Что такое атрибут rel=canonical? SEO-проверка канонических страниц онлайн. Как правильно использовать тэг для ссылок и пагинации?
Что такое атрибут rel=»canonical»
Атрибут rel="canonical" применяется для указания поисковым системам канонической страницы. Каноническая страница — это страница на сайте, которая является предпочтительной для индексации в поисковых системах. Поисковый робот, обнаружив атрибут rel="canonical" на какой-либо странице, вместо нее проиндексирует ту страницу, адрес которой указан в данном атрибуте (каноническую ссылку). В отличие от редиректа, использование rel="canonical" переадресует на другую страницу не пользователей, а только поисковые системы.
Как прописать атрибут rel=»canonical» в коде страницы
Задается он с помощью тега LINK с атрибутом rel=”canonical” в блоке HEAD. Для этого необходимо поместить в HEAD следующую запись:
<link rel=”canonical” href=”канонический адрес URL” />
Где «канонический URL» – указывает страницу, которую вы считаете предпочтительной для появления в результатах поиска.
Пример употребления атрибута:
Обязательно использовать относительный (полный) путь на страницу!
Зачем указывать канонический url?
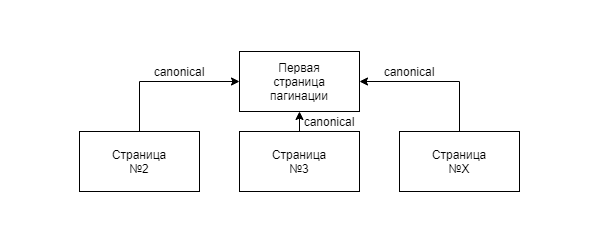
Этот атрибут применяется в тех случаях, когда на сайте имеются страницы с идентичным или очень похожим контентом. Так же используется для страниц пагинации в интернет-магазинах (первую страницу выбирают для сканирования, остальные — неканонические страницы — игнорируются). Чтобы поисковая система не расценивала такие адреса страниц как дубли, необходимо разместить на них ссылку на одну страницу предпочтительную для индексации каноничную страницу. Таким образом в выдаче появится только одна страница (каноническая версия). Это один из самых простых способов борьбы с дублированием контента. Более подробно изучить информацию про дубли страниц и способы борьбы с ними вы сможете в нашей статье Дубли страниц на сайте.
Почему это важно для поисковых систем?
Атрибут rel=canonical позволяет поисковым системам определить среди страниц с одинаковым содержанием основную, которую нужно проиндексировать и вывести в результаты поиска.
Информация от Яндекс о поддержке поисковыми роботами rel=canonical появилась в 2011 году. Кроме того, Вы можете ознакомиться с рекомендациями от Яндекс по употреблению rel=canonical в разделе Яндекс.Помощь.
Google также официально рекомендует использовать rel=canonicalдля борьбы с повторяющимися URL. Об этом можно прочитать в руководстве Консолидация повторяющихся URL.
Почему нужно знать, на каких страницах сайта есть rel=canonical?
Очень важно знать, на каких страницах вашего сайта употребляется этот атрибут, поскольку в некоторых случаях канонические страницы могут быть указаны неверно или ссылка может вести не ту страницу, на которую нужно. Это может обернуться для вас ошибками в индексации — одни страницы вашего сайта могут не проиндексироваться, а другие URL будут ошибочно указаны каноническими.
Например, известен кейс, когда на всех страницах сайта в качестве канонической прописали главную страницу, поэтому поисковые системы не могли проиндексировать все остальные страницы веб-ресурса.
Как обнаружить на сайте страницы с rel=canonical?
Это можно сделать с помощью сервиса Labrika. Отчет «Страницы с rel=»canonical» вы можете найти в разделе «Технический аудит» левого бокового меню. Страница с отчетом выглядит следующим образом:
Отчет показывает:
- URL-адрес страницы, на которой найден атрибут
rel=canonical. - URL, указанный в ссылке с
rel=canonicalв качестве канонического. - Код ответа страницы, которая прописана как каноническая — код 200 говорит об успешной обработке запроса (страница доступна).
- Разрешен ли канонический URL для индексации.
Поставив галочки около нужных пунктов в верхней части отчета, можно отфильтровать его содержимое так, чтобы отображались данные только по
rel=canonical с выбранными параметрами. Тогда вы сможете проверить наличие конкретных ошибок в указании канонической страницы.Какие виды ошибок rel=canonical поможет определить Labrika?
Страницы с несколькими rel=canonical
На странице может быть указан только один канонический URL. В случае нескольких объявлений
В случае нескольких объявлений rel=canonical Google и Яндекс проигнорируют все указания канонических страниц.
Страницы с кросс-доменным rel=canonical
Чаще всего ссылка на другой домен при использовании атрибута rel=canonical происходит по ошибке. Если в качестве канонического адреса указан URL на другом домене или субдомене, Яндекс не учитывает канонический адрес. Google допускает выбор основного URL на стороннем домене, но рекомендует проверить правильность такого указания.
Ссылки с rel=canonical на несуществующие страницы
Страница, содержащая rel=canonical, ссылается на несуществующую страницу (ошибка 404). Пользователи не смогут попасть на такие страницы, а поисковые системы исключают их из индекса. Страница, прописанная в атрибуте rel=canonical, должна быть доступна и отдавать код ответа 200.
Указание главной страницы в качестве канонической на всех страницах сайта
Это считается грубой ошибкой, поскольку тогда все страницы веб-ресурса, кроме главной, не будут проиндексированы и не попадут в результаты поиска.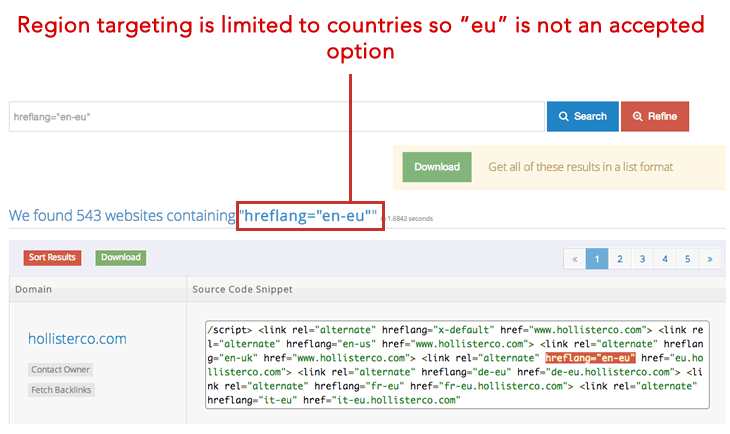
Канонический URL заблокирован для индексации
Не следует запрещать индексирование страниц, которые указаны как канонические. Это не позволит поисковым роботам их проиндексировать, и они не смогут участвовать в поиске. Если указанная в rel=canonicalстраница заблокирована от индексации, нужно снять блокировку или указать в качестве канонической другую страницу, которая доступна для индексирования.
В URL-адресе отсутствует префикс http или https
Абсолютные URL-адреса должны указывать полный путь к канонической странице, включая обозначение протокола (http:// или https://), например:
https:// mysite.ru/blog/page?id=2364, а не /blog/page?id=2364.
rel = canonical найден в <body>
Атрибут rel=canonical должен располагаться только между тегами <head> и </head>. Когда вы ставите rel=canonical в блок <body>, то он игнорируется.
Используйте данные отчета Labrika «Страницы с rel=canonical», чтобы найти и исправить ошибки в указании канонических страниц . Код ответа 200 говорит об успешной обработке запроса (страница доступна). При нажатии на эту кнопку вы скачаете отчет в формате Excel. Ссылка, с помощью которой можно скопировать отчет и отправить другому пользователю. Отчет будет доступен даже тем, кто не имеет аккаунта в Labrika. После получения данных о канонических страницах на сайте вы сможете увидеть ошибки, если они есть и исправить их и избежать проблем с индексацией.
Руководство по использованию атрибута rel=canonical вы найдете в отдельной статье нашего сайта.
Использование канонических ссылок (атрибут rel=canonical)
Заказать сайт
Искать везде
- Искать везде
- CMS
- Интернет-магазин 2.
 0
0 - Интернет-магазин 1.0
- Onicon
- Maliver
- Rekmala
- Pablex
- Кабинет и почта
- CRM
- Интеграции CMS.S3
 0
0Главная / Редактирование сайта / Как мне настроить сайт? / Настройки SEO / SEO-панель сайта / Использование канонических ссылок (атрибут rel=canonical)
С помощью описанной в данной инструкции функции вы сможете подключить к страницам на своем сайте атрибут rel=canonical.
Данный атрибут необходим для оптимизации сайта и борьбы c дублирующим контентом, иными словами, атрибут показывает, какую страницу из ряда дублирующих/похожих страниц считать приоритетной, а какие дочерними. Именно каноническая страница будет отображаться в поиске и иметь наибольший ссылочный вес по сравнению с другими страницами с дублирующим содержанием.
Работает это следующим образом:
- Все страницы с пагинацией (с номерами страниц в адресе) будут считаться дочерними по отношению к основной странице (иными словами, если у вас есть страница «shop/catalog» — она будет считаться приоритетной, а все последующие за ней страницы «shop/catalog/p/1», «shop/catalog/p/2» и т.д. будут дочерними).
- Все страницы с get-параметрами в адресе (со специальными параметрами, идущими в адресе после символа «?») будут считаться дочерними по отношению к основной странице без get-параметров (например, у вас на сайте есть статья по адресу «news/novoe_postulenie», она всегда будет считаться основной, тогда как все аналогичные адреса, содержащие метки из сервисов сбора аналитики или иные дополнительные параметры, уже будут считаться дочерними, в нашем примере адрес вида «news/novoe_postulenie?utm_source=metka&utm_medium=postuplenie&utm_campaign=article» будет уже дочерним.
Теперь рассмотрим, как подключить атрибут rel=canonical к своему сайту.
Шаг 1
Перейдите к разделу «SEO панель».
Шаг 2
На открывшейся странице перейдите к пункту «Использовать канонические ссылки».
Шаг 3
Затем отметьте соответствующую галочку и сохраните изменения.
Обратите внимание!
- В случае если ранее на вашем сайте производились какие-либо дополнительные работы и в шаблоны сайта вносились правки в рамках продвижения и доработок, данный функционал может не работать. Если вы отметили галочку, но на страницах сайта с пагинацией и get-параметрами не появился атрибут «rel=canonical» или он прописан как-то некорректно, обратитесь в техническую поддержку по адресу support@megagroup.ru.
- Также стоит учитывать, что данная настройка не сработает для закрытых от индексации страниц, так как атрибут «rel=canonical» не имеет смысла на неиндексируемых страницах.
Была ли статья вам полезна?
Да
Нет
Укажите, пожалуйста, почему?
- Рекомендации не помогли
- Нет ответа на мой вопрос
- Содержание статьи не соответствует заголовку
- Другая причина
Комментарий
Что такое канонический атрибут?
Вернуться к блогу
12 декабря 2018 г.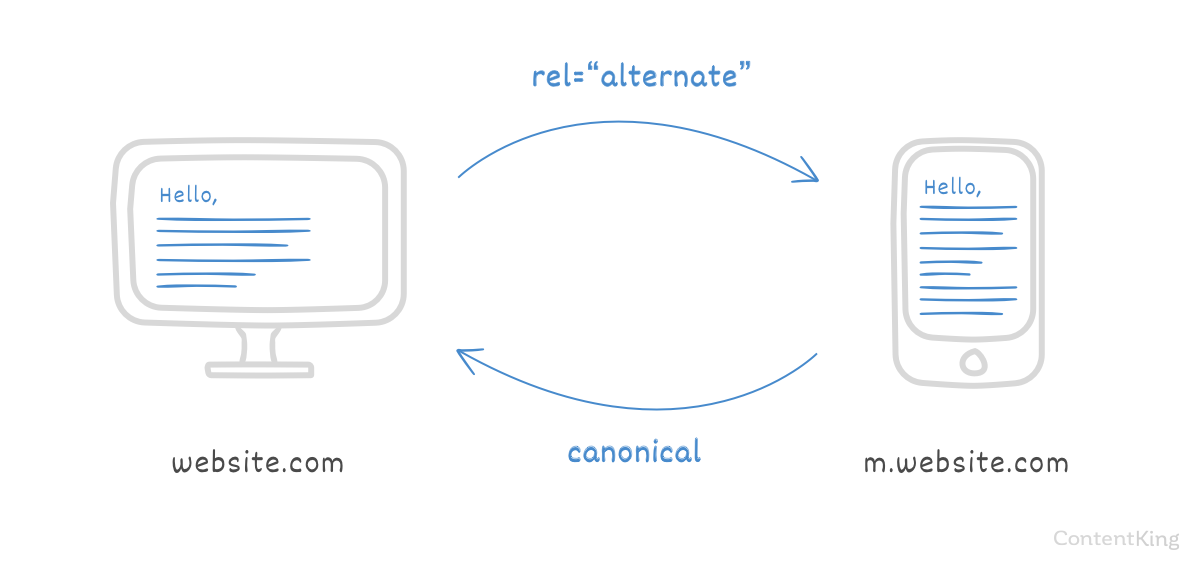
Канонический атрибут или тег — это способ объединить несколько URL-адресов с идентичным содержанием, указав, какой URL-адрес необходимо просканировать и проиндексировать сканерами поисковых систем. Сайт нередко имеет несколько URL-адресов, которые содержат идентичный или почти идентичный контент. Однако, если вы позволите сканерам поисковых систем сканировать и индексировать каждый URL-адрес, это может повредить поисковому рейтингу вашего сайта.
Вы часто будете видеть веб-сайты, использующие HTML-тег rel=»canonical», чтобы сообщить поисковым системам предпочтительный или «канонический» URL-адрес, который они хотят использовать.
Общий код HTML выглядит так:
Вы должны использовать тег canonical в любом случае, когда у вас есть один и тот же контент на нескольких URL-адресах.
Один из наиболее частых случаев использования канонических URL-адресов — это когда у вас есть защищенные и незащищенные версии URL-адреса вашего сайта.
Во-первых, ваш сайт электронной коммерции, скорее всего, будет иметь разные URL-адреса для небольших вариантов товаров, таких как цвет и размер. Например, вы можете продавать одну и ту же кожаную куртку черного, коричневого и серого цветов и разных размеров. Но когда кто-то выполняет поисковый запрос по кожаным курткам, вы не хотите, чтобы в его поиске отображались все варианты продукта.
Другая причина может заключаться в том, что у каждого посетителя вашего сайта разные URL-адреса из-за идентификаторов сеанса, но каждый отдельный URL-адрес содержит один и тот же контент.
URL-адрес вашего мобильного сайта также может отличаться от URL-адреса вашего сайта для настольных компьютеров, и сканеры поисковых систем будут индексировать его отдельно, если только им не будет указан правильный канонический тег.
Один из наиболее частых случаев использования канонических URL-адресов — это когда у вас есть защищенные и незащищенные версии URL-адреса вашего сайта, то есть версии с «www» и без «www». Каждая итерация может быть проиндексирована как отдельная страница, что создаст проблемы с дублированием контента:
- http://volusion.com
- https://volusion.com
- http://www.volusion.com
- https://www.volusion.com
Канонический URL-адрес не позволит поисковым системам индексировать URL-адреса отдельно, если они содержат другой префикс, например «www» вместо «https://www».
Вы также можете предпочесть, чтобы старые версии вашего веб-сайта были заархивированы, поэтому имеет смысл иметь отдельные URL-адреса, но вы также должны убедиться, что сканеры поисковых систем сканируют и индексируют самую последнюю версию.
URL-адреса также могут зависеть от местоположения и будут различаться в зависимости от страны. Если ваши продукты доставляются по всему миру, вы не хотите, чтобы поисковые системы индексировали каждую страну, в которую вы отправляете.
Если ваши продукты доставляются по всему миру, вы не хотите, чтобы поисковые системы индексировали каждую страну, в которую вы отправляете.
В каждом из этих случаев ваши URL-адреса содержат одно и то же содержимое, поэтому сканерам поисковых систем не нужно сканировать и индексировать каждый URL-адрес. Дублирование контента на сайте электронной коммерции неизбежно, и если вы разрешите индексировать каждый отдельный URL-адрес, это может негативно повлиять на ваш рейтинг.
Почему следует использовать канонический URL-адрес?Если вы не включаете канонический атрибут, сканеры поисковых систем в конечном итоге индексируют каждый отдельный URL-адрес, несмотря на схожесть контента на каждой странице. Затем им становится неясно, какую версию ранжировать после того, как каждый отдельный URL-адрес был проиндексирован.
Дублирующийся контент затрудняет поисковым роботам определение того, какой контент с вашего сайта релевантен поисковому запросу.

Дублированный контент негативно повлияет на рейтинг вашего сайта. Дублированный контент затрудняет поисковым роботам определение того, какой контент с вашего сайта релевантен поисковому запросу. В результате этой путаницы они отдадут предпочтение другому сайту, который, по их мнению, содержит более уникальный контент. Хотя ваш собственный контент может быть уникальным, поисковая система этого не понимает, потому что у вас есть несколько URL-адресов с одинаковым или похожим контентом.
Как добавить каноническую ссылку?
Большинство платформ электронной коммерции или систем управления контентом уже имеют атрибут canonical, встроенный в сайт, или имеют возможность добавить его в качестве подключаемого модуля. Вам просто нужно указать, какие URL-адреса необходимо сканировать, а какие являются дубликатами. Если вы хотите отсканировать код своего сайта, канонический атрибут будет выглядеть так:
К счастью, платформа управления контентом Volusion позволяет легко активировать эту удобную функцию.
После того, как вы вошли в свою панель инструментов, наведите указатель мыши на вкладку «Маркетинг» в строке меню и щелкните раздел «SEO» в раскрывающемся меню. В меню, которое появляется слева от этой страницы, найдите раздел значений по умолчанию.
Оказавшись там, прокрутите вниз до раздела «URL-адреса, удобные для поисковых систем». Появятся четыре флажка. Вы хотите убедиться, что установлен последний флажок «Включить полный URL-адрес для канонической ссылки на домашнюю страницу (включая / default.asp)». Как только вы это проверили, все готово! Если вы все еще не знаете, где найти этот инструмент, ознакомьтесь с нашей симуляцией в реальном времени о том, как включить канонический атрибут.
Похожие темы SEO
Будьте в курсе
Подпишитесь на информационный бюллетень Volusion
Получайте больше отраслевых идей, советов и эксклюзивных предложений, отправленных прямо на ваш почтовый ящик.
При подписке произошла ошибка. Попробуйте обновить страницу и отправить еще раз.
Спасибо за подписку!
Общие сведения о канонических URL-адресах: полное руководство
96 / 100
Powered by Rank Math SEO
Элемент ссылки rel=»canonical» , часто называемый каноническим URL-адресом, чрезвычайно важен, но все еще часто подвергается распространенным заблуждениям и неправильно используется даже опытными оптимизаторами, которые были в отрасль на какое-то время.
Итак, без лишних слов — в этом руководстве давайте подробно рассмотрим, что такое канонические URL-адреса, как их использовать, когда их использовать и многое другое…
В этом руководстве мы рассмотрим:
- Что такое канонические URL-адреса?
- Почему канонические теги имеют значение?
- Настройка канонических URL-адресов для записей и страниц WordPress
- Установка канонических URL-адресов вручную (дополнительно)
- Когда следует использовать канонические URL-адреса?
- Общие мифы и заблуждения о канонических URL
- Заключение. Правильное использование канонических URL-адресов важно
 Правильное использование канонических URL-адресов важно
Правильное использование канонических URL-адресов важноКанонический URL-адрес — это элемент ссылки, который можно использовать для указания поисковым системам, что все определенные URL-адреса связаны с главной страницей .
Короче говоря, они помогают указать, какая версия URL-адреса должна отображаться в результатах поиска. Это полезно, потому что в некоторых случаях, когда у вас может быть контент, доступный через несколько URL-адресов или разных веб-сайтов, вы можете использовать канонические URL-адреса, чтобы избежать дублирования контента из , что может негативно повлиять на рейтинг 9.0021 .
С технической точки зрения, канонические URL-адреса — это просто теги ссылок HTML, которые используют атрибут rel=canonical . Проще говоря, вот как работают канонические URL-адреса:
Канонический URL-адрес устанавливается путем размещения на страницах так называемого канонического тега. Теги Canonical — это просто фрагменты HTML-кода, которые определяют, что такое главная страница /основная страница для этих потенциально дублирующихся страниц.
Теги Canonical — это просто фрагменты HTML-кода, которые определяют, что такое главная страница /основная страница для этих потенциально дублирующихся страниц.
A канонический тег 9Сам 0021 представляет собой фрагмент HTML-кода , который используется для определения основных версий дублированных или похожих страниц. В целом ряде сценариев (которые мы рассмотрим в этом руководстве), когда у вас есть одинаковый или очень похожий контент, доступный по разным URL-адресам, следует использовать канонические теги, чтобы указать, какая версия является основной (или основной версией). ) и, следовательно, должны индексироваться поисковыми системами (например, Google)…
2 Почему канонические URL имеют значение? Теперь, когда вы знаете, что такое канонические теги и URL-адреса, давайте посмотрим, почему они важны, и вы должны начать рассматривать возможность установки разных канонических URL-адресов для определенных сообщений и страниц на ваших веб-сайтах.![]()
Как и следовало ожидать, Google не любит дублированный контент, главным образом потому, что это затрудняет ранжирование страниц. Другими словами:
Как Google должен знать, какую версию страницы индексировать и впоследствии ранжировать, а также как распределять «ссылочный вес»?
Слишком много дублированного контента также может повлиять на ваш «бюджет сканирования». Это означает, что Google может в конечном итоге тратить время на сканирование нескольких версий одной и той же страницы, а не другого важного контента на вашем веб-сайте.
ВАЖНО ПРИМЕЧАНИЯ
Канонические теги на самом деле не новы. Хотя возможно, что некоторые люди не сталкивались с этой концепцией (до сих пор!), на самом деле канонические теги были введены еще в 2009 году. не подходит для вашего веб-сайта.
Почему вы хотите, чтобы Google тратил время на сканирование нескольких версий одной и той же страницы вместо того, чтобы сосредоточиться на важных страницах вашего веб-сайта?
Если новые страницы, как правило, сканируются в тот же день, когда они опубликованы, веб-мастерам не следует уделять внимание краулинговому бюджету.
Центральный блог Google для веб-мастеров ( источник )
 Аналогичным образом, если на сайте менее нескольких тысяч URL-адресов, в большинстве случаев он будет сканироваться эффективно.
Аналогичным образом, если на сайте менее нескольких тысяч URL-адресов, в большинстве случаев он будет сканироваться эффективно. Хотя Google говорит, что это обычно не является проблемой, использование канонических тегов может исправить все эти потенциальные проблемы, потому что они не только позволяют вам указать [для Google], какая версия страницы должна быть проиндексированы, но и где ссылочный капитал (в просторечии называемый «ссылочным соком») должен быть консолидирован.
3 Настройка канонических URL-адресов для постов и страниц WordPressПлагин Rank Math SEO для WordPress упрощает изменение канонического URL-адреса с помощью мета-поля (как показано на рисунке ниже).
По умолчанию Rank Math использует текущий URL-адрес публикации/страницы в качестве канонического URL-адреса, поэтому вам нужно будет изменить этот параметр только в том случае, если вы хотите изменить его на что-то другое.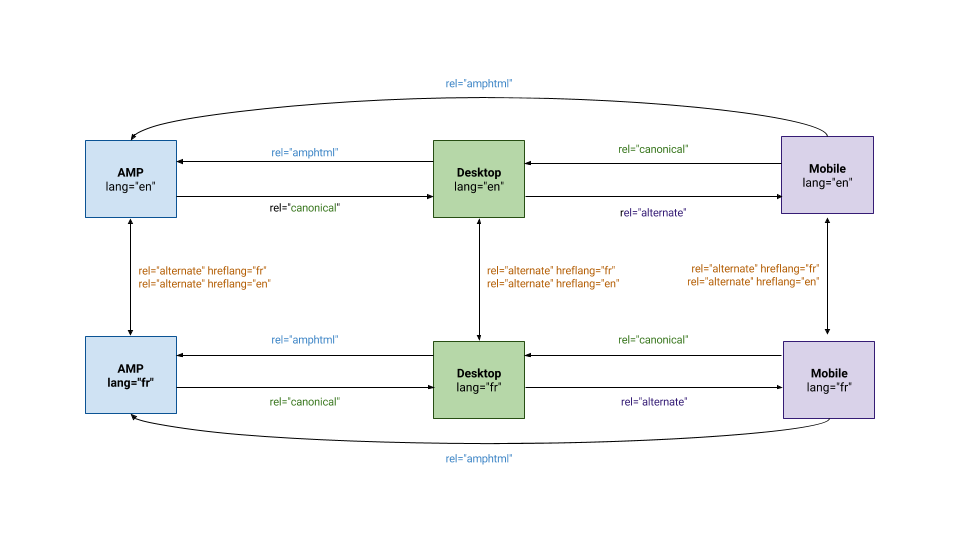
Это также известно как самоссылающийся канонический , который мы рассмотрим позже вместе со всеми другими сценариями, в которых канонизация полезна.
4 Настройка канонических URL-адресов вручную (дополнительно)Если ваш веб-сайт в настоящее время не использует преимущества системы управления контентом WordPress, которая в настоящее время поддерживает более 40% всех веб-сайтов в Интернете, включая такие сайты, как CNN, Bloomberg и другие. – вот как вы можете вручную установить канонические URL-адреса для страниц вашего веб-сайта…
Итак, как упоминалось ранее, канонический URL-адрес просто задается с помощью атрибута ссылки HTML rel=»canonical». Поэтому, чтобы установить его на любой странице веб-сайта, просто добавьте следующий код в раздел исходного HTML-кода веб-страницы:
Затем просто замените https://rankmath. com/about/ URL-адресом, который вы хотите установить в качестве канонического URL-адреса страницы, которую вы добавил приведенный выше код в.
com/about/ URL-адресом, который вы хотите установить в качестве канонического URL-адреса страницы, которую вы добавил приведенный выше код в.
Не уверены, что лучше реализовать перенаправление или использовать канонизацию? Самый простой способ:
Если можно использовать перенаправления для решения проблемы, используйте перенаправление . Однако используйте канонические URL-адреса, если вы все еще хотите, чтобы обе версии страницы были доступны (только не в результатах поиска), и для этого просто невозможно использовать перенаправления. Другими словами, если веб-страница идентична или почти идентична и не служит никакой дополнительной цели в том, чтобы быть доступной для Интернета (например, для пользователей вашего сайта или поисковых систем), просто перенаправьте ее на то, что вы считаете приоритетным.
А когда это невозможно, потому что обе страницы по-прежнему служат действительной и ценной цели в том, что они доступны, используйте канонический URL-адрес, чтобы указать, какую из связанных страниц вы предпочитаете, чтобы поисковые системы рассматривали как исходную/главную страницу.
5.2 Нужен ли страницам самоссылающийся канонический URL?На изображении Rank Math SEO Meta Box, которое появилось ранее в этом посте, мы не связывали другую страницу, вставляя URL-адрес, но канонический URL-адрес был установлен на саму текущую страницу.
Настоятельно рекомендуется иметь элементы ссылки rel=canonical на всех страницах, главным образом потому, что это было принято в качестве передовой практики с тех пор, как Google подтвердил, что это лучший способ справиться с этим.
Потенциальный побочный эффект отсутствия самоссылающихся канонических URL-адресов на страницах, которые указывают на обычную версию URL-адреса, приводит к ошибкам дублирования содержимого. Вот почему добавление канонического канонического к URL-адресам является хорошей практикой — и вам будет приятно узнать, что плагин Rank Math SEO уже делает это, поэтому вам не нужно об этом беспокоиться.
Вот почему добавление канонического канонического к URL-адресам является хорошей практикой — и вам будет приятно узнать, что плагин Rank Math SEO уже делает это, поэтому вам не нужно об этом беспокоиться.
Большинство людей считают, что на их веб-сайте нет дублирующегося контента, потому что они очевидно, не публиковали один и тот же контент снова и снова намеренно. При этом это не обязательно так, потому что поисковые системы сканируют отдельные URL-адреса, а не страницы на вашем сайте.
Да, это действительно означает, что они будут видеть rankmath.com/blog/seo-audit и rankmath.com/blog/seo-audit ?id=123 как уникальные страницы, несмотря на то, что это одна и та же фактическая страница либо с очень похожими, либо точно такое же содержание.
https://rankmath.com/blog/seo-audit/
https://rankmath.com/blog/seo-audit/?utm_source=active%20users&utm_medium=email
http://rankmath.com/ wordpress/seo-plugin/?utm_medium=twitter
URL-адреса со строками запроса, подобными приведенному выше, известны как параметризованные URL-адреса и могут вызывать проблемы с дублированием контента на веб-сайтах, особенно на тех, которые позволяют фильтровать, например веб-сайты электронной коммерции.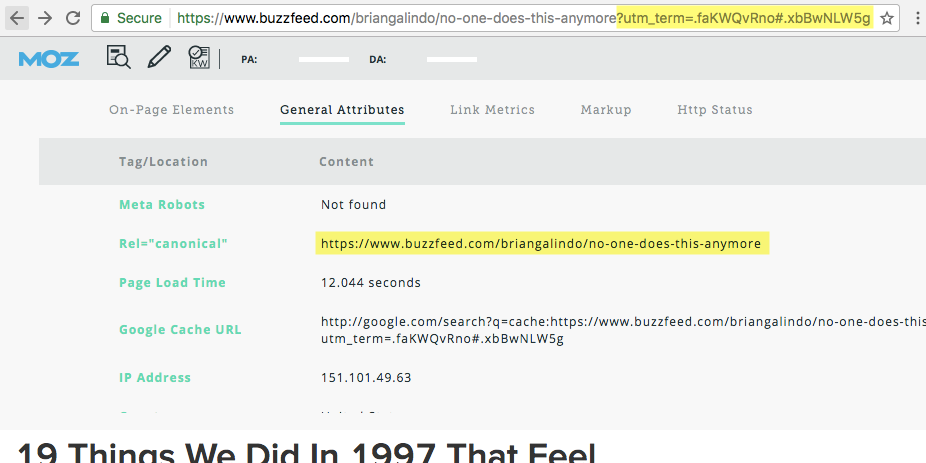
Вот почему самоссылающихся канонических символов невероятно полезны . Люди часто могут ссылаться на URL-адреса с запросами и параметрами UTM, а это означает, что когда это происходит, Google может начать выбирать URL-адрес с параметрами в качестве канонической версии. Таким образом, использование канонических ссылок на самих себя помогает избежать этой ситуации, явно указывая, какой URL-адрес вы считаете наиболее важной или основной версией этой страницы.
5.3 Междоменные канонические URL-адреса Если у вас есть один и тот же контент в нескольких доменах, вы также можете использовать канонизацию. Отличным примером этого являются некоторые веб-сайты, которые очищают и публикуют контент с веб-сайтов, которые не являются их собственными, возможно, курируя статьи в определенной нише. Если канонический URL-адрес указывает на исходный источник контента (там, где он был впервые опубликован), то любые ссылки, указывающие на вторую версию, будут учитываться как исходная каноническая версия, что повышает шансы исходного контента на ранжирование.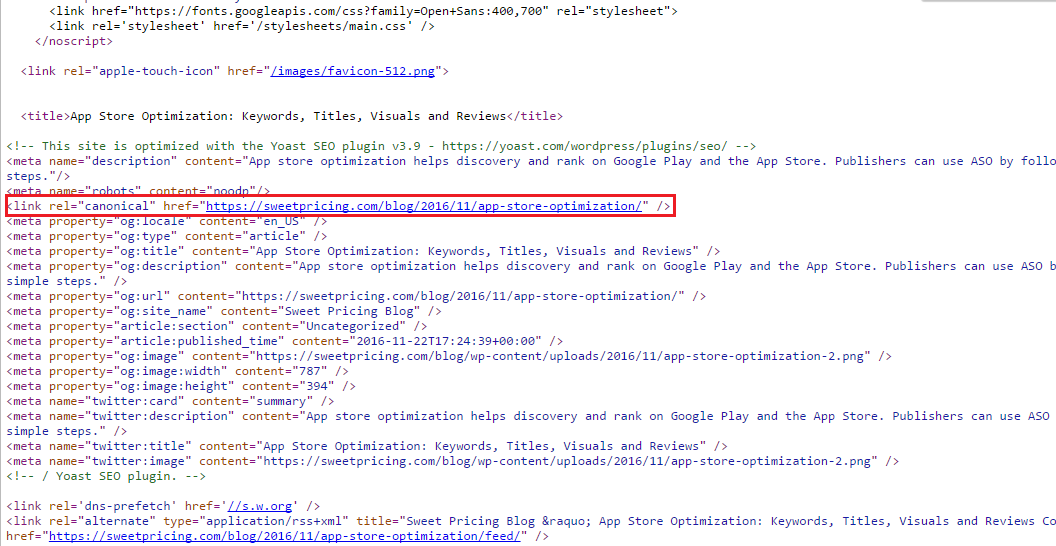
HTML-документы AMP, необходимые для установки канонических URL-адресов на всех страницах AMP, которые ссылаются на не-AMP-эквивалент (или ссылаются на AMP-страницу самостоятельно, если нет доступного эквивалента). Канонический тег является обязательным элементом HTML для действительного контента AMP, и в тех случаях, когда это возможно, канонический тег должен указывать на исходную не-AMP версию контента.
Примечание: В таких случаях исходная не-AMP-версия контента, которая используется в качестве канонического URL-адреса в эквиваленте AMP-страницы, сама по себе не может быть неиндексируемой (любым методом, включая перенаправление 301, другой канонический URL и т. д.)
Это связано с тем, что поисковые системы будут получать противоречивые сообщения, из-за чего весьма вероятно, что AMP-страница вообще не будет отображаться в результатах поиска.
TL; DR — тег canonical является обязательным элементом для AMP-страницы считаются действительными, а -канонический тег должен указывать на исходную «не- AMP » версию страницы . Если страница является автономной AMP , то каноническая страница должна быть самореферентной.
5.5 Разные версии веб-сайтов для разных устройствЕсли у вас есть сценарий с веб-сайтом, который имеет отдельные страницы для компьютеров и мобильных устройств, то есть две версии сайта, например одну на rankmath.com и мобильную версию на m. rankmath.com – следует использовать канонические URL и rel=альтернативный для указания сходства/отношения между этими двумя страницами.
Примечание. В настоящее время Google является единственной поисковой системой, официально поддерживающей эту реализацию.
На практике, вот как это будет выглядеть в десктопной и мобильной версиях веб-сайта:
Десктоп
В десктопной версии страницы канонический URL и альтернативный URL в разделе выглядят так: следует:
<голова> <ссылка rel="canonical" href="https://rankmath.com/" />
Mobile
В мобильной версии страницы канонический URL-адрес в разделе должен выглядеть следующим образом:
<ссылка rel="canonical" href="https://rankmath.com/" />
Таким образом поисковым системам будет проще понять, какую версию страницы показывать для мобильных устройств, а какую — для пользователей, выполняющих поиск на компьютере.
6 Распространенные мифы и заблуждения о канонических URLНесмотря на то, что канонизация существует уже некоторое время, ее трудно понять и легко ошибиться.
Вот несколько примеров распространенных проблем, с которыми вы можете столкнуться при использовании канонизации на своих веб-сайтах:
6. 1 Неправильное использование канонизации на многоязычных веб-сайтах
1 Неправильное использование канонизации на многоязычных веб-сайтах Многоязычные веб-сайты обычно используют теги Hreflang для хранения и отображения различных версий веб-страницы в зависимости от географического положения пользователя.
При использовании тегов hreflang вы должны указать каноническую страницу на том же языке, или, если канонический язык не существует, наилучший вариант не существует для замены языка.
При этом, если вы решите не указывать канонический URL-адрес, Google определит, что, по их мнению, является лучшей версией или URL-адресом.
Если вы используете WordPress в качестве предпочтительной системы управления контентом (которую мы настоятельно рекомендуем) и предоставляете контент посетителям веб-сайта на нескольких языках, мы настоятельно рекомендуем использовать плагин перевода Weglot для вашего веб-сайта.
Мы независимо проверили, что они выполняют канонизацию в соответствии с официальными рекомендациями Google. Еще один плагин, который мы можем порекомендовать, это TranslatePress.
6.2 Канонизация страниц с разбивкой на страницыДжон Мюллер из Google заявил, что канонизация всех страниц с разбивкой на страницы до первой страницы в серии считается неправильным использованием тега rel=canonical. Страница 2 в серии не может считаться эквивалентной странице 1, поэтому использование канонизации в этой ситуации было бы некорректным.
5.3 Также установка для канонизированного URL-адреса значения «Noindex»Использование канонизации и отсутствия индексации не имеет смысла. Просто отсутствие индексации страницы не указывает Google, какую страницу вы хотели бы объединить с другой страницей, и что сигналы ранжирования должны быть перенаправлены на указанную главную страницу .
Когда Google увидит два URL-адреса с вашего сайта, они выглядят одинаково, и вы четко сообщите нам о своих предпочтениях, мы постараемся объединить их и рассматривать как один (обычно более надежный) URL-адрес, а не как отдельные.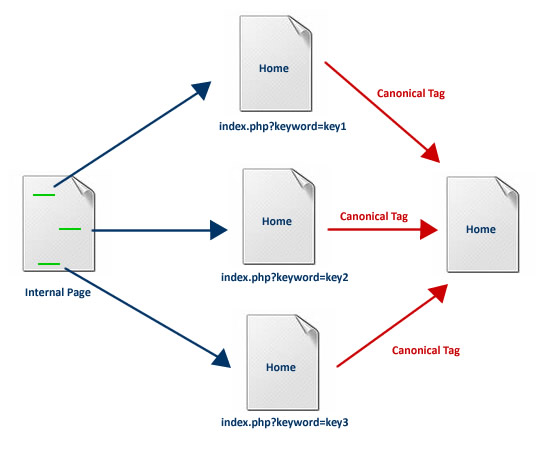 Перенаправления, rel=canonical, внутренние и внешние ссылки, карты сайта, hreflang и т. д. — все это говорит нам о ваших предпочтениях, и чем больше вы можете их согласовать, тем больше мы будем следовать им и использовать их, чтобы выбрать канонический из этого набора ( и пересылать все сигналы на выбранный канонический).
Перенаправления, rel=canonical, внутренние и внешние ссылки, карты сайта, hreflang и т. д. — все это говорит нам о ваших предпочтениях, и чем больше вы можете их согласовать, тем больше мы будем следовать им и использовать их, чтобы выбрать канонический из этого набора ( и пересылать все сигналы на выбранный канонический).
С другой стороны, noindex (отдельно) и запрет robots.txt (в целом) не являются явными признаками канонизации. Просто наличие noindex на странице не говорит нам о том, что вы хотите, чтобы он был объединен с чем-то еще, и что сигналы должны быть перенаправлены. Запрет robots.txt еще сложнее, мы даже не знаем, соответствует ли страница чему-либо еще на вашем сайте, поэтому мы даже не могли бы использовать ее для канонизации, если бы захотели.
Джон Мюллер, Webmaster Trends Analyst John Mueller
Проще говоря, можно сказать, что rel=canonical делает то же, что и переадресация 301; все ссылки на неканоническую версию атрибутировать на каноническую, но без редиректа (поскольку вы хотите сохранить доступ к обеим страницам).
Канонические URL-адреса предназначены для ситуаций, в которых вы просто не сможете (и не должны) реализовать перенаправление 301.
Точно так же не делайте таких вещей, как канонизация страницы A -> страница B и затем перенаправление страницы B -> страница A или объединение канонических тегов, например, указывающих на страницу A -> B, страницу B -> C и т. д.). Подача четких сигналов важна, потому что в противном случае вы часто приводите поисковые системы к принятию неверных решений.
Если вы когда-либо задумывались о том, чтобы канонизировать URL-адрес и не индексировать его, вам следует подумать об использовании переадресации 301. И если вы не можете использовать редирект, то вам следует использовать только rel=canonical.
6.4 Указание только предпочтительной версии веб-сайта в Google Search Console Одним из вариантов установки канонических URL-адресов является использование Google Search Console для указания предпочтительного канонического домена .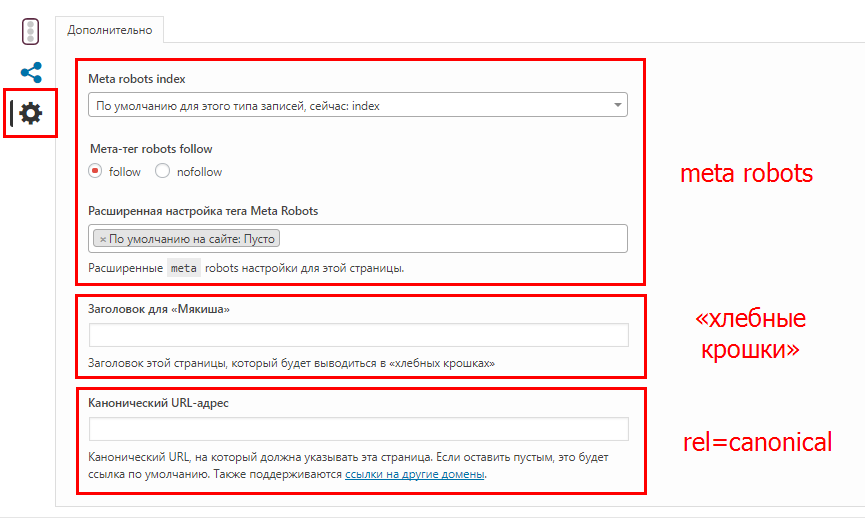 Есть несколько причин, по которым этот метод полезен, в том числе то, что он быстр и чрезвычайно прост в реализации.
Есть несколько причин, по которым этот метод полезен, в том числе то, что он быстр и чрезвычайно прост в реализации.
Однако существуют также некоторые известные проблемы, связанные с использованием этого метода. Например, его можно использовать для указания предпочтительного домена, но вам все равно понадобится плагин, такой как Rank Math, чтобы легко указывать канонические URL-адреса для определенных сообщений и страниц на индивидуальной основе при возникновении различных сценариев.
И, конечно же, еще один недостаток этого подхода заключается в том, что указание предпочтительного домена в Google Search Console корректно устанавливает канонический вариант только для Google, но не для других поисковых систем.
6.5 Считаются ли канонические URL директивами для поисковых систем? Канонические URL-адреса не считаются директивами , однако считаются сигналом поисковой системы. Это означает, что они важны и должны использоваться, потому что они помогают поисковым системам понять содержание веб-сайта и то, как оно соотносится с другим содержимым вашего сайта.
Нет, это очень распространенное заблуждение. Каждая страница в серии страниц с разбивкой на страницы должна иметь собственный канонический URL-адрес, ссылающийся на самого себя. Если вы сделали это на своем сайте или делали это, Google, скорее всего, просто уловит это и проигнорирует сигнал (поскольку это не директива).
6.7 Можно ли установить канонические URL-адреса как относительные URL-адреса?Хотя тег ссылки принимает относительные URL-адреса, поэтому он фактически считается допустимым HTML, использование относительных URL-адресов в канонических файлах может привести к другим проблемам, включая неправильную настройку базового URL-адреса, что сделает недействительной всю каноническую настройку.
На самом деле, сами Google заявили, что некоторые из наиболее распространенных проблем, с которыми они сталкиваются с каноническими именами, на самом деле возникают из-за использования относительных URL-адресов.
Короче говоря, поскольку смысл канонического URL-адреса состоит в том, чтобы точно указать, какой URL-адрес является предпочтительным (с точностью, а не двусмысленностью), этого действительно лучше всего добиться, используя абсолютные URL-адреса при настройке канонических URL-адресов на вашем веб-сайте.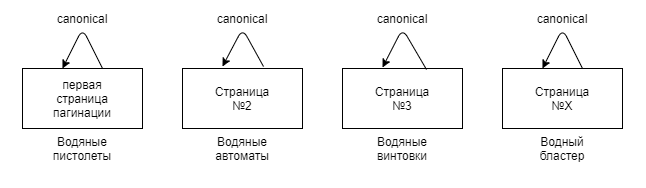
Многоязычные веб-сайты обычно используют теги Hreflang для хранения и отображения различных версий веб-страницы в зависимости от географического положения пользователя.
При использовании тегов hreflang вы должны указать каноническую страницу на том же языке или лучший из возможных замещающих языков, если канонический не существует для того же языка.
При этом, если вы решите не указывать канонический URL-адрес, Google определит, что, по их мнению, является лучшей версией или URL-адресом.
Если вы используете WordPress в качестве предпочтительной системы управления контентом (которую мы настоятельно рекомендуем) и предоставляете контент посетителям веб-сайта на нескольких языках, мы настоятельно рекомендуем использовать плагин перевода Weglot для вашего веб-сайта.
Мы независимо проверили, что они обрабатывают канонизацию, как указано и предложено Google.
7 Заключение.