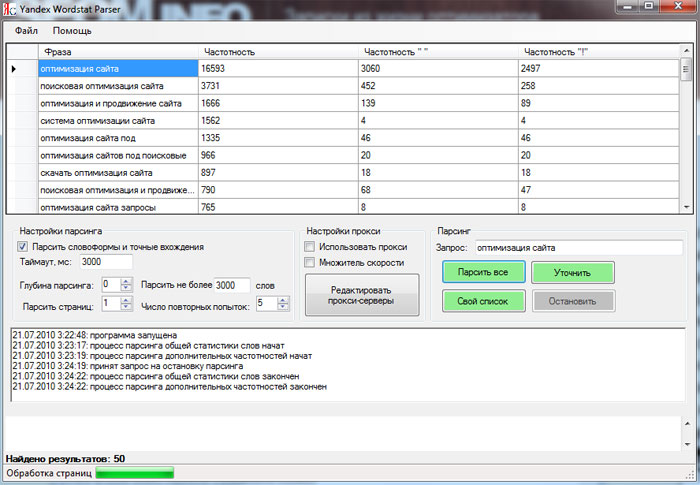
Парсер / wiki ТопЭксперт
Парсер (граббер) — это скрипт, предназначенный для автоматического наполнения сайтов текстовым контентом. Парсер в автоматическом режиме ищет в сети нужную текстовую информацию и, находя её, копирует на сайт, принадлежащий владельцу данного парсера. Таким образом, использование парсеров или грабберов избавляет веб-мастеров от рутинной работы по ручному наполнению своих ресурсов. Новый текстовый контент появляется на сайте автоматически, без вмешательства специалиста.
Примеры использования парсеров
- Актуальность и свежесть информации.
- Полное или частичное копирование материалов сайта и размещение этих материалов на своих ресурсах.
- Объединение потоков информации из разных источников в одном месте и ее постоянное обновление.
Главные требования поисковых систем к текстовому контенту:
- Актуальность
- Уникальность
Использование парсеров представляет собой беспроигрышный вариант. Качественно написанный и правильно настроенный скрипт обеспечивает наполнение сайта самыми свежими текстами. Речь идёт о новостях, но парсеры активно используются и для ведения блогов, где важным является постоянное обновление. С точки зрения актуальности у поисковых систем вопросов к сайтам не возникает.
Речь идёт о новостях, но парсеры активно используются и для ведения блогов, где важным является постоянное обновление. С точки зрения актуальности у поисковых систем вопросов к сайтам не возникает.
А вот об уникальности материалов, получаемых методом парсинга, говорить не приходится. Граббер не обрабатывает текст подобно тому, как это происходит при рерайтинге, а просто-напросто копирует чужой текст на страницы своего сайта. И вот здесь поисковые системы стоят на страже. Сайт, который пусть и совсем немного, но наполняется заимствованным контентом, никогда не получит сколько-нибудь значимых позиций в выдаче. Если же каждая страница ресурса будет содержать ворованные тексты, сайт могут даже исключить из поисковой базы.
Выделяют два вида парсинга в интернете, которые пользуются наибольшей популярностью:
- парсинг контента
- парсинг результатов выдачи поисковых систем.
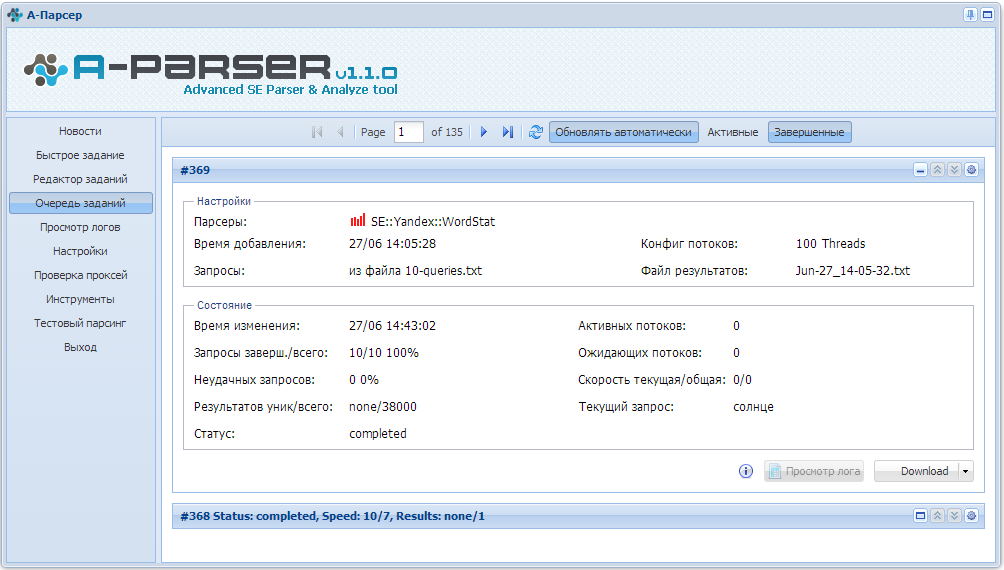
Программы-парсеры:
Выделяют следующие основные программы-парсеры:
- Универсальный парсер Datacol
Выполняет следующие функции:
- Результаты поисковой выдачи
- Сбор контента с заданных сайтов
- Сбор внутренних и внешних ссылок для интернет сайта
- Сбор графической информации, аудио контента, видео материалов
- Парсинг СЕО показателей сайтов с различных сервисов
- Различная информация с интернет ресурсов
Выполняет следующие функции:
- Парсер товаров
- Парсер интернет-магазинов
- Парсер картинок
- Парсер видео
- RSS парсер
- Парсер ссылок
- Парсер новостей
Выполняет следующие функции:
- Парсер выдачи любых поисковых систем по ключевым запросам
- Парсер контента с любого сайта
- Парсер контента по ключевым запросам из выдачи любой поисковой системы
- Парсер контента по списку URLов
- Парсер внутренних ссылок
- Парсер внешних ссылок
Выполняет следующие функции:
- Парсер поисковых систем.


Domen Monster Parser | Программы и Онлайн Сервисы для Интернет Маркетинга
Возможности:
- Поиск и парсинг неиспользуемых доменов
- Выгрузка полученных результатов в TXT
- Сбор доменов только в зоне .ru и .su
- Привязка доменов к DNS менеджеру
- Проверка не рабочих доменов
- Удаление доменов по списку из базы
+ Далее
Описание:
Существует очень большое количество доменов, которые не используются их владельцами. Домен всегда оплачивается на год как минимум и затем делегируется на хостинг или сервер для размещения на нем сайтов. Но хостинг нужно оплачивать ежемесячно. Если хостинг не оплачивается, то аккаунт на нем удаляется, а домен так и остается висеть на NS серверах этого хостинга.
Наш Парсер Доменов помогает находить такие домены, которые вы можете просто взять и прикрепить к своему аккаунту на хостинге или на сервере. И использовать эти домены например для Email рассылок или создания редиректов.
Вам нужно:
- ПК или ноутбук на операционной системе Windows 7/8/10
- Отключить ВСЕ антивирусники и встроенный защитник винды
- Установить программу на свой пк или VPS на Windows Server
- Изучить видео курс по тонкостям работы с программой (обязательно)
- Зарегистрировать хостинг или сервер куда вы будете добавлять домены
Видео курс:
5 Видео 00:56:00 Ч:М:С
Как работать с программой
2 Видео 00:30:47 Ч:М:С
- Видео обзор программы
Смотреть 00:09:46
Смотреть 00:21:01
Пример реального парсинга доменов
2 Видео 00:17:11 Ч:М:С
- Регистрация Сервера для парсинга доменов
Смотреть 00:04:33
- Парсинг и прикрепление доменов для редиректов Смотреть 00:12:38
Дополнительные уроки
1 Видео 00:08:02 Ч:М:С
- Как установить программу на Windows Server
Смотреть 00:08:02
+ Далее
Похожие
Об авторе
Рамиль Сабантуев
Пишу код, пишу много, иногда с ошибками.
Отзывы: 18 | Ученики: 775 | Разработки: 15
Подумав — решайся, а решившись — не думай
Отзывы учеников
5
1 Отзывы
- (0)
- (0)
- (0)
- (0)
- (1)
Отзывы
CURSOR Технологии
c++ — Лучшие практики написания парсера языка программирования
спросил
Изменено 9 лет, 11 месяцев назад
Просмотрено 13 тысяч раз
Существуют ли рекомендации, которым следует следовать при написании синтаксического анализатора?
- С++
- синтаксический анализ
- языки программирования
- соглашения
1
Принято считать, что следует использовать генераторы синтаксических анализаторов + грамматики, и это кажется хорошим советом, потому что вы используете строгий инструмент и, по-видимому, снижаете усилия и вероятность ошибок при этом.
Для использования генератора синтаксического анализатора грамматика должна быть контекстно-свободной. Если вы разрабатываете язык для анализа, вы можете контролировать это. Если вы не уверены, то это может стоить вам больших усилий, если вы начнете следовать грамматическому маршруту. Даже если на практике это не зависит от контекста, если только грамматика не огромна, может быть проще написать код рекурсивного приличного синтаксического анализатора.
Отсутствие контекста не только делает возможным создание парсеров, но и делает написанные вручную парсеры намного проще. В итоге вы получите одну (или две) функции на фразу. То есть, если вы правильно организуете и называете код, увидеть его не намного сложнее, чем грамматику (если ваша IDE может показать вам иерархию вызовов, вы сможете в значительной степени увидеть, что такое грамматика).
Преимущества:-
- Более простая конструкция
- Лучшая производительность
- Лучшее управление выходом
- Может справиться с небольшими отклонениями, напр. работать с грамматикой, которая не является на 100% контекстно-свободной
 работать с грамматикой, которая не является на 100% контекстно-свободной
работать с грамматикой, которая не является на 100% контекстно-свободнойЯ не говорю, что грамматики всегда не подходят, но часто преимущества минимальны и часто перевешиваются затратами и рисками.
(Я полагаю, что аргументы в их пользу нарочито привлекательны и что к ним существует общее предубеждение, поскольку это способ показать, что человек более грамотен в области компьютерных наук.)
Несколько советов:
- Знай свой грамматика — запишите в подходящей форме
- Выберите правильный инструмент. Сделайте это изнутри C++ с помощью Spirit2x или выберите внешние инструменты синтаксического анализа, такие как antlr, yacc или что-то другое, что вам подходит
- Вам нужен парсер? Может быть, regexp будет достаточно? Или, может быть, взломать Perl-скрипт, чтобы добиться цели? Написание сложных парсеров требует времени.
Не злоупотребляйте регулярными выражениями — хотя они и имеют свое место, они просто не в состоянии справиться с каким-либо реальным синтаксическим анализом. Вы можете подтолкнуть их, но в конечном итоге вы наткнетесь на стену или получите неуправляемый беспорядок. Вам лучше найти генератор синтаксического анализатора, который может обрабатывать больший набор языков. Если вы действительно не хотите углубляться в инструменты, вы можете взглянуть на парсеры с рекурсивным спуском — это действительно простой шаблон для написания небольшого парсера от руки. Они не такие гибкие и мощные, как большие генераторы синтаксических анализаторов, но у них гораздо более короткая кривая обучения.
Вы можете подтолкнуть их, но в конечном итоге вы наткнетесь на стену или получите неуправляемый беспорядок. Вам лучше найти генератор синтаксического анализатора, который может обрабатывать больший набор языков. Если вы действительно не хотите углубляться в инструменты, вы можете взглянуть на парсеры с рекурсивным спуском — это действительно простой шаблон для написания небольшого парсера от руки. Они не такие гибкие и мощные, как большие генераторы синтаксических анализаторов, но у них гораздо более короткая кривая обучения.
Если у вас нет очень жестких требований к производительности, постарайтесь разделить слои: лексер считывает отдельные токены, синтаксический анализатор упорядочивает их в дерево, затем семантический анализ проверяет все и связывает ссылки, а затем последний этап выводить все, что производится. Разделение различных частей логики облегчит поддержку в дальнейшем.
Сначала прочитайте большую часть книги о Драконе.
Парсеры не сложны, если вы знаете, как их создавать, но они НЕ из тех вещей, которые, если вы потратите достаточно времени, в конечном итоге добьетесь своего. Лучше опираться на существующую базу знаний. (В противном случае рассчитывайте написать его и выбросить несколько десятков раз).
Лучше опираться на существующую базу знаний. (В противном случае рассчитывайте написать его и выбросить несколько десятков раз).
Ага. Попробуйте сгенерировать, а не писать. Рассмотрите возможность использования yacc, ANTLR, Flex/Bison, Coco/R, генератор парсеров GOLD и т. д. Прибегайте к написанию парсера вручную только в том случае, если ни один из существующих генераторов парсеров не подходит вам.
- Выберите правильный тип парсера, иногда достаточно Recursive Descendant, иногда следует использовать LR-парсер (также есть много типов LR-парсеров).
- Если у вас сложная грамматика, постройте абстрактное синтаксическое дерево.
- Постарайтесь очень хорошо определить, что входит в лексер, что является частью синтаксиса и что является вопросом семантики.
- Попытайтесь сделать синтаксический анализатор как можно менее связанным с реализацией лексера.
- Предоставьте пользователю хороший интерфейс, чтобы он не зависел от реализации синтаксического анализатора.
Во-первых, не пытайтесь применять одни и те же методы для анализа всего. Существует множество возможных вариантов использования, от чего-то вроде IP-адресов (небольшой специальный код) до программ на C++ (для которых требуется промышленный синтаксический анализатор с обратной связью из таблицы символов) и от пользовательского ввода (который требует очень тщательной обработки). fast) компиляторам (которые обычно могут позволить себе потратить немного времени на синтаксический анализ). Возможно, вы захотите указать, что вы делаете, если хотите получить полезные ответы.
Во-вторых, имейте в виду грамматику для разбора. Чем она сложнее, тем более формальной должна быть спецификация. Попробуйте ошибиться в сторону слишком формального.
В-третьих, это зависит от того, что вы делаете.
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
языков программирования: парсинг
Языки программирования: ПарсингАбстрактный синтаксис
Абстрактный синтаксис — это представление программы, которая:
- абстрагирует ненужные детали конкретного синтаксиса;
- сохраняет только достаточно информации, чтобы мы могли назначить значение (семантика) терминов; а также
- соответствует структуре BNF языка.
Разбор означает интерпретацию входного потока как термов на подручном языке. Напомним, что мы рассматриваем язык синтаксиса как состоящего из трех слоев: лексических элементов, контекстно-свободного синтаксиса, и контекстно-зависимый синтаксис. Следовательно, мы будем анализировать язык рассматривая эти три слоя по отдельности.
Лексический анализатор или токенизатор принимает входной поток символов и разбивает его на токены. Для этого курса мы будем использовать Scheme tokenizer, чтобы сделать это за нас.
Синтаксический анализатор берет поток токенов, созданный лексическим анализатором, и
строит представление абстрактного синтаксиса программы, называемое абстрактное синтаксическое дерево или дерево разбора . Как видите,
термин синтаксический анализ часто (ab) используется для обозначения простой интерпретации
поток токенов в контекстно-свободный синтаксис.
Вернемся к примеру запроса. Запрос:
запрос ::= Слово
| НЕ запрашивать
| (запрос И запрос)
Чтобы разобрать запросы, мы должны исправить представление для токенов.
и представление для запросов, т.е. для реферата
синтаксис запросов. Для токенов,
мы будем использовать следующие представления:
Слово - символ
НЕТ НЕТ
И И
(-"("
) - ")"
Предположим, что у нас есть функция tokenize : ввод -> список токенов
который преобразует входной поток в список таких токенов.
Мы возьмем на себя функции сделай-Слово, сделай-Не и сделай-И
построить соответствующие представления запросов.Теперь мы можем написать функцию parse для разбора запросов. Эта функция примет список токенов в качестве входных данных и вернет пара абстрактного запроса и оставшаяся часть ввода.
(определить синтаксический анализ
(лямбда (вход)
(cond ((равно? 'НЕ (автомобильный ввод))
(let* ((r (анализ (ввод cdr)))
(q (автомобиль г))
(остальное (cdr r)))
(минусы(сделать-не д) остальное)))
((символ? (ввод автомобиля))
(минусы (сделать-Word (ввод автомобиля)) (ввод cdr)))
((равно? "(" (автомобильный ввод))
(let* ((r1 (анализ (ввод cdr)))
(q1 (автомобиль r1))
(остаток1 (cdr r1))
(остаток2 (cdr остаток1)); пропустить "И"
(r2 (разбор остальных2))
(q2 (автомобиль r2))
(остальное3 (cdr r2))
(остальное4 (cdr оставшееся3))) ; пропускать ")"
(минусы(сделать-И д1 д2)остальные4)))
(иначе (ошибка "Неверный ввод")))))
Это довольно просто, потому что грамматика для запросов — LL0. Но мы можем сделать это еще проще, воспользовавшись
встроенный синтаксический анализатор Scheme имеет для языка с именем s-выражений .
S-выражения определяются следующим образом:
Но мы можем сделать это еще проще, воспользовавшись
встроенный синтаксический анализатор Scheme имеет для языка с именем s-выражений .
S-выражения определяются следующим образом:
секс-выражение ::= #t | #f | номер | символ | символ | () | нить
| (половое выражение . половое выражение) | #(sexp*) | (секс*)
S-выражение вида (sexp .sexp) это пара; s-выражение вида #(sexp*) вектор; и (sexp*) — это список. Списки
представлено с помощью пар и нуля. S-выражения построены
на читается и (цитата sexp) ,
сокращенно 'sexp .Если мы теперь немного изменим синтаксис запросов, чтобы запросы являются подмножеством s-выражений, мы можем использовать s-выражение parser, чтобы сделать часть синтаксического анализа для нас. Давайте переопределим запросы следующим образом:
д ::= слово | (НЕ д) | (И q q)Обратите внимание на круглые скобки, которые теперь требуются вокруг запроса NOT.
 Наша новая функция разбора принимает список токенов и возвращает
просто проанализированный запрос:
Наша новая функция разбора принимает список токенов и возвращает
просто проанализированный запрос:
(определить синтаксический анализ
(лямбда (sexp)
(cond ((символ? sexp) (make-Word sexp))
((пара? секс)
(состояние ((равно? 'НЕ (автомобильное выражение))
(сделать-не (разобрать (кадр sexp))))
((равно? 'И (автомобильное секс-выражение))
(make-And (parse (caddr sexp)) (parse (caddr sexp))))
(иначе (ошибка "Неверный ввод"))))
(иначе (ошибка "Неверный ввод")))))
Давайте теперь создадим синтаксический анализатор для подмножества Scheme. мы рассмотрим следующее подмножество:
е ::= #t | #f | () | номер | ...
| Икс
| (лямбда (х*) е)
| (если е е е)
| (cond (e e)* [(else e)])
| (э э*)
Мы будем представлять токены точно так же, как Scheme представляет их в
s-выражения. Мы используем определить-запись средство для создания представлений абстрактного синтаксиса:(определить запись Const (значение)) (определить запись Var (имя)) (определить-записать Лам (формальное тело)) (определить-записать, если (проверить, а затем еще)) (определение-запись Cond (предложения еще)) (определить запись Ap (забавные аргументы))Каждое выражение
(define-record Foo (field1 . .. fieldN)) строит следующие процедуры:  .. fieldN))
.. fieldN)) мейк-фу , Фу? и Foo->field1 через Foo->fieldN .
Они называются конструктором, предикатом и селекторами (или средствами доступа).
для данных типа Foo .
Следующие тождества будут иметь место:(Foo? (make-Foo v1 ... vN)) = #t (Foo->fieldM (make-Foo v1 ... vN)) = vMдля значений
v1 ... vN .
Теперь давайте разберем Схему. (определить синтаксический анализ (лямбда (sexp) (cond ((член sexp '(#t #f ())) (сделать-константное секс-выражение)) ((или (число? секс-выражение) (строка? секс-выражение) (символ? секс-выражение)) (сделать-константное секс-выражение)) ((символ? секс-выражение) (сделать-Var секс)) ((пара? секс) (cond ((равно? 'лямбда (автомобильное выражение)) (сделать-лам (кадр sexp) (разобрать (каддр sexp)))) ((равно? 'если (автомобильное выражение)) (make-If (кадр sexp) (каддр sexp) (каддр sexp))) ((равно? 'cond (автомобиль секс)) .