
Яндекс улучшает индексацию AJAX-сайтов — Новости
Оксана Мамчуева
598
Команда поиска Яндекса сообщила об улучшении индексации AJAX-сайтов, использующих URL с #. Теперь вебмастер AJAX-сайта сможет указать поисковому роботу Яндекса на необходимость индексации, поддержав соответствующую схему в структуре сайта. Для этого нужно:
1. Заменить в URL страниц символ # на #!. Так робот будет понимать, что он может обратиться за HTML-версией контента этой страницы.
2. HTML-версия контента этой страницы размещается на URL, где #! заменен на ?_escaped_fragment_=.
Пример:
URL: http://www.examplesite.ru/#blog
Заменили на: http://www.examplesite.ru/#!blog
Положили HTML-контент на URL: http://www.
3. При этом контент главной страницы должен быть доступен по адресу http://www.examplesite.ru/?_escaped_fragment_=
4. Чтобы робот понимал, что главная страница также на AJAX, нужно разместить мета-тег. Мета-тег может использоваться на любой странице, сгенерированной с помощью AJAX.
Так робот Яндекса сможет проиндексировать AJAX-сайт, главное, чтобы его структура подчинялась определенным правилам.
Оптимизаторы и вебмастера встретили эту новость с энтузиазмом:
Елена Камская (SeoLib): «Это отличная новость для всех web-разработчиков, мы давно этого ждали. В прошлом не раз приходилось отговаривать клиентов от AJAX или использовать его минимально, чтоб не мешать индексации. Надеюсь, что теперь таких проблем не будет».
Олег Сахно (ИнтерЛабс): «AJAX-интерфейс сайта всегда был камнем преткновения между заказчиками и оптимизаторами. Заказчика можно понять: современные технологии, сайт более интерактивен, не надо заставлять пользователя ждать загрузки новой страницы. Но для оптимизаторов подгружаемый контент был большой проблемой. Приходилось искать компромиссы и содержимое некоторых документов дублировать на страницах с постоянным URL. При должной скорости индексации и отсутствии проблем со стороны индексирующего робота, возможность передавать параметры ajax-скрипта позволит, например, сделать поиск по каталогу товаров более удобным для пользователя».
Но для оптимизаторов подгружаемый контент был большой проблемой. Приходилось искать компромиссы и содержимое некоторых документов дублировать на страницах с постоянным URL. При должной скорости индексации и отсутствии проблем со стороны индексирующего робота, возможность передавать параметры ajax-скрипта позволит, например, сделать поиск по каталогу товаров более удобным для пользователя».
- Новости
- Интернет и медиа
Бывший директор Yahoo обвинен в промышленном шпионаже
Бывший сотрудник Yahoo и управляющая инвестиционным фондом обвиняются в промышленном шпионаже, продаже секретной информации и мошенничестве
Социальный поисковик Ark.com открыл публичную регистрацию
Как сообщает издание TechCrunch, начиная с 21 мая 2012 года, новый социальный поисковик Ark.com открыл публичную регистрацию для всех пользователей
Мэтт Каттс: «Одна некачественная ссылка не может повлиять на позиции сайта»
21 мая 2012 года Google опубликовал очередной обучающий видео-ролик, в рамках которого руководитель команды по борьбе с веб-спамом и главный инженер поисковой корпорации Мэтт. ..
..
Yahoo продает половину акций Alibaba
Yahoo Inc продаст половину акций китайской компании Alibaba Group предпринимателю Джеку Ма (Jack Ma) за $7.1 миллиарда…
В бирже статей Articles.Sape поддерживается атрибут rel=”canonical”
Биржа Sape сообщила о небольшом нововведении технического характера — теперь в Articles.Sape поддерживается атрибут rel=”canonical”
Bing объявил цены на использование поискового API
Как сообщает издание SearchEngineLand со ссылкой на официальный блог Bing, начиная с 17 мая 2012 года поисковик от Microsoft приступил к официальному внедрению платного…
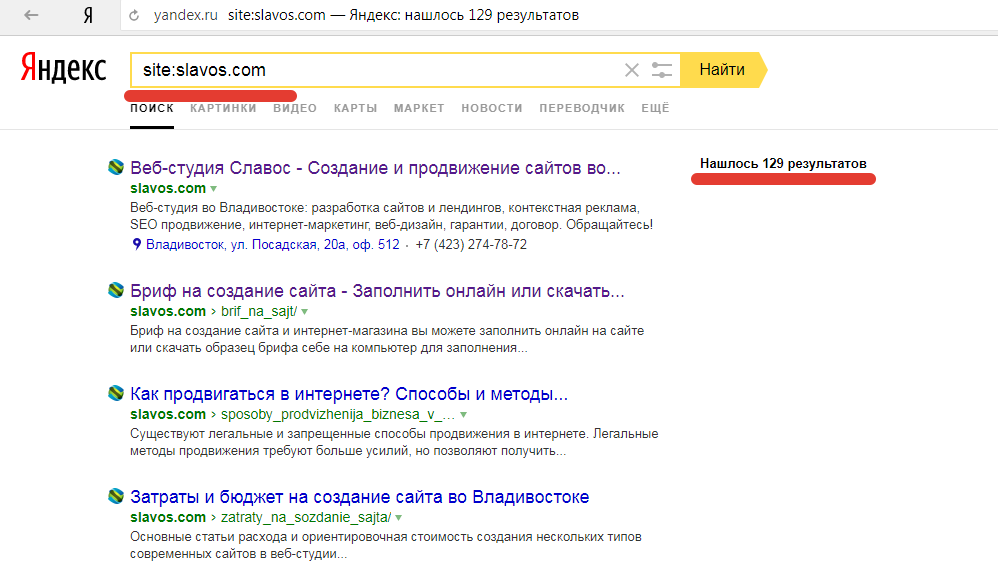
javascript — Индексация AJAX сайтов
Вопрос задан
Изменён 7 лет 2 месяца назад
Просмотрен 2k раз
Я уже читал о индексации AJAX сайтов на Yandex Help и GoogleSupport, но у меня структура уже не позволяет делать глобальные изменения.
Если я сделаю определение USER_AGENT на GoogleBot или YandexBot(названия могут быть не точными), в PHP скриптах, и подменю полностью сайт на HTML версию, будут ли мои ссылки индексироваться и появляться в поисковике?
- ajax
- javascript
- яндекс
- php
3
Чтобы обеспечить индексацию SPA (Sinlge Page Apps), лучше всего использовать изоморфные решения. Это такие фреймворки/библиотеки, которые умеют строить страницы как на клиенте, так и на сервере. Лучший вариант сейчас — это React.js + Flux, и хорошей альтернативой в будущем будет Angular2.
Поставили как то задачу чтобы музыка беспрерывно на сайте звучала. Также с помощью AJAX’а были созданы переходы по сайту. Для индексации поисковыми ботами создали дублирующий контроллер который выдавал страницы в зависимости от GET данных.
Создали sitemap для индексации поисковыми ботами.
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
Как JavaScript и AJAX влияют на индексацию в Google?
Автор: Ramón Saquete
Содержание
- 1 Проблемы CSR при начальной загрузке страницы
- 1.
 1 Проблемы в результате медленного рендеринга
1 Проблемы в результате медленного рендеринга - 1.2 Проблемы с индексацией: 9007
3 90 переход на следующую страницу - 1.
- 2.1 Проблемы с индексированием
- 2.2 Что происходит с фрагментами теперь, когда Google может индексировать AJAX?
- 3 Блокировка индексации частичных ответов через AJAX
- 4 Заключение
 1 Проблемы в результате медленного рендеринга
1 Проблемы в результате медленного рендерингаСо временем Google значительно улучшил индексацию JavaScript и AJAX . Вначале он ничего не индексировал и не переходил ни по каким ссылкам, появляющимся в контенте, загруженном через эти фреймворки. Но затем мало-помалу он начал индексировать некоторые реализации и улучшать свои возможности. В настоящее время он может индексировать множество различных реализаций и переходить по ссылкам, загруженным через AJAX или API Fetch . Тем не менее, все равно будут случаи, когда это может не сделать .
Чтобы проанализировать случаи, когда Google может не индексировать наш сайт, сначала нам нужно понять концепцию рендеринга на стороне клиента (CSR). Это означает, что HTML-код нарисован на стороне клиента с помощью JavaScript , обычно с использованием AJAX в избытке. Первоначально веб-сайты всегда рисовали HTML на стороне сервера ( Server Side Rendering или SSR), но с некоторых пор стал популярным CSR с появлением фреймворков JavaScript, таких как Angular, React и Vue . Однако CSR негативно влияет на индексацию , производительность рендеринга веб-сайтов и, следовательно, на SEO .
Это означает, что HTML-код нарисован на стороне клиента с помощью JavaScript , обычно с использованием AJAX в избытке. Первоначально веб-сайты всегда рисовали HTML на стороне сервера ( Server Side Rendering или SSR), но с некоторых пор стал популярным CSR с появлением фреймворков JavaScript, таких как Angular, React и Vue . Однако CSR негативно влияет на индексацию , производительность рендеринга веб-сайтов и, следовательно, на SEO .
Как мы уже объясняли ранее, для обеспечения индексации во всех поисковых системах и ситуациях , помимо достижения хорошей производительности, лучшим решением является использование универсального фреймворка , так как с этими мерами мы получаем что-то под названием Гибридный рендеринг . Он состоит в том, что прорисовывает веб-сайт на сервере при первой загрузке, а затем на клиенте через JavaScript и AJAX, когда навигация переходит к ссылкам, следующим за . Хотя на самом деле существует больше ситуаций, когда использование термина «гибридный рендеринг» также допустимо.
Хотя на самом деле существует больше ситуаций, когда использование термина «гибридный рендеринг» также допустимо.
Иногда компания-разработчик использует CSR и не предлагает нам вариант использования универсального фреймворка. Эта веб-разработка на основе CSR создаст нам проблемы , в большей или меньшей степени в зависимости от сканера и его алгоритмов ранжирования . В этом посте мы собираемся проанализировать, что это за проблемы с поисковым роботом Google и как их решить .
Проблемы с CSR при первоначальной загрузке страницы
Во-первых, мы собираемся проанализировать проблемы с индексированием, возникающие , как только мы вводим URL-адрес за пределами веб-сайта , и когда HTML отображается на стороне клиента с помощью JavaScript.
Проблемы из-за медленного рендеринга
Процесс индексации Google проходит следующие этапы:
- Сканирование : Googlebot запрашивает URL-адрес сервера.
- Первая волна индексации : она мгновенно индексирует содержимое, созданное на сервере, и получает новые ссылки для сканирования.
- Генерирует нарисованный HTML на стороне клиента, запуская JavaScript . Этот процесс требует значительных вычислительных ресурсов (это можно сделать сразу или даже занять несколько дней, ожидая получения необходимых для этого ресурсов).
- Вторая волна индексации : с раскрашенным HTML на стороне клиента оставшееся содержимое индексируется и получаются новые ссылки для сканирования.

Помимо того факта, что для полного индексирования страниц может потребоваться больше времени, что приведет к задержке индексации последующих страниц, связанных с ними, если рендеринг страницы выполняется медленно, модуль визуализации робота Googlebot может оставлять незакрашенные части . Мы проверили это, используя вариант «Просмотреть как Google», предоставленный консолью поиска Google , и созданный им снимок экрана не рисует ничего, что занимает более 5 секунд для отображения. Однако он генерирует HTML, который занимает больше времени, чем эти 5 секунд. Чтобы понять, почему это происходит, мы должны иметь в виду, что средство визуализации Google Search Console сначала создает HTML-код, запускающий JavaScript, с помощью средства визуализации Googlebot, а затем рисует пиксели страницы . Первая задача — та, которую необходимо учитывать для индексации, к которой мы относим термин CSR. В Google Search Console мы видим HTML-код, сгенерированный во время первой волны индексации, а не тот, который был сгенерирован модулем визуализации Googlebot .
Мы проверили это, используя вариант «Просмотреть как Google», предоставленный консолью поиска Google , и созданный им снимок экрана не рисует ничего, что занимает более 5 секунд для отображения. Однако он генерирует HTML, который занимает больше времени, чем эти 5 секунд. Чтобы понять, почему это происходит, мы должны иметь в виду, что средство визуализации Google Search Console сначала создает HTML-код, запускающий JavaScript, с помощью средства визуализации Googlebot, а затем рисует пиксели страницы . Первая задача — та, которую необходимо учитывать для индексации, к которой мы относим термин CSR. В Google Search Console мы видим HTML-код, сгенерированный во время первой волны индексации, а не тот, который был сгенерирован модулем визуализации Googlebot .
В Google Search Console мы не видим HTML-код, нарисованный с помощью JavaScript, запускаемый роботом Googlebot 🕷 и используемый на последнем этапе индексации. Для этого мы должны использовать этот инструмент: https://search.google.com/test/mobile-friendly 😲Нажмите, чтобы твитнуть
Для этого мы должны использовать этот инструмент: https://search.google.com/test/mobile-friendly 😲Нажмите, чтобы твитнуть
В проведенные нами тесты, когда рендеринг HTML занимал более 19секунд ничего не проиндексировал . Хотя это долгое время, в некоторых случаях его можно превзойти, особенно если мы интенсивно используем AJAX, и в этих случаях рендерер Google, как и любой рендерер, действительно должен ждать выполнения следующих шагов:
- HTML загружается и обрабатывается для запроса связанных файлов и создания DOM .
- CSS загружается и обрабатывается, для запроса связанных файлов и создания CSSOM .
- JavaScript загружается, компилируется и запускается для запуска запросов AJAX .
- Запрос AJAX перемещается в очередь запросов и ожидает ответа вместе с другими запрошенными файлами.
- Запущен AJAX-запрос , который должен пройти по сети на сервер.
- Сервер отвечает на запросы через сеть, и, наконец, мы должны дождаться запуска JavaScript, чтобы отрисовать содержимое HTML-шаблона страницы .

Время запроса и загрузки процесса, который мы только что описали, зависит от загрузки сети и сервера в это время . Более того, Googlebot использует только HTTP/1.1 , что медленнее, чем HTTP/2, потому что запросы обрабатываются один за другим, а не все одновременно. Необходимо, чтобы и клиент, и сервер разрешали использование HTTP/2, поэтому Googlebot будет использовать только HTTP/1.1, даже если наш сервер разрешает HTTP/2 . Подводя итог, это означает, что Googlebot ждет завершения каждого запроса, чтобы запустить следующий, и, возможно, он не будет пытаться распараллелить определенные запросы, открывая различные соединения, как это делают браузеры (хотя мы точно не знаем, как это происходит). Имеет ли это). Таким образом, мы находимся в ситуации, когда мы могли бы превысить эти 19 секунд, которые мы оценили ранее .
Имеет ли это). Таким образом, мы находимся в ситуации, когда мы могли бы превысить эти 19 секунд, которые мы оценили ранее .
Представьте, например, что с запросами изображений, CSS, JavaScript и AJAX запускается более 200 запросов, каждый из которых занимает 100 мс. Если запросы AJAX отправляются в конец очереди, мы, вероятно, превысим время, необходимое для индексации их содержимого .
С другой стороны, из-за этих проблем с производительностью CSR, мы получим худшую оценку метрики FCP (First Contentful Paint) в PageSpeed с точки зрения рендеринга и ее WPO, и, как следствие, худший рейтинг .
🕸Чистый подход CSR вредит индексированию и ранжированию, потому что генерация HTML обходится дороже как для робота Google, так и для браузеров 😕Нажмите, чтобы твитнуть
Проблемы с индексированием:
При индексировании контента, окрашенного на стороне клиента, Робот Google может столкнуться со следующими проблемами проблемы, которые препятствуют индексированию HTML-кода, сгенерированного JavaScript :
- Они используют версию JavaScript , которую сканер не распознает.
- Они используют JavaScript API не распознается роботом Googlebot (в настоящее время мы знаем, что веб-сокеты, WebGL, WebVR, IndexedDB и WebSQL не поддерживаются — дополнительная информация доступна на странице https://developers.google.com/search/docs/guides/rendering).
- Файлы JavaScript заблокированы robots.txt .
- Файлы JavaScript обслуживаются через HTTP, в то время как веб-сайт использует HTTPS .
- Есть ошибки JavaScript .
- Если приложение запрашивает разрешение пользователя что-то сделать, и от этого зависит рендеринг основного контента, он не нарисуется, потому что Googlebot по умолчанию отказывает в любом разрешении, которое он запрашивает.
Чтобы узнать, страдаем ли мы от какой-либо из этих проблем, мы должны использовать тест Google для мобильных устройств . Он покажет нам скриншот того, как страница отображается на экране, подобно Google Search Console, но также покажет нам HTML-код , сгенерированный средством визуализации (как упоминалось ранее), регистрирует ошибки в коде JavaScript и функций JavaScript, которые визуализатор еще не может интерпретировать . Мы должны использовать этот инструмент для проверки всех URL-адресов, которые представляют каждый шаблон страницы на нашем веб-сайте, чтобы убедиться, что веб-сайт индексируется.
Мы должны использовать этот инструмент для проверки всех URL-адресов, которые представляют каждый шаблон страницы на нашем веб-сайте, чтобы убедиться, что веб-сайт индексируется.
Мы должны иметь в виду, что в HTML , сгенерированном предыдущим инструментом, все метаданные (включая канонический URL) будут игнорироваться роботом Googlebot, так как он учитывает информацию только тогда, когда она отображается на сервере .
Проблемы CSR с переходом на следующую страницу
Теперь давайте посмотрим, что происходит, когда мы используем ссылку для навигации, когда мы уже находимся на веб-сайте и HTML-код нарисован на стороне клиента.
Проблемы с индексированием
В отличие от CSR во время начальной загрузки, переход на следующую страницу с переключением основного контента через JavaScript выполняется быстрее, чем SSR . Но у нас будут проблемы с индексацией, если:
- Ссылки не имеют действительного URL-адреса, возвращающего 200 OK в своих атрибут href .
- Сервер возвращает ошибку при прямом доступе к URL-адресу без JavaScript или с включенным JavaScript и удалении всех кешей . Будьте осторожны с этим: если мы перейдем на страницу, нажав на ссылку, может показаться, что она работает, потому что она загружается JavaScript. Даже при прямом доступе, если веб-сайт использует Service Worker, веб-сайт может имитировать правильный ответ, загружая свой кэш. Но Googlebot — это поисковый робот без сохранения состояния, поэтому он не принимает во внимание кеш Server Worker или любые другие технологии JavaScript, такие как локальное хранилище или хранилище сеансов, поэтому он получит сообщение об ошибке.

Кроме того, чтобы веб-сайт был доступен, URL-адрес должен измениться с помощью JavaScript с API истории .
Что происходит с фрагментами теперь, когда Google может индексировать AJAX?
Фрагменты — это часть URL-адреса, которая может стоять в конце, перед которой ставится решетка # . Например:
Например:
http://www.humanlevel.com/blog.html#example
Этот тип URL-адресов никогда не достигает сервера , они управляются только на стороне клиента. Это означает, что при запросе вышеуказанного URL-адреса на сервер он получит запрос «http://www.humanlevel.com/blog.html», а в клиенте браузер прокрутит до фрагмента документа, который упоминается. Это обычное и изначально предполагаемое использование для этих URL-адресов , широко известных как привязки HTML . А анкором, на самом деле, является любая ссылка (тег «а» в HTML происходит от анкора ). Однако в прежние времена фрагменты также использовались для изменения URL-адресов через JavaScript на загруженных AJAX страницах , чтобы позволить пользователю перемещаться по истории просмотров. Это было реализовано таким образом, потому что тогда фрагмент был единственной частью URL, которую мы могли изменить с помощью JavaScript, поэтому разработчики воспользовались этим, чтобы использовать их не по назначению. Это изменилось с появлением API-интерфейса истории, поскольку он позволял изменять весь URL-адрес с помощью JavaScript.
Это изменилось с появлением API-интерфейса истории, поскольку он позволял изменять весь URL-адрес с помощью JavaScript.
Раньше, когда Google не мог индексировать AJAX, если URL-адрес изменял свое содержимое через AJAX на основе части фрагмента, мы знали, что он будет индексировать только URL-адрес и содержимое без учета фрагмента. Итак… что происходит со страницами с фрагментами теперь, когда Google может индексировать AJAX? Поведение точно такое же. Если мы свяжем страницу с фрагментом, и она изменит свое содержимое при доступе через фрагмент, то она проиндексирует содержимое, игнорируя фрагмент, и популярность пойдет на этот URL , поскольку Google считает, что фрагмент будет использоваться в качестве привязки, а не для изменения содержимого, как следует.
Однако в настоящее время Google индексирует URL-адреса с хэш-бангом (#!). Это можно реализовать, просто добавив восклицательный знак или bang , и Google заставит это работать, чтобы поддерживать обратную совместимость с устаревшей спецификацией, чтобы сделать AJAX индексируемым. Такая практика, однако, не рекомендуется, так как теперь она должна реализовываться с API истории, к тому же Google может внезапно прекратить индексацию URL-адресов hashbang в любое время .
Такая практика, однако, не рекомендуется, так как теперь она должна реализовываться с API истории, к тому же Google может внезапно прекратить индексацию URL-адресов hashbang в любое время .
Блокировка индексации частичных ответов через AJAX
Когда запрос AJAX отправляется на URL-адресов REST или GraphQL API , нам возвращается JSON или часть страницы, которую мы не хотим индексировать . Поэтому мы должны заблокировать индексацию URL-адресов, на которые направлены эти запросы .
Когда-то мы могли заблокировать их с помощью robots.txt , но с тех пор, как появился рендерер Googlebot, мы не можем заблокировать какой-либо ресурс, используемый для рисования HTML.
В настоящее время Google немного умнее и обычно не пытается индексировать ответы с помощью JSON, но если мы хотим убедиться, что они не будут проиндексированы, универсальное решение, применимое ко всем поисковым системам, заключается в следующем: заставить все URL-адреса, используемые с AJAX, принимать только запросы, сделанные с помощью метода POST , потому что он не используется сканерами.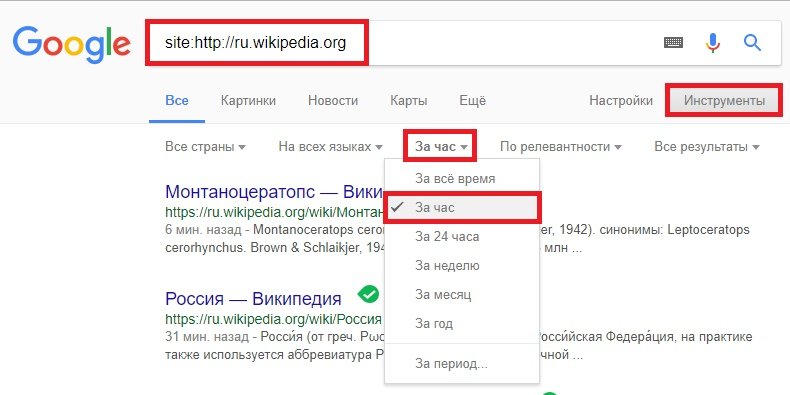 Когда запрос GET достигает сервера, он должен возвращать ошибку 404. С точки зрения программирования это не заставляет нас удалять параметры из QueryString URL.
Когда запрос GET достигает сервера, он должен возвращать ошибку 404. С точки зрения программирования это не заставляет нас удалять параметры из QueryString URL.
Существует также возможность добавить заголовок HTTP «X-Robots-Tag: noindex» (придуманный Google) к ответам AJAX или заставить эти ответы возвращаться с кодом 404 или 410. Если мы используем эти методы для загруженного контента непосредственно из HTML, он не будет проиндексирован, как если бы мы заблокировали его через файл robots.txt. Однако, учитывая, что это JavaScript, рисующий ответ на странице, Google не устанавливает связь между этим ответом и JavaScript, рисующим контент , поэтому он делает именно то, что мы от него ожидаем. А именно: не индексировать частичный ответ и полностью индексировать сгенерированный HTML. Будьте осторожны с этим, потому что это поведение может когда-нибудь измениться, как и весь наш контент, загружаемый через AJAX, если мы применим этот метод.
Заключение
Теперь Google может индексировать JavaScript и AJAX, но это неизбежно влечет за собой более высокие затраты на индексирование уже обработанного HTML на сервере . Это означает, что SSR будет и будет оставаться лучшим вариантом в течение достаточно долгого времени. Если у вас нет другой альтернативы, кроме как полностью или частично разобраться с веб-сайтом CSR, теперь вы знаете, как это сделать.
Это означает, что SSR будет и будет оставаться лучшим вариантом в течение достаточно долгого времени. Если у вас нет другой альтернативы, кроме как полностью или частично разобраться с веб-сайтом CSR, теперь вы знаете, как это сделать.
Рекомендуемый метод индексации контента AJAX в 2018 году: search foresight публикует демонстрацию в Аяксе. Таким образом, использование этой технологии потенциально ставит вас в невыгодное положение с точки зрения эффективного SEO.
Компания Google впервые представила метод, облегчающий обнаружение контента Ajax, еще в 2009 году: это был так называемый метод «хеш-взрыва». Однако это решение было объявлено устаревшим в 2015 году, и в течение нескольких лет Google выступал за использование другого подхода в HTML 5, который использует потенциал метода JavaScript pushState.
Но все это очень техническое, так как же вы поймете, как это работает, и как вы сможете показать разработчику, как хорошо кодировать в Ajax, оставаясь при этом SEO-совместимым?
Демо Search Foresight
Чтобы помочь понять принцип метода, рекомендованного Google, мы опубликовали онлайн-демонстрацию использования подхода, пропагандируемого Google, в двух типичных случаях:
- Загрузка содержимого страницы в Аякс
- бесконечная прокрутка страницы
Посмотреть демонстрацию
Как метод pushState делает страницу доступной для сканирования в Ajax?
Чтобы понять практическое функционирование этого кода, просто нажмите на вкладку « Нант» или «Париж» на демонстрационном сайте:
- содержимое вкладки динамически изменяется после загрузки содержимого Ajax
- URL страницы в панели навигации меняется без перезагрузки страницы
- тегов SEO динамически изменяются (заголовок, мета-описание и т. д.)0010
 д.)0010
д.)0010Почему эти действия позволяют индексировать содержимое, загруженное с помощью Ajax? Потому что Google интерпретирует изменения URL-адреса в браузере, произведенные с помощью метода pushState(), как если бы он читал URL-адрес новой страницы, перезагруженной обычным способом.
Метод был описан Google в этой статье:
Создать виртуальную разбивку на страницы с возможностью сканирования на странице с бесконечной прокруткой
Если вы нажмете ссылку «демонстрация бесконечной прокрутки», вы увидите вторую возможную реализацию этого подход на работе, который создает обходимый пейджинг с помощью метода pushState().
Прокручивая страницу, вы заметите, что через некоторое время:
– загруженное содержимое генерирует изменение URL-адреса в адресной строке браузера
– теги динамически изменяются (в частности, теги ссылок rel = [next/ prev])
Хотите использовать вызовы Ajax и технологию LA, рекомендованную Google? Затем просто дайте URL-адрес нашей демонстрации своей технической команде и попросите их черпать вдохновение из (сверхупрощенного) кода, представленного в этой демонстрации.