
10 инструментов, позволяющих парсить информацию с веб-сайтов, включая цены конкурентов + правовая оценка для России
Инструменты web scraping (парсинг) разработаны для извлечения, сбора любой открытой информации с веб-сайтов. Эти ресурсы нужны тогда, когда необходимо быстро получить и сохранить в структурированном виде любые данные из интернета. Парсинг сайтов – это новый метод ввода данных, который не требует повторного ввода или копипастинга.
Такого рода программное обеспечение ищет информацию под контролем пользователя или автоматически, выбирая новые или обновленные данные и сохраняя их в таком виде, чтобы у пользователя был к ним быстрый доступ. Например, используя парсинг можно собрать информацию о продуктах и их стоимости на сайте Amazon. Ниже рассмотрим варианты использования веб-инструментов извлечения данных и десятку лучших сервисов, которые помогут собрать информацию, без необходимости написания специальных программных кодов. Инструменты парсинга могут применяться с разными целями и в различных сценариях, рассмотрим наиболее распространенные случаи использования, которые могут вам пригодиться. И дадим правовую оценку парсинга в России.
1. Сбор данных для исследования рынка
Веб-сервисы извлечения данных помогут следить за ситуацией в том направлении, куда будет стремиться компания или отрасль в следующие шесть месяцев, обеспечивая мощный фундамент для исследования рынка. Программное обеспечение парсинга способно получать данные от множества провайдеров, специализирующихся на аналитике данных и у фирм по исследованию рынка, и затем сводить эту информацию в одно место для референции и анализа.
2. Извлечение контактной информации
Инструменты парсинга можно использовать, чтобы собирать и систематизировать такие данные, как почтовые адреса, контактную информацию с различных сайтов и социальных сетей. Это позволяет составлять удобные списки контактов и всей сопутствующей информации для бизнеса – данные о клиентах, поставщиках или производителях.
3. Решения по загрузке с StackOverflow
С инструментами парсинга сайтов можно создавать решения для оффлайнового использования и хранения, собрав данные с большого количества веб-ресурсов (включая StackOverflow). Таким образом можно избежать зависимости от активных интернет соединений, так как данные будут доступны независимо от того, есть ли возможность подключиться к интернету.
4. Поиск работы или сотрудников
Для работодателя, который активно ищет кандидатов для работы в своей компании, или для соискателя, который ищет определенную должность, инструменты парсинга тоже станут незаменимы: с их помощью можно настроить выборку данных на основе различных прилагаемых фильтров и эффективно получать информацию, без рутинного ручного поиска.
5. Отслеживание цен в разных магазинах
Такие сервисы будут полезны и для тех, кто активно пользуется услугами онлайн-шоппинга, отслеживает цены на продукты, ищет вещи в нескольких магазинах сразу.
В обзор ниже не попал Российский сервис парсинга сайтов и последующего мониторинга цен XMLDATAFEED (xmldatafeed.com), который разработан в Санкт-Петербурге и в основном ориентирован на сбор цен с последующим анализом. Основная задача — создать систему поддержки принятия решений по управлению ценообразованием на основе открытых данных конкурентов. Из любопытного стоит выделить публикация данные по парсингу в реальном времени 🙂
10 лучших веб-инструментов для сбора данных:
Попробуем рассмотреть 10 лучших доступных инструментов парсинга. Некоторые из них бесплатные, некоторые дают возможность бесплатного ознакомления в течение ограниченного времени, некоторые предлагают разные тарифные планы.
1. Import.io
Import.io предлагает разработчику легко формировать собственные пакеты данных: нужно только импортировать информацию с определенной веб-страницы и экспортировать ее в CSV. Можно извлекать тысячи веб-страниц за считанные минуты, не написав ни строчки кода, и создавать тысячи API согласно вашим требованиям.
Для сбора огромных количеств нужной пользователю информации, сервис использует самые новые технологии, причем по низкой цене. Вместе с веб-инструментом доступны бесплатные приложения для Windows, Mac OS X и Linux для создания экстракторов данных и поисковых роботов, которые будут обеспечивать загрузку данных и синхронизацию с онлайновой учетной записью.
2. Webhose.io
Webhose.io обеспечивает прямой доступ в реальном времени к структурированным данным, полученным в результате парсинга тысяч онлайн источников. Этот парсер способен собирать веб-данные на более чем 240 языках и сохранять результаты в различных форматах, включая XML, JSON и RSS.
Webhose.io – это веб-приложение для браузера, использующее собственную технологию парсинга данных, которая позволяет обрабатывать огромные объемы информации из многочисленных источников с единственным API. Webhose предлагает бесплатный тарифный план за обработку 1000 запросов в месяц и 50 долларов за премиальный план, покрывающий 5000 запросов в месяц.
3. Dexi.io (ранее CloudScrape)
CloudScrape способен парсить информацию с любого веб-сайта и не требует загрузки дополнительных приложений, как и Webhose. Редактор самостоятельно устанавливает своих поисковых роботов и извлекает данные в режиме реального времени. Пользователь может сохранить собранные данные в облаке, например, Google Drive и Box.net, или экспортировать данные в форматах CSV или JSON.
CloudScrape также обеспечивает анонимный доступ к данным, предлагая ряд прокси-серверов, которые помогают скрыть идентификационные данные пользователя. CloudScrape хранит данные на своих серверах в течение 2 недель, затем их архивирует. Сервис предлагает 20 часов работы бесплатно, после чего он будет стоить 29 долларов в месяц.
4. Scrapinghub
Scrapinghub – это облачный инструмент парсинга данных, который помогает выбирать и собирать необходимые данные для любых целей. Scrapinghub использует Crawlera, умный прокси-ротатор, оснащенный механизмами, способными обходить защиты от ботов. Сервис способен справляться с огромными по объему информации и защищенными от роботов сайтами.
Scrapinghub преобразовывает веб-страницы в организованный контент. Команда специалистов обеспечивает индивидуальный подход к клиентам и обещает разработать решение для любого уникального случая. Базовый бесплатный пакет дает доступ к одному поисковому роботу (обработка до 1 Гб данных, далее — 9$ в месяц), премиальный пакет дает четырех параллельных поисковых ботов.
5. ParseHub
ParseHub может парсить один или много сайтов с поддержкой JavaScript, AJAX, сеансов, cookie и редиректов. Приложение использует технологию самообучения и способно распознать самые сложные документы в сети, затем генерирует выходной файл в том формате, который нужен пользователю.
ParseHub существует отдельно от веб-приложения в качестве программы рабочего стола для Windows, Mac OS X и Linux. Программа дает бесплатно пять пробных поисковых проектов. Тарифный план Премиум за 89 долларов предполагает 20 проектов и обработку 10 тысяч веб-страниц за проект.
6. VisualScraper
VisualScraper – это еще одно ПО для парсинга больших объемов информации из сети. VisualScraper извлекает данные с нескольких веб-страниц и синтезирует результаты в режиме реального времени. Кроме того, данные можно экспортировать в форматы CSV, XML, JSON и SQL.
Пользоваться и управлять веб-данными помогает простой интерфейс типа point and click. VisualScraper предлагает пакет с обработкой более 100 тысяч страниц с минимальной стоимостью 49 долларов в месяц. Есть бесплатное приложение, похожее на Parsehub, доступное для Windows с возможностью использования дополнительных платных функций.
7. Spinn3r
Spinn3r позволяет парсить данные из блогов, новостных лент, новостных каналов RSS и Atom, социальных сетей. Spinn3r имеет «обновляемый» API, который делает 95 процентов работы по индексации. Это предполагает усовершенствованную защиту от спама и повышенный уровень безопасности данных.
Spinn3r индексирует контент, как Google, и сохраняет извлеченные данные в файлах формата JSON. Инструмент постоянно сканирует сеть и находит обновления нужной информации из множества источников, пользователь всегда имеет обновляемую в реальном времени информацию. Консоль администрирования позволяет управлять процессом исследования; имеется полнотекстовый поиск.
8. 80legs
80legs – это мощный и гибкий веб-инструмент парсинга сайтов, который можно очень точно подстроить под потребности пользователя. Сервис справляется с поразительно огромными объемами данных и имеет функцию немедленного извлечения. Клиентами 80legs являются такие гиганты как MailChimp и PayPal.
Опция «Datafiniti» позволяет находить данные сверх-быстро. Благодаря ней, 80legs обеспечивает высокоэффективную поисковую сеть, которая выбирает необходимые данные за считанные секунды. Сервис предлагает бесплатный пакет – 10 тысяч ссылок за сессию, который можно обновить до пакета INTRO за 29 долларов в месяц – 100 тысяч URL за сессию.
9. Scraper
Scraper – это расширение для Chrome с ограниченными функциями парсинга данных, но оно полезно для онлайновых исследований и экспортирования данных в Google Spreadsheets. Этот инструмент предназначен и для новичков, и для экспертов, которые могут легко скопировать данные в буфер обмена или хранилище в виде электронных таблиц, используя OAuth.
Scraper – бесплатный инструмент, который работает прямо в браузере и автоматически генерирует XPaths для определения URL, которые нужно проверить. Сервис достаточно прост, в нем нет полной автоматизации или поисковых ботов, как у Import или Webhose, но это можно рассматривать как преимущество для новичков, поскольку его не придется долго настраивать, чтобы получить нужный результат.
10. OutWit Hub
OutWit Hub – это дополнение Firefox с десятками функций извлечения данных. Этот инструмент может автоматически просматривать страницы и хранить извлеченную информацию в подходящем для пользователя формате. OutWit Hub предлагает простой интерфейс для извлечения малых или больших объемов данных по необходимости.
OutWit позволяет «вытягивать» любые веб-страницы прямо из браузера и даже создавать в панели настроек автоматические агенты для извлечения данных и сохранения их в нужном формате. Это один из самых простых бесплатных веб-инструментов по сбору данных, не требующих специальных знаний в написании кодов.
Самое главное — правомерность парсинга?!
Вправе ли организация осуществлять автоматизированный сбор информации, размещенной в открытом доступе на сайтах в сети интернете (парсинг)?
В соответствии с действующим в Российской Федерации законодательством разрешено всё, что не запрещено законодательством. Парсинг является законным, в том случае, если при его осуществлении не происходит нарушений установленных законодательством запретов. Таким образом, при автоматизированном сборе информации необходимо соблюдать действующее законодательство. Законодательством Российской Федерации установлены следующие ограничения, имеющие отношение к сети интернет:
1. Не допускается нарушение Авторских и смежных прав.
2. Не допускается неправомерный доступ к охраняемой законом компьютерной информации.
3. Не допускается сбор сведений, составляющих коммерческую тайну, незаконным способом.
4. Не допускается заведомо недобросовестное осуществление гражданских прав (злоупотребление правом).
5. Не допускается использование гражданских прав в целях ограничения конкуренции.
Из вышеуказанных запретов следует, что организация вправе осуществлять автоматизированный сбор информации, размещенной в открытом доступе на сайтах в сети интернет если соблюдаются следующие условия:
1. Информация находится в открытом доступе и не защищается законодательством об авторских и смежных правах.
2. Автоматизированный сбор осуществляется законными способами.
3. Автоматизированный сбор информации не приводит к нарушению в работе сайтов в сети интернет.
4. Автоматизированный сбор информации не приводит к ограничению конкуренции.
При соблюдении установленных ограничений Парсинг является законным.
p.s. по правовому вопросу мы подготовили отдельную статью, где рассматривается Российский и зарубежный опыт.
Какой инструмент для извлечения данных Вам нравится больше всего? Какого рода данные вы хотели бы собрать? Расскажите в комментариях о своем опыте парсинга и свое видение процесса…
habr.com
Парсер сайтов в Excel 🚩 Программа для парсинга данных с сайтов
О программе «Парсер сайтов»

Программа «Парсер сайтов» разработана для сбора, анализа, выборки, группировки, структуризации, трансформации данных с последующим выводом данных в таблицу Excel в форматах xls* и csv.
Парсер создан на VBA (Visual Basic for Applications) и представлен в виде надстройки для MS Excel, по сути это набор макросов, каждый набор отвечает за выполнение определенных функций при обработке.
Для парсинга любого сайта пишется подпрограмма управления макросами (файл-настройка с расширением .xlp).
Таким образом, для работы программы необходимы: файл надстройки Parser.xla и файл управления надстройкой Name.xlp (Name — имя файла).
Видеообзор парсера
Какие задачи решает программа
- Парсинг товаров для интернет магазинов в таблицу для последующего экспорта данных. Связь по артикулам с прайсами поставщиков. Загрузка фото под нужными именами в папки на жесткий диск.
- Формирование баз контактов организаций: e-mail, телефонов, адресов, наименований.
- Сбор и вывод в таблицу коэффициентов и результатов спортивных событий для дальнейшего анализа. Отслеживание и поиск необходимых матчей по условиям.
- Парсинг файлов и папок на жестком диске, поиск по маске, смена имени, удаление, группировка.
- Загрузка файлов любых форматов из сети интернет на жесткий диск или в облачное хранилище: фотографии, музыка, документы.
- Запуск программы по расписанию: раз в час, неделю и т.д. Возможность зацикливания программы для отслеживания динамических данных на веб-ресурсах. При нужном совпадении данных есть возможность передачи их на e-mail или в Telegram.
- При помощи парсера возможен не только сбор, но и подстановка/передача данных через браузер (например, отправка сообщений, простановка лайков в соцсетях и многое другое).
- Парсинг с прохождением авторизации, передачей cookies и решением различных captcha.
- Многопоточная загрузка, одновременный парсинг нескольких источников.
Скачать демо-версию «Парсер сайтов»
Скачать пробную (TRIAL) версию программы (версия 3.4.13 от 31.03.2019). Пробная версия имеет полный функционал и ограничена 10 дневным тестовым периодом (нажмите на зеленый кубик).
Купить вечную лицензию можно тут
Скачать тестовую настройку программы для сайта relefopt.ru (нажмите на шестерню). Тестовая настройка предполагает частичную загрузку данных для демонстрации возможностей парсера.
Заказать под Ваш источник можно тут
Инструкция по первому запуску программы
Перед работой с программой ознакомьтесь с ответами на технические вопросы о версиях Windows, Excel, как включить макросы и прочее.
Запуск на примере тестовой настройки для парсинга сайта-поставщика https://relefopt.ru/ (для наглядного восприятия посмотрите видео):
Примечание: рассмотренный выше парсер загружает по одной позиции с каждой подкатегории сайта. Другие тестовые настройки можно найти в каталоге работ.
Создать техническое задание на настройку программы «Парсер сайтов» можно тут.
Преимущества работы с программой
- Широко масштабируемый постоянно обновляемый программный комплекс, позволяет решить самые разнообразные задачи.
- Настройка программы практически под любой веб-ресурс для получения необходимой информации с выводом нужных Вам данных в таблицу.
- Запуск парсера пользователем в любое время неограниченное количество раз для получения самой актуальной информации.
- Прямая работа с исполнителем для настройки программы.
- Наш опыт настройки программы более 3 лет, реализовано более 800 проектов.
- Выше перечисленное позволяет получить Вам необходимые данные в сжатые сроки по доступной цене.
Остались вопросы? Пишите, звоните Skype и e-mail, с удовольствием ответим.
parserok.ru
Лучшие бесплатные и платные инструменты для парсинга сайтов и товаров…
Приложения для парсинга сайтов автоматизируют сбор данных через интернет. Эти программы обычно попадают в категории инструментов, которые вы устанавливаете на своем компьютере или в браузере вашего компьютера (Chrome или Firefox), или сервисов, предназначенных для самостоятельной работы без помощи разработчиков. Веб-инструменты парсинга (бесплатные или платные) и веб-сайты/приложения для работы в режиме самообслуживания могут пригодиться, если ваши требования к данным невелики, а исходные веб-сайты несложны. Однако, если сайты, которые вы собираетесь парсить, являются сложными или вам нужно много данных с одного или нескольких сайтов, эти инструменты плохо масштабируются. Стоимость этих инструментов и сервисов меркнет по сравнению с затратами времени и усилий, которые требуются для внедрения парсеров с использованием этих инструментов, а также в сравнении со сложностью обслуживания и эксплуатации этих программ. Для таких случаев поставщик с полным циклом обслуживания — лучший и экономичный выбор. В этой статье мы сначала дадим краткое описание инструментов, а затем быстро рассмотрим, как эти инструменты работают, чтобы вы могли быстро оценить, подходят ли они для вас. Обратим ваше внимание на Российский сервис парсинга сайтов https://xmldatafeed.com, который отличается тем, что на ежедневной основе предоставляет итоги парсинга более чем 300 крупнейших сайтов (Интернет- магазинов). Данные можно получить на портале, после бесплатной регистрации.
Итак, обзор лучших инструментов для парсинга сайтов и Интернет-магазинов:
- Web Scraper (расширение Google Chrome)
- Scrapy
- Data Scraper (расширение Google Chrome)
- Scraper (расширение Google Chrome)
- ParseHub
- OutWitHub
- FMiner
- Dexi.io
- Octoparse
- Web Harvey
- PySpider
- Apify SDK
- Content Grabber
- Mozenda
- Cheerio
- Как парсить списки Amazon BestSeller с помощью расширения Web Scraper Chrome (на английском)
- Как собрать исторические данные из Twitter (на английском)
- Как собрать данные о товарах и ценах от Walmart (на английском)
Скачать примеры парсинга компаний
Scrapy — это фреймворк с открытым исходным кодом на Python, используемый для создания парсеров. Он предоставляет вам все инструменты, необходимые для эффективного извлечения данных с сайтов, обработки их в нужном вам виде и сохранения их в необходимых структуре и формате. Одним из его главных преимуществ является то, что он построен на основе асинхронной сетевой структуры Twisted. Если у вас большой проект по поиску в сети и вы хотите сделать его максимально эффективным и гибким, вам обязательно следует использовать Scrapy. Он также может быть использован для широкого спектра задач, от интеллектуального анализа данных до мониторинга и автоматического тестирования. Вы можете экспортировать данные в форматы JSON, CSV и XML. Отличительная черта Scrapy — это простота использования, подробная документация и активное сообщество. Если вы знакомы с Python, вы сможете начать работу всего за пару минут. Он работает в системах Linux, Mac OS и Windows. Чтобы узнать, как парсить сайты с помощью Scrapy, вы можете обратиться к нашему руководству: Как парсить данные продукта Alibaba с помощью ScrapyData Scraper — это простой инструмент для извлечения данных из Интернет- сайтов, который позволяет извлекать данные с одной страницы в файлы формата CSV и XSL. Это персональное расширение для браузера, которое помогает вам преобразовывать данные в чистый табличный формат. Вам нужно будет установить плагин в браузере Google Chrome. Бесплатная версия позволяет парсить 500 страниц в месяц, и, если вы работаете с большим объёмом данных, вам нужно будет перейти на платную подписку. Скачать расширение можно по ссылке здесь.Scraper — это расширение Chrome для парсинга простых веб-страниц. Он прост в использовании и поможет вам сканировать содержимое сайта и загружать результаты в Google Docs. Он может извлекать данные из таблиц и преобразовывать их в структурированный формат. Вы можете скачать расширение по ссылке здесь.ParseHub — это инструмент для парсинга сайтов и Интернет- магазинов, который предназначен для сканирования одного или нескольких веб-сайтов, которые используют JavaScript, AJAX, файлы cookie, сеансы и редиректы. Приложение может анализировать и получать данные с сайтов и преобразовывать их в структурированную информацию. Он использует технологию машинного обучения для распознавания самых сложных документов и создает выходной файл в формате JSON, CSV или Google Sheets. Parsehub — это приложения для персональных компьютеров, доступное для пользователей Windows, Mac и Linux, и работает как расширение Firefox. Удобное веб-приложение может быть встроено в браузер и имеет хорошо написанную документацию. Оно имеет все расширенные функции, такие как нумерация страниц, бесконечная прокрутка страниц, всплывающие окна и навигация. Вы даже можете визуализировать данные из ParseHub в Tableau. Бесплатная версия имеет ограничение в 5 проектов с 200 страницами за запуск. Если вы покупаете платную подписку, вы можете получить 20 личных проектов с 10 000 страниц на сканирование и ротацию IP.OutwitHub это парсер данных, встроенный в веб-браузер. Если вы хотите пользоваться им в виде расширения, то его можно установить из магазина расширений Firefox. Если же хотите использовать автономное приложение, вам просто нужно следовать инструкциям, запустив приложение. OutwitHub позволяет вам извлечь данные из интернета и совершенно не требует навыков программирования. Это отлично подходит для сбора данных, которые могут быть недоступны. OutwitHub — это бесплатный инструмент, который является отличным вариантом, если вам нужно быстро извлечь данные с сайта. Благодаря своим функциям автоматизации, он автоматически просматривает серию веб-страниц и выполняет задачи извлечения. Вы можете экспортировать данные в различные форматы (JSON, XLSX, SQL, HTML, CSV и т.д.).FMiner представляет собой визуальный инструмент для парсинга сайтов и Интернет-магазинов и захвата экрана при веб-серфинге. Интуитивно понятный пользовательский интерфейс позволяет быстро использовать мощный механизм интеллектуального анализа данных для извлечения данных с сайтов. В дополнение к основным функциям парсинга веб-страниц в нём также есть обработка AJAX/Javascript и решение CAPTCHA. Его можно запускать как в Windows, так и в MacOS, и он выполняет парсинг с помощью встроенного браузера. Предоставляется 15-дневная бесплатная версия, впоследствии вы можете выбрать платную подписку.Dexi (ранее известный как CloudScrape) поддерживает сбор данных с любого сайта и не требует загрузки дополнительных приложений. Приложение предоставляет различные типы роботов для парсинга данных — “краулеры”, они же поисковые роботы (от англ. crawlers), “экстракторы”, скрипты для извлечения данных из страниц (от англ. extractors), “автоботы” (от англ. autobots) и скрипты-“вытяжки” (от англ. pipes). Роботы-экстракторы являются наиболее продвинутыми, поскольку они позволяют вам выбирать каждое действие, которое робот должен выполнять — например, нажатие кнопок и извлечение скриншотов. Приложение предлагает анонимные прокси, чтобы скрыть вашу личность. Dexi.io также предлагает ряд интеграций со сторонними сервисами. Вы можете загрузить данные непосредственно в хранилища Google Drive и Box.net или экспортировать данные в формате JSON или CSV. Dexi.io хранит ваши данные на своих серверах в течение 2 недель перед их архивированием. Если вам необходимо извлечь большой объём данных, то вы всегда можете получить платную версию.Octoparse — это инструмент для визуального анализа, который легко понять. Его простой интерфейс позволяет выбрать указателем и кликом компьютерной “мышки” те поля, которые нужно извлечь с веб-сайта. Парсер может обрабатывать как статические, так и динамические веб-сайты, использующие AJAX, JavaScript, файлы cookie и т.д. Приложение также предлагает облачную платформу, позволяющую извлекать большие объемы данных. Вы можете экспортировать извлеченные данные в TXT, CSV, HTML или форматы Microsoft Excel (XLSX). Бесплатная версия позволяет вам создать до 10 поисковых роботов, но с платной подпиской вы получите больше функций, таких как API, а также множество анонимных IP-прокси, которые ускорят процесс извлечения и получения большого объема данных в режиме реального времени.Визуальный веб-парсер WebHarvey содержит в себе встроенный браузер, который позволяет “вытягивать” данные с веб-страниц. Его функция “укажи и кликни” позволяет пользователю просто выбрать необходимый контент, который программа извлечет и сохранит. Преимущество этого парсера в том, что вам не нужно писать какой-либо код. Данные могут быть сохранены в файлы CSV, JSON или XML, а также храниться в базе данных SQL. В WebHarvey есть многоуровневая функция сканирования категорий, которая может отслеживать ссылки на каждом уровне и извлекать данные со страниц списков. Инструмент позволяет использовать регулярные выражения, предлагая большую гибкость. Вы можете настроить прокси-серверы, которые помогут вам поддерживать уровень анонимности, скрывая ваш IP и извлекая данные с веб-сайтов.Веб-краулер PySpider — это поисковый робот, написанный на Python. Он поддерживает сайта с Javascript и имеет распределенную архитектуру. Это даёт вам возможность парсить сайт в несколько потоков. PySpider может хранить данные в выбранном вами серверном решении, таком как базы данных MongoDB, MySQL, Redis и т. д. Вы можете использовать RabbitMQ, Beanstalk и Redis в качестве накопителя сообщений. Одним из преимуществ PySpider является простой в использовании пользовательский интерфейс, где вы можете редактировать сценарии, отслеживать текущие задачи и просматривать результаты. Данные могут быть сохранены в форматах JSON и CSV. Если вы работаете с веб-интерфейсом, попробуйте PySpider как веб-парсер, он будет разумным решением. Он также поддерживает тяжёлые сайты с AJAX-технологией.Apify является библиотекой Node.js, которая во многом похожа на Scrapy, позиционирующая себя как универсальная библиотека для парсинга веб-страниц в JavaScript, с поддержкой Puppeteer, Cheerio и многих других. Благодаря таким уникальным функциям, как RequestQueue и AutoscaledPool, вы можете начать с нескольких URL-адресов, а затем рекурсивно переходить по ссылкам на другие страницы и запускать задачи парсинга с максимальной пропускной способностью системы. Доступные форматы данных: JSON, JSONL, CSV, XML,XLSX или HTML, доступен также и селектор CSS. Он поддерживает любой тип веб-сайта и имеет встроенную поддержку Puppeteer. Для SDK Apify требуется Node.js 8 или новее.Content Grabber — это инструмент для визуального просмотра веб-страниц, который имеет интерфейс с функцией “укажи и кликни”, позволяющей легко выбирать элементы. Его интерфейс допускает нумерацию страниц, бесконечную прокрутку страниц и всплывающие окна. Кроме того, он имеет обработку AJAX/Javascript, решение капчи, позволяет использовать регулярные выражения и ротацию IP (с Nohodo). Вы можете экспортировать данные в форматах CSV, XLSX, JSON и PDF. Для использования этого инструмента необходимы навыки программирования среднего уровня.Mozenda — это корпоративная “облачная” платформа для парсинга. Она включает функцию «укажи и кликни» и имеет дружественный интерфейс. Mozenda состоит из двух частей — приложения для создания проекта извлечения данных и веб-консоли для запуска агентов, организации результатов и экспорта данных. Они также предоставляют доступ к API для получения данных и имеют встроенные интеграции с системами хранения, такими как FTP, Amazon S3, Dropbox и другими. Вы можете экспортировать данные в форматы CSV, XML, JSON или XLSX. Mozenda хорош для обработки больших объемов данных. Вам необходимо обладать навыками программирования выше базовых, чтобы использовать этот инструмент, поскольку он имеет довольно высокую “кривую обучения”.Cheerio — это библиотека, которая анализирует документы HTML и XML и позволяет использовать синтаксис jQuery при работе с загруженными данными. Если вы пишете парсер на JavaScript, Cheerio — это отличное приложение, которое делает парсинг, управление и рендеринг эффективными. Cheerio не может: интерпретировать результат как веб-браузер, производить визуальный рендеринг, применять CSS-стили, загружать внешние ресурсы или выполнять JavaScript. Если вам требуется какая-либо из этих функций, вам следует рассмотреть такие проекты, как PhantomJS или JSDom.Краткий обзор того, как использовать эти инструменты парсинга:
После загрузки расширения webscraper в Сhrome вы найдете его в инструментах разработчика и увидите новую панель инструментов с названием «Web Scraper». Активируйте вкладку и нажмите Create new sitemap (англ. “Создать новую карту сайта”), а затем Create sitemap (англ. “Создать карту сайта”). Карта сайта — это имя расширения Web Scraper для парсера. Это последовательность правил парсинга данных путем перехода от одного извлечения данных к другому. Мы установим в качестве начальной страницы каталога мобильных телефонов на Amazon.com и нажмем Create sitemap. GIF иллюстрирует, как создать карту сайта: Переход от корневой папки к страницам категории В данный момент у нас в _root открыт инструмент Web Scraper с пустым списком дочерних селекторов. Нажмите “Add new selector” (англ. “Добавить новый селектор”). Мы добавим селектор, который перенесет нас с главной страницы на страницу каждой категории. Давайте дадим ему категорию id с типом ссылки. Мы хотим получить несколько ссылок из корня, поэтому отметим флажок «Multiple» (англ. “Множественный выбор”) ниже. Кнопка «Select» (“Выбрать”) предоставляет нам инструмент для визуального выбора элементов на странице для создания селектора CSS. «Element Preview» (англ. “Предварительный просмотр элемента”) выделяет элементы на странице, а «Data Preview» (англ. “Предварительный просмотр данных”) — выборку данных, которые будут извлечены указанным селектором. Нажмите «Select» (“Выбрать”) на одной из ссылок категории, и конкретный селектор CSS будет заполнен слева от инструмента выбора. Нажмите на одну из других (не выбранных) ссылок — и CSS-селектор откорректирован. Продолжайте нажимать на оставшиеся ссылки, пока все они не будут выбраны. GIF ниже показывает весь процесс добавления селектора в карту сайта:
В данный момент у нас в _root открыт инструмент Web Scraper с пустым списком дочерних селекторов. Нажмите “Add new selector” (англ. “Добавить новый селектор”). Мы добавим селектор, который перенесет нас с главной страницы на страницу каждой категории. Давайте дадим ему категорию id с типом ссылки. Мы хотим получить несколько ссылок из корня, поэтому отметим флажок «Multiple» (англ. “Множественный выбор”) ниже. Кнопка «Select» (“Выбрать”) предоставляет нам инструмент для визуального выбора элементов на странице для создания селектора CSS. «Element Preview» (англ. “Предварительный просмотр элемента”) выделяет элементы на странице, а «Data Preview» (англ. “Предварительный просмотр данных”) — выборку данных, которые будут извлечены указанным селектором. Нажмите «Select» (“Выбрать”) на одной из ссылок категории, и конкретный селектор CSS будет заполнен слева от инструмента выбора. Нажмите на одну из других (не выбранных) ссылок — и CSS-селектор откорректирован. Продолжайте нажимать на оставшиеся ссылки, пока все они не будут выбраны. GIF ниже показывает весь процесс добавления селектора в карту сайта: 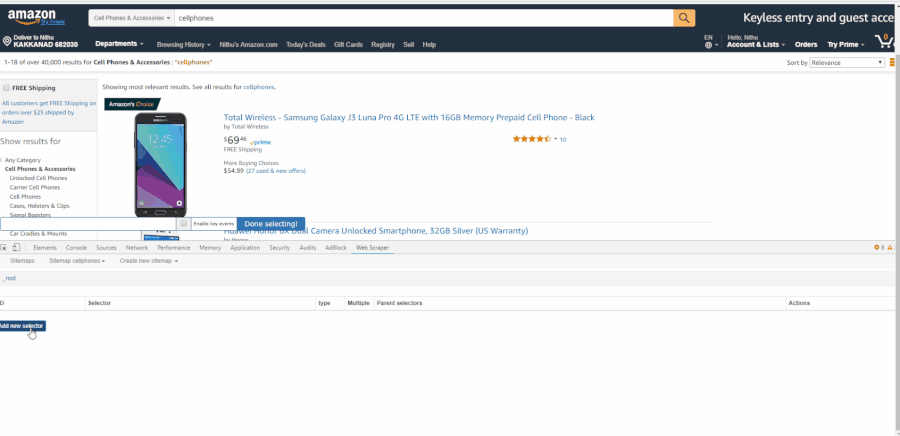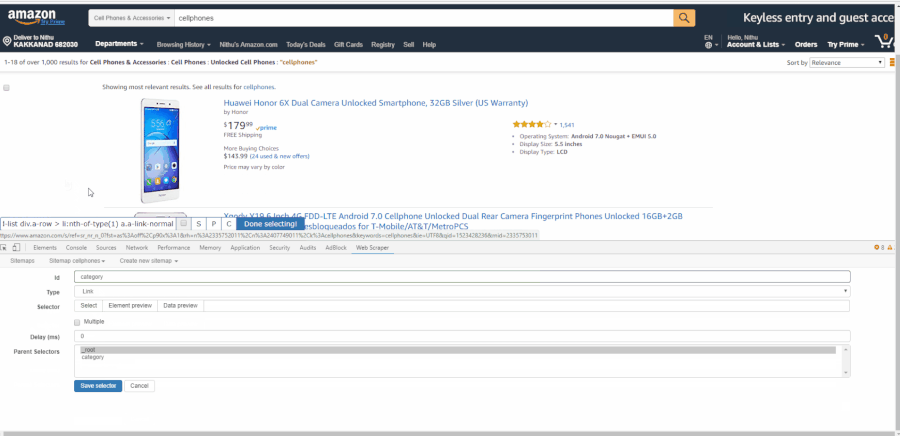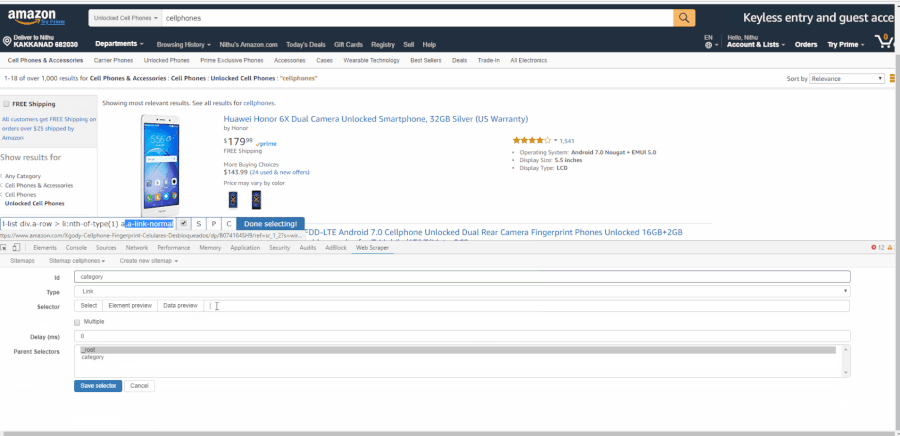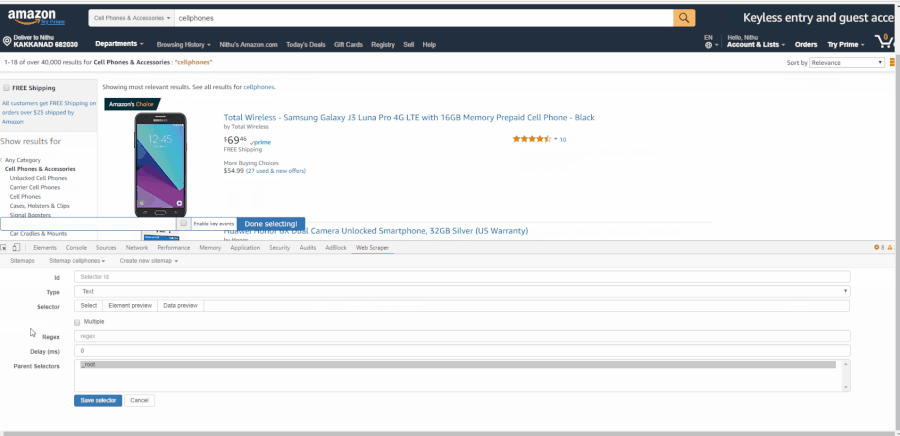 Граф селектора состоит из набора селекторов — контента для извлечения, элементов на странице и ссылки для отслеживания и продолжения просмотра. У каждого селектора есть корень (родительский селектор), определяющий контекст, в котором этот селектор должен быть применен. Вот визуальное представление окончательного парсера (граф селектора) для нашего парсера по категориям мобильных телефонов на Amazon:
Граф селектора состоит из набора селекторов — контента для извлечения, элементов на странице и ссылки для отслеживания и продолжения просмотра. У каждого селектора есть корень (родительский селектор), определяющий контекст, в котором этот селектор должен быть применен. Вот визуальное представление окончательного парсера (граф селектора) для нашего парсера по категориям мобильных телефонов на Amazon:  Здесь корнем представляется начальный URL, главную страницу с категориями мобильных телефонов на Amazon. Оттуда парсер получает ссылку на каждую страницу категории и для каждой категории извлекает набор элементов продукта. Каждый элемент продукта извлекает одно имя, один отзыв, один рейтинг и одну цену. Поскольку существует несколько страниц, нам нужен следующий элемент для парсера, чтобы перейти на каждую доступную страницу. Запуск парсера Нажмите Sitemap, чтобы открыть выпадающее меню, и нажмите Scrape. Панель парсинга предоставляет несколько вариантов того, как медленно Web Scraper должен выполнять парсинг, чтобы избежать перегрузки веб-сервера запросами и дать веб-браузеру время для загрузки страниц. Нас устраивают настройки по умолчанию, поэтому нажимаем «Start scraping». Появится окно, в котором парсер просматривает данные. После сканирования данных вы можете загрузить их, нажав опцию «Экспортировать данные в формате CSV» или сохранить их в базе данных.Мы покажем вам, как извлечь данные из Amazon.com с помощью расширения Data Scraper Chrome. Сначала скачайте расширение по ссылке здесь Откройте веб-сайт, с которого нужно извлечь данные. Мы рассмотрим информацию о кондиционерах в категории “Устройства” на Amazon.com. Щелкните правой кнопкой мыши на веб-страницу и выберите параметр “Get Similar (Data Miner)” (от англ. “Получить похожие (Извлечение данных”). Вы увидите список сохраненных шаблонов на левой стороне экрана. Вы можете выбрать любой из них или создать свой собственный шаблон и запустить его. Чтобы создать свой собственный шаблон, нажмите “New Recipe” (от англ. “Новый рецепт”) или выберите один из общих шаблонов под опцией «Public» (англ. “Общедоступные”). Data Scraper удобен для пользователя, так как покажет вам, как создать собственный шаблон шаг за шагом. Вы получите вывод данных в виде таблицы: Затем нажмите на кнопку загрузки и извлеките данные в формате CSV / XSL.
Здесь корнем представляется начальный URL, главную страницу с категориями мобильных телефонов на Amazon. Оттуда парсер получает ссылку на каждую страницу категории и для каждой категории извлекает набор элементов продукта. Каждый элемент продукта извлекает одно имя, один отзыв, один рейтинг и одну цену. Поскольку существует несколько страниц, нам нужен следующий элемент для парсера, чтобы перейти на каждую доступную страницу. Запуск парсера Нажмите Sitemap, чтобы открыть выпадающее меню, и нажмите Scrape. Панель парсинга предоставляет несколько вариантов того, как медленно Web Scraper должен выполнять парсинг, чтобы избежать перегрузки веб-сервера запросами и дать веб-браузеру время для загрузки страниц. Нас устраивают настройки по умолчанию, поэтому нажимаем «Start scraping». Появится окно, в котором парсер просматривает данные. После сканирования данных вы можете загрузить их, нажав опцию «Экспортировать данные в формате CSV» или сохранить их в базе данных.Мы покажем вам, как извлечь данные из Amazon.com с помощью расширения Data Scraper Chrome. Сначала скачайте расширение по ссылке здесь Откройте веб-сайт, с которого нужно извлечь данные. Мы рассмотрим информацию о кондиционерах в категории “Устройства” на Amazon.com. Щелкните правой кнопкой мыши на веб-страницу и выберите параметр “Get Similar (Data Miner)” (от англ. “Получить похожие (Извлечение данных”). Вы увидите список сохраненных шаблонов на левой стороне экрана. Вы можете выбрать любой из них или создать свой собственный шаблон и запустить его. Чтобы создать свой собственный шаблон, нажмите “New Recipe” (от англ. “Новый рецепт”) или выберите один из общих шаблонов под опцией «Public» (англ. “Общедоступные”). Data Scraper удобен для пользователя, так как покажет вам, как создать собственный шаблон шаг за шагом. Вы получите вывод данных в виде таблицы: Затем нажмите на кнопку загрузки и извлеките данные в формате CSV / XSL.- Расширение Scraper для Chrome
Итоги:
Несмотря на то, что эти инструменты для парсинга с легкостью извлекают данные из веб-страниц, они имеют свои ограничения. В конечном счете, программирование — это лучший способ парсинга данных из Интернета, поскольку оно обеспечивает большую гибкость и дает лучшие результаты. Если вы не разбираетесь в программировании, или ваши потребности сложны, или вам нужно собрать большие объемы данных, есть отличные сервисы парсинга, которые будут соответствовать вашим требованиям, чтобы облегчить вам работу. Вместо этого вы можете сэкономить время и получить чистые структурированные данные, обратившись к нам — мы являемся поставщиком полного спектра услуг, который не требует использования каких-либо инструментов, и все, что вы получаете, — это чистые данные без каких-либо хлопот.xmldatafeed.com
Вся правда про парсинг поставщиков и конкурентов или что такое парсер товаров
Вся правда про парсинг поставщиков и конкурентов или что такое парсер товаров
Погружение в данную тему требует динамика нашего времени — изменение цены — наиболее весомый фактор возложить кропотливую работу на парсер товаров.
Существует множество парсеров, обещающих моментальные результаты, но когда начинаешь пробовать спарсить из нового источника — могут возникнуть, кажущиеся непреодолимыми — препятствия.
В данной статье мы рассмотрим процесс парсинга и понимание процесса определит на что обратить внимание перед покупкой парсера.
Классический процесс парсинга товаров состоит из двух этапов:
1. парсинг ссылок на товары (чтобы спарсить информацию о товаре — надо знать адрес-ссылку по которой находится товар)
2. парсинг полей товара (название, фото, вес, цена и другие характеристики)
Рассмотрим каждый этап более подробно.
Парсинг ссылок на товары.
Этот этап можно пропустить — если у Вас уже есть подготовленный файл с парами значений «Название товара:ссылка на товар».
Когда нет подобной входной информации, то процесс парсинга данной информации не однотипен, как правило выбирают наиболее быстрый способ сбора данной информации из возможных.
А возможны следующие способы:
1. парсинг ссылок через чтение карты сайта (если есть карта и ней есть подобная информация). Этот способ наиболее быстрый, поскольку в карте сайта может хранится вся необходимая информация.
2. сбор категорий товаров в словарь и поочерёдный проход каждой страницы в категории. Для поочерёдного прохода определяется изменяемая часть в ссылке на страницу и элемент, который в случае отсутствия укажет на то, что следующих страниц уже не существует.
Данный этап при работе парсера — чаще всего — выполняется в однопоточном режиме работы.
В некоторых случаях, на некоторых ресурсах эти способы могут не сработать, поскольку ссылка на каждую страницу в категории будет одинаковая, и тогда заходят с другой стороны, рассматривать которою в этой статье мы не станем.
Парсинг полей товара.
На данном этапе определяются необходимые поля в каждой категории товаров и под каждый тип поля составляется регулярное выражение для поиска данного поля в содержимом страницы (мини-программа на языке regex), от общего количества разновидностей полей зависит время на создание парсера в текущем этапе.
При выполнении парсинга — данный этап — как правило — многопоточный, что позволяет одновременно обрабатывать страницы многих товаров и значительно ускоряет процесс парсинга.
Существуют и другие типы парсеров, но описанный тип — это наиболее распростронённый.
Кроме всего вышеописанного, следует обратить внимание, что некоторые ресурсы — не позволяют часто и много обращаться к своим страницам и блокируют доступ к содержимому. Для обхода защиты от парсинга используют прокси — простым языком — это адреса портов, через которые возможна передача информации с сайтов не расскрывая Ваш реальный айпи адрес.
Сам процесс создания или настройки — требует знаний и времени на разработку и тестирование, но окупается огромной экономией Вашего дорогого времени.
Если Вы захотите самостоятельно создать парсер, то на помощь Вам может прийти очень удобный инструмент — ZennoPoster (скачать демо версию с официального сайта), если же у Вас возникнут не решаемые быстро вопросы, а парсить нужно уже завтра — Вы всегда можете обратится к нам по поводу разработки парсера.
Наши контакты — skype — vipvodu
www.avtozenno.ru
Парсинг любого сайта «для чайников»: ни строчки программного кода
Если вам нужно просто собрать с сайта мета-данные, можно воспользоваться бесплатным парсером системы Promopult. Но бывает, что надо копать гораздо глубже и добывать больше данных, и тут уже без сложных (и небесплатных) инструментов не обойтись.
Евгений Костин рассказал о том, как спарсить любой сайт, даже если вы совсем не дружите с программированием. Разбор сделан на примере Screaming Frog Seo Spider.
Что такое парсинг и зачем он вообще нужен
Парсинг нужен, чтобы получить с сайтов некую информацию. Например, собрать данные о ценах с сайтов конкурентов.
Одно из применений парсинга — наполнение каталога новыми товарами на основе уже существующих сайтов в интернете.
Что такое парсинг
Упрощенно, парсинг — это сбор информации. Есть более сложные определения, но так как мы говорим о парсинге «для чайников», то нет никакого смысла усложнять терминологию. Парсинг — это сбор, как правило, структурированной информации. Чаще всего — в виде таблицы с конкретным набором данных. Например, данных по характеристикам товаров.
Парсер — программа, которая осуществляет этот самый сбор. Она ходит по ссылкам на страницы, которые вы указали, и собирает нужную информацию в Excel-файл либо куда-то еще.
Парсинг работает на основе XPath-запросов. XPath — язык запросов, который обращается к определенному участку кода страницы и собирает из него заданную информацию.
ПО для парсинга
Здесь есть важный момент. Если вы введете в поисковике слово «парсинг» или «заказать парсинг», то, как правило, вам будут предлагаться некие услуги от компаний, они стоят относительно дорого и называется это так: «мы напишем вам парсер». То есть «мы создадим некую программу либо на Python, либо на каком-то еще языке, которая будет собирать эту информацию с нужного вам сайта». Эта программа нацелена только на сбор конкретных данных, она не гибкая и без знаний программирования вы не сможете ее самостоятельно перенастроить для других задач.
При этом есть готовые решения, которые можно под себя настраивать как угодно и собирать что угодно. Более того, если вы — SEO-специалист, возможно, одной из этих программ пользуетесь, но просто не знаете, что в ней такой функционал есть. Либо знаете, но никогда не применяли, либо применяли не в полной мере.
Вот две программы, которые являются аналогами.
Эти программы занимаются сбором информации с сайта. То есть они анализируют, например, его заголовки, какие-то коды, теги и все-все остальное. Помимо прочего, они позволяют собрать те данные, которые вы им зададите.
Профессиональные инструменты PromoPult: быстрее, чем руками, дешевле, чем у других, бесплатные опции.
Съем позиций, кластеризация запросов, парсер Wordstat, сбор поисковых подсказок, сбор фраз ассоциаций, парсер мета-тегов и заголовков, анализ индексации страниц, чек-лист оптимизации видео, генератор из YML, парсер ИКС Яндекса, нормализатор и комбинатор фраз, парсер сообществ и пользователей ВКонтакте.
Давайте смотреть на реальных примерах.
Пример 1. Как спарсить цену
Предположим, вы хотите с некого сайта собрать все цены товаров. Это ваш конкурент, и вы хотите узнать — сколько у него стоят товары.
Возьмем для примера сайт mosdommebel.ru.
Вот у нас есть страница карточки товара, есть название и есть цена этого товара. Как нам собрать эту цену и цены всех остальных товаров?
Мы видим, что цена отображается вверху справа, напротив заголовка h2. Теперь нам нужно посмотреть, как эта цена отображается в html-коде.
Нажимаем правой кнопкой мыши прямо на цену (не просто на какой-то фон или пустой участок). Затем выбираем пункт Inspect Element для того, чтобы в коде сразу его определить (Исследовать элемент или Просмотреть код элемента, в зависимости от браузера — прим. ред.).
Мы видим, что цена у нас помещается в тег <span> с классом totalPrice2. Так разработчик обозначил в коде стоимость данного товара, которая отображается в карточке. Фиксируем: есть некий элемент span с классом totalPrice2. Пока это держим в голове.
Есть два варианта работы с парсерами.
Первый способ. Вы можете прямо в коде (любой браузер) нажать правой кнопкой мыши на тег <span> и выбрать Скопировать > XPath. У вас таким образом скопируется строка, которая обращается к данному участку кода.
Выглядит она так:
/html/body/div[1]/div[2]/div[4]/table/tbody/tr/td/div[1]/div/table[2]/tbody/tr/td[2]/form/table/tbody/tr[1]/td/table/tbody/tr[1]/td/div[1]/span[1]Но этот вариант не очень надежен: если у вас в другой карточке товара верстка выглядит немного иначе (например, нет каких-то блоков или блоки расположены по-другому), то такой метод обращения может ни к чему не привести. И нужная информация не соберется.
Поэтому мы будем использовать второй способ. Есть специальные справки по языку XPath. Их очень много, можно просто загуглить «XPath примеры».
Например, такая справка:
Здесь указано как что-то получить. Например, если мы хотим получить содержимое заголовка h2, нам нужно написать вот так:
//h2/text()Если мы хотим получить текст заголовка с классом productName, мы должны написать вот так:
//h2[@class="productName"]/text()То есть поставить «//» как обращение к некому элементу на странице, написать тег h2 и указать в квадратных скобках через символ @ «класс равен такому-то».
То есть не копировать что-то, не собирать информацию откуда-то из кода. А написать строку запроса, который обращается к нужному элементу. Куда ее написать — сейчас мы разберемся.
Куда вписывать XPath-запрос?
Мы идем в один из парсеров. В данном случае я воспользуюсь программой Screaming Frog Seo Spider.
Она бесплатна для анализа небольшого сайта — до 500 страниц.
Интерфейс Screaming Frog Seo Spider
Например, мы можем — бесплатно — посмотреть заголовки страниц, проверить нет ли у нас каких-нибудь пустых тайтлов или дубликатов тега h2, незаполненных мета-тегов или каких-нибудь битых ссылок.
Но за функционал для парсинга в любом случае придется платить, он доступен только в платной версии.
Предположим, вы оплатили годовую лицензию и получили доступ к полному набору функций сервиса. Если вы серьезно занимаетесь анализом данных и регулярно нуждаетесь в функционале сервиса — это разумная трата денег.
Во вкладке меню Configuration у нас есть подпункт Custom, и в нем есть еще один подпункт Extraction. Здесь мы можем дополнительно что-то поискать на тех страницах, которые мы укажем.
Заходим в Extraction. И напоминаю, что мы хотели с сайта (в данном случае с сайта Московский дом мебели) собрать цены товаров.
Мы выяснили в коде, что у нас все цены на карточках товара обозначаются тегом <span> с классом totalPrice2. Формируем вот такой XPath запрос:
//span[@class="totalPrice2"]/spanИ указываем его в разделе Configuration > Custom > Extractions. Для удобства можем еще назвать как-нибудь колонку, которая у нас будет выгружаться. Например, «стоимость»:
Таким образом мы будем обращаться к коду страниц и из этого кода вытаскивать содержимое стоимости.
Также в настройках мы можем указать, что парсер будет собирать: весь html-код или только текст. Нам нужен только текст, без разметки, стилей и других элементов.
Нажимаем ОК. Мы задали кастомные параметры парсинга.
Как подобрать страницы для парсинга
Дальше есть еще один важный этап. Это, собственно, подбор страниц, по которым будет осуществляться парсинг.
Если мы просто укажем адрес сайта в Screaming Frog, парсер пойдет по всем страницам сайта. На инфостраницах и страницах категорий у нас нет цен, а нам нужны именно цены, которые указаны на карточках товара. Чтобы не тратить время, лучше загрузить в парсер конкретный список страниц, по которым мы будем ходить, — карточки товаров.
Откуда их взять?
Как правило, на любом сайте есть карта сайта XML, и находится она чаще всего по адресу: «адрес сайта/sitemap.xml». В случае с сайтом из нашего примера — это адрес
https://www.mosdommebel.ru/sitemap.xml.Либо вы можете зайти в robots.txt (site.ru/robots.txt) и посмотреть. Чаще всего в этом файле внизу содержится ссылка на карту сайта.
Ссылка на карту сайта в файле robots.txt
Даже если карта называется как-то странно, необычно, нестандартно, вы все равно увидите здесь ссылку.
Но если не увидите — если карты сайта нет — то нет никакого решения для отбора карточек товара. Тогда придется запускать стандартный режим в парсере — он будет ходить вообще по всему сайту, по всем разделам. Но нужную вам информацию соберет только на карточках товара. Минус здесь в том, что вы потратите больше времени и дольше придется ждать нужных данных.
У нас карта сайта есть, поэтому мы переходим по ссылке https://www.mosdommebel.ru/sitemap.xml и видим, что сама карта разделяется на несколько карт. Отдельная карта по статичным страницам, по категориям, по продуктам (карточкам товаров), по статьям и новостям.
Ссылки на отдельные sitemap-файлы под все типы страниц
Нас интересует карта продуктов, то есть карточек товаров.
Ссылка на sitemap-файл для карточек товара
Что с этим делать дальше. Возвращаемся в Screaming Frog Seo Spider. Сейчас он запущен у нас в стандартном режиме, в режиме Spider (паук), который ходит по всему сайту и анализирует все-все страницы. Нам нужно его запустить в режиме List.
Мы загрузим ему конкретный список страниц, по которому он будет ходить. Нажимаем на вкладку Mode и выбираем List.
Жмем кнопку Upload и кликаем по Download Sitemap.
Указываем ссылку на Sitemap карточек товара, нажимаем ОК.
Программа скачает все ссылки, указанные в карте сайта. В нашем случае Screaming Frog обнаружил более 40 тысяч ссылок на карточки товаров:
Нажимаем ОК и у нас начинается парсинг сайта.
После завершения парсинга на первой вкладке Internal мы можем посмотреть информацию по всем характеристикам: код ответа, индексируется/не индексируется, title страницы, description и все остальное.
Это все полезная информация, но мы шли за другим.
Вернемся к исходной задаче — посмотреть стоимость товаров. Для этого в интерфейсе Screaming Frog нам нужно перейти на вкладку Custom. Чтобы попасть на нее, нужно нажать на стрелочку, которая находится справа от всех вкладок. Из выпадающего списка выбрать пункт Custom.
И на этой вкладке из выпадающего списка фильтров (Filter) выберите Extraction.
Вы как раз и получите ту самую информацию, которую хотели собрать: список страниц и колонка «Стоимость 1» с ценами в рублях.
Задача выполнена, теперь все это можно выгрузить в xlsx или csv-файл.
После выгрузки стандартной заменой вы можете убрать букву «р», которая обозначает рубли. Просто, чтобы у вас были цены в чистом виде, без всяких там пробелов, буквы «р» и прочего.
Таким образом, вы получили информацию по стоимости товаров у сайта-конкурента.
Если бы мы хотели получить что-нибудь еще, например дополнительно еще собрать названия этих товаров, то нам нужно было бы зайти снова в Configuration > Custom > Extraction. И выбрать после этого еще один XPath-запрос и указать, например, что мы хотим собрать тег <h2>.
Просто запустив еще раз парсинг, мы собираем уже не только стоимость, но и названия товаров.
Вот у нас теперь связка такая: url товара, его стоимость и название этого товара.
Если мы хотим получить описание или что-то еще — продолжаем в том же духе. Единственное, что нужно всегда помнить, что h2 собрать легко. Это стандартный элемент html-кода и для его парсинга можно использовать стандартный XPath-запрос (посмотрите в справке). В случае же с описанием или другими элементами нам нужно всегда возвращаться в код страницы и смотреть: как называется сам тег, какой у него класс/id либо какие-то другие атрибуты, к которым мы можем обратиться с помощью XPath-запроса.
Например, мы хотим собрать описание. Нужно снова идти в Inspect Element.
Оказывается, все описание товара лежит в теге <table> с классом product_description. Если мы его соберем, то у нас в таблицу выгрузится полное описание.
Здесь есть нюанс. Текст описания на странице сайта сделан с разметкой. Например, здесь есть переносы на новую строчку, что-то выделяется жирным.
Если вам нужно спарсить текст описания с уже готовой разметкой, то в настройках Extraction в парсере мы можем выбрать парсинг с html-кодом.
Если вы не хотите собирать весь html-код (потому что он может содержать какие-то классы, которые к вашему сайту никакого отношения не имеют), а нужен текст в чистом виде, выбираем только текст. Но помните, что тогда переносы строк и все остальное придется заполнять вручную.
Собрав все необходимые элементы и прогнав по ним парсинг, вы получите таблицу с исчерпывающей информацией по товарам у конкурента.
Такой парсинг можно запускать регулярно (например, раз в неделю) для отслеживания цен конкурентов. И сравнивать, у кого что стоит дороже/дешевле.
Пример 2. Как спарсить фотографии
Рассмотрим вариант решения другой прикладной задачи — парсинга фотографий.
На сайте Эльдорадо у каждого товара есть довольно таки немало фотографий. Предположим, вы их хотите взять — это универсальные фото от производителя, которые можно использовать для демонстрации на своем сайте.
Задача: собрать в эксель адреса всех картинок, которые есть у разных карточек товара. Не в виде файлов, а в виде ссылок. Потом по ссылкам вы сможете их скачать либо напрямую загрузить на свой сайт. Большинство движков интернет-магазинов, таких как Битрикс и Shop-Script, поддерживают загрузку фотографий по ссылке. Если вы в CSV-файле, который используете для импорта-экспорта, укажете ссылки на фотографии, то по ним движок сможет загрузить эти самые фотографии.
Ищем свойства картинок
Для начала нам нужно понять, где в коде пишутся свойства, адрес фотографии на каждой карточке товара.
Нажимаем правой клавишей на фотографию, выбираем Inspect Element, начинаем исследовать.
Смотрим, в каком элементе и с каким классом у нас находится данное изображение, что оно из себя представляет, какая у него ссылка и т.д.
Изображения лежат в элементе <span>, у которого id — firstFotoForma. Чтобы спарсить нужные нам картинки, понадобится вот такой XPath-запрос:
//*[@id="firstFotoForma"]/*/img/@srcУ нас здесь обращение к элементам с идентификатором firstFotoForma, дальше есть какие-то вложенные элементы (поэтому прописана звездочка), дальше тег img, из которого нужно получить содержимое атрибута src. То есть строку, в которой и прописан URL-адрес фотографии.
Давайте попробуем это сделать.
Берем XPath-запрос, в Screaming Frog переходим в Configuration > Custom > Extraction, вставляем и жмем ОК.
Для начала попробуем спарсить одну карточку. Нужно скопировать ее адрес и добавить в Screaming Frog таким образом: Upload > Paste
Нажимаем ОК. У нас начинается парсинг.
Screaming Frog спарсил одну карточку товара и у нас получилась такая табличка. Рассмотрим ее подробнее.
Мы загрузили один URL на входе, и у нас автоматически появилось сразу много столбцов «фото товара». Мы видим, что по этому товару собралось 9 фотографий.
Для проверки попробуем открыть одну из фотографий. Копируем адрес фотографии и вставляем в адресной строке браузера.
Фотография открылась, значит парсер сработал корректно и вытянул нужную нам информацию.
Теперь пройдемся по всему сайту в режиме Spider (для переключения в этот режим нужно нажать Mode > Spider). Укажем адрес https://www.eldorado.ru, нажимаем старт и запускаем парсинг.
Так как программа парсит весь сайт, то по страницам, которые не являются карточками товара, ничего не находится.
А там, где у нас карточки товаров — собираются ссылки на все фотографии.
Таким образом мы сможем собрать их и положить в Excel-таблицу, где будут указаны ссылки на все фотографии для каждого товара.
Если бы мы собирали артикулы, то еще раз зашли бы в Configuration > Custom > Extraction и добавили бы еще два XPath-запроса: для парсинга артикулов, а также тегов h2, чтобы собрать еще названия. Так мы бы убили сразу двух зайцев и собрали бы связку: название товара + артикул + фото.
Пример 3. Как спарсить характеристики товаров
Следующий пример — ситуация, когда нам нужно насытить карточки товаров характеристиками. Представьте, что вы продаете книжки. Для каждой книги у вас указано мало характеристик — всего лишь год выпуска и автор. А у Озона (сильный конкурент, сильный сайт) — у него характеристик много.
Вы хотите собрать в эксель все эти данные с Озона и использовать их для своего сайта. Это техническая информация, вопросов с авторским правом нет.
Изучаем характеристики
Нажимаете правой кнопкой по данной характеристике, выбираете Inspect Element и смотрите, как называется элемент, который содержит каждую характеристику.
У нас это элемент <div>, у которого в качестве класса указана строка eItemProperties_Line.
И дальше внутри каждого такого элемента <div> у нас содержится название характеристики и ее значение.
Значит, нам нужно собирать элементы <div> с классом eItemProperties_Line.
Для парсинга нам понадобится вот такой XPath-запрос:
//*[@class="eItemProperties_line"]Идем в Screaming Frog. Configuration > Custom > Extraction. Вставляем XPath-запрос, выбираем Extract Text (так как нам нужен только текст в чистом виде, без разметки), нажимаем ОК.
Переключаемся в режим Mode > List. Нажимаем Upload, указываем адрес страницы, с которой будем собирать характеристики, нажимаем ОК.
После завершения парсинга переключаемся на вкладку Custom, в списке фильтров выбираем Extraction.
И видим — парсер собрал нам все характеристики. В каждой ячейке находится название характеристики (например, «Автор») и ее значение («Игорь Ашманов»).
Пример 4. Как парсить отзывы (с рендерингом)
Следующий пример немного нестандартен — на грани «серого» SEO. Это парсинг отзывов с того же Озона. Допустим, мы хотим собрать и перенести на свой сайт тексты отзывов ко всем книгам.
Я покажу на одном примере — загружу один URL. Начнем с того, что посмотрим, где они лежат в коде.
Они находятся в элементе <div> с классом jsCommentContent:
Следовательно, нам нужен такой XPath-запрос:
//*[@class="jsCommentContents"]Добавляем его в Screaming Frog. Теперь копируем адрес страницы, которую будем анализировать, и загружаем в парсер.
Жмем ОК и видим, что никакие отзывы у нас не загрузились:
Почему так? Разработчики Озона сделали так, что текст отзывов грузится в момент, когда вы докручиваете до места, где отзывы появляются (чтобы не перегружать страницу). То есть они изначально в коде нигде не видны.
Чтобы с этим справиться, нам нужно зайти в Configuration > Spider, переключиться на вкладку Rendering и выбрать JavaScript. Так при обходе страниц парсером будет срабатывать JavaScript и страница будет отрисовываться полностью — так, как пользователь увидел бы ее в браузере. Screaming Frog также будет делать скриншот отрисованной страницы.
Мы выбираем устройство, с которого мы якобы заходим на сайт (десктоп). Настраиваем время задержки, перед тем как будет делаться скриншот — одну секунду.
Нажимаем ОК. Введем вручную адрес страницы, включая #comments (якорная ссылка на раздел страницы, где отображаются отзывы).
Для этого жмем Upload > Enter Manually и вводим адрес:
Обратите внимание. При рендеринге (особенно, если страниц много) парсер может работать очень долго.
Итак, парсер собрал 20 отзывов. Внизу они показываются в качестве отрисованной страницы. А вверху в табличном варианте мы видим текст этих отзывов.
Пример 5. Как спарсить скрытые телефоны на сайте ЦИАН
Следующий пример — сбор телефонов с сайта cian.ru. Здесь есть предложения о продаже квартир. Допустим, стоит задача собрать телефоны с каких-то предложений или вообще со всех.
У этой задачи есть особенности. На странице объявления телефон скрыт кнопкой «Показать телефон».
После клика он виден. А до этого в коде видна только сама кнопка.
Но на сайте есть недоработка, которой мы воспользуемся. После нажатия на кнопку «Показать телефон» мы видим, что она начинается «+7 967…». Теперь обновим страницу, как будто мы не нажимали кнопку, посмотрим исходный код страницы и поищем в нем «967».
И вот, мы видим, что этот телефон уже есть в коде. Он находится у ссылки, с классом a10a3f92e9—phone—3XYRR. Чтобы собрать все телефоны, нам нужно спарсить содержимое всех элементов с таким классом.
Используем этот класс в XPath-запросе:
//*[@class="a10a3f92e9--phone--3XYRR"]Идем в Screaming Frog, Custom > Extraction. Указываем XPath-запрос и даем название колонке, в которую будут собираться телефоны:
Берем список ссылок (для примера я отобрал несколько ссылок на страницы объявлений) и добавляем их в парсер.
Итак, пожалуйста, мы видим связку: адрес страницы — номер телефона.
Также мы можем собрать в дополнение к телефонам еще что-то. Например, этаж.
Алгоритм такой же:
- Кликаем по этажу, Inspect Element.
- Смотрим, где в коде расположена информация об этажах и как обозначается.
- Используем класс или идентификатор этого элемента в XPath-запросе.
- Добавляем запрос и список страниц, запускаем парсер и собираем информацию.
Пример 6. Как парсить структуру сайта на примере DNS-Shop
И последний пример — сбор структуры сайта. С помощью парсинга можно собрать структуру какого-то большого каталога или интернет-магазина.
Рассмотрим, как собрать структуру dns-shop.ru. Для этого нам нужно понять, как строятся хлебные крошки.
Нажимаем на любую ссылку в хлебных крошках, выбираем Inspect Element.
Эта ссылка в коде находится в элементе <span>, у которого атрибут itemprop (атрибут микроразметки) использует значение «name».
Используем элемент span с значением микроразметки в XPath-запросе:
//span[@itemprop="name"]Указываем XPath-запрос в парсере:
Пробуем спарсить одну страницу и получаем результат:
Таким образом мы можем пройтись по всем страницам сайта и собрать полную структуру.
Возможности парсинга на основе XPath
Что можно спарсить:
- Любую информацию с почти любого сайта. Нужно понимать, что есть сайты с защитой от парсинга. Например, если вы захотите спарсить любой проект Яндекса — у вас ничего не получится. Авито — тоже довольно таки сложно. Но большинство сайтов можно спарсить.
- Цены, наличие товаров, любые характеристики, фото, 3D-фото.
- Описание, отзывы, структуру сайта.
- Контакты, неочевидные свойства и т.д.
Любой элемент на странице, который есть в коде, вы можете вытянуть в Excel.
Ограничения при парсинге
- Бан по user-agent. При обращении к сайту парсер отсылает запрос user-agent, в котором сообщает сайту информацию о себе. Некоторые сайты сразу блокируют доступ парсеров, которые в user-agent представляются как приложения. Это ограничение можно легко обойти. В Screaming Frog нужно зайти в Configuration > User-Agent и выбрать YandexBot или Googlebot.
Подмена юзер-агента вполне себе решает данное ограничение. К большинству сайтов мы получим доступ таким образом.
- Запрет в robots.txt. Например, в robots.txt может быть прописан запрет индексирования каких-то разделов для Google-бота. Если мы user-agent настроили как Googlebot, то спарсить информацию с этого раздела не сможем.
Чтобы обойти ограничение, заходим в Screaming Frog в Configuration > Robots.txt > Settings
И выбираем игнорировать robots.txt
Если вы долгое время парсите какой-то сайт, то вас могут заблокировать на определенное или неопределенное время. Здесь два варианта решения:
- Использовать VPN.
- В настройках парсера снизить скорость, чтобы не делать лишнюю нагрузку на сайт и уменьшить вероятность бана.
- Анализатор активности / капча
Некоторые сайты защищаются от парсинга с помощью умного анализатора активности. Если ваши действия похожи на роботизированные (когда обращаетесь к странице, у вас нет курсора, который двигается, или браузер не похож на стандартный), то анализатор показывает капчу, которую парсер не может обойти.
Такое ограничение можно обойти, но это долго и дорого.
***
Теперь вы знаете, как собрать любую нужную информацию с сайтов конкурентов. Пользуйтесь приведенными примерами и помните — почти все можно спарсить. А если нельзя — то, возможно, вы просто не знаете как.
blog.promopult.ru
12 лучших инструментов и программного обеспечения для парсинга сайтов и мониторинга цен
Если и есть что-то, что я узнала о создании контента за последний год, так это то, что независимо от качества моего контента, без стратегического продвижения и маркетинга он не принесет пользы никому, будь то читатели или компания, в которой я работаю. Хотя я рассчитываю на продвижение в социальных сетях и на веб-сайте компании, все-таки если мой блог или whitepaper (англ. – мини-книга о решении определенной проблемы. Например, в ней может быть описана новая концепция или процесс выполнения технических задач) достигнет высококвалифицированного списка читателей, которые найдут контент действительно полезным, вы не сможете найти более благодарного писателя, чем я! Итак, как я собираюсь построить этот список для каждого контента, который я создаю? Интернет — это огромный рудник мыслей и интересов, выраженных различными людьми, и сбор данных из этого богатства информации может помочь мне определить правильную аудиторию — процесс, известный как парсинг.
Конечно, я могла бы передать всю работу по парсингу на аутсорсинг в специальную сервисную компанию, но мой инстинкт программиста и исследователя новых инструментов, культивируемый в течение 3 лет работы в качестве “кибертехника” в ведущей компании по разработке ПО, взял верх надо мной. И я решила окунуться с головой во все тонкости парсинга, и количество вариантов, которые я обнаружила, слегка сбило меня с толку. Изучив сферу парсинга, я классифицировала все доступные варианты, которые мне удалось найти, и уникальные особенности популярных инструментов, найденных на рынке, которые обращаются к различным сегментам аудитории.
Прежде чем переходить к инструментам парсинга, важно определиться, как вы будете собирать веб-данные. Это зависит от цели, от уровня любопытства и от ресурсов, которые у вас есть.
Итак, сначала выберите правильный подход к парсингу
С моей точки зрения, парсинг в основном выполняется следующими способами:
- Создание собственного поискового робота с нуля
Вариант для подкованных в коде людей, которые любят экспериментировать с макетами сайтов и решать проблемы блокировки, а также хорошо разбираются в разных языках программирования, таких как Python, R или Perl. Так же, как и решая свои повседневные задачи посредством программирования для любого научного проекта по data science, студент или исследователь может легко построить свое решение для парсинга с открытыми исходными кодами — такими, как Scrapy на основе Python или пакет rvest, RCrawler в R.
- Инструменты парсинга, предназначенные для разработчиков
Инструменты парсинга подходят для разработчиков, в основном, там, где они могут создавать пользовательские парсеры с визуальной логикой программирования. Эти инструменты можно приравнять к среде IDE Eclipse для приложений Java EE. Положения для поворота IPs, агентов хоста и данных синтаксического анализа доступны в этом диапазоне для персонализации.
- “Сделай сам” — инструменты парсинга для не программистов
Для тех, кто не считает себя “технарем” и в коде не разбирается, есть куча визуальных инструментов типа “выбери и кликни”, которые помогут создать список продаж или заполнить информацию о продукте для вашего каталога с помощью сценариев zero manual (без ручной работы).
- Аутсорсинг всего проекта парсинга
Для предприятий, которые настроены на масштабируемые проекты парсинга или для проектов в цейтноте, где у вас нет команды разработчиков, чтобы собрать собственное решение для парсинга, услуги специальных компаний становятся ценной помощью. Итак, если вы собираетесь воспользоваться инструментами, то вот список преимуществ и недостатков популярных инструментов парсинга, которые попадают во 2-ю и 3-ю категорию.
[su_box title=”Вам нужен парсинг и вы не программист?” style=”default” box_color=”#085fc8″]Бесплатно регистрируйтесь на нашем портале https://ru.xmldatafeed.com и используйте ежедневные итоги парсинга крупнейших сайтов России (товары и услуги)! Все данные уже в формате Excel!
[/su_box]“Сделай сам” — инструменты парсинга для не программистов, настраиваемые по принципу “выбери и кликни”
Import.io
Настоящий титан в категории инструментов “Сделай сам”, import.io дает шанс каждому, кому необходимо извлечь какую-либо информацию из веб-данных с очень удобным, интуитивно понятным и интерактивным интерфейсом. Облачная платформа может структурировать данные, найденные за изображениями, экраном входа в систему и сотнями веб-страниц — полностью без программирования. Мониторинг изменений веб-сайта и возможность интеграции с рядом инструментов отчетности и приложений делают его отличным вариантом для предприятий с насущной необходимостью в парсинге.
За:
- Простой и легкий пользовательский интерфейс, который хорошо работает для не программистов, желающих построить свой список потенциальных клиентов или отслеживать изменения цен.
- Это вполне адекватный вариант парсинга на нормальной скорости при сборе данных с разных веб-сайтов одновременно.
Против:
Если на данном этапе все выглядит классно, то осталось упомянуть всего лишь один минус, который может помешать вам попробовать этот инструмент, — это его цена. Несмотря на то что раньше у них была бесплатная пробная версия, теперь она больше не доступна (а базовый план начинается с $299/месяц). Так что вы извлекаете данные с сайтов, а программа извлекает деньги из вашего кармана.
Dexi.io
Ранее известный как CloudScrape, а ныне Dexi.io — еще один потрясающий визуальный инструмент для автоматизации сбора данных, предназначенный для коммерческого использования, надежное и безпроблемное приложение для браузера. Dexi предоставляет возможность для создания роботов, которые могут работать как экстрактор или поисковый робот или выполнять задачи по очистке ETL-данных после извлечения в форме Dexi Pipes. Этот мощный инструмент парсинга решает проблемы разбиения на страницы, выполняет извлечение в цикле и делает скриншоты веб-страниц. Он выдает свои предложения по выбору данных на веб-странице для “умного” извлечения содержимого.
За:
- Здесь нет жестких процедур настройки, которым вы должны строго следовать. Зарегистрируйтесь, и приложение браузера откроется для вас, чтобы создать своего робота. Их потрясающая команда поддержки поможет вам с созданием бота в случае, если вы попали в засаду.
- Для коммерческого использования есть стандартный тарифный план по цене $119/месяц (для небольших проектов), который выглядит вполне приемлемым, а также профи-тариф, который подойдет для более крупных бизнес-проектов.
Против:
- Концепция дополнений в Dexi.io, хотя и выглядит поначалу симпатичной, потом все-таки оказывается не такой классной. Так как дополнений становится все больше и больше, и цены на них тоже растут.
- Некоторые пользователи ворчат и высказывают недовольство по поводу документации продукта, которую я надеюсь, ребята из Dexi скоро исправят.
Octoparse
Синий осьминог обещает принести вам все данные “на блюдечке с голубой каемочкой” безо всякого программирования вовсе, и надо сказать, он действительно это может! В течение всего 2 лет после запуска Octoparse прошел через 7 версий сервиса, доводя до ума свой рабочий процесс по обратной связи, полученной от пользователей. Он имеет интуитивно понятный интерфейс “выбери-и-кликни”, который поддерживает бесконечную прокрутку, аутентификацию входа, многоформатный экспорт данных и неограниченное количество страниц на заход на своем бесплатном тарифе (да, вам не послышалось!).
За:
- Предусмотренные функции парсинга и работа с неограниченным списком веб-страниц за один заход делают его идеальным выбором для сценариев мониторинга цен.
- Функций, предусмотренных в их бесплатном плане более чем достаточно, если вы ищете эффективное одноразовое, готовое решение с хорошей документацией руководства пользователя. Кроме того, точное извлечение данных может быть достигнуто с помощью встроенных инструментов XPath и Regex.
Против:
- Octoparse еще только предстоит добавить функции извлечения pdf-данных и извлечения данных по изображениям (пока извлекается только URL-адрес изображения), поэтому называть его полноценным инструментом парсинга было бы несколько преждевременным.
- Поддержка клиентов “не огонь”, на быстрые ответы можно не рассчитывать.
ParseHub
Десктоп-приложение, которое предлагает графический интерфейс для выбора и извлечения данных по вашему выбору из Javascript и AJAX страниц, также поддерживается Windows, Mac OS X и Linux. ParseHub также может просматривать вложенные комментарии, карты, изображения, календари и всплывающие окна. А еще у него есть расширение на основе браузера, чтобы мгновенно запустить ваш парсинг, и тьюториалы, которые там есть, очень хорошо помогают.
За:
- ParseHub имеет богатый пользовательский интерфейс и извлекает данные из многих сложных областей веб-сайта, в отличие от других программ.
- Разработчики могут попробовать RestfulAPI от ParseHub, который предоставляет удобный доступ к данным по завершении парсинга.
Против:
- Предполагаемый бесплатный план от ParseHub выглядит несколько жалким, ограничивая количество пройденных страниц до 200 и количество проектов — всего до 5. Кроме того, их платные версии начинаются со вполне ощутимых $149 в месяц, и все это выглядят как провальный вариант, особенно для одноразовых проектов.
- Скорость, с которой выполняется парсинг, должна быть значительно улучшена, потому что в текущем формате парсинг большого объема данных выполняется слишком медленно.
OutwitHub
Outwit technologies предлагает простой, без выпендрежа графический интерфейс, который изначально поставлялся в качестве дополнения Firefox (устаревшая версия все еще доступна, но без обновлений функций), а теперь и в виде свободно загружаемого ПО, которое можно обновить до Light и Pro версий. Без каких-либо навыков программирования при помощи Outwit Hub можно извлекать и экспортировать ссылки, адреса электронной почты, новости RSS и таблицы данных в базы данных CSV, HTML, Excel или SQL. Их другие продукты, такие как Outwit Images и Documents, извлекают изображения и документы с веб-сайтов на ваши локальные диски.
За:
- Это вполне гибкий и мощный вариант для людей, которым нужны контакты источников и он доступен по цене, начинающейся с $69 для основной одноразовой покупки автономного приложения.
- Функция “Fast Scrape” (быстрый парсинг) — это приятное дополнение для быстрого удаления данных из списка URL-адресов, которые вы передали Outwit.
Против:
- Пригодность Outwit для повторяющихся широкомасштабных проектов по парсингу сомнительна, и их документация с обучающими материалами определенно нуждаются в развитии.
- Продукту не хватает удобного интерфейса “выбери-и-кликни”, поэтому пользователям в первый раз может потребоваться изучить обучающие видео на Youtube перед тем, как реализовывать свой проект по парсингу.
FMiner
ПО для визуального парсинга с макрокомпонентом дизайна для разработки блок-схемы парсинг-проекта путем визуального сопоставления со структурой сайта на том же экране. Инструмент на основе Python можно запускать как на Windows, так и на Mac OS с хорошей поддержкой Regex. FMiner имеет расширенные функции извлечения данных, такие как решение captcha, опции очистки данных после извлечения, а также позволяет вставлять код python для запуска задач на целевых веб-сайтах.
За:
Будучи мульти-платформенным программным обеспечением, доступным как для не программистов, так и для разработчиков, FMiner является мощным инструментом для сбора данных с сайтов со сложными макетами.
Против:
- Визуальный интерфейс не очень привлекателен, и необходимо приложить усилия для создания надлежащего рабочего процесса очистки (вспоминая о блок-схемах и соединителях). Вы должны знать свой путь вокруг определения элементов данных с помощью выражений XPath.
- После 15-дневной пробной версии вы вынуждены приобрести по крайней мере базовую версию программного обеспечения по цене $168 без планирования, емейл-отчетов или поддержки JS. Кстати, насколько активно они обновляют свой продукт? Не уверена, ибо не слышно новостей о каких-либо свежих улучшениях в FMiner.
Далее мы рассмотрим инструменты парсинга для разработчиков.
Инструменты парсинга для разработчиков
80Legs
Этот продукт размещен в облаке и такие популярные проблемы парсинга как ограничение скорости и вращение между несколькими IP-адресами тут не оставили без внимания (все в бесплатной версии!), так что 80Legs — это чудо парсинга! Загрузите список URL-адресов, установите ограничения обхода, выберите одно из встроенных приложений из обширного каталога от 80Legs, и полный вперед. Примером приложения от 80Legs будет “Ключевое слово”, которое подсчитывает количество раз, когда поисковый запрос появляется во всех перечисленных URL-адресах по отдельности. Пользователи могут создавать свои собственные приложения и код, которые могут быть помещены в 80Legs, что делает инструмент более настраиваемым и мощным.
О! И недавно они запустили новую версию своего портала. Загляните.
За:
- Неограниченное количество запусков в месяц; один запуск за раз обрабатывает до 10000 URL-адресов прямо в бесплатной версии. Так что можете себе представить, платные тарифы 80Legs еще более привлекательны!
- Приложения, перечисленные в 80Legs, дают пользователям возможность анализировать извлеченный веб-контент и позволяют пользоваться этим инструментом даже специалистам с ограниченными познаниями в коде.
Против:
- Хотя поддержка огромных краулеров веб-страниц и заявлена, нет никаких базовых вариантов обработки данных, которые были бы необходимы при таких крупномасштабных проектах.
- Расширенные функции краулера, которые могут заинтересовать кодеров, в платформе 80Legs не обнаружены, и их команда поддержки также реагирует довольно медленно.
Content Grabber
Хотя рекламируется как визуальный инструмент парсинга для не программистов, полный потенциал этого инструмента может быть использован как раз людьми с отличными навыками программирования, которые позволят им провести эффективный сбор данных. Шаблоны сценариев, предназначенные для захвата, нужны для настройки ваших парсеров, и вы можете добавить свои собственные строки кода C# или Visual Basic. Agent Explorer и XPath Editor предоставляют опции для группировки нескольких команд и редактирования XPath по мере необходимости.
За:
- Разработчики могут отлаживать скрипты очистки, регистрировать и обрабатывать ошибки с помощью встроенной поддержки команд.
- Крупные компании, ищущие инфраструктуру для сбора данных, могут попросту начать молиться на Content Grabber за его надежный и очень гибкий интерфейс парсинга, что стало возможным благодаря многим расширенным функциям, найденным в инструменте.
Против:
- Программное обеспечение доступно только для Windows и Linux, пользователям Mac OS рекомендуется запускать программное обеспечение в виртуальной среде.
- Цена установлена в $995 за одноразовую покупку программного обеспечения, которое ставит его вне досягаемости для скромных и небольших проектов по сбору данных.
Mozenda
Mozenda, предназначенная в основном для коммерческих предприятий и крупных организаций, позволяет создавать поисковые роботы, которые могут быть размещены на собственных серверах Mozenda или работать в вашей системе. Согласна, что у нее есть хороший пользовательский интерфейс, чтобы просто следовать алгоритму “выбери и кликни”, но для разработки поискового робота вам все равно нужно потратить время на обучающие материалы и часто обращаться за помощью их техподдержки. Поэтому классифицировать ее как инструмент DIY для не-технарей будет несправедливо. Этот надежный инструмент понимает списки и сложные макеты веб-сайтов наряду с совместимостью XPath.
За:
- Роботы Mozenda собирают данные в довольно быстром темпе для запланированного и параллельного парсинга и поддерживают различные макеты сайтов.
- Вы можете извлечь данные в файлах Excel, Word, PDF и объединить их с данными, полученными из интернета с помощью Mozenda.
Против:
Исключительно приложение для Windows по неумеренно высокой цене в $300/месяц, и это за 2 одновременных запуска и 10 роботов.
Connotate
Connotate — это платформа для извлечения данных, созданная исключительно для нужд бизнеса. Хотя там есть интерфейс для сбора данных методом “выбери-и-кликни”, все же пользовательский интерфейс и цены явно не предназначены для людей с запросами “на разок”. Работа со схемами и поддержание поисковых роботов требует обученных пользователей, и если ваша компания ищет способы сбора информации с тысяч URL-адресов, то Connotate — это хороший вариант.
За:
Способность Connotate работать с огромным количеством динамических сайтов наряду с его возможностями извлечения документов делают эту платформу приемлемым вариантом для крупных предприятий, которые собирают веб-данных на регулярной основе.
Против:
Обработка ошибок во время крупномасштабных проектов выполняется не совсем гладко, что может вызвать небольшую загвоздку в вашем текущем проекте сбора данных.
Apify
Apify, как указано в названии, является веб-платформой для программистов, которые хотят превратить веб-сайты в API. Cron-подобное планирование заданий и расширенные функции поискового робота, которые поддерживают обработку больших веб-сайтов, поддерживаются в Apify. У них есть варианты на разный вкус, как для самостоятельных разработчиков, так и для предприятий, чтобы развивать и поддерживать свои API.
За:
- Apify может похвастаться живым форумом и поддержкой сообщества, которые позволяют разработчикам повторно использовать исходные коды, размещенные на GitHub, а также он имеет открытую библиотеку конкретных инструментов очистки, таких как SEO audit tool, email extractor и т. Д.
- API интегрируется с огромным количеством приложений и может обрабатывать сложные вопросы разбиения на страницы и макета сайта.
Против:
Как бы легко это ни было для разработчиков — написать всего лишь несколько строк Javascript, обработка ротации IP и прокси будет их основной задачей, которая осталась без внимания непосредственно в Apify.
Diffbot
Это другой инструмент сбора данных, также использующий API-доступ к данным, который включает методы ML и NLP для идентификации и сортировки веб-контента. Разработчики могут создавать собственные API для анализа контента в блогах, обзорах и на страницах событий. Diffbot расширяет библиотеку этих API, что позволяет легко выбрать и интегрировать API по вашему выбору.
За:
Их алгоритм машинного обучения, который определяет и классифицирует тип контента, обеспечивая точное извлечение данных.
Против:
Понимание документов на уровне человека еще не внедрено, и Diffbot также находится в ряду дорогостоящих инструментов парсинга.
Diggernaut
“Превратите содержимое веб-сайта в набор данных”, так звучит утверждение на главной странице Diggernaut, дополненное фразой “не требуется навыков программирования”. Но облачный инструмент извлечения, который поставляется как расширение Chrome и как автономное настольное приложение, имеет функцию мета-языка, которая позволяет программистам автоматизировать сложные задачи парсинга с помощью собственного кода. Понимание языков разметки HTML,CSS/JQuery и YAML необходимо для настройки их краулеров.
За:
- Diggernaut поставляется с довольно классным модулем OCR, который может помочь вам вытащить данные из изображений.
- Существует также возможность для разработчиков создавать Restful API для легкого доступа к веб-данным, и все по очень доступным ценам — даже их бесплатная версия поддерживает 3 краулера и 5K запросов страниц.
Против:
Если использовать метод “выбери и кликни”, то Diggernaut сначала трудновато понять. Кроме того, при довольно хорошем качестве функций извлечения изображений печально не обнаружить модулей извлечения документов.
Подводя итоги
Инструменты сбора веб-данных представлены в огромном количестве, и они прекрасно работают как для одноразовых мини-поисков, так и для небольших любительских проектов по парсингу, и даже регулярных проектов по сбору данных, у которых есть собственная команда профессионалов, занятых их обслуживанием. Хотя всегда придется приложить некоторые усилия для очистки и обогащения выходных данных.
Об авторе: Ида Джесси Сагина — специалист по контент-маркетингу, в настоящее время фокусируется на контенте для Scrapeworks — ассоциированного подразделения Mobius Knowledge Services. Она следит за новыми технологическими разработками и любит писать обо всем, что записывает данные.
xmldatafeed.com
Парсеры — программы для сбора информации
Парсер – это программа для автоматизации процесса парсинга, то есть обработки информации по определенному алгоритму. В этой статье я приведу несколько примеров программ-парсеров и в двух словах опишу их назначение и основные функции.
Как мы уже определились, парсинг – это процесс синтаксического и лексического анализа, разбора и преобразования какого-либо документа или выбора из этого документа, интересующих нас данных. Это могут быть и трансляторы языков программирования, переводчики с одного языка на другой. Я думаю, что интерпретаторы скриптов тоже используют алгоритмы парсинга.
Но поскольку парсеры нас интересуют применительно к интернету и его приложениям, то мы вернемся к описанию использования парсеров для этой тематики. Выделю два наиболее популярных вида парсинга в интернете:
— парсинг контента
— парсинг результатов выдачи поисковых систем
Некоторые программы совмещают эти функции, плюс обрастают дополнительными функциями и возможностями.
Итак приступим
Универсальный парсер Datacol
Парсер Datacol представляет собой универсальный инструмент для сбора информации в интернете. Текущая версия программы — Datacol5.
На настоящий момент этот парсер является несомненным лидеров в Рунете по своим возможностям и функционалу.
Этот инструмент позволяет собирать в интернете данные следующего типа:
- Результаты поисковой выдачи
- Сбор контента с заданных сайтов
- Сбор внутренних и внешних ссылок для интернет сайта
- Сбор графической информации, аудио контента, видео материалов
- Парсинг СЕО показателей сайтов с различных сервисов
- И много много самой различной информации с различных интернет ресурсов
Вся полученная информация сохраняется в удобном для пользователя виде для дальнейшего анализа и использования.
Более подробное описание парсера Datacol5 находится на этой странице — web-data-extractor.net.
Программа Content Downloader
Представляет собой универсальную программу. Обладает очень широким функционалом и представляет собой целый набор парсинг-функций, вот перечень основных из них:
- Парсер товаров
- Парсер интернет-магазинов
- Парсер картинок
- Парсер видио
- RSS парсер
- Парсер ссылок
- Парсер новостей
И это еще неполный перечень всех функций. Программа платная, продается несколько вариантов, в зависимости от функционала колеблется и стоимость. Подробнее ознакомиться можно здесь.
Парсер контента X-Parser
Основные функции программы также состоят их нескольких программных блоков.
- Парсер вылачи любых поисковых систем по ключевым запросам
- Парсер контента с любого сайта
- Парсер контента по ключевым запросам из выдачи любой поисковой системы
- Парсер контента по списку URLов
- Парсер внутренних ссылок
- Парсер внешних ссылок
Довольно многофункциональная программа, более подродно узнать всю информацию, вплоть до цены можно перейдя по ссылке.
Программа WebParser
Парсер WebParser представляет собой универсальную программу. основная функция которой — парсинг поисковых систем. Работает с ПС Google, Яндексом, Рамблером, Yahoo и некоторыми другими. анализирует движки (CMS) сайтов. Совместима со всеми версиями Windows, начиная с W2000. Болле полную информацию можно получить здесь.
Плагин WP Uniparser
Не забудем и плагин для WordPress WP Uniparser. О нем можно больше узнать, пройдя по этой ссылке.
Парсер «Магадан»
Парсер ключевых слов c романтическим названием «Магадан» создан именно для целевой обработки ключевых слов Яндекс.Директа. Полезен при составлении семантического ядра, подготовке рекламных компаний и для сбора и анализа информации.
В завершение стоит упомянуть о языке программирования для создания сайтов Parser, созданного на студии Артемия Лебедева и служащего для разработки сайтов. Этот язык будет несколько посложнее, чем обыкновенный HTML, но не требующий такой основательной подготовки, как, например, язык PHP.
Полезные Материалы:
inetmkt.ru