
Заблуждение о том, что СУБД и БД — это одно и то же
Эта статья о различии между понятиями система управления базами данных (СУБД) и база данных (БД); в ней подчеркивается, что система управления базами данных является субъектом управления и программой, а база данных объектом управления и собственно данными, которыми управляет СУБД. Из этого объяснения становится понятно, чем отчается СУБД от БД.
Сокращения
Раскрывая сокращения, получаем:
с СУБД – это система управления базами данных,
с БД – это база данных.
Другими словами, СУБД – это то, что управляет базой данных, а посему СУБД — это субъект, а БД и объект управления.
Семантика
Различие между этими понятиями станет очевидным сразу же, как только мы вспомним, что СУБД – это программа1, а БД – это данные, которыми эта программа распоряжается (или управляет, или манипулирует).
Насколько различны программы и данные, настолько же различны СУБД и БД. На схемах базы данных обычно рисуют в виде диска-бочонка с данными, а СУБД в виде прямоугольника, см. схему (рисунок 1).
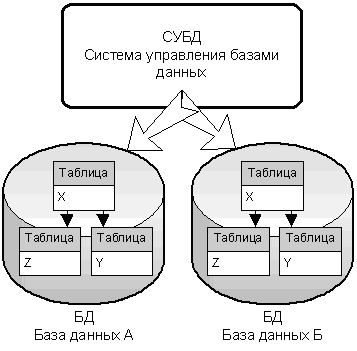
На этой схеме базы данных содержат табличные данные, что не обязательно.
Рисунок 1 – СУБД – это программа, БД – это данные
Все базы данных имеют некоторую, не всегда табличную, внутреннюю структуру и содержат наборы данных, уложенных в эту структуру. Структуры «родственных» баз одинаковы, а наборы данных в каждой базе уникальны.
Иногда заявляют, что СУБД и БД неразрывны, так как СУБД может управлять только созданной ей же БД и никакой другой. И на этом неверном основании, что СУБД и БД неразрывны, заключают, что слова СУБД и БД взаимозаменяемы. Утверждение о неразрывности неверное. Во-первых, потому что одна СУБД может управлять несколькими созданными ей же БД и тогда говорить о взаимозаменяемости слов не приходится. Во-вторых, некоторые СУБД могут управлять «чужими» БД, например, СУБД Access может управлять базой dbf, спроектированной и наполненной в СУБД FoxPro.
Количественные отношения
Одна СУБД может управлять несколькими базами данных, что, собственно, подчеркивает предыдущая схема (Рисунок 1): СУБД одна, а баз данных – две. Неравные количественные отношения между двумя терминами тоже свидетельствуют об их принципиальном различии.
Выводы
СУБД – это программа, а БД – это данные.
Слова СУБД и БД не синонимы. Нельзя вместо слова СУБД писать слово БД и наоборот.
Одна СУБД может управлять несколькими базами данных. Однако одна БД не может находиться под управлением нескольких СУБД одновременно.
В подавляющем большинстве случаев, СУБД это серийно выпускаемый программный продукт, а БД всегда уникальна, по меньшей мере, набором данных.
Немцов Э. Ф.
Статья впервые опубликована здесь, на моем сайте в декабре 2013.
nemtsov.ners.ru
SQL или NoSQL — вот в чём вопрос / RUVDS.com corporate blog / Habr
Все мы знаем, что в мире технологий баз данных существует два основных направления: SQL и NoSQL, реляционные и нереляционные базы данных. Различия между ними заключаются в том, как они спроектированы, какие типы данных поддерживают, как хранят информацию.Реляционные БД хранят структурированные данные, которые обычно представляют объекты реального мира. Скажем, это могут быть сведения о человеке, или о содержимом корзины для товаров в магазине, сгруппированные в таблицах, формат которых задан на этапе проектирования хранилища.
Нереляционные БД устроены иначе. Например, документо-ориентированные базы хранят информацию в виде иерархических структур данных. Речь может идти об объектах с произвольным набором атрибутов. То, что в реляционной БД будет разбито на несколько взаимосвязанных таблиц, в нереляционной может храниться в виде целостной сущности.
Внутреннее устройство различных систем управления базами данных влияет на особенности работы с ними. Например, нереляционные базы лучше поддаются масштабированию.
Какую технологию выбрать? Ответ на этот вопрос зависит от особенностей проекта, о котором идёт речь.
О выборе SQL-баз данных
Не существует баз данных, которые подойдут абсолютно всем. Именно поэтому многие компании используют и реляционные, и нереляционные БД для решения различных задач. Хотя NoSQL-базы стали популярными благодаря быстродействию и хорошей масштабируемости, в некоторых ситуациях предпочтительными могут оказаться структурированные SQL-хранилища. Вот две причины, которые могут послужить поводом для выбора SQL-базы:
- Необходимость соответствия базы данных требованиям ACID (Atomicity, Consistency, Isolation, Durability — атомарность, непротиворечивость, изолированность, долговечность). Это позволяет уменьшить вероятность неожиданного поведения системы и обеспечить целостность базы данных. Достигается подобное путём жёсткого определения того, как именно транзакции взаимодействуют с базой данных. Это отличается от подхода, используемого в NoSQL-базах, которые ставят во главу угла гибкость и скорость, а не 100% целостность данных.
- Данные, с которыми вы работаете, структурированы, при этом структура не подвержена частым изменением. Если ваша организация не находится в стадии экспоненциального роста, вероятно, не найдётся убедительных причин использовать БД, которая позволяет достаточно вольно обращаться с типами данных и нацелена на обработку огромных объёмов информации.
О выборе NoSQL-баз данных
Если есть подозрения, что база данных может стать узким местом некоего проекта, основанного на работе с большими объёмами информации, стоит посмотреть в сторону NoSQL-баз, которые позволяют то, чего не умеют реляционные БД.
Вот возможности, которые стали причиной популярности таких NoSQL баз данных, как MongoDB, CouchDB, Cassandra, HBase:
- Хранение больших объёмов неструктурированной информации. База данных NoSQL не накладывает ограничений на типы хранимых данных. Более того, при необходимости в процессе работы можно добавлять новые типы данных.
- Использование облачных вычислений и хранилищ. Облачные хранилища — отличное решение, но они требуют, чтобы данные можно было легко распределить между несколькими серверами для обеспечения масштабирования. Использование, для тестирования и разработки, локального оборудования, а затем перенос системы в облако, где она и работает — это именно то, для чего созданы NoSQL базы данных.
- Быстрая разработка. Если вы разрабатываете систему, используя agile-методы, применение реляционной БД способно замедлить работу. NoSQL базы данных не нуждаются в том же объёме подготовительных действий, которые обычно нужны для реляционных баз.
В следующем разделе рассмотрим некоторые различия между технологиями SQL и NoSQL. А именно, сначала взглянем на простой пример, показывающий фундаментальное различие двух подходов к организации баз данных, потом поговорим о масштабируемости и индексации данных. А в итоге остановимся на примере большой CRM-системы, нуждающейся в высокой производительности хранилища данных.
SQL и NoSQL
Начнём с некоторых ключевых концепций реляционных и нереляционных баз данных. Ниже показана база данных, содержащая сведения о взаимоотношениях людей. Вариант a — это бессхемная структура, построенная в виде графа, характерная для NoSQL-решений. Вариант b показывает, как те же данные можно представить в структурированном виде, типичном для SQL.
Два варианта представления данных
Бессхемность означает, что два документа в структуре данных NoSQL не должны иметь одинаковые поля и могут хранить данные разных типов. Вот, например, массив объектов, набор полей которых не совпадает.
var cars = [
{ Model: "BMW", Color: "Red", Manufactured: 2016 },
{ Model: "Mercedes", Type: "Coupe", Color: "Black", Manufactured: "1-1-2017" }
];При реляционном подходе данные надо хранить в заранее спроектированной структуре, из которой эти данные потом можно извлекать. Например, используя оператор
JOINSELECT Orders.OrderID, Customers.Name, Orders.Date
FROM Orders
INNER JOIN Customers
ON Orders.CustID = Customers.CustIDКак более продвинутый пример, для демонстрации того, когда SQL предпочтительнее NoSQL, рассмотрим особенности применения в NoSQL-базах алгоритмов уплотнения. Проблема заключается в том, что в некоторых NoSQL-базах (например, в CouchDB и HBase) постоянно приходится формировать так называемые
sstables — строковые таблицы в формате ключ-значение, отсортированные по ключу. В такие таблицы, которые сохраняются на диск, данные попадают из таблиц, хранящихся в памяти, при их переполнении и в других ситуациях. При интенсивной работе с базой создание таблиц, со временем, приводит к тому, что подсистема ввода-вывода устройства хранения данных становится узким местом для операций чтения данных. Как результат, чтение в NoSQL-базе происходит медленнее, чем запись, что сводит на нет одно из главных преимуществ нереляционных баз данных. Именно для того, чтобы уменьшить этот эффект, системы NoSQL используют, в фоновом режиме, алгоритмы уплотнения данных, пытаясь объединить множество таблиц в одну. Но и сама по себе эта операция весьма ресурсоёмка, система работает под повышенной нагрузкой.Масштабируемость
Одно из основных различий рассматриваемых технологий заключается в том, что NoSQL-базы лучше поддаются масштабированию. Например, в MongoDB имеется встроенная поддержка репликации и шардинга (горизонтального разделения данных) для обеспечения масштабируемости. Хотя масштабирование поддерживается и в SQL-базах, это требует гораздо больших затрат человеческих и аппаратных ресурсов.
| Тип хранилища данных |
Сценарий использования |
Пример |
Рекомендации |
| Хранилище типа ключ-значение |
Подходит для простых приложений, с одним типом объектов, в ситуациях, когда поиск объектов выполняют лишь по одному атрибуту. |
Интерактивное обновление домашней страницы пользователя в Facebook. |
Рекомендовано знакомство с технологией memcached. Если приходится искать объекты по нескольким атрибутам, рассмотрите вариант перехода к хранилищу, ориентированному на документы. |
| Хранилище, ориентированное на документы |
Подходит для хранения объектов различных типов. |
Транспортное приложение, оперирующее данными о водителях и автомобилях, работая с которым надо искать объекты по разным полям, например — имя или дата рождения водителя, номер прав, транспортное средство, которым он владеет. |
Подходит для приложений, в ходе работы с которыми допускается реализация принципа «согласованность в конечном счёте» с ограниченными атомарностью и изоляцией. Рекомендуется применять механизм кворумного чтения для обеспечения своевременной атомарной непротиворечивости. |
| Система хранения данных с расширяемыми записями |
Более высокая пропускная способность и лучшие возможности параллельной обработки данных ценой слегка более высокой сложности, нежели у хранилищ, ориентированных на документы. |
Приложения, похожие на eBay. Вертикальное и горизонтальное разделение данных для хранения информации клиентов. |
Для упрощения разделения данных используются HBase или Hypertable. |
| Масштабируемая RDBMS |
Использование семантики ACID освобождает программистов от необходимости работать на достаточно низком уровне, а именно, отвечать за блокировки и непротиворечивость данных, обрабатывать устаревшие данные, коллизии. |
Приложения, которым не требуются обновления или слияния данных, охватывающие множество узлов. |
Стоит обратить внимание на такие системы, как MySQL Cluster, VoltDB, Clustrix, ориентированные на улучшенное масштабирование. |
Более подробное сравнение SQL и NoSQL можно найти в этом материале. Вот его основные положения. А именно, были проведены испытания трёх основных характеристик систем: параллельная обработка данных, работа с хранилищами информации, репликация данных. Возможности параллельной обработки оценивались путём анализа механизмов блокировки, управления параллельным доступом на основе многоверсионности, и ACID. Тестирование хранилищ охватывало и физические носители, и хранилища использующие оперативную память. Репликацию испытывали в синхронном и асинхронном режимах.
Используя данные, полученные в ходе испытаний, авторы делают выводы о том, что SQL-базы с возможностью кластеризации показали многообещающие результаты производительности в расчёте на один узел, и, кроме того, обладают способностью масштабируемости, что даёт системам RDBMS преимущество перед NoSQL за счёт полного соответствия принципам ACID.
Индексация
В системах RDBMS индексация используется для ускорения операций извлечения данных из баз. Отсутствие индекса означает, что таблица должна быть просмотрена целиком для того, чтобы выполнить запрос на чтение.
И в SQL, и в NoSQL-базах индексы служат одной и той же цели — ускорить и оптимизировать извлечение данных. Но то, как именно они работают — различается из-за разных архитектур баз данных и особенностей хранения информации в базе. В то время, как SQL-индексы представлены в виде B-деревьев, которые отражают иерархическую структуру реляционных данных, в NoSQL базах данных они указывают на документы, или на части документов, между которыми, в основном, нет никаких отношений. Вот подробный материал на эту тему.
CRM-системы
CRM-приложения — это один из лучших примеров систем, для которых характерны огромные объёмы ежедневно обрабатываемых данных и очень большое количество транзакций. Все разработчики таких приложений используют и SQL, и NoSQL базы данных. И, хотя большая часть данных транзакций всё ещё хранится в SQL-базах, применение находят общедоступные системы класса DBaaS (data-base-as-a-service, база данных как сервис), наподобие AWS DynamoDB и Azure DocumentDB, в результате, серьёзная нагрузка по обработке данных может быть перенесена в облачные NoSQL-базы.
В то время, как использование подобных служб освобождает разработчика от решения задач по обслуживанию хранилищ, это, кроме того, область, где NoSQL базы применяются для того, для чего они, в основном, и были созданы, например, для глубинного анализа данных. Объёмы информации, хранимой в огромных CRM-системах финансовых и телекоммуникационных компаний, было бы практически невозможно проанализировать, используя инструменты вроде SAS или R. Это потребовало бы огромных аппаратных ресурсов.
Главное преимущество таких систем — использование неструктурированных данных, похожих на документы. Такие данные могут подаваться на вход статистических моделей, которые дают компаниям возможность выполнять различные виды анализа. CRM-приложения, кроме того, являются весьма удачным примером, в котором две системы баз данных выступают не конкурентами, а существуют в гармонии, играя каждая свою роль в большой архитектуре управления данными.
Итоги
Занимаясь поиском системы управления базами данных, можно выбрать одну технологию, а позже, уточнив требования, переключиться на что-то другое. Однако, разумное планирование позволит сэкономить немало времени и средств.
Вот признаки проектов, для которых идеально подойдут SQL-базы:
- Имеются логические требования к данным, которые могут быть определены заранее.
- Очень важна целостность данных.
- Нужна основанная на устоявшихся стандартах, хорошо зарекомендовавшая себя технология, используя которую можно рассчитывать на большой опыт разработчиков и техническую поддержку.
А вот свойства проектов, для которых подойдёт что-то из сферы NoSQL:
- Требования к данным нечёткие, неопределённые, или развивающиеся с развитием проекта.
- Цель проекта может корректироваться со временем, при этом важна возможность немедленного начала разработки.
- Одни из основных требований к базе данных — скорость обработки данных и масштабируемость.
В итоге хочется сказать, что в современном мире нет противостояния между реляционными и нереляционными базами данных. Вместо этого стоит говорить об их совместном использовании для решения задач, на которых та или иная технология показывает себя лучше всего. Кроме того, всё сильнее наблюдается интеграция этих технологий друг в друга. Например, Microsoft, Oracle и Teradata сейчас предлагают некоторые формы интеграции с Hadoop для подключения аналитических инструментов, основанных на SQL, к миру неструктурированных больших данных.
Уважаемые читатели, а вам приходилось выбирать системы управления базами данных для собственных проектов? Если да — поделитесь пожалуйста опытом, расскажите, что и почему вы в итоге выбрали.
habr.com
1.Определение бд. Отличие бд от других информационных систем.
Определение. Базой данных называется совокупность специальным образом организованных данных, которые: 1) подлежат долговременному хранению в памяти ЭВМ; 2) являются носителем информации о небольшом количестве классов объектов, однако количество экземпляров объектов в классе может быть огромным; 3) используются в одном или нескольких приложениях, относящихся к одной прикладной области
2.Категории бд: физический и логический уровень.
Физические:
Поле – наименьшая единица данных, с определенным адресом и размером
Физическая Запись – упорядочная последовательность фиксированного количества полей
Файл – совокупность однотипных физ. Записей
Блок — единица обмена данных между оперативной и внешней памятью
Логические:
Атрибут — наименьшая единица информации с определенным типом и наименованием
Логическая запись — совокупность фиксированного количества различных атрибутов
Отношение – совокупность однотип. Логических записей
Схема отношений – заголовок таблицы
Схема БД – совокупность схем отношений с установленными связями и ограничениями целостности
3. Ограничение целостности на данные
Целостность — понимается как правильность данных в любой момент времени.
Ограничение домена – задает допустимые значения того или иного атрибута
Ограничение первичного ключа –не удастся отношение заполнить записями с одинаковыми первичн. ключами
Ссылочная целостность — задаётся на связях между отношениями на схеме БД
4.Неизбыточность и непротиворечивость данных.
1. Неизбыточность и непротиворечивость данных. Если несколько приложений в одной прикладной области работают со своими собственными наборами файлов. При этом они используют общие данные из прикладной области, которые дублируются в файлах. Такая ситуация называется избыточностью данных. Противоречивость данных – следствие избыточности, так как согласование данных программным способом не выполняется.
5.Защита от программных и аппаратных сбоев.
2. Защита от программных и аппаратных сбоев должна обеспечиваться средствами СУБД. Типы сбоев:
а) Логический сбой:
1) Пользователь вводит информацию об объекте, но эта информация уже есть в БД.
2) Пользователь удаляет запись об объекте, но на нее есть ссылка из других объектов (записей).
б) Физический сбой происходит в результате прекращения работы СУБД
В результате может быть нарушена структура БД. Для решения проблемы используются:
1) локальность модифицирующих воздействий
2) архивация данных;
3) СУБД ведет журнал модификаций в служебном файле.
6.Принцип независимости данных. Технологическая основа его реализации.
Прикладная программа, работающая с БД, не должна зависеть от способа и места хранения данных на физическом уровне, а ее исходный текст не зависит от аппаратуры и операционной системы.
1) Физический уровень — информация о полях и структуре БД
2) Глобальное логическое описание – Схема БД
3) Внешние логические схемы — инф-ция о структуре данных, используемых прикладными программами
Защита от несанкционированного доступа к данных реализуется следующим образом:
а) Пароль при входе в систему
б) Защита файловой системы средствами операционной системы.
в) Шифрование данных на физическом уровне.
studfile.net
Базы данных SQL, NoSQL и различия в моделях баз данных
Сегодня довольно сложно представить себе какое-либо приложение, которое не использовало бы базы данных, будь то сервера, персональные компьютеры или мобильные устройства. От простых игр до серьезных бизнес приложений. Все они обрабатывают, читают и записывают определенный набор данных.
Система управления базами данных (DBMS/СУБД) — программное обеспечение, предназначенное для хранения и управления данными. Для решения различных задач разрабатывалось всё больше и больше различных СУБД (Реляционные и NoSQL) и программ для работы с ними (MySQL, PostgreSQL, MongoDB, Redis и т.д.)
Содержание
- СУБД
- Модели БД
- Реляционная модель
- Безсхемный подход (NoSQL)
- Популярные СУБД
- Реляционные СУБД
- NoSQL (NewSQL) СУБД
- Сравнение SQL и NoSQL БД
Системы управления базами данных
Термин СУБД включает в себя довольно большое количество сильно отличающихся друг от друга инструментов для работы с базами данных (отдельные программы и подключаемые библиотеки). Так как данные бывают различных видов и типов, начиная со второй половины 20 века было разработано огромное количество разных СУБД и других приложений для работы с БД.
СУБД основываются на модели базы данных — это специальные структуры предназначенные для работы с данными. Все СУБД сильно отличаются в том, каким образом они хранят и обрабатывают свои данные.
Хотя существуют много решений для работы с БД, популярными и востребованными становятся лишь некоторые из них. Наиболее часто применяемая на сегодняшний день — реляционная система управления базами данных.
Модели БД
Каждая система поддерживает различные модели и структуры баз данных. Эта модель и определяет, как создаваемая СУБД будет оперировать данными. Существует довольно немного моделей БД, которые предоставляют способы четкого структурирования данных, самая популярная из таких моделей — реляционная модель.
Реляционная модель и реляционные БД могут быть очень мощным инструментом, но только если программист знает как с ними обращаться. Недавно, стали набирать популярность NoSQL системы с обещанием избавиться от старых проблем БД и добавить новый функционал. Исключая жесткую структуру данных, при этом сохранив реляционный стиль, эти СУБД предлагают более свободный способ работы с ними и гораздо большие возможности для их настройки. Хотя не обходится и без возникновения новых проблем.
Реляционная модель
Представленная в 1970 году реляционная модель предложила математический способ структурирования, хранения и использования данных. По сути он расширил плоскую и сетевую модели, объединив их в реляционную. Основное преимущество которой было объединение данных в группы, именно реляционная модель позволила хранить данные в структурированном табличном виде (ФИО, адрес).
Благодаря десятилетиям разработки, СУБД достигли довольно высокого уровня в производительности и отказоустойчивости. Опытом разработчиков и сетевых администраторов было доказано, что все эти инструменты отлично справляются со своими функциями в приложениях любой сложности, не теряют данных даже при некорректных завершениях работы.
Несмотря на большие ограничения в формировании и управлении данными, реляционные базы данных сохраняют широкие возможности по настройке и предлагают довольно большой функционал.
Неструктурированный подход (NoSQL)
NoSQL убирает все ограничения реляционной модели (недостаточная производительность, трудоёмкое горизонтальное масштабирование, недостаточная производительность в кластере) и облегчает средства хранения и доступа к данным. Такие БД используют неструктурированный подход (создание структуры на лету), тем самым снимая ограничения жестких связей и предлагая различные типы доступа к специфическим данным.
Популярные СУБД
Цель этой статьи — познакомить вас с парадигмами основных систем баз данных. Довольно сложно озвучить определенное решение, но, как правило, приходится выбирать между реляционной моделью и NoSQL. Прежде чем начать искать различия, давайте разберемся во внутренних процессах.
Реляционные СУБД
Реляционные СУБД берут своё название от модели БД с которой работают. На данный момент и, наверное, в ближайшем будущем эти СУБД будут наиболее популярным выбором для хранения данных.
Реляционные СУБД используют строго описанные структуры данных — схемы. Схема базы данных включает в себя описание содержания, структуры и ограничений целостности, т.е. она определяет таблицы, поля в каждой таблице, а также отношения между полями и таблицами.
Вот некоторые из наиболее популярных систем:
- SQLite — довольно мощная встраиваемая СУБД
- MySQL — наиболее популярная СУБД
- PostgreSQL — самая профессиональная свободно распространяемая СУБД, полностью соответствующая стандартам SQL
Заметка: в статье Сравнение реляционных СУБД вы можете найти более подробную информацию о реляционных СУБД.
NoSQL (NewSQL) СУБД
NoSQL базы данных не работают с реляционными моделями. Существует много различных решений, каждое из которых работает немного по-своему и служит специфической цели. Эти безсхемные решения снимают ограничения с формирования сущностей и допускают хранения данных в виде ключ-значение.
В отличии от реляционных баз данных, можно группировать коллекции данных с другими NoSQL базами данных, например MongoDB. Такие СУБД хранят данные как одно целое в базе. Такие данные могут представлять собой одиночный объект как JSON и вместе с тем корректно отвечать на запросы к полям.
NoSQL базы данных не используют общий формат запроса, такой как SQL в реляционных базах данных. Каждое NoSQL решение использует собственную систему запросов.
Заметка: более подробно о NoSQL вы можете прочитать в нашей статье: Сравнение NoSQL СУБД
Сравнение SQL и NoSQL систем управления базами данных
Для представления общей картины давайте сравним эти два типа СУБД:
- Стуруктуры данных и их типы — реляционные БД используют строгие схемы данных, NoSQL БД допускают любой тип данных
- Запросы — вне зависимости от типа лицензии, реляционные базы данных в той или иной мере соответствуют стандартам SQL, поэтому данные из них можно получать при помощи языка SQL. NoSQL БД используют специфические способы запросов к данным.
- Масштабируемость — оба эти типа СУБД довольно легко поддаются вертикальному масштабированию (т.е. увеличение системных ресурсов). Тем не менее, так как NoSQL это более современный продукт, именно такие СУБД предлагают более простые способы горизонтального масштабирования (т.е. создание кластера из нескольких машин).
- Надежность — когда дело доходит до сохранности данных и гарантии выполнения транзакций SQL БД по прежнему занимают лидирующие позиции.
- Поддержка — Реляционные СУБД имеют не малую историю за плечами. Они очень популярны и предлагают как платные, так и бесплатные решения. При возникновении проблем, все же гораздо проще найти ответ, если дело касается реляционных систем, чем NoSQL, особенно если решение довольно сложное по своей природе (например MongoDB).
- Хранение и доступ к сложным структурам данных — изначально реляционные системы предполагали работу со сложными структурами, именно поэтому они превосходят остальные решения по производительности.
devacademy.ru
Реляционные БД vs Объектно-ориентированные БД / Habr
К сожалению не нашел на хабре достаточно интересных стаей про объектно-ориентированные базы данных (ООБД). Хотелось бы поднять эту тему, т.к. в последнее время все больше и больше идет разговоров об ООБД. Однако в одну статью всю информацию уложить не получится, поэтому приведу для начала небольшой обзор и свои размышления на эту тему. В этой статье я не буду рассматривать конкретные решения, основанные на каждой из технологий, а только постараюсь сравнить сами технологии.Предыстория
Я занимаюсь проектированием и разработкой баз данных уже порядка 6 лет. За это время у меня сложилось свое видение как лучше подходить к проектированию, как выбирать архитектуру системы, какие существуют особенности при нормализации и денормализации реляционных БД, как оптимизировать те или иные конструкции и запросы. В первый год работы я пришел к тому, что не хочу заниматься рутиной по написанию одних и тех же запросов. В результате я написал свой генератор хранимых процедур, который по структуре БД генерировал большинство рутинных запросов (если будет интересно, то могу написать статью на эту тему). Затем этот генератор эволюционировал из года в год, и, в итоге, я пришел к необходимости хранить объекты, как они есть, чтобы не заморачиваться переводом объектной модели в реляционную структуру. Т.е. фактически я пришел к генерации некой ORM надстройки. Конечно, Вы можете сказать, что уже создано достаточное количество качественных ORM надстроек и объектно-реляционных БД, которые можно успешно использовать (и я с Вами соглашусь, но с некоторыми оговорками). Но и это меня не устроило. И я решил пойти дальше.
Влияние ORM
По моему скромному мнению использование ORM надстроек только тормозит развитие ООБД. Постараюсь пояснить это достаточно спорное утверждение. Я не считаю, что ORM это зло, но и абсолютным добром она тоже не является. Технология ORM несомненно сыграла (да и сейчас играет) важную роль в развитии средств разработки, она показала, что программист на самом деле может и не заботиться о логике хранения данных. Однако здесь, как и везде есть свои «НО».
Использование ORM несомненно ускоряет разработку продукта, снижает трудозатраты и бла-бла-бла. Однако, любая ORM это некая прослойка, которая всегда будет работать медленнее, нежели прямая работа (я тут отнюдь не призываю перенести все вызовы SQL запросов в приложение – везде должна быть золотая середина). Наличие ORM позволяет разработчикам не особо задумываться о работе СУБД (и они-таки не задумываются в большистве своем), что влечет за собой, мягко говоря, не совсем оптимальную работу приложения под нагрузкой. Для оптимизации приходится лезть руками в прослойку и настраивать запросы так, чтобы они стали работать быстрее, приходится лезть в базу данных и перенастраивать индексы и таблицы. Таким образом, для оптимальной работы приложения необходимо приложить больше усилий, нежели когда ORM отсутствует. В итоге мы сокращаем затраты на разработку и ускоряем выпуск первой версии продукта, но усложняем процесс оптимизации.
Однако об оптимизации никто не думает в момент написания первой (а зачастую и второй, и третьей) версии продукта. Для большинства контор сейчас главным фактором является не качество, а скорость разработки. Оно и понятно: изначально заказчик хочет получить продукт как можно раньше, затратив минимум денег. И только спустя некоторое время, когда база наполнится реальными данными, пройдет пару месяцев, заказчик (да и разработчик тоже) с удивлением обнаруживает, что время выборок увеличилась почти вдвое, при работе 10-20 пользователей одновременно СУБД пытается покончить жизнь самоубийством и т.д. и т.п. Разработчик часто руководствуется восточной мудростью: А там уже либо ишак сдохнет, либо султан, либо сам Ходжа. Но, если никто не сдох, то вот тут-то разработчик и начинает искать узкие места, выдирает из ORM автоматически сгенерированные запросы, переписывает их руками, перестраивает индексы в таблицах БД и тратит на это и подобную оптимизацию еще уйму времени и сил.
Что-то меня понесло в сторону. Надеюсь, я достаточно понятно изложил свою позицию относительно ORM. Давайте вернемся к сравнению (или, если кому угодно — противостоянию) реляционных и объектно-ориентированных БД.
Реляционные БД vs ООБД
Не смотря на огромную популярность парадигмы ООП в программировании, в технологии разработки баз данных эта парадигма пока не особо популярна. И тому есть как объективные, так и субъективные причины.
- Популярность. Под реляционные базы создано множество замечательных продуктов, которые необходимо поддерживать и развивать. В эти продукты уже вложены большие деньги и заказчики готовы еще вкладывать деньги в их развитие. Напротив, с использованием ООБД разработано сравнительно мало серьезных коммерческих продуктов, существует мало мощных ООСУБД.
- Язык запросов и его стандартизация. Еще в далеком 1986 году был принят первый стандарт SQL-86, который определил всю судьбу реляционных БД. После принятия стандарта все разработчики реляционных СУБД обязаны были следовать ему. Для объектно-ориентированных баз данных пока стандарта языка запросов нет. Сейчас среди разработчиков даже нет единого мнения о том, что этот язык запросов должен делать, не говоря уже о том, как он это должен делать.
- Математический аппарат. Для реляционных БД в свое время Эдгар Кодд заложил фундамент математического аппарата реляционной алгебры. Этот мат. аппарат объясняет, как должны выполняться основные операции над отношениями в базе данных, доказывает их оптимальность (либо из него видно, где надо оптимизировать). С другой стороны для ООБД нет такого аппарата, даже не смотря на то, что работы в этой области ведутся с 80-х годов. Таким образом, в ООБД пока нет строгих терминов, таких как декартово произведение, отношение и т.д.
- Проблема хранения данных и методов. В реляционных БД хранятся только голые данные. Что с ними будет делать приложение, зависит уже от приложения. В ООБД же, напротив должны храниться объекты, а объект это совокупность его свойств (параметры объекта) и методов (интерфейс объекта). Здесь так же нет единого мнения, как ООБД должна осуществлять хранение объектов и как разработчик должен эти объекты разрабатывать и проектировать. Здесь же возникает и проблема хранения иерархии объектов, хранение абстрактных классов и т.п.
Выводы и перспективы
В свете сложившейся в настоящее время ситуации в мире разработки, перспектива появления серьезных и популярных решений с использованием ООБД кажется весьма сомнительной (но от этого не менее желаемой) до тех пор, пока не будут разрешены фундаментальные вопросы (мат аппарат и стандарт языка запросов). Меня, как разработчика, это несколько печалит, ибо я пришел к выводу, что наличие мощной и удобной ООБД просто необходимо для дальнейшего качественного развития средств разработки баз данных.
Что касается перспектив реляционных БД, то я полагаю, что они будут жить еще достаточно долго. ООБД все равно не смогут заменить реляционные БД в полном объеме. В некоторых реальных задачах все же удобней и правильней хранить данные не в объектах, а в таблицах.
Таким образом, я считаю, что со временем ООБД отвоюет у реляционных БД кусок рынка коммерческих систем, однако добиться такого тотального преимущества, которое сейчас имеют реляционные БД им не под силу.
habr.com
1) Определение бд. Отличие от других информационных систем.
Билет №1
Базы данных – это совокупность специальным образом организованных данных, которые:
подлежат долговременному хранению на внешних запоминающих устройствах ЭВМ.
содержат информацию о сравнительно небольшом, фиксированном кол-ве классов объектов, однако, кол-во экземпляров объектов в существующем классе может быть огромным
(все классы объектов принадлежат к одной прикладной области).
используется в одной или нескольких приложений.
Четко указывает место хранения данных – память, которое не стирается при выключении данных.
Подразумевается, что жизненный цикл данных намного больше чем программного обеспечения, которое с ними работает.
Специфическим свойством БД, которое отличает БД от др. видов информационных систем ИПС (информационно поисковые системы)
По технологии БД хотя бы на технологическом уровне должны быть одним целым.
2) Общие данные, данные пересечения и изолированные данные.
Общие данные присоединяются к определенному типу записи, при этом семантика общего данного изменится.
Элемент данных на схеме называется данные пересечения, если по правилу склейки он может быть присоединен сразу к нескольким типам записи, если его значение однозначно идентифицируется ключевыми полями нескольких типов записей одновременно.
Если элемент данных на схеме однозначно не явл. данным пересечения, то он изолированное данное.

Билет №2
1)Категории бд.
БД различаются терминологией физических и логических уровней.
На физическом уровне:
Поля наименования единицы информации, идентифицируемое БД. Характеристика поля — размер
физическая запись – упорядоченная совокупность фиксированного кол-ва полей. 2 записи однотипны, если ни состоят из одинаковой последовательности полей.
файл – совокупность однотипных физических записей.
индексный файл – структура, являющаяся реализацией какого-либо метода доступа к файлам. Базисные методы доступа
Методы доступа индексные:
Индексно-последовательный
Индексно-произвольный
В – дерево???
Мульти списки
Безындыксные методы доступа:
— прямой
— последовательный
— связные списки
— хемирование(???)
блок – объем данных, перекачиваемый в оперативную память за одно обращение к устройству ввода/вывода
На логическом уровне:
Элемент данных (атрибут). Наименьшая единица информации, идентифицируемая в БД, с определенным типом и наименованием – атрибут.
логическая запись – совокупность фиксированного количества элементов данных (атрибутов). Обычно соответствует физической записи.
2 записи однотипны, если они состоят из одинаковых атрибутов
отношение – совокупность однотипных логич. записей.
схема БД – совокупность отношений, относящихся к одной прикладной области, с установленным м/у ними связями и ограничениями целостности на данные.
2)Реляционные модели данных. Преобразование древовидных и сетевых моделей к реляционным.
Таблица представления данных называется реляционной, если:
— в таблице не может быть 2 кортежа с один содержанием
— все значения в таблице — однородны, т.е отображают одну и ту же характеристику
— каждый столбец во всей схеме базы имеет уникальное наименование и если наименование столбца совпадает, то они отображают одну и ту же характеристику разных объектов.
— каждая таблица в схеме отношений должна иметь уникальное имя.
— каждый элемент таблицы – элемент \ агрегат данных
— связи на схеме устанавливаются только за счёт одноименных элементов данных в таблице.
Если таблицы удовлетворяют всем шести признакам, то она называется 1 Нормально формой или 1 НФ
Правило преобразования:Если между парой отношений установлена связь 1:1, то эти отношения имеют совпадающие первичные ключи, причем главным является отношение значений ключа которого больше.
связь 1:1 на схеме не ликвидируется, она остается.
Если м/у двумя логическим записями установить связь 1:М, то первый тип отношения называется главным, во втором типе дублируются значения первичного ключа из 1-ого отношения, где оно будет не ключевым.
связь 1:М на схеме не ликвидируется, она остается.
Если м/у двумя логическим записями установить связь М:М, то формируется newтип записи, содержащих ключевые поля исходных записей, эти поля будут ключевыми в новом отношении.
связь М:М на схеме ликвидируется, а устанавливается связь 1:М .
удалям со схемы избыточные связи.
Билет №3
studfile.net
(Понятия базы данных, системы баз данных, системы управления базами данных
В широком смысле слова база данных (БД) – это совокупность сведений о конкретных объектах реального мира в какой-либо предметной области.
Для удобной работы с данными их необходимо структурировать, т.е. ввести определенные соглашения о способах их представления.
База данных (в узком смысле слова) — поименованная совокупность структурированных данных относящихся к некоторой предметной области
В реальной деятельности в основном используют системы БД.
Система баз данных (СБД) – это компьютеризированная система хранения структурированных данных, основная цель которой – хранить информацию и предоставлять ее по требованию.
Системы БД существуют и на малых, менее мощных компьютерах, и на больших, более мощных. На больших применяют в основном многопользовательские системы, на малых – однопользовательские.
Однопользовательская система (single-user system) – это система, в которой в одно и то же время к БД может получить доступ не более одного пользователя.
Многопользовательская система (multi-user system) — это система, в которой в одно и то же время к БД может получить доступ несколько пользователей.
Основная задача большинства многопользовательских систем – позволить каждому отдельному пользователю работать с системой как с однопользовательской.
Различия однопользовательской и многопользовательской систем – в их внутренней структуре, конечному пользователю они практически не видны.
Система баз данных содержит четыре основных элемента: данные, аппаратное обеспечение, программное обеспечение и пользователи.
Данные в БД являются интегрированными и общими.
Интегрированные – значит, данные можно представить как объединение нескольких, возможно перекрывающихся, отдельных файлов данных. (Например, имеется файл, содержащий данные о студентах – фамилию, имя, отчество, дату рождения, адрес и т.д., а другой – о спортивной секции. Необходимые данные о студентах, посещающих секцию, можно получить путем обращения к первому файлу.)
Общие – значит, отдельные области данных могут использовать различные пользователи, т.е. каждый из этих пользователей может иметь доступ к одной и той же области данных, даже одновременно. (Например, одни и те же данные БД о студентах может одновременно использовать студенческий отдел кадров и деканат.)
К аппаратному обеспечению относятся:
Накопители для хранения информации вместе с подсоединенными устройствами ввода-вывода, каналами ввода-вывода и т.д.
Процессор (или процессоры) вместе с основной памятью, которая используется для поддержки работы программного обеспечения системы.
Между собственно данными и пользователями располагается уровень программного обеспечения. Ядром его является система управления базами данных (databasemanagement system – DBMS), или диспетчер БД (database manager).
Система управления базами данных (СУБД) — это комплекс программных и языковых средств, необходимых для создания БД, поддержания их в актуальном состоянии и организации поиска в них необходимой информации.
Основная функция СУБД – это предоставление пользователю БД возможности работы с ней, не вникая в детали на уровне аппаратного обеспечения. Т.е. все запросы пользователя к БД, добавление и удаление данных, выборки, обновление данных – все это обеспечивает СУБД.
Иными словами, СУБД поддерживает пользовательские операции высокого уровня. Сюда включены и операции, которые можно выполнить с помощью языка SQL.
SQL — это специальные язык БД. Сейчас он поддерживается большинством СУБД, он является официальным стандартом языка для работы с реляционными системами. Название SQL вначале было аббревиатурой от Structured Query Language (язык структурированных запросов), сейчас название языка уже не считается аббревиатурой, т.к. функции его расширились и не ограничиваются только созданием запросов.
СУБД – это не единственный программный компонент системы, хотя и наиболее важный. Среди других – утилиты, средства разработки приложений, средства проектирования, генераторы отчетов и т.д.
Пользователей СБД можно разделить на три группы:
Прикладные программисты. Отвечают за написание прикладных программ, использующих БД. Для этих целей применимы различные языки программирования. Прикладные программы выполняют над данными стандартные операции – выборку, вставку, удаление, обновление – через соответствующий запрос к СУБД. Такие программы бывают простыми – пакетной обработки, или оперативными приложениями – для поддержки работы конечного пользователя.
Конечные пользователи. Работают с системами БД непосредственно через рабочую станцию или терминал. Конечный пользователь может получить доступ к БД, используя оперативное приложение или интегрированный интерфейс самой СУБД (такой интерфейс тоже является оперативным приложением, но встроенным). В большинстве систем есть хотя бы одно такое встроенное приложение – процессор языка запросов (или командный интерфейс). Язык SQL – пример языка запросов для БД. Кроме языка запросов в современных СУБД, как правило, есть интерфейсы, основанные на меню и формах – для непрофессиональных пользователей. Понятно, что командный интерфейс более гибок, содержит больше возможностей.
Администраторы БД. Отвечают за создание БД, технический контроль, обеспечение быстродействия системы, ее техническое обслуживание.
СУБД имеют свою архитектуру. В процессе разработки и совершенствования СУБД предлагались различные архитектуры, но самой удачной оказалась трехуровневая архитектура, предложенная исследовательской группой ANSI/SPARC американского комитета по стандартизации ANSI (American National Standards Institute). Упрощенная схема архитектуры СУБД приведена на рис. 1.
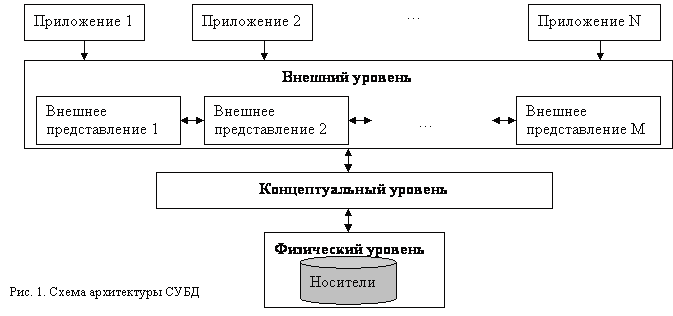
Внешний уровень – это уровень пользователя. По сути, это совокупность внешних представлений данных, которые обрабатывают приложения и какими их видит пользователь на экране. Это может быть таблица с отсортированными данными, с примененным фильтром, форма, отчет, результат запроса. Внешние представления взаимосвязаны, т.е. из одного внешнего представления можно получить другое.
Концептуальный уровень – центральный. Здесь БД представлена в наиболее общем виде, который объединяет данные, используемые всеми приложениями. Т.е. это обобщенная модель предметной области, для которой созданы БД. Можно сказать, что концептуальный уровень формируется при создании таблиц (определение их полей, типов, свойств), связей, а так же при заполнении таблиц.
Физический уровень – собственно данные, расположенные на внешних носителях.
studfile.net