
как правильно использовать и оптимизировать
18334 38
| How-to | – Читать 11 минут |
Прочитать позже
ЧЕК-ЛИСТ: ТЕХНИЧЕСКАЯ ЧАСТЬ — ССЫЛКИ
Инструкцию одобрил
Head of SEO в Ольшанский и Партнеры
Алексей Матвейчук
Страницы пагинации применяют, чтобы не перегружать одну страницу большим количеством контента, ускорить загрузку и улучшить юзабилити сайта. Разметка куаЕсли не оптимизировать такие страницы, на сайте будет формироваться большое количество частичных дублей, что ухудшит его позиции в SERP.
Обновление:
В данной статье указаны рекомендации о разметке, которые были актуальны на момент написания материала (ноябрь 2018 года). В марте 2019-го Google обновил свои алгоритмы и теперь не использует данные атрибуты. Rel=»next» и rel=»prev» больше не являются сигналами для поискового робота, советы по их применению удалены из официальной справки.
«Мы заметили, что уже несколько лет не используем rel next и rel prev в процессе индексации, поэтому решили, что можем также удалить эту документацию», — прокомментировал в Твиттере Senior Webmaster Trends Analyst в Google Джон Мюллер.
Теперь Google рекомендует вебмастерам по возможности размещать все позиции на одной странице, но уверяет, что проблемы с индексированием пагинации не возникнут.
«Используйте пагинацию. Googlebot достаточно умен, чтобы найти вашу следующую страницу, просматривая ссылки на странице. Нам не нужны явные сигналы «prev, next». И да, [у вас] есть и другие веские причины, чтобы по-прежнему добавлять их (например, доступность [сайта] для людей с ограниченными возможностями)», — добавил Web Performance Engineer Google Илья Григорик.
Указанные в статье рекомендации для Яндекса по-прежнему актуальны и проверены опытными SEO-специалистами.
Что такое пагинация в SEO?
Это порядковая нумерация страниц, которая зачастую применяется, чтобы разбить содержимое крупного каталога (товаров, статей, комментариев и пр. ) на несколько страниц.
) на несколько страниц.
Неправильная настройка пагинации может негативно сказаться на месте сайта в выдаче. Существуют следующие риски:
- дублирование существующего контента, которое ведет к санкциям от поисковиков;
- некорректно размеченные страницы пагинации в большинстве случаев не будут сканироваться роботами дальше первой или второй страницы. Как результат, они не будут попадать в индекс.
Рассмотрим основные способы оптимизации таких страниц для Google и Яндекса подробно, а также оценим различие между ними для SEO.
Google и страницы пагинации
Google предлагает несколько способов такой оптимизации, о чем сообщает официальная справка:
- Не вносить изменений.
- Установить кнопку для разворота остальных позиций «Показать еще» в связке со специальным атрибутом в коде «rel=»canonical»».
- Применить атрибуты, которые связывают веб-страницы между собой: «rel=»next»» и «rel=»prev»».


Мы рекомендуем
Вариант #1.
«rel=»next»» и «rel=»prev»» + «rel=»canonical»» на первую страницу пагинации. Если не оптимизировать текстовую составляющую страниц пагинации, робот будет сканировать все страницы (в том числе и карточки товара на страницах разбивки), но в индекс будет попадать только 1 страница.
Вариант #2.
«rel=»next»» и «rel=»prev»» + «rel=»canonical»» на саму себя. Например, для второй страницы:
<linkrel="canonical" href="http://site.com/canonical-link.html/?page=2">
Если провести текстовую оптимизацию основных SEO блоков — например, каждую страницу оптимизировать под определенный город — в индекс будут попадать все страницы пагинации. В качестве дополнительного плюса Ваш сайт может начать ранжироваться по новым ключам.
Мы не рекомендуем
Закрывать страницы пагинации от индексации любым известным для Вас способом (robots. txt, noindex, nofollow, через «Параметры URL»).
txt, noindex, nofollow, через «Параметры URL»).
Устанавливать кнопку для разворота остальных позиций «Показать еще» в связке со специальным атрибутом в коде «rel=»canonical»».
Пускать все на самотек.
Кнопка «Показать все» и атрибут rel=»canonical»
Значение «rel=»canonical»» показывает краулеру каноническую веб-страницу: в поиске будет одна основная страница, а все остальные будут считаться ее копиями, не участвуя в ранжировании. Взамен каноническая URL чаще сканируется поисковыми краулерами.
Этим атрибутом вы сообщаете, что все веб-страницы, отвечающие за пагинацию, доступны по единому URL, который и следует индексировать.
Схема внедрения атрибута «rel=»canonical»» выстраивается пошагово:
- создается общая страничка по всему кластеру товаров, например, все единицы из категории «Пальто»;
- добавляется кнопка «Показать все», «Смотреть все» или схожая по смыслу, которая добавляет поочередно товары;
- веб-страницу указывают канонической для поиска, прописав специальное значение «rel=»canonical»» в части head.

С технической стороны выходит, что мы создаем общую страничку для раздела пальто по адресу: http://example.com/palto/?&show-all, отмечая на других страницах канонику на общий URL:
rel="canonical" href="http://example.com/palto/?&show-all"
Теперь весь ассортимент товарных позиций, как в нашем образце, станет индексироваться посредством кнопки «Показать все».
Недостатков такого способа — несколько.
Большое количество товаров трудно свести на одной страничке. Так как она получит плохую скорость загрузки. Это вынуждает ограничиться в качестве изображений и объеме опубликованного контента. Возможно, этот факт повлияет на привлекательность сайта для пользователей, снизит поведенческие факторы и успех в ранжировании.
Если на веб-сайте присутствуют фильтры и сортировки, то образуется много динамических страниц, каждой из которых придется прописать канонический атрибут. Объем работы серьезный, потребуется много времени на реализацию.
Объем работы серьезный, потребуется много времени на реализацию.
На большинстве CMS метод применить невозможно вообще. Подобный подход больше применим для небольших по объему сайтов, желательно без динамических страниц.
В некоторых случаях перенаправление ставится на общую страницу, как описано выше, а иногда — на первую страницу пагинации. Google хочет видеть одну общую страницу с кнопкой «Развернуть товары», а Яндекс предпочитает видеть только первую страницу пагинации, на которую указывают остальные данным атрибутом.
Однако такое перенаправление именно на первую страницу не описано в Google, как рекомендуемое. Поэтому есть сомнения насчет того, насколько положительно этот подход сработает на ранжировании в Google.
Атрибуты «rel=»next»» и «rel=»prev»» в Google
Значения «rel=»next»» и «rel=»prev»» показывают поисковым ботам Google, что страницы связаны. То есть создается цепочка страниц, из которой робот понимает, что посетителя следует переслать на первую из них, например. Для внедрения указанных фрагментов применяются HTML-ссылки или HTTP-заголовки.
Для внедрения указанных фрагментов применяются HTML-ссылки или HTTP-заголовки.
Метод считается наиболее подходящим для использования в Google, поскольку поисковик самостоятельно будет определять более подходящую страницу из равных по приоритету. Обычно склоняясь к той, которая содержит наибольшее количество позиций, чтобы дать пользователю максимально широкий выбор.
- Минус этой манипуляции: Яндекс не понимает атрибуты: «rel=»next»» и «rel=»prev»», поэтому приходится ограничивать индексацию через мета-теги «noindex/nofollow».
- Плюс такого приема: хорошие позиции, которые сайту реально получить по низкочастотным запросам. Как правило, низкочастотные запросы могут привлекать трафик, который завершается конверсией в покупателей.
Иерархия веб-страниц такова:
http://example.com/category/
http://example.com/category/page-2
http://example.com/category/page-3
Обратите внимание, что адрес первой веб-страницы — именно http://example. com/category/, а не http://example.com/category/page-1. Это важно: новички допускают здесь ошибки. В результате создаются дубли, несколько URL ведут на одну и ту же страницу.
com/category/, а не http://example.com/category/page-1. Это важно: новички допускают здесь ошибки. В результате создаются дубли, несколько URL ведут на одну и ту же страницу.
Чтобы при возвращении со второй страницы на первую не возникал дубль по адресу http://example.com/category/page-1, из ссылок удаляют параметр «page-1», устанавливая с веб-страниц, содержащих этот параметр, перенаправление (301 редирект) на http://example.com/category/.
Учтите, что статический текст нужно убирать со всех нумерованных страниц, за исключением первой. Не допускайте, чтобы один и тот же текст размещался под разными URL-адресами. Это снизит уникальность, что негативно влияет на SEO продвижение.
Разбив страницы по нумерации, размещаем «link» в начальном разделе head с первой веб-страницы на вторую:
link rel="next" href="http://example.com/category/page-2/"
Затем на страничке «page-2» совершаем похожее действие только уже с указанием «page-3», не забывая прибавить теперь значение прошлой страницы:
link rel="prev" href="http://example.
 com/category/" (ссылка на первую веб-страницу, предыдущую по отношению к «page-2»)
link rel="next" href="http://example.com/category/page-3/" (ссылка на следующую по нумерации «page-3»)
com/category/" (ссылка на первую веб-страницу, предыдущую по отношению к «page-2»)
link rel="next" href="http://example.com/category/page-3/" (ссылка на следующую по нумерации «page-3»)По такому принципу далее прописываем ссылки. Первая страница включает значение атрибута «next», последняя должна завершаться атрибутом «prev».
Не закройте по неосторожности пронумерованные веб-страницы для всех поисковых краулеров: сделайте это только для Яндекса. При этом позвольте поисковым ботам проходить по ним через мета-тег «follow».
Важно выделить, что указывать канонику через «rel=»canonical»» вместо этих мета-тегов — не лучший выход, поскольку будет создан беспорядок среди разных атрибутов. В результате приоритетные для индексирования страницы могут вылететь из SERP.
Помните, что «rel=»next»» и «rel=»prev»» не воспринимаются роботами как директивы, они — скорее дополнительная помощь для Google. Значения атрибутов равны между собой.
Учтите, что если на веб-ресурсе присутствуют динамические параметры (образованные при сортировках или фильтрах), которые совсем не меняют содержимое контента — другими словами пассивные параметры, как идентификатор сеансов, — такие web-страницы обязательно должны содержать связку через «next» и «prev».
Ошибки при разметке страниц, например, отсутствие атрибутов, означают, что Google самостоятельно определит судьбу веб-страниц в индексе.
При этом Google допускает употребление атрибутов «rel=»next»» и «rel=»prev»» одновременно с «rel=»canonical»»:
Это дает пищу для размышления о новых способах оптимизации пагинации для корректного отображения в поиске.
Помните, что в карту веб-сайта «sitemap.xml» страницы пагинации не добавляют.
Яндекс и страницы пагинации
Яндекс совершенно иначе работает со страницами пагинации. Такие атрибуты как «rel=»next»» и «rel=»prev»» он абсолютно не понимает, но взамен включил поддержку атрибута «rel=»canonical»».
Благодаря канонической веб-странице Яндекс различает, какую страницу из всех предпочтительнее индексировать. Это помогает избежать дублирования контента, но в целом поисковый робот считает ссылку не строгой директивой, а всего лишь предлагаемым вариантом, что позволяет его игнорировать.
Основные причины, по которым возможно игнорирование, Яндекс перечисляет в справке:
Основная рекомендация Яндекса о том, как правильно обращаться со страницами нумерации, опубликована в советах Платона для интернет-магазинов по индексированию.
Стратегия выглядит так. Надо настроить канонику через «rel=»canonical»» тега «link» для первой страницы, а остальные нумерации оставить неканоническими. По словам Платона, такая схема постарается не допустить дублирование содержимого контента, поэтому стоит подстраховаться мета-тегами «noindex/follow».
Становится очевидно, что подходы у поисков существенно отличаются. Поэтому можно попробовать угодить всем поисковикам, насколько это реально: первую страницу делаем канонической, со второй и далее используем сочетание «rel=»next»» и «rel=»prev»» + закрытие через «noindex/follow» для Яндекса.
Так Яндекс получит свою заветную каноническую страницу и не будет получать дубли контента на последующих, а Google обретет вспомогательные атрибуты, которые помогут ему связать страницы.
Заключение
Страницы, отвечающие за пагинацию, помогают облегчить навигацию пользователя по сайту, разбивая нагрузку на ресурс.
При правильной настройке индексирования в Google и Яндекс это хорошо влияет на SEO оптимизацию. Неправильная настройка индексации пронумерованных страниц, способна:
- продублировать контент, а это — вероятность получить санкции от поисковых систем и понижение ранжирования;
- повлечь долгое индексирование, которое ухудшит SEO.
Но каждый поисковик имеет свое видение того, как он будет индексировать такие страницы. Это необходимо учитывать.
Варианты идеальной настройки пагинации для Google и Яндекса мы рассмотрели выше. Как и способ, который должен максимально удовлетворить обе поисковые системы и улучшить позиции сайта в выдаче.
Можно также провести SEO-аудит страницы.
» title = «Как SEO-оптимизировать страницы пагинации 16261788191704» />
«Список задач» — готовый to-do лист, который поможет вести учет
| Начать работу со «Списком задач» |
Сэкономьте время на изучении Serpstat
Хотите получить персональную демонстрацию сервиса, тестовый период или эффективные кейсы использования Serpstat?
Оставьте заявку и мы свяжемся с вами 😉
Оцените статью по 5-бальной шкале
3.64 из 5 на основе 11 оценок
Нашли ошибку? Выделите её и нажмите Ctrl + Enter, чтобы сообщить нам.
Рекомендуемые статьи
How-to
Denys Kondak
Как проверить и увеличить узнаваемость бренда в Google и Яндексе
How-to
Denys Kondak
Как настроить AMP на сайте
How-to
Denys Kondak
Как настроить обработку GET-параметров в Google и Яндекс
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе. Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.
Поделитесь статьей с вашими друзьями
Вы уверены?
Спасибо, мы сохранили ваши новые настройки рассылок.
Сообщить об ошибке
Отменить
что это за тег, его роль в пагинации и настройка канонических URL
Содержание статьи
- Что такое rel canonical?
- Что такое каноническая ссылка?
- Для чего нужен каноникал?
- Примеры использования
- Как каноникал используется для пагинации
- Атрибуты rel=»next» и rel=»prev»
- Тема с SEO пагинатором
- Настройка Canonical для WordPress
- Что еще полезно знать о каноникал?
Чтобы осуществлять правильное продвижение страниц сайта в поисковых системах, необходимо сообщать роботам, какие URL более предпочтительны для попадения в индекс. Это задаётся с помощью специальных тегов.
Что такое rel canonical?
Остановимся подробнее на теге rel=»canonical». Его основная цель — борьба с дублями страниц и неинформативными страницами (например страницами пагинации), а также повышение качества индексации с помощью прописывания приоритетного адреса.
У меня был сайт с ограниченным краулинговым бюджетом. То есть по факту там было тысяч 10 страниц, но в индексе могли быть только 2 тысячи (потому что сайт был молодой и не трастовый). В итоге те страницы, которые мне были нужны в индексе, часто туда не попадали. Помог каноникал — проставление со страниц пагинации каноникала на основные URL позволило четко дать поисковикам понять, какие страницы должны быть в индексе.
Что такое каноническая ссылка?
Тег canonical будет чрезвычайно полезен, если на вашем сайте есть страницы-дубли, которые имеются в доступе по различным адресам. С помощью него необходимо прописать приоритетный канонический URL для восприятия поисковиками.
Что важно — будет также передаваться ссылочный вес и прочие характеристики страницы (PageRank и др. ).
).
Этот атрибут указывается внутри тега <head> на URL-дубликатах с указанием предпочитаемого URL. Оформляется он таким образом:
Для чего нужен каноникал?
При наличии похожих страниц в индексации поисковиками участвуют все они одновременно. В итоге ни одна из них в полной мере не продвигается по причине того, что внутренние ссылки имеются на обе страницы. Поисковик не знает, какой из них нужно отдать приоритет.
А если бы все внутренние ссылки стояли на одну страницу, или если хотя бы у одной из них был проставлен каноникал на другую, это дало бы мощный плюс основному URL при продвижении.
То же самое касается и внешних ссылок — продвигается не один URL, а несколько, а вес также распределяется между ними. И сайт находится на более низких позициях, чем мог бы быть.
Благодаря каноникал в индексе поисковиков будет предпочитаемый канонический URL.
Примеры использования
Например, у вас на сайте есть печатная версия страницы. Или отдельный урл для мобильной версии. И вы ставите каноникал с них на основную страницу, в итоге эта основная страница получает больший вес и плюс при ранжировании, а из индекса убирается куча мусора.
Или отдельный урл для мобильной версии. И вы ставите каноникал с них на основную страницу, в итоге эта основная страница получает больший вес и плюс при ранжировании, а из индекса убирается куча мусора.
Как каноникал используется для пагинации
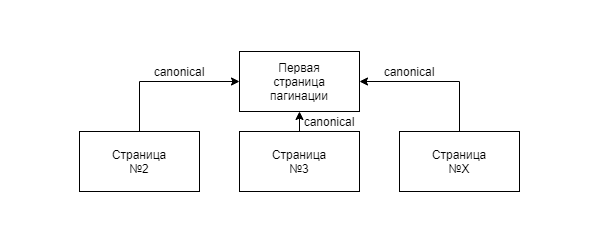
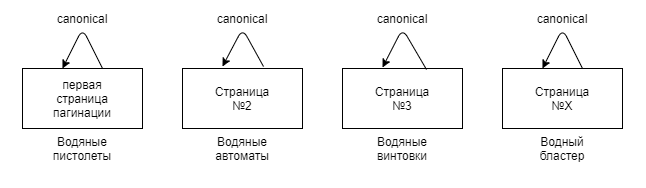
Нужно проставить rel canonical со страниц пагинации (site.ru/category/page/2) на первую из них (site.ru/category).
Мнения о настройке пагинации разнятся — некоторые специалисты говорят о необходимости закрытия от поисковиков всех страниц пагинации, другие — о том, что лучше их оставить в доступе роботов поисковых систем.
Яндекс рекомендует со всех страниц пагинации настраивать каноническую ссылку на первую из них. Как итог — яндекс-робот воспримет, что именно первую страницу необходимо индексировать. Про индексацию товаров уточняется, что по другим ссылкам Яндекс всё равно будет переходить.
Специалисты Google склоняются к следующим вариантам:
- оставить всё по-прежнему — поисковик по-разному распознаёт и воспринимает различные виды страниц;
- создать отдельный URL-адрес «Показать всё» и установить его как канонический — особенно рекомендуется для многостраничных статей;
- прописать в теге линк атрибуты rel=»prev» и rel=»next» с целью фиксации взаимосвязи между URL-адресами; поисковик будет выдавать первый из них.

А вот видос Деваки, где он подробно поясняет за пагинацию:
Атрибуты rel=»next» и rel=»prev»
Есть также и другое мнение — типа страницы пагинации закрывать не надо, что они наоборот должны получать дополнительный трафик. И тут важны два момента:
- Все URL должны иметь уникальный параметр тега Title, уникальный текст и meta-теги;
- Если Вы больше ориентируетесь на Google, то рекомендовано обязательное использование атрибутов rel=»next» и rel=»prev», которые нужно настроить так, чтобы каждая предыдущая страница ссылалась на следующую. На корневом адресе задаётся URL следующего, на последующих — URL предыдущей и следующей, на последней — только предыдущей.
Можно прописать пагинацию этими тегами, а каноническую ссылку оформить на первую или на главную страницу — в зависимости от особенностей ресурса.
Пример:
Тема с SEO пагинатором
Вот допустим один из блогов (Sawynih или как-то так, уже не помню) писал о кейсе, когда страницы пагинации давали дополнительный трафик.
Если на разных URL представлен похожий товар, навигацию можно задать следующими способами:
- Прописать уникальные значения параметров автоматически, собирая заголовки из отдельных частей, к примеру:
(купить|заказать|приобрести) юбки в (саратове|ростове|астрахани) (по низкой цене|выгодно|дешево) со скидкой (в магазине|в интернет магазине)
Будут созданы уникальные значения метатегов.
- Самым эффективным и трудоемким является самостоятельное прописывание этих параметров, вручную. Все заголовки будут уникальными и очень сильно отличаться друг от друга, в том числе по смыслу. Это позволит продвинуть каждый URL по низкочастотным и низко конкурентным ключевым запросам в ТОП выдачи поисковиков. Благодаря применению этого способа расширится семантическое ядро. Плюс также в том, что для интернет-магазина множество статей писать нецелесообразно.
 Плюс также в том, что для интернет-магазина множество статей писать нецелесообразно.
Плюс также в том, что для интернет-магазина множество статей писать нецелесообразно.Важно осуществить эту работу один раз индивидуально для каждого URL. Параметры будут зафиксированы поисковиками.
Настройка Canonical для WordPress
Многие плагины для WordPress прекрасно работают с данным тегом.
Большинство из них просты в применении — активируем плагин, а канонические ссылки прописываются автоматически. В других SEO-плагинах достаточно установить галочку возле этого параметра в настройках. Если какая-то статья относится одновременно к разным категориям, то каноническая ссылка фиксируется самостоятельно.
При использовании плагина Yoast SEO и расположения поста в разных категориях, поисковик будет видеть только одну страницу.
Что еще полезно знать о каноникал?
Важно подчеркнуть следующие моменты:
- Тег canonical — не директива, а подсказка, которую следует учесть и проанализировать, выделив наиболее подходящий URL для поисковой выдачи.
- Касаемо оформления канонических ссылок отсутствует запрещающий момент в виде относительного пути. Даже в случае введения тега <BASE> со ссылкой на документ, относительные пути станут восприниматься так, как прописано в базовом URL.
- Канонические страницы могут содержать не абсолютно одинаковое наполнение, и это логично. Могут присутствовать незначительные различия.
- Даже при наличии ошибки 404, контент будет индексироваться. Но рекомендуется указывать рабочие URL в качестве канонических.
- Если канонический url пока не проиндексирован, остаётся ждать — обычно недолго. Когда он распознается, подсказка будет пересмотрена.
- Можно использовать редирект — поисковик воспримет перенаправление и будет учитывать другой адрес.
- Рекомендуется задавать идентичный тег rel canonical, чтобы результат канонизации был оптимальным.
- Канонический урл может прописываться исключительно с текущего домена. Для указания урла с другого домена, следует использовать 301 редирект.
- Как оформляются канонические url, можно изучить на примере сайта wikia.com, открыв исходный код страницы http://starwars.wikia.com/wiki/Nelvana_Limited, содержащий canonical url http://starwars.wikia.com/wiki/Nelvana
Обе ссылки практически одинаковы, но в первой прописан атрибут каноникал — и Google будет отображать версию, заданную в этом параметре. - Вопросы применения каноникал можно задать в официальном блоге для вебмастеров поисковика Google.


В данном случае каноникал проставлен на чёрную овцу
Преимущества, связанные с умением правильно настраивать индексацию с помощью тега canonical:
- избавление от похожего контента, связанного с недостатками движка, а также созданного искусственно целенаправленными действиями конкурентов;
- отсутствие необходимости в применении robots.txt для запрета индексации отдельных страниц и угождения всем поисковикам.
Полное руководство по передовой практике Он используется в самых разных контекстах: от отображения элементов на страницах категорий до архивов статей, слайд-шоу галереи и тем форума.
Для специалистов по SEO это не вопрос , если вам придется иметь дело с нумерацией страниц, это вопрос , когда .
В определенный момент роста веб-сайтам необходимо разделить контент на ряд составных страниц для взаимодействия с пользователем (UX).
Наша работа заключается в том, чтобы помочь поисковым системам сканировать и понимать взаимосвязь между этими URL-адресами, чтобы они индексировали наиболее релевантную страницу.
С течением времени передовые методы SEO обработки разбиения на страницы эволюционировали. Попутно многие мифы преподносились как факты. Но не больше.
Эта статья будет:
- Развенчайте мифы о том, что нумерация страниц вредит поисковой оптимизации.
- Представьте оптимальный способ управления нумерацией страниц.
- Просмотрите неправильно понятые или некачественные методы обработки разбивки на страницы.
- Узнайте, как отслеживать влияние нумерации страниц на KPI.
Как нумерация страниц может повредить SEO
Вы, наверное, читали, что нумерация страниц вредна для SEO.
Однако в большинстве случаев это связано с отсутствием правильной обработки пагинации, а не с наличием самой пагинации.
Давайте посмотрим на предполагаемые недостатки нумерации страниц и на то, как преодолеть проблемы SEO, которые это может вызвать.
Разбиение на страницы приводит к дублированию содержимого
Исправьте, если разбиение на страницы было реализовано неправильно, например, у вас есть страница «Просмотреть все» и страницы с разбивкой на страницы без правильного rel=canonical или если вы создали страницу=1 в дополнение к своей корневой странице.
Неверно, если у вас оптимизированная для SEO нумерация страниц. Даже если ваши теги h2 и метатеги одинаковы, фактическое содержимое страницы отличается. Так что это не дублирование.
Да, все в порядке. Полезно получать отзывы о повторяющихся заголовках и описаниях, если вы случайно используете их на совершенно разных страницах, но для серий с разбивкой на страницы это нормально и ожидается, что вы будете использовать одно и то же.
— 🍌 John 🍌 (@JohnMu) 13 марта 2018 г.

Разбиение на страницы создает разреженный контент слишком мало контента на каждой странице.
Неверно, когда вы ставите желание пользователя легко потреблять ваш контент выше доходов от баннерной рекламы или искусственно завышенных просмотров страниц. Разместите на каждой странице UX-дружественный объем контента.
Пагинация ослабляет сигналы ранжирования
Верно. Пагинация приводит к тому, что внутренний вес ссылок и другие сигналы ранжирования, такие как обратные ссылки и социальные сети, распределяются между страницами.
Но может быть сведен к минимуму с помощью с использованием разбивки на страницы только в тех случаях, когда одностраничный подход к содержимому может привести к ухудшению взаимодействия с пользователем (например, страницы категорий электронной торговли). И на таких страницах, добавляя как можно больше элементов, не замедляя страницу до заметного уровня, чтобы уменьшить количество разбитых на страницы страниц.
Пагинация использует бюджет сканирования
Исправьте, если вы разрешаете Google сканировать страницы с разбивкой на страницы. И есть несколько случаев, когда вы хотели бы использовать этот бюджет.
Например, чтобы робот Googlebot перемещался по URL-адресам с разбивкой на страницы для доступа к страницам с более глубоким содержанием.
Часто неверно, когда вы устанавливаете для параметра обработки страницы Google Search Console значение «Не сканировать» или устанавливаете запрет в файле robots.txt, если вы хотите сохранить бюджет сканирования для более важных страниц.
Управление разбиением на страницы в соответствии с передовыми методами SEO
Используйте доступные для сканирования якорные ссылки
Чтобы поисковые системы могли эффективно сканировать страницы с разбивкой на страницы, сайт должен иметь якорные ссылки с атрибутами href на эти URL-адреса с разбивкой на страницы.
Убедитесь, что ваш сайт использует для внутренних ссылок на страницы с разбивкой на страницы. Не загружайте якорные ссылки с разбивкой на страницы или атрибут href через JavaScript.
Не загружайте якорные ссылки с разбивкой на страницы или атрибут href через JavaScript.
Кроме того, вы должны указать взаимосвязь между URL-адресами компонентов в разбивке на страницы с помощью атрибутов rel=»next» и rel=»prev».
Да, даже после печально известного твита Google о том, что они вообще больше не используют эти атрибуты ссылок.
Весенняя уборка!
Когда мы оценили наши сигналы индексации, мы решили отказаться от rel=prev/next.
Исследования показывают, что пользователям нравится одностраничный контент, стремитесь к нему, когда это возможно, но многостраничный контент также подходит для Google Поиска. Знайте и делайте то, что лучше для *ваших* пользователей! #весна идет pic.twitter.com/hCODPoKgKp— Веб-мастера Google (@googlewmc) 21 марта 2019 г.
Вскоре после этого Илья Григорик пояснил, что rel=»next» / «prev» все еще может быть ценным.
нет, использовать нумерацию страниц. позвольте мне переформулировать это. Googlebot достаточно умен, чтобы найти вашу следующую страницу, просматривая ссылки на странице, нам не нужен явный сигнал «предыдущая, следующая». и да, есть и другие веские причины (например, a11y), по которым вы можете или должны добавить их.
— Илья Григорик (@igrigorik) 22 марта 2019 г.
Google — не единственная поисковая система в городе. Вот мнение Бинга по этому вопросу.
Мы используем rel prev/next (как и большинство разметки) в качестве подсказок для обнаружения страниц и понимания структуры сайта. На данный момент мы не объединяем страницы в индексе на их основе и не используем предыдущее/следующее в модели ранжирования. https://t.co/ZwbSZkn3Jf
— Frédéric Dubut (@CoperniX) 21 марта 2019 г.
Дополните rel=»next» / «prev» ссылкой на себя rel=»canonical». Таким образом, /category?page=4 должен иметь отношение rel=”canonical” к /category?page=4.
Таким образом, /category?page=4 должен иметь отношение rel=”canonical” к /category?page=4.
Это уместно, поскольку нумерация страниц изменяет содержимое страницы, а также мастер-копию этой страницы.
Если у URL есть дополнительные параметры, включите их в ссылки rel=»prev» / «next», но не включайте их в rel=»canonical».
Например:
Это укажет на четкую взаимосвязь между страницами и предотвратит возможность дублирования содержимого.
Распространенные ошибки, которых следует избегать:
- Размещение атрибутов ссылки в содержимом
- Добавление ссылки rel=»prev» на первую страницу (также известную как корневая страница) в серии или ссылки rel=»next» на последнюю. Для всех остальных страниц в цепочке должны присутствовать оба атрибута ссылки.
- Остерегайтесь канонического URL корневой страницы. Скорее всего, на ?page=2 ссылка rel=prev должна указывать на каноническую, а не на ?page=1.
 Для всех остальных страниц в цепочке должны присутствовать оба атрибута ссылки.
Для всех остальных страниц в цепочке должны присутствовать оба атрибута ссылки. Код серии из четырех страниц будет выглядеть примерно так:
- Один тег разбиения на страницы на корневой странице, указывающий на следующую страницу серии.
-
- Два тега пагинации на странице 2.
-
- Два тега пагинации на странице 3.
-
- Один тег разбиения на страницы на странице 4, последней странице в серии с разбивкой на страницы.
-

Изменение элементов страницы с разбивкой на страницы
Джон Мюллер прокомментировал: «Мы не относимся к нумерации страниц по-разному. Мы относимся к ним как к обычным страницам».
Значение Страницы с разбивкой на страницы не распознаются Google как ряд страниц, объединенных в одну часть контента, как они рекомендовали ранее. Каждая страница с разбивкой на страницы может конкурировать с корневой страницей за ранжирование.
Чтобы побудить Google вернуть корневую страницу в поисковой выдаче и предотвратить появление предупреждений «Повторяющиеся метаописания» или «Повторяющиеся теги заголовков» в Google Search Console, внесите простые изменения в свой код.
Если корневая страница имеет формулу:
Последовательные страницы с разбивкой на страницы могут иметь формулу:
Эти заголовки URL-адресов с разбивкой на страницы и метаописание намеренно неоптимальны, чтобы отговорить Google от отображения этих результатов, а не корневой страница.
Если даже с такими изменениями страницы с разбивкой на страницы ранжируются в поисковой выдаче, попробуйте другие традиционные тактики SEO на странице, такие как:
- Деоптимизируйте теги h2 страницы с разбивкой на страницы.
- Добавить полезный текст на странице на корневую страницу, но не на страницы с разбивкой на страницы.
- Добавить изображение категории с оптимизированным именем файла и тегом alt на корневую страницу, но не на страницы с разбивкой на страницы.

Не включать страницы с разбивкой на страницы в XML-карты сайта
Хотя URL-адреса с разбивкой на страницы технически индексируются, они не являются приоритетом SEO для расходования краулингового бюджета.
Таким образом, им не место в вашей XML-карте сайта.
Обработка параметров разбиения на страницы в Google Search Console
Если у вас есть выбор, запустите разбиение на страницы с помощью параметра, а не статического URL-адреса. Например:
example.com/category?page=2 вместо example.com/category/page-2
Хотя нет никакого преимущества в использовании одного перед другим для целей ранжирования или сканирования, исследования показали, что Googlebot угадывает шаблоны URL-адресов на основе динамических URL-адресов. Таким образом, увеличивается вероятность быстрого обнаружения.
С другой стороны, это может потенциально вызвать ловушки сканирования, если сайт отображает пустые страницы для догадок, которые не являются частью текущей постраничной серии.
Например, серия состоит из четырех страниц.
URL-адреса с содержанием заканчиваются на www.example.com/category?page=4
Если Google угадывает www.example.com/category?page=7 и загружается действующая, но пустая страница, бот тратит время на сканирование бюджета и потенциально потеряться в бесконечном количестве страниц.
Убедитесь, что код состояния HTTP 404 отправляется для всех страниц с разбивкой на страницы, которые не являются частью текущей серии.
Еще одним преимуществом параметрического подхода является возможность настроить параметр в Google Search Console на «Разбивка на страницы» и в любое время изменить сигнал Google для сканирования «Все URL» или «Нет URL», в зависимости от того, как вы хотите использовать краулинговый бюджет. Разработчик не нужен!
Никогда не сопоставляйте содержимое страницы с разбивкой на страницы с идентификаторами фрагментов (#), поскольку оно недоступно для сканирования или индексации и, следовательно, не подходит для поисковых систем.
Неправильно понятые, устаревшие или просто неверные SEO-решения для разбитого на страницы контента
Ничего не делать
Google считает, что Googlebot достаточно умен, чтобы найти следующую страницу по ссылкам, поэтому ему не нужен явный сигнал.
По сути, SEO-специалистам нужно обрабатывать разбиение на страницы, ничего не делая.
Хотя в этом утверждении есть доля правды, ничего не делая, вы рискуете своим SEO.
Многие сайты видели, как Google выбирает страницу с разбивкой на страницы для ранжирования над корневой страницей для поискового запроса.
Всегда важно дать краулерам четкие указания, как вы хотите, чтобы они индексировали и отображали ваш контент.
Канонизировать до страницы «Просмотреть все»
Страница «Просмотреть все» была задумана так, чтобы содержать все содержимое страницы компонента на одном URL-адресе.
Все страницы с разбивкой на страницы имеют ссылку rel=»canonical» на страницу «Просмотреть все» для консолидации сигналов ранжирования.
Аргумент здесь в том, что пользователи предпочитают просматривать всю статью или список элементов категорий на одной странице, если она быстро загружается и удобна в навигации.
Идея заключалась в том, что если ваша серия с разбивкой на страницы имеет альтернативную версию «Просмотреть все», которая предлагает лучший пользовательский интерфейс, поисковые системы предпочтут эту страницу для включения в результаты поиска, а не страницу соответствующего сегмента цепочки разбиения на страницы.
В связи с этим возникает вопрос — зачем вообще страницы разбиты на страницы?
Давайте сделаем это проще.
Если вы можете предоставить свой контент по одному URL-адресу, предлагая удобный пользовательский интерфейс, нет необходимости в нумерации страниц или версии «Просмотреть все».
Если вы не можете, например, страница категории с тысячами продуктов была бы смехотворно большой и загружалась бы слишком долго, тогда разбивайте на страницы. «Просмотреть все» — не лучший вариант, поскольку он не обеспечивает хорошего пользовательского опыта.
Использование как rel=»next» / «prev», так и версии View All не дает четких указаний поисковым системам и приводит к путанице у поисковых роботов.
Не делай этого.
Канонизировать до первой страницы
Распространенной ошибкой является указание rel=»canonical» всех результатов с разбивкой на страницы на корневую страницу серии.
Некоторые плохо информированные специалисты по поисковой оптимизации предлагают использовать это как способ консолидировать полномочия по всему набору страниц на корневой странице, но это дезинформация.
Неправильная канонизация корневой страницы может ввести поисковые системы в заблуждение, заставив их думать, что у вас есть только одна страница результатов.
После этого робот Googlebot не будет индексировать страницы, расположенные дальше по цепочке, и не будет принимать сигналы к контенту, связанному с этими страницами.
Вы не хотите, чтобы страницы с подробным содержимым выпадали из индекса из-за плохой обработки пагинации.
Каждая страница в серии с разбивкой на страницы должна иметь каноническую ссылку на себя, если только вы не используете страницу «Просмотреть все».
Неправильное использование rel=canonical может привести к тому, что робот Googlebot просто проигнорирует ваш сигнал.
Страницы с нумерацией страниц
Классическим методом решения проблем с нумерацией страниц был тег robots noindex для предотвращения индексации содержимого страниц поисковыми системами.
Использование исключительно тега noindex для обработки разбиения на страницы приведет к игнорированию любых сигналов ранжирования от страниц-компонентов.
Однако более серьезная проблема с этим методом заключается в том, что долгосрочный noindex на странице в конечном итоге приведет к тому, что Google будет использовать nofollow для ссылок на этой странице.
Это может привести к удалению из индекса содержимого, связанного со страницами с разбивкой на страницы.
Разбиение на страницы и бесконечная прокрутка или Загрузить больше
Более новая форма обработки разбиения на страницы:
- Бесконечная прокрутка, , где содержимое предварительно загружается и добавляется непосредственно на текущую страницу пользователя по мере прокрутки вниз.
- Загрузить еще , где содержимое отображается при нажатии кнопки «Просмотреть больше».

Пользователи оценили эти подходы, но Googlebot? Не так много.
Робот Googlebot не имитирует такие действия, как прокрутка страницы вниз или щелчок, чтобы загрузить больше. Это означает, что без посторонней помощи поисковые системы не смогут эффективно сканировать весь ваш контент.
Чтобы оптимизировать SEO, преобразуйте бесконечную прокрутку или загрузите больше страниц в эквивалентную постраничную серию, основанную на просматриваемых якорных ссылках с атрибутами href, которые доступны даже при отключенном JavaScript.
Когда пользователь прокручивает или щелкает, используйте JavaScript для адаптации URL-адреса в адресной строке к странице компонента с разбивкой на страницы.
Кроме того, реализуйте pushState для любого действия пользователя, похожего на щелчок или активное перелистывание страницы. Вы можете проверить эту функциональность в демо, созданном Джоном Мюллером.
По сути, вы по-прежнему применяете передовой опыт SEO, рекомендованный выше, вы просто добавляете дополнительные функциональные возможности для взаимодействия с пользователем.
Препятствовать или блокировать сканирование страницы с разбиением на страницы
Некоторые специалисты по поисковой оптимизации рекомендуют вообще избегать проблемы обработки разбивки на страницы, просто блокируя Google от сканирования URL-адресов с разбивкой на страницы.
В таком случае вам понадобятся хорошо оптимизированные XML-карты сайта, чтобы страницы, связанные с помощью нумерации страниц, могли быть проиндексированы.
Есть три способа заблокировать сканеры:
- Беспорядочный способ : Добавьте nofollow ко всем ссылкам, которые ведут на страницы с разбивкой на страницы.
- Более чистый способ : Используйте запрет в файле robots.txt.
- Способ, не требуемый разработчиком : установите для параметра страницы с разбивкой на страницы значение «Разбивает на страницы», чтобы Google мог сканировать «Нет URL-адресов» в Google Search Console.

Используя один из этих методов, чтобы запретить поисковым системам сканировать URL-адреса с разбивкой на страницы, вы:
- Запретите поисковым системам распознавать сигналы ранжирования страниц с разбивкой на страницы.
- Предотвратить передачу внутренних ссылок со страниц с разбивкой на страницы на страницы с целевым содержимым.
- Помешать Google обнаружить ваши целевые страницы контента.
Очевидным преимуществом является то, что вы экономите на краулинговом бюджете.
Здесь нет однозначного правильного или неправильного ответа. Вам нужно решить, что является приоритетом для вашего сайта.
Лично я, если бы мне нужно было установить приоритет краулингового бюджета, я бы сделал это с помощью обработки разбивки на страницы в Google Search Console, так как она имеет оптимальную гибкость, чтобы передумать.
Отслеживание влияния разбиения на страницы на KPI
Итак, теперь вы знаете, что делать, как отслеживать эффект оптимизации обработки разбиения на страницы?
Во-первых, соберите контрольные данные, чтобы понять, как ваша текущая обработка пагинации влияет на SEO.
Источники для KPI могут включать:
- Файлы журнала сервера для количества просмотров страниц с разбивкой на страницы.
- Сайт: оператор поиска (например, site:example.com inurl:page), чтобы узнать, сколько страниц с разбивкой на страницы проиндексировал Google.
- Google Search Console Отчет Search Analytics, отфильтрованный по страницам, содержащим нумерацию страниц, чтобы понять количество показов.
- Отчет о целевых страницах Google Analytics , отфильтрованный по URL-адресам с разбивкой на страницы для понимания поведения на сайте.
Если вы видите проблему, связанную с тем, что поисковые системы сканируют страницы вашего сайта, чтобы получить доступ к вашему контенту, вы можете изменить ссылки на страницы.
После того, как вы запустили передовой метод обработки разбиения на страницы, еще раз посетите эти источники данных, чтобы оценить успех ваших усилий.
Авторы изображений
Избранное изображение: Пауло Бобита
Изображения/скриншоты In-Post: Создано/снято автором
Категория SEO
Канонизация страниц и SEO: ваше техническое руководство
Последнее обновление: 12 апреля 2019 г. — Пагинация: где бы мы были без нее? Если вы управляете сайтом электронной коммерции практически любого размера, вы почти наверняка используете разбиение на страницы для организации своих продуктов. От гигантов электронной коммерции, таких как Amazon и eBay, до небольших нишевых брендов, нумерация страниц является важным компонентом как для взаимодействия с пользователем, так и для поисковых систем.
Помимо электронной коммерции, нумерация страниц используется различными способами, чтобы помочь пользователям ориентироваться в больших объемах данных на веб-сайте и помочь поисковым системам лучше понять эти сайты. Примеры использования нумерации страниц:
- Ресурсные сайты
- Различная информация по отраслям или нишам
- Техническая документация, пресс-релизы, отраслевые статьи, практические руководства и т. д.
- Каталог сайтов
- Хороший вид, с полезной информацией
- Деловые справочники, профессиональные справочники и т. д.
- Блоги
- Хорошие блоги имеют регулярный и свежий контент
- Для большого количества контента требуются страницы с разбивкой на страницы, чтобы упорядочить информацию
 д.
д. Если вы не совсем понимаете, что такое нумерация страниц, то в основном это связанная серия страниц с похожими продуктами или информацией, сгруппированных вместе для удобства навигации.
Например, в категории может быть 1000 разных мужских джинсов. Вместо того, чтобы отображать длинный список из 1000 продуктов на одной странице, нумерация страниц разбивает их на серию пронумерованных страниц, содержащих от 25 до 50 продуктов на каждой.
Пагинация и поисковые системы
В марте 2019 г.Джон Мюллер из Google объявил, что Google больше не принимает во внимание теги rel=prev/next. На самом деле похоже, что Google не принимал во внимание эти теги «несколько лет» (источник). До этого открытия, чтобы поисковые системы могли правильно сканировать страницы для обнаружения ваших страниц отображения продуктов (PDP) и другого высококачественного контента, вам требовалась правильная канонизация тегов и rel=prev/next, настроенных для координации друг с другом. . 19 марта вот что сказал Джон Мюллер о тегах rel=prev/next:
На самом деле похоже, что Google не принимал во внимание эти теги «несколько лет» (источник). До этого открытия, чтобы поисковые системы могли правильно сканировать страницы для обнаружения ваших страниц отображения продуктов (PDP) и другого высококачественного контента, вам требовалась правильная канонизация тегов и rel=prev/next, настроенных для координации друг с другом. . 19 марта вот что сказал Джон Мюллер о тегах rel=prev/next:
Напрашивается вопрос; нам действительно нужно беспокоиться о нумерации страниц? Ответ положительный, но теперь это проще, так как нет необходимости реализовывать теги rel=prev/next. Когда дело доходит до нумерации страниц и поисковых систем, важно правильно настроить канонизацию и некоторые другие технические детали. У малых и средних компаний могут быть тысячи продуктов или страниц, а у корпоративных гигантов часто миллионы.
Самый важный элемент обеспечения того, чтобы поисковые системы, такие как Google, могли сканировать ваши страницы с разбивкой на страницы, заключается в том, чтобы ваши ссылки с разбивкой на страницы отображались в HTML, а не с использованием реализации JavaScript. Поисковые системы становятся все умнее в сканировании страниц, отображаемых с помощью JavaScript, но им есть, над чем работать. Наличие простых HTML-ссылок на отображаемой странице — лучшая практика для хорошего SEO.
Поисковые системы становятся все умнее в сканировании страниц, отображаемых с помощью JavaScript, но им есть, над чем работать. Наличие простых HTML-ссылок на отображаемой странице — лучшая практика для хорошего SEO.
Еще один важный элемент, который следует учитывать при работе с разбитыми на страницы страницами и, в частности, с фасетной навигацией, — это распространение URL-адресов и раздувание сканирования. Например, когда веб-сайт предлагает фильтры для набора продуктов, каждый фильтр может создать новый уникальный URL-адрес, а когда фильтры можно комбинировать, может существовать практически безграничное пространство URL-адресов.
Отличным способом борьбы с распространением URL-адресов является использование решения AJAX. Навигация с поддержкой AJAX допускает существование фильтров продуктов, но новые URL-адреса не создаются для каждого выбора фильтра. Скорее, выбранные фильтры просто возвращают отфильтрованные продукты в представление пользователя по тому же URL-адресу. Это быстрее для пользователей и лучше для сканеров поисковых систем.
Это быстрее для пользователей и лучше для сканеров поисковых систем.
Вот удобный список лучших практик для нумерации страниц и SEO, о которых я расскажу более подробно ниже:
- Канонизация
- Теги Rel=Prev/Next (устарели для Google, но, возможно, важны для поисковых систем, таких как Bing.)
- HTML-ссылки и путь сканирования поисковой системы
- JavaScript
Корневая страница Каноническая или самоканоническая
Вот как должны выглядеть ваши канонические теги:
- Корневая страница с разбивкой на страницы (первая страница в серии с разбивкой на страницы)
- Выбор глобального партнера по разработке программного обеспечения для ускорения вашей цифровой стратегии
Чтобы добиться успеха и опередить конкурентов, вам нужен партнер по разработке программного обеспечения, который преуспевает в точном типе цифровых проектов, с которыми вы сейчас сталкиваетесь, при ускорении и с максимальной стоимостью эффективным и оптимизированным способом.
Получить руководство
Продолжайте использовать приведенный выше шаблон канонических ссылок на каждой странице серии с разбивкой на страницы. Независимо от того, есть ли у вас всего две страницы или 200, этот простой шаблон поможет поисковым системам, таким как Google, лучше понять ваши разбитые на страницы страницы.
Добавление канонического тега к страницам с разбивкой на страницы, по сути, говорит Google: «Эй, все эти похожие страницы на самом деле уникальны и ценны».
Имейте в виду, что страницы с разбивкой на страницы должны быть уникальными и ценными, с уникальными продуктами и/или контентом на каждой странице. У вас не должно быть страниц и страниц с практически идентичным контентом с небольшими вариациями, и ожидать, что Google проиндексирует (не говоря уже о ранжировании) эти страницы.
Rel=Prev/Next Теги Google больше не нужны
Однако Bing все еще может использовать эти теги. Кроме того, использование этих тегов по-прежнему считается стандартом W3C (источник).
Следующим шагом в разбиении на страницы и канонизации является использование тегов rel=prev/next. Google инициировал использование этих тегов еще в 2011 году , «чтобы указать взаимосвязь между URL-адресами компонентов в серии с разбивкой на страницы». Цель этих тегов — помочь поисковым системам лучше понять вашу серию страниц с разбивкой на страницы. Правильный способ реализации тегов rel=prev/next выглядит следующим образом:- Один тег на корневой странице, указывающий на следующую страницу последовательности
 domain.com/category?page=4″/ >
domain.com/category?page=4″/ >
- Повторите процесс реализации rel=»prev», указывающего на предыдущую страницу в последовательности, и rel=»next», указывающего на следующую страницу в последовательности, до предпоследней страницы.
- Один тег на последней странице серии с разбивкой на страницы
 mydomain.com) полностью доступна для сканирования, ваши теги rel=prev/next также должны быть доступны на версии вашего сайта с m-dot.
mydomain.com) полностью доступна для сканирования, ваши теги rel=prev/next также должны быть доступны на версии вашего сайта с m-dot.Объединение разбиения на страницы с тегами Canonical и Rel=
Для получения наибольшей возможности сканирования и индексации ваших страниц в поисковых системах, таких как Bing, вам следует сочетать использование разбиения на страницы с тегами canonical и rel=prev/next. Очень важно, чтобы эти теги работали вместе и не конфликтовали.
Как упоминалось ранее, не размещайте каноническую ссылку на корневую страницу на всех страницах с разбивкой на страницы, потому что это, по сути, скажет поисковым системам, что есть только одна страница, которую они должны интересовать. Даже если вы добавляете правильные теги rel=next/prev, но неправильно получаете каноническую ссылку, у поисковых систем, скорее всего, возникнут проблемы, потому что теги будут посылать противоречивые сигналы.
Вот как должна выглядеть правильная реализация:
Каждая страница имеет самоссылающийся канонический тег, и каждая страница также имеет соответствующую настройку тегов rel=prev/next.
Если вас не интересует трафик из поисковых систем, кроме Google, возможно, нет необходимости их реализовывать. Если вы уже настроили их правильно, вы можете оставить их. Однако, если вы не уверены в реализации, удаление тегов rel=prev/next, вероятно, будет хорошей идеей.Как насчет бесконечной прокрутки?
За последние несколько лет методы бесконечной прокрутки позволили пользователям прокручивать списки информации без необходимости переходить на следующую страницу. Этот метод может хорошо работать с точки зрения пользователя, но он требует дополнительного внимания, чтобы поисковые системы, такие как Google, могли получить доступ ко всем доступным страницам.
Чтобы помочь разработчикам и веб-мастерам лучше понять оптимизированную для SEO реализацию бесконечной прокрутки, центральный блог Google для веб-мастеров опубликовал рекомендации по поиску с бесконечной прокруткой в 2014 году. Джон Мюллер также собрал эту демонстрацию о том, как следует настроить бесконечную прокрутку, чтобы Google мог сканировать и индексировать ваш контент.JavaScript
JavaScript предоставляет полезную технологию для Интернета, но создает проблемы для поисковых систем. Основным соображением является чистый путь сканирования в предварительно отрендеренном HTML, по которому поисковые роботы могут легко следовать.
В определенной степени Google анализирует JavaScript. Итак, если JavaScript используется для вставки ссылок с разбивкой на страницы в виде HTML на вашу страницу, это нормально. Однако чего Google не будет делать, так это предпринимать какие-либо действия, требующие ввода пользователя. Это означает, что если ваша настройка разбивки на страницы требует какого-либо взаимодействия с пользователем для создания ссылок, Google не «увидит» никаких страниц, кроме страницы 1 вашей серии.
Еще одним соображением, связанным с JavaScript, является время, необходимое Google для индексации контента, для которого требуется JS для отображения. Обратите внимание на комментарий Джона Мюллера: «Когда Google сканирует и индексирует контент, он выполняет два прохода. Первый проход рассматривает только HTML. Затем, через некоторое время, он выполнит второй проход, просматривая весь сайт. Мюллер говорит, что между первым и вторым проходом «нет фиксированных временных рамок». В некоторых случаях это может произойти быстро, в других случаях это может занять несколько дней или недель». (источник)
Недели на индексацию вашего контента, скорее всего, не тот риск, на который вы хотите пойти, поэтому убедитесь, что ваш HTML представлен полностью отрендеренным и что вы не полагаетесь на JavaScript для отрисовки важного контента. Если ваш сайт сильно зависит от JavaScript, рассмотрите такие варианты, как prerender.io, который позволяет вам отображать JS на сервере и по-прежнему отображать простой HTML для пользователей и поисковых систем.Убедитесь, что это работает
После того, как вы приняли во внимание все технические аспекты оптимизированной для SEO разбивки на страницы, проверьте настройки. Проверьте консоль поиска Google, чтобы убедиться, что Google индексирует страницы в ваших списках с разбивкой на страницы.
- Один тег на корневой странице, указывающий на следующую страницу последовательности
- Выбор глобального партнера по разработке программного обеспечения для ускорения вашей цифровой стратегии



 Первый проход рассматривает только HTML. Затем, через некоторое время, он выполнит второй проход, просматривая весь сайт. Мюллер говорит, что между первым и вторым проходом «нет фиксированных временных рамок». В некоторых случаях это может произойти быстро, в других случаях это может занять несколько дней или недель». (источник)
Первый проход рассматривает только HTML. Затем, через некоторое время, он выполнит второй проход, просматривая весь сайт. Мюллер говорит, что между первым и вторым проходом «нет фиксированных временных рамок». В некоторых случаях это может произойти быстро, в других случаях это может занять несколько дней или недель». (источник) 