
Парсер поисковой выдачи Butterfly
Butterfly 4 — Мощный сборщик ссылок с любых сайтов, каталогов и поисковых систем.
Парсер имеет простой и интуитивно понятный интерфейс, с которым разберется любой новичок, впервые запустивший программу.
Все найденные программой ссылки могут отсеиваться по фильтру, настроенному под Ваши личные потребности. Программа имеет много готовых настроенных и отлаженных профилей фильтрации и профилей поиска. Имеется возможность сохранять как целые найденные ссылки, так только домены, или ссылки, построенные по маске.
В версии 4:
Изменен интерфейс программы. Предоставлена возможность использовать программу на нетбуках с небольшим разрешением экрана.
Реализована поддержка проверки локальных ссылок
Реализован вывод в лог ошибок при проверке сайтов
Добавлена возможность выводить в файл результатов ссылки с ошибкой проверки
Реализован механизм авторизации и получения дополнительных функций программы
Реализован авточекер прокси
Возможность скрытия рекламы при наличии минимум одной дополнительной функции
Возможность не тестировать на работоспособность найденные ссылки (не фильтровать)
Изменен User-Agent
Возможность продолжения парсинга с того места где парсинг был прерван при следующем запуске программы
Возможность увеличения количества параллельных процессов до 300
Исправлена ошибка при работе с SSL
Исправлены и протестированы профили поиска и фильтрации
Исправлены мелкие ошибки
Изменения в версии 4.
 0.1:
0.1:Ручная настройка ограничения по времени проверки прокси сервера
В стандартной поставке Butterfly 4 включает 19 профилей поиска:
Поиск в Ask
Поиск в Bing
Поиск в каталоге DMOZ
Поиск в Gigablast
Поиск в Google
Поиск в Google (сайты на англиском)
Поиск в Google (сайты из USA)
Поиск в Mail.ru
Поиск в Meta.ua
Поиск в Lycos
Поиск в Nigma.ru
Поиск в новостях сайта NoNaMe
Поиск в Rambler
Поиск в Rambler TOP 100
Поиск в Refer.ru
Поиск в Yandex
Поиск в Yandex Каталог
Поиск в Yahoo
а так же 16 профилей фильтрации:
Отбор сайтов на Bitrix
Отбор каталогов CNCat
Отбор сайтов на DLE
Отбор сайтов на DLE (отбор реализованый в Butterfly 2)
Отбор сайтов на DLE (без Adult)
Отбор сайтов на Drupal
Отбор сайтов на Joomla
Отбор сайтов на MaxSite
Отбор сайтов на phpBB
Отбор сайтов на phpBB 3
Отбор сайтов на UCOZ
Отбор сайтов на WordPress
Отбор сайтов на vBulletin
Отбор сайтов на IPB
Отбор бесплатных и открытых торент трекеров
— See more at: http://bibyte.
 net/content/butterfly-40-beta-2#sthash.iI5MBtof.dpuf
net/content/butterfly-40-beta-2#sthash.iI5MBtof.dpufButterfly 5.1 Portable rus парсер выдачи поисковых систем
Дата: 09.04.2017Просмотров: 3354
Butterfly Portable rus парсер выдачи поисковых систем — имеет простой и интуитивно понятный интерфейс, с которым разберется любой новичок, впервые запустивший программу. Все найденные программой ссылки могут отсеиваться по фильтру, настроенному под Ваши личные потребности
Программа имеет много готовых настроенных и отлаженных профилей фильтрации и профилей поиска. Имеется возможность сохранять как целые найденные ссылки, так только домены, или ссылки, построенные по маске
Butterfly 5.1 включает 13 профилей поиска:
— Поиск в Ask
— Поиск в каталоге DMOZ
— Поиск в Google
— Поиск в Google (сайты на русском)
— Поиск в Google (сайты на английском)
— Поиск в Google (сайты из USA)
— Поиск в Nigma. ru
ru
— Поиск в новостях сайта NoNaMe
— Поиск в Rambler
— Поиск в Rambler TOP 100
— Поиск в Refer.ru
— Поиск в Yandex
— Поиск в Yandex Каталог
а так же 16 профилей фильтрации:
— Отбор сайтов на Bitrix
— Отбор каталогов CNCat
— Отбор сайтов на DLE
— Отбор сайтов на DLE (отбор реализованый в Butterfly 2)
— Отбор сайтов на DLE (без Adult)
— Отбор сайтов на Drupal
— Отбор сайтов на Joomla
— Отбор сайтов на MaxSite
— Отбор сайтов на phpBB
— Отбор сайтов на phpBB 3
— Отбор сайтов на UCOZ
— Отбор сайтов на WordPress
— Отбор сайтов на vBulletin
— Отбор сайтов на IPB
— Отбор бесплатных и открытых торент трекеров
— Без отбора (сохранение всех найденных сайтов)
Название: Butterfly
Версия: 5.1
Язык интерфейса: Русский, Английский
ОС: Windows 10 / 8.1 / 8 / 7 / Vista / XP
Разрядность: 32bit/64bit
Лекарство: Не требуется
скачать Butterfly 5.1 Portable rus парсер выдачи поисковых систем :
скачать программу
зеркало
После ознакомления лучше купить у разработчика!!!
Теги: скачать программы, парсер выдачи поисковых систем
Чтобы комментировать, зарегистрируйтесь или авторизуйтесь!
HomeGuard Pro 2.
 6.1 мониторинг активности пользователей
6.1 мониторинг активности пользователейДата: 15.07.2016
HomeGuard Pro 2.6.1 мониторинг активности пользователей — при работе в Интернете и в автономном режиме. Позволяет выбрать конкретного пользователя и время мониторинга
Poedit 1.8.8 Pro rus Portable программа перевода веб-ресурсов
Дата: 28.06.2016
Poedit 1.8.8 Pro rus Portable программа перевода веб-ресурсов — поможет сделать переводы для любого программного обеспечения или веб-сайта, который использует Gettext для локализации
Visual Web Ripper 3.0.7 парсер контента
Дата: 30.04.2016
Visual Web Ripper 3.0.7 парсер контента — это мощный визуальный инструмент для сбора всевозможных данных из Интернета
- ← Datacol 7.15 универсальный парсер + Plugins
- InstaEditor 1.0.2 программа для instagram →
Вернуться к списку
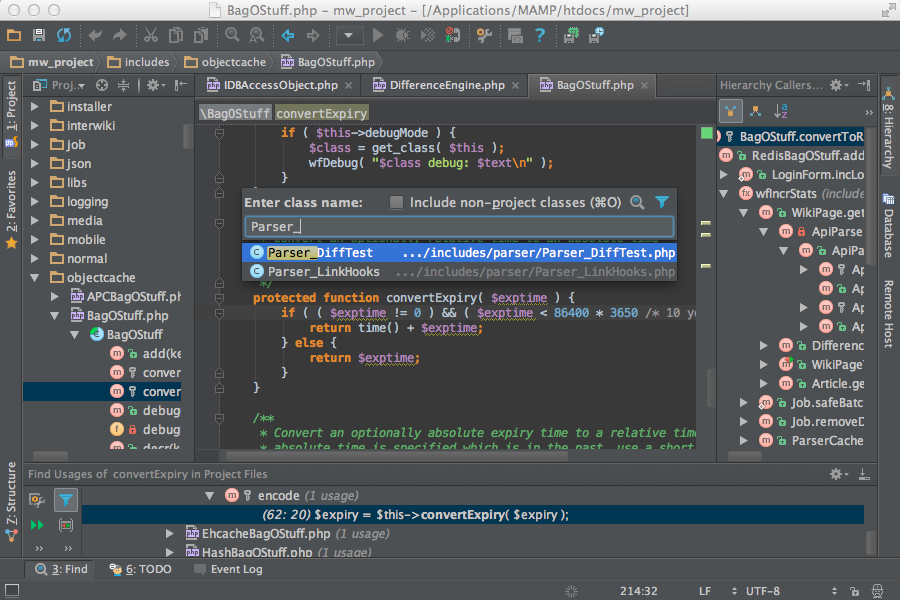
Butterfly.parser — Документация по Butterfly 0.0.1
"""Парсер словаря OpenFOAM/c++.""" импортировать повторно из коллекций импортировать OrderedDict
[документы] класс CppDictParser (объект): """Синтаксический анализ словаря OpenFOAM в словарь Python. Используйте свойство values для получения словаря. Атрибуты: текст: словарь OpenFOAM в виде одной многострочной строки. """ def __init__(я, текст): """Инициировать OpenFOAMDictParser.""" _t = self.remove_comments(текст) _t = ''.join(_t.replace('\r\n', ' ').replace('\n', ' ')) self.__values = self._convert_to_dict(self._parse_nested(_t))
[документы] @classmethod def from_file (cls, путь к файлу): """Создать анализатор из файла OpenFOAM.""" с открытым (путь к файлу) как f: вернуть cls('\n'.join(f.readlines()))
@имущество значения определения (я): """Получить значения словаря OpenFOAM как словарь Python.""" вернуть self.__values
def _convert_to_dict (самостоятельно, проанализировано): """Преобразовать проанализированный список в словарь.
http://stackoverflow.com/a/14715850/4394669 """ pat = r'({}|{}|{})'.format(left, right, sep) токены = re.split (patch, text) стек = [[]] для x в токенах: если не x.strip() или re.match(sep, x): Продолжить если re.match(слева, x): # Вложить новый список в текущий список текущий = [] стек[-1].append(текущий) stack.append(текущий) Элиф re.match (справа, х): стек.поп() если не стек: поднять ValueError('ошибка: отсутствует открывающая скобка') еще: стек[-1].append(x.strip()) если длина (стек) > 1: печать (стек) поднять ValueError('ошибка: отсутствует закрывающая скобка') возврат стека.pop() [документы] определение ToString (я): """Перезаписать метод ToString.""" вернуть себя.__repr__()
защита __repr__(сам): """Представление класса.
""" вернуть '{}'.format(self.values) [документы] класс ResidualParser (объект): """Paeser для остаточных значений из лог-файла. Атрибуты: filepath: полный путь к файлу .log. синтаксический анализатор: если ture Parser начнет синтаксический анализ значений после запуска. """ def __init__(я, путь к файлу, синтаксический анализ = Истина): """Инициировать остаточный синтаксический анализатор.""" self.filepath = путь к файлу self.__residuals = OrderedDict() если разобрать: self.parse ()
[документы] def parse(self): """Проанализируйте файл журнала.""" # открыть файл # пытаемся найти первую строку с Time = # отправить файл рекурсивному остаточному парсеру пытаться: с open(self.filepath, 'rb') как f: для строки в f: если line.startswith('Время ='): self.
timestep = self.__get_time(строка) self.__residuals[self.timestep] = {} self.__parse_residuals(f) кроме Исключения как e: поднять 'Не удалось разобрать {}:\n\t{}'.format(self.filepath, e)@имущество остатки определения (сам): """Получить остатки как словарь.""" вернуть себя.__остатки @имущество определение time_range (я): """Получить временной диапазон в виде кортежа.""" _times = self.get_times () вернуть _раз[0], _раз[-1]
[документы] def get_times(self): """Получить временные шаги.""" return self.__residuals.keys()
[документы] def get_residuals(я, количество, диапазон времени): """Получить остатки по количеству.""" если количество не в self.quantities: print('Недопустимое количество [{}]. Попробуйте из списка ниже:\n{}' .format(количество, само.
количества)) возвращаться () если не time_range: return (v[количество] для v в self.__residuals.itervalues()) еще: доступный_временной_диапазон = self.time_range пытаться: t0 = макс (доступный_временной_диапазон[0], временной_диапазон[0]) t1 = мин (доступный_временной_диапазон[1], временной_диапазон[1]) кроме IndexError как e: поднять ValueError('Не удалось прочитать time_range:\n{}'.format(e)) return (self.__residuals[int(t)][quantity] для t в xrange(t0, t1)) @статический метод защита __get_time (строка): вернуть int(line.split('Время =')[-1]) определение __parse_residuals (я, f): для строки в f: если не line.startswith('Время ='): пытаться: # количество, начальный остаток, конечный остаток, без итераций q, ir, fr, ni = line.
split(': Решение для ')[1].split(',') self.__residuals[self.timestep][q] = ir.split('= ')[-1] кроме IndexError: проходят еще: self.timestep = self.__get_time(строка) self.__residuals[self.timestep] = {} self.quantities = self.__остатки[self.timestep].keys()
 """
импортировать повторно
из коллекций импортировать OrderedDict
"""
импортировать повторно
из коллекций импортировать OrderedDict
 """
д = дикт()
itp = iter (проанализировано)
для пп в итп:
если не isinstance (pp, list):
если pp.find(';') == -1:
# если это не список и не включает ';' это ключ и
# следующий элемент это значение
d[pp.strip()] = self._convert_to_dict(следующий(itp))
еще:
s = pp.split(';')
если не pp.endswith(';'):
# последний элемент является ключом, а следующий элемент является значением
d[s[-1].strip()] = self._convert_to_dict(следующий(itp))
с = с[:-1]
для ppp в s:
сс = ppp.split()
если сс:
d[ss[0].strip()] = ' '.join(ss[1:]).strip()
вернуть д
@статический метод
def _parse_nested (текст, слева = r'[{]', справа = r'[}]', sep = '#'):
"""Синтаксический анализ вложен.
"""
д = дикт()
itp = iter (проанализировано)
для пп в итп:
если не isinstance (pp, list):
если pp.find(';') == -1:
# если это не список и не включает ';' это ключ и
# следующий элемент это значение
d[pp.strip()] = self._convert_to_dict(следующий(itp))
еще:
s = pp.split(';')
если не pp.endswith(';'):
# последний элемент является ключом, а следующий элемент является значением
d[s[-1].strip()] = self._convert_to_dict(следующий(itp))
с = с[:-1]
для ppp в s:
сс = ppp.split()
если сс:
d[ss[0].strip()] = ' '.join(ss[1:]).strip()
вернуть д
@статический метод
def _parse_nested (текст, слева = r'[{]', справа = r'[}]', sep = '#'):
"""Синтаксический анализ вложен.

| «»»Парсер словаря OpenFOAM/c++.»»» | |
| импорт по | |
| из импорта коллекций OrderedDict | |
| класс CppDictParser(объект): | |
«»»Синтаксический анализ словаря OpenFOAM в словарь Python. | |
| Используйте свойство values для получения словаря. | |
| Атрибуты: | |
| текст: словарь OpenFOAM в виде одной многострочной строки. | |
| «»» | |
| деф __init__(я, текст): | |
| «»»Инициировать OpenFOAMDictParser.»»» | |
| _t = self.remove_comments(текст) | |
_t = ».join(_t.replace(‘\r\n’, ‘ ‘). replace(‘\n’, ‘ ‘)) replace(‘\n’, ‘ ‘)) | |
| self.__values = self._convert_to_dict(self._parse_nested(_t)) | |
| @метод класса | |
| определение из_файла (cls, путь к файлу): | |
| «»»Создать анализатор из файла OpenFOAM.»»» | |
| с открытым (путь к файлу) как f: | |
| возврат cls(‘\n’.join(f.readlines())) | |
| @свойство | |
| значения по умолчанию (сам): | |
«»»Получить значения словаря OpenFOAM как словарь Python. «»» «»» | |
| вернуть self.__values | |
| @статический метод | |
| деф remove_comments (код): | |
| «»»Удалить комментарии из кода C++.»»» | |
| # удалить все потоковые комментарии вхождения (/*COMMENT */) из строки | |
| текст = re.sub(re.compile(‘/\*.*?\*/’, re.DOTALL), », код) | |
| # удалить все однострочные комментарии (//COMMENT\n ) из строки | |
| возврат re.sub(re.compile(‘//.*?\n’), », текст) | |
| по определению _convert_to_dict (самостоятельно, проанализировано): | |
«»»Преобразовать проанализированный список в словарь. «»» «»» | |
| д = дикт() | |
| itp = iter(проанализировано) | |
| для пп в итп: | |
| , если не isinstance(pp, list): | |
| , если pp.find(‘;’) == -1: | |
| # если это не список и не включает ‘;’ это ключ и | |
| # следующий элемент имеет значение | |
| d[pp.strip()] = self._convert_to_dict(следующий(itp)) | |
| еще: | |
| с = pp.split(‘;’) | |
, если не pp. endswith(‘;’): endswith(‘;’): | |
| # последний элемент является ключом, а следующий элемент является значением | |
| d[s[-1].strip()] = self._convert_to_dict(следующий(itp)) | |
| с = с[:-1] | |
| для ppp в s: | |
| сс = ppp.split() | |
| если СС: | |
| d[ss[0].strip()] = ‘ ‘.join(ss[1:]).strip() | |
| возврат д | |
| @статический метод | |
| def _parse_nested(text, left=r'[{]’, right=r'[}]’, sep=’#’): | |
«»»Синтаксический анализ вложен. | |
| http://stackoverflow.com/a/14715850/4394669 | |
| «»» | |
| pat = r'({}|{}|{})’.format(left, right, sep) | |
| токена = re.split(pat, text) | |
| стек = [[]] | |
| для x в токенах: | |
| , если не x.strip() или re.match(sep, x): | |
| продолжить | |
| , если re.match(left, x): | |
| # Вложить новый список в текущий список | |
| текущий = [] | |
стек[-1]. append(current) append(current) | |
| stack.append(текущий) | |
| elif re.match(справа, x): | |
| стек.поп() | |
| если не стек: | |
| поднять ValueError(‘ошибка: отсутствует открывающая скобка’) | |
| еще: | |
| стек[-1].append(x.strip()) | |
| , если длина (стек) > 1: | |
| печать (стек) | |
| поднять ValueError(‘ошибка: отсутствует закрывающая скобка’) | |
возврат стека. pop() pop() | |
| по определению ToString(я): | |
| «»»Перезаписать метод ToString.»»» | |
| вернуть self.__repr__() | |
| деф __repr__(сам): | |
| «»»Представление класса.»»» | |
| возврат ‘{}’.format(self.values) | |
| класс ResidualParser (объект): | |
«»»Paeser для остаточных значений из файла журнала. | |
| Атрибуты: | |
| путь к файлу: полный путь к файлу .log. | |
| синтаксический анализатор: Если синтаксический анализатор начнет анализировать значения после запуска. | |
| «»» | |
| по определению __init__(я, путь к файлу, синтаксический анализ = Истина): | |
| «»»Инициализировать остаточный синтаксический анализатор.»»» | |
| self.filepath = путь к файлу | |
self. __residuals = OrderedDict() __residuals = OrderedDict() | |
| при разборе: | |
| self.parse() | |
| деф синтаксический анализ (сам): | |
| «»»Проанализируйте файл журнала.»»» | |
| # открыть файл | |
| # попробуй найти первую строку с Time= | |
| # отправить файл на рекурсивный остаточный парсер | |
| попытка: | |
| с открытым (self.filepath, ‘rb’) как f: | |
| для строки в f: | |
, если строка. startswith(‘Время =’): startswith(‘Время =’): | |
| self.timestep = self.__get_time(строка) | |
| self.__residuals[self.timestep] = {} | |
| self.__parse_residuals(f) | |
| кроме Исключения как e: | |
| поднять исключение («Не удалось проанализировать {}:\n\t{}».format(self.filepath, e)) | |
| @свойство | |
| по определению остатков(я): | |
| «»»Получить остатки как словарь.»»» | |
вернуть self.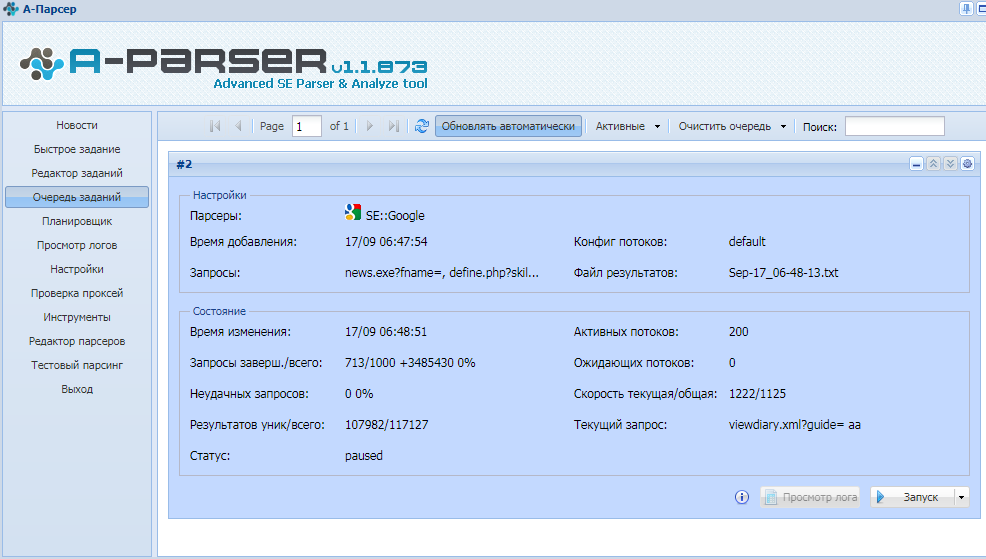 __остатки __остатки | |
| @свойство | |
| по определению time_range(self): | |
| «»»Получить диапазон времени в виде кортежа.»»» | |
| _times = self.get_times() | |
| возврат _times[0], _times[-1] | |
| по определению get_times(self): | |
| «»»Получить временные шаги.»»» | |
| вернуть self.__residuals.keys() | |
| по определению get_residuals (я, количество, диапазон времени): | |
«»»Получить остатки по количеству. «»» «»» | |
| , если количество не указано в self.quantities: | |
| print(‘Неверное количество [{}]. Попробуйте из списка ниже:\n{}’ | |
| .format(количество, само.количества)) | |
| возврат () | |
| , если не time_range: | |
| возврат (v[количество] для v в self.__residuals.itervalues()) | |
| еще: | |
| доступный_временной_диапазон = собственный.временной_диапазон | |
| попытка: | |
t0 = макс. (доступный_временной_диапазон[0], временной_диапазон[0]) (доступный_временной_диапазон[0], временной_диапазон[0]) | |
| t1 = мин (доступный_временной_диапазон[1], временной_диапазон[1]) | |
| , кроме IndexError как e: | |
| поднять ValueError(‘Не удалось прочитать time_range:\n{}’.format(e)) | |
| возврат (self.__residuals[int(t)][количество] для t в xrange(t0, t1)) | |
| @статический метод | |
| по определению __get_time(строка): | |
| возврат int(line.split(‘Время =’)[-1]) | |
| по определению __parse_residuals(я, е): | |
| для строки в f: | |
, если не line. startswith(‘Время =’): startswith(‘Время =’): | |
| попытка: | |
| # количество, начальный остаток, конечный остаток, без итераций | |
| q, ir, fr, ni = line.split(‘: Решение для ‘)[1].split(‘,’) | |
| self.__residuals[self.timestep][q] = ir.split(‘= ‘)[-1] | |
| , кроме IndexError: | |
| пройти | |
| еще: | |
| self.timestep = self.__get_time(строка) | |
| self.__residuals[self.timestep] = {} | |
self. |