говорят про диагональ экрана, мегапиксели. А пользователю вот это нужно.
Общее резюме: можно обращать внимание на то, о чём пишут люди, как они обсуждают ту или иную покупку в той или иной категории. Из этого понимать, что какой контент они ожидают увидеть, и какой контент для них полезен.
Есть и очевидные и совершенно не очевидные вещи. Например, в духовом шкафу, людей мало интересует, сколько конфорок, но, при этом, часто задают вопрос про то, какой ящик для хранения кастрюль.
Поэтому предугадать нельзя! — Измеряйте!
Советую подробнее почитать в докладе лингвиста Ирины Борисовой:«Лексическая статистика в оценке качества коммерческих текстов».
Другая очень простая идея : можно измерить востребованность типов контента по популярности соответствующих поисковых запросов.
То есть, за критерий мы можем взять отношение популярности запроса со словом «отзывы», и отнести это к популярности запроса.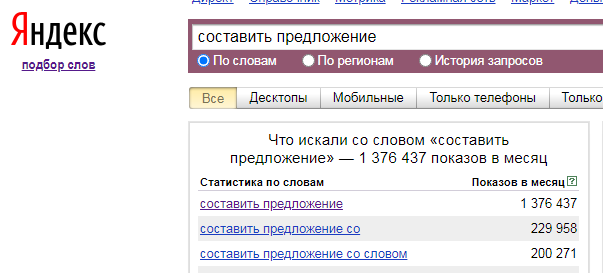
Иными словами, берём популярность РАДИОНЯНИ — ОТЗЫВЫ и делим на популярность РАДИОНЯНИ. Таким образом, мы получаем странную цифру, которая характеризует людей, которых интересуют отзывы при покупке радионяни.
Понятно, что так считать формально не совсем верно, но так считать можно. И таким жен образом вы можете поставить ВИДЕО или ОБЗОР, — любые типы контента, который у вас есть на сайте.
И, если мы упорядочим по убыванию важности, то категориями, которые больше всего нуждаются в отзывах, будут такие как РАДИОНЯНИ, ЭПИЛЯТОРЫ, ДЕТЕКТОРЫ.
Тут всё достаточно логично, — человек смотрит отзывы на такие приборы, которые не сильно сложные, но предугадать заранее, как этот прибор решает его задачи, непросто.
Например, радионяни, — набор приборов, один из которых, стоит в одной комнате, другой стоит у родителей. Непонятно, насколько он чувствительный, на сколько хватает батареек, может ли быть «ложное срабатывание».
С другой стороны, на стремянки и мангалы, отзывы не очень нужны. Тут всё понятно вроде. — Залезай и всё. Что тут непонятного?
Тут всё понятно вроде. — Залезай и всё. Что тут непонятного?
Если мы посмотрим на видео, в топе окажутся — дровокол, интерактивные животные и йо-йо. Я чувствую, что я посеял вопрос, и сегодня можно ожидать пик этих запросов из нашей аудитории.
Но тут всё понятно, — эти виды товаров очень непросто приобрести и выбрать просто по текстовому описанию, необходимо самому посмотреть, что это такое, и как работает.
Ну а какие-то другие виды и категории товаров могут не требовать видео вообще. Поэтому, вот такой простой и очень доступный способ.
Обратите внимание, что всё, что я говорю сейчас в целом подъёмно. Ни в какой из этих задач не требуется НИИ, чтобы всё это реализовать.
WordStat Цены, обзоры и характеристики
15 лет помогаем канадским предприятиям
выбирать лучшее программное обеспечение
Местный продукт
Что такое WordStat?
Кто использует WordStat?
Предназначен для академических учреждений, государственных предприятий, НПО и исследователей, использующих интеллектуальный анализ текста и качественный анализ данных для поиска тем, тенденций и тем в неструктурированных текстовых данных.
Предыдущий
Следующий
Просмотр изображений и видео Показать меньше
Не уверены в WordStat? Сравните с популярной альтернативой
WordStat
5,0 (3)
Местный продукт
400 долларов США
год
Бесплатная версия
Бесплатная пробная версия
9
Интеграции не обнаружено
3,7
(3)
5,0
(3)
5,0
(3)
Начальная цена
Варианты ценообразования
Особенности
.0004
Простота использования
Соотношение цены и качества
Служба поддержки клиентов
Самые просматриваемые
Чаттермилл
4,5 (23)
Посетите веб-сайт
Цены не найдены
Бесплатная версия
Бесплатная пробная версия
70
29
4,3
(23)
4,1
(23)
4,5
(23)
Другие отличные альтернативы WordStat
Посмотреть больше альтернатив
Обзоры ВордСтат
Средний балл
Всего
5. 0
0
Простота использования
3.7
Служба поддержки клиентов
5.0
Характеристики
5.0
Соотношение цены и качества
5.0
Отзывы по размеру компании (сотрудники)
- <50
- 51-200
- 201-1000
- >1001
Поиск отзывов по баллам
Напишите отзыв! Прочитать все 3 отзыва
Фэй
Консультант по международным маркетинговым исследованиям в Канаде
Программное обеспечение для маркетинговых исследований, 2–10 сотрудников
Использовали программное обеспечение в течение: 2+ лет
Источник рецензента
Самая эффективная и удобная программа для анализа текстов из когда-либо использовавшихся
5,0 6 лет назад
Комментарии:
Благодаря быстрому выявлению тем и созданию аналитических результатов на тысячах открытых ответов на опросы, а также анализу политик и расшифровок фокус-групп, WordStat сэкономил мне много часов и позволил мне повысить уровень понимания, который я могу предоставить. моим клиентам. Первый клиент, с которым мы использовали его, мировой лидер в сфере розничной торговли, был поражен, они никогда не видели компьютерного качественного анализа такого рода (и мы тоже) — благодаря этому мы сразу выиграли контракт на 2 года. программное обеспечение. Настоятельно рекомендуется.
моим клиентам. Первый клиент, с которым мы использовали его, мировой лидер в сфере розничной торговли, был поражен, они никогда не видели компьютерного качественного анализа такого рода (и мы тоже) — благодаря этому мы сразу выиграли контракт на 2 года. программное обеспечение. Настоятельно рекомендуется.
Плюсы:
Полезные аналитические результаты, легко интерпретируемые конечным пользователем. Легко создать и применить словарь для пользовательского анализа, используя те же аналитические инструменты. Легко оценить гипотезы о том, как тема трактуется в многочисленных свободных текстах, документах, статьях, расшифровках и т. д. Удобный и простой в освоении. Также доступна сегментация для удобства сравнения и дальнейшего понимания. Легкое извлечение релевантных дословных выражений или цитат благодаря отображению ключевых слов в контексте.
Минусы:
У меня не было проблем.
Эрин
США
Программное обеспечение использовалось для: Не предусмотрено
Источник рецензента
Мощный полнофункциональный анализатор свободного текста
5,0 6 лет назад
Комментарии:
WordStat функционирует как дополнение к другому программному обеспечению данных Provalis, Simstat и QDA Miner. Я использовал его только в сочетании с QDA Miner, так как мы имеем дело в основном с количественными данными. Мы обнаружили, что процесс первоначальной настройки довольно трудоемкий и интерактивный — при настройке словарей, классификаторов и исключений. Без этого шага программное обеспечение действительно ограничено простым анализом текста. Однако, когда они заполнены и уточнены, WordStat действительно делает некоторые удивительные отчеты — лучшие, которые я видел для анализа произвольного текста. У нас довольно узкий набор потребностей, и поэтому мы не использовали все его возможности, но способность выполнять частотный анализ тысяч документов и связывать произвольный текст с конкретными временными данными была действительно потрясающей! Это очень мощное программное обеспечение и, как таковое, требует значительного обучения. Он обрабатывается очень быстро, и легко импортировать текст из нескольких источников. Рекомендуется, но будьте готовы потратить время на настройку, контроль качества и ручную корректировку выходных данных.
Я использовал его только в сочетании с QDA Miner, так как мы имеем дело в основном с количественными данными. Мы обнаружили, что процесс первоначальной настройки довольно трудоемкий и интерактивный — при настройке словарей, классификаторов и исключений. Без этого шага программное обеспечение действительно ограничено простым анализом текста. Однако, когда они заполнены и уточнены, WordStat действительно делает некоторые удивительные отчеты — лучшие, которые я видел для анализа произвольного текста. У нас довольно узкий набор потребностей, и поэтому мы не использовали все его возможности, но способность выполнять частотный анализ тысяч документов и связывать произвольный текст с конкретными временными данными была действительно потрясающей! Это очень мощное программное обеспечение и, как таковое, требует значительного обучения. Он обрабатывается очень быстро, и легко импортировать текст из нескольких источников. Рекомендуется, но будьте готовы потратить время на настройку, контроль качества и ручную корректировку выходных данных.
Джейсон
Канада
Программное обеспечение использовалось для: Не указано
Источник рецензента
Решение для текстовой аналитики по конкурентоспособной цене
5,0 6 лет назад
Комментарии: WordStat и QDA Miner очень хороши для проектов с большим количеством документов. Я получил программное обеспечение за долю стоимости других продуктов, и оно не уступает по возможностям, если не лучше. Он отлично справляется с работой по сравнению с высококлассными инструментами, но по цене, которую наш университет может себе позволить.
Плюсы:
Вы можете контролировать анализ. Вы знаете, как делается анализ. Это не черный ящик. Расширенная компьютерная помощь для ускорения процесса анализа.
Минусы:
Кривая обучения
Прочитать все 3 отзыва
Программное обеспечение, найденное в
WordStat для Stata
ИНСТРУМЕНТ АНАЛИЗА СОДЕРЖИМОГО И ТЕКСТА ДЛЯ STATA
Stata — это полный интегрированный статистический пакет программного обеспечения, созданный StataCorp LP.
Он обеспечивает широкий спектр статистического анализа, управления данными и графики. В последних версиях Stata добавлено много новых функций, в том числе тип данных «длинная строка», позволяющий хранить наряду с числовыми и категориальными данными документы длиной до 2 миллиардов символов. Таким образом, можно создать статистическую базу данных с выдержками из журналов, расшифровками новостей, патентами, отчетами об инцидентах, отзывами клиентов, интервью и т. д.
WordStat для Stata был создан, чтобы позволить пользователям Stata 13 до Stata 16, работающим под Windows, применять методы анализа текста к любым строковым переменным, хранящимся в файле данных Stata. WordStat сочетает в себе обработку естественного языка, анализ контента и статистические методы для быстрого извлечения тем, шаблонов и отношений в больших объемах текста. Он может обрабатывать миллионы слов за секунды и сравнивать извлеченные темы с любыми другими числовыми, категориальными или датированными переменными в файле Stata.
Для чего он используется?
WordStat может использоваться всеми, кому необходимо быстро извлечь и проанализировать информацию, хранящуюся в текстовых переменных Stata. Его можно использовать для:
• Прямого импорта текстовых и количественных данных из социальных сетей, платформ онлайн-опросов, инструментов управления ссылками
• Контент-анализа открытых ответов, стенограмм интервью или фокус-групп
• Бизнес-аналитики и анализа конкурентных веб-сайтов
• Извлечение информации и обнаружение знаний из отчетов об инцидентах, жалоб клиентов
• Контент-анализ новостей или научной литературы (наукометрические или библиометрические исследования)
• Автоматическая маркировка и классификация документов
• Выявление мошенничества, установление авторства, патентный анализ
• Разработка и проверка таксономии
WORDSTAT FOR STATA ОСНОВНЫЕ ФУНКЦИИ:
ИССЛЕДОВАТЕЛЬСКИЙ ИССЛЕДОВАНИЕ ТЕКСТА
Интегрированные инструменты исследовательского извлечения текста и визуализации, такие как кластеризация, многомерное масштабирование, диаграммы близости и другие, для быстрого извлечения тем и автоматического определения закономерностей.
МОДЕЛИРОВАНИЕ ТЕМ
Получите краткий обзор наиболее важных тем из больших коллекций текстов. Боковая панель позволяет сравнивать частоту определенных тем с другими переменными, используя гистограммы или линейные диаграммы.
СЛОВАРИ КАТЕГОРИИ
Используйте существующие или создавайте собственные словари, состоящие из слов, шаблонов слов, фраз и правил близости. Получите компьютерную помощь для создания таксономий с извлечением фраз и именованных объектов, заменой опечаток, интегрированным тезаурусом и т. д.
СРАВНИТЕЛЬНЫЙ АНАЛИЗ
Изучите отношения между неструктурированным текстом и структурированными данными с помощью статистических и графических инструментов (анализ соответствия, тепловые карты, пузырьковые диаграммы и т. д.).
АНАЛИЗ ССЫЛОК
Исследуйте отношения между словами или извлеченными понятиями, используя графы на основе силы, многомерное масштабирование или круговые графы.