
RAID — это… Что такое RAID?
RAID (англ. redundant array of independent disks — избыточный массив независимых жёстких дисков) — массив из нескольких дисков, управляемых контроллером, взаимосвязанных скоростными каналами и воспринимаемых внешней системой как единое целое. В зависимости от типа используемого массива может обеспечивать различные степени отказоустойчивости и быстродействия. Служит для повышения надёжности хранения данных и/или для повышения скорости чтения/записи информации (RAID 0).
Аббревиатура RAID изначально расшифровывалась как «redundant array of inexpensive disks» («избыточный (резервный) массив недорогих дисков», так как они были гораздо дешевле RAM). Именно так был представлен RAID его создателями Петтерсоном (David A. Patterson), Гибсоном (Garth A. Gibson) и Катцом (Randy H. Katz) в 1987 году. Со временем RAID стали расшифровывать как «redundant array of independent disks» («избыточный (резервный) массив независимых дисков»), потому что для массивов приходилось использовать и дорогое оборудование (под недорогими дисками подразумевались диски для ПЭВМ).
Калифорнийский университет в Беркли представил следующие уровни спецификации RAID, которые были приняты как стандарт де-факто:
- RAID 0 представлен как дисковый массив повышенной производительности, без отказоустойчивости.
- RAID 1 определён как зеркальный дисковый массив.
- RAID 2 зарезервирован для массивов, которые применяют код Хемминга.
- RAID 3 и 4 используют массив дисков с чередованием и выделенным диском чётности.
- RAID 5 используют массив дисков с чередованием и «невыделенным диском чётности».
- RAID 6 используют массив дисков с чередованием и двумя независимыми «чётностями» блоков.
- RAID 10 — RAID 0, построенный из массивов RAID 1
- RAID 50 — RAID 0, построенный из RAID 5
- RAID 60 — RAID 0, построенный из RAID 6
Аппаратный RAID контроллер может поддерживать несколько разных RAID массивов одновременно, суммарное количество жёстких дисков которых не превышает количество разъёмов для них. При этом контроллер, встроенный в материнскую плату, в настройках BIOS имеет всего 2 состояния (включён или отключён), поэтому новый жёсткий диск, подключённый при активном RAID режиме в незадействованный разъём контроллера может игнорироваться системой, пока не будет ассоциирован как ещё один RAID массив типа JBOD (spanned), состоящий из одного диска.
Уровни RAID
RAID 0
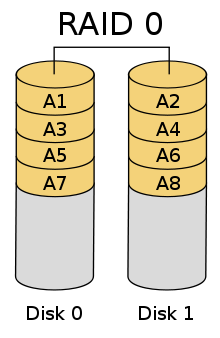 Схема RAID 0
Схема RAID 0RAID 0 (striping — «чередование») — дисковый массив из двух или более жёстких дисков без резервирования (т.е., по сути RAID-массивом не является). Информация разбивается на блоки данных () фиксированной длины и записывается на оба/несколько дисков одновременно.
(+): За счёт этого существенно повышается производительность (от количества дисков зависит кратность увеличения производительности).
(-): Надёжность RAID 0 заведомо ниже надёжности любого из дисков в отдельности и падает с увеличением количества входящих в RAID 0 дисков, т. к. отказ любого из дисков приводит к неработоспособности всего массива.
RAID 1
Два диска — минимальное количество для построения «зеркального» массива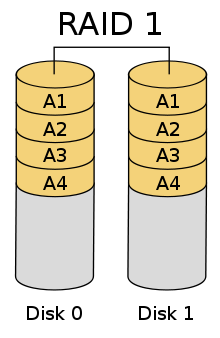 Схема RAID 1
Схема RAID 1RAID 1 (mirroring — «зеркалирование») — массив из двух дисков, являющихся полными копиями друг друга. Не следует путать с массивами RAID 1+0, RAID 0+1 и RAID 10, в которых используется более двух дисков и более сложные механизмы зеркалирования.
(+): Обеспечивает приемлемую скорость записи и выигрыш по скорости чтения при распараллеливании запросов.[1]
(+): Имеет высокую надёжность — работает до тех пор, пока функционирует хотя бы один диск в массиве. Вероятность выхода из строя сразу двух дисков равна произведению вероятностей отказа каждого диска. На практике при выходе из строя одного из дисков следует срочно принимать меры — вновь восстанавливать избыточность. Для этого с любым уровнем RAID (кроме нулевого) рекомендуют использовать диски горячего резерва. Достоинство такого подхода — поддержание постоянной доступности.
(-): Недостаток заключается в том, что приходится выплачивать стоимость двух жёстких дисков, получая полезный объём лишь одного жёсткого диска.
RAID 1+0 и RAID 0+1
Зеркало на многих дисках — RAID 1+0 или RAID 0+1. Под RAID 10 (RAID 1+0) имеют в виду вариант, когда два или более RAID 1 объединяются в RAID 0. Под RAID 0+1 может подразумеваться два варианта:
- два RAID 0 объединяются в RAID 1;
- в массив объединяются три и более диска, и каждый блок данных записывается на два диска данного массива[2]; таким образом, при таком подходе, как и в «чистом» RAID 1, полезный объём массива составляет половину от суммарного объёма всех дисков (если это диски одинаковой ёмкости).
Как и в других случаях, рекомендуется включать в массив диски горячего резерва из расчёта один резервный на пять рабочих.
RAID 2
Массивы такого типа основаны на использовании кода Хемминга. Диски делятся на две группы: для данных и для кодов коррекции ошибок, причём если данные хранятся на дисках, то для хранения кодов коррекции необходимо дисков. Данные распределяются по дискам, предназначенным для хранения информации, так же, как и в RAID 0, т.е. они разбиваются на небольшие блоки по числу дисков. Оставшиеся диски хранят коды коррекции ошибок, по которым в случае выхода какого-либо жёсткого диска из строя возможно восстановление информации. Метод Хемминга давно применяется в памяти типа ECC и позволяет на лету исправлять однократные и обнаруживать двукратные ошибки.
Достоинством массива RAID 2 является повышение скорости дисковых операций по сравнению с производительностью одного диска.
Недостатком массива RAID 2 является то, что минимальное количество дисков, при котором имеет смысл его использовать,— 7. При этом нужна структура из почти двойного количества дисков (для n=3 данные будут храниться на 4 дисках), поэтому такой вид массива не получил распространения. Если же дисков около 30-60, то перерасход получается 11-19%.
RAID 3
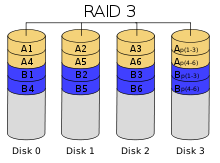 Схема RAID 3
Схема RAID 3В массиве RAID 3 из дисков данные разбиваются на куски размером меньше сектора (разбиваются на байты) или блоки и распределяются по дискам. Ещё один диск используется для хранения блоков чётности. В RAID 2 для этой цели применялся диск, но большая часть информации на контрольных дисках использовалась для коррекции ошибок на лету, в то время как большинство пользователей удовлетворяет простое восстановление информации в случае поломки диска, для чего хватает информации, умещающейся на одном выделенном жёстком диске.
Отличия RAID 3 от RAID 2: невозможность коррекции ошибок на лету и меньшая избыточность.
Достоинства:
- высокая скорость чтения и записи данных;
- минимальное количество дисков для создания массива равно трём.
Недостатки:
- массив этого типа хорош только для однозадачной работы с большими файлами, так как время доступа к отдельному сектору, разбитому по дискам, равно максимальному из интервалов доступа к секторам каждого из дисков. Для блоков малого размера время доступа намного больше времени чтения.
- большая нагрузка на контрольный диск, и, как следствие, его надёжность сильно падает по сравнению с дисками, хранящими данные.
RAID 4
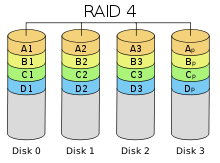 Схема RAID 4
Схема RAID 4RAID 4 похож на RAID 3, но отличается от него тем, что данные разбиваются на блоки, а не на байты. Таким образом, удалось отчасти «победить» проблему низкой скорости передачи данных небольшого объёма. Запись же производится медленно из-за того, что чётность для блока генерируется при записи и записывается на единственный диск. Из систем хранения широкого распространения RAID-4 применяется на устройствах хранения компании NetApp (NetApp FAS), где его недостатки успешно устранены за счет работы дисков в специальном режиме групповой записи, определяемом используемой на устройствах внутренней файловой системой WAFL.
RAID 5
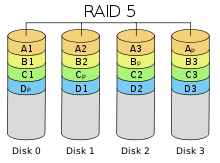 Схема RAID 5
Схема RAID 5Основным недостатком уровней RAID от 2-го до 4-го является невозможность производить параллельные операции записи, так как для хранения информации о чётности используется отдельный контрольный диск. RAID 5 не имеет этого недостатка. Блоки данных и контрольные суммы циклически записываются на все диски массива, нет асимметричности конфигурации дисков. Под контрольными суммами подразумевается результат операции XOR (исключающее или).
(+): RAID5 получил широкое распространение, в первую очередь, благодаря своей экономичности. Объём дискового массива RAID5 рассчитывается по формуле (n-1)*hddsize, где n — число дисков в массиве, а hddsize — размер наименьшего диска. Например, для массива из 4-х дисков по 80 гигабайт общий объём будет (4 — 1) * 80 = 240 гигабайт. На запись информации на том RAID 5 тратятся дополнительные ресурсы и падает производительность, так как требуются дополнительные вычисления и операции записи, зато при чтении (по сравнению с отдельным винчестером) имеется выигрыш, потому что потоки данных с нескольких дисков массива могут обрабатываться параллельно.
(-): Производительность RAID 5 заметно ниже, в особенности на операциях типа Random Write (записи в произвольном порядке), при которых производительность падает на 10-25% от производительности RAID 0 (или RAID 10), так как требует большего количества операций с дисками (каждая операция записи сервера заменяется на контроллере RAID на три — одну операцию чтения и две операции записи). Недостатки RAID 5 проявляются при выходе из строя одного из дисков — весь том переходит в критический режим (degrade), все операции записи и чтения сопровождаются дополнительными манипуляциями, резко падает производительность. При этом уровень надежности снижается до надежности RAID-0 с соответствующим количеством дисков (то есть в n раз ниже надежности одиночного диска). Если до полного восстановления массива произойдет выход из строя, или возникнет невосстановимая ошибка чтения хотя бы на еще одном диске, то массив разрушается, и данные на нем восстановлению обычными методами не подлежат. Следует также принять во внимание, что процесс RAID Reconstruction (восстановления данных RAID за счет избыточности) после выхода из строя диска вызывает интенсивную нагрузку чтения с дисков на протяжении многих часов непрерывно, что может спровоцировать выход какого-либо из оставшихся дисков из строя в этот наименее защищенный период работы RAID, а также выявить ранее необнаруженные сбои чтения в массивах cold data (данных, к которым не обращаются при обычной работе массива, архивные и малоактивные данные), что повышает риск сбоя при восстановлении данных. Минимальное количество используемых дисков равно трём.
RAID 5EE
Примечание: поддерживается не во всех контроллерах RAID level-5EE подобен массиву RAID-5E, но с более эффективным использованием резервного диска и более коротким временем восстановления. Подобно RAID level-5E, этот уровень RAID-массива создает ряды данных и контрольных сумм во всех дисках массива. Массив RAID-5EE обладает улучшенной защитой и производительностью. При применении RAID level-5E, ёмкость логического тома ограничивается ёмкостью двух физических винчестеров массива (один для контроля, один резервный). Резервный диск является частью массива RAID level-5EE. Тем не менее, в отличие от RAID level-5E, использующего неразделенное свободное место для резерва, в RAID level-5EE в резервный диск вставлены блоки контрольных сумм, как показывается далее на примере. Это позволяет быстрее перестраивать данные при поломке физического диска. При такой конфигурации, вы не сможете использовать его с другими массивами. Если вам необходим запасной диск для другого массива, вам следует иметь еще один резервный винчестер. RAID level-5E требует как минимум четырех дисков и, в зависимости от уровня прошивки и их ёмкости, поддерживает от 8 до 16 дисков. RAID level-5E обладает определенной прошивкой. Примечание: для RAID level-5EЕ, вы можете использовать только один логический том в массиве.
Достоинства:
- 100% защита данных
- Большая ёмкость физических дисков по сравнению с RAID-1 или RAID -1E
- Большая производительность по сравнению с RAID-5
- Более быстрое восстановление RAID по сравнению с RAID-5Е
Недостатки:
- Более низкая производительность, чем в RAID-1 или RAID-1E
- Поддержка только одного логического тома на массив
- Невозможность совместного использования резервного диска с другими массивами
- Поддержка не всех контроллеров
RAID 6
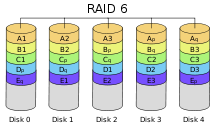 Схема RAID 6
Схема RAID 6RAID 6 — похож на RAID 5, но имеет более высокую степень надёжности — под контрольные суммы выделяется ёмкость 2-х дисков, рассчитываются 2 суммы по разным алгоритмам. Требует более мощный RAID-контроллер. Обеспечивает работоспособность после одновременного выхода из строя двух дисков — защита от кратного отказа. Для организации массива требуется минимум 4 диска[3]. Обычно использование RAID-6 вызывает примерно 10-15% падение производительности дисковой группы, по сравнению с аналогичными показателями RAID-5, что вызвано большим объёмом обработки для контроллера (необходимость рассчитывать вторую контрольную сумму, а также прочитывать и перезаписывать больше дисковых блоков при записи каждого блока).
RAID 7
RAID 7 — зарегистрированная торговая марка компании Storage Computer Corporation, отдельным уровнем RAID не является. Структура массива такова: на дисках хранятся данные, один диск используется для складирования блоков чётности. Запись на диски кешируется с использованием оперативной памяти, сам массив требует обязательного ИБП; в случае перебоев с питанием происходит повреждение данных.
RAID 10
Схема архитектуры RAID 10RAID 10 — зеркалированный массив, данные в котором записываются последовательно на несколько дисков, как в RAID 0. Эта архитектура представляет собой массив типа RAID 0, сегментами которого вместо отдельных дисков являются массивы RAID 1. Соответственно, массив этого уровня должен содержать как минимум 4 диска. RAID 10 объединяет в себе высокую отказоустойчивость и производительность.
Нынешние контроллеры используют этот режим по умолчанию для RAID 1+0. То есть, один диск основной, второй — зеркало, считывание данных производится с них поочередно. Сейчас можно считать, что RAID 10 и RAID 1+0 — это просто разное название одного и того же метода зеркалирования дисков. Утверждение, что RAID 10 является самым надёжным вариантом для хранения данных, ошибочно, т.к., несмотря на то, что для данного уровня RAID возможно сохранение целостности данных при выходе из строя половины дисков, необратимое разрушение массива происходит при выходе из строя уже двух дисков, если они находятся в одной зеркальной паре.
Комбинированные уровни
Помимо базовых уровней RAID 0 — RAID 5, описанных в стандарте, существуют комбинированные уровни RAID 1+0, RAID 3+0, RAID 5+0, RAID 1+5, которые различные производители интерпретируют каждый по-своему.
- RAID 1+0 — это сочетание зеркалирования и чередования (см. выше).
- RAID 5+0 — это чередование томов 5-го уровня.
- RAID 1+5 — RAID 5 из зеркалированных пар.
Комбинированные уровни наследуют как преимущества, так и недостатки своих «родителей»: появление чередования в уровне RAID 5+0 нисколько не добавляет ему надёжности, но зато положительно отражается на производительности. Уровень RAID 1+5, наверное, очень надёжный, но не самый быстрый и, к тому же, крайне неэкономичный: полезная ёмкость тома меньше половины суммарной ёмкости дисков…
Стоит отметить, что количество жёстких дисков в комбинированных массивах также изменится. Например для RAID 5+0 используют 6 или 8 жёстких дисков, для RAID 1+0 — 4, 6 или 8.
Сравнение стандартных уровней
| Уровень | Количество дисков | Эффективная ёмкость* | Отказоустойчивость | Преимущества | Недостатки |
|---|---|---|---|---|---|
| 0 | от 2 | S * N | нет | наивысшая производительность | очень низкая надёжность |
| 1 | 2 | S | 1 диск | надёжность | двойная стоимость дискового пространства |
| 1E | от 3 | S * N / 2 | 1 диск** | высокая защищённость данных и неплохая производительность | двойная стоимость дискового пространства |
| 10 или 01 | от 4, чётное | S * N / 2 | 1 диск*** | наивысшая производительность и высокая надёжность | двойная стоимость дискового пространства |
| 5 | от 3 до 16 | S * (N — 1) | 1 диск | экономичность, высокая надёжность, неплохая производительность | производительность ниже RAID 0 |
| 50 | от 6, чётное | S * (N — 2) | 2 диска** | высокая надёжность и производительность | высокая стоимость и сложность обслуживания |
| 5E | от 4 | S * (N — 2) | 1 диск | экономичность, высокая надёжность, скорость выше RAID 5 | производительность ниже RAID 0 и 1, резервный накопитель работает на холостом ходу и не проверяется |
| 5EE | от 4 | S * (N — 2) | 1 диск | быстрое реконструирование данных после сбоя, экономичность, высокая надёжность, скорость выше RAID 5 | производительность ниже RAID 0 и 1, резервный накопитель работает на холостом ходу и не проверяется |
| 6 | от 4 | S * (N — 2) | 2 диска | экономичность, наивысшая надёжность | производительность ниже RAID 5 |
| 60 | от 8, чётное | S * (N — 2) | 2 диска | высокая надёжность, большой объем данных | высокая стоимость и сложность организации |
| 61 | от 8, чётное | S * (N — 2) / 2 | 2 диска** | очень высокая надёжность | высокая стоимость и сложность организации |
* N — количество дисков в массиве, S — объём наименьшего диска.[4][5][6][7][8] ** Информация не потеряется, если выйдут из строя все диски в пределах одного зеркала. *** Информация не потеряется, если выйдут из строя два диска в пределах разных зеркал.
Matrix RAID
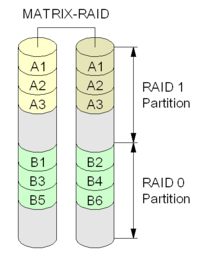 Схема Intel Matrix RAID
Схема Intel Matrix RAIDMatrix RAID — это технология, реализованная фирмой Intel в своих чипсетах начиная с ICH6R. Строго говоря, эта технология не является новым уровнем RAID (ее аналог существует в аппаратных RAID-контроллерах высокого уровня), она позволяет, используя небольшое количество дисков организовать одновременно один или несколько массивов уровня RAID 1, RAID 0 и RAID 5. Это позволяет за сравнительно небольшие деньги обеспечить для одних данных повышенную надёжность, а для других высокую скорость доступа и производства.
Дополнительные функции RAID-контроллеров
Многие RAID-контроллеры оснащены набором дополнительных функций:
- «Горячая замена» (Hot Swap)
- «Горячий резерв» (Hot Spare)
- Проверка на стабильность.
Программный (англ. software) RAID
Для реализации RAID можно применять не только аппаратные средства, но и полностью программные компоненты (драйверы). Например, в системах на ядре Linux существуют специальные модули ядра, а управлять RAID-устройствами можно с помощью утилиты mdadm. Программный RAID имеет свои достоинства и недостатки. С одной стороны, он ничего не стоит (в отличие от аппаратных RAID-контроллеров, цена которых от $250). С другой стороны, программный RAID использует ресурсы центрального процессора, и в моменты пиковой нагрузки на дисковую систему процессор может значительную часть мощности тратить на обслуживание RAID-устройств.
Ядро Linux 2.6.28 (последнее из вышедших в 2008 году) поддерживает программные RAID следующих уровней: 0, 1, 4, 5, 6, 10. Реализация позволяет создавать RAID на отдельных разделах дисков, что аналогично описанному выше Matrix RAID. Поддерживается загрузка с RAID.
ОС семейства Windows NT, такие как Windows NT 3.1/3.5/3.51/NT4/2000/XP/2003 изначально, с момента проектирования данного семейства, поддерживает программный RAID 0, RAID 1 и RAID 5 (см. Dynamic Disk). Более точно, Windows XP Pro поддерживает RAID 0. Поддержка RAID 1 и RAID 5 заблокирована разработчиками, но, тем не менее, может быть включена, путем редактирования системных бинарных файлов ОС, что запрещено лицензионным соглашением.[9] Windows 7 поддерживает программный RAID 0 и RAID 1, Windows Server 2003 — 0, 1 и 5. Windows XP Home не поддерживает RAID.
В ОС FreeBSD есть несколько реализаций программного RAID. Так, atacontrol, может как полностью строить программный RAID, так и может поддерживать полуаппаратный RAID на таких чипах как ICH5R. Во FreeBSD, начиная с версии 5.0, дисковая подсистема управляется встроенным в ядро механизмом GEOM. GEOM предоставляет модульную дисковую структуру, благодаря которой родились такие модули как gstripe (RAID 0), gmirror (RAID 1), graid3 (RAID 3), gconcat (объединение нескольких дисков в единый дисковый раздел). Также существуют устаревшие классы ccd (RAID 0, RAID 1) и gvinum (менеджер логических томов vinum). Начиная с FreeBSD 7.2 поддерживается файловая система ZFS, в которой можно собирать следующие уровни RAID: 0, 1, 5, 6, а также комбинируемые уровни.
OpenSolaris и Solaris 10 используют Solaris Volume Manager, который поддерживает RAID-0, RAID-1, RAID-5 и любые их комбинации как 1+0. Поддержка RAID-6 осуществляется в файловой системе ZFS.
Дальнейшее развитие идеи RAID
Синий разъём PCI-X на материнской плате сервера FSC Primergy TX200 S2 специально предназначен для платы ноль-канального RAID (zero-channel RAID, ZCR). Установлен MegaRAID 320-0 Zero Channel RAID Controler фирмы LSI)[10]Идея RAID-массивов — в объединении дисков, каждый из которых рассматривается как набор секторов, и в результате драйвер файловой системы «видит» как бы единый диск и работает с ним, не обращая внимания на его внутреннюю структуру. Однако, можно добиться существенного повышения производительности и надёжности дисковой системы, если драйвер файловой системы будет «знать» о том, что работает не с одним диском, а с набором дисков.
Более того: при разрушении любого из дисков в составе RAID-0 вся информация в массиве окажется потерянной. Но если драйвер файловой системы разместил каждый файл на одном диске, и при этом правильно организована структура директорий, то при разрушении любого из дисков будут потеряны только файлы, находившиеся на этом диске; а файлы, целиком находящиеся на сохранившихся дисках, останутся доступными.
Интересные факты
Сотрудник корпорации Y-E Data, которая является крупнейшим в мире производителем USB флоппи-дисководов, Дэниэл Олсон в качестве эксперимента создал RAID-массив из четырех iPod Shuffle[11].
Годовая вероятность отказа дискового массива RAID 5 из 3-х дисков WD Caviar Blue = 0.05%[12].
См. также
- JBOD — RAID-массив с последовательным распределением дискового пространства по дискам.
- NAS — внешнее сетевое хранилище данных со встроенным RAID.
Примечания
Ссылки
dic.academic.ru
Описание и схемы Raid массивов и способов их восстановления
Описание рэйд массива и способы его восстановления
К сожалению, жесткие диски, которые являются на сегодняшний день основным хранилищем данных, не так надежны, как хотелось бы. И достаточно остро стоит проблема обезопасить свои файлы, чтобы не пришлось прибегать к восстановлению данных. Одним из путей решения этой проблемы является организация из двух и более накопителей raid массивов. Рейд массивы бывают разных конфигураций, и их создание преследует разные цели. От создания резервной копии информации, до ускорения существующей дисковой системы.
Почему может пропасть информация с RAID массива?
Основная причина, с которой мне, как инженеру по восстановлению информации приходится сталкиваться, это поломка одного или нескольких дисков рейд массива, когда перед непосредственно сборкой требуется произвести ремонт жесткого диска, вышедшего из строя. Следующая по частоте обращений с поломанным raid проблема — выход из строя рейд контроллера. Далее следуют всевозможные глюки raid контроллера, когда из рэйд массива выпадают диски (диск в raid массиве стал неактивным, получил статус degraded) и логические сбои — потеря логических томов raid или утрачена конфигурация массива. Нередко приходится сталкиваться с человеческим фактором — диски в рэйд массиве переставили местами, провели некорректную переинициализацию массива, провели неправильный ребилд рэйда.
В особо сложных случаях приходится сталкиваться с ситуациями, когда рейд массив был некорректно собран, и после такой пересборки были запущены проверочные утилиты Windows — чекдиск и им подобные.
Рассмотрим основные типы рэйд массивов:
Raid 0
Raid 0 описание
Рэйд 0 или рейд страйп (raid stripe) состоит в простейшем случае из двух дисков, блоки которых чередуются следующим образом: первые 64 килобайта на первом диске с 0-го сектора, второй блок в 64 килобайта на втором диске с 0-го сектора, третий блок опять на первом диске сразу по окончании первого, четвертый на втором диске по окончании второго блока и так далее. Размер блоков может варьироваться. За счет подобной организации массива достигается повышенная пропускная способность, по сравнению с одиночным диском, и как следствие повышается общая производительность дисковой подсистемы.

Raid 0 описание
Минимально необходимое количество дисков для создания raid0 массива — 2. При выходе из строя одного жесткого диска рэйд массив перестает функционировать, как говорится, рейд рассыпался и нужно восстановить информацию.
Восстановление raid 0
Как восстановить данные с raid0 массива? Очень просто. Определяем порядок и очередность дисков, размер блока, после чего с помощью программного обеспечения, которое может реализовывать виртуальный рэйд массив, указав все характеристики raid 0 массива, производим виртуальную сборку рэйд 0. По окончании этого процесса данные с raid 0 можно копировать на внешнее хранилище информации.
Raid 1
Raid 1 описание
Рэйд 1 или рейд зеркало, зеркальный raid массив, mirrored raid. В названии содержится его суть. Все диски массива имеют зеркальную копию содержимого raid array. Подобный raid массив имеет повышенную отказоустойчивость, и может функционировать до тех пор, пока хоть один из дисков рэйд массива продолжает работать.

Raid 1 описание
Минимально необходимое количество дисков для создания raid1 массива — 2, но в ряде случаев, в частности когда нужно программно восстановить LVM, собирается массив из одного диска с изначальным статусом degraded.
Восстановление raid 1
Не смотря на кажущуюся простоту — для того, чтобы восстановить данные с рэйд1 достаточно казалось бы восстановить информацию с любого из накопителей, на деле инженер сталкивается с необходимостью восстановления данных с наиболее актуального диска в массиве, т.к. изначально сложно сказать, какой именно диск в raid 1 массиве вышел из строя раньше и соответственно содержит устаревшие версии данных, а какой позже, и соответственно актуальность этого диска выше. В худшем случае приходится организовывать доступ к пользовательским данным на всех дисках для восстановления информации с неисправного raid 1 массива.
Raid 1e
Raid 1e описание
В raid 1E реализована функция сквозной записи блоков данных (stripe) когда каждый следующий блок записывается на следующий жесткий диск, кроме того на него же дублируется блок данных с предыдущего диска. Такая схема позволяет использовать нечетное количество дисков в рейде. При отказе одного диска в системе, потери данных не происходит. Ремонт raid 1e массива требуется при отказе более одного диска.
Raid 5
Raid 5 описание
По сути, RAID 5, пятый рэйд это тот же страйп, дополненный блоками контрольных сумм. Минимальное количество дисков для организации рейд массива пятого уровня — три HDD. Raid 5 подразделяется на forward (форвард), backward (бэквард), forward dynamic (форвард динамик) и backward dynamic (бэквард динамик). Отличия между этими типами raid 5 в очередности блоков контрольной суммы и их ротации. Отдельно стоит упомянуть про особенности восстановления raid 5 с серверов HP восстановление raid 5 hewlett Packard) где средствами контроллера организован так называемый delay, задержка, после которой собственно и начинается ротация блоков.

Raid 5 backward описание

Raid 5 forward описание

Raid 5 forward dynamic описание

Raid 5 backward dynamic описание
Минимально необходимое количество дисков для создания raid5 массива — 3. Рэйд 5 способен функционировать при выходе из строя одного диска в массиве. В этом случае замедляется скорость работы системы в целом. Появляются задержки особенно заметные при работе с базами данных. При выходе из строя двух дисков и более, raid 5 перестает работать и требуется восстановление данных.
Восстановление raid 5
Для восстановления данных с raid 5 массива требуется создание клонов по возможности всех дисков массива и сборка рейда виртуально. Порядок тот же, что и в случаях с восстановлением данных на raid 0, а именно: определение порядка дисков, размера блока и на финальных стадиях восстановления данных с рэйд 5 массива определение актуальной сборки в тех случаях, когда в массиве сперва вышел из строя один диск, какое-то время сервер работал в критическом режиме, и только потом на raid 5 отказало два диска или более.
Raid 5e
Raid 5e описание
Массив RAID 5e (RAID 5 enhanced) является усовершенствованной версией RAID5, с повышенной производительностью и сохранностью данных. Кроме резервирования места для контрольных сумм, также резервируется место для горячей замены (hot-spare). Причем, запись производится на каждый из жестких дисков и резервированное место так же есть на каждом из hdd. Таким образом , возрастает скорость работы raid-массива и каждый из жестких дисков используется равномерно. Для построения Raid 5E потребуется как минимум 4 жестких диска. Отличительная особенность массива этого уровня в том, что резервная область hot spare расположена в логическом конце физических дисков.

Raid 5-e backward описание
Восстановление raid 5e
По сравнению с обычной пятеркой рейд 5е собирается несколько сложнее, так как приходится учитывать наличие hot spare пространства. Если из массива не выпадали в процессе диски, не шел процесс самовосстановления raid массива средствами контроллера, то сборка 5e рэйд массива ни чем не отличается от обычной пятерки. Если же хот спейр пространство было использовано (или началось использоваться) то приходится этот нюанс учитывать. Но в целом базовый подход такой же — определение очередности накопителей, определения размера блока, типа ротации блоков четности и определение актуальности жестких дисков в массиве.
Raid 5ee
Raid 5ee описание
RAID 5EE отличается от RAID 5E только логической структурой расположения данных. Если в RAID 5E резервное место выделяется общим куском в конце массива, то в RAID 5EE это место делится на блоки которые ротируются с блоками контрольной суммы и блоками данных. При перестройке(rebuild) массива, такая схема расположения блоков ускоряет процесс восстановления работоспособности. Рэйд 5 ее так же весьма напоминает по своему строению raid 6 где вместо одного из блоков четности используется hot-spare блок.

Raid 5-ee backward описание
Восстановление raid 5ee
Особенности восстановления информации с такого, прямо скажем нечасто встречающегося рейд массива, каким является raid 5ee заключаются в сложности его идентификации. Если массив вышел из строя по причине поломки рэйд контроллера идентификация достаточно проста, наличие регулярно повторяющихся пустых блоков ожидаемого размера говорит само за себя. Если же в процессе работы рэйд массива вышел из строя один жесткий диск и его заменили другим, начался процесс переинициализации массива (ребилд рэйда) который закончился с ошибкой, или raid контроллер перевел массив в аварийный режим, то ранее пустые блоки могут содержать данные, рассчитанные контроллером по контрольным суммам.
Raid 6
Raid 6 описание
Дальнейшее логическое развитие пятого рэйда — raid 6, который от пятого отличается наличием двух блоков контрольных сумм, и соответственно в состоянии пережить выход из строя двух дисков в массиве. Типы ротации блоков контрольных сумм те же — forward, backward и их dynamic вариации. При выходе из строя трех дисков и больше в рэйд 6 массиве сервер перестает функционировать и требуется восстановление информации. Точно так же различают рэйд форвард, рэйд бэквард и их динамик вариации.

Raid 6 backward описание

Raid 6 forward описание
Минимально необходимое количество дисков для создания raid6 массива — 4.
Восстановление raid 6
И опять методология сходна с восстановлением информации на raid 5, проблема осложняется только тем, что из коммерческого программного обеспечения мало кто может похвастаться поддержкой восстановления данных с raid 6. Но в целом порядок тот же — определение очередности, размера блоков и выяснение степени актуальности. Кроме того, нужно отметить что на raid 6 массивах чаще чем на 5-х и уж тем более чаще чем на страйпах или рейд-зеркалах встречаются такие вещи, как слайсы, десятки виртуальных машин, малораспространенные файловые *NIX системы и прочие прелести.
Рекомендую к прочтению дополнительные материалы: восстановление raid 6 и raid 6 wide pace proNAS OS
Raid 10
Raid 10 описание
Raid 10 представляет из себя комбинацию рейдов первого и нулевого уровней. В raid 10 используется 4 (или более) жестких диска, которые попарно зеркалированы друг на друга(RAID 1), а пары объединены в RAID 0. Поломка диска внутри пары, не приводит к потере данных, однако при выходе из строя пары, данные теряются и требуется процедура восстановления.

Raid 10 описание
Минимально необходимое количество дисков для создания raid10 массива — 4.
Восстановление raid 10
Восстановление данных с рэйд массива raid 10 вышедшего из строя по причине аппаратного сбоя (поломки нескольких жестких дисков в рэйд массиве) приходится делать не часто. Гораздо чаще приносят на восстановление raid10 массивы на которых потеряны данные вследствие сбоя контроллера или неквалифицированных действий персонала (системных администраторов). Ввиду недостаточно эффективного использования дискового пространства подобные рэйд-массивы используют в крупных коммерческих организациях и как правило подобные задачи осложнены использованием слайсов, когда идет поступенчатое представление физические жесткие диски — логические — физические — логические. Когда аппаратно собранный неразмеченный еще рейд-массив средствами raid контроллера делится на слайсы, которые опять таки представляются как физические накопители, из которых в свою очередь собирается другой raid массив, возможно с другой конфигурацией, например рэйд5 или рэйд0.
Raid JBOD
JBOD Raid описание
JBOD (Just a bundle of disks), то есть связка жестких дисков, рейд массивом строго говоря не является. Однако несколько дисков могут быть объединены в один логический раздел с помощью операционной системы, либо аппаратно, с помощью рэйд контроллера, поддерживающего функцию построения jbod массива. Файлы обычно записываются последовательно до конца диска, далее запись продолжается на следующий указанный hdd. Подобная организация данных не требует специального оборудования, как я сказал выше, и может быть реализована на программном уровне средствами ОС или стороннего ПО. Однако при поломке одного из дисков файловая система разрушается и требуется операция восстановления данных jbod массива.

JBOD массив описание
Минимально необходимое количество томов (дисков) для создания jbod — 2.
Восстановление JBOD
В случае выхода из строя дискового jbod массива необходимо определиться с порядком дисков, это не сложно сделать, если в джибод-массиве всего два накопителя, и задача становится сложнее, если дисков три или более. В этом случае нужно провести анализ таблиц размещения файлов, определиться с адресацией начала файла или директории и проведя необходимые вычисления достаточно легко определить очередность дисков в массиве. Так же нужно отметить, что в ряде случаев, когда один или несколько дисков jbod массива вышли из строя и не подлежат восстановлению, информацию с поврежденного jbod все же можно достать, пусть и частично.
Raid 50
Raid 50 описание
Raid 50 является комбинацией между двумя рэйд-массивами пятого уровня, объединенными между собой в страйп, или raid 0. Минимальное количество дисков для построения рэйд 50 массива — шесть штук.

Raid 50 описание
На иллюстрации показан частный случай организации такого массива. Нужно иметь ввиду, что на ряде контроллеров идет каскадное представление дисков по цепочке физический-логический-физический. То есть шесть физических жестких дисков объединяются в два логических массива (диска) raid-5, далее они представляются как два физических диска соответствующего размера и уже эти диски объединяются между собой в страйп, со своим размером блока и очередностью и восстановление raid может быть в такой ситуации весьма нетривиальной задачей. Полученный логический диск собранный по технологии рейд 50, уже средствами ОС воспринимается как физический, и размечается и форматируется.
В качестве иллюстрации возможных нагромождений представим что этот «физический» диск raid-50 делится средствами ОС на два логических, из которых собирается JBOD или raid-0 уже средствами ОС. Инженер осуществляющий восстановление данных raid и получивший шесть дисков которые состояли в подобном массиве может потратить массу времени на построение таблиц соответствия блоков и дисков.
Восстановление Raid-50
Как и в случаях с рэйд массивами 6-го уровня, на raid-50 достаточно часто встречаются надстройки в виде слайсов, крутятся десятки виртуальных машин, *nix файловые системы, VMFS и прочие радости бытия. Восстановление информации с raid50 является достаточно сложной задачей. Для начала нужно попытаться получить максимально полную информацию о предполагаемой конфигурации, количестве и размере разделов и т.п. Далее, определившись с конфигурацией, целесообразно идти по пути сборки, которой оперировал raid контроллер. То есть сначала собираются все рэйд-5 массивы входившие в состав raid50, выгружаются в отдельные образы и уже они объединяются в виртуальный страйп.
Какой raid массив
лучше использовать на практике?
Рекомендации по выбору рэйд массива и эксплуатации рэйд массивов
Для того, чтобы ответить на вопрос, какой же рэйд массив лучше использовать на практике, нужно определиться с задачами, которые стоят перед конторой или системным администратором. В общем случае таких задач две, повышение скорости дисковой подсистемы и повышение надежности хранения информации. Редко какая то из этих двух целей доминирует, как правило, используется комбинированный подход со смещением приоритетов в сторону быстродействия или сохранности данных. Немаловажную роль в принятии решения играет и финансовая составляющая, которую можно условно представить как цена за гигабайт дискового пространства. Очевидно, что у страйпа и JBOD она будет ниже всего, т.к. потерь нет, дисковое пространство всех жестких дисков в массиве суммируется, а например на зеркальном рэйде стоимость доступного гигабайта будет больше всего.
Комбинированные решения, они же наиболее популярные, это массивы Raid level 5. Эти массивы являются абсолютными лидерами по использованию, соответственно и обращаются с проблемами в рйэд 5 массивах чаще.
Наиболее критичные данные целесообразно держать на рэйд 1 или рэйд 10, либо на рэйд 5 с обязательной продуманной политикой создания резервных копий на внешние диски, не входящие в состав массива. Страйпы целесообразно использовать для выделенного дискового пространства в файлах подкачки на графических станциях, известно, что тот же Photoshop очень любит свопы туда сюда прокачивать и при работе с большими изображениями это может серьезно сказаться на быстродействии системы.
JBOD как правило используют, чтобы достичь объема единого диска, недоступного в качестве физического. То есть если вам требуется диск на 10 терабайт для выгрузки части образа при восстановлении raid 10 на 24-х двух терабайтниках (а это еще не самый сложный массив с которым приходилось сталкиваться), то создание JBOD массива это самый удобный и правильный в этой ситуации подход к решению задачи.
Если вы столкнулись с потерей данных на рэйд массиве, вы можете получить бесплатную online или телефонную консультацию и рекомендации к дальнейшим действиям от специалиста по восстановлению данных.
www.hardmaster.info
Начнем с математики. Векторизация вычислений в реализации технологии RAID-6
Многие помнят публикацию о «Рэйдикс» на Хабре «Как разработчики сидели в Петербурге и тихо ели грибы», в которой партнеры кратко изложили историю появления нашего продукта. Поэтому в первой статье своего Хаброблога мы бы хотели погрузиться в математические основы технологий RAIDIX.
Image: www.nonotak.com
Дисковый массив
Многие промышленные программно-аппаратные системы (системы управления ресурсами предприятия, оперативного анализа данных, управления цифровым контентом и др.) требуют активного обмена данными между компьютерами и внешними накопителями данных. Быстродействие таких накопителей (жёстких дисков) значительно ниже, чем быстродействие оперативной памяти компьютера (а производительность всей системы, как правило, и упирается в самый «медленный» её компонент). В связи с этим возникает задача увеличения скорости доступа к данным, хранимым на внешних устройствах. Поэтому широкое распространение на практике получили подсистемы хранения данных (СХД), объединяющие несколько независимых дисков в единое логическое устройство.
Для повышения производительности в состав СХД включаются несколько дисковых накопителей с возможностью параллельного чтения и записи информации. В настоящее время активно применяется семейство технологий под общим названием RAID: Redundant Array of Independent/Inexpensive Disks — избыточный массив независимых/недорогих жёстких дисков (Chen, Lee, Gibson, Katz, & Patterson, 1993).
Данные технологии решают не только задачу повышения производительности СХД, но и сопутствующую ей задачу — повышение надёжности хранения данных: ведь отдельные диски могут выходить из строя при работе системы. Надежность обеспечивается с помощью информационной избыточности: в системе используются дополнительные диски, на которые записываются специальным образом вычисленные контрольные суммы, позволяющие восстановить информацию в случае выхода из строя одного или нескольких дисков СХД.
Введение избыточных дисков позволяет решить проблему надёжности, но влечёт за собой необходимость выполнять дополнительные действия, связанные с вычислением контрольных сумм при каждом чтении/записи данных с дисков. Производительность этих вычислений, в свою очередь, оказывает существенное влияние на производительность СХД в целом. В целях увеличения производительности RAID-вычислений наиболее востребованной на практике является технология RAID-6, позволяющая восстановить два вышедших из строя диска.
В данном материале приводится обзор семейства технологий RAID и обсуждаются детали реализации RAID-6 алгоритмов на платформе Intel 64. Данная информация доступна в открытых источниках (Anvin, 2009), (Intel, 2012), мы же приводим ее в сжатом, удобочитаемом виде. Кроме того, мы представляем результаты сравнения библиотеки помехоустойчивого кодирования СХД RAIDIX с популярными библиотеками, реализующими похожий функционал: ISA-l (Intel), Jerasure (J. Plank).
Уровни RAID
Вычислительные алгоритмы, которые используются при построении RAID-массивов, появлялись постепенно и впервые были классифицированы в 1993 году в работе Chen, Lee, Gibson, Katz, & Patterson, 1993.
В соответствии с этой классификацией массивом RAID-0 именуется массив независимых дисков, в котором не предпринимаются меры по защите информации от утраты. Преимущество таких массивов по сравнению с одиночным диском состоит в возможности существенного увеличения ёмкости и производительности за счёт организации параллельного обмена данными.
Технология RAID-1 подразумевает дублирование каждого диска системы. Таким образом, массив RAID-1 имеет удвоенное количество дисков по сравнению с RAID-0, но выход из строя одного диска системы не влечёт за собой утрату данных, поскольку в массиве для каждого диска имеется копия.
Технологии RAID-2 и RAID-3 не получили распространения на практике, и мы опустим их описание.
Технология RAID-4 подразумевает использование одного дополнительного диска, на который записывается сумма (XOR) остальных дисков данных СХД:
Контрольная сумма (или синдром) обновляется при выполнении каждой записи данных на диски СХД. Отметим, что для этого нет необходимости вычислять (1) заново, а достаточно прибавить к синдрому разность старого и нового значения изменяемого диска. В случае выхода из строя одного из дисков уравнение (1) может быть решено относительно появившегося неизвестного, т.е. данные с утраченного диска будут восстановлены.
Очевидно, что операции чтения и записи синдрома происходят чаще, чем операции с любым другим диском данных. Этот диск становится самым загруженным элементом массива, т.е. слабым звеном с точки зрения производительности. Кроме того, он быстрее изнашивается. Для решения этой проблемы была предложена технология RAID-5, в которой для хранения синдромов используются части различных дисков системы (Рис. 1). Таким образом, загрузка дисков операциями чтения и записи выравнивается.
Рис. 1. Отличие технологий RAID-4 и RAID-5
Отметим, что технологии RAID-1 — RAID-5 позволяют восстанавливать данные в случае выхода из строя одного из дисков, но в случае утраты двух дисков эти технологии оказываются бессильны. Конечно, вероятность одновременного выхода из строя двух дисков значительно ниже, чем одного. Однако на практике замена отказавшего диска требует определенного времени, в течение которого данные остаются «беззащитными». Этот интервал может оказаться весьма длительным в случае, если системные администраторы работают в одну смену или система расположена в труднодоступном месте.
С другой стороны, при механической замене диска нельзя исключить возможность человеческой ошибки (замены исправного диска вместо неисправного), в результате которой перед нами вновь встает проблема восстановления двух дисков. Для решения указанных задач была предложена технология RAID-6, ориентированная на восстановление двух дисков. Рассмотрим данный алгоритм более подробно.
Технология RAID-6
Алгоритмы вычислений, используемые при построении СХД по спецификации RAID-6, приведены в (Anvin, 2009). Здесь мы изложим их в форме, удобной для использования в рамках настоящего исследования.
С целью увеличения производительности системы данные, поступающие для записи, обычно накапливаются во внутреннем кэше системы хранения данных и записываются на диски в соответствии с внутренней стратегией кэширования, которая существенно влияет на производительность системы в целом. При этом операции записи выполняются большими блоками данных, которые в дальнейшем будем называть страйпами (stripe).
Аналогично записи, при запросе на физическое чтение с дисков производится чтение не только запрошенных данных, но и всего страйпа (или нескольких страйпов), в котором эти данные расположены. В дальнейшем страйп остается в кэше системы в ожидании относящихся к нему запросов на чтение.
Для повышения производительности СХД страйп записывается и читается параллельно на все диски системы. Для этого он разбивается на блоки одинакового размера, которые будем обозначать . Количество блоков N равно количеству дисков данных в массиве. Для обеспечения отказоустойчивости в дисковый массив вводятся два дополнительных диска, которые будем обозначать P и Q. В страйп включим блоки, соответствующие массивам , а также дискам P и Q (Рис 2.) В случае выхода из строя одного или двух дисков СХД данные в соответствующих блоках восстанавливаются с использованием синдромов.
Рис. 2. Структура страйпа
Отметим, что в RAID-6 для поддержания равномерной нагрузки дисков, так же, как и в технологии RAID-5, синдромы разных страйпов помещаются на разные физические диски. Впрочем, для нашего исследования этот факт не релевантен. В дальнейшем по умолчанию считаем, что все синдромы хранятся в последних блоках страйпа.
Для вычисления синдромов разобьём блоки на отдельные слова и будем повторять вычисления контрольных сумм для всех слов с одинаковыми номерами. Для каждого слова будем вычислять синдромы по следующему правилу:
Тогда в случае утраты дисков с номерами α и β можно составить следующую систему уравнений:
$$display$$\left\{ \begin{aligned} D_α + D_β & = P — \sum{}D_i \\ q_αD_α + q_βD_β & = Q — \sum{}q_iD_i \end{aligned} \right. i≠α,β; α≠β$$display$$
Если система однозначно разрешима для любых α и β, то в страйпе можно восстановить два любых утраченных блока. Введём следующие обозначения:
$$display$$P_{α,β} = \sum_{i=0\\i≠α\\α≠β}^{N-1}D_i; \bar{P}_{α,β} = P — P_{α,β}$$display$$
$$display$$Q_{α,β} = \sum_{i=0\\i≠α\\α≠β}^{N-1}q_iD_i; \bar{Q}_{α,β} = Q — Q_{α,β}$$display$$
Тогда имеем:
$$display$$ \left\{ \begin{aligned} D_α + D_β & = \bar{P}_{α,β} \\ q_αD_α + q_βD_β & = \bar{Q}_{α,β} \end{aligned} \right. \Leftrightarrow \left\{ \begin{aligned} D_α &= \bar{P}_{α,β} — D_β \\ D_β & = \frac {q_α\bar{P}_{α,β} — \bar{Q}_{α,β}}{q_α — q_β} \end{aligned} ,α≠β \right. \qquad (3)$$display$$
Для однозначной разрешимости (3) необходимо обеспечить, чтобы все и были различны и чтобы их разность была обратима в той алгебраической структуре, в которой производятся вычисления. Если в качестве такой структуры выбрать конечное поле (поле Галуа), то оба эти условия совпадают при правильном выборе примитивного элемента поля.
Если из двух вышедших из строя дисков один содержал данные, а другой — синдром, то восстановить оба диска можно при помощи уцелевшего синдрома. Не будем подробно рассматривать этот случай — математические основания здесь сходные.
Поскольку на практике количество дисков в массиве не очень велико (редко превышает 100), то для повышения производительности мы можем заранее вычислить всевозможные необходимые константы $inline$(q_α-q_β )^{-1},q_α,$inline$, и использовать их в дальнейшем при вычислениях.
Скорость выполнения вычислений в рассматриваемой задаче критически важна для поддержания общей производительности СХД не только в случае выхода из строя двух дисков, но и в «штатном» режиме, когда все диски работоспособны. Это связано с тем, что страйп разбит на блоки, которые физически располагаются на разных дисках. Для чтения страйпа целиком инициируется операция параллельного чтения блоков со всех дисков системы. Когда все блоки прочитаны, из них собирается страйп, и операция чтения страйпа считается завершенной. При этом время чтения страйпа определяется временем чтения последнего блока.
Таким образом, деградация производительности одного диска влечёт за собой деградацию производительности всей системы. Кроме того, замедление чтения с одного диска может быть вызвано такими факторами, как неудачное расположение головки, случайно увеличенная нагрузка на диск, исправляемые электроникой внутренние ошибки диска и масса других. Для решения данной проблемы имеется возможность не дожидаться завершения операции чтения с самых медленных дисков системы, а вычислить их значение по формуле (3). Впрочем, подобные вычисления будут полезны в рассматриваемой ситуации, только если они могут выполняться достаточно быстро.
Отметим, что в приведённых рассуждениях для нас важно, что номер отказавшего диска заведомо известен. С практической точки зрения это означает, что факт выхода из строя какого-либо диска обнаруживается системами аппаратного контроля, и нам нет необходимости устанавливать его номер. Задача обнаружения «скрытой» потери данных, т.е. искажения данных на дисках, которые система считает работоспособными, в данном материале нами не рассматривалась.
Стоит отметить, что в используемый выше термин «умножение» мы вкладывал особый смысл, отличный от умножения чисел, к которому мы привыкли со школы. Классическое понимание здесь не применимо, т.к. при перемножении двух чисел размерности n бит в результате мы получим размерность 2 бит. Следовательно, с каждым последующим умножением размер значения контрольный суммы будет увеличиваться, а нам требуется, чтобы размер всех блоков страйпа был одинаковым.
Далее рассмотрим, какие операции используются в практических расчетах, в чем их сложность и как их можно оптимизировать.
Арифметические операции в конечных полях
Для детальной оценки трудоёмкости и снижения сложности вычислений в технологии RAID-6 необходимо более подробно рассмотреть вычисления в конечных полях.
Мы остановимся на полях вида , состоящих из элементов. Следуя (Лидл & Нидеррайтер, 1988), представим элементы поля как многочлены с двоичными коэффициентами степени не выше . Такие многочлены удобно записывать в виде машинных слов разрядности . Будем их записывать в шестнадцатеричной системе счисления, например:
$$display$$x^7+x^5+x^2+1→10100101→A5 \\ x^5+x^3+1→101001→29$$display$$
Известно, что для любого n поле получается путём факторизации кольца многочленов над GF(2) по модулю неприводимого многочлена степени . Назовем такой многочлен порождающим. Таким образом, сложение в поле можно выполнять как операцию сложения многочленов, а умножение — как операцию умножения многочленов по модулю порождающего многочлена. Т.е. результат умножения двух многочленов делится на порождающий многочлен и остаток от этого деления и оказывается конечным результатом умножения двух элементов поля .
Обширный список неприводимых многочленов приведён в (Seroussi, 1998). Например, в качестве порождающего многочлена для поля может быть выбран многочлен 171: .
Операция сложения в выполняется одинаково и не зависит от выбора порождающего многочлена, поскольку степень суммы не может превышать наибольшую из степеней слагаемых. Например:
В случае, когда степень порождающего многочлена не превышает разрядности машинного слова, операция сложения элементов поля выполняется за одну машинную команду поразрядного исключающего «или».
Операция умножения выполняется в два этапа: элементы поля умножаются как многочлены, а затем находится остаток от деления этого произведения на порождающий многочлен. Например:
При этом в пересчёте на элементарные машинные операции необходимо произвести до 2(n-1) сложений в зависимости от значения сомножителей. Именно в этой «зависимости» и состоит существенный резерв повышения производительности вычислений. Например, если выбрать
, то вычисление сумм вида можно производить по схеме Горнера:
т. е. в качестве сомножителя в операции умножения при вычислении синдромов P и Q можно зафиксировать многочлен . Умножение на многочлен сводится к операции сдвига на один разряд влево и сложения результата с модулем, если при сдвиге произошёл перенос. Например:
С учётом выбора формулы (2), (3) могут быть переписаны в следующем виде:
Вычисление синдромов
Восстановление двух утраченных дисков данных
$$display$$\left\{ \begin{aligned} D_α &= \bar{P}_{α,β} — D_β \\ D_β & = \frac {\bar{P}_{α,β} — \bar{Q}_{α,β}x^{α-N+1}}{1 — x^{α-β}} \end{aligned} ,α≠β \right. \qquad (3′)$$display$$
Важно отметить, что при расчете контрольных сумм использовались только операции умножения на и сложения. А при восстановлении данных к этим операциям также добавилось несколько результатов умножения на константы, которые являются элементами поля. Операцию умножения двух произвольных элементов поля, которыми являются многочлены степени меньше , можно переписать в следующем виде:
Отсюда следует, что и при восстановлении данных нам достаточно уметь складывать и умножать на . Эти операции следует осуществлять с максимальной скоростью.
Векторизация вычислений
Тот факт, что для всех блоков данных и кодовых слов в этих блоках мы выполняем одинаковые действия, позволяет применять различные алгоритмы векторизации вычислений, используя такие расширения процессора Intel, как SSE, AVX, AVX2, AVX512. Суть такого подхода состоит в том, что мы загружаем в специальные векторные регистры процессора сразу несколько кодовых слов. Например, при использовании SSE с размером векторного регистра в 128 бит в одном регистре можно разместить 16 элементов поля . Если же процессор поддерживает AVX512, то 64 элемента.
Рис. 3. Расположения данных в векторных регистрах
Такая идея расположения данных в векторных регистрах при вычислении используется в библиотеках ISA-L (Intel) и Jerasure (James Plank). Эти библиотеки помехоустойчивого кодирования очень популярны благодаря широкому функционалу и серьезным оптимизациям. Умножение элементов поля в этих библиотеках использует инструкцию SHUFFLE и вспомогательные предрассчитанные «таблицы умножения». Более подробное описание библиотек можно найти на сайтах Intel и Jerasure.
Когда речь идет о векторизации вычислений, то основным «искусством» разработчика является размещение данных в регистрах. Именно здесь человек пока побеждает компиляторы.
Одно из основных преимуществ RAIDIX состоит в оригинальном подходе, который позволил увеличить скорость кодирования и декодирования данных более чем в два раза по сравнению с другими, уже «разогнанными» векторизацией, библиотеками. Данный подход в «Рэйдикс» называют «побитовым параллелизмом». У компании, кстати, есть патент на соответствующий метод расчета и реализации алгоритма.
В RAIDIX был применен иной подход к векторизации. Суть подхода следующая: мысленно разместим векторные регистры вертикально; считаем с блоков данных 8 значений, равных размеру регистра; используя SSE, получим 8*16 байт, при AVX – 8*32 байт.
Рис. 4. Вертикальное размещение регистров
В рамках данной концепции мы разместили в регистрах столько элементов поля, сколько бит в одном векторном регистре. Умножение на всех элементов сразу выполняется за счет трех операций XOR и перестановки (переобозначения) этих 8 регистров. Другими словами, мы можем выполнить умножение сразу 128 или 256 элементов поля на х, используя всего несколько простых инструкций!
Рис. 5. Схема векторного умножения на X
Эта процедура повторяется для каждого умножения на и используется при умножении на константы. Таком подход позволяет выполнять кодирование и декодирование с высочайшей скоростью.
Мы произвели сравнение алгоритмов RAIDIX с наиболее популярными библиотеками помехоустойчивого кодирования ISA-l и Jerasure. Сравнение касалось только скорости работы алгоритма кодирования или декодирования — без учета получения данных с дисков. Сравнение производилось на системе со следующей конфигурацией:
- OC: Debian 8
- CPU: Intel Core i7-2600 3.40GHz
- RAM: 8GB
- Компилятор gcc 4.8
На рис. 6 показано сравнение скорости кодирования и декодирования данных в RAID-6 на одно вычислительное ядро. Алгоритм RAIDIX обозначен как “rdx”. Приведено аналогичное сравнение для алгоритмов RAID с тремя контрольными суммами (RAID-7.3).
Рис. 6. Сравнение скорости кодирования и декодирования в RAID 6
Рис. 7. Сравнение скорости кодирования и декодирования в RAID 7.3
В отличие от ISA-L и Jerasure, некоторые части которых реализованы на Ассемблере, библиотека RAIDIX полностью написана на С, что позволяет легко переносить код «Рэйдикс» на новые или «экзотические» типы архитектуры.
Еще раз отметим, что достигнутые цифры относятся к одному ядру. Библиотека прекрасно параллелизуется, и скорость растет почти линейно в многоядерных и многосоккетных системах.
Такая реализация операций кодирования и декодирования позволяет RAID-системам обеспечивать производительность реконструкции и записи/чтения в режиме отказа на уровне нескольких десятков гигабайт в секунду.
Так, в качестве базового типа данных при векторизации, как правило, используется __m128i (SSE) или __m256i (AVX). Поскольку алгоритм использует лишь простые операции XOR, то, заменив базовый тип на __m512i (AVX512), инженеры «Рэйдикс» смогли быстро пересобрать, запустить и протестировать алгоритмы на современных многоядерных процессорах Intel Xeon Phi. С другой стороны, при использовании long long (64 бита, стандартный тип С) в качестве базового типа алгоритмы «Рэйдикс» успешно запускаются на российских процессорах «Эльбрус».
Литература
- Anvin, H. P. (21 May 2009 г.). The mathematics of RAID-6. Получено 18 Nov 2009 г., из The Linux Kernel Archives: ftp.kernel.org/pub/linux/kernel/people/hpa/raid6.pdf
- Chen, P. M., Lee, E. K., Gibson, G. A., Katz, R. H., & Patterson, D. A. (1993). RAID: High-Performance, Reliable Secondary Storage. Technical Report No. UCB/CSD-93-778. Berkeley: EECS Department, University of California.
- Intel. (1996-1999). Iometer User’s Guide, Version 2003.12.16. Получено 2012, из Iometer project: iometer.svn.sourceforge.net/viewvc/iometer/trunk/IOmeter/Docs/Iometer.pdf?revision=HEAD
- Intel. (2012). The Intel 64 and IA-32 Architectures Software Developer’s Manual. Vol 1, 2a, 2b, 2c, 3a, 3b, 3c.
- Seroussi, G. (1998). Table of Low-Weight Binary Irreducible Polynomials. Hewlett Packard Computer System Laboratory, HPL-98-135.
habr.com
Raid (рейд) 10: описание, как сделать
Приветствую всех, уважаемые читатели блога Pc-information-guide.ru! Ранее, я уже публиковал статью о видах raid массивов, очень рекомендую почитать. Там я только вкратце рассказал о том, что такое рейд массив десятого уровня, или «1+0» — как его еще называют. В этой статье будет подробный рассказ о всех преимуществах и недостатках такого вида Raid массива, а также о его сравнении с пятым рейдом.
Как известно, Raid 10 вобрал в себя все хорошее из Raid 0 и Raid 1: увеличенную скорость доступа и повышенную надежность данных — соответственно. Рейд 10 представляет собой некую «полоску» зеркал, состоящих из пар жестких дисков, объединенных в рейд первого уровня. Иными словами, диски вложенного массива соединены парами в «зеркальный» рейд первого уровня, а эти вложенные массивы, в свою очередь — трансформируются в общий массив нулевого уровня, используя чередование данных.
Описание особенностей массива raid 10 сводится к следующему:
- если любой один диск из вложенных массивов raid 1 поломается — потери данных не произойдет. То есть, если «внутри» десятого raid находится всего четыре диска, что являет собой минимально допустимое количество, тогда возможен безболезненный выход из строя аж двух дисков одновременно;
- следующая особенность (скорее недостаток) — невозможность замены поврежденных накопителей, если конечно массив не оснащен технологией «hot spare»;
- если ориентироваться на высказывания производителей устройств и многочисленные тесты, то получается, что именно raid «1+0» обеспечивает наилучшую пропускную способность по сравнению с другими видами, кроме нулевого raid, конечно же.
Количество дисков
Отвечая на вопрос — сколько же дисков требуется для рейд 10, скажу, что для такого массива необходимо четное их количество. Причем, минимально допустимое количество винчестеров составляет 4, а максимальное 16. Также, бытует мнение, что raid «1+0» (он же 10) и «0+1» чем-то различаются. Это правда, но различие состоит только в последовательности соединения массивов.
Последняя цифра обозначает тип массива самого верхнего уровня. Например, raid «0+1» обозначает некую зеркальную систему полос, внутри которой два нулевых рейда (общее количество: 4 жестких диска) объединяются в один рейд 1 — это как пример, «нулевых» рейд массивов тут может быть и больше. Причем, снаружи визуально эти два подвида рейд 10 ничем не отличаются. И чисто теоретически они имеют равную степень устойчивости к сбоям.
На практике же, большинство производителей сейчас используют Raid 1+0 вместо Raid 0+1, объясняя это большей устойчивостью первого варианта к ошибкам и сбоям.
Столько дисков может поломаться и потери данных не произойдет
Повторюсь, главным недостатком raid 10 остается — необходимость включения в массив дисков «горячего резерва». Расчет примерно следующий: на 5 рабочих накопителей должен быть один резервный. Теперь пару слов про емкость дисков. Особенность емкости рейд 1 заключается в том, что вам всегда доступна лишь половина пространства винчестеров от их общего объема. В RAIDе 10 из 4 дисков общим объемом 4 Терабайта для записи будут доступны всего 2 Тб. Вообще, легко подсчитать доступный объем можно по формуле: F*G/2, F означает — количество дисков в массиве, а G — их емкость.
Сравнение raid 10 vs raid 5
Говоря о выборе между «десятым» raid и любым другим, на ум обычно приходит мысль о рейд 5. Raid 5 похож на первый по своему назначению, с той лишь разницей, что для него требуется минимум 3 накопителя. Причем один из них не будет доступен в качестве места для записи данных, на нем будет храниться лишь служебная информация.
Пятый рейд способен пережить выпадение (поломку) только одного жесткого, поломка второго повлечет за собой потерю всех данных. Однако, рейд пятого уровня — хороший и дешевый способ продлить жизнь накопителям и снизить вероятность их поломки. Для того, чтобы наше сравнение было эффективным и наглядным, попробую упорядочить преимущества и недостатки пятого рейда перед десятым:
- Емкость массива raid 5 равна общему объему дисков за вычетом объема одного диска. В то время как в рейд 10, по факту, доступна лишь половина объема накопителей.
- При операциях чтения/записи взаимодействие с потоками данных может вестись параллельно с нескольких дисков. Поэтому скорость записи или чтения возрастает, по сравнению с обычным жестким диском. Но, без хорошего рейд-контроллера скорость будет не сильно высокой.
- Производительность рейд 5 в операциях случайного чтения/записи блоков ниже на 10–25% в сравнении с десятым. При поломке одного из дисков в пятом рейде весь массив переходит в критический режим — все операции записи и чтения сопровождаются дополнительными манипуляциями, производительность при этом резко падает.
Итак, что же мы имеем в итоге: рейд 10 имеет лучшую отказоустойчивость и скорость, по сравнению с рейд 5. Однако, собрать такой массив из дисков будет по карману далеко не каждому. Рейд 5 — некое промежуточное решение между нулевым массивом и зеркалом (рейд 1). О том, как сделать raid 10 из четырех дисков будет рассказано чуть ниже, хотя я уже затрагивал «вскользь» эту тему в статье, ссылка на которую указана вверху. Конечно же, для этой цели лучше использовать аппаратный уровень — нужен специальный контроллер, но хорошее оборудование стоит дорого.
Так называемый «фейк рейд» (встроенный в материнскую плату) не отличается надежностью и быстротой, использовать не рекомендую. Лучше уж тогда организовать это все на программном уровне. Ну а сейчас, подробный пример создания массива на четырех дисках, используя рейд-контроллер. Для начала через BIOS выбираем соответствующую утилиту.
Затем, в меню утилиты выбираем пункт «инициализация драйверов».
Выделяем все наши диски.
Снова возвращаемся к главному меню утилиты и выбираем пункт «создать массив».
И на последнем шаге — указываем тип массива, его размер и другие параметры.
До скорых встреч на страницах блога pc-information-guide.ru
pc-information-guide.ru
RAID 0, RAID 1, RAID 5, RAID6, RAID 10 или что такое уровни RAID? — ISO27000.ru
В своей статье я попытаюсь охарактеризовать самые популярные уровни RAID, а затем сформулирую рекомендации по использованию этих уровней. Для иллюстрации статьи я построил диаграмму, на которой поместил эти уровни в трехмерном пространстве надежности, производительности и ценовой эффективности.
JBOD (Just a Bunch of Disks) – это простое объединение (spanning) жестких дисков, которое уровнем RAID формально не является. Томом JBOD может быть массив из одного диска или объединение нескольких дисков. Контроллеру RAID для работы с таким томом не требуется проведение каких-либо вычислений. На нашей диаграмме диск JBOD служит в качестве «ординара» или отправной точки – его значения надежности, производительности и стоимости совпадают с соответствующими показателями единичного жесткого диска.
RAID 0 (“Striping”) избыточности не имеет, а информацию распределяет сразу по всем входящим в массив дискам в виде небольших блоков («страйпов»). За счет этого существенно повышается производительность, но страдает надежность. Как и в случае JBOD, за свои деньги мы получаем 100% емкости диска.
Поясню, почему уменьшается надежность хранения данных на любом составном томе – так как при выходе из строя любого из входящих в него винчестеров полностью и безвозвратно пропадает вся информация. В соответствии с теорией вероятностей математически надежность тома RAID0 равна произведению надежностей составляющих его дисков, каждая из которых меньше единицы, поэтому совокупная надежность заведомо ниже надежности любого диска.
Хороший уровень – RAID 1 (“Mirroring”, «зеркало»). Он имеет защиту от выхода из строя половины имеющихся аппаратных средств (в общем случае – одного из двух жестких дисков), обеспечивает приемлемую скорость записи и выигрыш по скорости чтения за счет распараллеливания запросов. Недостаток заключается в том, что приходится выплачивать стоимость двух жестких дисков, получая полезный объем одного жесткого диска.
Изначально предполагается, что жесткий диск – вещь надежная. Соответственно, вероятность выхода из строя сразу двух дисков равна (по формуле) произведению вероятностей, т.е. ниже на порядки! К сожалению, реальная жизнь – не теория! Два винчестера берутся из одной партии и работают в одинаковых условиях, а при выходе из строя одного из дисков нагрузка на оставшийся увеличивается, поэтому на практике при выходе из строя одного из дисков следует срочно принимать меры – вновь восстанавливать избыточность. Для этого с любым уровнем RAID (кроме нулевого) рекомендуют использовать диски горячего резерва HotSpare. Достоинство такого подхода – поддержание постоянной надежности. Недостаток – еще большие издержки (т.е. стоимость 3-х винчестеров для хранения объема одного диска).
Зеркало на многих дисках – это уровень RAID 10. При использовании такого уровня зеркальные пары дисков выстраиваются в «цепочку», поэтому объем полученного тома может превосходить емкость одного жесткого диска. Достоинства и недостатки – такие же, как и у уровня RAID1. Как и в других случаях, рекомендуется включать в массив диски горячего резерва HotSpare из расчета один резервный на пять рабочих.
RAID 5, действительно, самый популярный из уровней – в первую очередь благодаря своей экономичности. Жертвуя ради избыточности емкостью всего одного диска из массива, мы получаем защиту от выхода из строя любого из винчестеров тома. На запись информации на том RAID5 тратятся дополнительные ресурсы, так как требуются дополнительные вычисления, зато при чтении (по сравнению с отдельным винчестером) имеется выигрыш, потому что потоки данных с нескольких накопителей массива распараллеливаются.
Недостатки RAID5 проявляются при выходе из строя одного из дисков – весь том переходит в критический режим, все операции записи и чтения сопровождаются дополнительными манипуляциями, резко падает производительность, диски начинают греться. Если срочно не принять меры – можно потерять весь том. Поэтому, (см. выше) с томом RAID5 следует обязательно использовать диск Hot Spare.
Помимо базовых уровней RAID0 — RAID5, описанных в стандарте, существуют комбинированные уровни RAID10, RAID30, RAID50, RAID15, которые различные производители интерпретируют каждый по-своему.
Суть таких комбинаций вкратце заключается в следующем. RAID10 – это сочетание единички и нолика (см. выше). RAID50 – это объединение по “0” томов 5-го уровня. RAID15 – «зеркало» «пятерок». И так далее.
Таким образом, комбинированные уровни наследуют преимущества (и недостатки) своих «родителей». Так, появление «нолика» в уровне RAID 50 нисколько не добавляет ему надежности, но зато положительно отражается на производительности. Уровень RAID 15, наверное, очень надежный, но он не самый быстрый и, к тому же, крайне неэкономичный (полезная емкость тома составляет меньше половины объема исходного дискового массива).
RAID 6 отличается от RAID 5 тем, что в каждом ряду данных (по-английски stripe) имеет не один, а два блока контрольных сумм. Контрольные суммы – «многомерные», т.е. независимые друг от друга, поэтому даже отказ двух дисков в массиве позволяет сохранить исходные данные. Вычисление контрольных сумм по методу Рида-Соломона требует более интенсивных по сравнению с RAID5 вычислений, поэтому раньше шестой уровень практически не использовался. Сейчас он поддерживается многими продуктами, так как в них стали устанавливать специализированные микросхемы, выполняющие все необходимые математические операции.
Согласно некоторым исследованиям, восстановление целостности после отказа одного диска на томе RAID5, составленном из дисков SATA большого объема (400 и 500 гигабайт), в 5% случаев заканчивается утратой данных. Другими словами, в одном случае из двадцати во время регенерации массива RAID5 на диск резерва Hot Spare возможен выход из строя второго диска… Отсюда рекомендации лучших RAIDоводов: 1) всегда делайте резервные копии; 2) используйте RAID6!
Недавно появились новые уровни RAID1E, RAID5E, RAID5EE. Буква “Е” в названии означает Enhanced.
RAID level-1 Enhanced (RAID level-1E) комбинирует mirroring и data striping. Эта смесь уровней 0 и 1 устроена следующим образом. Данные в ряду распределяются точь-в-точь так, как в RAID 0. То есть ряд данных не имеет никакой избыточности. Следующий ряд блоков данных копирует предыдущий со сдвигом на один блок. Таким образом как и в стандартном режиме RAID 1 каждый блок данных имеет зеркальную копию на одном из дисков, поэтому полезный объем массива равен половине суммарного объема входящих в массив жестких дисков. Для работы RAID 1E требуется объединение трех или более дисков.
Мне очень нравится уровень RAID1E. Для мощной графической рабочей станции или даже для домашнего компьютера – оптимальный выбор! Он обладает всеми достоинствами нулевого и первого уровней – отличная скорость и высокая надежность.
Перейдем теперь к уровню RAID level-5 Enhanced (RAID level-5E). Это то же самое что и RAID5, только со встроенным в массив резервным диском spare drive. Это встраивание производится следующим образом: на всех дисках массива оставляется свободным 1/N часть пространства, которая при отказе одного из дисков используется в качестве горячего резерва. За счет этого RAID5E демонстрирует наряду с надежностью лучшую производительность, так как чтение/запись производится параллельно с бОльшего числа накопителей одновременно и spare drive не простаивает, как в RAID5. Очевидно, что входящий в том резервный диск нельзя делить с другими томами (dedicated vs. shared). Том RAID 5E строится минимум на четырех физических дисках. Полезный объем логического тома вычисляется по формуле N-2.
RAID level-5E Enhanced (RAID level-5EE) подобен уровню RAID level-5E, но он имеет более эффективное распределение spare drive и, как следствие, – более быстрое время восстановления. Как и уровень RAID5E, этот уровень RAID распределяет в рядах блоки данных и контрольных сумм. Но он также распределяет и свободные блоки spare drive, а не просто оставляет под эти цели часть объема диска. Это позволяет уменьшить время, необходимое на реконструкцию целостности тома RAID5EE. Входящий в том резервный диск нельзя делить с другими томами – как и в предыдущем случае. Том RAID 5EE строится минимум на четырех физических дисках. Полезный объем логического тома вычисляется по формуле N-2.
Как ни странно, никаких упоминаний об уровне RAID 6E на просторах Интернета я не нашел — пока такой уровень никем из производителей не предлагается и даже не анонсируется. А ведь уровень RAID6E ( или RAID6EE? ) можно предложить по тому же принципу, что и предыдущий. Диск HotSpare обязательно должен сопровождать любой том RAID, в том числе и RAID 6. Конечно, мы не потеряем информацию при выходе из строя одного или двух дисков, но начать регенерацию целостности массива крайне важно как можно раньше, чтобы скорее вывести систему из «критического» режима. Поскольку необходимость диска Hot Spare для нас не подлежит сомнению, логичным было бы последовать дальше и «размазать» его по тому так, как это сделано в RAID 5EE, чтобы получить преимущества от использования бОльшего количества дисков (лучшая скорость на чтении-записи и более быстрое восстановление целостности).
В таблицу я собрал некоторые важные параметры почти всех уровней RАID, чтобы можно было сопоставить их между собой и четче понять их суть.
|
Уровень |
Избы- точ-ность |
Исполь-зование емкости дисков |
Произво-дитель-ность чтения |
Произво-дитель-ность записи |
Встроен-ный диск резерва |
Мин. кол-во дисков |
Макс. кол-во дисков |
|||||||
|
RAID 0 |
нет |
100% |
Отл |
Отл |
нет |
1 |
16 |
|||||||
|
RAID 1 |
+ |
50% |
Хор + |
Хор + |
нет |
2 |
2 |
|||||||
|
RAID 10 |
+ |
50% |
Хор + |
Хор + |
нет |
4 |
16 |
|||||||
|
RAID 1E |
+ |
50% |
Хор + |
Хор + |
нет |
3 |
16 |
|||||||
|
RAID 5 |
+ |
67-94% |
Отл |
Хор |
нет |
3 |
16 |
|||||||
|
RAID 5E |
+ |
50-88% |
Отл |
Хор |
+ |
4 |
16 |
|||||||
|
RAID 5EE |
+ |
50-88% |
Отл |
Хор |
+ |
4 |
16 |
|||||||
|
RAID 6 |
+ |
50-88% |
Отл |
Хор |
нет |
4 |
16 |
|||||||
|
RAID 00 |
нет |
100% |
Отл |
Отл |
нет |
2 |
60 |
|||||||
|
RAID 1E0 |
+ |
50% |
Хор + |
Хор + |
нет |
6 |
60 |
|||||||
|
RAID 50 |
+ |
67-94% |
Отл |
Хор |
нет |
6 |
60 |
|||||||
|
RAID 15 |
+ |
33-48% |
Отл |
Хор |
нет |
6 |
60 |
Давайте еще раз попробуем досконально разобраться, чем же различаются эти уровни?
RAID 1.
Это – классическое «зеркало». Два (и только два!) жестких диска работают как один, являясь полной копией друг друга. Выход из строя любого из этих двух дисков не приводит к потере ваших данных, так как контроллер продолжает работу с оставшимся диском. RAID1 в цифрах: двукратная избыточность, двукратная надежность, двукратная стоимость. Производительность на запись эквивалентна производительности одного жесткого диска. Производительность чтения выше, так как контроллер может распределять операции чтения между двумя дисками.
RAID 10.
Суть этого уровня в том, что диски массива объединяются парами в «зеркала» (RAID 1), а затем все эти зеркальные пары в свою очередь объединяются в общий массив с чередованием (RAID 0). Именно поэтому его иногда обозначают как RAID 1+0. Важный момент – в RAID 10 можно объединить только четное количество дисков (минимум – 4, максимум – 16). Достоинства: от «зеркала» наследуется надежность, от «нуля» – производительность как на чтение, так и на запись.
RAID 1Е.
Буква «E» в названии означает «Enhanced», т.е. «улучшенный». Принцип этого улучшения следующий: данные блоками «чередуются» («striped») на все диски массива, а потом еще раз «чередуются» со сдвигом на один диск. В RAID 1E можно объединять от трех до 16 дисков. Надежность соответствует показателям «десятки», а производительность за счет большего «чередования» становится чуть лучше.
RAID 1Е0.
Этот уровень реализуется так: мы создаем «нулевой» массив из массивов RAID1E. Следовательно, общее количество дисков должно быть кратно трем: минимум три и максимум – шестьдесят! Преимущество в скорости при этом мы вряд ли получим, а сложность реализации может неблагоприятно отразиться на надежности. Главное достоинство – возможность объединить в один массив очень большое (до 60) количество дисков.
Сходство всех уровней RAID 1X заключается в их показателях избыточности: ради реализации надежности жертвуется ровно 50% суммарной емкости дисков массива.
Андрей Егоров, начальник отдела по работе с корпоративными клиентами ЗАО «ТИМ», сертифицированный профессионал – MCSE, Master CNE, CIA, ICIS, etc.
www.iso27000.ru
Производительность mdadm raid 5,6,10 и ZFS zraid, zraid2, ZFS striped mirror / Habr
Тестируем производительность ZFS и mdadm+ext4 на SSD Sandisk CloudSpeedдля выбора технологии создания локального дискового массива.
Цель данного тестирования — выяснить, с какой реальной скоростью смогут работать виртуальные машины в raw файловых образах, если разместить их на 4-х производительных SSD-дисках. Тестирование будет производится в 32 потока, чтобы приблизительно создать условия работы реального гипервизора.
Другие наши публикации
Замеры будем производить при помощи инструмента fio.
Для mdadm+ext4 были выбраны опции —buffered=0 —direct=1. ZFS не умеет работать с этими опциями, поэтому ожидается, что результат ZFS будет несколько выше. Для сравнения я также отключу эти опции в одном из тестов и для варианта с mdadm.
Мы будем проводить тест с файлом размером в 10ГБ. Предположительно, что этого размера достаточно, чтобы оценить производительность файловой системы при выполнении рутинных операций. Разумеется, если увеличить объем тестовых данных, то общие цифры по всем тестам будут значительно ниже, так как мы сведем на нет все дополнительные средства кеширования и предсказания на файловых системах. Но такой цели нет. Нам нужны не сухие цифры синтетического тестирования, а что-то более приближенное к реальной жизни.
В качестве тестового стенда используем следующую конфигурацию:
Производитель:
Supermicro X9DRT-HF+
Процессоры:
2x Intel® Xeon® CPU E5-2690 0 @ 2.90GHz C2
Техпроцесс — 32 нм
Количество ядер — 8
Количество потоков — 16
Базовая частота процессора — 2,90 ГГц
Максимальная турбо частота — 3,80 ГГц
Кэш 20 МБ SmartCache
Скорость шины — 8 GT/s QPI
TDP — 135 Вт
Оперативная память:
16x 16384 MB
Тип: DDR3 Registered (Buffered)
Частота: 1333 MHz
Производитель: Micron
Дисковый контроллер:
LSI SAS 2008 RAID IT mode
Твердотельные диски:
4x 1.92Tb SSD Sandisk CloudSpeed ECO Gen. II
SSD, 2.5″, 1920 Гб, SATA-III, чтение: 530 Мб/сек, запись: 460 Мб/сек, MLC
Заявленный IOPS произвольного чтения/записи 76000/14000 IOPS
Время наработки на отказ 2000000 ч.
Ядро:
Linux 4.13.4-1-pve #1 SMP PVE 4.13.4-26 (Mon, 6 Nov 2017 11:23:55 +0100) x86_64
Версия ZFS:
v0.7.3-1
Планировщик IO:
cat /sys/block/sdb/queue/scheduler
[noop] deadline cfqТестовый инструмент:
fio-2.16
Параметры сборки массивов
# Параметры создания ZFS массива на одном диске
zpool create -f -o ashift=12 /dev/sdb# Параметры создания zraid (raid5 аналога на ZFS)
zpool create -f -o ashift=12 test raidz /dev/sdb /dev/sdc /dev/sdd /dev/sde# Параметры создания zraid2 (raid6 аналога на ZFS)
zpool create -f -o ashift=12 test raidz2 /dev/sdb /dev/sdc /dev/sdd /dev/sde# Параметры создания striped mirror (raid10 аналога на ZFS)
zpool create -f -o ashift=12 test mirror sdb sdc mirror sdd sde# Общие параметры для ZFS массивов
ZFS set atime=off test
ZFS set compression=off test
ZFS set dedup=off test
ZFS set primarycache=all testПод arc выделено 1/4 всей памяти или 52 ГБ
cat /etc/modprobe.d/ZFS.conf
options ZFS zfs_arc_max=55834574848# Параметры создания массива mdadm raid5
mdadm --zero-superblock /dev/sd[bcde]
mdadm --create --verbose --force --assume-clean --bitmap=internal --bitmap-chunk=131072 /dev/md0 --level=5 --raid-devices=4 /dev/sd[bcde]# Параметры создания массива mdadm raid6
mdadm --zero-superblock /dev/sd[bcde]
mdadm --create --verbose --force --assume-clean --bitmap=internal --bitmap-chunk=131072 /dev/md0 --level=6 --raid-devices=4 /dev/sd[bcde]# Общие параметры для mdadm 5/6 массивов
echo 32768 > /sys/block/md0/md/stripe_cache_size
blockdev --setra 65536 /dev/md0
echo 600000 > /proc/sys/dev/raid/speed_limit_max
echo 600000 > /proc/sys/dev/raid/speed_limit_min# Параметры создания массива mdadm raid10
mdadm --zero-superblock /dev/sd[bcde]
mdadm --create --verbose --force --assume-clean --bitmap=internal --bitmap-chunk=131072 /dev/md0 --level=10 --raid-devices=4 /dev/sd[bcde]# Параметры создания таблицы разметки GPT
parted -a optimal /dev/md0
mktable gpt
mkpart primary 0% 100%
q# Параметры создания ext4 файловой системы
mkfs.ext4 -m 0 -b 4096 -E stride=128,stripe-width=256 /dev/md0p1 (/dev/sdb)
Где stripe-width=256 для raid6 и raid10 и stripe-width=384 для raid5# Параметры монтирования ext4 файловой системы в fstab
UUID="xxxxx" /test ext4 defaults,noatime,lazytime 1 2Результаты
fio --directory=/test/ --name=read --rw=read --bs=4k --size=200G --numjobs=1 --time_based --runtime=60 --group_reporting --ioengine libaio --iodepth=32
# Для ext4 + параметры --buffered=0 --direct=1В тесте на чтение явно видно влияние буфера ARC на работу файловой системы ZFS. ZFS демонстрирует ровную и высокую скорость во всех тестах. Если выключить —buffered=0 —direct=1 скорость на mdadm raid10 + ext4 по ZFS оказывается в 3 раза медленнее и в 10 раз медленнее по части задержек и IOPS.
Наличие дополнительных дисков в zraid не дает существенного прироста скорости для ZFS. ZFS 0+1 — это так же медленно, как и zraid.
fio --directory=/ --name=test --rw=randread --bs=4k --size=10G --numjobs=1 --time_based --runtime=60 --group_reporting --ioengine libaio --iodepth=32 --buffered=0 --direct=1
# Для ext4 + параметры --buffered=0 --direct=1Вот тут ARC никак не спасает ZFS. Цифры наглядно показывают положение дел.
fio --directory=/ --name=test --rw=write --bs=4k --size=10G --numjobs=1 --group_reporting --ioengine libaio --iodepth=32 --buffered=0 --direct=1
# Для ext4 + параметры --buffered=0 --direct=1Опять же, буферы помогают ZFS давать ровный результат на всех массивах. mdadm raid6 явно пасует перед raid5 и raid10. Буферизированный и кэшированный mdadm raid10 дает вдвое лучший результат через все варианты на ZFS.
fio --directory=/ --name=test --rw=randwrite --bs=4k --size=10G --numjobs=1 --group_reporting --ioengine libaio --iodepth=32 --buffered=0 --direct=1
# Для ext4 + параметры --buffered=0 --direct=1Картина аналогичная и по случайному чтению. ZFS не помогают его буферы и кеши. Он сливает со страшной силой. Особенно пугает результат одиночного диска на ZFS и в целом результаты по ZFS отвратительные.
По mdadm raid5/6 все ожидаемо. Raid5 медленный, raid6 еще медленней, а raid10 примерно на 25-30 % быстрее одиночного диска. Raid10 с буферизацией уносит массив в космос.
Выводы
Как всем известно, ZFS не быстр.
Он содержит десятки других важных возможностей и достоинств, но это не отменяет того факта, что он существенно медленнее, чем mdadm+ext4, даже с учетом работы кешей и буферов, систем предсказаний и так далее. По этой части неожиданностей нет.
ZFS версий v0.7.x не стал существенно быстрее.
Возможно, быстрее чем v0.6.x, но далек до mdadm+ext4.
Можно найти информацию, что zraid/2 — это улучшенная версия raid5/6, но не по части производительности.
Использование zraid/2 или 0+1 не позволяет добиться более высокой скорости от массива, чем одиночный диск ZFS.
В лучшем случае, скорость будет не ниже или совсем немного выше. В худшем, наличие дополнительных дисков замедлит общую скорость работы. Raid для ZFS — это средство повышения надежности, но не производительности.
Наличие большого ARC не позволит компенсировать отставание ZFS по производительности относительно того же ext4.
Как вы можете увидеть, даже буфер размером в 50 ГБ не способен существенно помочь ZFS не отставать от младшего брата EXT4. Особенно на операциях случайной записи и чтения.
Использовать ли ZFS для виртуализации?
Каждый ответит сам. Лично я отказался от ZFS в пользу mdadm + raid10.
Спасибо Вам большое за внимание.
habr.com
Восстановление данных из поврежденного массива RAID 5 в NAS под управлением Linux / Habr
Обычный будний день в одной организации перестал быть обычным после того, как несколько десятков человек не смогли продолжать свою деятельность, так как замерли все привычные процессы. Прекратила свою работу CRM, перестала откликаться база менеджеров, аналогичная картина была с бухгалтерскими базами. На системного администратора обрушился шквал звонков пользователей с сообщениями о проблемах и требованиями срочного вмешательства. Системный администратор, который сравнительно недавно начал карьеру в этой компании, попытался подключиться к NAS и обнаружил, что устройство не откликается. После отключения питания и повторного включения NAS вернулся к жизни, но запуска виртуальных машин не произошло. Для пользователей оказалось доступным только общее хранилище файлов. Анализ проблем системным администратором показал, что один из двух RAID массивов не содержит томов и является чистым неразмеченным пространством. Какими были дальнейшие действия системного администратора, история умалчивает, но достаточно быстро он осознал, что у него нет четкого плана действий по восстановлению данных и рабочей среды компании. На данном этапе шесть накопителей на жестких магнитных дисках (2 HDD – 3 TB HDS5C3030ALA630, 4 HDD – 4 TB WD4000FYYZ-01UL1B1) из этого NAS поступают в наше распоряжение. В техническом задании нам предлагается «восстановить таблицу разделов».
Разумеется, при таких объемах дисков ни о какой классической таблице разделов не может идти и речи. Для безопасного проведения работ нам необходимо оценить состояние каждого из накопителей, чтобы выбрать оптимальные методики создания посекторных копий. Для этого анализируем показания SMART, также проверяем состояние БМГ посредством чтения небольших участков каждой из головок в зонах разной плотности. В нашем случае все накопители оказались исправными.
Для оптимизации времени выполнения работ создадим копии по 100 000 000 секторов от начала диска. Эти 50-гигабайтные образы нам потребуются для проведения анализа в то время, как будут создаваться посекторные копии накопителей (создание полных копий – обязательная страховка, хотя порой кажется не таким важным мероприятием, которое только задерживает процедуру восстановления данных).
Необходимо понять, каким образом NAS работает с дисками, и какие средства логической разметки используются. Для этого посмотрим в LBA 0 и 1 каждого из дисков.
рис. 2
На двух накопителях по 3ТБ по смещению 0x01C2 записан тип раздела 0xEE, берущий начало с LBA 0x00000001 и размер его 0xFFFFFFFF секторов. Данная запись является типичной защитной записью для накопителей, где используется GPT. Полагая, что использовалась GPT, оценим содержимое сектора 1, который в образе берет начало с 0x200. Регулярное выражение 0x45 0x46 0x49 0x20 0x50 0x41 0x52 0x54 (в текстовом виде: EFI PART) информирует нас о том, что перед нами заголовок GPT.
В секторе 2 обнаруживаем записи о разделах GPT
рис. 3
В первой записи описан раздел с 0x0000000000000022 сектора по 0x0000000000040021 сектор, который имеет GUID, не соответствующий стандарту. В нем содержится восклицание от разработчика, который в слегка сжатом виде вещает “Hah! I don’t Need EFI“. Метка тома “BIOS boot partition“.
Во второй записи описан раздел с 0x0000000000040022 сектора по 0x0000000000140021, идентификатор этого раздела A19D880F-05FC-4D3B-A006-743F0F84911E. Метка тома “Linux RAID”.
В третьей записи описана раздел с 0x0000000000140022сектора по 0x000000015D509B4D сектор, которые также имеет GUID A19D880F-05FC-4D3B-A006-743F0F84911E. Метка тома “Linux RAID”.
Исходя из размеров разделов, можно пренебречь первым и вторым, так как очевидно, что данные разделы созданы для нужд NAS. Третий раздел – это то, что нас на данные момент интересует. Согласно идентификатора имеет признак участника RAID массива, созданного средствами Linux. Исходя из этого, нам необходимо найти суперблок конфигурации RAID. Ожидаемое место его расположения через 8 секторов от начала раздела.
рис. 4
В нашем случае по смещению 0x0 обнаружено регулярное выражение 0xFC 0x4E 0x2B 0xA9, которое является маркером суперблока конфигурации RAID. По смещению 0x48 видим значение 0x00000001, что говорит о том, что в данном блоке описан массив RAID 1 (зеркало), значение 0x00000002 по смещению 0x5C сообщает нам, что в составе данного массива 2 участника. По смещению 0x80 сообщается, что область данных массива начнется через 0x00000800 (2048) секторов (отсчет ведется от начала раздела с суперблоком). По смещению 0x88 в QWORD прописано количество секторов 0x000000015D3C932C (5 859 218 220), которое на данном разделе принимает участие в RAID массиве.
Перейдя к области начала данных находим признак LVM
рис. 5
переходим к последней версии конфигурации.
рис. 6
В конфигурации видим, что на данном массиве один том, состоящий из одного сегмента, с именем «FILESHARE», который занимает практически всю емкость массива (количество экстентов*размер экстента=емкость в секторах 715 206*8 192=5 858 967 552. Проверив раздел, описанный в этом томе, обнаруживаем файловую систему Ext4, записи в которой явно свидетельствуют о соответствии имени раздела содержимому.
Анализируя содержимое второго накопителя емкостью 3ТБ, обнаруживаем наличие идентичных структур и полное соответствие в области данных для RAID 1, что подтверждает, что этот диск также был в составе данного массива. Зная, что файлообменник с именем FILESHARE был доступен пользователям, исключаем эти два диска из дальнейшего рассмотрения.
Переходим к анализу накопителей емкостью 4ТБ. Для этого рассмотрим содержимое нулевого сектора каждого из накопителей на предмет наличия защитной таблицы разделов.
рис. 7
Но вместо этого обнаруживаем некое мусорное содержимое, которое не может претендовать на звание таблицы разделов. Аналогичная картина с 1 по 33 секторы. Признаки таблицы разделов (защитной MBR) и GPT отсутствуют на всех дисках. При анализе RAID 1, описанном выше, мы получили информацию, какие области этот NAS отводит для служебных целей, на основании этого мы предполагаем, с какого смещения может начинаться раздел с областью, участвующей в другом массиве с пользовательскими данными.
Выполним поиск суперблоков конфигурации RAID (по регулярному выражению 0xFC 0x4E 0x2B 0xA9) на данных накопителях в окрестностях смещения 0x28000000. На каждом из дисков находится суперблок по смещению 0x28101000 (адрес несколько отличается от того, что на первой паре дисков, вероятно из-за того, что в данном случае было учтено, что данные 4ТБ диски с физическим сектором 4096 байт с эмуляцией 512 байтного сектора).
рис. 8
По смещению 0x48 значение 0x00000005 (RAID5)
По смещению 0x58 значение 0x00000400 (1024) – размер блока чередования 1024 сектора (512КБ)
По смещению 0x5C значение 0x00000003 – количество участников в массиве. Учитывая, что дисков с одинаковыми суперблоками 4, а, согласно записи, участвует 3 диска, можно сделать вывод, что одному из дисков отведена роль диска горячей замены (hot spare). Также уточняем, что данный массив был RAID 5E.
По смещению 0x80 значение 0x0000000000000800 (2048) – количество секторов от начала раздела до области, принимающей участие в массиве.
По смещению 0x88 значение 0x00000001D1ACAE8F (7 812 722 319) секторов – размер области, принимающей участие в массиве.
Если накопитель, задействованный в качестве диска горячей замены, не вступил в работу, и не была произведена операция rebuild, то его содержимое будет сильно отличаться от содержимого остальных трех дисков. В нашем случае при пролистывании дисков в hex редакторе легко обнаруживается практически пустой накопитель. Его также исключаем их рассмотрения.
Полагая, что суперблок конфигурации RAID находился по стандартному смещению от начала раздела, можем получить адрес начала раздела 0x28101000-0x1000=0x208100000. Соответственно, область начала данных с учетом содержимого по смещению:
0x208100000+(0x0000000000000800*0x200)=0x208200000.
Перейдя по данному смещению, видим, что на протяжении 1024 (0x800) секторов на каждом из дисков не обнаруживается ничего похожего на LVM либо какой-то иной вариант логической разметки. При выполнении теста корректности данных со смещения 0x208200000 посредством XOR операции над содержимым трех накопителей стабильно получаем 0, что свидетельствует о целостности RAID 5 и подтверждает, что ни один накопитель не был исключен из массива (и не была проведена операция Rebuild). Исходя из содержимого массива RAID 1 предположим, что и в массиве RAID 5 область 0x100000 в начале, которая на данный момент заполнена мусорными данными, предназначалась для размещения LVM.
Учитывая, что данный RAID является чередующимся массивом с блоком четности, то отступив на 0x100000 от начала массива, нам необходимо на каждом диске переместиться на позицию 0x208280000, предположительно с этого адреса начнется область данных в LVM. Проверим это предположение посредством анализа данных по этому смещению. Если это не том, используемый для свопа, то должны быть признаки либо какой-то логической разметки внутри раздела, описанного в LVM, либо признаки какой-либо файловой системы.
рис. 9
По характерному смещению 0x0400 на одном из дисков (согласно нумерации клиента – №2) обнаруживаем суперблок Ext4. В нем по смещению 0x04 DWORD – количество блоков в данной файловой системе, по смещению 0x18 в неявном виде указывается размер блока (для вычисления размера блока необходимо возвести 2 в степень (10+Х), где Х – значение по смещению 0x18). На основании этих значений выполним расчет размера раздела, с которым оперирует данная файловая система 0x00780000*0x1000=0x780000000 байт (30ГБ). Видим, что размер раздела существенно меньше емкости массива. Полагаем, что это лишь один из разделов, который был описан в LVM, и, исходя из смещения относительно начала массива, можем полагать, что он начинался с нулевого экстента.
Хоть и первичные предположения о расположении данных оказались верны, но для сборки массива мы не будем использовать информацию из суперблока конфигурации RAID, а проведем анализ данных внутри раздела и на основании этого установим параметры массива. Данный метод позволит нам подтвердить корректность параметров в суперблоке конфигурации RAID применительно к этому массиву или опровергнуть и установить правильные.
Для определения размера блока и параметров чередования блока четности удобно использовать монотонно возрастающие последовательности. На разделах Ext2, Ext 3, Ext 4 их можно найти в Group Descriptors (не во всех случаях). Возьмем удобную область для каждого из дисков:
рис. 10 (HDD 2)
рис. 11 (HDD 1)
рис. 12 (HDD 0)
Листая в hex редакторе c шагом 0x1000 каждый из дисков, заметим, что возрастание чисел по внутрисекторным смещениям 0x00, 0x04, 0x08 и т.д. идет на протяжении 1024 секторов или 0x80000 байт (справедливо только для блоков с данными, но не для блоков с результатами XOR операции), что достаточно явно подтверждает размер блока, описанный в суперблоке конфигурации RAID.
Глядя на рис. 10, рис. 11, рис. 12, легко определим роли дисков на данном месте и порядок их использования. Для построения полной матрицы будем пролистывать образы всех дисков с шагом 0x80000 и вписывать значения со смещений 0x00 в таблицу. Для заполнения таблицы использования дисков впишем названия дисков согласно возрастанию значений, вписанных нами в первую таблицу.
рис. 13
Согласно матрице использования дисков, проведем сбор массива RAID 5 с 0x28280000 в рамках первых 30 ГБ. Этот адрес был выбран, исходя из отсутствия LVM и того, что начало обнаруженного нами EXT4 раздела приходится на это смещение. В полученном образе мы сможем полностью проверить файловую систему и соответствие типов файлов, описанных в ней, фактически размещенным данным. В нашем случае эта проверка не выявила каких-либо недостатков, что подтверждает корректность всех предыдущих выводов. Теперь можно приступить к полному сбору массива.
Из-за отсутствия LVM нам предстоит процедура поиска разделов в собранном массиве. Для разделов, состоящих из одного сегмента, эта процедура не будет ничем отличаться от поиска разделов на обычном накопителе с очищенной таблицей разделов (MBR) или GPT. Все сведется к поиску признаков начала разделов различных файловых систем и таблиц разделов.
В случае же томов, которые принадлежали утерянной LVM, и состоящих из 2 и более фрагментов, потребуется дополнительный комплекс мероприятий:
– построение карты логических томов, состоящих из одного сегмента посредством записи диапазона секторов, занимаемых томом на разделе;
– построение карты разделов первых сегментов фрагментированных томов. Предстоит точно определить место обрыва раздела. Эта процедура намного проще, если известен точный размер экстента, используемого в утерянной LVM. Порядок размера экстента можно предположить, исходя из местоположения начала томов. К сожалению, данная методика не всегда применима.
Рис. 14
В пустых участках карты предстоит поиск сегментов, которые необходимо приращивать к первому сегменту какого-либо из фрагментированных томов. Следует обратить внимание, что таких фрагментов томов может быть достаточно много. Проверять корректность приращений можно посредством анализа файловых записей в файловой системе тома с сопоставлением фактическим данным.
Выполнив весь комплекс мероприятий, получим все образы логических томов, находившихся в RAID массиве.
Также обращаю внимание, что в данной публикации намеренно не упомянуты профессиональные комплексы для восстановления данных, которые позволяют упростить некоторые этапы работ.
Следующая публикация: Немного реверс-инжиниринга USB flash на контроллере SK6211
Предыдущая публикация: Восстановление файлов после трояна-шифровальщика
habr.com