
Частотность поисковых запросов в система Яндекс или Google
Что такое частотность поисковых запросов: основные виды и возможности для продвижения
Поисковые запросы – это фразы и словосочетания, которые пользователи набирают в строке поисковых систем. В зависимости от популярности, ключи подразделяются на несколько типов.
Для грамотного продвижения web сайта нужно учитывать информацию, которая интересует пользователей. На основе этих данных составляется набор релевантных ключевых фраз, соответствующий тематике портала. Затем эти словосочетания используют на страницах веб ресурса. Поисковые системы оценивают качество и полезность контента, и если информация соответствует, ресурс продвигается в поисковой выдаче. В этом обзоре рассмотрена классификация фраз по частотности, а также указаны основные преимущества каждого вида ключа.
Термин
Частотность запросов – это параметр, который показывает, сколько раз пользователи интересовались конкретной фразой или словосочетанием за определенный период. Эта информация важна для SEO-специалистов. На основе данных выбираются запросы, релевантные тематике сайта и составляется семантическое ядро. Используя эту информацию, можно оптимизировать контент, настраивать контекстную рекламу для продвижения ресурса.
Виды запросов
Поисковые запросы по частотности подразделяются на несколько видов. Рассмотрим эту информацию подробнее.
1. Высокочастотные
Это популярные словосочетания, запрашиваемые большим количеством пользователей за определенный период. ВЧ-запросы обычно состоят из комбинации двух слов и соответствуют определенной тематике. Количество показов для таких фраз составляет 10 000 – 20 000 в месяц.
Специфика такая: пользователи ищут различную информацию, не всегда уточняя запрос. По ВЧ-запросам в поисковой выдаче высокая конкуренция.
Высокочастотные запросы содержат обобщенную информацию, поэтому важно учитывать, что из большинства пользователей только некоторые заинтересованы в покупке товаров, заказе услуг. Также применение фраз из высокочастотных запросов отлично подходит для имиджевой рекламы компании.
Продвижение подходит сайтам, которые существуют несколько лет, имеют стабильную прибыль, но хотят продвигаться выше в позициях выдачи. Выполняя SEO-оптимизацию ресурса, высокочастотные ключи следует размещать на главной странице и в основных разделах сайта, грамотно распределяя по тексту.
2. Среднечастотные
Эти запросы состоят из основного и нескольких дополнительных слов. Частотность для этого типа составляет от 1000 до 10 000 обращений в месяц. Они отличаются конкретностью. Обычно такие словосочетания используют пользователи, которые знакомы с тематикой.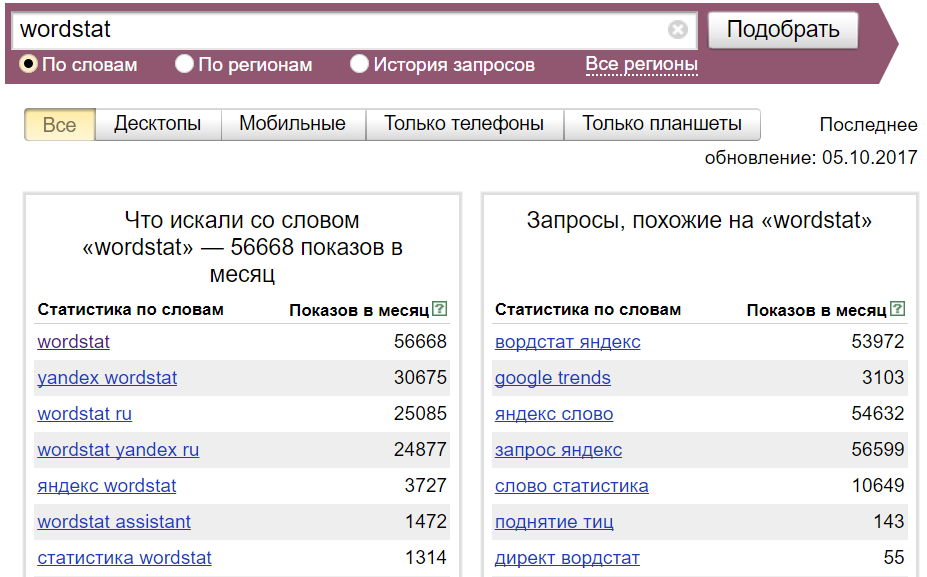
Среднечастотные запросы – отличный источник целевого трафика на сайт, большинству посетителей ресурса интересен конкретный продукт или услуга. Среднечастотные ключевые слова можно размещать на внутренних страницах сайта, в разделах каталога, подзаголовках текстов.
Продвижение по среднечастотным фразам выгоднее по стоимости, если сравнивать с высокочастотной оптимизацией. СЧ-запросы идеально подойдут для продвижения информационных ресурсов и интернет-магазинов. Грамотное распределение бюджета позволит увеличить рейтинг в поисковой выдаче, оптимизировать продажи интернет-магазина, посещаемость информационного сайта.
3. Низкочастотные
Это поисковые фразы, которые состоят из пяти или более слов. Количество показов составляет от 100 до 1000 в месяц. Такие словосочетания не пользуются значительной популярностью. По этим запросам можно быстро продвинуть сайт в ТОП 10 поисковых систем.
Запросы отличаются высокой точностью – пользователи хорошо знают, какая требуется информация. Низкочастотные запросы обладают высокой конверсией.
Низкочастотные запросы обладают высокой конверсией.
Продвижение сайта по НЧ-запросам оптимально для компаний с небольшим бюджетом, у которых основная задача – получить дополнительных покупателей и повысить количество продаж. Ключевые слова можно разместить в карточках товаров, блоге и дополнительных страницах. Целевой трафик на сайт небольшой, в основном состоит из заинтересованной целевой аудитории.
4. Нулевые
Это редкие комбинации слов, которые набирают пользователи в поисковых системах. Количество показов для такого вида не превышает 10 в месяц. Такие запросы состоят из семи и более слов.
Трафик по этим фразам отсутствует, продвижение сайта для этого класса применяют очень редко. Но информацию из словосочетаний можно использовать для составления семантического ядра портала. Также эти данные позволяют дополнительно узнать, что интересует пользователей.
Дополнительные параметры
Для продвижения ресурса SEO-специалисту нужно учитывать частотность, также важна тематика сайта и особенности компании.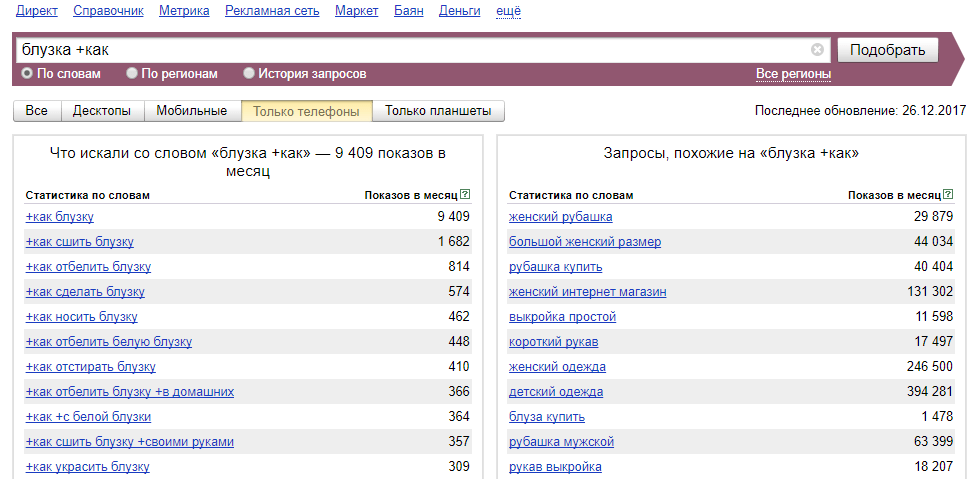 Для каждого направления деятельности параметры частотности могут отличаться. Для компаний с редкой специализацией бизнеса 100 показов в месяц – это уже высокочастотный запрос.
Для каждого направления деятельности параметры частотности могут отличаться. Для компаний с редкой специализацией бизнеса 100 показов в месяц – это уже высокочастотный запрос.
Для популярных тематик аналогичные показатели составляют от 100 000 и выше. Для продвижения сайта важен бюджет: лучший вариант – это комбинация, состоящая из среднечастотных и низкочастотных запросов. Такой вариант оптимален по стоимости, позволяет повысить ресурс в поисковой выдаче. Проверку частотности ключей рекомендуем проверять через систему Яндекс wordstat.
Итоговая информация
От SEO-оптимизации зависит популярность сайта, количество целевого трафика и уровень продаж. Все запросы пользователей по частотности подразделяются на три основных вида. Релевантные данные объединяют в семантическое ядро.
Грамотный выбор ключевых фраз, использование на страницах сайта важно для высоких позиций ресурса в поисковой выдаче.
Стоимость продвижения зависит от тематики и частотности – для оптимизации по высокочастотным запросам нужен значительный бюджет, среднечастотные и низкочастотные варианты доступны по стоимости для большинства компаний, не требуют значительных финансовых затрат.
Похожие статьи
SEO-продвижение лендинга
Как бороться с негативной накруткой поведенческих факторов
Зачем нужна пагинация на страницах сайта?
Стратегия интернет-маркетинга: эффективное продвижение бизнеса
Виды частотностей поисковых запросов или почему позиция по однословнику не гарантирует получение трафика
У нас иногда спрашивают:
«Почему мой сайт в ТОПе по такому на первый взгляд «жирному» запросу как «металлоконструкции», но трафика на сайт с этого ключевика совсем мало. Какие-то 50-100 человек в месяц! Но ведь частотность у этого запроса огромная, аж 250 тысяч в месяц! Почему такое происходит?»
И правда, если вбить в wordstat.yandex.ru такой запрос, то частотность он нам покажет довольно внушительную:
При такой частотности позиция даже на 10 месте в выдаче должна приносить много трафика, но на деле все происходит совершенно иначе.
Регион
Первое, про что все часто забывают, – это выбор региона при съеме частотности. Ни один коммерческий сайт не может продвигаться сразу по всем регионам, если он, конечно, не имеет офисы в каждом из них. Поэтому частотность снимается именно по тому региону, где находится офис компании. Если регионов несколько – отмечаем их все.
Например, компания, которая специализируется на поставках металлоконструкций и металлопроката, имеет офис в Москве, который добавлен в Яндекс.Справочник. Таким образом, ни по каким другим регионам данный сайт ранжироваться не будет, поэтому и ориентироваться надо в первую очередь на посетителей из Москвы. Значит, в wordstat нужно выставить соответствующий регион: Москва.Ключевой момент – наличие организации в Яндекс.Справочнике, так как именно по нему происходит привязка региона сайту.
Иногда клиенты нам говорят:
«Я хочу продвигаться по всей России, мой интернет-магазин доставляет товар в любой регион».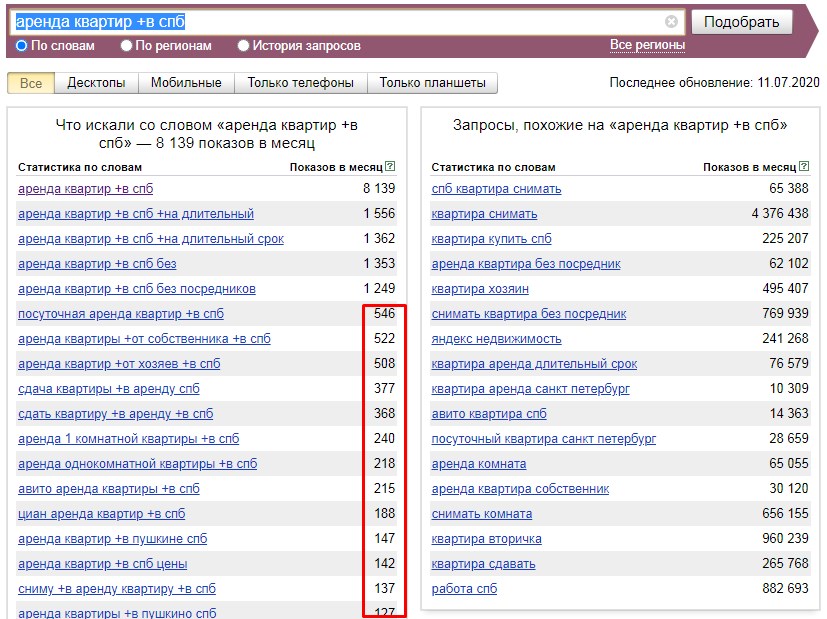
И здесь мы вынуждены их разочаровать: к сожалению, даже внутри России интернет-магазин не может ранжироваться, если у него нет филиалов в соответствующих регионах. Под филиалами подразумевается привязанная в Яндекс.Справочнике карточка организации с подтвержденным офисом в регионе.Таким образом, при оценке спроса всегда нужно строго определять региональность.
Виды частотности
После выбора региона сразу видно, что частотность значительно уменьшилась.
Однако все равно это не реальные цифры конкретных фраз и, чтобы точно определить частотность каждого ключевика, нужно использовать специальный синтаксис.
Базовая частотность
Пока что мы собрали так называемую «Базовую частотность». Такой частотностью называют ту, которую мы получаем при вводе запроса в wordstat без какого-либо синтаксиса, выбрав регион или нет. Такая частотность представляет собой сумму частотностей всех фраз, где встречаются слова из запроса в любых словоформах и в любом порядке.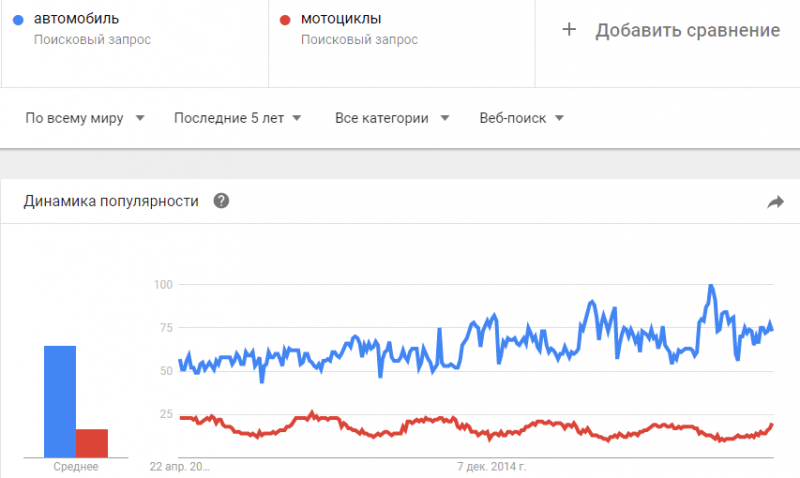 Например, в нашем случае запрос «Металлоконструкции» без указания региона имел частотность около 250 тыс. в месяц по всему миру и 33 тыс по Москве. В эту частотность вошли все фразы, которые содержат слово «металлоконструкции». Причем слово может иметь разные окончания, то есть сюда войдут фразы: «завод металлоконструкций», «сварные металлоконструкции», «купить металлоконструкции недорого» и т.п.
Например, в нашем случае запрос «Металлоконструкции» без указания региона имел частотность около 250 тыс. в месяц по всему миру и 33 тыс по Москве. В эту частотность вошли все фразы, которые содержат слово «металлоконструкции». Причем слово может иметь разные окончания, то есть сюда войдут фразы: «завод металлоконструкций», «сварные металлоконструкции», «купить металлоконструкции недорого» и т.п.
Частотность в кавычках
Если мы хотим узнать частотность поискового запроса более точно, например, отсечь из нее те запросы, где присутствуют другие слова, то нужно брать запрос в кавычки. Иными словами, если вбить в wordstat запрос в таком виде – “металлоконструкции” – то получим следующую цифру:
Теперь мы видим, что отдельно слово «металлоконструкции» по Москве запрашивают в Яндексе только 948 человек. Однако сюда все равно еще подмешиваются словоформы, например, «металлоконструкций» «металлоконструкция».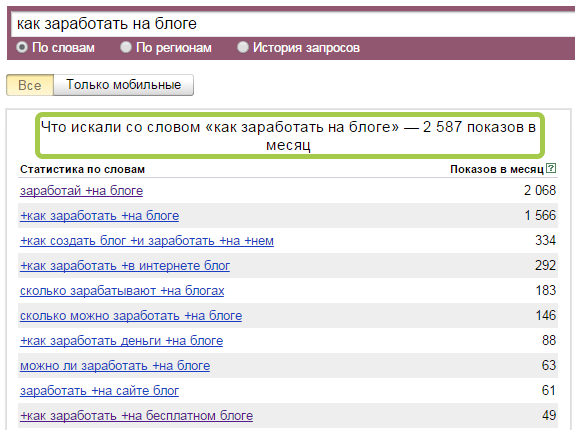 Чтобы их убрать, воспользуемся следующим видом частотности.
Чтобы их убрать, воспользуемся следующим видом частотности.
Частотность в кавычках и с восклицательным знаком (точная частотность)
Если задать запрос в wordstat в таком виде – “!металлоконструкции” – мы получим самую точную частотность. То есть будет отображаться частотность данного слова именно в таком виде, как мы написали:
В многословных запросах восклицательный знак нужно ставить перед каждым словом, так как данный оператор фиксирует словоформу каждого слова запроса по отдельности.
Таким образом, видна существенная разница в финальной частотности однословного запроса «металлоконструкции» по сравнению с изначальной базовой.
Точная частотность с учетом порядка слов
Однако, если мы подобным образом будем оценивать запрос, состоящий из двух слов, например, «купить металлоконструкции», то нужно еще учитывать порядок слов.
Так, например, если мы проверим точную частотность запросов: “!купить !металлоконструкции” и “!металлоконструкции !купить”, то обнаружим, что странным образом частотность у них будет одинаковая:
Это происходит по той причине, что операторы «кавычки» и «восклицательный знак» не учитывают порядок слов. Чтобы собрать точную частотность фразы «купить металлоконструкции» с учетом порядка слов, нужно использовать оператор «скобки» и вводить фразу следующим образом: “[!купить !металлоконструкции]”:
Чтобы собрать точную частотность фразы «купить металлоконструкции» с учетом порядка слов, нужно использовать оператор «скобки» и вводить фразу следующим образом: “[!купить !металлоконструкции]”:
Таким образом, мы видим, что «купить металлоконструкции» ищут чаще, чем «металлоконструкции купить».
В результате мы разобрались, что основным фактором в оценке спроса по ключевым запросам, который обязательно нужно учитывать, является правильный съем частотности для семантического ядра. В качестве примера мы сравнили базовую и точную частотность для первых трех десятков фраз, которые выдает wordstat по запросу «металлоконструкции». В приведенной таблице в колонке «Показов в месяц» указана базовая частотность, которую выдал Яндекс без учета региона. В колонке «Реальная частотность» указана уже точная частотность по региону Москва и снятая с использованием операторов «кавычки», «восклицательный знак» и «квадратные скобки».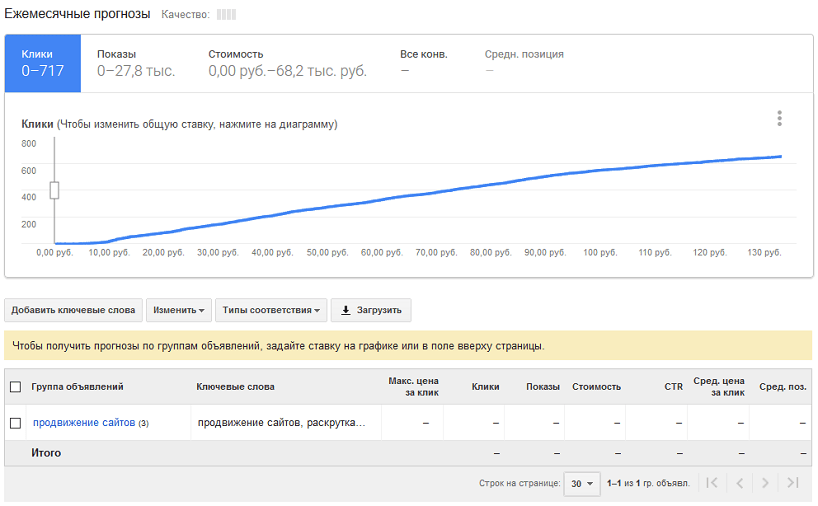
Как видно, точная частотность значительно меньше базовой. Если исходить из такой методики оценки спроса, то картина, при которой позиция в ТОП-10 Яндекса по ключевой фразе «металлоконструкции», имеющей частотность 839, приносит 50-100 посетителей, уже выглядит более реальной.
Распределение кликабельности на первой странице выдачи
Но можно справедливо возразить:
Неужели при позиции в ТОП-10 с ключевика частотностью 839 будет всего лишь 50-100 посещений?
В общем-то да!
По разным оценкам распределение CTR в органической выдаче в ТОП-10 примерно такое:
- ТОП-1: 15-35%
- ТОП-2: 10-25%
- ТОП-3: 7-20%
- ТОП-4: 5-15%
- ТОП-5 – ТОП-10: 3-12%
Подсчеты, конечно, очень обобщенные, но примерно отражают актуальную картину: 3 или даже 4 блока контекстной рекламы забирают больше половины всего CTR. Далее могут идти сервисы Яндекса: маркет, картинки, карты, что делает кликабельность на обычные сайты еще меньше.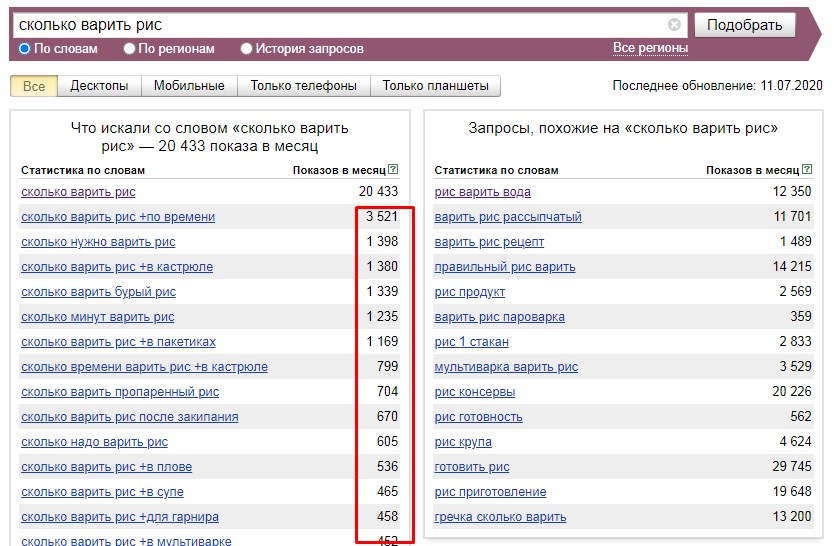 Учитывая еще то, что позиция в Яндексе редко у какого сайта бывает стабильной в ТОП-10 вследствие работы так называемого алгоритма «бандита», можно смело заключить, что вышеприведенные цифры по количеству трафика являются нормальными.
Учитывая еще то, что позиция в Яндексе редко у какого сайта бывает стабильной в ТОП-10 вследствие работы так называемого алгоритма «бандита», можно смело заключить, что вышеприведенные цифры по количеству трафика являются нормальными.
Оценка CTR через Яндекс.Директ
Наши слова легко проверить – достаточно зайти в Яндекс.Директ в прогноз бюджета и посмотреть там прогнозируемый CTR в зависимости от позиции в блоках контекстной рекламы на поиске. Яндекс обычно слишком занижает показатели кликабельности в своих прогнозах, но это еще раз показывает, что даже высокая позиция по какому-либо запросу не гарантирует большого количества посетителей.
Заключение
В заключении подытожим, что для правильной оценки спроса и составления на ее основе стратегии поискового продвижения сайта важно собирать максимально полное семантическое ядро и правильно снимать частотность у всех фраз, а также задавать регион. Абсолютно неправильно «зацикливаться» на отдельных и предположительно самых «жирных» поисковых фразах и полагать, что, продвинувшись по ним в ТОП-10, сайт станет лидером тематики. Лидерство сайта в поисковом продвижении определяется исключительно совокупной видимостью сайта по определенному семантическому ядру, то есть многочисленному списку поисковых запросов различной частотности и длины.
Абсолютно неправильно «зацикливаться» на отдельных и предположительно самых «жирных» поисковых фразах и полагать, что, продвинувшись по ним в ТОП-10, сайт станет лидером тематики. Лидерство сайта в поисковом продвижении определяется исключительно совокупной видимостью сайта по определенному семантическому ядру, то есть многочисленному списку поисковых запросов различной частотности и длины.
Хотите увеличить продажи с вашего сайта?
За 3 дня составим набор точечных рекомендаций по вашему сайту, как за 1 месяц сделать рост на 30-50%
Адрес вашего сайта
Номер вашего телефона
Нажимая на кнопку, вы даете согласие на обработку ваших персональных данных, согласно политике конфиденциальности
Cadence #1 28.01: Утечка данных Яндекса
Январь 2023 года был интересным месяцем для Яндекса, в котором произошла крупная утечка данных.
Подробнее об этом можно прочитать здесь.
В документе из 1922 факторов 244 были отнесены к категории «неиспользованных» и исключены из рассмотрения.
Исходное имя фактора ранжирования, описание и другая идентифицирующая информация, кроме его номера в документе, были удалены.
988 факторов ранжирования также указаны как устаревшие, а это означает, что 64% документа либо не используются активно, либо были заменены — так что это больше похоже на ~690 потенциальных факторов ранжирования, и многие из них содержат тонкие описания.
Возраст некоторых из этих факторов также вызывает сомнения, поскольку некоторые из авторов/лица, ответственные за определенные факторы, похоже, покинули Яндекс более десяти лет назад.
Например, автор DenPlusPlus некоторое время не был в Яндексе и прокомментировал утечку, подчеркнув, что в утечке нет «центральных папок». Так что в лучшем случае у нас есть небольшое окно в настоящее и прошлое внутренней работы Яндекса, но определенно не все факторы или алгоритмы ранжирования.
DenPlusPlus комментирует утечку. PageRank Просочившийся файл подтверждает, что Яндекс использует форму PageRank в качестве фактора ранжирования, и, учитывая, как работают многие тактики «Google», можно предположить, что Яндекс PageRank работает так же, как Google PageRank.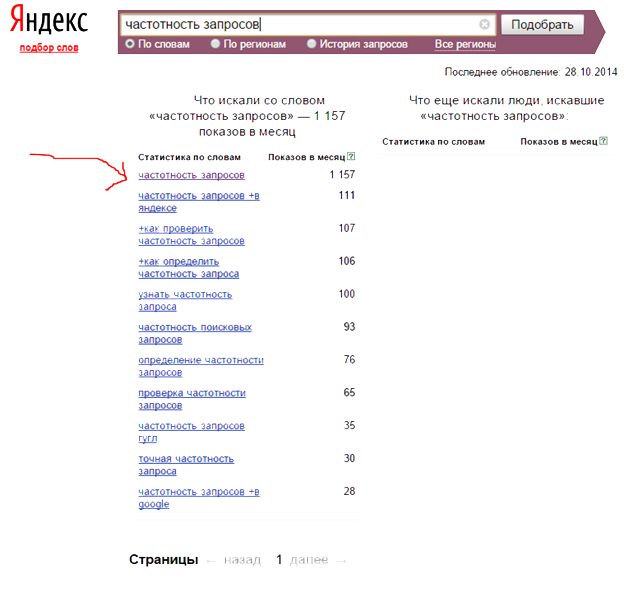
Также стоит отметить, что PageRank является первым в списке фактором ранжирования.
ПессимизацияЭто то, на что обращают внимание многие люди. Наша интерпретация заключается в том, что когда веб-сайт наказывается (пессимизируется), его PageRank снижается до нуля.
Это соответствует давней теории о том, что когда вы получаете штраф в Яндексе, восстановить его намного сложнее.
Клики и CTR как фактор (пользовательские сигналы)Давно известно, что манипулирование кликами работает в Яндексе. Теперь с просочившимися факторами ранжирования у нас есть дополнительные подтверждения.
Есть также упоминания о жестких кликах, мягких кликах, быстрых возвратах и трафике на веб-сайты из определенных источников.
Общая производительность сайта влияет на отдельные запросы Средняя производительность URL-адреса (и хоста) является фактором ранжирования, включая количество запросов URL-адреса (и хоста).
Помимо конкретных факторов ранжирования, ориентированных на URL, компонент URL помечен более чем 130 факторами ранжирования. Некоторые выводы верхнего уровня:
Минусы
- Слишком много косых черт в конце воспринимаются как минус
- Использование чисел в URL может рассматриваться как минус
Положительные
- URL-адрес содержит соответствующую страну или город (идентификатор GEO) для пользователя
- URL-адрес содержит запрос или семантическое отношение к запросу
не колеблется ни в положительную, ни в отрицательную сторону. Например, один описанный фактор — это деление длины URL-адреса на 5.
Другой говорит о длине запроса (запроса) и длине URL-адреса, но следует из аналогичного фактора, который говорит о URL-адресах YouTube и, в частности, использует расстояние Левенштейна.
Расстояние Левенштейна — это строковая метрика для измерения разницы между двумя последовательностями.Неформально расстояние Левенштейна между двумя словами — это минимальное количество односимвольных правок (то есть вставок, удалений или замен), необходимых для замены одного слова другим.
 Неформально расстояние Левенштейна между двумя словами — это минимальное количество односимвольных правок (то есть вставок, удалений или замен), необходимых для замены одного слова другим.
Неформально расстояние Левенштейна между двумя словами — это минимальное количество односимвольных правок (то есть вставок, удалений или замен), необходимых для замены одного слова другим. Оба фактора помечены как часть одного и того же «поискового билета», поэтому можно предположить, что оба используют метрику расстояния Левенштейна, но в описаниях она не заявлена.
Таким образом, упрощенный вывод здесь будет состоять в том, чтобы сделать URL-адреса простыми и максимально сфокусированными на поисковом запросе.
Прогнозирование количества продуктов на страницеЯндекс использует DSSM, просматривая URL-адрес и заголовок страницы, чтобы определить, есть ли на веб-странице один продукт или несколько продуктов, перечисленных на ней.
- Предсказание вероятности DSSM с использованием URL-адреса документа и заголовка, чтобы определить, что на странице есть только один продукт.
- Прогноз вероятности DSSM с использованием URL-адреса документа и заголовка, чтобы определить, что на странице, вероятно, много продуктов.

Это особенно важно, если вы определили, что несколько продуктов (например, типичная страница категории электронной коммерции) более подходят и являются более ценным предложением для обслуживания пользователей, чем одна страница продукта.
Яндекс имеет показатели качества страницыСуществует 7 факторов ранжирования, в которых упоминается качество страницы, и хотя два из них ускользают от экспериментов с качеством страницы, два дают дополнительную информацию:
- DSSM прогнозирует показатель качества страницы для документа
- Качество страницы, агрегированное хостом (средний балл)
Интересно, что хост играет роль в восприятии качества страницы (при условии, что дешевые хосты получают дешевые веб-сайты со спамом?).
Другие факторы ранжирования в документе также показывают, какую роль играет хост…
YMYL Exists/Existed Всего 15 факторов, связанных с медицинскими, финансовыми и юридическими темами.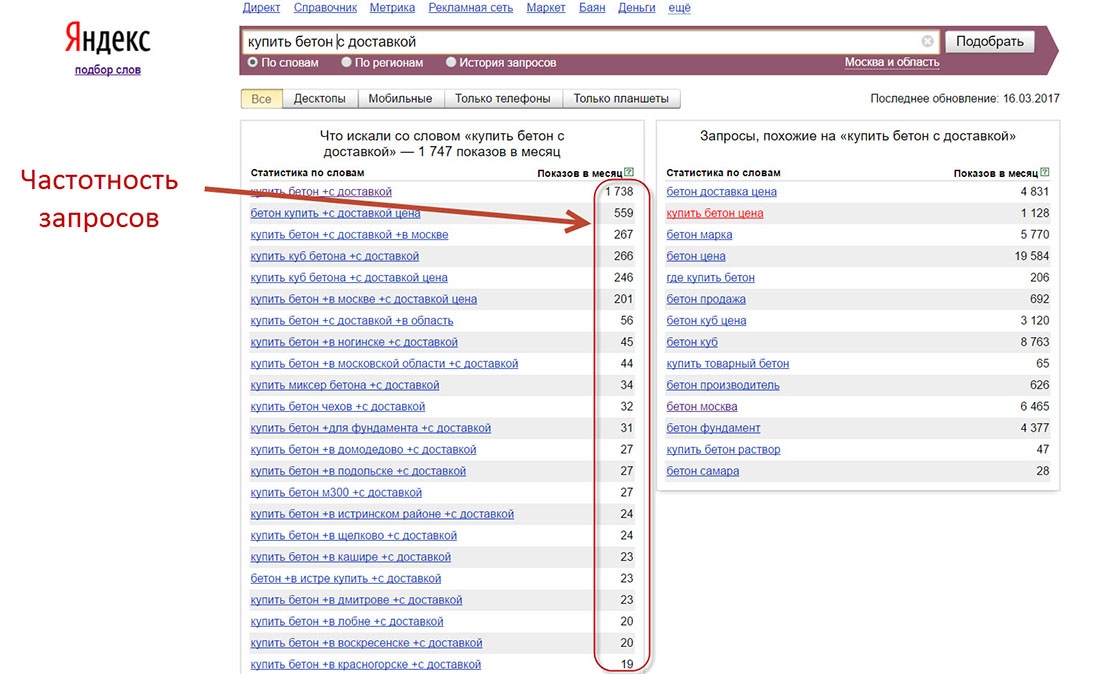
Есть факторы, которые упоминают трафик и ссылки из TikTok. Не на 100% ясно, реализованы ли они.
Надежность хостаКоличество URL-адресов в домене, которые отвечают с ошибками (предположительно 5XX и 4XX), является показателем качества.
Данные Метрики влияют на ранжированиеУтечка факторов ранжирования показывает, что данные Яндекс Метрики влияют на ранжирование.
Многие описания просто ссылаются на аналогичный механизм, похожий на YabarUrlVisits. У этого есть собственный фактор ранжирования, который описывается как объем трафика, поступающего с Yabar (i bar) 9.0003
И затем через другие индивидуальные факторы ранжирования мы знаем факторы Метрики, влияющие на ранжирование. Это:
- Количество посещений отдельных URL-адресов
- Количество посещений отдельных URL-адресов
- Среднее время, проведенное пользователями на отдельных URL-адресах
- Данные об аудитории (основная аудитория) посетителей веб-страниц со счетчиком Metrika
- Среднее время, которое пользователь проводит на хосте при доступе извне (с другого сайта, не связанного с поиском) с определенного URL-адреса
- Средняя «глубина» (количество обращений внутри хоста) пребывания пользователя на хосте при доступе извне (с другого непоискового сайта) с определенного URL
Это также указывает на то, что Яндекс Директ (например, Яндекс КПП/ Платный поиск Яндекса) влияет и может влиять на эффективность органического поиска.
Ходят слухи, что этот тип манипуляции некоторое время работал/работал анекдотически, когда некоторые веб-мастера Рунета настраивали учетные записи Метрики и искусственный трафик, что коррелировало с улучшением рейтинга.
Возраст ссылокУтечка показала, что возраст обратных ссылок влияет на то, как они, ссылки, влияют на общий поисковый рейтинг.
Факторы релевантности запроса в тексте и заголовкахУтечка факторов ранжирования также дает нам хорошее представление о том, как обрабатывается наличие запроса в тексте и заголовках документа.
- Ключевые слова в тексте и заголовках.
- Встречаемость ключевых слов в предложениях.
- Вхождение ключевых слов в абзацы.
Также стоит отметить, что также упоминается IDF (Inverse Document Frequency).
Мета-ключевые слова также были повторно подтверждены.
Алгоритм BM25, используемый для анализа текста 33 различных фактора ранжирования используют алгоритм BM25 для анализа текста.
Приведенное ниже объяснение BM25 было взято из Википедии:
В информационном поиске Okapi BM25 (BM — сокращение от наилучшего соответствия) — это функция ранжирования, используемая поисковыми системами для оценки релевантности документов заданному поисковому запросу. . Он основан на модели вероятностного поиска, разработанной в XIX веке.70-е и 1980-е годы Стивена Э. Робертсона, Карен Спэрк Джонс и других.
Имя фактической функции ранжирования — BM25. Более полное название, Okapi BM25, включает в себя название первой системы, которая его использовала, — информационно-поисковой системы Okapi, внедренной в Лондонском городском университете в 1980-х и 1990-х годах. BM25 и его более новые варианты, например. BM25F (версия BM25, которая может учитывать структуру документа и текст привязки) представляет функции поиска, подобные TF-IDF, используемые при поиске документов.
Наличие рекламы Яндекса и рекламы в целом Наличие рекламы Яндекса и рекламы в целом — это два отдельных фактора ранжирования.
Ничто в описании не дает мнения о том, хорошо это или плохо наличие общей рекламы или рекламы Яндекса, только то, что это как-то имеет значение.
Яндекс также активно проверяет, содержит ли веб-страница рекламу для взрослых.
Время суток/день недели ВлияниеСуществует около 10 перечисленных факторов, которые указывают на то, что время суток и день недели влияют на ранжирование.
Это имеет смысл.
Если вы ищете [рестораны рядом со мной] в 10:00, имеет смысл предоставить вам локализованные результаты и результаты на карте, которые открыты/откроются в ближайшее время на обед, а также подборку обзорных статей на обед и, возможно, некоторые на ужин.
Если вы выполните тот же поиск в 16:00, результаты, связанные с обедом, перестанут быть такими релевантными, поэтому рестораны на карте и локализованные результаты в поисковой выдаче будут лучше обслуживать пользователей, если они связаны с ужином.
Идентификаторы для определенных веб-сайтов Существуют идентификаторы для определенных веб-сайтов, например. Википедия и Вконтакте. Таким образом, эти веб-сайты рассматриваются как собственные типы источников в результатах поиска и почти имеют свой собственный набор правил (до определенного момента).
Википедия и Вконтакте. Таким образом, эти веб-сайты рассматриваются как собственные типы источников в результатах поиска и почти имеют свой собственный набор правил (до определенного момента).
Об обновлениях групп таблиц Supermetrics
Для переноса данных в хранилище данных Supermetrics и места назначения облачного хранилища можно настроить операции обновления с использованием запланированных обновлений или исторической обратной засыпки. Комбинируйте их с различными типами обновлений, чтобы найти правильный тип и частоту обновления для ваших данных.
Узнайте больше об операциях обновления и типах обновлений ниже. Мы включили обзорную таблицу, которая обобщает каждый вариант.
Операции обновления
Обновление по расписанию
При настройке передачи можно указать, когда и как часто ее результаты должны обновляться с помощью операции обновления по расписанию.
При настройке этой операции вы определите окно обновления для каждого запроса. Окно обновления определяет, сколько дней данные будут обновляться при каждом обновлении данных. Например, окно обновления, равное 7, гарантирует, что каждый раз при выполнении переноса данные за последние 7 дней, включая сегодняшние, будут заменяться отдельно.
Историческая обратная засыпка
Историческая обратная засыпка позволяет переносить данные за определенный период в прошлом. Как только вы укажете диапазон дат, Supermetrics будет извлекать эти данные из источника по одному дню.
Максимальный исторический диапазон заполнения запроса определяется следующим:
- Ваша лицензия Supermetrics
- Политики хранения данных источника данных
- Это также может применяться к политикам хранения для определенных полей. Например, некоторые источники данных ограничивают срок хранения полей демографических данных.
- Это также может применяться к политикам хранения для определенных полей.
 Например, некоторые источники данных ограничивают срок хранения полей демографических данных.
Например, некоторые источники данных ограничивают срок хранения полей демографических данных.Типы обновлений
Последовательные обновления
Операции обновления Supermetrics по умолчанию будут выполнять последовательные обновления, если в запрос включен параметр «Дата». Это происходит потому, что большинство источников данных, к которым он подключается, предоставляют данные, которые можно секционировать по дате (иногда называемые «данными временных рядов»).
Последовательные обновления предоставляют диапазон дат выполнения, начиная с даты начала и заканчивая датой окончания, в очередь обработки. Данные обрабатываются в обратном хронологическом порядке, по одному дню за раз, при этом каждый день рассматривается отдельно. Это относится как к запланированным обновлениям, так и к историческим обратным засыпкам.
Различные места назначения обрабатывают этот тип обновления следующим образом:
- BigQuery : Данные за один день хранятся в виде отдельных осколков таблицы. Операции обновления перезаписывают сегмент с датами, исключая возможность появления дубликатов в наборе данных.
- Места назначения хранилища данных : Запросы с последовательными обновлениями будут хранить данные в той же таблице. Supermetrics выполнит операцию DELETE и COPY INTO на основе даты, связанной с обновляемыми данными.
- Облачное хранилище (включая SFTP): Данные за каждый день хранятся в отдельном файле. Операции обновления заменят файлы в папке назначения новыми данными из Supermetrics.
 Операции обновления перезаписывают сегмент с датами, исключая возможность появления дубликатов в наборе данных.
Операции обновления перезаписывают сегмент с датами, исключая возможность появления дубликатов в наборе данных.Однодневные обновления моментальных снимков
Однодневные обновления моментальных снимков захватывают данные из источника данных в определенный момент времени.
Они полезны, когда:
- Тип API или отчета не содержит исторических данных. Это распространено в органических социальных API при отслеживании таких показателей, как количество подписчиков или просмотры видео, которые не разбиты на ежедневные значения
 Это распространено в органических социальных API при отслеживании таких показателей, как количество подписчиков или просмотры видео, которые не разбиты на ежедневные значения
Это распространено в органических социальных API при отслеживании таких показателей, как количество подписчиков или просмотры видео, которые не разбиты на ежедневные значенияОднодневные обновления моментальных снимков заменяют все данные таблицы каждый день. Таблицы в местах назначения хранилища данных будут удаляться и создаваться заново с результатами запроса каждый день, а файлы в местах назначения облачного хранилища будут полностью перезаписаны.
Обновления моментальных снимков за один день происходят, когда в запросе отсутствует измерение «Дата», но включено «Сегодня». Для успешного выполнения обновлений моментальных снимков важно, чтобы окно обновления было установлено как минимум на 2, чтобы гарантировать, что по крайней мере одна из дат выполнения равна предыдущему дню.
Исторический моментальный снимок
Исторические моментальные снимки запрашивают данные о доступном сроке службы источника данных на основе базовых ограничений API. Узнайте больше об исторических ограничениях диапазона источников данных.
Узнайте больше об исторических ограничениях диапазона источников данных.
Исторические моментальные снимки полезны, когда:
- Вы хотите получить метрики жизненного цикла из заданного источника данных. Например, неагрегируемые показатели, такие как охват и частота, выигрывают от обновлений моментальных снимков.
- Данные из API не являются данными временного ряда. Это может произойти при извлечении данных из таких полей, как «Контакты», «Компании» или «Сделки», из источников управления взаимоотношениями с клиентами (CRM).
Когда «Дата выполнения» равна предыдущему дню, это инициирует обновление моментального снимка, добавляя диапазон дат начала и окончания к основному запросу. Датой начала будет максимально допустимый исторический предел, определенный базовым источником данных, а датой окончания — предыдущий день.
Исторические моментальные снимки можно получить, исключив из запроса как «Дата», так и «Сегодня». Этот тип обновления заменяет всю таблицу в вашем хранилище данных или весь файл в вашем озере данных каждый день. Исторические моментальные снимки несовместимы с засыпками. Для успешного выполнения обновлений исторических моментальных снимков важно, чтобы окно обновления было установлено как минимум на 2, чтобы гарантировать, что по крайней мере одна из дат выполнения равна предыдущему дню.
Скользящие исторические моментальные снимки
Скользящие исторические моментальные снимки разделяют результаты запроса исторических моментальных снимков по дням и сохраняют их каждый день для исторического использования.
Они полезны, когда:
- Вы хотите отслеживать, как совокупный показатель, такой как стоимость или показы, изменяется с течением времени в одной таблице.
- Вам удобно обрабатывать и хранить большие объемы данных.
- Объем данных, обработанных вашим запросом, достаточно мал, чтобы его можно было выполнить в одном запросе. В зависимости от количества данных, к которым у вас есть доступ, и детализации вашего запроса вы можете столкнуться с проблемами квоты или проблемами выполнения запроса из-за размера данных.

Прокручивающиеся исторические снимки можно создать, добавив в запрос поля «Дата» и «Сегодня». Результирующий запрос будет содержать максимально допустимый объем данных из источника данных, разделенных по дате, и будет добавлен к существующей таблице в хранилище данных. Для облачных хранилищ каждый день будет создаваться новый файл. В случаях, когда максимальный объем данных не указан источником данных, используется значение по умолчанию 730 дней.
Для успешного выполнения последовательных обновлений моментальных снимков важно, чтобы окно обновления было установлено как минимум на 2, чтобы гарантировать, что по крайней мере одна из дат выполнения совпадает с предыдущим днем.