
Поисковый алгоритм Яндекса «Палех»
«Палех» – новый поисковый алгоритм Яндекса
Эволюция поисковых интернет-машин за последние 16 лет проделала огромный путь. Начиная когда-то развитие с простого обнаружения слов, сегодня крупные поисковики пришли к алгоритму так называемого «умного поиска» при помощи нейронных сетей.
Не отстаёт от актуальных мировых трендов и российский Яндекс – в начале ноября 2016 года в корпоративном блоге интернет-компании появилась статья с анонсом запуска нового поискового алгоритма «Палех».
Что такое нейронные сети – краткий ликбез, понятный и гуманитарию
Само понятие нейронных сетей появилось ещё на заре тотальной компьютеризации и зарождения интернета, однако, актуализировалось только в последние годы. Название программистами было выбрано по аналогии с научным термином биологических нейронов, которые, как известно, организуют работу нервной системы человека (и в том числе головного мозга). Ключевая задача каждого нейрона заключается в организации электрохимического импульса, – с его помощью один нейрон осуществляет взаимосвязь со всеми другими нейронами.
Ключевая задача каждого нейрона заключается в организации электрохимического импульса, – с его помощью один нейрон осуществляет взаимосвязь со всеми другими нейронами.
И этот же принцип общего одновременного взаимодействия одной части поступающих запросов с другими частями большой сети лежит в основе работы компьютерных нейросетей.
Биология нейронных сетей в виде единого живого организма
К прорывной технологической особенности машинных нейронных сетей можно отнести их «умение» работать с образами. Привычная классика подхода к обработке информация заключается в последовательной (алгоритмической) обработке символов, тогда как нейронные сети способны уже параллельно друг другу распознавать образы.
В сфере поисковых систем под символами и образами понимаются те «слова», которые люди вбивают в строку браузеров. Символы отличаются от образов своей размерностью, – условный размер вторых может на несколько порядков превышать размер символов.
«Палех» – низкочастотный словесный хвост поискового трафика Яндекса
Наглядности схематичной работе современных компьютерных нейросетей могут добавить простые факты результативности работы: сегодня машины способны работать с изображениями, звуками, текстом и другими образчиками образного мышления (присущего, казалось бы, только человеку). Машину можно обучить различать на картинках любые объекты действительности: людей, машины, животных, еду и т. д.
Работа поискового алгоритма «Палех» настроена на различении смысла забиваемых в поисковик пользователями слов. Притом даже не простых, популярных в народе, а – сложных, многосоставных, неконкретных, имеющих очень далёкое отношение к тому, что человек пытается найти (то есть, по сути образных).
Почему, собственно, новый алгоритм называется «Палехом»? Разработчики Яндекса все пользовательские запросы разделили на три части, представив их в виде туловища мифологической Жар-птицы, частой героини, отображаемой на изделиях в стиле русского палехского ремесла.
Палехская Жар-птица – мифологическое существо, как символ поискового потока Яндекса
Примеры фантастических, ассоциативно-образных многочастотных запросов
Примеры многочастотных образных запросов в Рунете бывают поистине причудливыми, если не сказать даже фантастическими. Ищущие фильм «Бойцовский клуб» люди, например, могут вбить в поисковик следующее: «офисный клерк и его воображаемый друг фильм». Интересующиеся днём Благодарения, но забывшие название торжества люди обращаются за помощью с запросом «праздник с курицами в Америке».
Понятно, что такие длинные и сложные по семантике запросы машинная система Яндекса встречает гораздо реже, чем короткие, одночастотные из «клюва» условной Жар-птицы. Соответственно, и чётко работающего алгоритма для понимания того, что всё же нужно человеку в каждом конкретном случае нет. Задача нередко осложняется тем, что человеческое слово многозначно: в поисковой выдаче вообще может выпадать с десяток ссылок на источники не имеющие отношения к искомой информации.
В решении этой сложной проблемы понимания образного, ассоциативного мышления человека и участвует нейронные системы нового поискового алгоритма «Палех».
Суть работы «Палеха» – немного простейшей математики
Для представления того, как функционирует нейросети русскоязычного поисковика при обработке многочастотных запросов, нужно понимать, что они накапливают внутри себя необходимую статистику правильности/неправильности соответствия выдачи страниц тому, что ищут люди. Эта статистика основывается на поведенческом факторе пользователей: если в выдаче нет сайтов с нужной информации, – человек ни по одной странице просто не кликнет. Или, кликнув и поняв, что на том или ином сайте необходимая информация отсутствует, он её тут же, в течение двух-трёх секунд закроет.
Эта статистика основывается на поведенческом факторе пользователей: если в выдаче нет сайтов с нужной информации, – человек ни по одной странице просто не кликнет. Или, кликнув и поняв, что на том или ином сайте необходимая информация отсутствует, он её тут же, в течение двух-трёх секунд закроет.
Понятно, что количество удачных (или неудачных) соответствий запросов с веб-страницами миллиарды. Нейронная сеть «Палех» позволяет для внутреннего математического удобства переводить это количество соответствий в группы, состоящие из трёхсот чисел каждая. Способ обработки запросов с близкими им вероятными ответами в трёхсотмерной системе координат называется семантическим вектором.
Математика семантического вектора помогает человеку искать нужную информацию
Поисковая технология семантического вектора имеет в интернете огромный потенциал развития. Она позволяет, к примеру, работать, анализировать не только заголовки, но и сами тексты различных документов. Более того, в качестве семантического вектора можно представить всю совокупность сведений о пользователе в интернете – взятые со страничек соцсетей интересы, статистику предыдущих поисковых запросов и переходов по ссылкам, и это очень полезная информация не только для поисковиков, но и для маркетологов, веб-мастеров и других, связанных с интернет-бизнесом, людей.
Более того, в качестве семантического вектора можно представить всю совокупность сведений о пользователе в интернете – взятые со страничек соцсетей интересы, статистику предыдущих поисковых запросов и переходов по ссылкам, и это очень полезная информация не только для поисковиков, но и для маркетологов, веб-мастеров и других, связанных с интернет-бизнесом, людей.
Не исключено, что в перспективе алгоритмы нейронных поисковых систем по способу образного мышления, понимания запросов вплотную приблизятся к людям. И как знать, каким будет этот самый интернет в эпоху, когда поисковики будут понимать любого человека буквально с полуслова…
Алгоритм «Палех». Или нейронные сети на службе Яндекса – Блог ITC MEDIA
Компания Яндекс совершенствует поисковые механизмы, распознающие запросы пользователей и определяющие, какие сайты и статьи наиболее полно соответствуют поступившим запросам. И самое последнее изобретение — алгоритм «Палех», анализирующий не только ключевые слова из запросов и сайтов, но и смысловую нагрузку выбранных статей. В основе алгоритма — нейронные сети.
В основе алгоритма — нейронные сети.
«Хвост жар-птицы»
Ежедневно поисковые алгоритмы Яндекса дают ответы почти на 300 миллионов запросов. Многие запросы повторяются из минуты в минуту, другие являются уникальными. Уникальный запрос может никогда больше ни в этот день, ни в этом столетии не повториться. Но ежедневно Яндекс дает ответы на сто миллионов уникальных запросов.
График частотного распределения запросов любой поисковой системы, в частности, Яндекса, можно изобразить в виде птицы: есть клюв, шея, туловище и огромный хвост. Все наиболее часто встречающиеся запросы можно считать клювом. Подобных запросов (стандартных) много, но разнообразием они не отличаются. Запросы, менее популярные, но достаточно часто встречающиеся можно отнести к шее и туловищу птицы. А в хвосте «собираются» те запросы, которые имеют сравнительно низкую частоту. Но подобных запросов много, они могут отличаться деталями. И в итоге «хвост» образуется очень значительных размеров.
И разработка нового алгоритма позволит давать ответы на все самые сложные, экзотические вопросы вне зависимости от длины «хвоста». Почему алгоритм получил название «Палех»? Все очень просто. В российской сказочной культуре очень часто упоминается «жар-птица», имевшая дивный длинный хвост. А мастерицы Палеха на своих изделиях очень часто ее изображали во всей красе. И название появилось само собой.
Все запросы, составляющие хвост, достаточно разнообразны. Но и их можно определенным образом классифицировать и разделить на группы:
- запросы от детей или лиц, не имеющих опыта обращения с «поисковиками». В таких запросах можно встретить обращения к Яндексу, как к живому человеку, просьбы — «покажи, пожалуйста»;
- в отдельную группу можно выделить запросы, в которых пользователь четко не знает, что ему нужно, а может только приблизительно указать, что это было (например, американское кино про войны с империей). Можно выделить и другие типы запросов.


Запросы, составляющие «клюв» птицы однообразны. Они не представляют никакой сложности для поисковых роботов. И по таким запросам уже сформирована определенная статистика. Соответственно, при поступлении нового запроса из «клюва» нет необходимости опять пересматривать все необъятные просторы интернета. Ответ поступает в течение миллисекунд. Если же запрос относится к «хвосту», то никакой статистики подобных запросов у Яндекса нет и быть не может. И сложность заключается еще и в том, что запрос может быть сформулирован «коряво» или противоречиво. В такой ситуации определить, какие из найденных страниц будут релевантными запросу, очень непросто.
Но разработчики Яндекса полагают, что ни один из поступивших запросов не должен оставаться без ответа. И на помощь призваны нейронные сети, способствующие лучшему поиску.
Семантический вектор
Разработкой нейронных сетей или искусственного интеллекта и ученые, и программисты заинтересовались давно.
В случае с поиском ответа на запросы от пользователей Яндекса ситуация обстоит так же. Только вместо картинок нужно искать текст. Система так же обучается и использованием примеров, соответствующих и не соответствующих запросу. В данном случае обучение начинается с поиска соответствия между запросами пользователей и заголовками страниц, попавших в «поле зрения» поискового робота. И нейронная сеть накапливает определенный багаж знаний, позволяющих выделять нужное.
И нейронная сеть накапливает определенный багаж знаний, позволяющих выделять нужное.
Изначально, еще в те времена, когда компьютеры только появились, вся обрабатываемая информация для простоты переводилась в цифровое выражение. Каждому символу соответствовало некоторое двоичное выражение. И с того времени ничего не изменилось. По-прежнему, каждый набор знаков переводится в формат числа. И поисковые роботы в процессе поиска соответствий запросам от пользователей последовательно сравнивают коды запросов с кодами заголовков страниц. А для простоты поиска все заголовки страниц уже сгруппированы по триста единиц. И поисковое пространство Яндекса стало трехсот мерным.
И в получившейся трехсот мерной системе координат каждому веб-адресу соответствует определенная точка, к которой и обращается поисковая система при обработке запросов. Запрос пользователя в свою очередь так же переводится в числовое выражение и размещается в той же системе координат. И, если координаты запроса и веб-страницы совпали, то ответ на запрос пользователя найден. Если же координаты не совпали полностью, то есть все основания предполагать, что веб-страницы с максимально близкими координатами так же содержат ответы на запрос пользователя.
Если же координаты не совпали полностью, то есть все основания предполагать, что веб-страницы с максимально близкими координатами так же содержат ответы на запрос пользователя.
У разработчиков такой метод поиска ответов на заданные вопросы получил название «семантического вектора». И этот вариант обработки запросов, как никакой другой актуален, если нужно найти ответ на запрос, относящийся к «длинному хвосту». Метод позволяет быстро и качественно обрабатывать запросы, имеющие низкую частотность, по которым не сформирована статистика. Главное достоинство метода: он позволяет формировать ответы на те запросы, которые сформулированы нечетко, содержат только приблизительные данные.
Компания Яндекс перешла на использование «семантического вектора» в своих поисковых алгоритмах уже несколько месяцев назад. Нейронные модели за это время прошли сложное обучение, научились преобразовывать полученные запросы в цепочки цифр и анализировать их положение в пространстве.
Развитие на этом не останавливается
Поисковая система Яндекс — не единственная, основанная на использовании семантических векторов. По такому же принципу работают Картинки. Пользователь может задать текстовый запрос и получить в качестве ответа некоторое изображение.
В дальнейших планах перевод на поиск по семантическим векторам не только заголовков сайтов и страниц, но и полностью текстов документов. В идеальном варианте пользователь будет получать ответы, полностью соответствующие его запросам. В планах разработчиков — вывод компьютерных нейронных сетей на один уровень с человеческим мозгом. Это позволит «читать мысли» и организовывать поиск соответствий даже тем запросам, которые еще не введены в поисковую строку.
Поисковый алгоритм Яндекс «Палех»
2-го ноября 2016 года Яндекс анонсировал поисковый алгоритм «Палех», основанный на нейронных сетях.
Поиск Яндекс использует нейронные сети для того, чтобы находить документы не по словам, которые используются в запросе и в самом документе, а по смыслу запроса и заголовка.
Исследователи постоянно бьются над проблемой семантического поиска, в котором документы ранжируются, исходя из смыслового соответствия запросу. Поисковый алгоритм «Палех» – это реализация семантического поиска и важный шаг в будущее.
Искусственный интеллект или машинное обучение?
Почти все знают, что современные поисковые системы работают с помощью машинного обучения. Почему об использовании нейронных сетей для его задач надо говорить отдельно? И почему только сейчас?
Поиск в интернете — сложная система, которая появилась достаточно давно.
Сначала это был просто поиск страничек, потом он превратился в решателя задач, и сейчас становится полноценным помощником. Чем больше интернет, и чем больше в нём людей, тем выше их требования, тем сложнее приходится становиться поиску.
Эпоха наивного поиска
Сначала был просто поиск слов — инвертированный индекс. Потом страниц стало слишком много, их стало нужно ранжировать. Начали учитываться разные усложнения — частота слов, tf-idf.
Эпоха ссылок
Потом страниц стало слишком много на любую тему, произошёл важный прорыв — начали учитывать ссылки, появился PageRank.
Эпоха машинного обучения
Интернет стал коммерчески важным, и появилось много жуликов, пытающихся обмануть простые алгоритмы, существовавшие в то время. Произошёл второй важный прорыв — поисковики начали использовать свои знания о поведении пользователей, чтобы понимать, какие страницы хорошие, а какие — нет.
На этом этапе человеческого разума перестало хватать на то, чтобы придумывать, как ранжировать документы. Произошёл следующий переход — поисковики стали активно использовать машинное обучение.
Один из лучших алгоритмов машинного обучения изобрели в Яндексе — это Матрикснет.
Можно сказать, что ранжированию помогает коллективный разум пользователей и «мудрость толпы».
Информация о сайтах и поведении людей преобразуется во множество факторов, каждый из которых используется Матрикснетом для построения формулы ранжирования. Фактически, формулу ранжирования пишет машина (получалось около 300 мегабайт).
Фактически, формулу ранжирования пишет машина (получалось около 300 мегабайт).
Но у «классического» машинного обучения есть предел: оно работает только там, где очень много данных.
Небольшой пример. Миллионы пользователей вводят запрос [вконтакте], чтобы найти один и тот же сайт. В данном случае их поведение является настолько сильным сигналом, что поиск не заставляет людей смотреть на выдачу, а подсказывает адрес сразу при вводе запроса. Но люди сложнее, и хотят от поиска всё больше.
Сейчас уже до 40% всех запросов уникальны, то есть не повторяются хотя бы дважды – в течение всего периода наблюдений. Это значит, что у поиска нет данных о поведении пользователей в достаточном количестве, и Матрикснет лишается ценных факторов. Такие запросы в Яндексе называют «длинным хвостом», поскольку (все вместе) они составляют существенную долю обращений к поиску.
Эпоха искусственного интеллекта
Компьютеры становятся быстрее и данных становится больше, поэтому назрела необходимость использовать нейронные сети.
На основе технологий нейронных сетей основан машинный интеллект (или искусственный интеллект). Он основан потому, что нейронные сети построены по образу нейронов в нашем мозге и пытаются эмулировать работу некоторых его частей.
Машинный интеллект гораздо лучше старых методов справляется с задачами, которые могут делать люди: например, распознаванием речи или образов на изображениях.
Так каким образом это может помочь поиску?
Как правило, низкочастотные и уникальные запросы довольно сложны для поиска и найти качественный ответ по ним заметно труднее.
Как это сделать?
У Яндекс нет подсказок от пользователей (какой документ лучше, а какой — хуже), поэтому для решения поисковой задачи нужно научиться лучше понимать смысловое соответствие между двумя текстами: запросом и документом.
Итак, искусственные нейросети – это один из методов машинного обучения. Нейронные сети показывают впечатляющие результаты в области анализа естественной информации — звука и образов. Это происходит уже несколько лет. Но почему их до сих пор не так активно применяли в поиске? Простой ответ — потому что говорить о смысле намного сложнее, чем об образе на картинке, или о том, как превратить звуки в расшифрованные слова.
Это происходит уже несколько лет. Но почему их до сих пор не так активно применяли в поиске? Простой ответ — потому что говорить о смысле намного сложнее, чем об образе на картинке, или о том, как превратить звуки в расшифрованные слова.
Тем не менее, в поиске смыслов, искусственный интеллект действительно стал приходить из той области, где он уже давно является лидирующим — из поиска по картинкам.
Несколько слов о том, как это работает в поиске по картинкам.
Вы берёте изображение и с помощью нейронных сетей преобразуете его в вектор в N-мерном пространстве.
Берете запрос (который может быть как в текстовом виде, так и в виде другой картинки) и делаете с ним то же самое. А потом сравниваете эти векторы.
Чем ближе векторы друг к другу, тем больше картинка соответствует запросу и, соответственно, если это работает в картинках, почему не применить эту логику в web-поиске?
Таим образом можно сформулировать задачу.
В поиске Яндекс, на входе, есть запрос пользователя и заголовок страницы. Нужно понять, насколько они соответствует друг другу по смыслу.
Нужно понять, насколько они соответствует друг другу по смыслу.
Для этого необходимо представить текст запроса и текст заголовка в виде таких векторов, скалярное умножение которых было бы тем больше, чем релевантнее запросу документ с данным заголовком. Иначе говоря, мы хотим обучить нейронную сеть так, чтобы для близких по смыслу текстов она генерировала похожие векторы, а для семантически-несвязанных запросов и заголовков векторы должны отличаться.
Сложность этой задачи заключается в подборе правильной архитектуры и метода обучения нейронной сети.
Из научных публикаций известно довольно много подходов к решению проблемы. Вероятно, самым простым методом здесь является представление текстов в виде векторов с помощью алгоритма word2vec (к сожалению, практический опыт говорит о том, что для рассматриваемой задачи это довольно неудачное решение).
Что пробовали в Яндекс, как добились успеха и как смогли обучить то, что получилось.
DSSM
В 2013 году исследователи из Microsoft Research описали свой подход, который получил название Deep Structured Semantic Model.
На вход модели подаются тексты запросов и заголовков. Для уменьшения размеров модели, над ними производится операция, которую авторы называют word hashing. К тексту добавляются маркеры начала и конца, после чего он разбивается на буквенные триграммы. Например, для запроса [палех] мы получим триграммы [па, але, лех, ех].
Поскольку количество разных триграмм ограничено, то мы можем представить текст запроса в виде вектора размером в несколько десятков тысяч элементов (размер нашего алфавита в 3 степени). Соответствующие триграммам запроса элементы вектора будут равны 1, остальные — 0.
По сути, мы отмечаем вхождение триграмм из текста в словарь, состоящий из всех известных триграмм.
Если сравнить такие векторы, то можно узнать только о наличии одинаковых триграмм в запросе и заголовке, что не представляет особого интереса. Поэтому теперь их надо преобразовать в другие векторы, которые уже будут иметь нужные нам свойства семантической близости.
После входного слоя, расположено несколько скрытых слоёв как для запроса, так и для заголовка.
Последний слой размером в 128 элементов и служит вектором, который используется для сравнения.
Выходом модели является результат скалярного умножения последних векторов заголовка и запроса (если быть совсем точным, то вычисляется косинус угла между векторами).
Модель обучается таким образом, чтобы для положительны обучающих примеров выходное значение было большим, а для отрицательных — маленьким. Иначе говоря, сравнивая векторы последнего слоя, мы можем вычислить ошибку предсказания и модифицировать модель таким образом, чтобы ошибка уменьшилась.
В Яндекс тоже активно исследуются модели на основе искусственных нейронных сетей, поэтому заинтересовались моделью DSSM.
Характерное свойство алгоритмов, описываемых в научной литературе, состоит в том, что они не всегда работают «из коробки». «Академический» исследователь и исследователь из индустрии находятся в существенно разных условиях.
В качестве отправной точки (baseline), с которой автор научной публикации сравнивает своё решение, должен выступать какой-то общеизвестный алгоритм — так обеспечивается воспроизводимость результатов.
Исследователи берут результаты ранее опубликованного подхода, и показывают, как их можно превзойти. Например, авторы оригинального DSSM сравнивают свою модель по метрике NDCG с алгоритмами BM25 и LSA.
В случае с прикладным исследователем, который занимается качеством поиска в реальной поисковой машине, отправной точкой служит не один конкретный алгоритм, а всё ранжирование в целом.
Цель разработчика Яндекс состоит не в том, чтобы обогнать BM25, а в том, чтобы добиться улучшения на фоне всего множества ранее внедренных факторов и моделей. Таким образом, baseline для исследователя в Яндекс чрезвычайно высок, и многие алгоритмы, обладающие научной новизной и показывающие хорошие результаты при «академическом» подходе, оказываются бесполезными на практике, поскольку не позволяют реально улучшить качество поиска.
В случае с DSSM в Яндекс столкнулись с этой же проблемой. В практических экспериментальных условиях точная реализация модели из статьи показала скромные результаты. Потребовался ряд существенных «доработок напильником», прежде чем в Яндекс смогли получить результаты, интересные с практической точки зрения.
Потребовался ряд существенных «доработок напильником», прежде чем в Яндекс смогли получить результаты, интересные с практической точки зрения.
Об основных модификациях оригинальной модели, чтобы сделать её более мощной.
В оригинальной модели DSSM входной слой представляет собой множество буквенных триграмм. Его размер равен 30000.
У подхода на основе триграмм есть несколько преимуществ:
во-первых, их относительно мало, поэтому работа с ними не требует больших ресурсов;
во-вторых, их применение упрощает выявление опечаток и ошибок в словах.
Однако, эксперименты показали, что представление текстов в виде «мешка» триграмм заметно снижает выразительную силу сети, поэтому в Яндекс радикально увеличили размер входного слоя, включив в него, помимо буквенных триграмм, ещё около 2 миллионов слов и словосочетаний. Таким образом, в Яндекс представляют тексты запроса и заголовка в виде совместного «мешка» слов, словесных биграмм и буквенных триграмм, а использование большого входного слоя приводит к увеличению размеров модели, длительности обучения и требует существенно больших вычислительных ресурсов.
Как нейронная сеть боролась сама с собой и научилась на своих ошибках
Обучение исходного DSSM состоит в демонстрации сети большого количества положительных и отрицательных примеров. Эти примеры берутся из поисковой выдачи (судя по всему, для этого использовался поисковик Bing).
Положительными примерами служат заголовки кликнутых документов выдачи, отрицательными — заголовки документов, по которым не было клика.
У этого подхода есть определённые недостатки. Например, отсутствие клика далеко не всегда свидетельствует о том, что документ нерелевантен. Справедливо и обратное утверждение — наличие клика не гарантирует релевантности документа.
По сути, обучаясь описанным в исходной статье образом, алгоритм стремится предсказывать аттрактивность заголовков при условии того, что они будут присутствовать в выдаче. Это, конечно, неплохо, но имеет достаточно косвенное отношение к главной цели — научиться понимать семантическую близость.
Во время экспериментов в Яндекс обнаружили, что результат можно заметно улучшить, если использовать другую стратегию выбора отрицательных примеров.
Для достижения цели хорошими отрицательными примерами являются такие документы, которые гарантированно нерелевантны запросу, но при этом помогают нейронной сети лучше понимать смыслы слов. Откуда их взять?
Сначала, в качестве отрицательного примера, возьмём заголовок случайного документа. Например, для запроса [палехская роспись] случайным заголовком может быть «Правила дорожного движения 2016 РФ».
Разумеется, полностью исключить то, что случайно выбранный из миллиардов документ будет релевантен запросу, нельзя, но вероятность этого настолько мала, что ей можно пренебречь. Таким образом мы можем очень легко получать большое количество отрицательных примеров.
Казалось бы, теперь мы можем научить сеть тому, чему хочется отличать хорошие документы, которые интересуют пользователей, от документов, не имеющих к запросу никакого отношения.
К сожалению, обученная на таких примерах модель оказалась довольно слабой. Нейронная сеть – штука умная, и всегда найдет способ упростить себе работу. В данном случае, она просто начала выискивать одинаковые слова в запросах и заголовках: есть — хорошая пара, нет — плохая. Но это Яндекс и сам умеет делать. Важно – чтобы сеть научилась различать неочевидные закономерности.
В данном случае, она просто начала выискивать одинаковые слова в запросах и заголовках: есть — хорошая пара, нет — плохая. Но это Яндекс и сам умеет делать. Важно – чтобы сеть научилась различать неочевидные закономерности.
Следующий эксперимент состоял в том, чтобы добавлять в заголовки отрицательных примеров слова из запроса. Например, для запроса [палехская роспись] случайный заголовок выглядел как [Правила дорожного движения 2016 РФ роспись]. Нейронной сети пришлось чуть сложнее, но, тем не менее, она довольно быстро научилась хорошо отличать естественные пары от составленных вручную. Стало понятно, что такими методами мы успеха не добьемся.
Многие очевидные решения становятся очевидны только после их обнаружения. Так получилось спустя некоторое время и обнаружилось, что лучший способ генерации отрицательных примеров — это заставить сеть «воевать» против самой себя – учиться на собственных ошибках.
Среди сотен случайных заголовков в Яндекс выбирали такой, который текущая нейросеть считала наилучшим. Но, так как этот заголовок всё равно случайный, с высокой вероятностью он не соответствует запросу. И именно такие заголовки экспериментаторы стали использовать в качестве отрицательных примеров.
Но, так как этот заголовок всё равно случайный, с высокой вероятностью он не соответствует запросу. И именно такие заголовки экспериментаторы стали использовать в качестве отрицательных примеров.
Другими словами, можно показать сети лучшие из случайных заголовков, обучить её, найти новые лучшие случайные заголовки, снова показать сети и так далее.
Раз за разом повторяя данную процедуру, экспериментаторы видели, как заметно улучшается качество модели, и всё чаще лучшие из случайных пар становились похожи на настоящие положительные примеры. И в итоге – проблема была решена.
Подобная схема обучения в научной литературе обычно называется hard negative mining.
Следует также отметить, что, схожие по идее, решения получили широкое распространение в научном сообществе для генерации реалистично выглядящих изображений, подобный класс моделей получил название Generative Adversarial Networks.
В качестве положительных примеров исследователи из Microsoft Research использовались клики по документам. Однако, как уже было сказано, это достаточно ненадежный сигнал о смысловом соответствии заголовка запросу.
Однако, как уже было сказано, это достаточно ненадежный сигнал о смысловом соответствии заголовка запросу.
В конце концов, задача состоит не в том, чтобы поднять в поисковой выдаче самые посещаемые сайты, а в том, чтобы найти действительно полезную информацию. Поэтому в Яндекс пробовали, в качестве цели обучения, использовать другие характеристики поведения пользователя. Например, одна из моделей предсказывала, останется ли пользователь на сайте или уйдет. Другая – насколько долго он задержится на сайте.
Как оказалось, можно заметно улучшить результаты, если оптимизировать такую целевую метрику, которая свидетельствует о том, что пользователь нашёл то, что ему было нужно.
Так что нам дает это на практике?
Если сравнить поведение нейронной модели Яндекс и простого текстового фактора, основанного на соответствии слов запроса и текста — это алгоритм BM25, который удобно использовать – как базовый уровень.
В качестве примера возьмем запрос [келлская книга] и посмотрим, какое значение принимают факторы на разных заголовках. Для контроля добавим в список заголовков явно нерелевантный результат.
Для контроля добавим в список заголовков явно нерелевантный результат.
Все факторы в Яндекс нормируются в интервал [0;1]. Ожидается, что BM25 имеет высокие значения для заголовков, которые содержат слова запроса. И предсказуемо, что этот фактор получает нулевое значение на заголовках, не имеющих общих слов с запросом.
Если обратить внимание на то, как ведет себя нейронная модель, то она одинаково хорошо распознаёт связь запроса как с русскоязычным заголовком релевантной страницы из Википедии, так и с заголовком статьи на английском языке! Кроме того, кажется, что модель «увидела» связь запроса с заголовком, в котором не упоминается келлская книга, но есть близкое по смыслу словосочетание («ирландские евангелия»). Значение же модели для нерелевантного заголовка существенно ниже.
Если посмотреть, как будут себя вести наши факторы, если переформулировать запрос, не меняя его смысла: [евангелие из келлса], то для BM25 переформулировка запроса превратилась в настоящую катастрофу — фактор стал нулевым на релевантных заголовках, а модель Яндекс демонстрирует отличную устойчивость к переформулировке: релевантные заголовки по-прежнему имеют высокое значение фактора, а нерелевантный заголовок — низкое. Кажется, что именно такое поведение мы и ожидали от штуки, которая претендует на способность «понимать» семантику текста.
Кажется, что именно такое поведение мы и ожидали от штуки, которая претендует на способность «понимать» семантику текста.
Итак, нейронная модель оказалась способна высоко оценить заголовок с правильным ответом, несмотря на полное отсутствие общих слов с запросом. Более того, стало очевидным то, что заголовки, не отвечающие на запрос, но всё же связанные с ним по смыслу, получают достаточно высокое значение фактора (как будто модель Яндекс «прочитала» рассказ Брэдбери и «знает», что это именно о нём идёт речь в запросе).
И что дальше?
Специалисты Яндекс находятся в самом начале интересного пути. Судя по всему, нейронные сети имеют отличный потенциал для улучшения ранжирования. Уже понятны основные направления, которые нуждаются в активном развитии. Например, очевидно, что заголовок содержит неполную информацию о документе, и хорошо бы научиться строить модель по полному тексту (как оказалось, это не совсем тривиальная задача).
Далее, можно представить себе модели, имеющие существенно более сложную архитектуру, нежели DSSM и есть основания предполагать, что таким образом Яндекс сможет лучше обрабатывать некоторые конструкции естественных языков.
Долгосрочную цель специалисты Яндекс видят в создании моделей, способных «понимать» семантическое соответствие запросов и документов на уровне, сравнимом с уровнем человека.
Статья основана на материалах Яндекс о том, как работает новый поисковый алгоритм «Палех»
Как алгоритм «Палех» работает с поисковыми подсказками
11799 2
| SEO | – Читать 4 минуты |
Прочитать позже
Игорь Горбенко
Эксперт по диджитал-маркетингу в Serpstat
Яндекс запустил новый поисковый алгоритм «Палех». С его помощью поисковик лучше понимает пользователя и находит страницы, которые соответствуют его запросам по смыслу, а не по словам.
Я решил узнать, как спустя неделю работает обновленный поиск Яндекса, а именно, как он ведет себя с поисковыми подсказками. Начну с самого начала.
Почему «Палех» и на чем строится новый алгоритм?
Новый алгоритм основан на нейронных сетях и помогает Яндексу находить соответствие между поисковым запросом и заголовками страниц, даже если у них нет общих ключевых фраз.
Например, при вводе в поиск «фильм про Джека-воробья» поисковик покажет несколько страниц с названием исходного фильма «Пираты Карибского моря»:
Казалось бы, у словосочетаний «Фильм про Джека-Воробья» и «Пираты Карибского моря» лексически мало общего, зато по смыслу связь очевидна. И Яндекс это хорошо теперь понимает.
«Палех» создан чтобы эффективнее работать с LSI. Для тех, кто забыл, что такое латентно-семантическое индексирование, ловите простое объяснение Алексея Чекушина 😉
Простые же смертные используют следующее определение латентное семантического индексирования:
LSI предполагает, что поисковый робот выделяет из текста не отдельные фразы, которые часто встречаются среди вводимых в поисковую строку, а выбирает тематику страницы на основании целого комплекса используемых на ней слов, включая словоформы, синонимы и близкотематические фразы. Вот так просто.
LSI-ключи учитываются поисковиком и тогда, когда нет достаточной статистики, чтобы предоставить более очевидные (на первый взгляд) результаты. Особенно, это касается редких низкочастотных фраз, по-настоящему уникальных.
В Яндексе график частотного распределения представляют в виде жар-птицы, у которых есть клюв, туловище и длинный хвост:
- Клюв — самые высокочастотные запросы. Список таких запросов не очень большой, но их задают очень-очень часто.
- Туловище — среднечастотные запросы.
- Хвост — низкочастотные и микронизкочастотные запросы. «По отдельности они встречаются редко, но вместе составляют существенную часть поискового потока и поэтому складываются в длинный хвост».
Такой хвост принадлежит Жар-птице, которая часто появляется на палехской миниатюре. Именно поэтому алгоритм получил название «Палех».
Как дела обстоят с поисковыми подсказками?
Выходит, что теперь с запуском нового алгоритма в Яндексе будет проще продвигаться по фразе, используя ее описательный анализ. Но где брать такие фразы, и как узнать, работают ли они?
Но где брать такие фразы, и как узнать, работают ли они?
Один из выходов — поисковые подсказки. Подсказки у Яндекса существуют уже давно. Это варианты наиболее популярных запросов, которые начинаются с той же буквы, что и вводимый запрос. Они появляются в специальном блоке под поисковой строкой и обновляются по мере набора новых символов в строке.
Подсказки — это своеобразные рекомендации поисковика, его предположения о том, что в действительности пытается найти пользователь. Если хотите продвинуть сайт по низкочастотным ключам, то можете использовать поисковые подсказки.
У нас, в Serpstat можно получить поисковые подсказки бесплатно (!), чтобы найти дополнительные LSI-фразы по интересующей теме. Они подгружаются в реальном времени.
Просто введите свой ключевик в поиск сервиса, выберите регион (в нашем случае, Яндекс) и перейдите в подраздел «SEO-анализ» → «Поисковые подсказки».
Используя подсказки, вы найдете связь между ключом и соответствующим ему LSI-ключем, и тем самым узнаете, как продвинуть этот ключ.
Заключение
Вспомним ключевые моменты этой статьи:
Новый алгоритм Яндекса «Палех» основан на нейронных сетях и помогает поисковику находить соответствие между поисковым запросом и заголовками страниц, даже если у них нет общих ключевых фраз.
LSI-ключи используются для ответов к редким низкочастотным фразам, по-настоящему уникальных.
«Палех» дает возможность продвигаться по ключевым фразам, используя их описательные аналоги.
Такие аналоги можно поискать в поисковых подсказках.
Оцените статью по 5-бальной шкале
5 из 5 на основе 1 оценок
Нашли ошибку? Выделите её и нажмите Ctrl + Enter, чтобы сообщить нам.
Рекомендуемые статьи
Обновления Serpstat +1
Анастасия Сотула
«Видимость» сайта в Serpstat: что это и как считается?
SEO
Author
Как с помощью Google карт попасть в топ поиска: подробное руководство
SEO +2
Игорь Мутерко
Как Serpstat помогает SEO- и PPC-менеджеру
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор подберет материалы, которые точно помогут в работе. Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Только полезные статьи, реальные кейсы и новости Serpstat раз в неделю. Присоединяйся к уютному комьюнити 🙂
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.
Поделитесь статьей с вашими друзьями
Вы уверены?
Спасибо, мы сохранили ваши новые настройки рассылок.
Сообщить об ошибке
Отменить
Палех Яндекс: особенности нового алгоритма
Друзья, я рада приветствовать вас на Blog-Bridge.ru. Вы, наверное, уже слышали новость о новом алгоритме Палех? Яндекс как поисковая система постоянно совершенствует свои алгоритмы обработки информации.
Вот и в этом году он анонсировал запуск нового алгоритма с креативным названием «Палех».
Я буквально недавно узнала эту новость и сразу обратила на это внимание. Думаю, что многие блогеры и веб-мастера тоже заинтересовались данной информацией.
Кроме того, мы ведь не так давно запустили новый эксперимент и я теперь полностью погружена в его реализацию.
Эксперимент «Комплексное продвижение блога». В ходе данного эксперимента вы узнаете: какими методами мы будем продвигать блог, какие из них окажутся эффективными и какие результаты они принесут; какой прирост посещаемости будет у нас ежемесячно; какими способами мы будем набирать подписную базу; как будут задействованы социальный сети; какими сервисами мы будем пользоваться для выполнения поставленных задач; и многое другое.
В ходе данного эксперимента вы узнаете: какими методами мы будем продвигать блог, какие из них окажутся эффективными и какие результаты они принесут; какой прирост посещаемости будет у нас ежемесячно; какими способами мы будем набирать подписную базу; как будут задействованы социальный сети; какими сервисами мы будем пользоваться для выполнения поставленных задач; и многое другое.
Ведь что мы сейчас наблюдаем в Сети? Сайтов, блогов и веб-порталов становится всё больше и больше, и вот чтобы давать максимально точные ответы на запросы пользователей, Яндекс начал использовать нестандартные подходы в обучении своих поисковых роботов.
Цель создания нового поискового алгоритма – улучшить качество предоставляемых ответов в выдаче для пользователей. Предыдущие поисковые модели подбирали информацию по соответствию ключевым словам. Новая модель на основе нейронных сетей умеет подбирать информацию по смыслу. Представляете? И это не фантастика!
Ещё одна интересная разработка нового метода поиска «Палех» — распознавание изображений. Поисковые роботы смогут различать образы на картинках – например, деревья или дома. И это тоже не фантастика 🙂
Поисковые роботы смогут различать образы на картинках – например, деревья или дома. И это тоже не фантастика 🙂
Итак, друзья, если вам хочется узнать побольше про этот подход и познакомиться с Жар-птицей Яндекса поближе, то приглашаю к прочтению
Содержание статьи:
- 1 Как соотносятся запросы с образом Жар-Птицы
- 2 Как используются нейронные сети в алгоритме «Палех» Яндекс
- 3 Как информация обрабатывается в трёхсотмерном пространстве
- 4 Перспективы развития семантического вектора
Как соотносятся запросы с образом Жар-Птицы
Наверняка, первый вопрос, который возникает, после прочтения названия алгоритма: «А почему собственно Палех?» Кстати, я подумала об этом в первую очередь. Есть еще среди моих читателей такие индивиды?
Название алгоритма у Яндекса «Палех» напрямую связано с палехской живописью. Ведь если вспомнить, то именно на росписях знаменитых художников часто использовался образ Жар-птицы. Я даже помню на уроках ИЗО пыталась нарисовать что-то из этого художественного жанра.
Но вернемся к теме нашей статьи.
Яндекс разделяет все поисковые запросы на три большие группы, которые соответствуют клюву, туловищу и длинному хвосту Жар-птицы.
- Первая группа – это высокочастотные запросы. Люди запрашивают ответы на них ежесекундно. О чем это могут быть запросы? Это новости, погода, такие распространённые вопросы «Как сбить температуру?» и тому подобные. Сам список высокочастотных запросов не велик – поэтому они составляют клюв Жар-птицы.
- Вторая группа — среднечастотные запросы. Их список значительно шире, поэтому они составляют туловище птицы.
- Третья группа – низкочастотные запросы. Это очень редкие и своеобразные запросы, многие из которых задаются единожды в истории поиска. Если все эти уникальные запросы сложить вместе, получится гигантская цифра: 100 млн. запросов ежедневно. Вы только вдумайтесь в эту цифру! Именно поэтому низкочастотные запросы составляют пышный и длинный хвост Жар-птицы.
Алгоритм «Палех» призван находить релевантные ответы на запросы из «длинного хвоста», чтобы не оставлять миллионы пользователей без ответа.
Статья в тему:
Как проверить релевантность страницы онлайн: самый крутой сервис
Что такое поисковая выдача Яндекса и Гугл или зачем нужен ТОП
Чем отличаются редкие запросы от обычных?
Редкие запросы не рассчитаны на прежние алгоритмы поисковых роботов. Например, люди пытаются, так сказать, по-человечески спросить у Яндекса ту или иную информацию.
Приведу конкретный пример из моего недавнего опыта. Решила дать послушать дочке песенку, которая нравилась мне в детстве, но я не помню ни её названия, ни кто поёт. И в поисковую строку Яндекса мне пришлось вбивать единственную строчку, которая всплыла в моей памяти «растет на болоте зеленая трава». Яндекс, конечно же, нашел мне эту песню, и мы и наслушались, и натанцевались под нее. Вот мой запрос — это редкий, поскольку не все ведь будут искать эту песню именно по этой строчке 🙂
Сюда же можно отнести и запросы от детей и подростков: «какой мне посмотреть интересный мультик, только не про пони».
Согласитесь, что высокочастотные запросы обрабатываются тысячи раз, поэтому Яндексу известна статистика поведения пользователей на каждый запрос из выдачи. А редкие запросы требуют индивидуального подхода, потому что по ним нет статистики – какие ответы подходят, а какие нет.
Вот чтобы различать и понимать смысл уникальных вопросов и были придуманы нейронные сети.
Как используются нейронные сети в алгоритме «Палех» Яндекс
Давайте теперь поговорим немного о нейронной сети.
В последние несколько лет они положительно зарекомендовали себя в обработке естественной информации: текстовой, звуковой и графической.
Что же из себя представляют эти сети?
Нейронные сети — это «искусственный интеллект», который после машинного обучения успешно распознает информацию.
Например, во время обучения им показывают картинки слона в ряду с другими картинками, обозначая изображения со слонами за положительные примеры, а все остальные – за отрицательные. Или сообщают нейронной сети набор характерных черт слона: длинный хобот, большие уши и так далее.
Или сообщают нейронной сети набор характерных черт слона: длинный хобот, большие уши и так далее.
Изображения без слонов и не характерные черты выдают за отрицательные примеры. Это позволяет находить верные изображения на запрос: «картинка со слоном» из миллиона других.
Принцип обучения нейронных сетей в алгоритме «Палех» тот же, только он помогает роботам соотносить поисковые запросы с текстами и заголовками на сайтах. Нейронной сети показывают ряд примеров: положительных и отрицательных.
Таким образом, нейросеть учится распознавать, насколько заголовок и текст отражают информацию, которую ищут люди.
Как информация обрабатывается в трёхсотмерном пространстве
Думаю, сложно поспорить с тем фактом, что особенность любого компьютера в том, что ему легче работать с числами. Поэтому Яндекс и придумал, чтобы нейронные сети переводили заголовки страниц на ресурсах в числа.
В Сети размещаются миллиарды различных заголовков. Они разбиваются нейронными сетями на группы, каждая из которых состоит из трёхсот чисел. Таким образом, все документы, занесённые после обработки информации в базу Яндекса, измеряются координатами в трёхсотмерном пространстве. Да, друзья, вы не ослышались, именно трёхсотмерное!
Таким образом, все документы, занесённые после обработки информации в базу Яндекса, измеряются координатами в трёхсотмерном пространстве. Да, друзья, вы не ослышались, именно трёхсотмерное!
В этом же ключе планируется работать с текстами веб-порталов.
Разобраться в такой системе для робота так же просто, как человеку представить систему координат с двумя осями х и y. Только для человека понятно двухмерное пространство, а для робота – трёхсотмерное. После того как заголовки или текст переводятся в числа и попадают в трёхсотмерное пространство, они представляют собой точку с координатами на оси (почти как в учебнике по алгебре).
Переведённые в числовой эквивалент заголовок и текст запроса располагают в одной системе координат. Таким образом, они представляют собой две точки в трёхсотмерном пространстве. В принципе все логично и достаточно просто.
Благодаря нахождению запроса и ответа в одном измерении, нейронной сети легко понять, насколько они друг другу соответствуют. Близкое расположение говорит о том, что текст точно отвечает на вопрос. И тогда именно его робот и даст в выдаче.
Близкое расположение говорит о том, что текст точно отвечает на вопрос. И тогда именно его робот и даст в выдаче.
Технология перевода информации в числа и их последующего измерения в системе координат получила название семантического вектора.
Перспективы развития семантического вектора
Изначально технология семантического вектора была задумана для улучшения качества выдачи на редкие запросы из «хвоста Жар-птицы». Но после короткого промежутка времени она дала положительные результаты, и стала использоваться в других сервисах.
Сейчас технология семантического вектора помогает выдавать максимально точные изображения на запросы пользователя. А в обозримом будущем предполагается исследовать в трёхсотмерном пространстве целые полотна текстов с ресурсов. Вообщем то ли еще будет 🙂
Нейронные сети всё время совершенствуются и выводят на новый уровень взаимодействие человека и компьютера. Благодаря нестандартному подходу подбора информации по смыслу – поисковая система в перспективе сможет отвечать на вопросы не хуже, чем человек. К этому в принципе все и движется.
К этому в принципе все и движется.
***
Друзья, на этом буду заканчивать свой пост. Интересна ли вам была данная информация? Как планируете ею воспользоваться? Делитесь в комментариях ))
С вами была Екатерина Калмыкова,
пока-пока!
что такое, как использовать и почему это хорошо?
По статистике каждый день поисковик получает до 100 млн. уникальных или просто редких запросов. В связи с этим Яндекс запустил новый алгоритм «Палех», основанный на работе нейронных сетей. Он помогает системе точнее отвечать на любые сложные запросы людей.
Почему «Палех»?
График распределения запросов по их популярности в Яндексе представлен в виде птицы, у которой клюв — высокочастотные запросы, туловище — среднечастотные и длинный хвост — низкочастотные. Соединив все 3 части, мы получаем очертания Жар-птицы, которая нередко встречается в палехской миниатюре (тип русской росписи яркими красками на темном фоне). Отсюда и необычное название.
На основе высокочастотных запросов накоплено немало поведенческой статистики в поисковой системе. Благодаря этому она быстрее находит нужный вам результат. С редкими запросами дело обстоит иначе — статистка зачастую отсутствует. Поэтому, когда вы вводите запрос типа «фильм, где фокусник тонет в аквариуме», Яндексу сложнее понять, какой результат лучше соответствует. Как решить эту задачу? На помощь пришли нейронные сети.
Благодаря этому она быстрее находит нужный вам результат. С редкими запросами дело обстоит иначе — статистка зачастую отсутствует. Поэтому, когда вы вводите запрос типа «фильм, где фокусник тонет в аквариуме», Яндексу сложнее понять, какой результат лучше соответствует. Как решить эту задачу? На помощь пришли нейронные сети.
Что такое нейронные сети?
Это способ машинного обучения, основанный на анализе картинок, звука и текста. Например, чтобы научить сеть идентифицировать разные объекты, вначале ей показывают множество изображений. По ним она учится отличать деревья от собак, людей от домов, легковые машины от грузовиков и т.д.
По той же схеме нейросеть учится распознавать тексты. Основу составляют примеры «запрос-заголовок», собранные с помощью накопленной пользовательской статистики. Среди множества таких пар нейросеть научилась находить те, где слова в заголовке и запросе совпадают. Самый подходящий заголовок становился лучшим, но в большинстве случаев он все равно не соответствовал изначальной потребности по смыслу. Чтобы добиться нужного результата, разработчики стали использовать такие случаи в качестве отрицательного примера. Изучая все больше и больше сочетаний, нейросеть постепенно начинала понимать смысловое соответствие между запросом и заголовками страниц. В результате – самые удачные из них действительно соответствуют запросу. Даже самому сложному.
Чтобы добиться нужного результата, разработчики стали использовать такие случаи в качестве отрицательного примера. Изучая все больше и больше сочетаний, нейросеть постепенно начинала понимать смысловое соответствие между запросом и заголовками страниц. В результате – самые удачные из них действительно соответствуют запросу. Даже самому сложному.
Одно из главных преимуществ технологии «Палех» Яндекса в том, что ему не страшны даже переформулировки. Теперь Яндексу осталось решить единственную и самую важную задачу — развить алгоритм до такой степени, чтобы он понимал все содержимое страницы.
Как нововведение повлияет на SEO?
Теперь сайты могут ранжироваться не только на точных ключевых словах, но и на близких по смыслу фразах, которые собраны в пользовательской базе российского поисковика. Например, понятия «seo» и «продвижение сайтов» одинаковые по смыслу, поэтому человеку будет выдаваться дополненная информация.
Новый алгоритм, в первую очередь, затронул те сайты, на которых контент размещен в большом объеме. Одни и те же ключи приобрели новый смысл и начали ранжироваться по таким запросам, по которым ранее они не находились. Если контента не только много, но он еще и качественный, то каждое слово в составе текста может находиться наравне с ключевым словом, схожим по тематике. Чтобы сайт хорошо ранжировался с учетом нового алгоритма, нужно выполнить три условия:
Одни и те же ключи приобрели новый смысл и начали ранжироваться по таким запросам, по которым ранее они не находились. Если контента не только много, но он еще и качественный, то каждое слово в составе текста может находиться наравне с ключевым словом, схожим по тематике. Чтобы сайт хорошо ранжировался с учетом нового алгоритма, нужно выполнить три условия:
- создавать много текстов,
- повышать качество текстов: учитывать пользу и вдумчиво прописывать ключи,
- размещать контент на сайт, которому доверяют.
Какой вывод мы делаем из вышесказанного? Если вы создавали тексты исключительно для поисковых роботов и обильно пичкали их ключевыми фразами, не задумываясь над качеством и количеством написанного, то пришло время это менять. Выполнив все три критерия создания контента, со временем вы заметите, что «Палех» пойдет на пользу. Более того, вы сможете повысить свои позиции, используя запросы с низкой частотностью. Их доля в сутки равна 30% от общей массы запросов, поэтому при грамотной оптимизации сайт начнет расти естественным путем.
Как с помощью «Палеха» получить новых клиентов?
Допустим, у вас нет возможности наполнить свой сайт контентом, который будет соответствовать критериям нового алгоритма Яндекса «Палех» и одновременно нравиться пользователям. Стоит обратиться к нам за грамотно написанным и оптимизированным текстом. Для начала мы проанализируем специфику вашей торговой ниши, чтобы понять, о чем писать и в какой форме преподносить информацию вашей целевой аудитории. Мы прекрасно понимаем, что материал создается для пользователя, а не поисковых роботов. Он должен снимать все возражения и вопросы о вашем товаре или услуге. Мы внедряем ключевые фразы и слова в разумном количестве и читабельном виде так, что они не выбиваются из общего полотна текста.
Прогнозируем результат
Мы тоже решили воспользоваться нейронными сетями во благо и разработали свой уникальный алгоритм прогнозирования. Он учитывает тысячи факторов, влияющих на поисковую выдачу, и предсказывает результат продвижения в сети. В конечном итоге мы получаем план работ над проектом, который помогает нам максимально быстро, эффективно и с минимальными затратами добиться высоких позиций. Нейросети предоставляют бесконечные возможности для развития сайтов и разработки новых смелых стратегий продвижения.
В конечном итоге мы получаем план работ над проектом, который помогает нам максимально быстро, эффективно и с минимальными затратами добиться высоких позиций. Нейросети предоставляют бесконечные возможности для развития сайтов и разработки новых смелых стратегий продвижения.
Если вы задумались о повышении прибыли, прочитайте полезные советы: 5 способов поднять продажи без крупных вложений
Как ИИ повлияет на контент?
1. Появление поисковых систем
Системы поисковых систем были разработаны в соответствии с ростом количества материалов в Интернете. Чем больше документов находили поисковые системы, тем более сложные алгоритмы использовались. Сначала поисковые системы с искусственным интеллектом были предназначены только для выполнения поиска по страницам, затем они решали простые задачи, а теперь отвечали на всестороннюю помощь пользователей.
Поисковые системы прошли следующие этапы развития:
- Шаблон наивного поиска — был поиск по словам, также называемый «инвертированный индекс». Также пользователи должны учитывать частоту слов и ранжирование страниц
- Ссылочное ранжирование – с увеличением количества страниц возникла необходимость ранжирования страниц, и ранжирование важности страниц было привязано к системам ранжирования. Рейтинг важности страниц зависел от качества и количества ссылок на эти страницы.
- Машинное обучение — сначала для Яндекса использовалась система под названием «Матрикснет». В 2017 году Яндекс начал использовать новую систему машинного обучения под названием Cat Boost. Cat Boost дает более точный рейтинг.
 Также пользователи должны учитывать частоту слов и ранжирование страниц
Также пользователи должны учитывать частоту слов и ранжирование страницИскусственный интеллект (ИИ)
2. Искусственный интеллект
ИИ основан на разработках машинного обучения. О разработках в этом направлении известно с 2013 года, когда были проведены первые исследования в области семантического анализа и возможностей системы Word2Vec. Google создала самообучающуюся систему с ИИ — Rank Brain — на основе этой программы. Система была запущена в 2015 году. Целью этого алгоритма было уловить смысл текстов путем поиска связей между отдельными словами.
Целью этого алгоритма было уловить смысл текстов путем поиска связей между отдельными словами.
Rank Brain — это часть алгоритма Hummingbird в Google. Когда эта система находит незнакомые слова, она ищет подсказки и синонимы по запросу. Найденные аналогии становятся основой для фильтрации данных. В настоящее время Rank Brain является одним из трех наиболее важных критериев оценки страницы вместе со ссылками и текстом.
В 2016 году Яндекс объявил о запуске нового алгоритма «Палех» на основе нейронных связей. Этот алгоритм позволяет осуществлять поиск страниц, соответствующих запросам как по ключевым словам, так и по смыслу. «Палех» анализирует заголовки страниц и находит скрытые смысловые связи.
Еще один алгоритм «Королев» был представлен в 2017 году. В отличие от «Палеха», «Королев» сравнивает семантические векторы запросов и целых страниц. Ранее для этой цели использовались заголовки. Кроме того, кроме нейронных связей, используется машинное обучение, основанное на поведении человека. Таким образом, миллионы пользователей выступают в роли оценщиков. Все алгоритмы имеют аналогичную процедуру с 1 задачей, которая предназначена для улучшения понимания сложных словесных запросов.
Таким образом, миллионы пользователей выступают в роли оценщиков. Все алгоритмы имеют аналогичную процедуру с 1 задачей, которая предназначена для улучшения понимания сложных словесных запросов.
3. Как изменилась SEO-оптимизация
Проникновение ИИ коренным образом изменило результаты запросов и правила SEO. Использование ИИ связано с определенными преимуществами:
- Увеличилась точность вывода по нечастым и низкочастотным запросам – поисковые системы понимают простой человеческий язык;
- В выдаче преобладают более качественные ресурсы – фильтруется спам и переоптимизация по ключевым словам;
- SEO-тексты не обязательны — учитываются только потребности пользователей. LSI-копирайтинг используется для оптимизации текстов под запросы пользователей.
- Можно выполнить деоптимизацию поисковой системы, чтобы удалить ссылки, связанные с определенным термином.
Несмотря на многочисленные преимущества, связанные с ИИ, есть и определенные недостатки:
- Нечеткие результаты поиска — робот не может точно определить нужный контекст, если значение многозначно. Поэтому предлагает несколько вариантов.
- Непрозрачная система ранжирования – пользователь не может указать область поиска, подбирая словосочетания, так как поисковые системы выбирают то, что считают нужным.
- Нетематические ресурсы в выдаче — часто в результатах поиска появляются сайты, не относящиеся к теме поиска, или в выдаче может быть найден некачественный контент.
 Поэтому предлагает несколько вариантов.
Поэтому предлагает несколько вариантов.5. ИИ можно использовать для оптимизации контент-стратегий
Менеджеры по контент-маркетингу сталкиваются с проблемами, связанными с принятием решения о том, какой тип контента использовать для привлечения клиентов и как побудить клиентов от этапа знакомства с брендом до совершения покупок. Once может разработать подробные профили клиентов и удовлетворить потребности целевой аудитории. Иногда ИИ может объяснить, что нужно клиентам, даже если они не могут сформулировать свои настоящие потребности. Анализируя профили в социальных сетях и отслеживая обсуждения в тематических блогах (форумах), ИИ может понять потребности клиентов. Многие известные бренды используют эти инструменты искусственного интеллекта, чтобы оправдать ожидания клиентов. Бренды могут создавать образы клиентов, изучая SEO-результаты целевой аудитории с помощью инструмента SEO-мониторинга. Кроме того, ИИ помогает решить эти проблемы, поскольку он позволяет идентифицировать личность покупателя с помощью анализа трафика, поведения в социальных сетях и взаимодействиях по электронной почте.
Многие известные бренды используют эти инструменты искусственного интеллекта, чтобы оправдать ожидания клиентов. Бренды могут создавать образы клиентов, изучая SEO-результаты целевой аудитории с помощью инструмента SEO-мониторинга. Кроме того, ИИ помогает решить эти проблемы, поскольку он позволяет идентифицировать личность покупателя с помощью анализа трафика, поведения в социальных сетях и взаимодействиях по электронной почте.
6. Новый взгляд на контент
ИИ позволяет создавать гиперперсонализированный контент со ссылкой на профили целевой аудитории. Это будет новая эра контент-маркетинга, поскольку он предлагает мощные инструменты для более эффективного управления удовлетворенностью клиентов. Раньше это было невозможно. Старомодные приемы больше не работают, и маркетологи должны воспользоваться преимуществами новых алгоритмов для создания потрясающего контента и маркетинговых стратегий.
7. Заключительные мысли
Имея в виду недавние изменения в подходах к поисковой оптимизации, маркетологи смогут разрабатывать более подробные маркетинговые стратегии, используя различные инструменты и устройства управления контентом. ИИ позволяет маркетологам сосредоточиться на потребностях клиентов на основе факторов ранжирования. ИИ — отличный помощник для маркетологов с разных точек зрения, поскольку он предлагает инструменты для создания контента, ожидаемого клиентами.
ИИ позволяет маркетологам сосредоточиться на потребностях клиентов на основе факторов ранжирования. ИИ — отличный помощник для маркетологов с разных точек зрения, поскольку он предлагает инструменты для создания контента, ожидаемого клиентами.
Яндекс — Вики | Golden
Яндекс — технологическая компания, которая создает интеллектуальные продукты и услуги на основе машинного обучения. Их цель — помочь потребителям и компаниям лучше ориентироваться в онлайн- и офлайн-мире. С 1997 года Яндекс предоставляет локальные поисковые и информационные услуги мирового класса. Кроме того, они разработали ведущие на рынке транспортные услуги по запросу, навигационные продукты и другие мобильные приложения для миллионов потребителей по всему миру. Яндекс, у которого более 30 офисов по всему миру, котируется на NASDAQ с 2011 года9.0005
Яндекс заблокирован на территории украины в 2017 году.
Хронология
Яндекс запустил проект «Рука помощи» для поддержки врачей, медсестер и других медицинских работников, а также всех, кто оказался в трудной ситуации. Службы доставки Яндекса развивались экспоненциально, в том числе из-за роста числа клиентов, вызванного карантином. Новый скачок в поисковых технологиях и главное улучшение за последние десять лет получило название YATI. Яндекс.Маркет, пионер системы сравнения покупок, снова присоединился к экосистеме Яндекса. у яндекс
Службы доставки Яндекса развивались экспоненциально, в том числе из-за роста числа клиентов, вызванного карантином. Новый скачок в поисковых технологиях и главное улучшение за последние десять лет получило название YATI. Яндекс.Маркет, пионер системы сравнения покупок, снова присоединился к экосистеме Яндекса. у яндекс
Экспресс-доставка продуктов и товаров для дома на дом менее чем за 15 минут после оформления заказа запускает летом Яндекс.Лавка. Яндекс запускает первую в России экосистему умного дома на базе Алисы. Яндекс представляет крупное обновление поиска (Vega). Яндекс добился значительного прогресса в беспилотных технологиях, протестировав в дорожных условиях автономного робота для доставки малогабаритных грузов и протестировав лидары собственной разработки. Образовательная инициатива Яндекса стартует в сентябре, когда компания объявляет об инвестициях в пять миллиардов рублей в подготовку 100 000 специалистов для ИТ-сектора в течение трех лет.
Яндекс представляет свой первый аппаратный продукт — Яндекс. Станцию, умную колонку, оснащенную русскоязычным голосовым помощником компании на основе искусственного интеллекта. Яндекс выводит свой автономный автомобиль из лаборатории на дорогу. В начале этого года Яндекс запускает два сервиса: каршеринг Яндекс.Драйв и сервис доставки заказов Яндекс.Еда. Яндекс выпускает большое обновление своей поисковой системы, которое включает в себя более тысячи улучшений.
Станцию, умную колонку, оснащенную русскоязычным голосовым помощником компании на основе искусственного интеллекта. Яндекс выводит свой автономный автомобиль из лаборатории на дорогу. В начале этого года Яндекс запускает два сервиса: каршеринг Яндекс.Драйв и сервис доставки заказов Яндекс.Еда. Яндекс выпускает большое обновление своей поисковой системы, которое включает в себя более тысячи улучшений.
Яндекс запустил первого диалогового ИИ-помощника, не ограниченного набором предопределенных сценариев, под названием «Алиса». Компания открыла исходный код CatBoost, новой библиотеки машинного обучения, основанной на повышении градиента. Яндекс разработал и внедрил новый поисковый алгоритм Королев. Компания начала тестировать свою беспилотную автомобильную технологию. «Яндекс.Такси» и Uber договорились об объединении бизнеса в России, Азербайджане, Армении, Беларуси, Грузии и Казахстане. Яндекс.Переводчик добавил нейронную модель машинного перевода. Компания также представила ряд новых услуг и продуктов для бизнеса, в том числе многофункциональное голосовое решение для подключенных автомобилей «Яндекс. Авто» и платформу для совместной работы на рабочем месте «Яндекс.Коннект».
Авто» и платформу для совместной работы на рабочем месте «Яндекс.Коннект».
Яндекс запустил новый алгоритм поиска, использующий нейронные сети для извлечения результатов поиска по смыслу, а не по ключевым словам. Назван в честь села Палех. Компания запустила образовательный проект «Яндекс.Лицей» по обучению программированию 14-15-летних. В браузер Яндекса и лаунчер Яндекса встроена технология персонализированных рекомендаций по контенту под названием Дзен. Яндекс запускает программу, направленную на развитие и поддержку образовательных веб-проектов по истории, литературе, языкознанию, искусству и философии. Также в этом году было выпущено приложение для записи на прием к врачу «Яндекс.Здоровье», а также новые сервисы для бизнеса — виртуальная автоматизированная система общения с клиентами «Яндекс.Телефония» и «Яндекс.Аудитория».
Яндекс разработал собственную технологию прогнозирования погоды под названием Meteum. Новые правила в Яндекс.Директе. В этом году запущено мобильное приложение «Яндекс. Паркинг» для водителей и «Яндекс.Радио». Также была выпущена бета-версия Яндекс.Транспорта. Заработали два сервиса для бизнеса: летом агрегатор логистических услуг «Яндекс.Доставка»; а осенью медиа-сервис, который, как автоматическое информационное агентство.
Паркинг» для водителей и «Яндекс.Радио». Также была выпущена бета-версия Яндекс.Транспорта. Заработали два сервиса для бизнеса: летом агрегатор логистических услуг «Яндекс.Доставка»; а осенью медиа-сервис, который, как автоматическое информационное агентство.
Яндекс открыл Yandex Data Factory, международный проект, предоставляющий решения для работы с большими данными корпоративным и корпоративным клиентам. Яндекс и Московская Высшая школа экономики совместно открыли факультет информатики, который готовит специалистов по двум направлениям — программной инженерии и прикладной математике и информатике. Выпущено мобильное новостное приложение и два новых сервиса — «Яндекс.Город» и «Яндекс.Мастер». Первый помогал пользователям находить и выбирать предприятия и организации до 2016 года, а второй помогал людям находить специалистов для своих бытовых задач и был закрыт через год после запуска.
На конференции ЯК-2013 Яндекс представил собственную технологию распознавания голоса SpeechKit и API для работы с ней. Яндекс стал ассоциированным членом CERN openlab. Яндекс открыл Yandex.Store, магазин приложений для Android.
Яндекс стал ассоциированным членом CERN openlab. Яндекс открыл Yandex.Store, магазин приложений для Android.
Яндекс выпустил браузер собственной разработки. Яндекс внедрил Real Time Bidding — технологию аукциона показов рекламы. Яндекс открыл свой облачный сервис хранения данных Яндекс.Диск. Яндекса
В мае Яндекс провел IPO на фондовой бирже NASDAQ в Нью-Йорке. Акции компании торгуются под тикером YNDX. Компания вышла за пределы постсоветского пространства, открыв 20 сентября в Турции портал yandex.com.tr. Он предлагает Яндекс.Поиск, Яндекс.Карты, Яндекс.Почту и другие сервисы для турецких пользователей. «Яндекс» представил свою новую технологию «Крипта», которая может классифицировать разные группы пользователей на основе их поведения в сети. Компания организовала соревновательный чемпионат по программированию «Яндекс.Алгоритм. Запущен Яндекс.Переводчик.
Продукты
Приобретения
Патенты
Дополнительные ресурсы
Воспроизведение видео в браузере — бета-версия браузера. Справка
Справка
Яндекс
ЯК 2021: Как живет Яндекс
8 декабря 2021
Яндекс — История — История Яндекса FinSMEs
FinSMEs
20 сентября 2021
FinSMEs
О компании | Рекламировать | Контакты | Отказ от ответственности | Новости | Ежедневный информационный бюллетень сделок FinSMEs.com от FinSMEs находится под лицензией Creative Commons Attribution-NonCommercial-NoDerivs 3.0 Unported License.
Яндекс выкупает долю Uber в Yandex Self-Driving Group, Eats, Lavka и Delivery за 1 млрд долларов
Ребекка Беллан
31 августа 2021 Российская компания 100% владеет всеми четырьмя предприятиями.
The Station: Рождение Rimac-Bugatti, Tesla выпускает бета-версию FSD v9 и Ola привлекает 500 миллионов долларов настоящие и будущие средства перемещения людей и посылок из пункта А в пункт Б. Я вернулся из своего путешествия и плаваю в электронных письмах. Если вы отправили мне сообщение в Твиттере, по электронной почте или в голубиной почте, пожалуйста, дайте мне несколько дней […]
Если вы отправили мне сообщение в Твиттере, по электронной почте или в голубиной почте, пожалуйста, дайте мне несколько дней […]
Yandex Self-Driving Group сотрудничает с Grubhub для роботизированной доставки в кампусы колледжей , объявила о партнерстве со службой доставки еды Grubhub, которая станет ее многолетним поставщиком роботизированной доставки в кампусах американских колледжей. По словам Дмитрия Полищука, генерального директора Yandex Self-Driving Group, Яндекс начнет работать этой осенью с десятками автомобилей и надеется достичь […]
Яндекс выступает против решения России ограничить иностранное владение стриминговыми сервисами до…
Надежда Цыденова
22 декабря 2020 г.
DealStreetAsia
Яндекс может быть затронут, поскольку он зарегистрирован на фондовой бирже Nasdaq.
ПОКАЗАТЬ ЕЩЕ
Ссылки
Яндекс Королев — пиар-ход, а не революция — Реальное время
09:00, 05. 09.2017
09.2017
Яндекс обновил свой поисковик и представил новый алгоритм ранжирования Королев. Презентация прошла с помпой, об этом написали практически все российские СМИ, а некоторые эксперты сочли этот шаг российских интернет-компаний революционным. Основное отличие от предыдущей версии в том, что новый алгоритм оценивает запросы не по ключевым словам, а по смыслу, причем — с высокой точностью за счет использования обучающихся нейронных сетей. «Реальному времени» удалось побеседовать с вице-президентом Российско-Тунисского делового совета и IT-предпринимателем Эльбрусом Латыповым, который доступным языком объяснил, как будет работать «Королев», как скоро пользователи заметят разницу в выдаваемых им результатах, будет ли Яндекс пионер и сколько людей сейчас обучает нейросеть российской компании.
«Хороший пиар-ход, больше направленный на привлечение доли рынка в России»
Эльбрус, как вы оцениваете Королев? Правда ли, что этот алгоритм можно назвать революционным?
Что касается революционности, то это скорее пиар-ход. В данном случае Яндекс перенимает опыт американских партнеров с намерением представить что-то «новое». На самом деле, если взять Google, аналогичный алгоритм под названием Hummingbird они разработали еще в 2013 году. Google в то время вел себя скромнее — они разработали алгоритм и представили его исключительно в профессиональной сфере, а не широкой публике.
В данном случае Яндекс перенимает опыт американских партнеров с намерением представить что-то «новое». На самом деле, если взять Google, аналогичный алгоритм под названием Hummingbird они разработали еще в 2013 году. Google в то время вел себя скромнее — они разработали алгоритм и представили его исключительно в профессиональной сфере, а не широкой публике.
Есть ли другие компании, кроме Google и Яндекса, которые используют нейросеть?
Нейронная сеть сегодня является модным словом. Машинное обучение, нейросети, искусственный интеллект — это своего рода тренд, за ним не будущее, а настоящее. В общем, объем информации в Интернете таков, что старые алгоритмы, разработанные Google и Яндексом, уже не подходят. Линейный анализ запросов больше не работает. Существует огромное количество информации, которая пересекается с другой информацией, и люди, которые используют поисковые системы, не получают должных результатов.
»Если взять Google, то аналогичный алгоритм под названием Hummingbird они разработали еще в 2013 году.
 паблик». Фото siteclinic.ru
паблик». Фото siteclinic.ruКолибри, Королев, Палех – такая система эффективна, когда человек пытается найти, например, название фильма или песни, но у него есть только часть ее описания. В этом случае линейный поиск не работает. Здесь он должен работать как человеческий мозг – анализировать картинку в целом и давать ответ не линейный, а смысловой. Человеческий мозг оперирует значениями, а не какими-то конкретными линейными показателями.
Например, вы ищете фильм Армагеддон , но забыли его название. Вы пишете в поиске: «Люди летят на метеор и спасают Землю». Линейный поиск даст вам несколько отдельных ссылок на каждое слово или фразу. Он даст вам метеор, Землю, какие-то актуальные образы, но не сам фильм. Новый алгоритм ищет значение всех слов вместе, объединяет их и дает единственный правильный ответ, который нашел бы человеческий мозг.
Если вернуться к Гуглу и Яндексу, то после элементарного анализа получим тот же результат. У Google и Яндекса почти одинаковые алгоритмы. Мы их не знаем, мы их не видим — это тайна, но в итоге имеем почти тот же результат. Ни одна из систем не имеет какого-либо серьезного преимущества.
Мы их не знаем, мы их не видим — это тайна, но в итоге имеем почти тот же результат. Ни одна из систем не имеет какого-либо серьезного преимущества.
Естественно, Яндекс более корректно работает с русскими запросами. Однако Google в последние годы также продвинулся в этой области и дает правильные ответы. Кстати, у Google релевантность выше, чем у Яндекса.
Поэтому тут сложно что-то сказать о революционности. Это хорошая презентация, хороший пиар-ход, но больше направленный на привлечение доли рынка на российском рынке.
«Яндекс привлек более миллиона волонтеров, которые обучают нейросети на личном опыте. Каждому человеку дается задание: что-то поискать и выбрать побольше правильных ответов. Так нейросеть учится». Фото inorehovo.ru
Нейронная сеть сейчас находится в процессе обучения. Как вы думаете, сколько времени потребуется, чтобы показать публике ощутимый результат?
Нейронная сеть — это алгоритм, который обучается с участием реальных людей. На сегодняшний день, по имеющейся у меня информации, Яндекс привлек более миллиона добровольцев, которые обучают нейросети на личном опыте. Каждому человеку дается задание: что-то поискать и выбрать побольше правильных ответов. Так учится нейронная сеть. Эффективность нейронной сети будет больше зависеть от алгоритмов, которые смогут обрабатывать информацию. По сути, это некий порог и подобие искусственного интеллекта, который будет анализировать сам, а пока ему нужно учиться у реальных людей.
На сегодняшний день, по имеющейся у меня информации, Яндекс привлек более миллиона добровольцев, которые обучают нейросети на личном опыте. Каждому человеку дается задание: что-то поискать и выбрать побольше правильных ответов. Так учится нейронная сеть. Эффективность нейронной сети будет больше зависеть от алгоритмов, которые смогут обрабатывать информацию. По сути, это некий порог и подобие искусственного интеллекта, который будет анализировать сам, а пока ему нужно учиться у реальных людей.
Проблема в том, что человеческий мозг работает намного мощнее любой техники. Все существующие нейронные сети очень примитивны по сравнению с нашим мозгом. Сегодня трудно сказать, сколько времени потребуется, чтобы технология приблизилась к человеческим возможностям, к анализу и восприятию на том же уровне.
«По большому счету, нейронные сети и искусственный интеллект находятся в зачаточном состоянии»
Согласны ли вы с теми, кто говорит, что благодаря Королеву качество выдаваемого контента повысится? Когда пользователь это увидит?
Думаю теперь будет сложно заметить. Эта огромная работа будет заметна через несколько лет. Увидеть это «невооруженным глазом» пока невозможно. По большому счету, нейронные сети и искусственный интеллект находятся в зачаточном состоянии, и нас ждет огромная работа. Думаю, на данный момент еще и 10% работы не сделано.
Эта огромная работа будет заметна через несколько лет. Увидеть это «невооруженным глазом» пока невозможно. По большому счету, нейронные сети и искусственный интеллект находятся в зачаточном состоянии, и нас ждет огромная работа. Думаю, на данный момент еще и 10% работы не сделано.
Вы наверняка слышали об исследовании, результаты которого показывают, что женщины обычно формулируют свой запрос более подробно, а мужчины используют ключевые слова. Унифицирует ли алгоритм этот момент, как вы думаете?
Вы затронули интересный момент. Мы вернемся к уникальности человеческого мозга, к тому, что он по-разному функционирует у мужчин и женщин. Мужчины мыслят более конкретно, женщины – более абстрактно. Это огромная работа для искусственного интеллекта, а также для изучения нейронных сетей — различать мужчин и женщин.
«Перед разработчиками ИИ и нейронных сетей стоит огромная задача — не только различать желания пользователей, но и распознавать их пол.
 Задача очень интересная». Фото iab.ru
Задача очень интересная». Фото iab.ruДаже если взять одинаковую просьбу женщины и мужчины, необходимый результат для каждого может быть очень разным, хотя они оба будут использовать одинаковый набор слов. Они хотят другого результата, понимаете? Это другая история. Именно поэтому перед разработчиками ИИ и нейросетей стоит огромная задача — не только различать желания пользователей, но и распознавать их пол. Задача очень интересная.
Правда ли, что продвижение сайта усложнится из-за Короева? Что будет с методами SEO-копирайтинга?
Я думаю, SEO не изменится. Сейчас идет противостояние — есть те, кто продвигает сайты, а есть сами поисковые системы. Они стараются оптимизировать поиск и выводить свои сайты в топ, но во многих случаях это не совсем справедливо. В свою очередь поисковые системы с этим борются. Следует также иметь в виду, что они оба зарабатывают на этом деньги.
Возможно, мы увидим другой способ продвижения. Возможно, в итоге, чтобы оптимизировать поиск и сделать его справедливым для всех игроков, будут задействованы именно нейронные сети и ИИ. Я не думаю, что правила игры существенно изменятся, скорее будут использоваться новые механизмы, потому что это прежде всего бизнес.
Я не думаю, что правила игры существенно изменятся, скорее будут использоваться новые механизмы, потому что это прежде всего бизнес.
Лина Саримова
Как ИИ повлияет на контент в будущем SEO?
1. Появление поисковых системУвеличение объема контента, доступного в Интернете, привело к развитию поисковых систем. Когда поисковые системы обнаруживали больше документов, использовались более сложные алгоритмы. Первоначально поисковые системы ИИ предназначались только для выполнения поиска по страницам; позже они были созданы для выполнения простых задач, а сегодня они отвечают на запросы пользователей о всесторонней помощи.
Поисковые системы прошли следующие этапы развития:
- Поиск по словам, получивший название «перевернутый индекс», был наивным шаблоном поиска. Пользователи также должны учитывать частоту терминов и диапазон страниц.
- Ссылочное ранжирование – по мере роста количества страниц возникла необходимость их ранжирования, а в системы ранжирования был добавлен рейтинг важности страниц. Качество и количество переходов на эти страницы использовались для определения их ценности.
- Первоначально Яндекс использовал систему машинного обучения под названием «Матрикснет». Яндекс начал внедрять Cat Boost, новый метод машинного обучения, в 2017 году. Cat Boost обеспечивает более точное ранжирование.
 Качество и количество переходов на эти страницы использовались для определения их ценности.
Качество и количество переходов на эти страницы использовались для определения их ценности.Искусственный интеллект (ИИ)
2. Искусственный интеллект
Достижения в области машинного обучения лежат в основе ИИ. С 2013 года, когда были проведены первые исследования в области семантического анализа и возможностей системы Word2Vec, в этом направлении произошли подвижки. На основе этой программы Google разработал Rank Brain, самообучающуюся систему искусственного интеллекта. В 2015 году система была запущена. Цель этого алгоритма заключалась в том, чтобы найти отношения между разными словами, чтобы уловить смысл текстов.
Rank Brain — это компонент алгоритма Hummingbird от Google. Когда эта система встречает неизвестные слова, она делает запрос, чтобы найти предложения и синонимы. Фильтрация данных основана на обнаруженных аналогиях. Вместе со ссылками и текстом Rank Brain в настоящее время является одним из трех наиболее важных факторов оценки страницы.
Фильтрация данных основана на обнаруженных аналогиях. Вместе со ссылками и текстом Rank Brain в настоящее время является одним из трех наиболее важных факторов оценки страницы.
В 2016 году Яндекс объявил о запуске нового нейросетевого алгоритма «Палех». Этот метод позволяет выполнять поиск по страницам, который соответствует запросам как по ключевым словам, так и по смыслу. «Палех» исследует заголовки страниц на наличие скрытых смысловых связей.
В 2017 году был представлен новый алгоритм под названием «Королев». В отличие от «Палеха», «Королев» исследует как семантические векторы поисковых запросов, так и целые страницы. Ранее для этого использовались заголовки. Кроме того, за исключением нейронных сетей, используется машинное обучение, основанное на поведении человека. Миллионы пользователей участвуют таким образом в качестве оценщиков. В каждом алгоритме есть процедура, состоящая из одной задачи, которая разработана, чтобы помочь людям понять длинные и сложные запросы.
3. Как изменилась SEO-оптимизация
Проникновение ИИ коренным образом изменило результаты запросов и правила SEO. Использование ИИ связано с определенными преимуществами:
- В результате преобладают более качественные ресурсы – фильтруется спам и переоптимизация по ключевым словам; Улучшилась точность вывода по редким и низкочастотным запросам — поисковики понимают простой человеческий язык;
- Не обязательно использовать SEO-тексты; следует учитывать только потребности пользователей. LSI-копирайтинг — это метод оптимизации документов на основе поисковых запросов пользователей.
- Чтобы отделить ссылки, связанные с определенным термином, может использоваться деоптимизация поисковой системы.
Несмотря на многочисленные преимущества, связанные с искусственным интеллектом, у него есть и определенные недостатки:
- Нечеткие результаты поиска — если значение многозначно, робот не сможет правильно указать требуемый контекст. В результате он предоставляет множество альтернатив.
- Непрозрачный механизм ранжирования — поскольку поисковые системы извлекают то, что считают релевантным, пользователь не может указать область поиска, выбирая словосочетания.
- Нетематические ресурсы в выдаче — сайты, не относящиеся к теме поиска, часто появляются в результатах поиска, а в выдаче часто содержится некачественный контент.
 В результате он предоставляет множество альтернатив.
В результате он предоставляет множество альтернатив.5. ИИ можно использовать для оптимизации контент-стратегий
Менеджеры по контент-маркетингу сталкиваются с проблемами при выборе того, какой тип контента использовать для привлечения клиентов и как вдохновить клиентов на совершение покупок по мере того, как они переходят от изучения бренда к знакомству с ним. Это. Можно создавать полные профили клиентов и реагировать на потребности целевой аудитории. Даже если клиенты не могут определить свои истинные потребности, ИИ иногда может объяснить, что им нужно. ИИ может понять желания клиентов, анализируя профили в социальных сетях и наблюдая за обсуждениями в тематических блогах (форумах). Эти ИИ-решения используются несколькими известными брендами для удовлетворения ожиданий клиентов. Используя инструмент мониторинга SEO для изучения результатов SEO целевых групп, бренды могут создавать профили потребителей. Кроме того, искусственный интеллект помогает решить эти проблемы, позволяя идентифицировать личность покупателя с помощью мониторинга трафика, поведения в социальных сетях и взаимодействия по электронной почте.
Эти ИИ-решения используются несколькими известными брендами для удовлетворения ожиданий клиентов. Используя инструмент мониторинга SEO для изучения результатов SEO целевых групп, бренды могут создавать профили потребителей. Кроме того, искусственный интеллект помогает решить эти проблемы, позволяя идентифицировать личность покупателя с помощью мониторинга трафика, поведения в социальных сетях и взаимодействия по электронной почте.
6. Новый взгляд на контент
ИИ позволяет создавать гиперперсонализированный контент на основе профилей целевых потребителей. Это будет новая эра контент-маркетинга, поскольку он предоставляет потрясающие инструменты для лучшего управления удовлетворенностью потребителей. Раньше это было невозможно. Старые методы больше не эффективны, и маркетологи должны использовать новые алгоритмы для создания потрясающего контента и маркетинговых тактик.
7. Заключительные мысли
Маркетологи смогут разрабатывать более сложные маркетинговые кампании, используя многочисленные платформы и устройства управления контентом, принимая во внимание текущие разработки в области методов поисковой оптимизации. Основываясь на переменных ранжирования, ИИ позволяет маркетологам сосредоточиться на требованиях клиентов. С разных точек зрения искусственный интеллект является огромным подспорьем для маркетологов, поскольку он предоставляет инструменты для создания того типа контента, который нужен клиентам.
Основываясь на переменных ранжирования, ИИ позволяет маркетологам сосредоточиться на требованиях клиентов. С разных точек зрения искусственный интеллект является огромным подспорьем для маркетологов, поскольку он предоставляет инструменты для создания того типа контента, который нужен клиентам.
Нужна помощь в поиске вашей компании в Интернете? Stridec — ведущее SEO-агентство в Сингапуре, которое может помочь вам достичь ваших целей с помощью структурированной и эффективной программы SEO, которая привлечет больше клиентов и продаж. Свяжитесь с нами для обсуждения сейчас.
Нужно ли обновлять яндекс на королеве. Алгоритм Яндекса
В 2015 году на рынке бинарных опционов появился проект «Алгоритм Королева», его сайт — algoritm-koroleva.com, который представляет собой автоматическую торговую систему. По словам авторов, для его использования нужно иметь минимальные знания о финансовых рынках, так как это полноценный торговый робот, совершающий сделки в автоматическом режиме. Главным условием успешной работы советника является наличие необходимой мощности компьютерной техники.
Главным условием успешной работы советника является наличие необходимой мощности компьютерной техники.
Разработчики проекта Денис Королев и Максим Никитин создали систему, которая определяет мощность компьютера и при выполнении необходимых требований пользователь становится участником проекта. После установки программы компьютеры объединяются в большие сегменты, формирующие устойчивый тренд. Это дает возможность зарабатывать каждому участнику системы. Выбор бинарных опционов обусловлен доступностью способов заработка и значительной прибылью.
Авторы призывают участников проекта стать финансово независимыми, работать только на себя. Денис Королев и Максим Никитин — молодые специалисты в области информационных технологий, которые, несмотря на свою молодость, всего за 14 месяцев сумели создать собственный продукт и заработать более $2 млн.
Ежедневная прибыль трейдера, работающего с проектом, может достигать более 500 долларов в день, а владельцы мощных компьютеров могут рассчитывать на в несколько раз больше. Для работы советника подойдет не только Персональный компьютер, но и смартфоны, планшеты и другие мобильные устройства.
Для работы советника подойдет не только Персональный компьютер, но и смартфоны, планшеты и другие мобильные устройства.
Как работает алгоритм Королева?
Каждый клиент, зашедший на сайт, проходит проверку своего компьютера и получает результаты о возможной ежедневной прибыли. Далее вам необходимо стать подписчиком и зарегистрировать торговый счет у одного из финансовых посредников. К надежным компаниям авторы относят брокеров WhiteOption и Ubinary.
Сумма начального депозита может быть минимальной, но рекомендуемые инвестиции от 300$. Общее количество участников системы составляет более 1000 человек. Успех проекта подтверждают многочисленные видеоотзывы, оставленные каждым участником.
На сайте есть таблица с ежедневной статистикой транзакций. Исходя из этих данных следует, что самые прибыльные контракты заключаются по валютным парам, а средняя прибыль участника достигает более 200 долларов за сделку. Программа предоставляется бесплатно, авторы зарабатывают наравне со всеми участниками. Большое количество подписчиков гарантирует успех всей команды.
Большое количество подписчиков гарантирует успех всей команды.
Какие онлайн отзывы?
Проект «Алгоритм Королева» числится на многих интернет-ресурсах как мошеннический. По сути, авторы являются всего лишь агентами брокеров и работают за реферальные отчисления с депозитов привлеченных трейдеров. Отзывы с сайта проекта не соответствуют действительности и сделаны на платной основе. Вся торговая статистика «нарисована» авторами для привлечения доверчивых инвесторов.
Яндекс запустил новый алгоритм ранжирования — «Королев». Теперь поисковик сопоставляет значения поискового запроса и страницы. Это очень удобно для пользователей. Однако что означает новый алгоритм для сеошников и владельцев сайтов, как изменится продвижение и стоит ли ждать изменения посещаемости.
Как никогда весь SEO-мир ждал запуска нового алгоритма ранжирования, анонсированного 22 августа 2017 года. Все-таки такие объявления абсолютно нетипичны для Яндекса, обычно они предпочитают не рассказывать о своих планах, а анонсировать следующий выпуск алгоритма ранжирования постфактум.
22 августа 2017 года Яндекс запустил новую версию поиска. В его основе поисковый алгоритм «Королев» (с 2008 года новые алгоритмы ранжирования в Яндексе носят названия городов). Алгоритм использует нейросеть для сопоставления смысла запросов и веб-страниц — это позволяет Яндексу точнее реагировать на сложные запросы. Для изучения новой версии поиск использует поисковую статистику и рейтинги миллионов людей. Таким образом, в развитие поиска вносят свой вклад не только разработчики, но и все пользователи Яндекса.
Сфера действия нового алгоритма практически не затрагивает традиционные направления SEO-продвижения, к которым в первую очередь относится коммерческая выдача. «Королев» оказался логическим продолжением алгоритма «Палех» и предназначен для обслуживания длинного хвоста микрочастотных запросов, обычно заданных на естественном языке. Особенностью таких запросов является то, что релевантные им документы могут не содержать многих слов, входящих в запрос. Это сбивает с толку традиционные алгоритмы ранжирования, основанные на релевантности текста.

Решение было найдено в виде использования нейронных сетей, которые также обучаются на поведении пользователей. Поэтому новый алгоритм Яндекса работает на основе нейросети. Он учится на примерах пользовательских запросов и выбирает ответы, исходя из смысла текста на странице. Это означает, в частности, что он будет намного эффективнее работать с нестандартными запросами, когда пользователи сами не уверены, как называется то, что они хотят найти. Тут многое зависит от вычислительной мощности.
В целом такой подход к решению задачи ранжирования длинного микрочастотного хвоста запросов не нов. Еще в 2015 году стало известно о технологии, которую использует поисковик. Система Google для поиска ответов на многословные запросы, заданные на естественном языке — RankBrain. Эта технология, также основанная на машинном обучении, позволяет распознавать наиболее значимые слова в запросах и анализировать контекст, в котором осуществляется поиск. Это позволяет найти релевантные документы, которые не содержат всех слов запроса.

Кроме того, алгоритм работает и с картинками. Он анализирует содержимое изображения и подбирает нужный вариант на его основе, а не только по описанию в тегах или окружающему его тексту.
Однако длинный хвост микрочастотных многословных запросов на естественном языке вполне может заинтересовать «сжигателей» информационной семантики — создателей так называемых инфосайтов «на все случаи жизни». В общем, они уже так стараются, чтобы как можно больше известных им запросов, которые им удается получить с помощью различных методов сбора семантики, организовать точное вхождение в свои тексты. Там же, где не будет точных вхождений, т.е. по запросам, не засосанным «смысловым пылесосом» создателей инфосайтов или по которым не дали точных вхождений в содержании, «Королев» начинается patrimony, который предназначен для поиска совпадений между запросами и ответами в случае, когда между ними мало пересечений по ключевым словам. В таких случаях «Королев», несомненно, повысит требования к качеству контента, а действительно интересные читабельные статьи еще больше выиграют от сборников статей. ключевые фразы, разбавленные водой, ведь именно в таких статьях могут содержаться полезные для нового алгоритма сигналы. Ну а всем остальным сеошникам можно совсем расслабиться — очередная порка откладывается. Жертв и разрушений нет.
ключевые фразы, разбавленные водой, ведь именно в таких статьях могут содержаться полезные для нового алгоритма сигналы. Ну а всем остальным сеошникам можно совсем расслабиться — очередная порка откладывается. Жертв и разрушений нет.
Запустив Палех, Яндекс научил нейросеть преобразовывать поисковые запросы и заголовки веб-страниц в группы чисел — семантические векторы.
Важным свойством таких векторов является то, что их можно сравнивать друг с другом: чем сильнее сходство, тем ближе по смыслу запрос и заголовок друг к другу.
Чем отличается от Палеха?
Основным отличием нового алгоритма, помимо улучшения технической реализации, является возможность распознавать схожие «смыслы» по всему документу, а не только по заголовку (Title), появляющемуся в окне браузера.
Как работает алгоритм Королева
Алгоритм поиска «Королев» сравнивает семантические векторы поиск запросов и целые веб-страницы — не только их заголовки.
 Это позволяет выйти на новый уровень понимания смысла.
Это позволяет выйти на новый уровень понимания смысла.Как и в случае с Палехом, тексты веб-страниц конвертируются в семантические векторы нейросетью. Эта операция требует много вычислительных ресурсов. Поэтому Королев вычисляет векторы страниц не в реальном времени, а заранее, на этапе индексации.
Когда человек делает запрос, алгоритм сравнивает вектор запроса с уже известными ему векторами страниц.
Эффект королевы
Способность понимать смысл особенно полезна при обработке редких и необычных запросов — когда люди пытаются своими словами описать свойства объекта и ожидают, что поиск подскажет его название.
Такая схема позволяет начать отбор веб-страниц, соответствующих запросу по смыслу на ранних этапах ранжирования. В «Палехе» семантический анализ — один из завершающих этапов: через него проходит всего 150 документов. В «Королеве» производится 200000 документов.
Кроме того, новый алгоритм не только сопоставляет текст веб-страницы с поисковым запросом, но и обращает внимание на другие запросы, по которым люди приходят на эту страницу.

Таким образом можно установить дополнительные смысловые связи.
Люди учат машины
Использование машинного обучения, а особенно нейронных сетей, рано или поздно позволит научить поиск оперировать смыслами на человеческом уровне. Для того, чтобы машина поняла, как решить ту или иную задачу, необходимо показать ей огромное количество примеров: положительных и отрицательных. Такие примеры приводят пользователи Яндекса.
Нейронная сеть, используемая алгоритмом Королёва, обучена обезличенной статистике поиска. Системы сбора статистики учитывают, на какие страницы пользователи переходят по тем или иным запросам и сколько времени они там проводят.
Если человек открыл веб-страницу и «завис» там на долгое время, вероятно, он нашел то, что искал — то есть страница хорошо откликается на его запрос. Это положительный пример.
Отрицательные примеры подобрать гораздо проще: достаточно взять запрос и любую случайную веб-страницу. Статистика, используемая для обучения алгоритма, является обезличенной
Статистика, используемая для обучения алгоритма, является обезличенной
Компания Matrixnet, создающая формулу ранжирования, также нуждается в помощи людей.
Толока
Чтобы поиск развивался, люди должны постоянно оценивать его работу. Когда-то выставлением оценок занимались только сотрудники Яндекса — так называемые асессоров. Но чем больше оценок, тем лучше — поэтому Яндекс всех к этому привлек и запустил сервис Яндекс.Толока. Сейчас там зарегистрировано более миллиона пользователей: они анализируют качество поиска и участвуют в улучшении других сервисов Яндекса. Задания на Толоке платные — рядом с заданием указана сумма, которую можно заработать. За более чем два года существования сервиса толокеры поставили около двух миллиардов оценок.
Современный поиск основан на сложных алгоритмах. Алгоритмы придумывают разработчики, а учат миллионы пользователей Яндекса. Любой запрос — это анонимный сигнал, который помогает машине лучше понимать людей. Новый поиск — это поиск, который мы делаем вместе.
Новый поиск — это поиск, который мы делаем вместе.
Здравствуйте уважаемые читатели блога сайта. Прошу прощения, что некоторые посты выходят с большим временным интервалом, но я запустил еще несколько проектов, резко вырвавшихся в ТОП за 1,5 месяца, используя свои знания в области блогерства (кому нужен совет, пишите в личку). Вам предстоит разрываться между проектами и строительством дома для своей семьи.
Сегодня мы коснемся нового алгоритма Королева от Яндекса и попробуем сравнить его с предшественниками. Лично на моем блоге это особо не отразилось, разве что полезные и объемные статьи стали еще выше в ТОПе. Что ж, давайте внимательно рассмотрим все в статье и сделаем необходимые выводы после наблюдения за этим алгоритмом.
Алгоритм Королев Яндекс — что это такое и как работает
В конце августа 2017 года вышел новый алгоритм Яндекс Королев. Новость об обновлении в поисковике сразу же заинтересовала гендиректора специалистов и СМИ.
Основная функция The Queen заключается в увеличении скорости обработки информации и повышении качества семантического анализа текста.
Скорость обработки данных увеличилась в несколько тысяч раз. Палех использовал 150 документов для формирования ТОП. Сейчас более 200 000 статей сравниваются друг с другом. Такой результат был достигнут за счет оптимизации протокола ранжирования.
Чтобы понять новый алгоритм, мы должны вернуться на шаг назад в Палех. Его презентация состоялась 2 ноября 2016 года. Статистика показала, что наибольшая часть поисковых фраз приходится на низкочастотные фразы, заточенные под единственно правильный ответ. Эта часть приходится на длинный хвост птицы.
Чтобы дать правильный ответ клиенту, необходимо иметь ассоциативное мышление и навык самообучения, как у человека. Лучше всего для таких задач подходят нейронные сети, именно поэтому они и стали основой нового алгоритма.
Основная цель «Королевы»
При желании найти конкретный предмет человек начинает описывать его свойства, это особенности ассоциативного мышления. Если мы забываем название видео, то начинаем говорить, что было внутри: «фильм о девушках во время войны» или «фильм о существе с хвостом и крыльями». В первом случае Яндекс выдает «А зори здесь тихие», во втором варианте получаем «химеру».
В первом случае Яндекс выдает «А зори здесь тихие», во втором варианте получаем «химеру».
Яндекс улучшает качество сравнения многословных фраз. Программа анализирует взаимосвязь между каждым словом в предложении и выстраивает некую ассоциацию при множестве ответов. Так же, как человеческий мозг.
Что нового?
Инновации:
- семантический вектор для всего контента, а не только для заголовка;
- сравнение более 200 000 статей при формировании результатов поиска; Учитывается поведение
- пользователей на странице;
- человек помогают обучать систему.
Королев анализирует не только заголовок, но и весь контент (включая фото, видео, таблицы и т.д.) и на его основе создает смысловой вектор.
Главным нововведением стало многократное ускорение работы методов поиска. Раньше семантический вектор строился в момент ввода фразы в поисковую строку. Этот метод сильно нагружал сервер и замедлял скорость выдачи ответа.
При отправке поисковой фразы ее семантический вектор сравнивается с массивом, уже записанным в базу данных. Палех сравнивает около 150 вариантов, а в новой версии единовременно анализируется более 200 000 статей. Это увеличивает шанс найти нужный ответ.
Нейросеть Яндекс: принцип работы нейросети Королев + примеры
Главной особенностью нейросети является возможность самообучения. Работа ведется не только по обдуманным формулам, но и на основе предыдущего опыта и ошибок.
Человеческий мозг представляет собой огромную нейронную сеть с ассоциативным мышлением, в то время как компьютеры пытаются имитировать человеческое поведение, воссоздавая архитектуру нейронных сетей.
Особенности структуры нейронной сети
Нейронная сеть представляет собой набор одиночных нейронов, каждый из которых хранит или обрабатывает информацию. Каждый из нейронов способен получать, обрабатывать и отдавать сигналы. Поток входных данных постепенно обрабатывается от одного нейрона к другому и в конце получается нужный результат.
Искусственные нейронные сети передают между собой условные веса — числа от 0 до 1, чтобы определить, насколько тот или иной вариант поступающей информации соответствует необходимой информации. После окончания анализа наиболее подходящим для ответа на вопрос считается нейрон с наибольшим весом.
На схеме изображена нейронная сеть. Обрабатываются первые два слоя. Каждый из нейронов содержит определенную функцию, которая получает входные данные и после обработки выдает требуемый ответ. Так сравниваются семантические векторы.
Семантические векторы
Компьютеры не умеют работать со словами или изображениями, поэтому они используют массивы чисел для сравнения информации друг с другом. Поисковые системы должны самостоятельно определить основную тему и идею текста, чтобы дать пользователю то, что ему нужно.
Чем похожи вектора заданного вопроса и текста, тем выше статья в приоритете поиска. Королева использует анализ всего контента:
- таблиц;
- текст;
- фото;
- видео;
- рубрик;
- котировок;
- списков;
- выделений (курсив, полужирный и т. д.).
 д.).
д.).Качество построения вектора повышается в несколько раз за счет преобразования большего количества информации.
Для создания векторов используется нейронная сеть, текст пропускается через последовательность нейронов и в результате получается выходной трехсотмерный массив чисел. В дальнейшем она заносится в единую базу данных и используется для сравнения.
Образование
Основной особенностью нейронных сетей является обучение. В отличие от стандартных алгоритмов, нейроны способны запоминать свой предыдущий опыт и учиться на нем. Компьютер с каждым разом все лучше и лучше различает информацию.
Раньше сотрудники компании занимались обучением, их задачей было перебирать миллионы запросов и менять приоритеты выдачи по своему усмотрению. Затем разработчики создали приложение Яндекс.Толока, представляющее собой список простых задач. Необходимо следить за запросами и оценивать качество результатов поиска. За каждое задание платят около 0,1-1$
Какой контент считается хорошим по новому алгоритму поиска
Наиболее подходящей для выдачи ТОП будет статья, содержащая максимум полезной информации для пользователя и соответствующая запросу. Поэтому его следует разделить на разделы, чтобы раскрыть всевозможные вопросы от клиента.
Поэтому его следует разделить на разделы, чтобы раскрыть всевозможные вопросы от клиента.
Королева отдает приоритет поведению пользователя на странице. Поэтому задача администраторов постараться удержать пользователя и заинтересовать его. Для этого используйте структуру заголовков, таблиц, списков, выделения, фото и видео.
Новые поисковые приоритеты
SEO-специалисты после релиза провели исследование по оценке изменения приоритетов ранжирования. Особых изменений не наблюдалось, приоритеты остались:
- структурированный текст;
- полнота раскрытия темы; чтение содержания простаты
- ;
- соответствие заголовков смысловому содержанию текста;
- корректное формирование семантического ядра.
Главное писать для живых людей, этот приоритет остается самым важным.
Почему Яндекс запустил новый поисковый алгоритм и чем он грозит сайтам
Любая компания стремится сделать свой продукт лучшим на рынке услуг. В этом случае самым большим конкурентом Яндекса является Google. Нововведения созданы для следующих целей:
В этом случае самым большим конкурентом Яндекса является Google. Нововведения созданы для следующих целей:
- улучшение качества поиска по нестандартным вопросам;
- привлечение новых инвесторов;
- увеличение производительности ранжирования (более 200 000 статей при формировании выдачи).
Основной целью было улучшение качества выдачи. Кроме того, нужно было показать инвесторам, что работа в компании кипит и их деньги используются по назначению. Нововведения впоследствии были использованы для создания голосового помощника «Алиса».
Строка предыдущих алгоритмов
Чтобы лучше понять новые технологии, нужно вернуться в прошлое. В этом случае рассмотрим ряд предыдущих алгоритмов, которые использовались поисковой системой для ранжирования.
Сначала в Интернете было всего несколько тысяч сайтов; чтобы найти по ним нужную статью, достаточно было сравнить ключевые слова поисковой фразы. Впоследствии глобальная сеть разрослась в геометрической прогрессии, теперь на одну тему можно найти более сотни тысяч подобных сайтов с миллионом статей.
Поэтому пришлось усложнить системы ранжирования и стали учитывать следующие дополнительные параметры:
- количество ссылающихся материалов;
- уникальность контента;
- поведение клиента на странице.
Matrixnet
В 2009 году Яндекс столкнулся с проблемой, что статьи все чаще не отвечают на вопросы пользователей. Чтобы исправить эту ошибку, нужно было научить сервер самостоятельно принимать решения и учиться.
Придумана сложная математическая формула с множеством параметров для определения соответствия текста поисковой фразе.
Но остались следующие проблемы:
- поиск зависит от слов;
- вспомогательные материалы (фото, видео, цитаты и т.д.) не учитываются.
Основная проблема заключалась в том, что не всегда можно было полностью описать смысл статьи в одном заголовке. Довольно часто статья не содержит конкретных ключевых слов, но при этом полностью раскрывает тему и дает развернутый ответ на вопрос пользователя.
Алгоритм Палеха
В 2016 году в системе ранжирования применялась компьютерная модель нейронных сетей. Главная особенность такого подхода в том, что теперь компьютер способен помнить свои ошибки и учиться на собственном опыте.
В том же году были введены семантические векторы. Заголовок статьи был пропущен через нейросеть и разложен на множество векторов. Теперь компьютеры сравнивали не поисковые слова, а многомерные массивы чисел и векторов. Удалось уйти от прямой зависимости от количества определенных слов во фразе и отдать приоритет смысловому наполнению.
Из недостатков осталась проблема низкой скорости. Для формирования результатов поиска сравнивались только 200 наиболее релевантных статей. Поэтому системе было сложно найти многословные смысловые словосочетания типа «фильм о девочке-шпионке, которая убегает и идет в школу».
Алгоритм Яндекс Королев
В последнем новшестве, прежде всего, мы оптимизировали нейросеть и повысили производительность обработки текста. Теперь векторы сравниваются заранее в автономном режиме, благодаря этому удалось повысить эффективность поискового построения.
Теперь векторы сравниваются заранее в автономном режиме, благодаря этому удалось повысить эффективность поискового построения.
Яндекс самостоятельно собирает статистику по интересам пользователей и формирует на их основе заранее подготовленные результаты поиска.
Благодаря оптимизации семантический вектор составляется не только для заголовков, но и для всего содержания столбцов. Можно найти максимум смысловых связей между словами.
Угрозы сайтам
В целом никаких опасностей для сайтов не создавалось, и статистика переходов сильно не меняется. В первую очередь новшества касаются информационных блогов, форумов и сайтов с фильмами.
Сайты, не отвечающие интересам пользователя, могут слетать с лидирующих позиций. Например, название «яблочный сок домашний», а в статье обсуждаются способы выращивания деревьев, блины с вареньем и совсем другой текст.
Не забудьте сделать репост и подписаться на рассылку новостей блога. Всего наилучшего.
Всего доброго, Галиуин Руслан.
Что он анализирует не только заголовок страницы, но и все содержимое страницы перед показом пользователю результатов запроса.
Прошла всего неделя, выводы делать рано, но, тем не менее, мы поинтересовались у представителей сео-сообщества об их ожиданиях от нового алгоритма и изменениях в работе сео-мастеров.
Кирилл Николаев, технический директор студии ВЭБЛАБ:
Сразу после выхода Палеха был ясен дальнейший вектор развития нового алгоритма. Незадолго до анонса шли жаркие споры о том, что же будет (самый популярный вариант: первая страница только прямая), но в глубине души мы все понимали, чего ожидать. Яндекс увеличил цифры, и это хорошая новость. Если раньше в оперативной памяти было 150 документов по популярным запросам, то сейчас их количество перевалило за 200 000, чему очень старательно помогают спецагенты из Толоки. Чтобы оказаться в топе этих 200 000, нужно иметь хорошую поведенческую (что логично) и подобную семантику, которая заставляет думать, что времена воровства контента возвращаются с новой силой. И времена длинных листов в каталогах интернет-магазинов тоже говорят нам «Привет, Андрей!»
И времена длинных листов в каталогах интернет-магазинов тоже говорят нам «Привет, Андрей!»
Однако, насколько мне известно, матрица по популярным запросам хранится в базе на время очередного обновления, а матрица по низким/низкочастотным запросам формируется на лету.
Ждать таких колоссальных изменений в результатах поиска, как после запуска Снежинска в 2009 году, не стоит, поэтому оставим в покое запросы ВЧ/СЧ и поговорим о более приземленных вещах.
Лично меня больше всего заинтересовало это утверждение:
«…новый алгоритм не только сравнивает текст веб-страницы с поисковым запросом, но и обращает внимание на другие запросы, по которым люди приходят на эту страницу. » Для отрасли это может означать две вещи:
1. Хорошо: еще более тщательный отбор семантики, еще более усердная кластеризация дадут свои плоды. Текстовые факторы выходят на первый план по важности и актуальности, работать становится сложнее, но и результат становится лучше.
2. Плохо: максимальный объем текста для индексации одного документа 32 тыс. знаков. Так что могу ожидать, что сейчас под описанием каталога в каком-нибудь магазине можно будет прочитать небольшие рассказы о доставке воды, в которых есть сюжет, развитие, кульминация, развязка и эпилог. Это логично, потому что это самый простой способ расширить семантику. Я, конечно, утрирую, ведь понятно, что ТОР формируется немного по-другому, но я сильно подозреваю, что именно так это воспримут наши «короли контента».
Плохо: максимальный объем текста для индексации одного документа 32 тыс. знаков. Так что могу ожидать, что сейчас под описанием каталога в каком-нибудь магазине можно будет прочитать небольшие рассказы о доставке воды, в которых есть сюжет, развитие, кульминация, развязка и эпилог. Это логично, потому что это самый простой способ расширить семантику. Я, конечно, утрирую, ведь понятно, что ТОР формируется немного по-другому, но я сильно подозреваю, что именно так это воспримут наши «короли контента».
Ну и в дополнение просто подкину мысль: а если не переписывать тексты и не тратить время на сложные вещи, а попробовать грамотно накрутить трафик на LF/MLF запросы? Интересное поле для экспериментов.
Яндекс развивается и мы растем вместе с ним.
Это здорово. Очень хочется представить, что будет через 5-10-15 лет.
Хочешь быть хорошим сеошником — учи матчасть.
Все в порядке. Жду новых курсов от БМ на тему «Семантические векторы для бизнеса». А если серьезно, профессия становится все сложнее, что не может не радовать. Я надеюсь, что очень скоро исчезнут лица, которые делают справочные прогоны по базам данных, составленным по «последним исследованиям Дмитрия Шахова (известного SEO-специалиста)».
Я надеюсь, что очень скоро исчезнут лица, которые делают справочные прогоны по базам данных, составленным по «последним исследованиям Дмитрия Шахова (известного SEO-специалиста)».
Еще большее погружение в текстовые факторы
Больше курсов от БМ, жду только запуска нейросетевого выбора семантики и кластеризации от Чекушина. И курс от Деваки, конечно.
Алаев Александр, директор веб-студии «Алаич и Ко»:
Яндекс выкатил новый алгоритм с большим шумом и ажиотажем. Я думал, что моя жизнь как оптимизатора изменится навсегда, но… Спешу всех успокоить — ничего не изменилось!
Новый алгоритм Яндекса направлен на улучшение результатов поиска по «длинным» информационным запросам (такие запросы характерны для голосового поиска). Яндекс со своей нейросетью стал понимать и искать по смыслу, то есть не только по ключевым словам, но и по тому, что они означают. Продолжение «Палеха», который искал смыслы только по заголовкам документов, «Королев» ищет смыслы по всему документу. Но вы уже это знаете, если смотрели презентацию или читали публикации по ней.
Но вы уже это знаете, если смотрели презентацию или читали публикации по ней.
Давайте поговорим о том, как это повлияет на жизнь веб-мастеров и оптимизаторов. Повторяю — никак. Новый алгоритм никак не повлияет на коммерческие запросы. Если человек хочет что-то купить или заказать, то он наверняка знает, что это такое. А даже если и не знает, то все равно, имея в виду ноутбук, не будет спрашивать «компактный настольный компьютер, состоящий из двух половинок», а сначала узнает, как эта штука называется.
Королев должен позитивно реагировать на качественные информационные страницы. А вот сгенерированные, синонимизированные и похожие тексты должны проигрывать в трафике, если он вообще был. Я думаю, что рерайт и копирайт, написанные без погружения в тему, тоже могут пострадать, уступив место более качественным текстам, пусть и без использования правильных ключевых слов в нужных количествах.
Как видите, ничего нового я не сказал, а сайты, как и раньше, надо делать качественно и для людей!
Александр Ожигбесов, руководитель проекта ozhgibesov. net :
net :
Внедряя в поиск Яндекса новые алгоритмы, Яндекс делает небольшие, но уверенные шаги к пониманию смысла запроса и поиску такого же осмысленного ответа — вот как Палех и Королёв представлены нам в компании. По сути, это копия алгоритма Google Hummingbird, который был запущен в 13 году, однако стоит реально оценить имеющиеся у компании мощности. Яндекс не может завтра дать ответы на все уникальные запросы и перестроить выдачу. Ошибка в компании в том, что представили алгоритм как что-то новое, хотя Google сделал это раньше и без такого «русского» пафоса, но это безусловно сильное достижение и я уверен, что в будущем нейросети смогут показать нам идеальный поиск, если к тому времени отечественный поисковик не сделает платной всю первую страницу выдачи. Но это тоже не особо страшно, давайте перераспределим приоритеты и масштабируем семантику под контекст.
Какие изменения ждут оптимизаторов и будут ли они вообще?
Особых изменений после Палеха и Королева в данный момент нет в популярном интернет-магазине. Пока Яндекс тестирует свои алгоритмы на ТНК, не стоит ожидать кардинальных изменений в регламентах и методах компаний. Здесь сеошникам не о чем беспокоиться, длинные и уникальные запросы присутствуют только в инфо-темах и сложных коммерческих сервисах. Но задача Палеха и Королёва не в том, чтобы подменить текущие параметры ранжирования, они пытаются дать осмысленные ответы на сложные запросы, поэтому необязательно выбирать запросы типа «Красное платье, сквозь которое видны трусики». Лично мое мнение, что топлю и буду топить за качественное написание и структурирование контента, последующую аналитику и дополнительную оптимизацию, чтобы алгоритм не нанес ущерб серьезным коммерческим проектам, как это было, например, с Минусинском.
Пока Яндекс тестирует свои алгоритмы на ТНК, не стоит ожидать кардинальных изменений в регламентах и методах компаний. Здесь сеошникам не о чем беспокоиться, длинные и уникальные запросы присутствуют только в инфо-темах и сложных коммерческих сервисах. Но задача Палеха и Королёва не в том, чтобы подменить текущие параметры ранжирования, они пытаются дать осмысленные ответы на сложные запросы, поэтому необязательно выбирать запросы типа «Красное платье, сквозь которое видны трусики». Лично мое мнение, что топлю и буду топить за качественное написание и структурирование контента, последующую аналитику и дополнительную оптимизацию, чтобы алгоритм не нанес ущерб серьезным коммерческим проектам, как это было, например, с Минусинском.
После презентации нового алгоритма Яндекса Королева 22 августа у многих SEO-специалистов возникли опасения по поводу возможного падения посещаемости сайта. С другой стороны, если поисковый трафик на одних сайтах упадет, то на других вырастет.
Но давайте вместе разберемся, так ли все страшно.
Кстати говоря, исходя из данных Яндекс Метрики, мы видим, что многие пользователи вводят запрос «Как включить Яндекс Королев?» и перейти к нашей статье. На самом деле нечего включать , это новая система ранжирования уже работает у всех автоматически.
Что такое алгоритм Яндекса Королева?
По сути «Королев» — это прокачанная версия Палеха , работа которого основана на распознавании смысла с помощью нейросети. Если Палех умел распознавать только заголовки и обрабатывал до 150 документов, то Королев оценивает весь текст на странице и может обрабатывать более 200 тысяч страниц.
В официальном блоге также говорится, что изменения касаются не только приложения нейросети для поиска не по словам, а по смыслу, но и по самой архитектуре индекса SERP.
Как работает алгоритм Королева
По словам создателей алгоритма, он позволит перейти на совершенно другой уровень понимания смысла запросов пользователей. Теперь вся страница сайта будет оцениваться семантическими векторами поисковых запросов.
Когда пользователь вводит запрос, поисковая система должна понять, какая страница и с каким заголовком ему больше всего соответствует. Для этого запрос и заголовок преобразуются в произведение векторов, и чем больше результат, тем релевантнее страница запросу. В момент формирования ответа на запрос текст заголовков и запросов моментально конвертируется в векторы и сравнивается. Это позволяет выявить возможные связи по смыслу, но требует огромных вычислительных мощностей. Так работает Палех.
Что сделано для повышения производительности? Алгоритм «Королев» выполняет предварительный расчет векторов , что позволяет не нагружать сервер во время самого запроса, а взять уже готовый результат. Кроме того, как было сказано выше, «Королев» преобразует в смысловой вектор не только заголовок страницы, но и все ее содержимое.
Но вы должны понимать, что Королев не является революционным алгоритмом ранжирования сайтов, который перевернет результаты поиска Яндекса с ног на голову. Это комплекс уже реализованных решений, улучшенных с помощью нейросетей и пользовательского опыта.
Это комплекс уже реализованных решений, улучшенных с помощью нейросетей и пользовательского опыта.
Что ждет промышленность после выхода «Королева»?
На данный момент глобальных изменений в результатах выдачи нет, и вряд ли они наметятся в ближайшее время. Например, в поиске еще много страниц, отвечающих на синонимичные запросы «интерьер кухни» и «дизайн кухни», используя разные страницы, где есть прямое вхождение ключа.
Настоящие изменения наступят, когда не нужно будет собирать базу данных для одного «большого» запроса низкочастотные запросы , под ними писать текст от 10000 символов.
Яндекс презентовал новый поисковик
Думаю, вы помните наши статьи об одном из недавних алгоритмов — Палехе. Во всяком случае, вы можете освежить знания и.
Для ленивых вкратце скажу, что Палех позволяет Яндексу понять суть запроса без привязки к конкретным ключевым словам. Но это работает только в заголовке запроса ссылки. Если объяснять полностью на пальцах, Палех умеет только понимать смысл заголовков (а не всей страницы) и сопоставлять его с сутью запроса.
22 августа 2017 года Яндекс на презентации в Московском планетарии анонсировал новый поисковый алгоритм «Королевы». Алгоритм назван в честь советского ученого и основоположника советской космонавтики Сергея Павловича Королева. И это логическое продолжение Палеха.
Яндекс со своей стороны сделал все возможное, чтобы мы (пользователи поиска) осознали значимость нововведений и поняли, что этот алгоритм особенный и фундаментальный, из разряда великих шагов для человечества.
Сначала Яндекс создал отдельный сайт — https://yandex.ru/korolev/, чего не было сделано ни для одного предыдущего алгоритма.
Во-вторых, я устроила из объявления настоящее шоу — запустила масштабные рекламные кампании (не знаю, как у вас — Яндекс меня догнал даже в инстаграме дочери, чего я раньше не замечала), во время эфир, ведущие вышли на связь с космонавтами; представил команду, работающую над алгоритмом; награжден ракетными медалями.
Кому интересно — вот запись трансляции, суть там на пару минут, остальное пафосное шоу:
Давайте разбираться, что в этом алгоритме такого особенного.
Обычно заголовок страницы отражает суть документа, поэтому Палех способен понять суть заголовка, но этого недостаточно. Контент на странице также важен. И Яндекс придумал, как это сделать.
Yandex Space Search
Но прежде чем мы начнем объяснять умные вещи простым языком, мы проверим вопрос. Сравните, что было и что было с внедрением Королёва на самом деле. Тестируем на «длиннохвостых запросах», т.к. во всей красе именно там раскрываются алгоритмы Палеха и Королева.
Помните, в статье о Палехе мы гоняли разные запросы и анализировали результаты выдачи? На их примере и посмотрим, что изменилось. Смотрим в режиме инкогнито, чтобы персонализация не мешала.
Возьмем запрос «фильм, в котором доктор подарил девушке конфетку смеха»:
Выдача по этому запросу явно лучше. При этом в описании ни слова о девушке или смехе:
Чудо — скажете вы, нет — Королев.
Следующий запрос: «Кто самое высшее млекопитающее»:
Опять вопрос стал лучше.
Еще один запрос «купить инструмент для проделывания отверстий в мелком бетоне»:
Выдача тоже стала лучше. Если при Палехе среди вариантов было много дырок для кожи, то при Королеве подача стала гораздо четче.
Ну и последний запрос, который уже не сравним с яндексовской версией Палеха, а с гугловской актуальной версией RankBrain — «как называется книга о вымирающих видах животных и растений»
Яндекс на счет в-ва ответ выглядит представительнее, но гугл в первом же фрагменте дает правильный ответ. И если раньше Палех явно проигрывал Rank Brain’у, то Яндекс в версии Королёва если и лагает, то ненамного.
Мы понимаем, что изменилось технически.
Алгоритм Королёва простыми словами
Алгоритм Палеха смог сопоставить смысл запроса и заголовок страницы. Королев также умеет анализировать всю страницу, а не только запрос.
Например, Королев легко находит ответ на вопрос «картинка, где на дереве висят часы», хотя прямого употребления этих слов в описании на странице нет:
Из-за чего это происходит?
Королев, в отличие от Палеха, научился делать две принципиально важные вещи.
Первый — стал определять сущность страницы в момент индексации. Те. уже в момент обхода роботом Яндекс понимает смысл содержимого проиндексированной страницы и хранит эти данные в себе. Палех определил значение заголовка на момент запроса. Если с шапкой еще можно было, то с полной страницей проблематично — это займет больше времени, и пользователь не будет ждать поиска, гугл сразу гугл.
Второй — учитывает смысл других запросов, которым релевантна страница. Я объясню это.
Любая страница может быть релевантна нескольким запросам. Например, картинку «Постоянство памяти» можно искать по различным запросам: «картина, где часы висят на дереве», «известная картина Сальвадора Дали», «картина про мягкие часы» и так далее. И если мы знаем лучший ответ на запрос «картинка про мягкие часы», то логично предположить, что эти же ответы будут лучшими и на остальные эти запросы.
Что это означает для владельцев веб-сайтов и индустрии SEO в целом?
Да в общем ничего. Эпоха семантического SEO движется семимильными шагами.
Эпоха семантического SEO движется семимильными шагами.
Все новейшие алгоритмы, что в Палехе, что в Баден-Бадене, что в Королеве говорят только об одном — делают сайты для людей. Только технической оптимизации сейчас недостаточно — сегодня поисковые системы всего мира делают все, чтобы на первых местах были действительно лучшие сайты в своей тематике.
Забудьте о показателях тошноты и спама на странице, о ТЗ с конкретным вводом ключевых слов и оптимизации под роботов.
При традиционной оптимизации текста перейти на LSI-копирайтинг. Лучше понять смысл страниц Яндекса поможет семантическая разметка. А если вы не знаете, что делать — обращайтесь к нам — мы правильно раскрутим ваш сайт.
К сожалению, зачастую наличие такого сайта влетает в копеечку, и вместо развития своего сайта и бизнеса предпочитают вкладывать деньги в покупку ссылок, накрутку поведенческих и других незаконных, но менее затратных способов.
«Что?! Редизайн сайта 89000 рублей?! Да, я куплю ссылки на Сапу за эти деньги», — буквально вчера услышал от одного из наших клиентов. Обидно. Но кто был прав — покажет время.
Обидно. Но кто был прав — покажет время.
Космос вам ТОП поисковика! новая версия поиска.Основана на алгоритме поиска «Королев» — с помощью нейросети сравнивает смысл запроса и веб-страницы.Благодаря этому поиск понимает, что действительно нужно пользователю, и отвечает сложные вопросы еще точнее.В новой версии поиска используется более широко поисковая статистика и учитываются оценки пользователей Яндекс.Толоки.
Первый шаг к поиску по смыслу Яндекс сделал еще в прошлом году, когда реализовал алгоритм «Палех» — он в режиме реального времени сопоставляет смысл запроса и заголовок веб-страницы. «Королев» использует нейросеть, которая анализирует не только заголовок, но и всю страницу в целом. Это сложная вычислительная задача, поэтому Яндекс определяет суть страницы заранее, на этапе индексации. Благодаря этому количество страниц, которые поиск сопоставляет по смыслу с запросом, выросло со 150 документов до 200 тысяч. Еще одной важной особенностью «Королева» является то, что, помимо сопоставления смысла запроса и страницы, он также учитывает смысл других запросов, по которым на него переходят люди.
Чтобы нейронная сеть оценила семантическую близость запроса и документа, ей нужно огромное количество примеров. Такие примеры дают обезличенную статистику поиска: на какие сайты люди переходят по запросам и сколько времени там проводят. Итак, если человек зашел на страницу и некоторое время смотрел на нее, скорее всего, она близка по смыслу запросу. Используя поисковую статистику миллионов людей, Яндекс учится понимать смысловые связи. Например, он поймет, что в запросе [картинка, где крутится небо] речь идет о картине Ван Гога, а в запросе [ленивый кот из Монголии] — о мануле.
«Поиск — очень сложная система. Тысячи инженеров работают над тем, чтобы она понимала человека и помогала решать его проблемы. В «Королеве» мы объединили машинный интеллект и усилия миллионов людей. Наши пользователи совершенствуют ищите вместе с нами, задавая вопросы и помогая обучать наши алгоритмы», — говорит Андрей Стыскин, руководитель Поиска Яндекса.
Чтобы изучить поисковик, нужно также оценить качество ответов. И чем сложнее система, тем больше требуется оценок. Раньше Яндекс оценивал качество поиска с помощью своих экспертов — асессоров. Теперь оценки учитываются и пользователями Яндекс.Толок. Это сервис, где каждый может выполнять задания и получать за это вознаграждение. Сейчас в Яндекс.Толок зарегистрировано более миллиона пользователей, которые уже выставили более двух миллиардов оценок.
И чем сложнее система, тем больше требуется оценок. Раньше Яндекс оценивал качество поиска с помощью своих экспертов — асессоров. Теперь оценки учитываются и пользователями Яндекс.Толок. Это сервис, где каждый может выполнять задания и получать за это вознаграждение. Сейчас в Яндекс.Толок зарегистрировано более миллиона пользователей, которые уже выставили более двух миллиардов оценок.
Нейросеть анализирует не только заголовок, но и всю страницу целиком, при этом поисковик определяет ее суть еще на этапе индексации
МОСКВА, 22 августа. /ТАСС/. «Яндекс» запустил новую версию поиска, которая основана на сравнении смысла запроса и веб-страницы, говорится в сообщении компании. Новая версия работает на алгоритме Королева, который использует нейронную сеть для определения того, чего хочет пользователь. Нейросеть анализирует не только заголовок, но и всю страницу целиком, тогда как «Яндекс» определяет суть страницы заранее, на этапе индексации.
Еще одна особенность «Королевы» в том, что она учитывает также смысл других запросов, по которым к ней переходят люди. «Чтобы нейросеть оценила семантическую близость запроса и документа, ей нужно огромное количество примеров. Такие примеры дают обезличенную статистику поиска: на какие сайты люди переходят по запросам и сколько времени они там проводят. Итак, если человек зашел на страницу и некоторое время смотрел на нее, скорее всего, она близка по смыслу запроса.Используя поисковую статистику миллионов людей, «Яндекс» учится понимать смысловые связи.Например, он поймут, что в запросе «картинка, где небо крутится» речь идет о картине Ван Гога, а в запросе «ленивый кот из Монголии» — о мануле», — говорится в сообщении компании.
«Чтобы нейросеть оценила семантическую близость запроса и документа, ей нужно огромное количество примеров. Такие примеры дают обезличенную статистику поиска: на какие сайты люди переходят по запросам и сколько времени они там проводят. Итак, если человек зашел на страницу и некоторое время смотрел на нее, скорее всего, она близка по смыслу запроса.Используя поисковую статистику миллионов людей, «Яндекс» учится понимать смысловые связи.Например, он поймут, что в запросе «картинка, где небо крутится» речь идет о картине Ван Гога, а в запросе «ленивый кот из Монголии» — о мануле», — говорится в сообщении компании.
В прошлом году Яндекс уже запустил систему, работающую на основе нейросетей — Палех. Прежняя система проиндексировала 150 страниц, в «Королеве» количество страниц, которые поиск сопоставляет по смыслу с запросом, выросло до 200 тысяч.
Новый алгоритм назван в честь основоположника отечественной космонавтики Сергея Королева.
«А сегодня мы запускаем новый алгоритм ранжирования» Королев.
 «Почему мы выбрали такое название? Сергей Павлович Королев осуществил мечту человечества о полетах в космос. Для нас в «Яндексе» сегодняшний запуск так же важен, как важный технологический прорыв к мечте о поиске, который понимают пользователи», — сказал Александр Сафронов, руководитель службы лингвистической релевантности Яндекса, на презентации новой версии поиска.
«Почему мы выбрали такое название? Сергей Павлович Королев осуществил мечту человечества о полетах в космос. Для нас в «Яндексе» сегодняшний запуск так же важен, как важный технологический прорыв к мечте о поиске, который понимают пользователи», — сказал Александр Сафронов, руководитель службы лингвистической релевантности Яндекса, на презентации новой версии поиска.Hall Assistance
Для изучения поисковой системы необходимы оценки качества ответов. Ранее «Яндекс» оценивал качество поиска с помощью своих оценщиков. Новый поиск будет учитывать оценки, которые будут выставлять пользователи сервиса «Яндекс.Толок» — распределенной сети оценщиков. Сервис позволяет любому выполнять задания и получать за них вознаграждение, на данный момент в нем зарегистрировано более миллиона пользователей. Любой желающий может зарегистрироваться на платформе.
Яндекс — крупнейшая поисковая система в России. Доля компании на российском рынке поиска (включая поиск на мобильных устройствах) во втором квартале 2017 года в среднем составила 54,3%, в первом квартале этого года — 54,7% (по данным аналитической службы «Яндекс.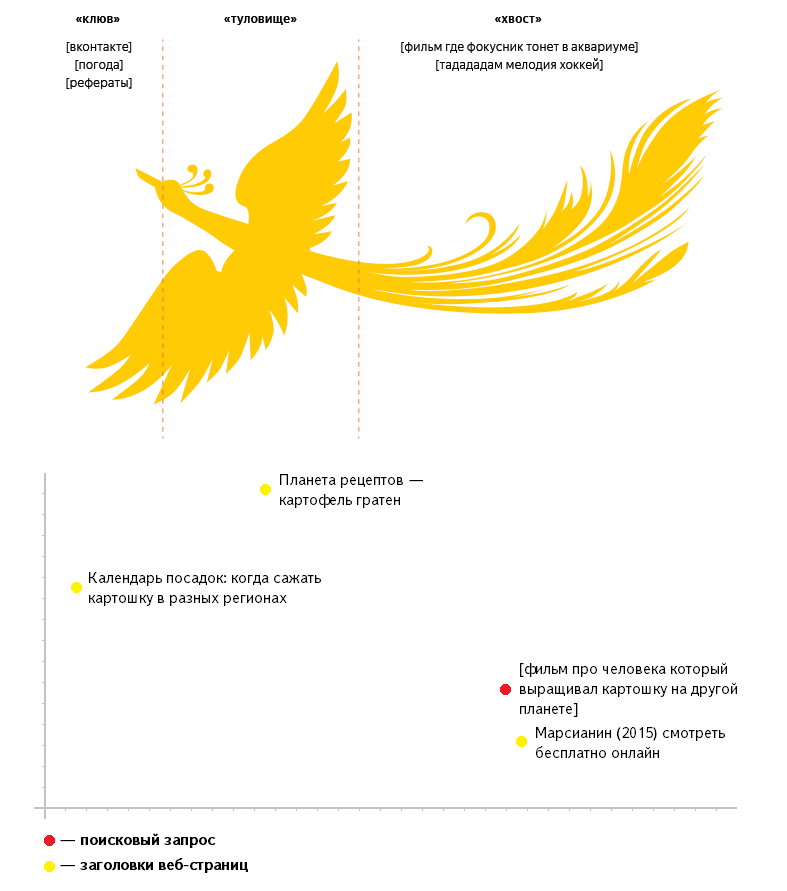 Радар»). По данным Liveinternet.ru, в июне этого года доля поиска Яндекса составляла 51,3%.
Радар»). По данным Liveinternet.ru, в июне этого года доля поиска Яндекса составляла 51,3%.
В этой статье мы поговорим о том, как быстро добавить свой сайт в Яндекс и Гугл, чтобы поисковые системы заходили на ваш сайт, индексировали его и страницы сайта появлялись в результатах поиска.
3 способа добавить новый сайт в яндекс
Рассмотрим 3 самых простых способа.
Сообщить о новом сайте
Чтобы перейти на эту страницу, вам необходимо войти под своим логином и паролем от Яндекса или зарегистрировать новый аккаунт. Введите адрес сайта в поле «URL», затем капчу и нажмите кнопку «Добавить».
Добавление сайта в Яндекс.Вебмастер
Для доступа к сервису необходимо зарегистрироваться или использовать свой логин и пароль от Яндекса. Вебмастер позволяет отслеживать индексацию сайта, отслеживать ошибки, добавлять карту сайта и многое другое. Рекомендую зарегистрировать свой сайт в этом сервисе.
Чтобы добавить новый сайт, нажмите «Начать работу», затем «Добавить сайт», введите адрес сайта в специальное поле и нажмите кнопку «Добавить».
На следующей странице вам необходимо подтвердить право собственности на домен. Для этого предлагаются следующие способы:
- Загрузить HTML-файл в корень сайта
- Разместите метатег в шапке сайта
- Загрузить TXT файл в корень сайта (временно не работает)
- Через домен WHOIS
- Через DNS-домен
Рекомендую использовать проверку через загрузку HTML-файла. Скачайте файл и залейте его через файловый менеджер хостинга или FTP в корень сайта. После этого нажмите кнопку «Проверить». Через несколько секунд проверки вы получите сообщение «Сайт успешно поставлен в очередь на индексацию».
Для доступа к странице необходимо зарегистрироваться в Google или ввести свой логин и пароль. Введите адрес сайта в поле «URL»; подтверждаем, что мы не робот и нажимаем кнопку «Отправить запрос». Если все сделано правильно, видим сообщение «Ваша заявка получена и скоро будет обработана».
Этого достаточно, чтобы сообщить Google о вашем новом сайте.