Rel Canonical или Noindex? Что лучше использовать для закрытия дублирующих страниц?
Опубликовано seonomad — 18, Jun 2019
Чтобы избежать дублирования контента и некачественных страниц при индексации, веб-мастера обычно предпочитают устанавливать теги noindex, nofollow, иногда rel = canonical, а иногда и все вместе. Так как же все таки правильней ?
Теги canonical и noindex в Google
Джон Мюллер (John Mueller) на одной из встреч в Google Webmaster Central рассказал, что поисковик Google при определении качества сайта использует только те страницы, которые разрешены для индексации. То есть, страницы закрыты через теги noindex учитываться не будут, именно поэтому Джон рекомендовал веб-мастерам вместо тега «noindex» использовать rel = canonical для страниц с дублирующим контентом.
При использовании тега noindex все сигналы, связанные с дублирующейся страницей, теряются и не передаются при учете качества сайта в целом. Канонический тег позволяет передать все сигналы с дублирующей страницы, на каноническую.
Канонический тег позволяет передать все сигналы с дублирующей страницы, на каноническую.
В случае если Вы будете использовать оба тега одновременно (noindex, nofollow, и rel = canonical), это может привести к непредсказуемым последствиям, так как они совершенно противоречат друг-другу и не могут использоваться вместе. По этому вопросу Джон Мюллер ответил:
Общее правило заключается в том, что сигналы передаются и объединены с канонизацией. Когда Google видит два похожих URL адреса с вашего сайта и вы чётко нам указываете на то, какой из них вы предпочитаете, мы попытаемся их объединить и будем учитывать только один (обычно более весомый) URL. Редиректы, rel=canonical, внутренние и внешние ссылки, sitemaps, hrflang и так далее — всё это говорит нам о ваших предпочтениях и чем больше вы их настроите, тем больше мы будем следовать им и использовать их для выбора канонического адреса (пересылая при этом все сигналы на выбранную страницу).
С другой стороны, noindex и disallow в robots.
txt не являются признаками канонизации. Т.е. их наличие на странице не говорит нам, что вы хотите чтобы она сочеталась с какой-либо другой и что её сигналы нужно перенаправить. Disallow в robots.txt нам труднее понять, потому что мы даже не знаем соответствует ли указанная в нём страница чему-либо ещё на вашем сайте, есть ли похожие страницы, поэтому мы не можем использовать данный файл для канонизации, если бы захотели.Отсюда следует: вы не должны смешивать noindex и rel=canonical так как для нас это очень противоречивая информация. Обычно мы выбираем rel=canonical и используем его поверх noindex, поэтому в любое время, когда вы полагаетесь на интерпретацию компьютерным скриптом (ботом), вы уменьшаете вес вашего входа (а SEO — во многом сводится на тем, чтобы указать боту ваши предпочтения).

Яндекс
Поисковая система Яндекс также распознает и учитывает оба тега, но комментариев от представителей Яндекса по вопросу можно ли использовать оба тега одновременно я не нашел.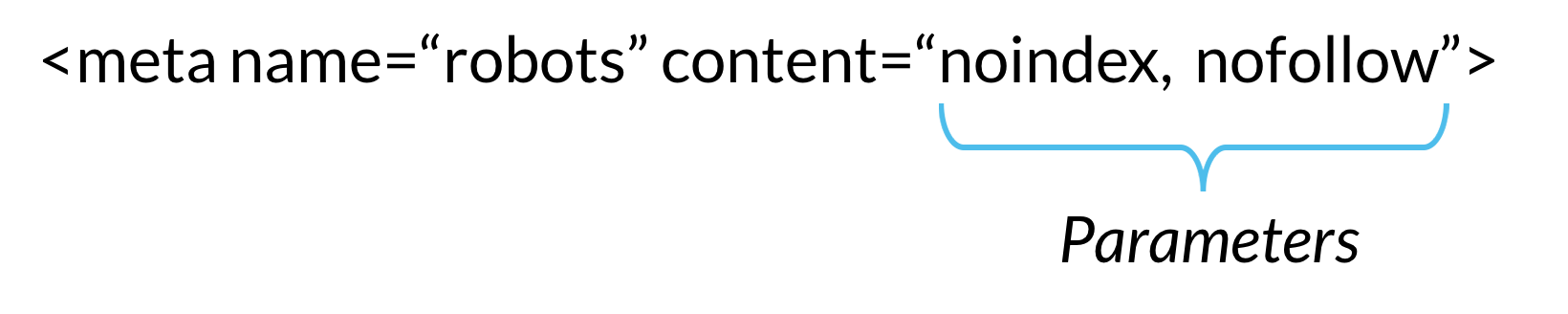 Но логически понятно, если теги распознаются также как и в Google, правила их использования должны быть теже.
Но логически понятно, если теги распознаются также как и в Google, правила их использования должны быть теже.
Бороться с дублированием контента на сайте Яндекс также рекомендует в большей с помощью тега rel=cannonical, о чем есть небольшая заметка с примерами в блоге Платона Щукина https://yandex.ru/blog/platon/2878
SEO в примерах
SEO для чайников
Внешняя оптимизация
Золотые правила удаления дубликатов страниц с помощью NoIndex или Canonical
Обеспечьте редирект 301
Ненужный индексный тег
Без индекса, но следуйте
Канонический
Дублирование страниц плохо влияет на SEO (поисковая оптимизация). Они снижают рейтинг вашей страницы. Дубликаты страниц имеют похожее или даже идентичное содержимое. Например, разные стили, HTTP или HTTPS, www или без www и т. д. Эти страницы обычно содержат один и тот же контент, и вы должны убедиться, что поисковые системы индексируют только 1 копию для всех похожих страниц.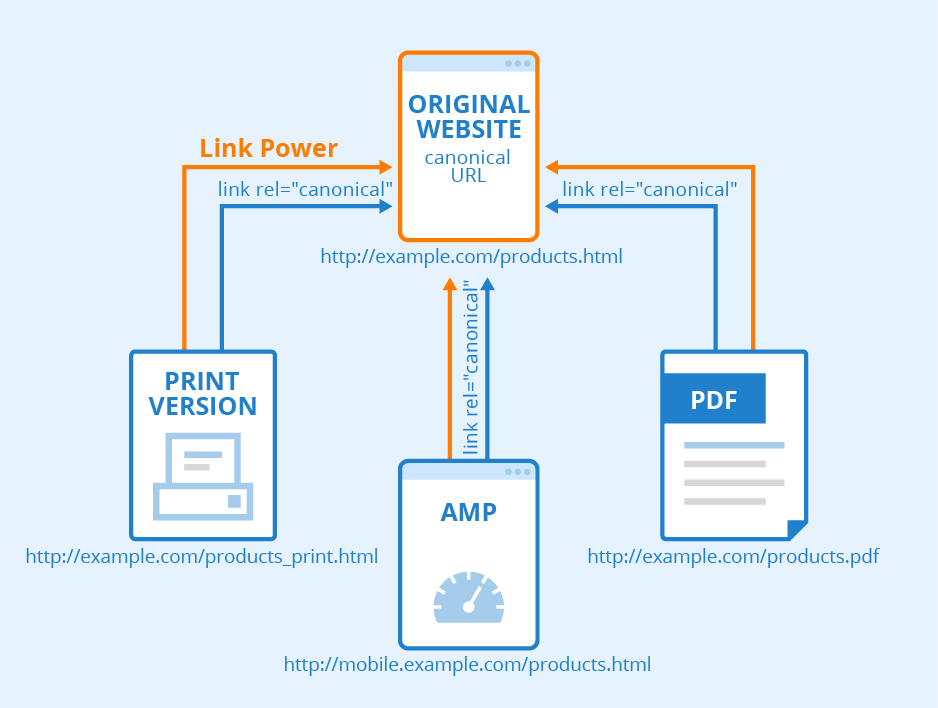
Обеспечьте редирект 301
Перенаправление 301 сообщает поисковым системам, что эта страница постоянно перенаправляется на новую страницу, и оценка страницы также должна быть перенесена на нее. Это полезно, когда вы переходите на новый домен, начинаете использовать версию HTTPS или решаете использовать URL-адреса с www или без www. Помните, что поисковые системы рассматривают HTTP и HTTPS как две разные копии, если вы не запретите им этого делать. Поисковые системы, хранящие повторяющееся содержимое, плохи, потому что оценки также будут разделены между этими страницами. Для перенаправления 301 целевой URL-адрес будет отображаться в браузере, поэтому вам просто нужно сохранить копию версии. Следовательно, это не подходит, если вы хотите иметь несколько версий, доступных, например, www и корневые домены, версии HTTP или HTTPS.
Ненужный индексный тег
По умолчанию боты поисковых систем работают по принципу:
<meta name=robots content="index,follow"/>
Это означает, что боты будут индексировать страницу и переходить по всем найденным на ней ссылкам. Если вы не меняете поведение по умолчанию, не нужно помещать это правило в тег head.
Если вы не меняете поведение по умолчанию, не нужно помещать это правило в тег head.
Без индекса, но следуйте
Это почти правда, что вы должны сделать noindex, но следовать, если вы не хотите, чтобы подобная страница была проиндексирована. Когда страница удаляется из индексов поисковых систем, другие метаданные могут быть проигнорированы/исключены, например, тег: ключевое слово и описание.
SEO-улучшения
Метатег NoIndex поддерживается большинством поисковых роботов, например GoogleBot, Yahoo Bot. Это хорошее место для использования NoIndex на дублирующихся страницах, которые отличаются только стилями (например, версия для мобильных устройств или версия для ПК). Вы также можете использовать их на страницах с низкой ценностью, таких как индексные страницы форума.
Канонический
Вы можете указать следующий синтаксис, чтобы указать поисковым системам исходный/подлинный URL:
<link rel=canonical href="
Помните, что это только подсказка, и поисковая система все еще может проиндексировать страницу. Тег Canonical может поддерживаться не всеми поисковыми ботами, поэтому не полагайтесь на них. Таким образом, использование Canonical и NoIndex служит противоположной цели. Канонический намекает, что эта страница не должна быть проиндексирована, если целевой URL не является самим собой (самоканоническим). NoIndex явно указывает не индексировать текущую страницу. Поэтому вам просто нужно выбрать один и не отправлять смешанный сигнал, который может вызвать проблемы, если целевой канонический URL-адрес имеет значение NoIndex.
Тег Canonical может поддерживаться не всеми поисковыми ботами, поэтому не полагайтесь на них. Таким образом, использование Canonical и NoIndex служит противоположной цели. Канонический намекает, что эта страница не должна быть проиндексирована, если целевой URL не является самим собой (самоканоническим). NoIndex явно указывает не индексировать текущую страницу. Поэтому вам просто нужно выбрать один и не отправлять смешанный сигнал, который может вызвать проблемы, если целевой канонический URL-адрес имеет значение NoIndex.
Если страница имеет Canonical и NoIndex, некоторые поисковые системы могут не индексировать целевой Canonical URL, даже если он должен быть проиндексирован, потому что поисковые системы могут подумать, что две страницы должны быть эквивалентны. Это зависит от того, как поисковые системы интерпретируют ключевое слово Canonical.
Итак, вот правило:
На проиндексированных страницах используйте ключевое слово Canonical. На неиндексированных страницах используйте NoIndex. Нажмите, чтобы твитнуть
Нажмите, чтобы твитнуть
Источник записи: helloacm.com
Когда использовать Rel Canonical или Noindex …или и то, и другое
Во время встречи в рабочее время Google SEO Джона Мюллера из Google спросили, какой тег rel canonical или noindex является лучшим подходом для работы с дублирующимся и неполноценным контентом на сайте электронной коммерции. . Джон Мюллер обсудил оба варианта, а затем предложил третий способ решения этой проблемы.
Директива Noindex
Метатег noindex является директивой, которая означает, что Google должен подчиняться метатегу и исключать веб-страницу из результатов поиска.
Все, что делает тег noindex, — это удаляет эту страницу из результатов поиска Google.
В официальной документации Google указано:
«Вы можете предотвратить появление страницы или другого ресурса в поиске Google, включив метатег noindex или заголовок в ответ HTTP. Когда робот Googlebot в следующий раз просканирует эту страницу и увидит тег или заголовок, робот Googlebot полностью исключит эту страницу из результатов поиска Google, независимо от того, ссылаются ли на нее другие сайты».

Rel Canonical
Тег rel=canonical является подсказкой, а не директивой. Это дает Google предложение, для которого URL вы хотите показать в результатах поиска.
Это полезно, когда есть несколько похожих страниц, особенно когда CMS для покупок создает несколько страниц для одного и того же продукта, и обычно единственное различие заключается в чем-то тривиальном, например, в цвете товара.
Официальная каноническая документация Google объясняет проблему следующим образом:
«Канонический URL-адрес — это URL-адрес страницы, которая, по мнению Google, является наиболее репрезентативной из набора повторяющихся страниц на вашем сайте. Например, если у вас есть URL-адреса одной и той же страницы (example.com?dress=1234 и example.com/dresses/1234), Google выбирает один из них как канонический».
rel canonical — полезное решение, потому что оно может объединить все сигналы ссылок и релевантности на главную страницу, которые издатель хочет видеть в результатах поиска.
Но поскольку Google воспринимает тег rel canonical как подсказку, нет никакой гарантии, что Google будет ему подчиняться, и алгоритм Google может решить показать какую-то другую страницу в результатах поиска.
Rel Canonical Versus Noindex
Человек, задавший вопрос, хотел уточнить, лучше ли использовать noindex или канонизацию.
Путаница не является неразумной, потому что дело может быть возбуждено с использованием любого решения.
Вот вопрос:
«У нас есть веб-сайт… интернет-магазин с большим количеством вариантов продуктов, которые иногда имеют неполный контент или дублируют контент.
Итак… я составил список всех URL-адресов, которые мы хотим сохранить или которые мы хотим проиндексировать… а затем я составил список всех URL-адресов, которые мы не хотим индексировать.
Чем больше я над этим работал, тем больше задавал себе этот вопрос, канонизация или неиндексация?
Я не знаю, что из этого лучше.
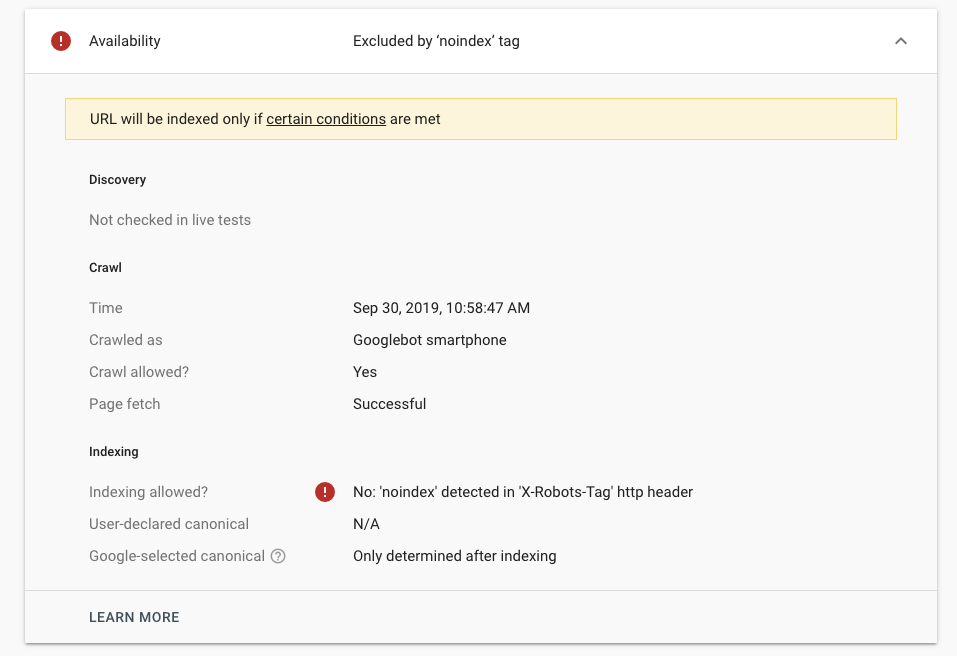
Мюллер ответил:
«… Я думаю, что общий вопрос о том, следует ли мне использовать noindex или rel canonical для другой страницы, — это то, на что, вероятно, нет абсолютного ответа.
Так что это как-то навскидку. Это похоже на то, что если вы боретесь с этим, вы не единственный человек, который такой, о, какой из них я должен использовать?
Обычно это также означает, что обе эти опции могут быть приемлемыми.
Так что обычно я обращаю внимание на ваши предпочтения.
И если вы действительно не хотите, чтобы этот контент вообще отображался в поиске, я бы использовал noindex.
Если вы предпочитаете, я действительно хочу, чтобы все было объединено на одной странице, и если будут отображаться отдельные, например, что угодно, но большинство из них должны быть объединены, тогда я бы использовал rel canonical.
И, в конечном счете, эффект аналогичен тому, что страница, которую вы просматриваете, скорее всего, не будет отображаться в поиске.
А вот с noindex точно не показывается.
А с рел каноническим скорее не показывается.

Третий способ борьбы с повторяющимися и тонкими страницами
Затем Мюллер предложил издателю использовать как noindex, так и rel canonical, чтобы извлечь выгоду из обоих.
Мюллер сказал:
«…можно и то, и другое.
И еще кое-что… если внешние ссылки, например, ведут на эту страницу, то наличие их обеих помогает нам хорошо понять, вы не хотите, чтобы эта страница индексировалась, но вы также указали другую.
Так что, возможно, мы можем просто передать некоторые сигналы.
Объединение Rel Canonical и Noindex не является часто обсуждаемым решением. Но, по словам Джона Мюллера, это действенный способ борьбы с дублирующимся и неполноценным контентом.
Но, в конечном счете, именно издатель должен решить, основываясь на желаемом результате, важно ли объединение ссылок и сигналов релевантности и является ли первостепенным обеспечение того, чтобы страница не отображалась в поиске.
Цитаты
Официальная документация Google по Noindex
Блокирование поискового индексирования с помощью noindex
Официальная документация Google по Rel Canonical
Объединение повторяющихся URL-адресов
Что лучше: NoIndex или Rel Canonical?
Смотреть в 16:49 минутную отметку
Категория Новости SEO
Канонический и без индекса? Используйте вместе | SEO Форум
Ваш браузер не поддерживает JavaScript. В результате ваши впечатления от просмотра будут уменьшены, и вы будете переведены в режим только для чтения .
Загрузите браузер, поддерживающий JavaScript, или включите его, если он отключен (например, NoScript).
- SEO-тактика
- Средний и продвинутый SEO
- Канонический и безиндексный? Использовать вместе
 org/ListItem»> Дом
org/ListItem»> ДомЭта тема была удалена. Его могут видеть только пользователи с правами управления вопросами.
-
Для дубликатов страниц, созданных функцией «печать»,
semoz говорит, что лучше использовать noindex (http://www.semoz.
 org/blog/complete-guide-to-rel-canonical-how-to-and-why-not)
org/blog/complete-guide-to-rel-canonical-how-to-and-why-not), а JohnMu говорит, что лучше использовать канонический http://www.google.com/support/forum/p/Webmasters/thread?tid=6c18b666a552585d&hl=en
Что вы думаете?
-
Я работаю над удалением низкокачественных страниц из каталога, в то же время позволяя просканировать и проиндексировать несколько высококачественных страниц в том же каталоге. Для этого я поместил тег robots noindex на страницы низкого качества, которые мы не хотим индексировать.
Теги noindex были добавлены вчера, но страницы низкого качества никуда не делись. Я даже использовал «Просмотреть как Googlebot», чтобы принудительно просканировать несколько страниц низкого качества. Может быть, мне нужно дать им несколько дней, чтобы они исчезли, но это заставило меня задуматься: «Почему Google игнорирует тег robots noindex?» Потом я придумал теорию.
Я заметил, что мы включаем канонический тег по умолчанию на каждую страницу нашего сайта, включая те, которые я хочу запретить индексировать. Я никогда не использовал тег noindex в сочетании с каноническим тегом, поэтому, возможно, канонический тег сбивает с толку поисковых роботов SE.Я провел небольшое исследование и нашел цитату сотрудника Google JohnMu в следующей статье: http://www.seroundtable.com/archives/020151.html Это не точное совпадение с моей ситуацией, потому что наш канонический тег указывает сам на себя, а не чем другой URL. Но похоже, что использовать их вместе — плохая идея.
Кто-нибудь использовал или видел теги canonical и noindex вместе в дикой природе? Может ли кто-нибудь подтвердить или опровергнуть эту теорию о том, что канонический код снижает эффективность мета-тега robots?
 org/blog/complete-guide-to-rel-canonical-how-to-and-why-not)
org/blog/complete-guide-to-rel-canonical-how-to-and-why-not)
 org/Comment»>
org/Comment»> Я согласен с рассуждениями Линдси, но мне не совсем ясно ее заявление по этому поводу: «Если печатные страницы вашего веб-сайта содержат ссылку на исходную страницу, вы также можете использовать метатег robots ‘noindex’. индекса, и любое значение ссылки будет передано обратно в исходную каноническую веб-версию страницы».
Если вы добавите тег «noindex» на страницу печати, поисковые системы будут игнорировать страницу, которая ДОЛЖНА оставить им только каноническую версию страницы. Вы требуете, чтобы поисковая система сделала некоторые предположения, чего мы хотим избежать. Используя тег canonical, мы явно сообщаем поисковой системе правильную версию страницы для индексации.
Судя по приведенной выше цитате, Линдсей предлагает использовать тег «noindex» и «канонический». Основное внимание в ее статье уделяется тому, что существуют превосходные методы канонизации веб-страниц без использования канонического тега, поэтому мне непонятна логика.
В настоящее время я использую тег canonical в таких ситуациях. Я хотел бы попросить Линдси дать дополнительные разъяснения по поводу использования тега «noindex» в этом случае. Последний комментарий в блоге был вопросом, заданным в мае, на который так и не ответили, поэтому похоже, что она не слишком часто посещает сайт.
У вас есть животрепещущий вопрос по SEO?
Подпишитесь на Moz Pro, чтобы получить полный доступ к вопросам и ответам, отвечать на вопросы и задавать свои.
Начать бесплатную пробную версию
Есть вопрос?
Просмотр вопросов
Посмотреть Все вопросыНовые (нет ответов)ОбсуждениеОтветыПоддержка продуктаБез ответа
От Все времяПоследние 30 днейПоследние 7 днейПоследние 24 часа
Сортировка по Последние вопросыНедавняя активностьБольше всего лайковБольшинство ответовМеньше всего ответовСамые старые вопросы
С категорией Все категорииПартнерский маркетингОбновления алгоритмовAPIBandingСообществоКонкурентные исследованияРазработка контентаОптимизация коэффициента конверсииЦифровой маркетингЗапросы функцийНачало работыОптимизация изображений и видеоОтраслевые событияНовости отраслиПромежуточное и продвинутое SEOМеждународное SEOВакансии и возможностиИсследование ключевых словИсследование ключевых словСоздание ссылокЛокальные спискиЛокальное SEOЛокальная оптимизация веб-сайтаMoz BarMoz LocalMoz NewsReport Marketing Analytics & Product Analytics ToolsOn-Page Analytics Search поиск и тенденцииОтзывы и рейтингиПоисковое поведениеSEO ТактикаТренды поисковой выдачиСоциальные сетиТехническое SEOВеб-дизайнБелое/черное SEO
Связанные вопросы
 schema.org/ItemList» data-nextstart=»» data-set=»»>
schema.org/ItemList» data-nextstart=»» data-set=»»>Привет! В последнее время я много слышал о Rich Snippets, но я действительно не знаю, как они работают. Являются ли они очень важным фактором для SEO? Я хотел бы знать ваши мысли по этому поводу. Спасибо!
Средний и продвинутый SEO | | люсирайтс
0
Привет всем!
На моем веб-сайте я хотел бы использовать CSS, чтобы установить якорный текст на «услуги веб-дизайна» (моя компания предоставляет услуги веб-дизайна), но отображать текст кнопки как «веб-сайт» из-за некоторых художественных соображений. Таким образом, якорный текст для ссылки — «услуга по разработке веб-сайтов», но то, что видят пользователи, — это «веб-сайты». Это звучит как спам для Google? Это рискованный шаг, который может повредить моему SEO?
Ищу несколько советов здесь. Большое спасибо.
Лучший,
Таким образом, якорный текст для ссылки — «услуга по разработке веб-сайтов», но то, что видят пользователи, — это «веб-сайты». Это звучит как спам для Google? Это рискованный шаг, который может повредить моему SEO?
Ищу несколько советов здесь. Большое спасибо.
Лучший,
Средний и продвинутый SEO | | Раймондли
0
Мы должны значительно сократить одну из наших услуг и сосредоточиться на других, более успешных. Мне нужно выяснить, что делать со всеми страницами, относящимися к службе, которую мы сокращаем. Просто чтобы было ясно, мы не избавимся от сервиса. Таким образом, им по-прежнему нужны страницы на веб-сайте, но для нас лучше иметь больше ссылок, идущих на другие страницы услуг, больше нашего соотношения контента, чтобы быть вокруг более прибыльных услуг и т. д.
Итак, должен ли я не индексировать/не отслеживать все страницы, относящиеся к услуге, которую мы сокращаем? Или я должен не индексировать/следить за всеми страницами, относящимися к услуге, которую мы сокращаем?
Спасибо,
Рубен
Просто чтобы было ясно, мы не избавимся от сервиса. Таким образом, им по-прежнему нужны страницы на веб-сайте, но для нас лучше иметь больше ссылок, идущих на другие страницы услуг, больше нашего соотношения контента, чтобы быть вокруг более прибыльных услуг и т. д.
Итак, должен ли я не индексировать/не отслеживать все страницы, относящиеся к услуге, которую мы сокращаем? Или я должен не индексировать/следить за всеми страницами, относящимися к услуге, которую мы сокращаем?
Спасибо,
Рубен
Средний и продвинутый SEO | | КемпRugeLawGroup
0
Привет
Я пытаюсь потренироваться, если что-то не так с нашей нумерацией страниц. Мы включаем rel=»next» и «prev» на наши страницы.
При нажатии на страницу 2 на странице продукта URL-адрес будет выглядеть примерно так:
/lockers#productBeginIndex:30&orderBy:5&pageView:list&
Однако, если я ищу сайт: http://www.key.co.uk/en/key/lockers в Google, он, похоже, находит страницы с разбивкой на страницы:
http://www.key.co.uk/en/key/lockers?page=2
У меня есть ощущение, что здесь что-то идет не так, но раньше я не работал в массовом порядке над разбивкой на страницы. Кто-нибудь может помочь?
Мы включаем rel=»next» и «prev» на наши страницы.
При нажатии на страницу 2 на странице продукта URL-адрес будет выглядеть примерно так:
/lockers#productBeginIndex:30&orderBy:5&pageView:list&
Однако, если я ищу сайт: http://www.key.co.uk/en/key/lockers в Google, он, похоже, находит страницы с разбивкой на страницы:
http://www.key.co.uk/en/key/lockers?page=2
У меня есть ощущение, что здесь что-то идет не так, но раньше я не работал в массовом порядке над разбивкой на страницы. Кто-нибудь может помочь?
Средний и продвинутый SEO | | БеккиКи
0
 Должен ли я использовать CDN в Великобритании, поскольку он говорит, что мой сервер находится в США
Должен ли я использовать CDN в Великобритании, поскольку он говорит, что мой сервер находится в США Привет всем,
Мы британская компания с клиентами только из Великобритании и используем CloudFlare CND. Наш сайт размещен британской компанией с серверами здесь, но при поиске в Интернете и проверке того, где размещен мой сайт и т. д., некоторые сайты сообщают мне название нашей компании, размещенной в Великобритании, а другие сайты сообщают мне, что мой сайт размещен в Сан-Франциско. (США), где, как я полагаю, базируется Cloudflare.
Я знаю, что у Cloudflare есть несколько серверов в Великобритании, которые он использует, но, учитывая, что все мои клиенты находятся в Великобритании, я не хочу, чтобы это влияло на рейтинг и т. Д., Так как я думал, что размещение в стране, в которой вы находитесь, было бы преимуществом в рейтинге. .
Есть ли какие-либо проблемы с этим, и я должен измениться, или Google достаточно умен, чтобы знать, поэтому мне не о чем беспокоиться. Спасибо
Домашний питомец
Спасибо
Домашний питомец
Средний и продвинутый SEO | | ПитС12
0
Допустим, у нас есть белый виджет, который находится в нашей коллекции белых виджетов, а также в нашей коллекции свадебных виджетов. В настоящее время у нас есть 3 разных URL-адреса для этого продукта (white-widgets/white-widget и wedding-widgets/white-widget и all-widgets/white-widget). Мы автоматически генерируем тег rel=canonical для этих отдельных продуктов коллекции. страницы, которые каноничны исходной странице продукта (/all-widgets/white-widget). В этом руководстве говорится, что это структура, которую использует Zappos, и говорится: «В этом подходе есть элегантность. Тем не менее, я хотел бы вернуться к нему сегодня в свете изменений в мире SEO».
В этом руководстве говорится, что это структура, которую использует Zappos, и говорится: «В этом подходе есть элегантность. Тем не менее, я хотел бы вернуться к нему сегодня в свете изменений в мире SEO».
Я заметил, что Zappos и многие другие магазины теперь на самом деле просто ссылаются на страницу родительского продукта (например, если я нахожусь в разделе свадебных виджетов и нажимаю на виджет, я перехожу на все продукты/белый виджет вместо свадебных виджетов). /white-widget). Итак, мой вопрос: должны ли мы вообще иметь эти отдельные URL-адреса продуктов или просто избавиться от них вообще? Моя первоначальная мысль заключалась в том, что для поискового запроса «белый виджет свадьбы» было бы полезно иметь URL-адрес продукта Wedding-widget/white-widget, но мы все равно не воспользуемся этим, используя rel=canonical.
Средний и продвинутый SEO | | берхлор
0
 org/ListItem»> Как бы вы использовали эту возможность построения неработающих ссылок?
org/ListItem»> Как бы вы использовали эту возможность построения неработающих ссылок? Я нашел хорошую возможность создать несколько ссылок, и я хотел бы узнать ваше мнение о моих вариантах здесь.
Раз в год в моем городе происходит большое событие. Допустим, у мероприятия был веб-сайт под названием www.CityEvent.com. Мероприятие решило больше не использовать этот веб-сайт, а вместо этого разместить всю информацию о своем мероприятии на своей странице в Facebook. Похоже, они допустили истечение срока действия своего доменного имени, и кто-то другой прихватил его. Теперь он выглядит как пустой блог WordPress с одной строкой текста.
Этот пустой веб-сайт имеет 1300 ссылок, указывающих на него.
Я вижу здесь две возможности:
1. Напишите очень подробную статью на моем веб-сайте (на которую я пытаюсь создать ссылки), описывающую событие и предоставляющую людям всю необходимую информацию о нем. (Объем информации на странице Facebook минимальный.)
или
2. Создайте новый веб-сайт под названием www.EventCity.com и разместите статическую страницу со всей необходимой людям информацией. На этой странице будет ссылка, указывающая на сайт, который я пытаюсь ранжировать.
В обоих случаях будет гораздо больше информации, чем доступно на странице Facebook, включая коллекцию видеороликов на YouTube о мероприятии и множество полезных ссылок для людей, интересующихся такого рода мероприятиями.
Затем план состоит в том, чтобы связаться с сайтами, которые ссылаются на мертвую страницу, и предложить им сделать ссылку на мою новую страницу (либо на мой сайт, либо на новый сайт, который я мог бы создать).
Я вижу несколько плюсов и минусов в каждом методе.
Что касается варианта № 2, я думаю, что люди с большей вероятностью будут ссылаться на более официальную страницу, чем на статью на отдельном веб-сайте. (На моем веб-сайте есть информация о рассматриваемом городе, но он никак не связан с этим событием.
(Объем информации на странице Facebook минимальный.)
или
2. Создайте новый веб-сайт под названием www.EventCity.com и разместите статическую страницу со всей необходимой людям информацией. На этой странице будет ссылка, указывающая на сайт, который я пытаюсь ранжировать.
В обоих случаях будет гораздо больше информации, чем доступно на странице Facebook, включая коллекцию видеороликов на YouTube о мероприятии и множество полезных ссылок для людей, интересующихся такого рода мероприятиями.
Затем план состоит в том, чтобы связаться с сайтами, которые ссылаются на мертвую страницу, и предложить им сделать ссылку на мою новую страницу (либо на мой сайт, либо на новый сайт, который я мог бы создать).
Я вижу несколько плюсов и минусов в каждом методе.
Что касается варианта № 2, я думаю, что люди с большей вероятностью будут ссылаться на более официальную страницу, чем на статью на отдельном веб-сайте. (На моем веб-сайте есть информация о рассматриваемом городе, но он никак не связан с этим событием. ) Однако я получу только одну ссылку на свой сайт. Одним из минусов этого является то, что настоящие организаторы мероприятия могут быть недовольны тем, что кто-то создал официальную страницу. Но опять же, возможно, они были бы счастливы иметь бесплатный веб-сайт.
Для варианта № 1 я, возможно, получу больше ссылок с сайтов, авторитетных в моем городе, которые указывают непосредственно на сайт, который я пытаюсь ранжировать. Однако люди с меньшей вероятностью будут ссылаться на нас, потому что мы не официальный сайт мероприятия, а просто очень хорошая статья о мероприятии. Других хороших статей об этом событии, занимающих высокие позиции в Google, нет.
Надеюсь, это имеет смысл. Что бы вы сделали?
РЕДАКТИРОВАТЬ. Просто подумал о третьем варианте — попробуйте купить домен.
) Однако я получу только одну ссылку на свой сайт. Одним из минусов этого является то, что настоящие организаторы мероприятия могут быть недовольны тем, что кто-то создал официальную страницу. Но опять же, возможно, они были бы счастливы иметь бесплатный веб-сайт.
Для варианта № 1 я, возможно, получу больше ссылок с сайтов, авторитетных в моем городе, которые указывают непосредственно на сайт, который я пытаюсь ранжировать. Однако люди с меньшей вероятностью будут ссылаться на нас, потому что мы не официальный сайт мероприятия, а просто очень хорошая статья о мероприятии. Других хороших статей об этом событии, занимающих высокие позиции в Google, нет.
Надеюсь, это имеет смысл. Что бы вы сделали?
РЕДАКТИРОВАТЬ. Просто подумал о третьем варианте — попробуйте купить домен.
Средний и продвинутый SEO | | Мари Хэйнс
0