
Multivk Parser — бесплатный парсер вк
JavaScript отключен. Для полноценно использования нашего сайта, пожалуйста, включите JavaScript в своем браузере.
- Автор темы Mr.Roman
- Дата начала
Mr.Roman
- #1
Multivk Parser — бесплатная программа для таргетинга целевой аудитории вконтакте.
Возможности:
Парсинг групп по кею
Парсинг админов групп
Парсинг всех участников групп
Поиск пересечений
Парсинг по активностям
Парсинг возлюбленных
Парсинг по городу+др
Парсинг по имени
Парсер телефонов вк
Система фильтров и отсева собранной аудитории позволяет максимально качественно отобрать вашу целевую аудиторию для таргетинга вконтакте.
Экспорт в xls и txt.
Здесь отвечать смогу редко, поэтому задавайте вопросы или пожелания через сайт программы. Перед пользованием программой ОБЯЗАТЕЛЬНО прочтите справку программы! Справка доступна по клику на кнопке «справка» в меню программы.
Скачать:
Ссылки могут видеть только зарегистрированные пользователи. Зарегистрируйтесь или авторизуйтесь для просмотра ссылок!
Mr.Roman
- #2
Mr.
 Roman
Roman
- #3
Mr.Roman
- #4
 youtube.com/embed/fLk8Eu3vcq8?wmode=opaque&start=0″ frameborder=»0″ allowfullscreen=»true»> Как быстро набрать друзей вконтакте на новом аккаунте
youtube.com/embed/fLk8Eu3vcq8?wmode=opaque&start=0″ frameborder=»0″ allowfullscreen=»true»> Как быстро набрать друзей вконтакте на новом аккаунте
Mr.Roman
- #5
 Также добавлены новые классные фильтры, при помощи которых вы сможете более гибко отсеивать целевую аудиторию.
Также добавлены новые классные фильтры, при помощи которых вы сможете более гибко отсеивать целевую аудиторию.Что можно сделать при помощи программы:
Парсер групп вк по ключевым словам и отсев групп по количеству участников
Парсер людей с открытой стеной
Парсер активных участников групп или по ключевым словам
Парсер всех участников групп вк
Поиск пересечений аудитории — вы можете найти людей из большого кол-ва групп, а уже потом искать пересечения аудитории в этих группах, при этом поиск участников не нужно производить заново.
Парсер по городу и дню рождения — можно парсить всех людей из данного города.
Парсер телефонов по списку id или по городу или по списку групп
Парсер возлюбленных — можно найти людей, у которых скоро день рождения и найти их возлюбленных, чтобы крутить рекламу на них.
Можно найти мам (или пап) с детьми для предложения детских услуг — товаров для детей, кружков, обучательных центров и т.д.
Парсер админов групп вк
Парсер авторов постов вк — хорошо подходит для набора друзей для новых аккаунтов, если искать авторов постов в группах «Добавь в друзья»
Парсер по семейному положению — можно найти всех людей города и отсеять нужных вам по семейному положению, полу, возрасту и т. д. Подойдёт для сайтов знакомств, брачных агентств и т.д.
д. Подойдёт для сайтов знакомств, брачных агентств и т.д.
Фильтр по кол-ву подписчиков позволяет найти самых популярных людей города, или из списка групп.
Mr.Roman
- #6
Таргетинг на мам с двумя детьми. Ищем молодых мамочек вконтакте
Как найти целевую аудиторию свадебного агентства Ищем невест в вк
wertttes
- #7
Быстрый парсер ВКонтакте пользуюсь.Mr.
Roman сказал(а): Multivk Parser — бесплатная программа для таргетинга целевой аудитории вконтакте. Возможности:
Парсинг групп по кею
Парсинг админов групп
Парсинг всех участников групп
Поиск пересечений
Парсинг по активностям
Парсинг возлюбленных
Парсинг по городу+др
Парсинг по имени
Парсер телефонов вкСистема фильтров и отсева собранной аудитории позволяет максимально качественно отобрать вашу целевую аудиторию для таргетинга вконтакте.
Экспорт в xls и txt.
Здесь отвечать смогу редко, поэтому задавайте вопросы или пожелания через сайт программы. Перед пользованием программой ОБЯЗАТЕЛЬНО прочтите справку программы! Справка доступна по клику на кнопке «справка» в меню программы.
Скачать:
Ссылки могут видеть только зарегистрированные пользователи. Зарегистрируйтесь или авторизуйтесь для просмотра ссылок!
Нажмите, чтобы раскрыть…

Ссылки могут видеть только зарегистрированные пользователи. Зарегистрируйтесь или авторизуйтесь для просмотра ссылок!
Для ответа нужно войти/зарегистрироваться
Поделиться:Facebook Twitter Reddit Pinterest Tumblr WhatsApp Электронная почта Ссылка
c++ — Анализ раздела ассоциации программы транспортного потока
спросилИзменено 5 лет, 8 месяцев назад
Просмотрено 1к раз
Я пытаюсь найти тип PID (АУДИО, ВИДЕО и т. д.), я проанализировал раздел заголовка транспортного потока и извлек PIDS. Пройдя стандарт транспортного потока, я узнал, что мне нужно проанализировать PAT, чтобы получить это. Раздел ассоциации программ, упомянутый в стандарте, приведен ниже. В приведенном ниже разделе, что на самом деле означает «N» в цикле for, может ли кто-нибудь помочь мне (см. Таблицу 2-25 в стандарте)
д.), я проанализировал раздел заголовка транспортного потока и извлек PIDS. Пройдя стандарт транспортного потока, я узнал, что мне нужно проанализировать PAT, чтобы получить это. Раздел ассоциации программ, упомянутый в стандарте, приведен ниже. В приведенном ниже разделе, что на самом деле означает «N» в цикле for, может ли кто-нибудь помочь мне (см. Таблицу 2-25 в стандарте)
программа_ассоциация_секция () {
table_id
section_syntax_indicator
'0'
сдержанный
section_length
transport_stream_id
сдержанный
номер версии
текущий_следующий_индикатор
section_number
last_section_number
для (я = 0; я < N; я ++) {
номер_программы
сдержанный
если (номер_программы = = '0') {
network_PID
}
еще {
программа_карта_PID
}
}
CRC_32
}
- c++
- c
- ffmpeg
- мультимедиа
Таблица ассоциаций программ ( PAT ) может содержать информацию о нескольких программах. Пакеты PAT всегда имеют PID 0x00 .
Чтобы узнать тип потока, вам нужно больше, чем PAT .
Анализ раздела программы в PAT даст PID таблиц карты программ ( PMT ) для каждой программы.
Вам нужны пакеты PMT , поскольку они содержат информацию об элементарных потоках каждой программы, включая тип потока.
Обзор можно найти здесь.
2Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google Зарегистрироваться через Facebook Зарегистрируйтесь, используя адрес электронной почты и парольОпубликовать как гость
Электронная почтаТребуется, но не отображается
Опубликовать как гость
Электронная почтаТребуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.
Что такое синтаксический анализатор языка программирования?
Прежде всего, исправление:
Алгоритмы синтаксического анализа не предназначены для языков программирования; они сделаны для грамматики языка.
Грамматика — это набор правил, которые определяют, как вы можете писать символы один за другим, чтобы сформировать допустимые предложения (то есть действительные для данной грамматики).
Например, английская грамматика говорит нам, что вы можете поставить символы 'y', 'o', 'u' один за другим и образовать действительный токен (слово «you»), и что если вы также добавите символов ' ', 'a', 'r', 'e', ' ', 'g', 'r', 'e', 'a', 't', вы составите правильное предложение (то есть, "ты замечательный"). Английская грамматика определяет английский язык.
Формальная грамматика работает аналогичным образом. Путаница возникает из-за того, что формальные грамматики используются в компьютерных науках для определения новых языков программирования, и поэтому эти два определения часто смешиваются. Но я надеюсь, что теперь различие ясно.
Но я надеюсь, что теперь различие ясно.
Теперь давайте ответим на вопрос .
Синтаксический анализатор — это алгоритм, разработанный для того, чтобы взять последовательность токенов и решить, допустима ли эта последовательность в рассматриваемой грамматике.
Этот ответ вызывает больше вопросов, как это часто бывает. Вот некоторые:
Откуда берется последовательность жетонов?
С более широкой точки зрения компилятор принимает на вход поток символов, например файл с исходным кодом программы, которую необходимо скомпилировать. Первый шаг в процессе компиляции, называемый лексическим анализом, заботится о создании последовательности токенов из всего потока символов. Затем такая последовательность передается парсеру, что является вторым этапом компиляции.
Парсер только решает, принять или отклонить последовательность токенов? Нравится ответ Да/Нет?
Строго говоря, так и есть. Парсер может «просто» принять решение о принятии или отклонении ввода. Однако для этого он строит некоторую структуру данных (древовидную) и выполняет над ней некоторые вычисления. Такая структура данных также полезна в оставшейся части процесса компиляции и, следовательно, не отбрасывается синтаксическим анализатором, а может считаться его выходными данными.
Парсер может «просто» принять решение о принятии или отклонении ввода. Однако для этого он строит некоторую структуру данных (древовидную) и выполняет над ней некоторые вычисления. Такая структура данных также полезна в оставшейся части процесса компиляции и, следовательно, не отбрасывается синтаксическим анализатором, а может считаться его выходными данными.
Что делает последовательность токенов действительной?
Все дело в соблюдении правил, установленных Грамматикой. Если жетоны размещены один за другим в допустимом порядке, то последовательность принимается. Однако грамматики — сложные звери, поэтому алгоритм принятия решения о достоверности последовательности токенов нетривиален. Если бы это было так, то эта статья остановилась бы здесь!
Я считаю, что ответы на данный момент дают довольно хорошее понимание того, что такое парсер, хотя и слишком общее. Давайте тогда углубимся в детали.
Различные типы алгоритмов синтаксического анализа
Написание алгоритма синтаксического анализа немного похоже на художественную работу. На самом деле, если вы погуглите или, может быть, поищите на GitHub, вы найдете тысячи программистов, которые создали свой собственный синтаксический анализатор для предметной области. Логика и алгоритмы этих парсеров в основном не следуют какой-либо схеме.
На самом деле, если вы погуглите или, может быть, поищите на GitHub, вы найдете тысячи программистов, которые создали свой собственный синтаксический анализатор для предметной области. Логика и алгоритмы этих парсеров в основном не следуют какой-либо схеме.
Несмотря на то, что вы можете создать парсер с нуля и без особых знаний теории, это не то, как вы должны это делать . Наука и теория существуют по уважительной причине: чтобы направлять ученых, а также инженеров и практиков. Это только мое мнение, конечно.
Таким образом, вместо того, чтобы сразу бросаться писать какой-то код, который может работать или не работать в конечном итоге, я всегда стараюсь не торопиться, чтобы исследовать проблему и посмотреть, каков уровень техники.
В случае с алгоритмами разбора грамматики оказывается, что современные алгоритмы довольно надежны и широко используются для очень большого класса грамматик (подробнее об этом последнем пункте через минуту).
Повторю еще раз, другими словами:
Вам действительно следует избегать написания синтаксического анализатора без предварительного изучения и понимания основных шаблонов синтаксического анализа, которые используются в самых известных компиляторах.
Таким образом, понять и изучить эти алгоритмы и предстоит нам!
А первая классификация
Книги и теоретики сначала делят алгоритмы синтаксического анализа на две очень большие группы. Я думаю, что знать такое определение крайне полезно: представьте, что вы разговариваете с коллегой о каком-то куске кода. Затем вы оба можете использовать этот общий язык, чтобы понять, что каждый говорит другому.
Эта первая классификация основана на том, как алгоритм строит дерево синтаксического анализа во внутренней памяти.
Прежде всего, позвольте мне повторить концепцию: синтаксические анализаторы строят так называемое дерево синтаксического анализа , которое представляет собой древовидную структуру данных, листья которой являются терминальными токенами грамматики, а промежуточные узлы в дереве — нетерминальными токенами. . Почему дерево? Это очень хороший вопрос, но позвольте мне пропустить его на минуту и вернуться к нему позже.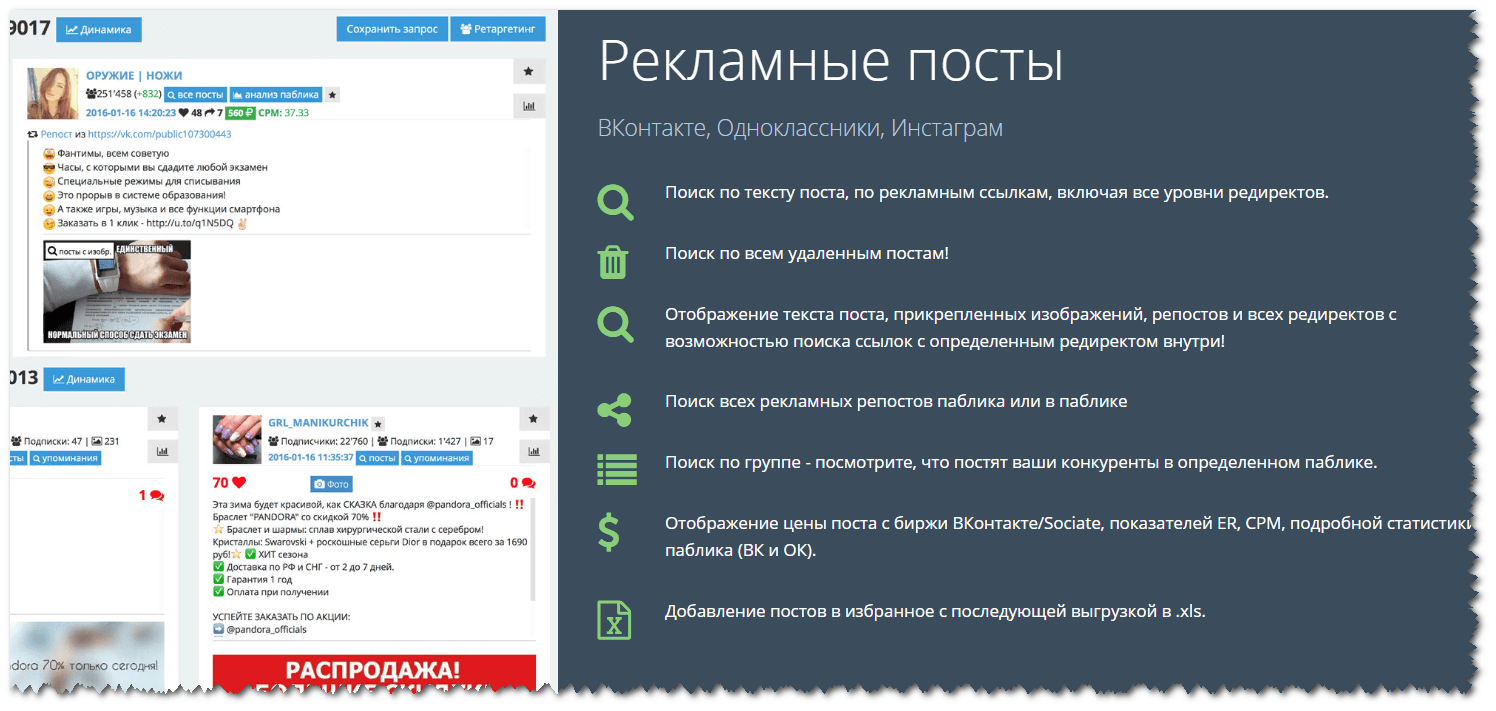 Просто предположим, что мы действительно хотим иметь древовидную форму.
Просто предположим, что мы действительно хотим иметь древовидную форму.
Если вы думаете о древовидной структуре данных, есть два разумных способа ее построения. Один — сверху (корень) к низу (лист), а другой — наоборот.
И действительно, алгоритмы синтаксического анализа в первую очередь классифицируются как:
- Нисходящие Парсеры,
- Восходящие Парсеры.
Что это означает на практике? Помните, что алгоритмы синтаксического анализа работают с определением грамматики. Таким образом, нисходящий синтаксический анализатор будет считать, что первая лексема, которую он увидит во входной строке, является начальным символом грамматики. Затем он получит все остальные токены как дочерние элементы начального символа.
Синтаксические анализаторы «снизу вверх» следуют обратной логике. Они будут предполагать, что первый символ, увиденный во входной строке, является листом дерева, и начнут строить дерево, решив, что является родительским узлом этого листа, и так далее, пока не доберутся до корня дерева.
Эта очень простая классификация на самом деле чрезвычайно важна. На самом деле парсеры «сверху вниз» и «снизу вверх» не отличаются «просто» тем, как они строят дерево. На самом деле они могут «делать» разные вещи.
В частности, и это очень важно помнить, восходящие алгоритмы более мощные, но и гораздо более сложные .
Что значит «более мощный»? Это означает, что они могут работать с большим набором грамматик.
Например, нисходящие парсеры не работают с леворекурсивной грамматикой, тогда как восходящие работают. Леворекурсивные грамматики — это такие грамматики, в которых продукционное правило для нетерминального символа A начинается с того же самого символа. Например, продукционное правило
А : Аб
сделает грамматику леворекурсивной, потому что для «замены» символа A в строке нужно начать с другого A (за которым следует b ).
Через минуту мы увидим, почему в таких случаях у нисходящих синтаксических анализаторов возникают проблемы.
Вторая классификация
Вторая классификация основана на том, как алгоритм расширяет узлы в дереве разбора .
Вообще говоря, расширить узел в дереве означает выяснить, каковы его связи (например, его потомки, если вы строите дерево сверху вниз). В дереве синтаксического анализа это означает понять, какое производственное правило нужно применить к этому узлу . Приведу конкретный пример.
Допустим, мы только начинаем процедуру синтаксического анализа и хотим сделать это нисходящим подходом. Следовательно, у нас будет только один узел в дереве, корень, с начальным символом грамматики. Допустим, этот символ S .
Грамматика, вероятно, будет иметь много правил производства для начального символа S , например
S : aAb | Ак | дБ.
Итак, первая цель нисходящего синтаксического анализатора состоит в том, чтобы выяснить, какое правильное производственное правило следует использовать для расширения корневого узла дальше вниз в его дочернем элементе. У него может быть три потомка в форме aAb или два потомка в форме
У него может быть три потомка в форме aAb или два потомка в форме Ac или dB .
Теперь, когда вы расширяете корневой узел, дерево синтаксического анализа будет иметь три или два узла, которые необходимо расширить дальше. Вопрос: какой взять для расширения?
Существует два распространенных подхода:
- Крайний левый синтаксический анализатор выбирает для расширения самый левый узел в дереве, который не является токеном терминала.
- Крайний правый синтаксический анализатор расширяет самый правый узел, который не является токеном терминала.
В этот момент возникает естественный вопрос: могут ли разные правила раскрытия привести к разным деревьям синтаксического анализа или нет.
Ответ в целом, да , может быть два разных дерева синтаксического анализа для одной и той же входной строки. Однако, и это очень важно, одна и та же строка может иметь несколько деревьев синтаксического анализа, только если грамматика неоднозначна.
Неоднозначность — это ПЛОХО , и на самом деле грамматики, разработанные для языков программирования, недвусмысленны. Это означает, что каждая строка, допустимая в этой грамматике, может иметь одно и только одно дерево синтаксического анализа. И, следовательно, мы должны получить один и тот же результат независимо от того, расширим ли мы самого левого или самого правого дочернего элемента.
Возврат или нет, вот в чем вопрос
Третья классификация основана на том, использует ли алгоритм синтаксического анализа возврат с возвратом или нет.
Я считаю, что знание этого различия очень полезно для понимания статей и чужого кода.
Backtracking — это общая техника программирования, которая (очень неформально) гласит: каждый раз, когда вам нужно принять решение о том, что делать в процедуре, сохраните текущее состояние, попробуйте один из вариантов, которые у вас есть, и, если это не удается, просто начните сначала. снова, возобновив сохраненное состояние и приняв другое решение в этот момент.
снова, возобновив сохраненное состояние и приняв другое решение в этот момент.
При синтаксическом анализе все решения заключаются в том, какое производственное правило выбрать, когда многие из них кажутся подходящими. Давайте посмотрим на конкретный пример.
Рассмотрим строку a = b + 1 , и предположим, что вы уже правильно проанализировали его до символа = (включено). Итак, синтаксический анализатор должен выяснить, что находится в правой части этого оператора присваивания.
В вашей грамматике, скорее всего, есть продукционные правила о назначениях, подобные следующим
assign_stm : ID '=' ID
| ID '=' выражение
| ID '=' ЧИСЛО Такое правило в основном говорит:
оператор присваивания может быть сделан только тремя способами: идентификатор, = знак и еще один идентификатор; идентификатор, знак = и целое выражение; идентификатор, знак = и число».
Обратите внимание, что приведенное выше правило также можно записать как
.assign_stm : ID '=' (ID | exp | NUM).
Таким образом, когда вы анализируете входную строку и получаете знак = , пора выяснить, какая из трех альтернатив является правильной. Если вы понятия не имеете об этом, то решение состоит в том, чтобы сохранить текущее дерево синтаксического анализа, выбрать один вариант из трех наугад и продолжать, доверяя этому решению. Если окажется, что это было неправильное решение (потому что вы зашли в тупик в процедуре синтаксического анализа), то вы должны вернуться: восстановить сохраненное дерево синтаксического анализа и сделать другой выбор.
Возвращение назад — очень мощная техника , потому что она гарантирует, что вы в конце концов примете правильное решение. Или, в случае парсера, что не было правильного решения и поэтому входную строку приходится отбрасывать (как при ошибке компиляции).
Однако, как это часто бывает, мощные приемы стоят еще и дорого . А обратная связь очень дорогая. Поэтому вы можете избежать этого в синтаксическом анализаторе.
А обратная связь очень дорогая. Поэтому вы можете избежать этого в синтаксическом анализаторе.
Цена отказа от поиска с возвратом заключается в том, что вы не можете предположить, что синтаксический анализатор сможет обрабатывать все типы грамматик. На самом деле, чтобы избежать возврата, синтаксический анализатор должен иметь некоторую подсказку о том, какое решение следует принять, когда доступно несколько производственных правил.
Эти «подсказки», необходимые синтаксическому анализатору, называются просмотр вперед . Проще говоря, алгоритму синтаксического анализатора позволено заглянуть немного дальше во входную строку, и он может решить, какое производственное правило продолжить, основываясь на токенах, которые он видит впереди.
Определения теперь немного усложняются, но позвольте мне попытаться обобщить их.
Если синтаксическому анализатору для успешного анализа грамматики (т. е. для анализа всех возможных входных строк) требуется просмотреть только одну лексему вперед, то говорят, что грамматика является LL(1).
- Первая буква L означает крайнее левое производное (которое я объяснил выше).
- Второй L означает просмотр вперед.
- Целое число в скобках — это количество маркеров, необходимых для просмотра вперед. В общем, если синтаксическому анализатору необходимо просмотреть k токенов, то говорят, что грамматика является LL(k).
Грамматики LL(k), очевидно, являются (небольшим) подмножеством всех формальных грамматик, которые вы можете создать. Вот что я имел в виду, говоря, что «возврат более мощный»:
- С возвратом вы можете проанализировать очень большой набор грамматик, но это займет много времени.
- Без него можно парсить ограниченный набор грамматик, но это будет намного эффективнее.
Рекурсия или нет, это другой вопрос
Последнее различие, которое я хочу сделать, потому что считаю его очень полезным, носит более технический характер и конкретно связано с реализацией алгоритма синтаксического анализа.
На самом деле хорошо известно, что каждый рекурсивный алгоритм может быть реализован с помощью нерекурсивной процедуры, обычно использующей стековую структуру данных (Last In First Out — LIFO).
Грамматики и языки программирования по своей сути рекурсивны , потому что продукционные правила используют друг друга. Таким образом, наиболее естественной реализацией почти каждого алгоритма синтаксического анализа является рекурсивная схема. Однако часто бывает удобно переключиться на эквивалентную итеративную процедуру (нерекурсивную) для целей управления памятью.
Память об этих четырех различиях очень помогла мне в изучении реализации парсеров.
сообщений на вынос
На этом этапе я считаю полезным повторить несколько ключевых понятий, чтобы не потерять нить темы, прежде чем продолжить. Сначала про парсинг вообще:
- Анализатор — это программное обеспечение, способное решить, соответствует ли строка правилам грамматики и, следовательно, принадлежит ли она языку.

- Парсинг — это второй шаг в процессе компиляции после лексического анализа. Фактически вход парсера — это последовательность токенов, сгенерированных лексическим анализатором.
- Чтобы решить, принимать или отклонять введенную строку, синтаксический анализатор строит в памяти дерево синтаксического анализа, листья которого являются конечными маркерами грамматики. Это дерево синтаксического анализа можно рассматривать как результат процесса синтаксического анализа (и, следовательно, входные данные для следующего шага компиляции).

Я также обсудил с вами основные отличия, которые могут существовать в парсере:
- Парсер может строить дерево разбора от корня к листьям, и в этом случае говорят, что он является нисходящим анализатором, или наоборот, и в этом случае он называется восходящим анализатором.
- Восходящий анализатор более общий, чем нисходящий, в том смысле, что он может обрабатывать больше типов грамматик. С другой стороны, нисходящие парсеры имеют гораздо более простую алгоритмическую структуру, их легче поддерживать.
- При построении Parse-Tree синтаксический анализатор может расширить либо самый левый неконечный узел дерева, либо самый правый. Самый левый, безусловно, самый распространенный подход.
- Полезные грамматики содержат множество правил производства, по несколько для каждого символа. В таком случае синтаксический анализатор должен решить, какое правильное производственное правило следует применить для расширения нетерминального узла. Самый общий подход к этому — возврат, который, однако, очень медленный. Альтернативой (более часто используемой) является написание синтаксического анализатора, работающего с LL(k) Grammars, поскольку при просмотре вперед k токенов откат не требуется.
- Хотя грамматики сильно рекурсивны, синтаксические анализаторы могут быть реализованы либо с помощью рекурсивного алгоритма, либо с помощью итеративного алгоритма. Последний часто использует структуру данных стека, чтобы итеративно имитировать рекурсию.
Думаю, этого достаточно для обзора алгоритмов синтаксического анализа! Далее я собираюсь более глубоко погрузиться в гайки и болты прототипа синтаксического анализатора .