Как рассчитать слова для seo оптимизации — SEO на vc.ru
Расчет документа по BM 25
2861 просмотров
BM25 – данная функция анализирует слова запроса в каждом документе, в беспорядочном количестве терминов и количестве документов не учитывая связь между ними. Это род функций с разными параметрами и компонентами. Okapi BM25 которую разработали в университете Лондона в 1980-х и 1990-х годах и опирается на допустимости модели разработанной Стивеном Робертсоном, Карен Спарк Джоунсом в 1970-х и в 1980-х годах.
Версия BM25 – BM25F является более современные TF-IDF — определяет важность слова применяемое в тексте. Чем длиннее текст, тем больше может быть вхождений в него термина. Однако это не значит, что текст отвечает желаниям посетителей. Для этого используется формула, которая рассчитывает количество применений одного слова к общей сумме слов в документе.TF- частотность вхождений термина к общему числу слов в тексте. IDF – обратная частота документа анализирующие то как регулярно слово встречается в коллекции документов.
Так же надо вспомнить о BM25F – учет релевантности по фактору частотности, где учитывается различность важности зон документа. К примеру предложение в середине текста имеет меньшее значение, чем заголовок.
Особенности ранжирования НЧ запросов
· ВМ25 без учета расстояний между словами. Это значит, что все слова из запроса должны быть в тексте, не важно на каком расстоянии они идут.
· Минимум 1 вхождение в title, текст ссылки
· В рамках шингла (6 слов) должно быть вхождение.
Шингл- это текст, разбитый на определенные отрезки.
Можно использовать блок 2-3 предложения через весь сайт для привлечения шлейфа НЧ.
Текстовое ранжирование
· TF*idf
· Bm25
Текст нужно считать и рассчитывать.
Score = Wsin gle + Wpair + k1 *WAllWords +
k2 *WPhrase + k3 *WHalfPhrase + WPRF
Вхождение 1 слова, вхождение пар слов, есть ли все слова в тексте (фразовое соответствия, пол фразы, часть фразы), где они встречаются и т.
Пример формулы текстового ранжирования
Hdr-сумма весов слова за форматирование. CF-число вхождений леммы в коллекцию. D-число документов в коллекции.
Учет пар слов
Слова запроса встречаются в тексте-1, через слово или в обратном порядке 0.5 Слова из трехсловных запросов через слово идут подряд-0.1.
Учет фраз
Помимо перечисленного является присутствие всех слов запроса, за каждое отсутствующие слово умножается на коэффициент 0.03. Полная формула:
Nmiss-кол-во отсутствующих слов в документе.
Бонус за наличие всех слов в документе.
Концентрация всех слов в тексте (в той зоне), где надо рассматривать если отсутствуют какие-то слова будет штраф, потому что это указанно в формуле.
ВМ25 – модификация ВМ25F в которой документ представляется как совместимость нескольких полей таких как, например, заголовки, основной текст, ссылочный текст, протяженность которых самостоятельно упорядочивается и каждой из которой может быть назначен свой уровень ценности и итоговой функции ранжирования.
ВМ25 – это формула текстового ранжирования которая используется в ПС, для того что бы понять какой текст релевантный по определенному слову, фразе. Соответственно используется в ПС модификация F (что значит field- поле). Считается ВМ25 не для всего документа, а по каждому отдельному полю. Поле может быть, как title, так h2, текст, большой сео текст, так и фрагменты теста, входящих внешних ссылок, внутренних анкоров, исходящих ссылок из документа, то есть посчитать можно по абсолютно разные поля в документе.
Связанные с ВМ25
· Предложения, в которых есть вхождения
· Заголовки
· Различные теги выделений (<b> strong и др.)
· Учет позиции в док-те
· С учётом синонимов в документе
· Различные участки текста
Не относящиеся к ВМ25
· Наличие всех слов в документе
· Точное вхождение
· Позиция в документе
· Вхождение фраз в анкоры исходящих ссылок
· Вхождение лемм
· Релевантные пассажи
· Все выше перечисленное с учетом синонимов.
Тематическая близость-ISI
Ни где не отмечено в факторах ПС слова, которые чаще всего используют сайты из ТОПа.
Тематическая близость, не каким индексом в тематике, условно, что в Топе есть сайты по запросам, которых есть схожий набор слов в тематике который может оказывать влияние на ранжирование. Учитывая, что нельзя найти нормальные синонимы. Очень часто могут оказываться синонимы, слова имеющие отношения к тематике и из-за этого можно понять контент. Можно использовать слова, которые используют конкуренты.
Расчет ВМ25 для 2-х зон документа. Title
Bady (без разбиения на фрагменты). Bady- весь основной контент.
Есть зависимость от контента, но это не значит, что чем больше текста, тем лучше, но вероятность есть.
Важен расчет, может быть дан в видеTF (частота использования слова или фразы), или в виде рекомендаций по количеству вхождений и объему зоны документа. ВМ25 сильно зависит как раз от объема самого документа и от количества вхождений в него.
Выводы
1. Существует зависимость между позицией документа и формулой текстовой релевантности ВМ25.
2. По зоне документа (bady) большой ВМ25 не значит лучше
3. Нужно рассчитывать по разным полям документа
4. ВАЖНО. Расчет возможен по TF
5. Для ВЧ запросов данные отличаются (потому что факторы текстового влияния меньше больше учитывается коммерческие и поведенческие факторы)
Если не известно какое слово использовать по составной фразе, нужно отдать предпочтение более редко встречающемуся слову.
Особенности ранжирования СЧ запросов
СЧ
Title аналогично с НЧ
Необходимость текста
Статистический вес. Перелить вес с не нужных страниц
Работа с сниппетами
Слова имеют разные веса IDF
Анкор лист считается по ВМ25
Вхождение дополнительных слов улучшают релевантность
Все тоже самое, что НЧ
Сам текст, нужно определить нужна ли большая текстовая область, для продвижения СЧ. Определить можно по поисковые выдачи у какого количества конкурентов есть текст, сколько текста, если у 3 конкурентов текст есть значит писать. Так же принимается решение писать текст не большой на страницу СЧ запросов, если туда ведет несколько ключевых фраз, если дополнительных слов нет нужно проверять по конкурентам.
Определить можно по поисковые выдачи у какого количества конкурентов есть текст, сколько текста, если у 3 конкурентов текст есть значит писать. Так же принимается решение писать текст не большой на страницу СЧ запросов, если туда ведет несколько ключевых фраз, если дополнительных слов нет нужно проверять по конкурентам.
Особенности ранжирования ВЧ запросов
Первое место ПФ занимает кликстрим
Важна связка вопрос + документ
Работа со сниппетами
Корректная работа со всеми остальными факторами
Корректно нужно проработать все факторы для НЧ и СЧ + очень важно соблюдать связку запрос + документ по типу сайта, по типу страницы, с которой идти в ТОП. Количество запросов, которые надо двигать на одной странице. И очень важно поведенческий фактор. Проработать сниппеты. Для более успешного продвижения сайтов seo необходимо учитывать все факторы.
Алгоритм BM25 / Хабр
Впервые данный алгоритм встретил на Википедии и не обратил на него особого внимания. Позже изучая научные труды сотрудников Яндекса, я обратил внимание на то, что они ссылаются на него, например, в статье Сегаловича об алгоритмах определения нечетких дубликатов, поэтому решил разобраться, в чем смысл его использования. Постараюсь на простых примерах это объяснить. Итак, для чего этот алгоритм?
Позже изучая научные труды сотрудников Яндекса, я обратил внимание на то, что они ссылаются на него, например, в статье Сегаловича об алгоритмах определения нечетких дубликатов, поэтому решил разобраться, в чем смысл его использования. Постараюсь на простых примерах это объяснить. Итак, для чего этот алгоритм?Первое. Вводится зависимость релевантности от вхождения или не вхождения слов в запросах с более чем одного слова.
Пусть есть несколько запросов состоящих из нескольких слов, например (пример чисто иллюстративный):
- купить смартфон Samsung
- купить смартфон Samsung Galaxy
Релевантность каждого из слова равна его IDF * на второй множитель в выражении выше. Релевантность всего поискового запроса равна сумме релевантностей всех слов.
Второе. Преимущество при поиске в запросах с более чем 2-ух слов, одно из которых менее употребительно (более узкоспециализированное) будет отдаваться документам которые содержат это узкоспециализированное слово. Например, есть запрос купить Samsung Galaxy Note 2 (чисто иллюзорный пример). Пусть Note 2 – это более редкое слово (меньше раз встречается в коллекции чем Samsung и Galaxy). Пусть есть 2-а документа каждый из которых релевантен запросу и каждый из них содержит кроме Samsung и Galaxy также Note 2. При этом в первом документе note 2 употребляется только один раз, тогда как во втором – 3 раза (подразумевается, что документ содержит больше информации о Note 2). Но сначала рассмотрим, результат вычисление релевантности алгоритмом, если частоты всех указанных слов в документах одинаковы.
Обратите также внимание, что из-за того, что количество документов содержащее слово Note 2 меньше равно в 50 раз от содержащих слово galaxy (500) мы получаем IDF равный 3,279634 что значительно больше IDF для слова galaxy.
Пока что у нас были одинаковые значения частот для слова note 2 (для других слов также). Теперь давайте в Excel увеличим частотность слова note 2 для док2, вместо 0,02 сделаем 0,05 (5 вхождений слова).
Обратите внимание, что значение IDF не изменяется но значение формула (второй множитель на изображении в самом вверху) теперь стало равно 0,061856 и именно это значение участвует в вычислении score, которое теперь для док2 равно уже 0,290559
Теперь самое главное. Увеличим частоту вхождения слова galaxy до 5 в док 1
Как мы видим суммарная частота каждого из слов в док1 и док2 одинакова. Но значение score (релевантность) выше у док2, потому что слово note2 является более редко встречающимся соответственно его результирующее влияние больше чем слово galaxy.
На практике наличие слов в многосложных запросах очень важно. Конечно же релевантность современных поисковых систем определяется не только исходя из частот как это было показано на примере формулы BM25, но все же некоторые корреляции провести можно. В основном это касается того, что если в документе нет слова из поискового запроса то такому документу значительно сложнее подняться в ТОП по запросу по сравнению с теми, у которых это слово содержится. Давайте рассмотрим пример на поисковой системе Яндекс.
Вводим запрос Samsung galaxy. У меня выдача касалась Samsung galaxy в целом (2 сайта, как обычно Википедия) остальное модели, картинки и т.д.
Вводим запрос samsung galaxy note 2. Выдача полностью меняется, теперь представлены страницы, которые содержат информацию не просто о Samsung galaxy, а о Samsung galaxy note 2.
Вводим запрос samsung galaxy note 2 ценаОпять выдача меняется теперь в выдаче страницы, которые уже содержат слово цена, а не просто Samsung galaxy.
Вводим запрос samsung galaxy note 2 цена Харьков. Выдача кардинально меняется, все страницы в ТОП10 содержат слово Харьков.
Можно ли сказать, что слово Харьков является более узкоспециализированным, как это приводилось в алгоритме BM25 выше? IDF cлова Харьков знает только поисковая система, но в контексте поискового запроса Samsung galaxy note 2 оно без сомнения сужает область поиска. Может быть пример с Яндексом немного неудачен, в силу того, что в приведенном случае большую роль будет играть учет региональности запроса, но я думаю со мной согласится любой сеошник, что слово из поискового запроса обязательно должно быть в тексте, я же всего лишь постарался показать работу алгоритма BM25 и раскрыть 2-а важных его аспекта.
Ссылка на xls документ — книга11.xls
Понимание методов поиска на основе терминов в информационном поиске | by Lan Chu
Интуиция, стоящая за наиболее распространенными методами поиска на основе терминов, такими как BM25, TF-IDF, модель правдоподобия запроса.
 Опубликовано в
Опубликовано в·
Чтение: 11 мин.·
10 апреля 2022 г. 1. Что такое поиск информации? Photo by Siora Photography on UnsplashЗначение термина информационного поиска (IR) может быть очень широким. Например, достать свой идентификатор из кармана, чтобы вы могли напечатать его в документе, — это простая форма поиска информации. Хотя существует несколько определений IR, многие согласны с тем, что IR составляет около технологии для подключения людей к информации . Сюда входят поисковые системы, рекомендательные системы, диалоговые системы и т. д. С академической точки зрения поиск информации можно определить как:
2.Информационный поиск (ИП) — это поиск материала (обычно документов) неструктурированного характера (обычно текста). которая удовлетворяет потребность в информации из больших коллекций (обычно хранящихся на компьютерах).
Мэннинг и др., «Введение в поиск информации»
 Методы поиска на основе терминов
Методы поиска на основе терминов Методы поиска на основе терминов представляют собой математические основы для определения соответствия запроса и документа на основе точного синтаксического соответствия между документом и запросом для оценки релевантности документов для данного поиска. запрос. Идея состоит в том, что пара документа и поискового запроса представлена содержащимися в них терминами. В этой статье объясняется интуиция, стоящая за наиболее распространенными методами поиска на основе терминов, такими как BM25, TF-IDF, модель правдоподобия запроса.
Получите 💬 GPT ответы на любые вопросы по науке о данных или программированию. Создавайте сводки и учебные заметки для тысяч 📚 учебных ресурсов всего одним щелчком мыши. 👉
Бесплатные учебные ресурсы для специалистов по данным и разработчиков. Отобранные вручную блоги, учебные пособия, книги и…
Учебные курсы, хакатоны, мероприятия и вакансии для инженеров по машинному обучению и искусственному интеллекту
aigents. co
co
2.1. TF-IDF
TF-IDF занимается поиском информации на основе модели Bag of Words (BOW), которая, вероятно, является самой простой моделью IR. TF-IDF состоит из двух частей: TF (частота терминов) и IDF (обратная частота документа).
TF — Частота термина
Частота термина, как следует из названия, — это частота термина t в документе d . Идея состоит в том, что мы присваиваем вес каждому термину в документе в зависимости от количества вхождений этого термина в документе. Таким образом, оценка документа равна частоте термина, которая предназначена для отражения того, насколько важно слово для документа.
Термин Частота. Источник: Мэннинг и др., «Введение в поиск информации» В литературе мы находим две часто используемые формулы для частоты терминов: частота терминов необработанная , которая подсчитывает, как часто термин t появляется в документе d, и частота терминов log , определяемая формулой ниже. Лог имеет демпфирующий эффект при больших значениях частот терминов. Если мы посмотрим на приведенную выше таблицу для термина «Антоний», то он появляется в два раза чаще в Антоний и Клеопатра , чем в Юлий Цезарь. При частоте необработанных терминов это означало бы, что Антоний и Клеопатра в два раза актуальнее, чем Юлий Цезарь .
Лог имеет демпфирующий эффект при больших значениях частот терминов. Если мы посмотрим на приведенную выше таблицу для термина «Антоний», то он появляется в два раза чаще в Антоний и Клеопатра , чем в Юлий Цезарь. При частоте необработанных терминов это означало бы, что Антоний и Клеопатра в два раза актуальнее, чем Юлий Цезарь .
IDF — обратная частота документов
Частота терминов страдает от критической проблемы: все термины считаются одинаково важными, когда дело доходит до оценки релевантности документа по запросу. , хотя это не всегда так. На самом деле, некоторые термины имеют мало или вообще не имеют различительной способности при определении релевантности (например, «the» может встречаться в одном документе много раз, но не вносить никакого вклада в релевантность). С этой целью мы вводим механизм для снижения влияния терминов, которые слишком часто встречаются в коллекции, чтобы иметь смысл для определения релевантности. Чтобы определить только важные термины, мы можем указать частоту документов (DF) этого термина, которая представляет собой количество документов, в которых термин встречается. Это что-то говорит об уникальности терминов в сборнике. Чем меньше DF, тем больше уникальность заданных терминов.
Чтобы определить только важные термины, мы можем указать частоту документов (DF) этого термина, которая представляет собой количество документов, в которых термин встречается. Это что-то говорит об уникальности терминов в сборнике. Чем меньше DF, тем больше уникальность заданных терминов.
Итак, у нас дела идут лучше. А в чем проблема с ДФ? Один только DF, к сожалению, ничего нам не говорит. Например, если DF термина «компьютер» равен 100, это редкий или распространенный термин? Мы просто не знаем. Вот почему DF необходимо помещать в контекст, который соответствует размеру корпуса/коллекции. Если корпус содержит 100 документов, то термин встречается очень часто, если он содержит 1 млн документов, то термин встречается редко. Итак, давайте добавим размер корпуса, называемый N, и разделим, чтобы документировать частоту термина.
Инверсная частота документа. Источник: Manning et al., «Introduction to Information Retrieval» Звучит неплохо, верно? Но допустим, что размер корпуса равен 1000, а количество документов, содержащих термин, равно 1, тогда N/DF будет равно 1000. Если количество документов, содержащих термин, равно 2, то N/DF будет равно 500. Очевидно, небольшое изменение в DF может иметь очень большое влияние на N/DF и показатель IDF. Важно иметь в виду, что нас в основном волнует, когда DF находится в низком диапазоне по сравнению с размером корпуса. Это связано с тем, что если DF очень большой, термин используется во всех документах и, вероятно, не очень актуален для конкретной темы. В этом случае мы хотим сгладить изменение N/DF, и один из простых способов сделать это — взять логарифм N/DF. Кроме того, применение журнала может помочь сбалансировать влияние как TF, так и N/DF на окончательный результат. Таким образом, если термин встречается во всех документах коллекции, DF будет равен N. Log(N/DF) = log1 = 0, что означает, что термин не имеет никакой силы в определении релевантности.
Если количество документов, содержащих термин, равно 2, то N/DF будет равно 500. Очевидно, небольшое изменение в DF может иметь очень большое влияние на N/DF и показатель IDF. Важно иметь в виду, что нас в основном волнует, когда DF находится в низком диапазоне по сравнению с размером корпуса. Это связано с тем, что если DF очень большой, термин используется во всех документах и, вероятно, не очень актуален для конкретной темы. В этом случае мы хотим сгладить изменение N/DF, и один из простых способов сделать это — взять логарифм N/DF. Кроме того, применение журнала может помочь сбалансировать влияние как TF, так и N/DF на окончательный результат. Таким образом, если термин встречается во всех документах коллекции, DF будет равен N. Log(N/DF) = log1 = 0, что означает, что термин не имеет никакой силы в определении релевантности.
Вместе мы можем определить оценку TF-IDF следующим образом:
TF-IDF. Источник: Manning et al., «Introduction to Information Retrieval» 2. 2 BM25
2 BM25
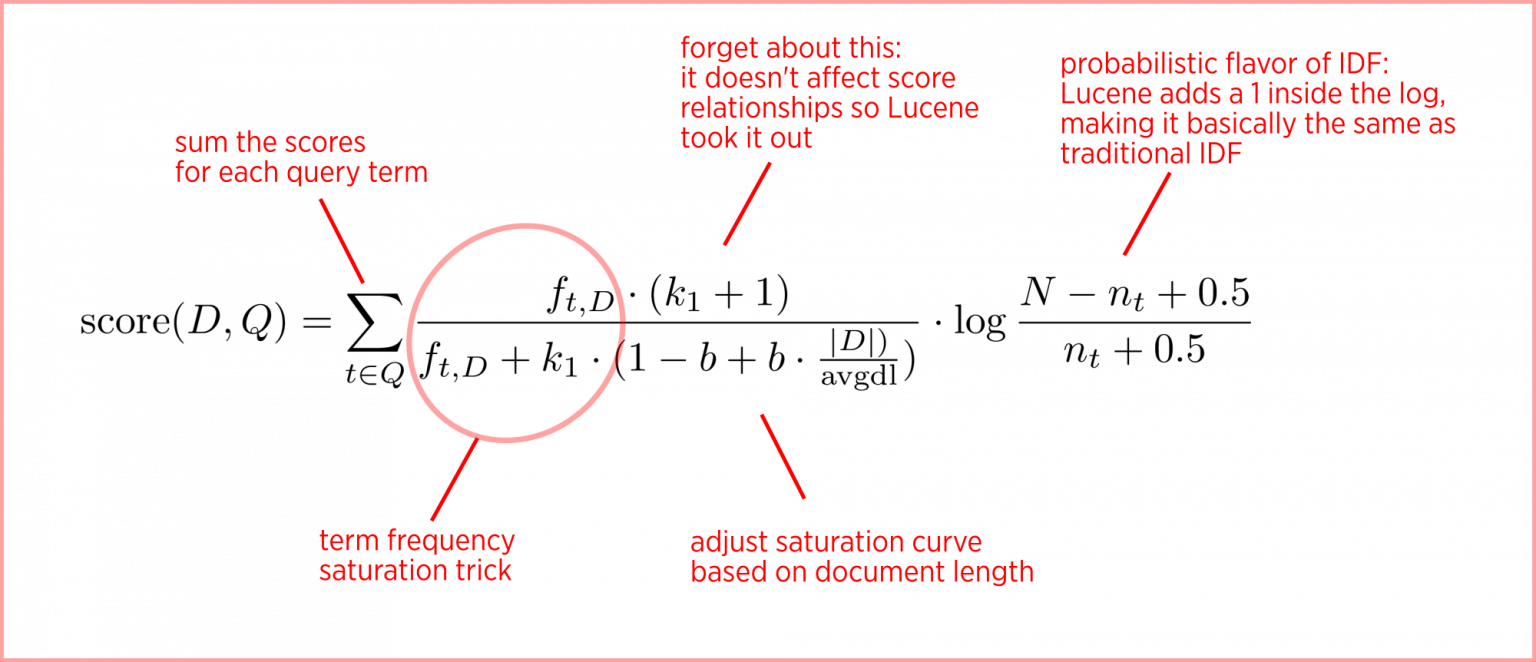
BM25 представляет собой вероятностную структуру поиска, которая расширяет идею TF-IDF и устраняет некоторые недостатки TF-IDF, связанные с насыщением терминов и длиной документа. . Полная формула BM25 выглядит немного пугающе, но вы могли заметить, что IDF является частью формулы BM25. Давайте разобьем оставшуюся часть на более мелкие компоненты, чтобы понять, почему это имеет смысл.
Формула BM25. Источник: Manning et al., «Introduction to Information Retrieval»Насыщение терминов и убывающая отдача
содержит 50 вхождений? Мы могли бы утверждать, что если термин «компьютер» встречается достаточно много раз, документ почти наверняка релевантен, и любые другие упоминания не увеличивают вероятность релевантности. Итак, мы хотим контролировать вклад TF, когда срок, вероятно, будет насыщен. BM25 решает эту проблему, вводя параметр k1, который управляет формой этой кривой насыщения. Это позволяет нам экспериментировать с различными значениями k1 и смотреть, какое значение работает лучше всего.
Вместо использования TF мы будем использовать следующее: (k1+1)* TF / (TF + k1)
Итак, что это дает нам? Он говорит, что если k1 = 0, то (k1+1)*TF/TF+ k1 = 1. В этом случае BM25 теперь оказывается IDF. Если k стремится к бесконечности, BM25 будет таким же, как TF-IDF. Параметр k1 можно настроить таким образом, что i f TF увеличивается, в какой-то момент оценка BM25 будет насыщена , как видно на рисунке ниже, что означает, что увеличение TF больше не вносит большого вклада в счет.
TF и кривая насыщения BM25 с использованием параметра k1. Источник: Author ImageНормализация длины документа
Другая проблема, которая не учитывается в TF-IDF, — это длина документа. Если документ очень короткий и однажды содержит слово «компьютер», это уже может быть хорошим индикатором релевантности. Но если документ действительно длинный и термин «компьютер» встречается только один раз, вполне вероятно, что документ не о компьютерах. Мы хотим дать вознаграждение за совпадение терминов с короткими документами и оштрафовать за длинные. Тем не менее, вы не хотите чрезмерно наказывать, потому что иногда документ длинный, потому что он содержит много релевантной информации, а не просто много слов. Итак, как мы можем этого добиться? Введем еще один параметр b, который используется для построения нормализатора: (1-b) +b*dl/dlavg в формуле BM25. Чтобы он работал, значение параметра b должно быть между 0 и 1. Теперь оценка BM25 будет следующей:
Мы хотим дать вознаграждение за совпадение терминов с короткими документами и оштрафовать за длинные. Тем не менее, вы не хотите чрезмерно наказывать, потому что иногда документ длинный, потому что он содержит много релевантной информации, а не просто много слов. Итак, как мы можем этого добиться? Введем еще один параметр b, который используется для построения нормализатора: (1-b) +b*dl/dlavg в формуле BM25. Чтобы он работал, значение параметра b должно быть между 0 и 1. Теперь оценка BM25 будет следующей:
Во-первых, давайте разберемся, что означает, что документ может быть коротким или длинным. Опять же, документ считается длинным или коротким в зависимости от контекста корпуса. Один из способов принять решение — использовать среднюю длину корпуса в качестве точки отсчета. Длинный документ — это просто документ, который на длиннее средней длины корпуса на , а короткий — короче средней длины корпуса. Что этот нормализатор делает для нас? Как видно из формулы, когда b равно 1, нормализатор превратится в (1–1 + 1*dl/dlavg). С другой стороны, если b равно 0, все становится равным 1, и влияние длины документа вообще не учитывается.
Что этот нормализатор делает для нас? Как видно из формулы, когда b равно 1, нормализатор превратится в (1–1 + 1*dl/dlavg). С другой стороны, если b равно 0, все становится равным 1, и влияние длины документа вообще не учитывается.
Если длина документа (dl) больше средней длины документа, этот документ получает штраф и получает более низкую оценку. Параметр b определяет, насколько сильными будут штрафы для этих документов: чем выше значение b, тем выше штраф для больших документов, потому что влияние длины документа по сравнению со средней длиной корпуса сильнее. С другой стороны, документы размером меньше среднего вознаграждаются и дают более высокий балл.
Длина документа и показатель BM25 с использованием параметра b. Источник: Автор ИзображениеТаким образом, TF-IDF вознаграждает за частоту терминов и штрафует за частоту документов. BM25 выходит за рамки этого, чтобы учитывать длину документа и насыщенность частоты терминов.
2.3. Языковые модели
Одна из центральных идей языкового моделирования заключается в том, что когда пользователь пытается создать хороший поисковый запрос, он или она выдает термины, которые, вероятно, появятся в соответствующем документе. Другими словами, релевантный документ — это документ, который может содержать термины запроса. Что отличает языковое моделирование от других вероятностных моделей, так это то, что оно создает языковая модель для каждого документа, из которого генерируются вероятности, соответствующие вероятности того, что запрос может быть найден в этом документе. Эта вероятность определяется как P(q|M_d).
Другими словами, релевантный документ — это документ, который может содержать термины запроса. Что отличает языковое моделирование от других вероятностных моделей, так это то, что оно создает языковая модель для каждого документа, из которого генерируются вероятности, соответствующие вероятности того, что запрос может быть найден в этом документе. Эта вероятность определяется как P(q|M_d).
Определение языковой модели — это функция, которая производит вероятности для слова или набора слов (например, (часть) предложения) с учетом словарного запаса. Давайте посмотрим на пример модели, которая производит вероятности для отдельных слов:
Пример языковой модели. Источник: Автор Изображение Вероятность предложения «кошка любит рыбу» равна 0,3×0,2×0,2 = 0,012, тогда как вероятность предложения «собака любит кошку» равна 0,1×0,2×0,3 = 0,006 . Это означает, что термин «кошка любит рыбу» чаще встречается в документе, чем «собака любит кошку». Если мы хотим сравнить разные документы с одним и тем же поисковым запросом, мы производим вероятность для каждого документа отдельно. Помните, что каждый документ имеет свою языковую модель с разными вероятностями.
Если мы хотим сравнить разные документы с одним и тем же поисковым запросом, мы производим вероятность для каждого документа отдельно. Помните, что каждый документ имеет свою языковую модель с разными вероятностями.
Другой способ интерпретации этих вероятностей состоит в том, чтобы спросить, насколько вероятно, что эта модель генерирует предложение «кошка любит рыбу» или «собака любит кошку». С технической точки зрения вы также должны включить вероятности того, насколько вероятно, что предложение продолжится или остановится после каждого слова. Эти предложения не обязательно должны существовать в документе и не должны иметь смысла. В этой языковой модели, например, предложения «кошка любит рыбу» и «сом-рыба-рыба» имеют одинаковую вероятность, другими словами, они с одинаковой вероятностью будут генерироваться.
Языковая модель из приведенного выше примера называется модель языка униграмм, это модель, которая оценивает каждый термин независимо и игнорирует контекст.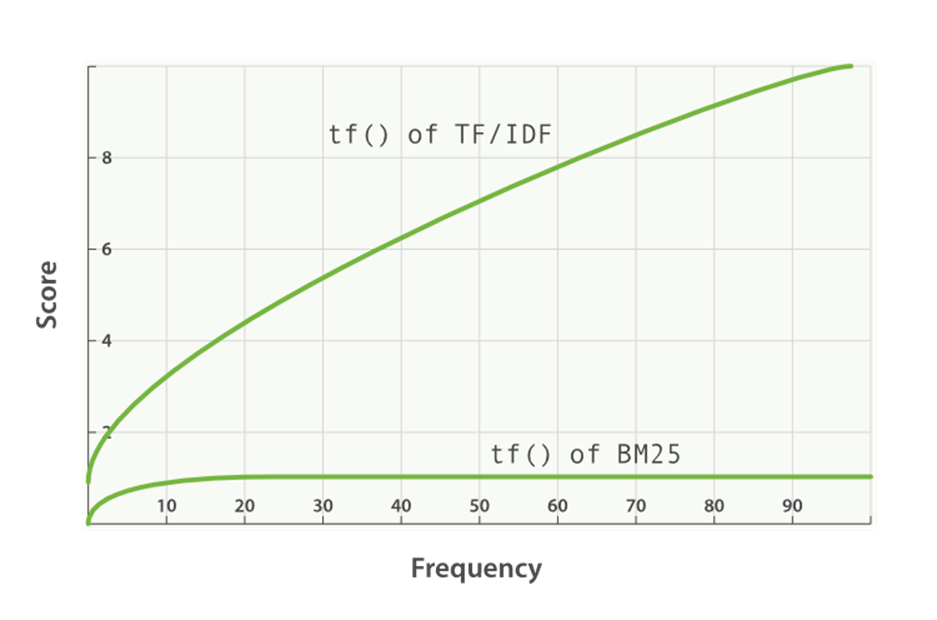 Одной из языковых моделей, в которой включает контекст, является языковая модель биграмм . Эта модель включает условные вероятности для терминов при условии, что им предшествует другой термин. Вероятность того, что «кошка любит рыбу», будет равна P(кошка) x P(нравится|кошка) x P(рыба|нравится) . Это, конечно, требует существования всех условных вероятностей.
Одной из языковых моделей, в которой включает контекст, является языковая модель биграмм . Эта модель включает условные вероятности для терминов при условии, что им предшествует другой термин. Вероятность того, что «кошка любит рыбу», будет равна P(кошка) x P(нравится|кошка) x P(рыба|нравится) . Это, конечно, требует существования всех условных вероятностей.
Существуют более сложные модели, но они реже используются. Каждый документ создает новую языковую модель, но обучающих данных в одном документе часто недостаточно для точного обучения более сложной модели. Это напоминает компромисс между смещением и дисперсией. Сложные модели имеют высокую дисперсию и склонны к переобучению на небольших обучающих данных.
Сопоставление с использованием модели вероятности запроса
При ранжировании документов по степени их релевантности запросу нас интересует условная вероятность P(d|q). В модели вероятности запроса эта вероятность является так называемой ранговой эквивалентностью в P(q|d), так что нам нужно использовать только вероятности, обсуждавшиеся выше. Чтобы понять, почему они ранговых эквивалентов , давайте посмотрим на правило Байеса:
Чтобы понять, почему они ранговых эквивалентов , давайте посмотрим на правило Байеса:
P(d|q) = P(q|d) P(d) / P(q)
Поскольку P(q) имеет одинаковое значение для каждого документа, это никак не повлияет на ранжирование. P(d), с другой стороны, рассматривается как однородный для простоты и поэтому также не влияет на ранжирование (например, в более сложных моделях P(d) можно сделать зависимым от длины документа). Итак, вероятность P(d|q) эквивалентна P(q|d). Другими словами, в модели вероятности запроса следующие два ранга эквивалентны :
- Вероятность того, что документ d релевантен запросу q.
- Вероятность того, что запрос q сгенерирован языком документа d.
Когда пользователь создает запрос, у него уже есть представление о том, как может выглядеть соответствующий документ. Термины, используемые в запросе, с большей вероятностью появятся в релевантных документах, чем в нерелевантных документах. Одним из способов оценки вероятности P(q|d) для модели униграмм является использование оценки максимального правдоподобия: модель правдоподобия
запросов.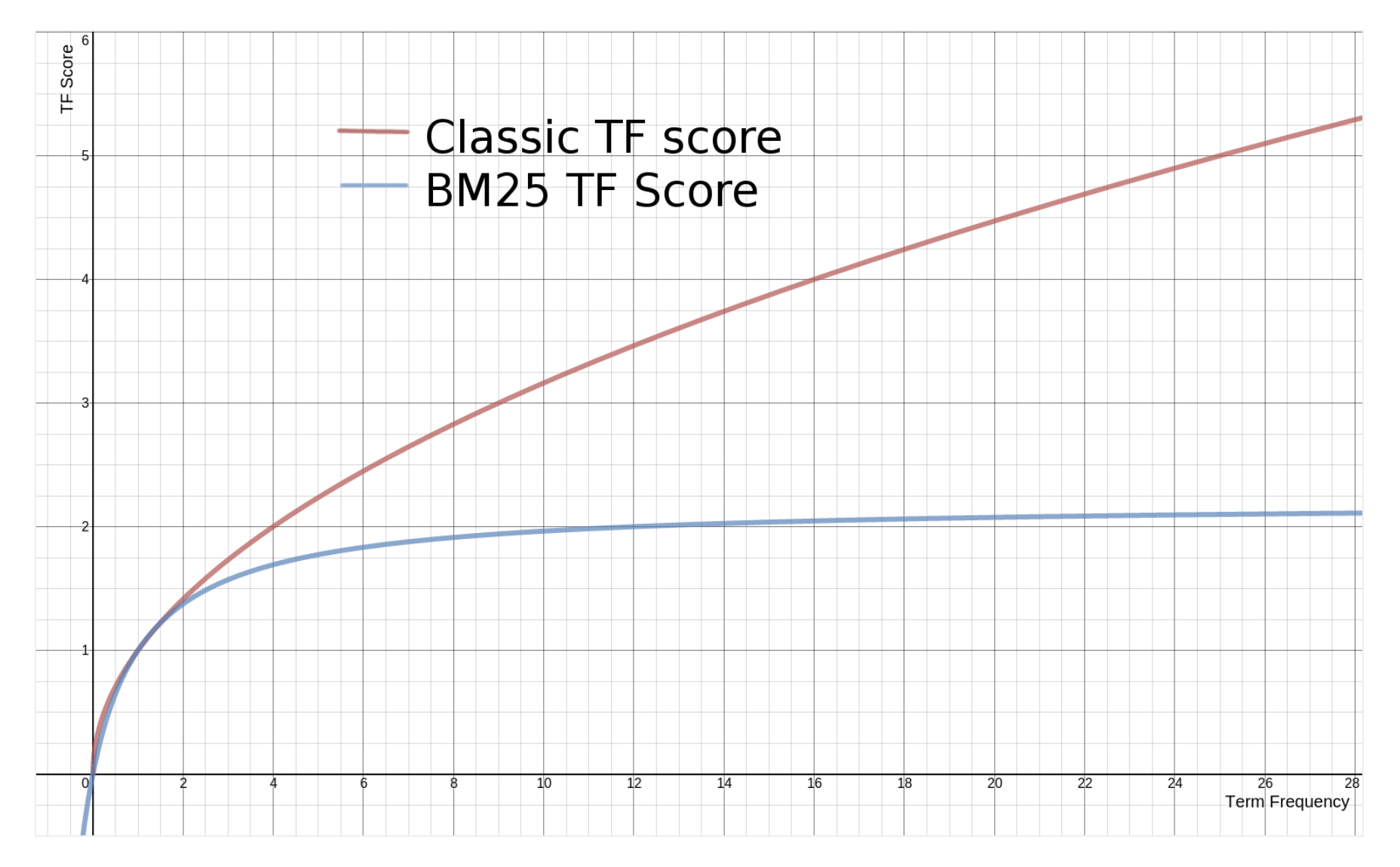 Источник: Мэннинг и др., «Введение в поиск информации»
Источник: Мэннинг и др., «Введение в поиск информации», где tf_t,d — частота термина t в документе d, а L_d — размер документа d. Другими словами, подсчитайте долю частоты появления каждого слова запроса в документе d по сравнению со всеми словами в этом документе, а затем перемножьте все эти доли друг с другом.
В приведенной выше формуле есть две небольшие проблемы. Во-первых, если одно из условий запроса не встречается в документе, вся вероятность P(q|d) будет равна нулю. Другими словами, единственный способ получить ненулевую вероятность — это если каждый термин в запросе появляется в документе. Вторая проблема заключается в том, что вероятность терминов, встречающихся в документе реже, может быть завышена.
Методы сглаживания
Решение упомянутых выше проблем состоит в том, чтобы ввести методов сглаживания, которые помогут путем создания ненулевых вероятностей для терминов, не фигурирующих в документе, и создания эффективных весов для частые термины. Существуют различные методы сглаживания, такие как сглаживание Елинека-Мерсера, в котором используется линейная комбинация оценок максимального правдоподобия для конкретного документа и коллекции:
Существуют различные методы сглаживания, такие как сглаживание Елинека-Мерсера, в котором используется линейная комбинация оценок максимального правдоподобия для конкретного документа и коллекции:
Или сглаживание Дирихле:
Сглаживание Дирихле. Источник: Manning et al., «Introduction to Information Retrieval». Но это тема для другого сообщения в блоге.
Таким образом, традиционные методы поиска на основе терминов просты в реализации, а такой метод, как BM25, является одним из наиболее широко используемых функций поиска информации из-за его неизменно высокой точности поиска. Однако они решают проблему, основанную на представлении Bag-of-Words (BoW), поэтому они сосредоточены только на точном синтаксическом сопоставлении и, следовательно, не учитывают семантически связанные слова.
Страница не найдена – Khoury College Development
В мире, где информатика (CS) везде, CS для всех.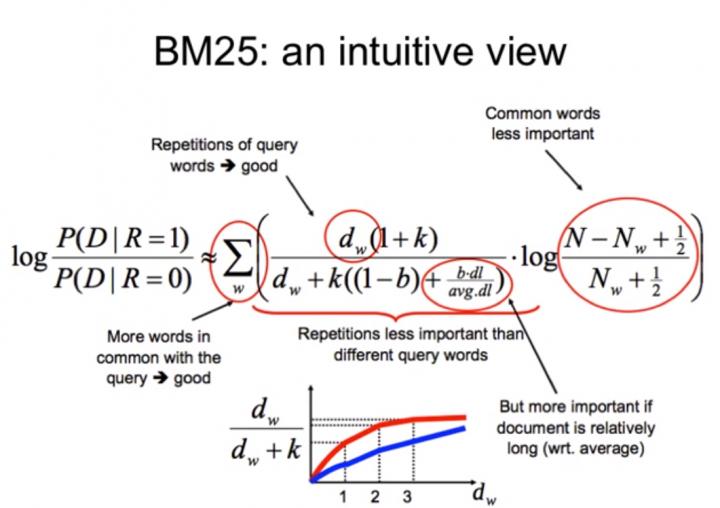 CS пересекает все дисциплины и отрасли.
CS пересекает все дисциплины и отрасли.
Колледж компьютерных наук Хури стремится создавать и развивать разнообразную инклюзивную среду.
Колледж Хури, первый в стране колледж информатики, основанный в 1982 году, вырос в размерах, разнообразии, программах на получение степени и превосходстве исследований.
В наших региональных кампусах, расположенных в промышленных и технологических центрах, Колледж Хури предлагает сильные академические программы в оживленных городах для жизни, работы и учебы.
Khoury College — это сообщество людей, занимающихся обучением, наставничеством, консультированием и поддержкой студентов по всем программам.
Программы награждения колледжей и университетов проливают свет на выдающихся преподавателей, студентов, выпускников и отраслевых партнеров.
Наши реальные исследования, выдающиеся преподаватели, выдающиеся докладчики, энергичные выпускники и разнообразные студенты рассказывают свои истории и попадают в новости.
В Колледже Хури обучение происходит в классе и за его пределами. Мероприятия в нашей сети кампусов обогащают образовательный опыт.
Информатика повсюду. Студенты Khoury College занимаются соответствующей работой, исследованиями, глобальными исследованиями и опытом обслуживания, которые помогают им расти.
Студенты магистратуры углубляют свои знания, работая над проектами, приобретая профессиональный опыт и помогая исследователям.
Работа над исследованиями с преподавателями занимает центральное место в работе доктора философии. Докторанты Колледжа Хури также могут проводить исследования с отраслевыми партнерами.
Преподаватели и студенты Колледжа Хури проводят эффективную работу по различным дисциплинам. Благодаря широкому спектру областей исследований мы каждый день решаем новые проблемы в области технологий.
Наши институты и исследовательские центры объединяют ведущих академических, отраслевых и государственных партнеров для использования вычислительной мощности.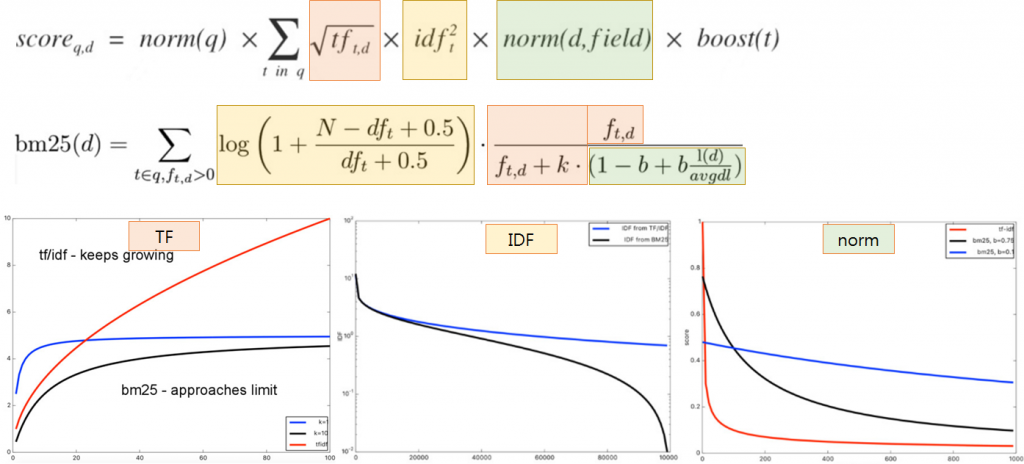
Исследовательские проекты, разработанные и проводимые преподавателями мирового уровня Khoury College, вовлекают студентов и других исследователей в получение новых знаний.
Исследовательские лаборатории и группы сосредотачиваются на ряде проблем в определенном контексте, поощряя исследования и сотрудничество.
Эта новая инициатива направлена на устранение рисков для конфиденциальности и личных данных с помощью коллективных усилий на низовом уровне с упором на прозрачность и подотчетность.
Современное оборудование, бесшовные системы и инновационные лаборатории и пространства позволяют нашим преподавателям и студентам проводить передовые исследования.
Колледж Хури гордится своим инклюзивным сообществом, основанным на сотрудничестве. Каждый день мы стремимся создавать программы, которые приветствуют самых разных студентов в CS.
Более 20 компьютерных клубов в колледже Хури и на Северо-Востоке предлагают что-то для каждого студента. Мы всегда рады новым членам на каждом уровне.
Мы всегда рады новым членам на каждом уровне.
Учащиеся учатся в современных классах, конференц-залах для совместной работы, а также в ультрасовременных лабораториях и исследовательских центрах.
Сети обеспечивают безопасную и бесперебойную работу кода, современное и надежное оборудование, а наша квалифицированная системная команда управляет поддержкой и обновлениями.
Заинтригован Колледжем Хури и северо-восточным университетом? Начните здесь, чтобы увидеть общую картину: академические науки, экспериментальное обучение, студенческая жизнь и многое другое.
Готовы сделать следующий шаг в технической карьере? Наши магистерские программы сочетают в себе академическую строгость, исследовательское превосходство и значимые экспериментальные возможности.
Добро пожаловать в магистерскую программу Align, предназначенную для людей, готовых добавить информатику (CS) в свой набор навыков или переключиться на совершенно новую карьеру в области технологий.