
Анализ robots.txt — Вебмастер. Справка
- Как проверить файл
- Как узнать, обойдет ли робот определенный URL
- Как отслеживать изменения файла
- Вопросы и ответы
Инструмент Анализ robots.txt помогает проверить, правильно ли составлен файл robots.txt или написать содержимое файла и после проверки скопировать его в robots.txt.
Также инструмент поможет отследить изменения в файле и скачать определенную версию.
- Как проверить файл
- Как узнать, обойдет ли робот определенный URL
- Как отслеживать изменения файла
- Вопросы и ответы
- Если сайт добавлен в Яндекс Вебмастер и права на его управление подтверждены
Содержимое файла появится на странице Инструменты → Анализ robots.txt после подтверждения прав на управление сайтом.
Если содержимое отображается на странице Анализ robots.txt, нажмите кнопку Проверить.
- Если сайт не добавлен в Яндекс Вебмастер
Перейдите на страницу Анализ robots.
 txt.
txt.В поле Проверяемый сайт укажите адрес вашего сайта. Например, https://example.com.
- Нажмите значок . Содержимое robots.txt и результаты анализа отобразятся ниже.
 txt.
txt.В предназначенных для робота Яндекса (User-agent: Yandex или User-agent:*) разделах инструмент проверяет директивы, руководствуясь правилами использования robots.txt. Остальные разделы проверяются в соответствии со стандартом.
После проверки могут отобразиться:Предупреждения. Они сообщают об отклонении от правил, которое инструмент может исправить самостоятельно. Также предупреждения указывают на потенциальную проблему, связанную с опечаткой или неточностью в написании правил.
Ошибки в файле. Это значит, что инструмент не может обработать строку, секцию или весь файл из-за серьезных ошибок в синтаксисе, допущенных при составлении директив.
Когда ваш файл robots.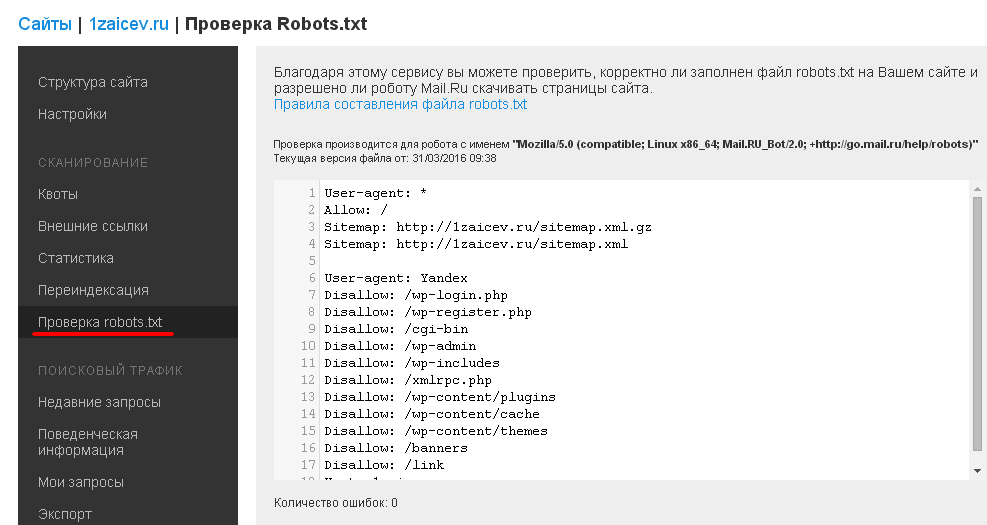 txt загружен в Яндекс Вебмастер, на странице Анализ robots.txt отображается блок Разрешены ли URL?.
txt загружен в Яндекс Вебмастер, на странице Анализ robots.txt отображается блок Разрешены ли URL?.
В поле Список URL укажите адрес страницы, которую хотите проверить. Можно указать полный URL или адрес относительно корневого каталога сайта. Например, https://example.com/page/ или /page/.
Нажмите кнопку Проверить.
Если URL разрешен для индексирования роботами Яндекса, напротив адреса появится значок , если запрещен — отобразится адрес, выделенный красным.
Примечание. Доступна история изменений за шесть месяцев. Максимальное количество сохраненных версий — 100.
Чтобы своевременно узнавать об изменениях файла robots.txt, настройте уведомления.
Яндекс Вебмастер регулярно проверяет обновления файла и сохраняет версии с учетом даты и времени изменения. Чтобы их посмотреть, перейдите на страницу Инструменты → Анализ robots.txt.
Список версий отображается, если одновременно выполнены следующие условия:вы добавили сайт в Яндекс Вебмастер и подтвердили права на управление сайтом;
в Яндекс Вебмастере есть информация об изменениях robots.
txt.
 txt.
txt.- Просмотреть текущую и предыдущие версии файла
Выберите из списка Версия robots.txt версию файла. В поле ниже отобразится содержимое robots.txt, а также результаты анализа.
- Скачать выбранную версию файла
Выберите из списка Версия robots.txt версию файла.
Нажмите кнопку Скачать. Файл сохранится на вашем устройстве в формате TXT.
- Ошибка «Этот URL не принадлежит вашему домену»
Скорее всего, в списке URL вы указали адрес одного из зеркал вашего сайта, например http://example.com вместо http://www.example.com. Формально это два различных URL. Проверяемые URL должны принадлежать сайту, для которого производится анализ robots.txt.
Укажите инструмент, в работе которого вы нашли ошибку, опишите ситуацию как можно подробнее, а при необходимости приложите скриншот, иллюстрирующий ситуацию.
синтаксис и инструкция по работе
Файл robots. txt — это текстовый файл, в котором содержаться инструкции для поисковых роботов, в частности каким роботам и какие страницы допускается сканировать, а какие нет.
txt — это текстовый файл, в котором содержаться инструкции для поисковых роботов, в частности каким роботам и какие страницы допускается сканировать, а какие нет.
- Инструкция;
- Синтаксис;
- Директивы;
- Проверка работы;
Директивы и инструкция по работе с robots.txt
В первую очередь записывается User-Agent, указывая на то, к какому роботу идет обращение, например:
- User-agent: Yandex — для обращения к поисковому роботу Яндекса;
- User-agent: Googlebot — в случае с краулером Google;
- User-agent: YandexImages — при работе с ботом Яндекс.Картинок.
Полный список роботов Яндекс:
https://yandex.ru/support/webmaster/robot-workings/check-yandex-robots.html#check-yandex-robots
И Google:
https://support.google.com/webmasters/answer/1061943?hl=ru
Синтаксис в robots.txt
- # — отвечает за комментирование;
- * — указывает на любую последовательность символов после этого знака. По умолчанию указывается при любого правила в файле;
- $ — отменяет действие *, указывая на то что на этом элементе необходимо остановиться.

Директивы в Robots.txt
Disallow
Disallow запрещает индексацию отдельной страницы или группы (в том числе всего сайта). Чаще всего используется для того, чтобы скрыть технические страницы, динамические или временные страницы.
Пример #1
# Полностью закрывает весь сайт от индексации
User-agent: *
Disallow: /
Пример #2
# Блокирует для скачивания все страницы раздела /category1/, например, /category1/page1/ или caterogy1/page2/
Disallow: /category1/
Пример #3
# Блокирует для скачивания страницу раздела /category2/
User-agent: *
Disallow: /category1/$
Пример #4
# Дает возможность сканировать весь сайт просто оставив поле пустым
User-agent: *
Disallow:
Важно! Следует понимать, что регистр при использовании правил имеет значение, например, Disallow: /Category1/ не запрещает посещение страницы /category1/.
Allow
Директива Allow указывает на то, что роботу можно сканировать содержимое страницы/раздела, как правило, используется, когда в полностью закрытом разделе, нужно дать доступ к определенному документу.
Пример #1
# Дает возможность роботу скачать файл site.ru//feed/turbo/ несмотря на то, что скрыт раздел site.ru/feed/.
Disallow: */feed/*
Allow: /feed/turbo/
Пример #2
# разрешает скачивание файла doc.xml
# разрешает скачивание файла doc.xml
Allow: /doc.xml
Sitemap
Директива Sitemap указывает на карту сайта, которая используется в SEO для вывода списка URL, которые нужно проиндексировать в первую очередь.
Важно понимать, что в отличие от стандартных директив у нее есть особенности в записи:
- Следует указывать полный URL, когда относительный адрес использовать запрещено;
- На нее не распространяются остальные правила в файле robots.txt;
- XML-карта сайта должна иметь в URL-адресе домен сайта.
Пример
# Указывает карту сайта
Sitemap: https://serpstat.com/sitemap.xml
Clean-param
Используется когда нужно указать Яндексу (в Google она не работает), что страница с GET-параметрами (например, site.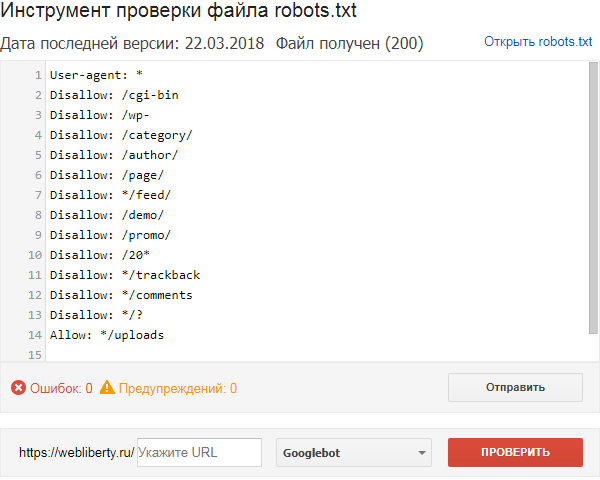 ru?param1=2¶m2=3) и метками (в том числе utm) не влияющие на содержимое сайта, не должна быть проиндексирована.
ru?param1=2¶m2=3) и метками (в том числе utm) не влияющие на содержимое сайта, не должна быть проиндексирована.
Пример #1
#для адресов вида:
www.example1.com/forum/showthread.php?s=681498b9648949605&t=8243
www.example1.com/forum/showthread.php?s=1e71c4427317a117a&t=8243
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: s /forum/showthread.php
Пример #2
#для адресов вида:
www.example2.com/index.php?page=1&sid=2564126ebdec301c607e5df
www.example2.com/index.php?page=1&sid=974017dcd170d6c4a5d76ae
#robots.txt будет содержать:
User-agent: Yandex
Disallow:
Clean-param: sid /index.php
Подробнее о данной директиве можно прочитать здесь:
https://serpstat.com/ru/blog/obrabotka-get-parametrov-v-robotstxt-s-pomoshhju-direktivy-clean-param/
Crawl-delay
Важно! Данная директива не поддерживается в Яндексе с 22 февраля 2019 года и в Google 1 сентября 2019 года, но работает с другими роботами. Настройки скорости скачивания можно найти в Яндекс.Вебмастер и Google Search Console.
Настройки скорости скачивания можно найти в Яндекс.Вебмастер и Google Search Console.
Crawl-delay указывает временной интервал в секундах, в течение которого роботу разрешается делать только 1 сканирование. Как правило, необходима лишь в случаях, когда у сайта наблюдается большая нагрузка из-за сканирования.
Пример
# Допускает скачивание страницы лишь раз в 3 секунды
Crawl-delay: 3
Как проверить работу файла robots.txt
В Яндекс.Вебмастер
В Яндекс.Вебмастер в разделе «Инструменты→ Анализ robots.txt» можно увидеть используемый поисковиком свод правил и наличие ошибок в нем.
Также можно скачать другие версии файла или просто ознакомиться с ними.
Чуть ниже имеется инструмент, который дает возможно проверить сразу до 100 URL на возможность сканирования.
В нашем случае мы проверяем эти правила.
Как видим из примера все работает нормально.
Также если воспользоваться сервисом «Проверка ответа сервера» от Яндекса также будет указано, запрещен ли для сканирования документ при попытке обратиться к нему.
В Google Search Console
В случае с Google можно воспользоваться инструментом проверки Robots.txt, где потребуется в первую очередь выбрать нужный сайт.
Важно! Ресурсы-домены в этом случае выбирать нельзя.
Теперь мы видим:
- Сам файл;
- Кнопку, открывающую его;
- Симулятор для проверки сканирования.
Если в симуляторе ввести заблокированный URL, то можно увидеть правило, запрещающее сделать это и уведомление «Недоступен».
Однако, если ввести заблокированный URL в страницу поиска в новой Google Search Console (или запросить ее индексирование), то можно увидеть, что страница заблокирована в файле robots.txt.
Поисковый робот— в чем разница между «Разрешить: /» и «Запретить:» в файле robots.txt?
спросил
Изменено 1 год, 4 месяца назад
Просмотрено 683 раза
В чем разница между двумя файлами robots. ниже? txt
txt
Агент пользователя: * Позволять: /
против
User-agent: * Запретить:
В Википедии последний указан как пример в разделе Примеры .
Однако позже он имеет код, аналогичный первому коду:
User-agent: bingbot Позволять : / Задержка сканирования: 10
- поисковый робот
- robots.txt
Лучше использовать синтаксис запрета:
Агент пользователя: * Запретить:
Disallow является частью исходного стандарта robots.txt, который понимает каждый бот, подчиняющийся robots.txt.
Разрешить — это синтаксис расширения, представленный Google и понятный только нескольким ботам. Он был добавлен, чтобы иметь возможность запретить все, но затем снова разрешить несколько вещей. Наиболее уместно использовать его как:
User-agent: * Запретить: / Разрешить: /public
В этом случае большинство ботов вообще не смогут сканировать сайт, но несколько ботов, понимающих Разрешить: сможет сканировать общедоступный каталог.
Когда директивы Disallow: и Allow: конфликтуют (как в приведенном выше примере), приоритет имеет более длинная директива, применимая к данному URL-адресу. Например, /public/foo будет использовать правило Allow: /public , потому что могут применяться оба правила, но это правило длиннее. /private/foo будет использовать правило Disallow: / , потому что только оно соответствует. Порядок правил не имеет значения.
Первый сообщает всем пользовательским агентам, таким как поисковые роботы или поисковые роботы Google, что им разрешено просматривать весь веб-сайт, поскольку / — это корневой путь веб-сайта, например, http://example. org будет / , а https://example.org/admin будет /admin в вашем robots.txt
Директива Disallow делает прямо противоположное, она сообщает агентам пользователя держаться подальше от указанных путей.
Разрешить и Запретить можно использовать по-разному, например, в виде белого или черного списка.
И поэтому следующий
User-agent: * Позволять: /
совпадает с
User-agent: * Запретить:
Самый простой способ понять это, если подумать, что Allow и Disallow подобны «спискам» путей, но должен использоваться только один тип директивы ( Allow или Disallow ).
Например, давайте занесем в черный список файл robots.txt с помощью директивы Disallow , запретив только индексатору bing индексировать наш веб-сайт.
Агент пользователя: Bingbot Запретить: / Пользовательский агент: * Запретить:
Короче.
Если disallow пусто, то разрешено все.
А если все разрешать, то ничего не запрещается.
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google Зарегистрироваться через Facebook Зарегистрируйтесь, используя адрес электронной почты и парольОпубликовать как гость
Электронная почтаТребуется, но не отображается
Опубликовать как гость
Электронная почтаТребуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.
seo — Использование «Разрешить» в robots.txt
спросил
Изменено 6 лет, 6 месяцев назад
Просмотрено 3к раз
Недавно я увидел файл robots.txt сайта следующим образом:
User-agent: * Разрешить: /логин Разрешить: /регистр
Я смог найти только Разрешить записей и ни одного Запретить записей.
Из этого я понял, что robots.txt — это почти файл черного списка для Запретить сканирование страниц. Таким образом, Разрешить используется только для разрешения части домена, которая уже заблокирована с помощью Запретить . Аналогично этому:
Разрешить: /crawlthis Запретить: /
Но в файле robots. txt нет записей
txt нет записей Disallow . Итак, позволяет ли этот robots.txt Google сканировать все страницы? Или он разрешает только указанные страницы с тегом Разрешить ?
- поисковая оптимизация
- поисковый робот
- robots.txt
- googlebot
Вы правы в том, что этот файл robots.txt позволяет Google сканировать все страницы сайта. Подробное руководство можно найти здесь: http://www.robotstxt.org/robotstxt.html.
Если вы хотите, чтобы роботу googleBot было разрешено сканировать только указанные страницы, правильный формат будет следующим:
Агент пользователя:* Запретить:/ Разрешить: /логин Разрешить: /регистр
(Обычно я бы запретил доступ к этим конкретным страницам, поскольку они не представляют большой ценности для искателей.)
Важно отметить, что командная строка Разрешить работает только с некоторыми роботами (включая Googlebot)
1 Нет смысла иметь запись robots.
Разрешить строк, но не Запретить строк. В любом случае по умолчанию все разрешено сканировать. Согласно оригинальной спецификации robots.txt (которая не определяет Разрешить ), он даже недействителен, так как по крайней мере один Запретить требуется строка (выделено жирным шрифтом):
Запись начинается с одной или нескольких строк
User-agent, за которыми следует одна или несколько строкDisallow[…]
В записи должно присутствовать хотя бы одно поле
Disallow.
Другими словами, запись типа
User-agent: * Разрешить: /логин Разрешить: /регистр
эквивалентно записи
Агент пользователя: * Запретить:
т. е. разрешено сканирование всего, включая (но не ограничиваясь) URL-адреса с путями, начинающимися с /login и /register .