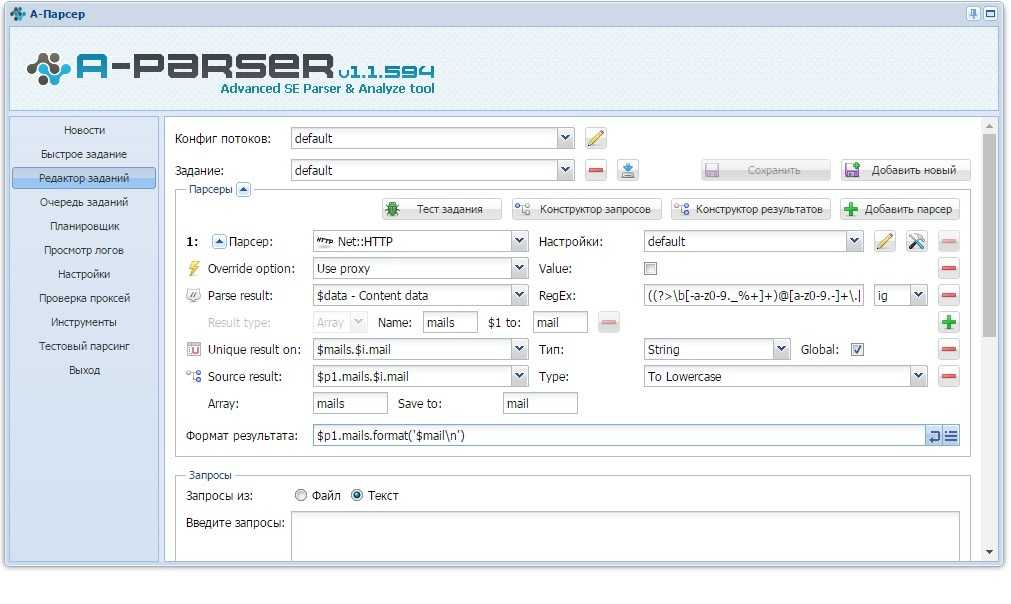
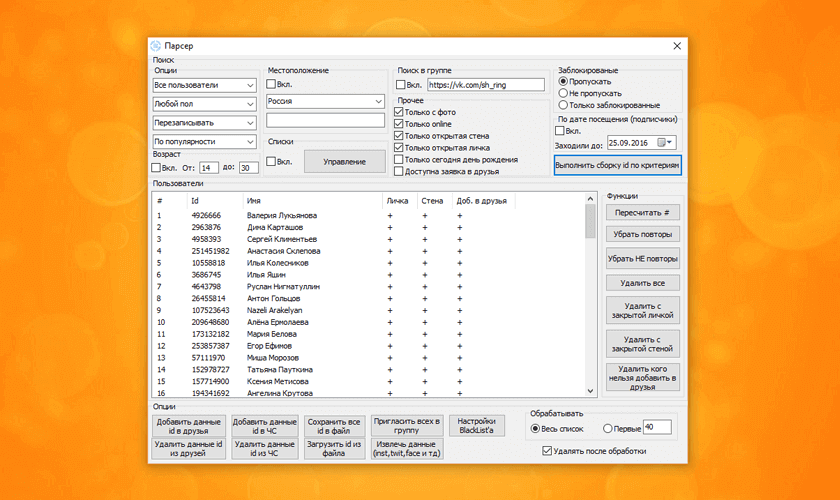
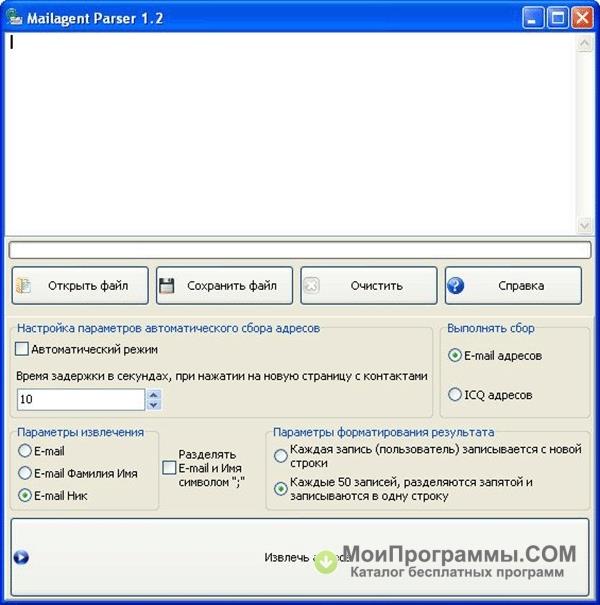
программы для парсинга контента и товаров с сайтов, как сделать своими руками
Мы увеличиваем посещаемость и позиции в выдаче. Вы получаете продажи и платите только за реальный результат, только за целевые переходы из поисковых систем
Заказывайте честное и прозрачное продвижение
Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
Есть приложения, которые позволяют автоматизировать множественные процессы интернет-маркетинга. Они необходимы многим бизнесменам, которые либо хотят использовать сбор информации с конкурирующих веб-источников, либо защитить себя от подобного «воровства» контента. В любом случае, работая с интернет-ресурсом важно знать о парсинге сайта – что это такое (мы расскажем простыми словами) и как настроить и пользоваться парсером данных.
- Parsing
- Законно ли использовать парсинг семантического ядра с сайтов конкурентов
- Сквозная аналитика
- Для чего нужен парсинг
- Достоинства применения программ для парсинга каталога товаров с сайта для интернет-магазина
- Ограничения: почему бывает сложно парсить
- Как работает парсинг и какой контент можно парсить своими руками или автоматически
- Алгоритм работы парсера
- Способы применения
- Как парсить данные
- Как спарсить цену
- Как парсить характеристики товаров
- Как спарсить отзывы (с рендерингом)
- Как парсить структуру сайта
Parsing
Данный механизм действует по заданной программе и сопоставляет определенный набор слов, с тем, что нашлось в интернете. Как поступать с полученной информацией, написано в командной строке, называемой «регулярное выражение». Она состоит из символов и задает правило поиска.
Как поступать с полученной информацией, написано в командной строке, называемой «регулярное выражение». Она состоит из символов и задает правило поиска.
Фактически понятие переводится с английского языка как семантический анализ или разбор. Но термин, применяемый в технологиях создания и наполнения вебсайта, имеет более широкое значение. Это процедура, действие, предполагающее многостороннее исследование страницы, документа, целого раздела на предмет нахождения лексических, грамматических единиц или иных элементов (не только текста, но и видео-, аудио-контента) с последующей систематизацией. Искомые сведения находятся и преобразуются, они подготавливаются для дальнейшей работы с ними. Еще можно сказать, что это быстрая оценка и скорая обработка интернет-ресурса, данных с него. Вручную подобный процесс занял бы много времени, но автоматизация его значительно упрощает.
Больше видео на нашем канале — изучайте интернет-маркетинг с SEMANTICA
Таким образом, парсер – это программа для парсинга ключевых слов сайтов. Она настраивается, в нее вводятся параметры поиска и прочие указания, чтобы получить семантическое ядро или анализ карточек товаров для интернет-магазина.
Она настраивается, в нее вводятся параметры поиска и прочие указания, чтобы получить семантическое ядро или анализ карточек товаров для интернет-магазина.
Второе название для процедуры – скраппинг, или скрейпинг от англоязычного «scraping». В ходе этого буквального «соскабливания» программное обеспечение заходит на вебсайт под видом обыкновенного пользователя и, используя скрипты, производит сбор данных.
Исходником может быть ваш собственный веб-ресурс (для аналитики и принятия последующих решений), сайт конкурента, страничка из социальных сетей и пр. Полученным результатом можно будет пользоваться в дальнейшем по усмотрению владельца. Приведем понятный пример. По такому принципу работают поисковые системы, когда они анализируют страницы на релевантность, наличие ключевых слов из запроса и соответствие тематике, а затем на основе полученных сведений автоматически формируется выдача.
Законно ли использовать парсинг семантического ядра с сайтов конкурентов
Посмотрим на это с такой стороны.
Незаконно:
- Взламывать ресурс и извлекать внутренние, конфиденциальные сведения, например, о пользователях интернет-магазина, совершенных ими покупках, персональных данных, записях в личных кабинетах и пр.
- Намеренные перезагрузки системы, то есть атаки DDOS. В ходе них на сервер оказывается чрезмерное искусственное давление, вычислительная система не может оперативно обрабатывать все полученные запросы и отказывается работать.
- Воровство уникального контента. На любую информацию может распространяться авторское право, в том числе, на изображения, фотографии и текст, если их подлинность была нотариально заверена.
Таким образом, никто вас не накажет за сам факт автоматизированного сбора данных с открытых источников. Но проблемы у многих пользователей парсеров начинаются в тот момент, когда нужно распоряжаться полученной информацией.
Но проблемы у многих пользователей парсеров начинаются в тот момент, когда нужно распоряжаться полученной информацией.
Сквозная аналитика
Это услуга, которая признана дать отчет о результативности интернет-рекламы. То есть с помощью сервиса собираются данные с рекламных площадок, связывает их со сведениями об обращениях и продажах. Анализируя это, можно понять, насколько эффективно было использование того или иного метода продвижения. Таким образом возможно выявить, какие каналы являются затратными, но не приносят достаточно выгодного результата, это помогает оптимизировать бюджет.
Такую услугу постоянной аналитики предлагает компания SEMANTICA в комбинации с комплексным продвижением сайтов. Клиенты этого агентства могут наблюдать за тем, какой результат он получает от того или иного действия, проекта. Все сведения предоставляются в виде отчетов, диаграмм.
Для чего нужен парсинг
Первое с чем сталкивается начинающий руководитель – вокруг много информации, слишком большое ее количество затрудняет возможность оперировать большинством ее массы вручную.
Именно здесь необходимы парсеры.
Их основная задача – автоматизация сбора и систематизации данных. Это помогает:
- Сделать анализ средних цен на рынке. Это очень большая работа, если проводить ее самостоятельно. Ведь в одном сегменте может быть представлена масса позиций и многочисленные конкуренты. Нужно не только узнать усредненные параметры, но и самые низкие границы, чтобы проводить акции, скидки, быть конкурентоспособным.
- Следить за изменениями, которые происходят в сфере. Это может быть включение новых товаров, смена цен.
- Периодически осуществлять генеральную «уборку» в собственном интернет-магазине. Особенно это необходимо для крупных ресурсов с обширным каталогом, где могут затеряться страницы с ошибками, дубли, незаполненные разделы и прочие недоработки.
- Наполнение карточками товаров. Можно просто копировать описания на аналогичные позиции у конкурентов, но это может вызвать неодобрение со стороны поисковых систем.
 Повысить уникальность помогает синонимайзер. Или еще одна возможность – с помощью парсера позаимствовать информацию с иноязычного ресурса, а затем провести ее через переводчик. Получится коряво, потом можно вручную исправлять. При этом быстро наполняется большой объем карточек.
Повысить уникальность помогает синонимайзер. Или еще одна возможность – с помощью парсера позаимствовать информацию с иноязычного ресурса, а затем провести ее через переводчик. Получится коряво, потом можно вручную исправлять. При этом быстро наполняется большой объем карточек. - Формирование баз клиентов. Данные берутся из относительно открытых ресурсов, архивов и резюме. Насколько этично пользоваться таким контентом – решать только вам.
 Повысить уникальность помогает синонимайзер. Или еще одна возможность – с помощью парсера позаимствовать информацию с иноязычного ресурса, а затем провести ее через переводчик. Получится коряво, потом можно вручную исправлять. При этом быстро наполняется большой объем карточек.
Повысить уникальность помогает синонимайзер. Или еще одна возможность – с помощью парсера позаимствовать информацию с иноязычного ресурса, а затем провести ее через переводчик. Получится коряво, потом можно вручную исправлять. При этом быстро наполняется большой объем карточек.Достоинства применения программ для парсинга каталога товаров с сайта для интернет-магазина
Сравним автоматический режим сбора с ручным, преимущества:
- скорость, возможность работать в любой период времени, даже круглосуточно, только бы было поставлено достаточно целей;
- заданные параметры могут быть настолько тонкими и разнообразными, насколько это требуется;
- не происходит ошибок из-за человеческого фактора – невнимательность, усталость вычислительной системе не известны;
- проверка может запускаться автоматически, например, если настроить еженедельную аналитику, полностью без вмешательства человека;
- можно выбрать удобный формат отчетности и менять его в один клик при необходимости – диаграммы, списки и пр. ;
- нагрузка на анализируемую страницу распределяется равномерно, чтобы вас не уличили в противозаконной атаке DDOS.
 ;
;Ограничения: почему бывает сложно парсить
Многие задумываются о том, как защитить сайт от парсинга, потому что не хотят терять уникальность контента. Поэтому используют различные программы, которые запрещают доступ к ресурсу ботам.
Запреты могут накладываться на работу по следующим аспектам:
- По user-agent. Клиентское приложение отправляет запросы, чтобы получить информацию о пользователе. Многие вебсайты блокируют парсеры, но это можно избежать, если настроить все как YandexBot или Googlebot.
- По robots.txt. Здесь еще проще. Прописываем в настройках, что нужно игнорировать этот протокол.
- По IP. Подозрительно, что с одного адреса с удивительной регулярностью поступают одинаковые запросы, действия. Решить это можно, используя VPN.
- По капче. Ряд ресурсов при подозрении на автоматизацию процесса предлагают ее пройти. Обучение системы отгадывать и распознавать картинку – это дорогая и длительная процедура.
 Обучение системы отгадывать и распознавать картинку – это дорогая и длительная процедура.
Обучение системы отгадывать и распознавать картинку – это дорогая и длительная процедура.Как работает парсинг и какой контент можно парсить своими руками или автоматически
Вам удастся получить любую информацию (текстовую или медийную), которая находится в открытом доступе, например:
- Названия товаров, карточек и категорий, в которые они обобщены.
- Характеристики. Особенно важно для бытовой техники, смартфонов.
- Стоимость, наличие скидки.
- Изменение товарного ряда, добавление новых позиций.
- Описание услуг или продаваемых предметов.
- Изображения. Но с ними следует работать аккуратнее, они могут быть авторскими, а значит, их использование уже будет незаконным.
Мы очень не рекомендуем перезаливать полученный текст на свою страничку в надежде, что он пройдет через фильтры поисковых систем. Скорее всего, они сразу вас забанят при попытке продвинуть такой неуникальный ресурс.
Алгоритм работы парсера
Тонкости процесса зависят от задачи, которая забивается в программы, но в остальном действия имеют следующую последовательность, схему:
- В приложение вбиваются параметры для поиска.
- По ним он осуществляет отбор вебсайтов.
- По завершении полученные сведения систематизируются в единую базу. Глубина также указывается.
- Формируется отчетность в наиболее удобном для вас варианте.
Способы применения
Парсинг для начинающих начинается с анализа конкурирующих фирм, чтобы сформировать собственную ценовую политику и план продвижения, стратегию интернет-маркетинга. А уже уверенные пользователи одновременно используют парсеры и для изучения конкурентов, и для аудита своего ресурса, для сравнения полученных сведений. Такая работа в тесной связке помогает поддерживать конкурентоспособность на высоком уровне.
Как парсить данные
Можно пойти двумя путями – купить программу, которых представлено большое множество, или создать приложение собственными силами фактически на любом из языков программирования.
Второе особенно актуально, когда нужно выставить только несколько параметров. Посмотрим теперь на особенности парсинга некоторых данных для «чайников».
Как спарсить цену
Определение ценовой политики – это самая ходовая задача для приложений. Для этого необходимо посмотреть код анализируемого товара и ввести его в программу. Она автоматически подтянет другие позиции, отвечающие запросу. Сэкономить время и повысить эффективность можно, если ограничить круг страничек. Например, так он не будет искать по разделу с информационными статьями. Добавлять стоит категории и сами карточки продукции. Прописываются ссылки на них в карте XML.
Как парсить характеристики товаров
Для этого понадобится вручную определить код у каждого продукта, который вам требуется. Затем можно подвязать полученные сведения с автозаполнением полей в вашем интернет-магазине. Особенно актуально подтягивать описание, когда вы занимаетесь реализацией техники, автомобилей, смартфонов. Часто характерные особенности берутся на сайтах производителей. Они не могут отличаться уникальностью, поэтому поисковики за это не ругаются.
Как спарсить отзывы (с рендерингом)
Процедура аналогичная – копирование кода, а затем его ввод в приложение для парсинга.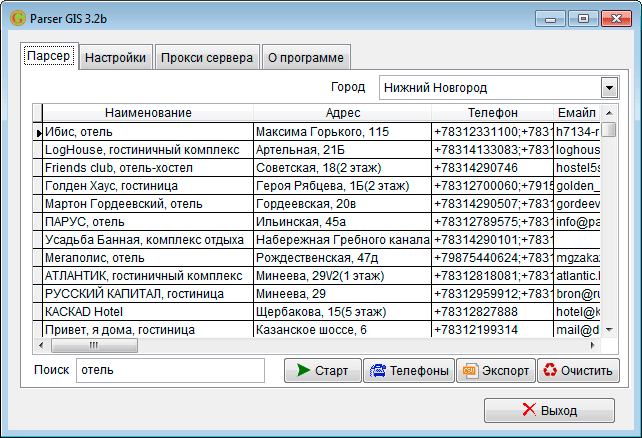 Но несколько отличаются последующие действия. Обычно комментарии открываются в тот момент, когда пользователь прокручивает страницу вниз, чтобы ознакомиться с ними. И тогда нужно снова залезть в настройки и изменить поле «Рендеринг» на JavaScript. В таком случае программа будет себя вести точно как юзер, прокручивая вниз контент до отзывов.
Но несколько отличаются последующие действия. Обычно комментарии открываются в тот момент, когда пользователь прокручивает страницу вниз, чтобы ознакомиться с ними. И тогда нужно снова залезть в настройки и изменить поле «Рендеринг» на JavaScript. В таком случае программа будет себя вести точно как юзер, прокручивая вниз контент до отзывов.
Как парсить структуру сайта
Это важное занятие, которым также часто занимаются новички. Основная задача – узнать, из каких разделов, подразделов и категорий состоит веб-ресурс, чтобы сделать аналогичные. Структурирование определяется, благодаря изучению breadcrumbs, или хлебных крошек в буквальном переводе. На самом деле термин подразумевает навигационную цепочку, которая выстраивается от начального элемента (корневого файла) до итогового.
Что нужно для этого сделать:
- навести курсор на одну из строчек навигации;
- скопировать код по аналогии с тем, как мы это делали с ценами;
- отправить его в приложение.
Данный алгоритм следует повторить и с другими элементами структуры.
Теперь вы знаете, как сделать парсинг сайта интернет-магазина самостоятельно. Но не всегда удается правильно распорядиться полученной информацией, а также быстро обойти все существующие ограничения на поиск. В таком случае мы рекомендуем обратиться к компании по продвижению вебсайтов. Специалисты агентства SEMANTICA производят анализ конкурентов на начальном этапе работы с проектом, а заказчик получает готовый результат в удобном формате.
Парсеры Сайтов — Что Это Простыми Словами
Глагол «to parse» означает структурировать, анализировать. В последнее время добавилось и значение «парсить». То есть, собирать и структурировать данные из сети интернет с помощью специальных программ.
Парсер — это программа для сбора и систематизирования информации по определенным параметрам.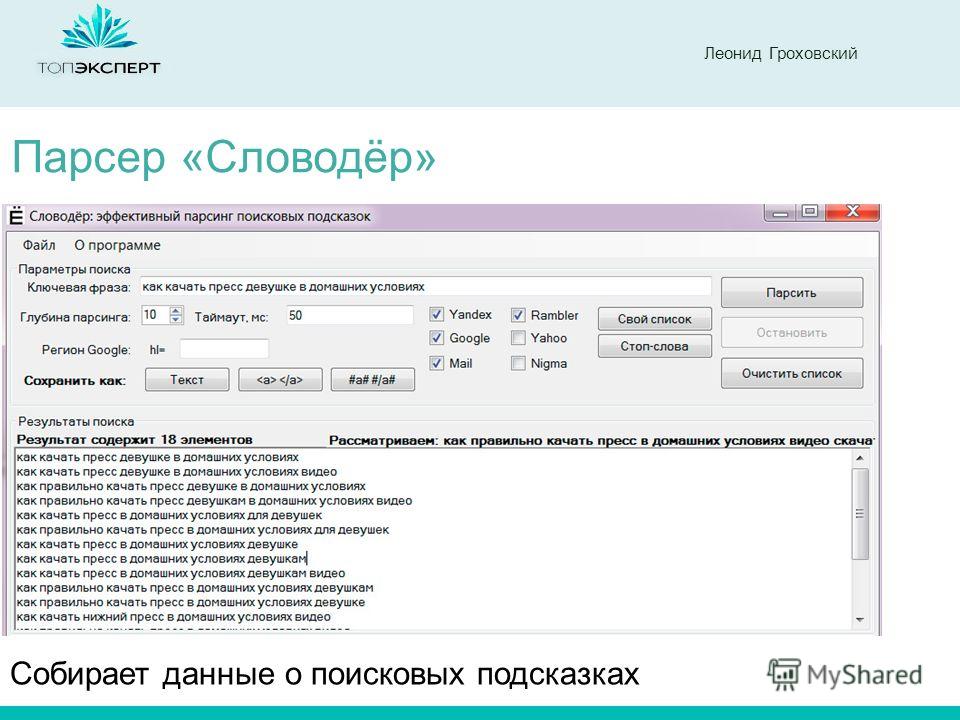
В каких случаях используется парсинг
Парсер используется:
Для исследования рынка, когда нужно получить информацию по товарам конкурентов, по запросам пользователей и другие данные, позволяющие понять ситуацию в определенном сегменте рынка.
Отслеживание цен в магазинах. Нужно, когда вы хотите держать цены не выше или не ниже, чем у конкурентов. Также в случае, когда цены зависят от цен другого ресурса. При смене цен вы должны обновить их у себя на сайте.
Парсинг каталога. Полностью скопировать все товары, описания и изображения без согласия собственника и добавить себе на сайт незаконно. Спарсить чей-то каталог вы можете только в целях ознакомления. А разместить можно только при условии, что владельцы контента согласны.
Можно парсить новости. Но в этом случае также нельзя выкладывать полностью скопированный текст. Его нужно изменить, добавить свои фото, либо указать ссылку на источник. Обычно все СМИ так и делают, просто следят за новостями друг друга и переписывают их.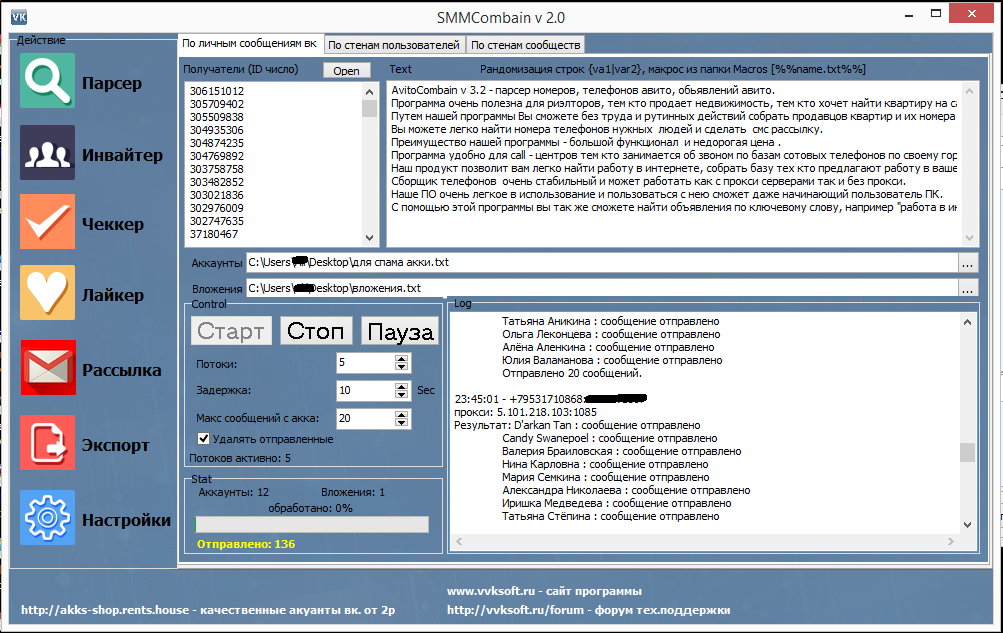
Парсеры применяются при переносе информации с одного сайта на другой, когда структура другого сайта сильно отличается от предыдущего, и нет возможности взять эту информацию из базы данных. Например, на новом сайте страницы товара имеют четкое разграничение по элементам. Все они заполняются отдельно в базе данных: вы вводите название товара, описание, затем в отдельное поле цену, затем задаете категорию, загружаете одну основную картинку. Потом в следующем поле добавляете дополнительные картинки. Отдельно указываете артикул, бренд. Характеристики заносятся в таблицу. А на предыдущем сайте весь этот контент не структурирован, это просто html-документ. При этом данных настолько много, что вручную переносить всю информацию займет очень много времени. Без парсинга в этом случае не обойтись.
Парсинг часто используется в продвижении сайта. С его помощью можно выполнять техническую оптимизацию:
— находить битые ссылки
— находить редиректы
— искать входящие и исходящие ссылки сайта
— находить дублированный контент
— проверять оптимальность мета-тегов
Как работает парсинг
Для начала нужно понять, что предстоит сделать.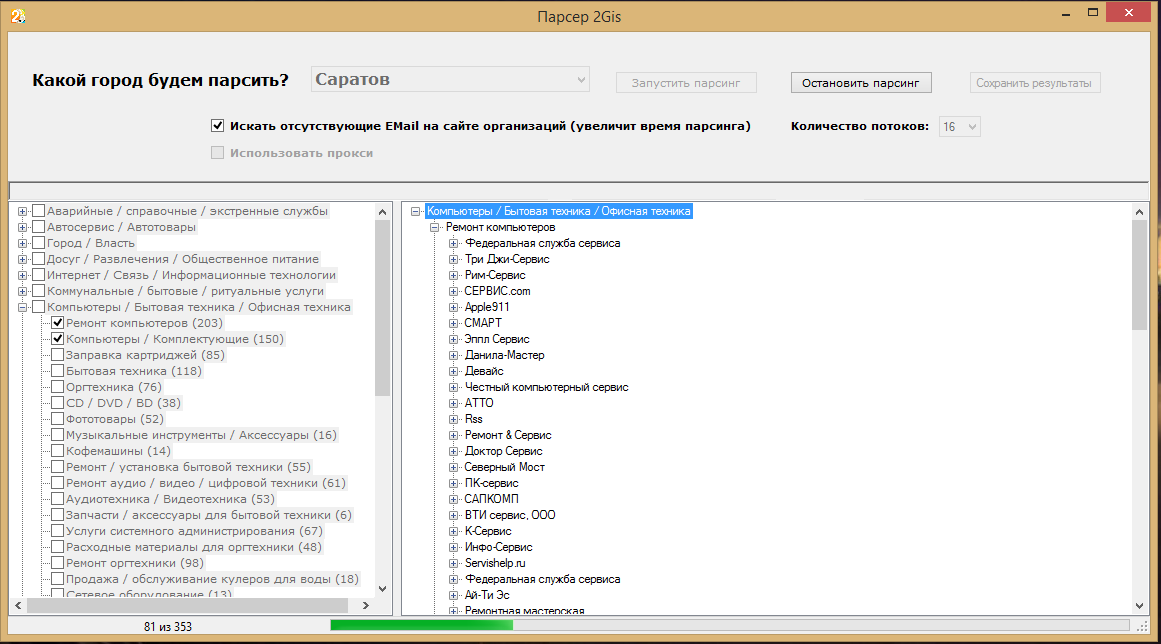 Задача «скопировать товары» слишком размыта. Уточняем, что нам нужно: название, артикул, характеристики, описание и все картинки.
Задача «скопировать товары» слишком размыта. Уточняем, что нам нужно: название, артикул, характеристики, описание и все картинки.
После этого заходим на сайт, с которого нужно спарсить товары. Смотрим html этого сайта. Ищем общий признак для каждого элемента, который нам необходимо взять. Это может быть класс, или id, или html-тег. Если такого признака нет, парсинг невозможен.
После этого разрабатывается скрипт, который соберет все данные по указанным общим признакам.
Затем этот скрипт должен обработать полученную информацию. Что ему нужно сделать с данными? Возможно, загрузить на сайт.
Успешно выполнив все задания, парсер выводит отчет и заканчивает работу.
Правомерность парсеров
Нельзя использовать чужой контент без согласия владельца контента. Если согласие не получено, вы можете использовать данные только для анализа информации. На основе полученных данных вы можете создать свой контент.
Парсер, заходящий на сайты, можно заблокировать. Многие хостинги делают это автоматически. Если вы пару раз спарсите контент с сайта, ничего не произойдет. Но если делать это постоянно, рано или поздно вас заблокируют. Варианты блокировки: блокировка юзер-агента, блокировка IP-адреса, использование невидимой капчи.
Если вы пару раз спарсите контент с сайта, ничего не произойдет. Но если делать это постоянно, рано или поздно вас заблокируют. Варианты блокировки: блокировка юзер-агента, блокировка IP-адреса, использование невидимой капчи.
Однако нужно помнить, парсинг вашего сайта происходит в любом случае. Как минимум, это будут поисковые боты, считывающие контент. А этот процесс важен для успешного продвижения.
Сам парсинг законен. Ведь парсят те ресурсы, к которым есть доступ. Это значит, что информацию с сайта можно получить вручную. Можно сохранить сразу всю страницу целиком, можно ее сфотографировать, можно просто выделить и скопировать текст. Однако чужой контент нельзя использовать без разрешения.
Существуют ли программы для парсинга?
На этих сайтах можно скачать бесплатные программы для парсинга:
Scrapy
https://scrapy.org
Beautiful Soup
https://www.crummy.com/software/BeautifulSoup
Octoparse
https://www.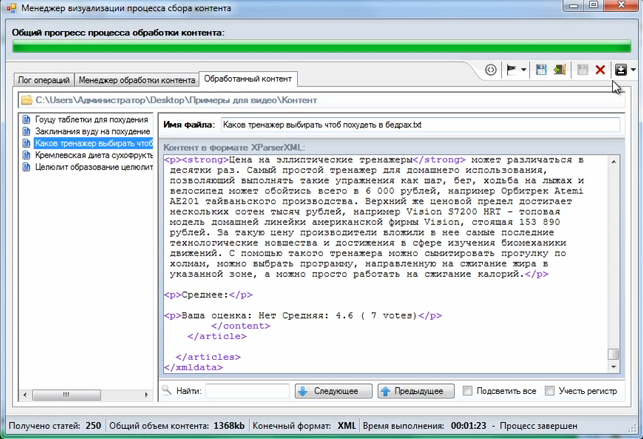 octoparse.com
octoparse.com
Parsehub
https://www.parsehub.com
Apify
https://apify.com
PySpider
http://docs.pyspider.org/en/latest
Spinn3r
http://docs.spinn3r.com
Ficstar
https://ficstar.com
Frontera
https://github.com/scrapinghub/frontera
Scrapinghub Platform
https://www.scrapinghub.com/platform
Visual Web Ripper
http://visualwebripper.com
Mozenda
https://www.mozenda.com
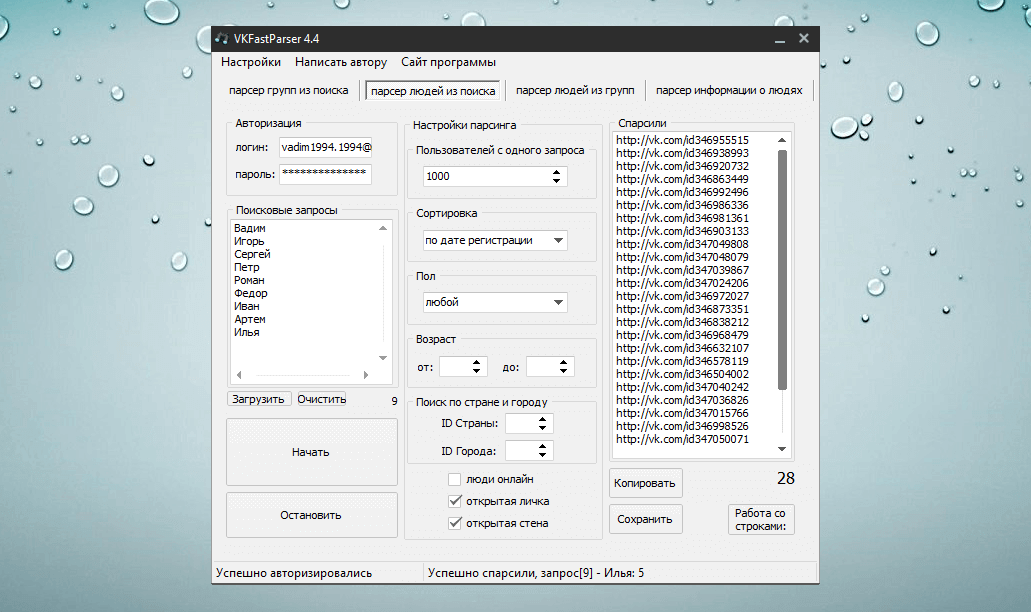
Парсеры соцсетей: Вк, Инстаграм, Одноклассники
Парсеры соцсетей применяются для получения данных:
— Логин, Email
— Личные данные профиля – интересы, дни рождения, места работы и т.д.
— Статистика — количество постов, подписчиков, друзей
— Ссылки на группы и профили
Можно спарсить всю информацию, к которой есть доступ. А именно – ту, которую вы видите в браузере.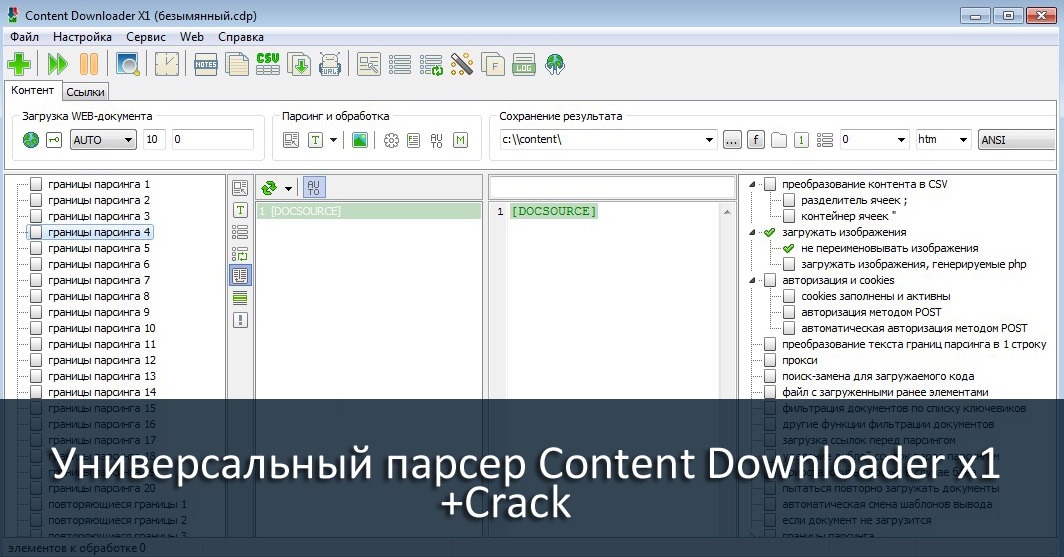 Если у пользователя закрытый профиль, и вы не видите, чем он делится со своими подписчиками, получить эти данные с помощью парсинга нельзя.
Если у пользователя закрытый профиль, и вы не видите, чем он делится со своими подписчиками, получить эти данные с помощью парсинга нельзя.
Однако для соцсетей есть более удобные методы. Дело в том, что почти все социальные сети предоставляют API для веб-разработчиков. Вы можете обратиться к какому-либо методу API и получить нужную информацию.
У Вконтакте очень удобные и многофункциональные методы API. Можно работать с фотографиями, искать группы, получать количество участников в группах, получать количество друзей и подписчиков пользователя. С API вы можете получить и структурировать любую информацию, к которой открыт доступ.
https://vk.com/dev/methods
API Одноклассников имеет мало методов. Нет очень важных решений. Например, мне потребовался поиск групп по запросу. В API есть метод поиска, и он ищет все, кроме групп. Увы. Причем, в описании метода сказано о такой возможности, но на деле это не работает. Не знаю, как сейчас обстоят дела. Тогда мне пришлось создать скрипт в браузере, который имитирует поиск и получает список групп. То есть, скрипт просто за меня вводил фразы поиска, переходил по ссылкам постраничной навигации, если результатов было много, и сохранял названия и адреса групп.
То есть, скрипт просто за меня вводил фразы поиска, переходил по ссылкам постраничной навигации, если результатов было много, и сохранял названия и адреса групп.
https://apiok.ru/dev/methods/rest
Инстаграм
Можно работать с профилями пользователей, получить альбомы, фото и видео.
https://developers.facebook.com/docs/instagram-basic-display-api
Все, что нельзя сделать с помощью API, будет сделано с помощью парсинга
Парсеры досок объявлений: Авито и Юла
В основном нужны уведомления о новых объявлениях. Таким образом вы первым узнаете о продаже нужного товара и бронируете его.
Парсер может проверять объявления часто, например, раз в 3 секунды. Парсер группирует объявления, фильтрует цены, отсекает объявления без фото.
Кроме объявлений, также можно парсить: телефоны продавцов, цены товаров, названия и описания товаров, изображения.
Что такое парсинг и парсер?
В чем разница между понятиями парсер и парсинг? Парсинг (Parsing) – это процесс синтаксического анализа, во время которого полученные данные разбиваются на более мелкие элементы для облегчения перевода их на другой язык. Анализатор – это компонент компилятора или интерпретатора, своего рода переводчик, который принимает входные данные, программные инструкции и разбивает их на слова, символы, т.е. на токены (наименьшую единицу языка программирования). Таким образом происходит лексический анализ.
Анализатор – это компонент компилятора или интерпретатора, своего рода переводчик, который принимает входные данные, программные инструкции и разбивает их на слова, символы, т.е. на токены (наименьшую единицу языка программирования). Таким образом происходит лексический анализ.
Программа обрабатывает, анализирует полученную информацию, проверяет данные синтаксиса, чтобы удостовериться, что их достаточно для построения структуры синтаксического древа, что они образуют осмысленное выражение и что они размещены в конкретном необходимом порядке.
Полученные таким образом токены используются в программировании, например, они являются входными символами для парсера. На основе этих данных и базируется вся его работа. Данная математическая модель может быть написана любым из языков программирования, например, Python, PHP, Perl или др. Затем из полученных данных происходит генерирование кода или сортировка по определенным критериям. То есть программа для парсинга это и есть парсер.
Парсер — это программное решение или скрипт, который предназначен для поиска, сбора информации с различных веб-ресурсов в сети, а также извлечения данных, их автоматической обработки и анализа.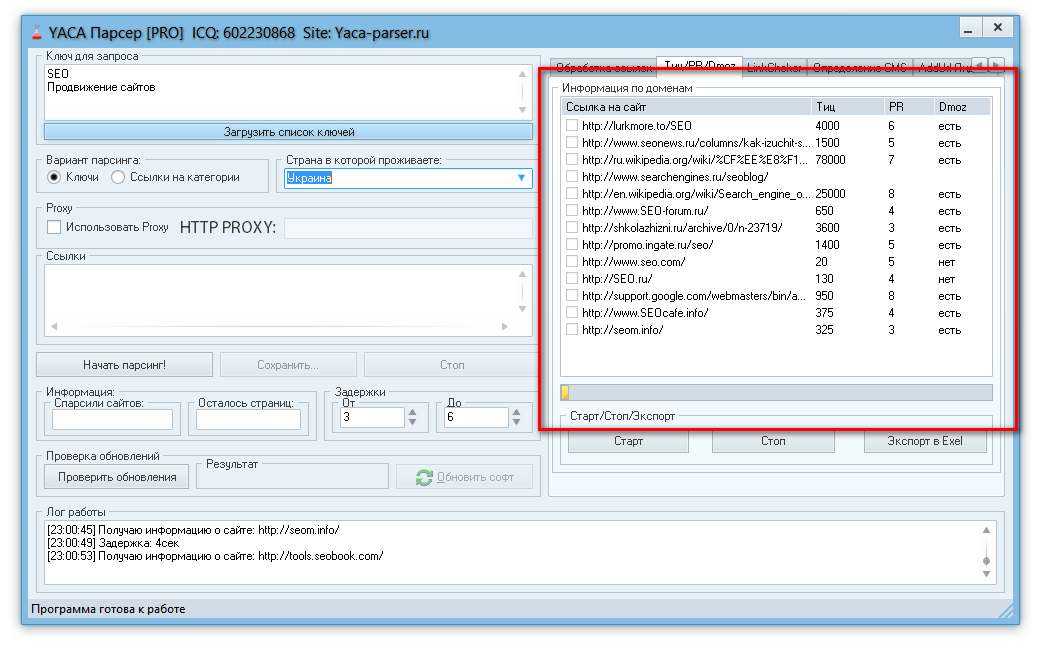
Итак, парсер – это программное решение, парсинг – сам процесс. А парсить – это собирать и систематизировать информацию со сторонних ресурсов с помощью специальных программ, автоматизирующих процесс. С терминами разобрались, идем дальше.
Зачем нужны эти парсеры?
Все эти программы действуют практически по одному алгоритму и сфера их применения очень широка. С помощью подобных программ, сервисов или скриптов, можно выполнить:
Парсинг метаданных и комплексный анализ сайта. Благодаря этому существенно сокращаются трудозатраты СЕО специалистов, так как есть возможность парсить title, description и многое другое. Возможно достаточно быстро провести технический аудит, обнаружить неработающие ссылки, дубли страниц, ошибку 404, проверить коды ответа и др. Кроме того, подобные программы позволяют достаточно просто находить ключевые ошибки во внутренней оптимизации ресурса.
Парсинг цен. Это очень востребованная услуга, так как благодаря этой процедуре возможно отслеживать цены конкурентов, сопоставлять их с вашими и корректировать их при необходимости.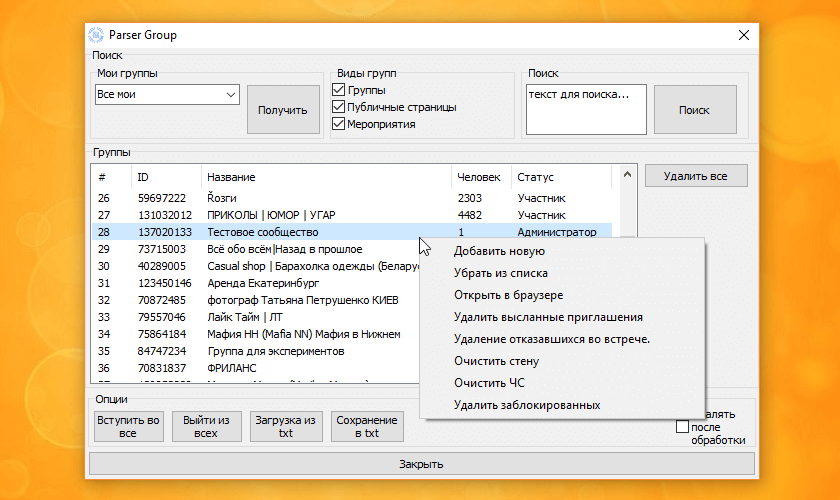 Или же актуализировать свои цены в соответствии со стоимостью товара у вашего поставщика. Подобные услуги актуальны и востребованы не только для интернет-магазинов, но и могут пригодиться для компаний, работающих в сфере услуг.
Или же актуализировать свои цены в соответствии со стоимостью товара у вашего поставщика. Подобные услуги актуальны и востребованы не только для интернет-магазинов, но и могут пригодиться для компаний, работающих в сфере услуг.
Парсинг каталога. Это идеальный инструмент для заполнения/пополнения/обновления вашего каталога информацией. Процесс происходит автоматизировано, а не в ручном режиме, и все данные о товарных позициях, включая артикул, название продукции, описание, изображение, стоимость и т.д. загружаются с сайта вашего поставщика. Это не только существенно экономит время, но исключает любого типа ошибки, возникающее по причине человеческого фактора. При этом возможно добавлять свою наценку (если парсите товар с оптовыми ценами), а также настраивать автоматический сбор/обновление данных по графику. Подобные услуги необходимы при открытии торгового представительства в интернете, заполнения сайта по продаже недвижимости или пополнения сайта-каталога новыми объектами.
Кроме того, подобные программы возможно установить на веб-ресурс производителя и каждый, интересующийся товарами этой компании, сможет воспользоваться парсером прямо на сайте, и выгрузить весь ассортимент продукции на свой ресурс.
Где используется парсинг?
Он широко используется в различных технологиях: в языках программирования, моделирования, в базах данных, в качестве интерактивного языка, HTML, XML, для протокола HTTP и др.
Как найти оптимальный для себя парсер?
На сегодняшний день у вас есть несколько вариантов:
1. Заказать парсер у компании, специализирующейся на их разработке.
2. Воспользоваться облачными сервисами. Можно использовать готовые программы в сети, они есть как бесплатные, так и платные, при этом ничего не нужно скачивать и устанавливать на свой компьютер. Весь процесс проходит в облачном сервисе, а вам остается только скачать результат. Бесплатный вариант подойдет далеко не всем, так как он ограничивает вас либо по времени, либо по объему данных.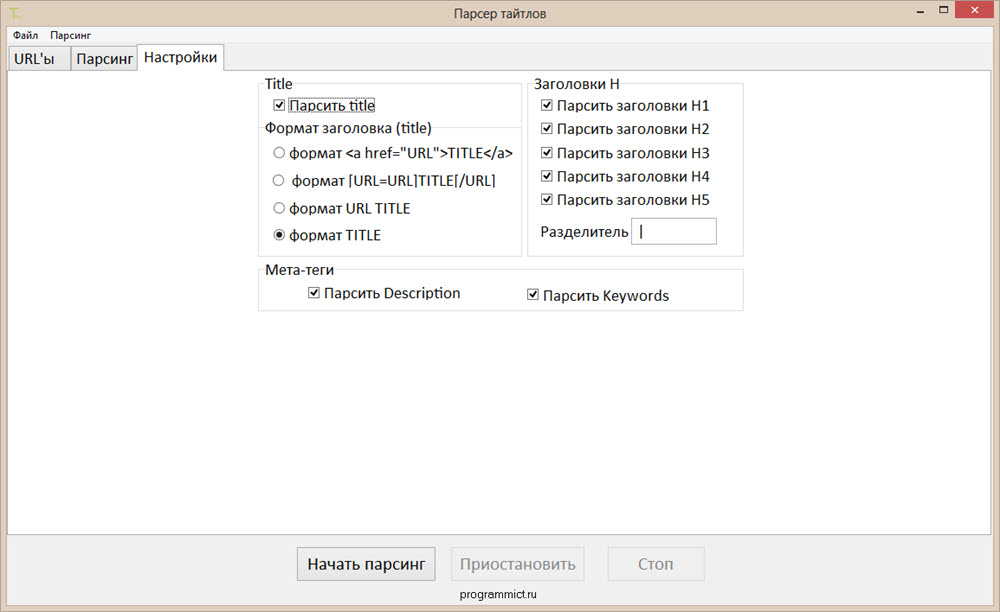
3. Использовать десктопные программы. Подобные платные инструменты разработаны под Windows на macOS и их необходимо запускать с виртуальных машин, обычно это сложные программы с мощным функционалом. Некоторые из них также можно запускать с внешнего накопителя. Но в любом варианте, коробочная версия – это программа, которая устанавливается на ваш компьютер, и вы работаете с ней в окне.
4. И последний вариант. Если у вас в компании работает программист, то он может разработать программу «заточенную» под нужды вашего предприятия. Но к сожалению, это не всегда выполнимо, так как вовсе не обязательно, что в штате организации присутствует IT-специалист.
Советы по выбору парсера
Важно сразу отметить, что, если вам необходимо производить сложную обработку данных или у вас крупный проект, и необходимо парсить большие объемы, то для этих задач оптимально будет разработка собственного парсера под ваши конкретные цели.
В остальных случаях при выборе программы вам необходимо определить для себя:
1. Цели и задачи парсера. Какая информация вас интересует, и для чего она вам нужна? Это могут быть: данные для наполнения/обновления каталога, анализ цен с нескольких сайтов в вашей нише, комплексный аудит сайта, в том числе и конкурентов и т.д.
Цели и задачи парсера. Какая информация вас интересует, и для чего она вам нужна? Это могут быть: данные для наполнения/обновления каталога, анализ цен с нескольких сайтов в вашей нише, комплексный аудит сайта, в том числе и конкурентов и т.д.
2. Объем. Важно определиться в каком виде информацию вы хотите получать, и какой объем данных вы планируете парсить.
3. Регулярность. Важно учитывать, как часто вы собираетесь парсить данные. Это будет происходить регулярно (с определенной периодичностью раз в день/неделю/месяц) или единоразово.
4. Перед тем как приобретать ту или иную программу, выберите несколько инструментов и попробуйте поработать в их демо-версиях. Так вы сможете их оценить на практике и решить подходят ли они для решения ваших задач.
5. Цена – качество – удобство – полезность. Определите для себя наиболее подходящий для вас сервис по этим критериям.
Важно отметить, что как существует серое и белое продвижение, так есть серый и белый парсинг. Все вышеперечисленные действия относятся к последнему – законному способу добычи информации. К серому же относят, например, парсинг контента целиком с сайта конкурента или сбор с различных сервисов персональных данных для организации спам-рассылок или прозвонов. Мы занимаемся сбором информации, находящейся только в открытом доступе и не нарушаем законы. И немного подробнее о легальности этого процесса.
Все вышеперечисленные действия относятся к последнему – законному способу добычи информации. К серому же относят, например, парсинг контента целиком с сайта конкурента или сбор с различных сервисов персональных данных для организации спам-рассылок или прозвонов. Мы занимаемся сбором информации, находящейся только в открытом доступе и не нарушаем законы. И немного подробнее о легальности этого процесса.
Парсить – это законно?
Согласно статье 29. 4 Конституции РФ каждый имеет право свободно искать, получать, передавать, производить и распространять информацию любым законным способом. Исключением являются сведения, составляющие государственную тайну, что определяется федеральным законом. Таким образом, в законодательстве РФ нет запрета на сбор открытой информации в интернет-сети.
Например, вам нужно спарсить цены с ресурса вашего конкурента. Вся эта информация есть в открытом доступе, и в принципе, вы можете в любой момент посетить этот веб-ресурс и переписать с него цены вручную.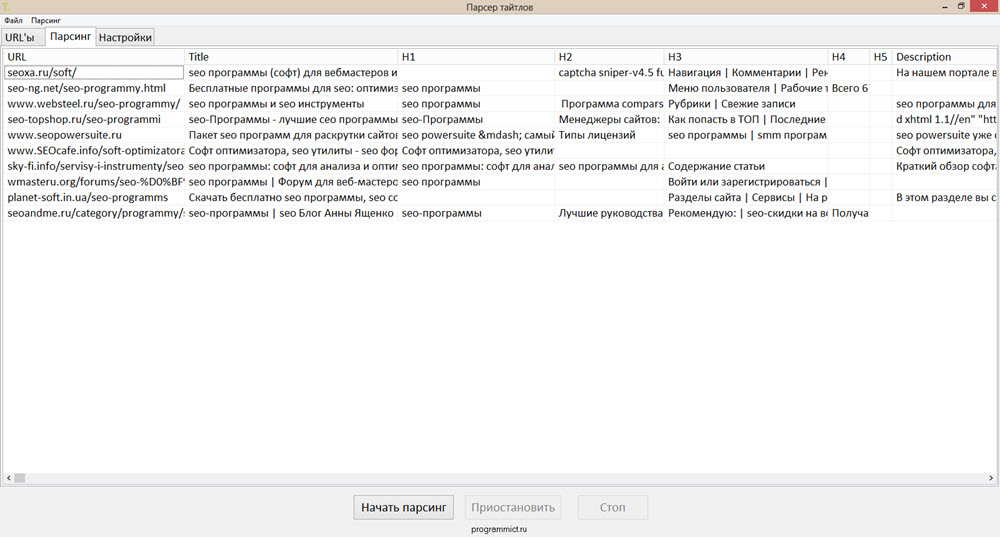 Но с помощью парсинга вы просто делаете это автоматизировано. Но, совсем другая история, если вы собираете персональные данные пользователей и хотите использовать их для таргетированной рекламы или спам-рассылок. Согласно закону о защите персональных данных делать это запрещено, и, соответственно, использовать подобную информацию незаконно. Также незаконно использовать парсинг с целью организации DDOS-атаки.
Но с помощью парсинга вы просто делаете это автоматизировано. Но, совсем другая история, если вы собираете персональные данные пользователей и хотите использовать их для таргетированной рекламы или спам-рассылок. Согласно закону о защите персональных данных делать это запрещено, и, соответственно, использовать подобную информацию незаконно. Также незаконно использовать парсинг с целью организации DDOS-атаки.
Подводя итого, стоит отметить, что преимущества использования парсинга очевидны, особенно, если его сравнивать его с ручным сбором данных. Это быстрый и эффективный процесс, который полностью исключает ошибки в отчетах, и предоставляет огромные возможности в его настройке, так, например, можно задать множество параметров для составления выборки или настроить периодичность сбора данных и многое другое.
Что такое анализ данных? | Программное обеспечение TIBCO
Анализ данных — преобразование данных из одного формата в другой. Широко используемый для структурирования данных, он обычно делается для того, чтобы сделать существующие, часто неструктурированные, нечитаемые данные более понятными.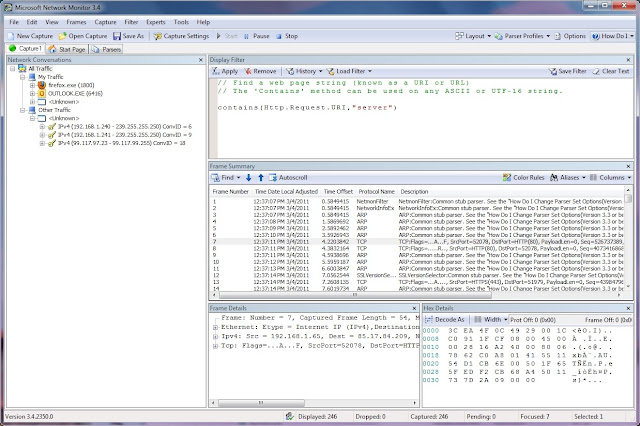
Например, предположим, что пользователь просматривает HTML-файл, который может быть сложным для чтения и понимания. Синтаксический анализ данных поможет преобразовать их в более читаемый формат, например, в обычный текст, который зритель сможет легко понять.
Этот процесс используется в различных отраслях, от финансов до образования и от спорта до розничной торговли, для извлечения необходимой информации без ручного труда для получения правильных данных.
Необходимость синтаксического анализа данных
Подобно естественным языкам, компьютерам часто требуется перевод для эффективного общения. Поэтому, чтобы помочь машинам понять строку данных, которую они не распознают или не понимают в текущем формате, используется синтаксический анализ для преобразования данных в форму, которую устройство может понять и использовать. Это похоже на предоставление перевода, чтобы говорящий по-английски мог понять текст на другом языке.
Анализ данных обычно требуется для преобразования неструктурированных и неразборчивых строк данных в структурированные и простые наборы, понятные компьютеру.
Экономия времени и средств
Синтаксический анализ данных позволяет компаниям лучше структурировать данные, чтобы обеспечить улучшенный доступ и читабельность. По мере анализа данных сотрудники могут быстрее понять их и сэкономить время на выполнении своих обязанностей. По мере сокращения оплачиваемых часов организация может сэкономить на стоимости найма и заработной плате.
Повышение прозрачности
Анализ данных помогает предприятиям улучшить видимость. Поскольку данные преобразуются в более разборчивый формат, пользовательский интерфейс переключается на более удобный формат. Это позволяет пользователям просматривать всю необходимую информацию, снижая вероятность пропуска каких-либо ключевых точек данных.
Понимание процесса анализа данных
Анализ данных выполняется с помощью анализатора. Синтаксический анализатор действует как интерпретатор для компьютера и представляет собой инструмент, который используется для разбиения строки данных на более мелкие части. Эти меньшие фрагменты данных затем отдельно анализируются и получают желаемую структуру, которую хочет пользователь. Например, синтаксический анализатор HTML можно использовать для анализа данных в файле HTML, разделения их на более мелкие части, понимания требований к деталям, а затем преобразования их в более читаемый формат, такой как CSV.
Эти меньшие фрагменты данных затем отдельно анализируются и получают желаемую структуру, которую хочет пользователь. Например, синтаксический анализатор HTML можно использовать для анализа данных в файле HTML, разделения их на более мелкие части, понимания требований к деталям, а затем преобразования их в более читаемый формат, такой как CSV.
Варианты использования анализа данных
Некоторые варианты использования анализа данных широко распространены во всех отраслях и для конкретных отраслей.
Анализ данных для сообщений электронной почты
В сегодняшней деловой среде основным каналом для профессионального общения остается электронная почта. Сегодня самые важные и обширные наборы информации передаются по электронной почте. Однако по мере увеличения количества электронных писем и длины ветки становится все труднее понять смысл передаваемой информации.
Поэтому предприятия используют синтаксический анализ, чтобы получить более полное представление о данных, отправляемых по электронной почте. Синтаксический анализ данных может помочь извлечь и сжать соответствующую информацию из электронных писем и заменить необходимую ручную работу. С помощью ключевых слов и определенных команд решение для анализа данных может помочь предприятиям извлечь все необходимые данные из своей электронной почты, чтобы открыть использование ключевых слов и четких команд; решение для анализа данных может помочь компаниям удалить все необходимые данные из своей электронной почты, не открывая каждую ветку по отдельности.
Синтаксический анализ данных может помочь извлечь и сжать соответствующую информацию из электронных писем и заменить необходимую ручную работу. С помощью ключевых слов и определенных команд решение для анализа данных может помочь предприятиям извлечь все необходимые данные из своей электронной почты, чтобы открыть использование ключевых слов и четких команд; решение для анализа данных может помочь компаниям удалить все необходимые данные из своей электронной почты, не открывая каждую ветку по отдельности.
Анализ данных для обработки профессиональных резюме и биографических данных
Рекрутеры ежедневно получают множество резюме и автобиографий от людей, претендующих на вакансии в различных фирмах. Однако, когда многие люди претендуют лишь на несколько должностей, компаниям становится сложно выделить подходящих кандидатов на эту должность. Хотя резюме могут быть структурированы в удобной для читателя форме, само рассмотрение каждого из них в отдельности делает процесс трудоемким и трудоемким, что делает его длительным и неэффективным.
Для этого рекрутеры и HR-специалисты используют парсинг данных. Это позволяет им сортировать резюме на основе определенных критериев, включая ключевые слова, которые ищет фирма. Ключевые слова могут быть конкретными навыками, квалификацией, талантом или сертификатами, которые сделают кандидата идеальным для работы. Анализ данных позволяет рекрутерам создавать фильтры в процессе найма только для того, чтобы принимать заявки от кандидатов, которые соответствуют определенным требованиям или выделяются из остальной группы определенным образом.
Анализ данных для инвестиций
Мир инвестиций полон информации, поступающей из различных источников. Фондовый рынок, банковские ставки, прибыль и валюта существенно влияют на мир инвестиций. Поэтому инвесторам необходимо обрабатывать огромные объемы информации, чтобы реагировать на изменения на рынке в режиме реального времени. Даже самая маленькая задержка может привести к серьезным финансовым потерям для инвесторов.
Синтаксический анализ данных позволяет инвесторам анализировать огромные объемы данных и получать всю необходимую информацию в более разборчивом формате. Это сокращает ручную работу для инвесторов и аналитиков и помогает им анализировать такие величины, которые люди не могут понять. Следовательно, инвесторы могут сэкономить время и затраты на операции и опередить рынок.
Это сокращает ручную работу для инвесторов и аналитиков и помогает им анализировать такие величины, которые люди не могут понять. Следовательно, инвесторы могут сэкономить время и затраты на операции и опередить рынок.
Анализ данных для анализа рынка
Почти каждая отрасль в мире состоит из нескольких игроков, конкурирующих друг с другом за более значительную долю рынка. Поскольку рынок постоянно развивается, а предпочтения потребителей регулярно меняются, предприятия всегда стараются идти в ногу с последними тенденциями, чтобы получить преимущество над своими конкурентами. Однако при наличии миллиардов клиентов по всему миру объем генерируемых потребительских данных слишком велик, чтобы его можно было анализировать вручную, что затрудняет выявление закономерностей и получение релевантной информации, необходимой для принятия стратегических решений.
Анализ данных позволяет компаниям лучше понять рынок, помогая им извлекать необходимые статистические данные из неизмеримых объемов данных. Такая статистика помогает компаниям выявлять тенденции на рынке, понимать поведение потребителей и понимать, как меняется конкурентная среда. Синтаксический анализ помогает компаниям совершать шаги в режиме реального времени, чтобы меняться вместе с самим рынком.
Такая статистика помогает компаниям выявлять тенденции на рынке, понимать поведение потребителей и понимать, как меняется конкурентная среда. Синтаксический анализ помогает компаниям совершать шаги в режиме реального времени, чтобы меняться вместе с самим рынком.
Понимание того, что делает анализатор данных
Анализатор данных — это инструмент, используемый для выполнения функции анализа. Это программа, которая понимает требования сущности и преобразует формат данных на основе введенных в нее команд.
Предприятие может создать или приобрести анализатор данных в зависимости от потребностей рынка, отрасли и предприятия.
Создание или покупка анализатора данных
Некоторые компании предпочитают создавать анализатор самостоятельно. Обычно это делается, когда у компании есть надлежащая инфраструктура и таланты, как правило, полноценный ИТ-отдел с программистами, способными разрабатывать ИТ-инструменты.
Создание синтаксического анализатора часто предпочтительнее, поскольку создающая его организация имеет полный контроль над его работой. Это позволяет им настраивать синтаксический анализатор в соответствии с конкретными требованиями фирмы. Кроме того, это помогает им создавать узкоспециализированные решения, которые очень эффективно работают в определенных бизнес-средах.
Это позволяет им настраивать синтаксический анализатор в соответствии с конкретными требованиями фирмы. Кроме того, это помогает им создавать узкоспециализированные решения, которые очень эффективно работают в определенных бизнес-средах.
Покупка синтаксического анализатора, как правило, идеальна для компаний, у которых нет собственной команды или которые не хотят задействовать эти ИТ-команды для работы над созданием инструмента. На рынке представлено множество вариантов парсинга данных, и практически для любой организации можно найти идеальное решение.
Покупка синтаксического анализатора дает компаниям возможность выбирать из множества доступных вариантов. Кроме того, эти решения создаются специалистами, специализирующимися на создании таких инструментов. Кроме того, эти решения разнообразны и могут работать в различных рабочих средах.
При создании и покупке синтаксического анализатора есть как преимущества, так и проблемы, и организация должна понимать, какой вариант идеально подходит для их ситуации.
Стоимость разработки
Одной из основных проблем при создании анализатора собственными силами является стоимость. Кроме того, создание парсера данных может потребовать от компании дополнительных наймов, создания инфраструктуры и обучения сотрудников.
С другой стороны, покупка синтаксического анализатора может быть экономически выгодным решением. Поскольку на рынке можно найти множество вариантов, купить парсер проще и доступнее. Покупка синтаксического анализатора также включает в себя поддержку службы поддержки клиентов, в отличие от создания синтаксического анализатора, который требует дополнительных затрат на обслуживание, поскольку разработка велась собственными силами, что увеличивает расходы.
Время выхода на рынок
Время — еще один критический фактор при рассмотрении разницы между покупкой и созданием синтаксического анализатора. Самостоятельное создание синтаксического анализатора требует нескольких внутренних усилий, таких как исследования и разработки, развитие инфраструктуры, найм и тестирование. Это заставляет компании тратить много времени, прежде чем анализатор данных будет готов к развертыванию. Двойные затраты приходится нести компаниям, разрабатывающим парсер взамен купленного.
Это заставляет компании тратить много времени, прежде чем анализатор данных будет готов к развертыванию. Двойные затраты приходится нести компаниям, разрабатывающим парсер взамен купленного.
Однако купить парсер данных, как правило, намного быстрее. Поскольку процесс включает только определение правильного решения и совершение покупки, это экономит много времени для компании. Кроме того, в случае возникновения каких-либо ошибок в парсере, можно связаться со службой поддержки клиентов для приобретения приобретенного парсера. Однако, когда синтаксический анализатор создается собственными силами, любые ошибки в синтаксическом анализаторе должны устраняться внутри компании, что может занять гораздо больше времени.
Контроль и специализация
Центральным аргументом сторонников создания синтаксического анализатора является контроль над решением. Когда компании создают синтаксический анализатор, они могут разработать решение таким образом, который наиболее подходит для рабочей среды предприятия. Однако, когда компании покупают синтаксический анализатор, они обычно покупают стандартизированное решение, созданное для работы в различных условиях.
Однако, когда компании покупают синтаксический анализатор, они обычно покупают стандартизированное решение, созданное для работы в различных условиях.
Приобретенный синтаксический анализатор не может обеспечить специализацию и настройку, которые предлагает встроенный синтаксический анализатор. Кроме того, когда компании создают синтаксический анализатор, они могут корректировать его работу по мере развития бизнеса. Решение изменяется только для купленного парсера, когда разработчик отправляет какие-либо обновления, что делает его более жестким, чем встроенные парсеры.
Какой синтаксический анализатор лучше всего подходит для бизнеса?
Малые предприятия
Малые предприятия обычно имеют меньшую команду и меньше ресурсов. Следовательно, создание синтаксического анализатора может существенно повлиять на стоимость разработки для организаций. Если небольшие компании по-прежнему предпочитают разрабатывать его собственными силами, это может быть ниже номинала, связанного с одним собственным; он может быть некачественным из-за отсутствия большого пула талантов, создания серьезных проблем с безопасностью, проблем с удобством использования или ошибочного синтаксического анализа.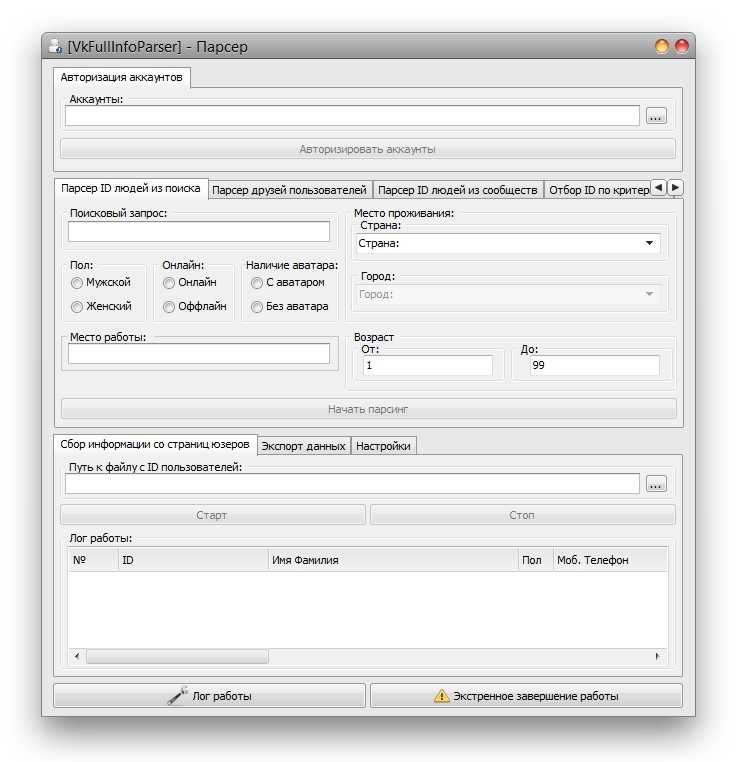
Поэтому для небольших компаний рекомендуется приобрести парсер. Поскольку на рынке доступно множество решений, небольшие компании, скорее всего, найдут решение, соответствующее их потребностям.
Предприятия среднего размера
Предприятия среднего размера находятся в зоне, где им может потребоваться или не потребоваться создание синтаксического анализатора. Это полностью зависит от объема данных, с которыми приходится иметь дело компании, а также от размера и качества собственной ИТ-команды.
Если бизнес чувствует необходимость и имеет ресурсы для разработки решения собственными силами, он может это сделать. Особенно это актуально в тех случаях, когда требуется узкоспециализированное решение, которое невозможно найти на рынке по разумной цене. В тех случаях, когда бизнес ищет доступное решение, парсер можно приобрести.
Крупные организации и транснациональные корпорации
Крупные компании обычно имеют более крупные ИТ-команды и квалифицированных специалистов. Эти команды состоят из высококвалифицированного персонала, способного предлагать комплексные решения. Поэтому более крупным компаниям обычно следует рассматривать возможность создания своих инструментов собственными силами.
Эти команды состоят из высококвалифицированного персонала, способного предлагать комплексные решения. Поэтому более крупным компаниям обычно следует рассматривать возможность создания своих инструментов собственными силами.
Из-за масштаба организации и количества доступных ресурсов. Это дает им больший контроль над решением и помогает им получить узкоспециализированные решения для удовлетворения конкретных потребностей организаций. Поскольку организация большая и часто географически разнородная, обслуживание и разработка, вероятно, будут стоить меньше, чем покупка синтаксического анализатора из-за эффекта масштаба.
Синтаксический анализ данных — отличный способ извлечь важные фрагменты информации из сложного набора данных. Этот процесс помогает предприятиям стать более эффективными, сокращая ручные операции за счет автоматизации. Это экономит время и деньги для организаций и обеспечивает более точные результаты, устраняя опасность человеческой ошибки.
Что такое анализ данных? — Определение синтаксического анализатора данных
Синтаксический анализ данных используется для сканирования информации из больших наборов данных и ее структурирования в понятном для человека виде.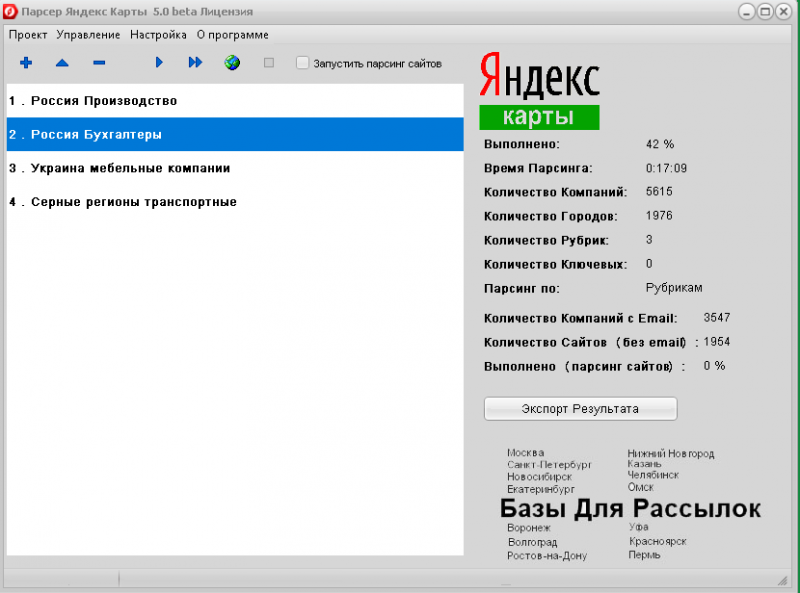 Традиционный синтаксический анализ данных выполняется в файлах HTML, где синтаксический анализатор преобразует текст HTML в читаемые данные. Однако не все синтаксические анализаторы работают одинаково, и существуют явные различия в технологиях синтаксического анализа. Существует множество преимуществ анализа данных для бизнеса, начиная от автоматизированного извлечения данных, улучшения видимости, сокращения затрат и повышения производительности труда сотрудников. Но парсинг на этом не заканчивается, и сегодня мы углубимся в то, о чем идет речь.
Традиционный синтаксический анализ данных выполняется в файлах HTML, где синтаксический анализатор преобразует текст HTML в читаемые данные. Однако не все синтаксические анализаторы работают одинаково, и существуют явные различия в технологиях синтаксического анализа. Существует множество преимуществ анализа данных для бизнеса, начиная от автоматизированного извлечения данных, улучшения видимости, сокращения затрат и повышения производительности труда сотрудников. Но парсинг на этом не заканчивается, и сегодня мы углубимся в то, о чем идет речь.
Синтаксический анализ данных — это процесс преобразования строки данных из одного формата в другой. Если вы читаете данные в необработанном HTML, анализатор данных поможет вам преобразовать их в более читаемый формат, например, в обычный текст. Не вся информация преобразуется в процессе синтаксического анализа, и программы имеют свои собственные наборы правил, когда речь идет о синтаксическом анализе информации.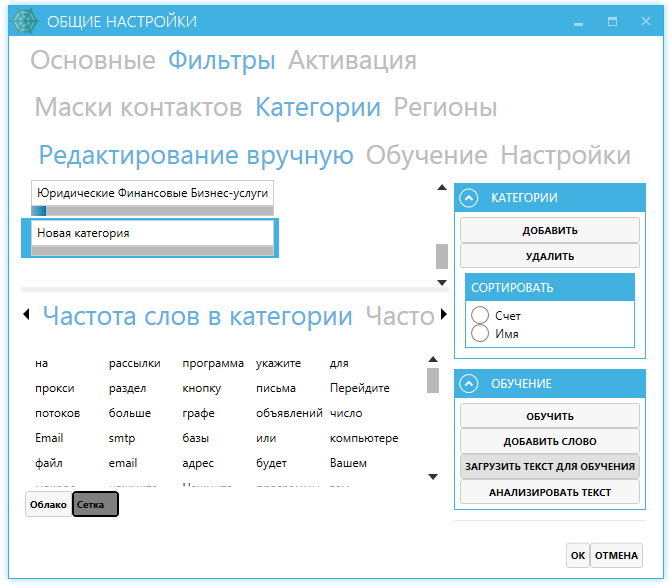
Короче говоря, программа анализа данных используется для преобразования неструктурированных данных в JSON, CSV и другие форматы файлов и добавляет структуру к указанной информации.
Определение синтаксического анализаВ области компьютерного программирования синтаксический анализ определяется как анализ строки символов, специальных символов и структур данных с использованием обработки естественного языка (NLP). Когда вы определяете извлечение при синтаксическом анализе, это относится к структурированию информации из наборов данных и приданию ей значения путем ее организации на основе определенных пользователем правил.
Синтаксический анализ имеет разные определения для лингвистов и программистов, но общее мнение состоит в том, что он используется для анализа предложений и отображения семантических отношений между ними. Другими словами, вы определяете извлечение информации из файлов и их фильтрацию как синтаксический анализ.
Типы анализа данных Анализ данных использует два подхода, когда речь идет о семантическом анализе анализа данных, управляемого текстовой грамматикой, и анализа данных, управляемого данными.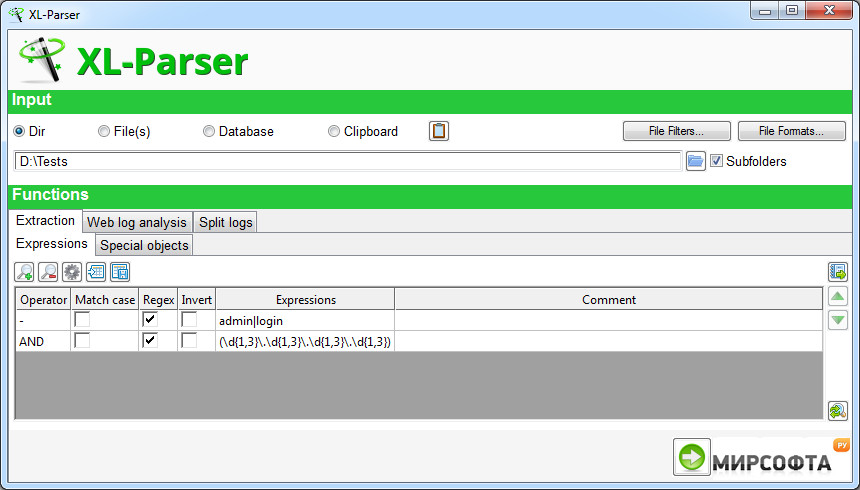 Важным аспектом синтаксического анализа является извлечение информации из данных таким образом, чтобы она соответствовала контекстуальным структурам.
Важным аспектом синтаксического анализа является извлечение информации из данных таким образом, чтобы она соответствовала контекстуальным структурам.
Вот как работают эти два подхода:
1. Анализ данных на основе грамматики Анализ данных на основе грамматики означает, что анализатор использует набор правил формальной грамматики для процесса анализа. Это работает так: предложения из неструктурированных данных фрагментируются и преобразуются в структурированный формат. Проблема анализа данных на основе грамматики заключается в том, что моделям не хватает надежности. Это преодолевается путем ослабления грамматических ограничений, так что предложения, выходящие за рамки грамматических правил, могут быть исключены для последующего анализа. Синтаксический анализ текста является подмножеством анализа грамматики и назначает ряд анализов для данной строки. Он также решает проблемы устранения неоднозначности, с которыми сталкиваются традиционные методы синтаксического анализа.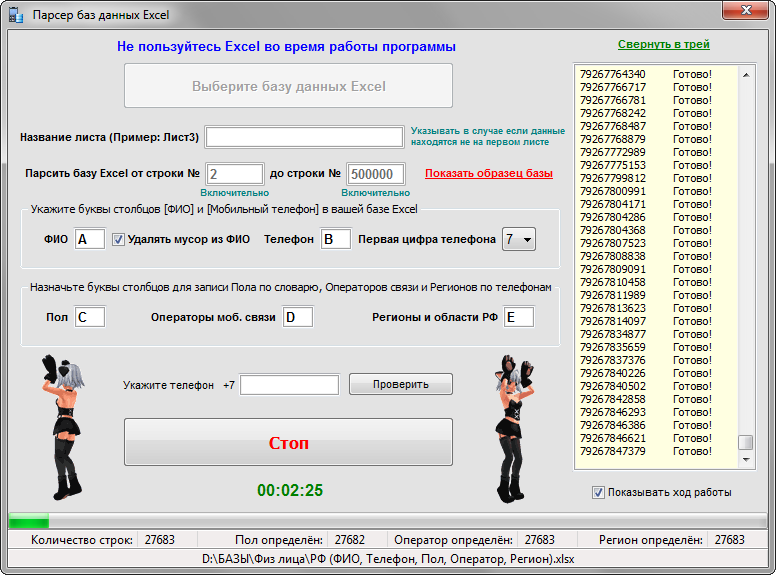
Анализ данных на основе данных использует вероятностную модель и обходит дедуктивные подходы к анализу текста, которые часто используются в моделях на основе грамматики. В этом типе синтаксического анализа программа синтаксического анализа применяет методы, основанные на правилах, семантические уравнения и обработку естественного языка (NLP) для структурирования и анализа предложений. В отличие от синтаксического анализа на основе грамматики, синтаксический анализ данных на основе данных использует статистические синтаксические анализаторы и современные банки деревьев для получения широкого охвата языков. Анализ разговорных языков и предложений, требующих точности, с немаркированными данными, относящимися к предметной области, подпадает под область анализа данных на основе данных.
Варианты использования парсера данных Что делает парсер? Он извлекает данные из документов, структурирует их и фильтрует детали.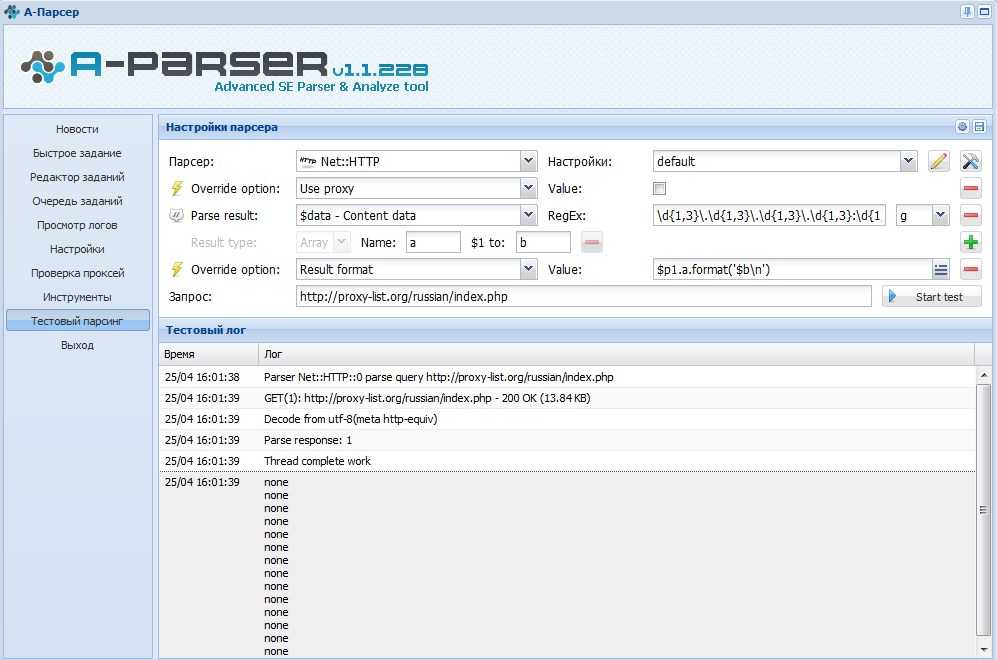
Синтаксический анализ данных используется различными отраслевыми вертикалями для преобразования информации в электронные форматы из документов. Ниже приведены наиболее популярные варианты использования синтаксического анализа в отраслях:
1. Оптимизация бизнес-процессовАнализаторы данных используются компаниями для структурирования неструктурированных наборов данных в полезную информацию. Предприятия используют синтаксический анализ данных для оптимизации своих рабочих процессов, связанных с извлечением данных. Синтаксический анализ используется в области инвестиционного анализа, маркетинга, управления социальными сетями и других бизнес-приложений.
2. Финансы и бухгалтерский учет Банки и NBFC используют анализ данных для очистки миллиардов данных клиентов и извлечения ключевой информации из приложений. Анализ данных используется для анализа кредитных отчетов, инвестиционных портфелей, проверки доходов и получения более полных сведений о клиентах. Финансовые фирмы используют синтаксический анализ для определения процентных ставок и сроков погашения кредита после извлечения данных.
Финансовые фирмы используют синтаксический анализ для определения процентных ставок и сроков погашения кредита после извлечения данных.
Предприятия, предоставляющие товары/услуги в режиме онлайн, используют анализаторы данных для получения сведений о счетах и доставке. Парсеры используются для упорядочивания отгрузочных этикеток и обеспечения правильного форматирования данных.
4. Сфера недвижимостиДанные о потенциальных клиентах извлекаются из электронных писем владельцев недвижимости и строителей. Технологии парсинга используются для извлечения данных для платформ CRM и обработки документации для передачи агентам по недвижимости. Благодаря контактным данным, адресам собственности, данным о денежных потоках и источникам потенциальных клиентов, парсеры очень полезны для компаний, занимающихся недвижимостью, когда речь идет о покупках, аренде и продажах.
Стоит ли создавать собственный парсер? Распространенный вопрос, который постоянно возникает при обработке документов в организациях, заключается в том, следует ли создавать собственный анализатор данных. Специальное программное обеспечение для синтаксического анализа текста, созданное для внутренних команд, определенно создано с учетом конкретных требований к синтаксическому анализу в организациях.
Специальное программное обеспечение для синтаксического анализа текста, созданное для внутренних команд, определенно создано с учетом конкретных требований к синтаксическому анализу в организациях.
Однако недостатком является то, что весь персонал должен быть обучен тому, как им пользоваться. Затраты на создание пользовательской программы синтаксического анализа могут быть высокими, поскольку требуется больше времени и ресурсов. Кроме того, эти решения требуют тщательного планирования и собственных выделенных серверов для более быстрого анализа. Если вы переносите системы, они могут быть несовместимы с новыми технологиями и потребуют обновления.
Идеальным сценарием является использование анализатора данных, совместимого с устаревшими системами и предназначенного для различных вариантов использования. Парсер данных Docsumo дает вам полный контроль над извлечением данных и предназначен для работы со всеми типами предприятий, будь то стартапы, предприятия или крупные организации.
Анализ данных делает информацию доступной для организаций и упрощает ее чтение. Преобразованные данные могут быть эффективно переданы клиентам, а синтаксические анализаторы предназначены для обеспечения гибкости и масштабируемости бизнес-операций по своей природе. С хорошим синтаксическим анализатором большая часть ручной работы, связанной с извлечением и очисткой данных, автоматизируется, и ее важность нельзя недооценивать.
Обработка документов становится препятствием для развития вашего бизнеса?
Присоединяйтесь к Docsumo, чтобы быть в курсе последних тенденций DocAI и советов по автоматизации. Docsumo является партнером Document AI для ведущих кредиторов и страховых компаний в США.
Что такое анализ данных? | Блог Nanonets
Ищете решение для анализа данных?
Попробуйте Nanonets для анализа данных из PDF-файлов, вложений электронной почты, счетов-фактур, счетов, квитанций и многого другого.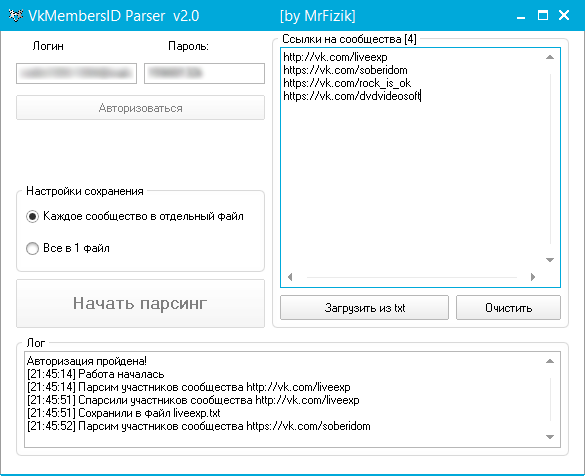
Попробуйте Nanonets бесплатно
Внедрение больших данных в бизнес-модели полностью изменило наше восприятие бизнеса и технологий. Тем не менее, это привело к необходимости в тяжелых инструментах для извлечения, анализа и обработки такого огромного объема данных. Кроме того, как и естественные языки, компьютерные языки и языки программирования требуют точного перевода для обеспечения эффективного общения.
Именно здесь анализ данных вступает в игру и решает проблему понимания сложных данных. Синтаксический анализ данных преобразует неструктурированные или нечитаемые данные в хорошо структурированные и легко читаемые данные.
Самое приятное в анализе данных то, что независимо от того, работаете ли вы в команде разработчиков компании или имеете дело с клиентами, играющими роль в маркетинге, вам необходимо понимать данные для поддержания своей производительности, развития новых предприятий или общения с клиентами. . Короче говоря, для долгосрочного успеха в бизнесе важно знать данные.
В этой статье мы объясним структуру анализаторов данных, как они могут помочь вашей организации и как анализ данных облегчает вам понимание данных. Кроме того, мы подскажем, стоит ли вам разработать свой парсер или купить его для нужд вашей компании.
Начнем.
Что такое анализ данных?
Анализ данных ОпределениеПроще говоря, анализ данных — это преобразование данных из одного формата в другой. Например, если текст находится в формате HTML, синтаксический анализ данных может помочь вам преобразовать файл в более читаемый формат, такой как обычный текст.
Это популярный процесс преобразования данных, обычно используемый в компиляторах, где нам нужно преобразовать компьютерный код в более простой машинный код. Точно так же, когда веб-разработчики пишут код, работающий на оборудовании, им приходится использовать синтаксические анализаторы данных. Точный процесс также используется в механизмах SQL, где механизмы SQL сначала анализируют запрос SQL, а затем выполняют его и показывают результаты.
Синтаксический анализ данных также полезен в случае парсинга веб-страниц, поскольку данные, извлеченные с веб-страницы после парсинга, обычно трудно понять. Таким образом, парсер данных делает их более читабельными и подготавливает к более качественному анализу исследователями.
Мощные анализаторы данных могут преобразовывать любые данные в другой формат. Например, они могут преобразовать необработанный HTML-код в объект JSON или преобразовать страницу JavaScript в удобочитаемый файл CSV.
Однако важным аспектом разбора данных является то, что не каждый фрагмент информации преобразуется во время процедуры разбора данных. Это связано с тем, что программы имеют свои собственные правила синтаксического анализа.
Как работает анализатор данных? С точки зрения вычислительной техники синтаксический анализ данных — это процесс анализа строки символов, специальных символов или структур данных с использованием обработки естественного языка (NLP), а затем структурирование данной информации из наборов данных и организация ее в соответствии с определенным пользователем -определенные правила. Или, другими словами, это метод извлечения информации из файлов и их фильтрация.
Или, другими словами, это метод извлечения информации из файлов и их фильтрация.
Тем не менее, точно так же, как лингвистическое определение синтаксического анализа, весь процесс синтаксического анализа данных вращается вокруг тщательного изучения предложений и отображения некоторых семантических отношений между ними.
Структура анализатора данныхАнализатор данных состоит из двух компонентов: лексического анализа и синтаксического анализа. Некоторые парсеры также имеют компонент семантического анализа. Он берет уже проанализированные и структурированные данные и применяет к ним значение. Например, семантический компонент будет дополнительно фильтровать данные на положительные или отрицательные, полные или неполные и т. д. и повышать качество окончательных данных.
Как это работает?Вот как работает анализатор данных —
● Прежде всего, анализатор различает информацию строки HTML и распознает, какие данные действительно ценны и необходимы для дальнейших операций.
● Теперь, следуя заранее написанным правилам и кодам парсеров, он выбирает необходимую информацию и преобразует ее в JSON, CSV или другой формат.
Важно отметить, что анализатор данных не привязан к какому-либо конкретному формату данных. Скорее это инструмент, который конвертирует данные из одного формата в другой, и весь процесс изменения формата зависит от сборки парсера.
Использование анализа данныхАнализаторы данных используются для многих технологий и языков, таких как:
● Java и другие языки программирования
● HTML и XML
● ● Язык интерактивных данных и язык определения объектов
25 SQL и другие языки баз данных
● Языки моделирования
● Языки сценариев
● HTTP и другие интернет-протоколы
Хочу анализировать данные из документов PDF или автоматизировать анализ данных с помощью рабочих процессов? Попробуйте бесплатно анализатор данных Nanonets.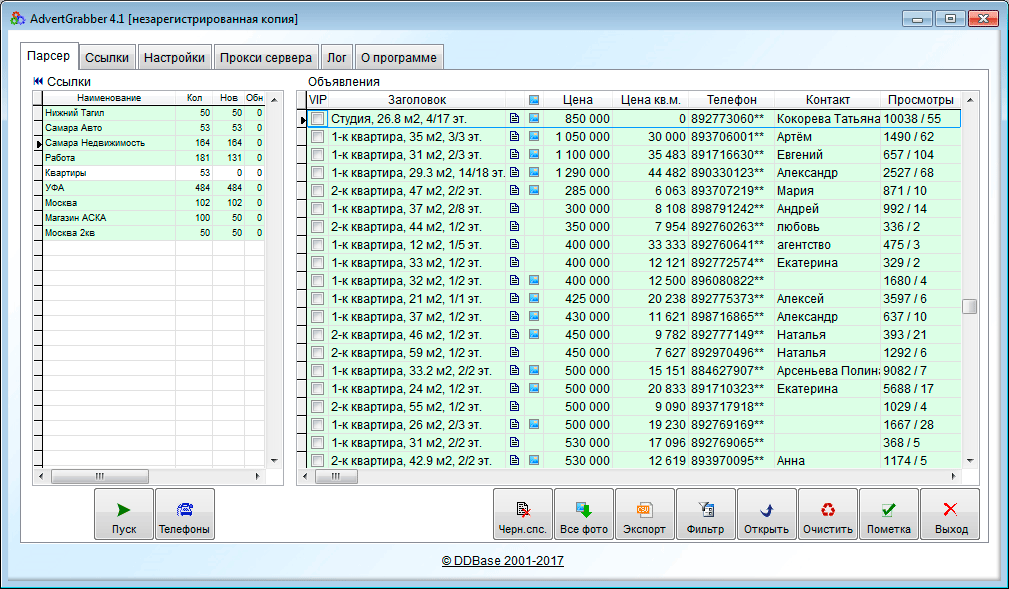 Начните бесплатный пробный период. Кредитная карта не требуется.
Начните бесплатный пробный период. Кредитная карта не требуется.
Попробуйте Nanonets бесплатно
Какие существуют типы анализа данных?
Анализ данных обычно использует два типа подходов для семантического анализа текста, т. е. анализ данных на основе грамматики и анализ данных на основе данных. Давайте подробно обсудим оба подхода —
Анализ данных на основе грамматикиВ этом методе анализатор данных использует набор формальных правил грамматики и выполняет задачу анализа. Простыми словами, предложения из неструктурированных данных сначала фрагментируются, а затем трансформируются в более структурированный и понятный формат.
Однако у этого подхода есть одна проблема: ему не хватает надежности. Таким образом, чтобы преодолеть эту проблему, грамматические ограничения часто ослабляются, так что предложения, выходящие за рамки обычной грамматики, могут быть исключены для анализа синтаксического анализа данных.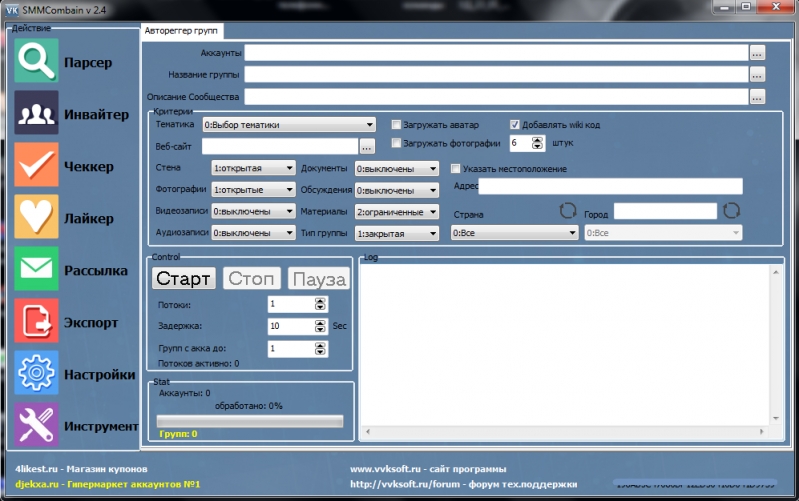
Популярным подмножеством синтаксического анализа данных на основе грамматики является синтаксический анализ текста, который анализирует заданную строку. Этот тип процесса синтаксического анализа очень успешен в решении проблемы устранения неоднозначности, с которой сталкиваются обычные методы синтаксического анализа.
Анализ данных на основе данныхАнализ данных на основе данных основан на вероятностной модели преобразования. В отличие от дедуктивного подхода к анализу текста, используемого моделями синтаксического анализа на основе грамматики, он применяет методы, основанные на правилах, семантические уравнения и обработку естественного языка (NLP) для структурирования результирующих предложений и их анализа.
Этот подход к синтаксическому анализу использует интеллектуальные статистические синтаксические анализаторы и современные банки деревьев для получения широкого охвата языков. Вот почему разговорные языки и предложения, которые требуют точности, но относятся к предметной области и не имеют маркировки, обычно управляются синтаксическим анализом данных на основе данных.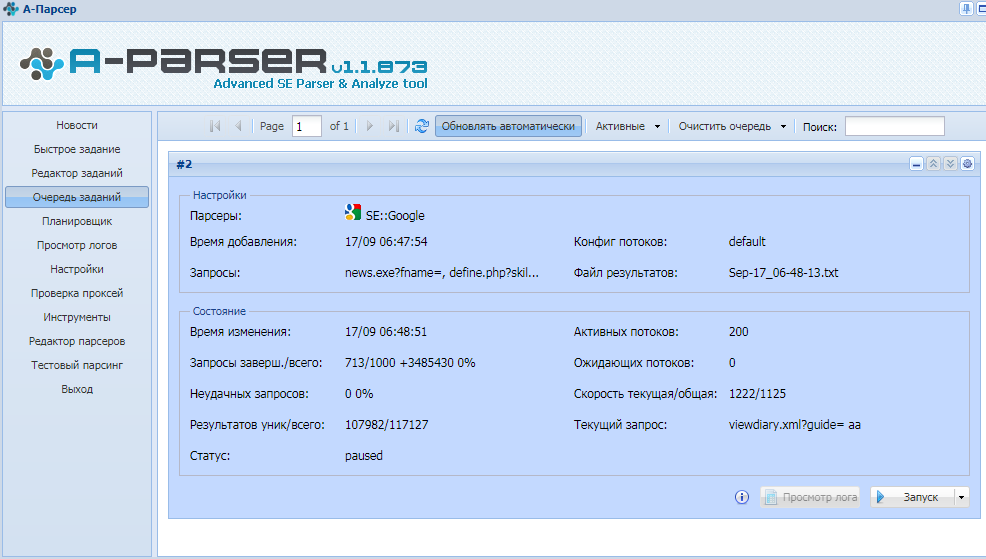
Автоматизируйте процессы обработки документов с помощью анализатора данных и документов Nanonets. Извлекайте данные из счетов-фактур, удостоверений личности или любого документа на автопилоте!
Разобрать данные сейчас
Преимущества программного обеспечения для анализа данных
Оптимизация работыСамым значительным преимуществом анализа данных является то, что он помогает вам ориентироваться в огромном количестве данных, упрощая их и делая более читабельными. Следовательно, это позволяет организации быть более продуктивной и эффективной.
Экономия времени Парсеры данных помогают предприятиям, предоставляя им правильный алгоритм или правильный инструмент для извлечения данных из их текущей формы. Затем он преобразует данные в другую форму и автоматизирует процесс, который в противном случае пришлось бы выполнять вручную. В результате это помогает компании работать быстрее, чем когда-либо.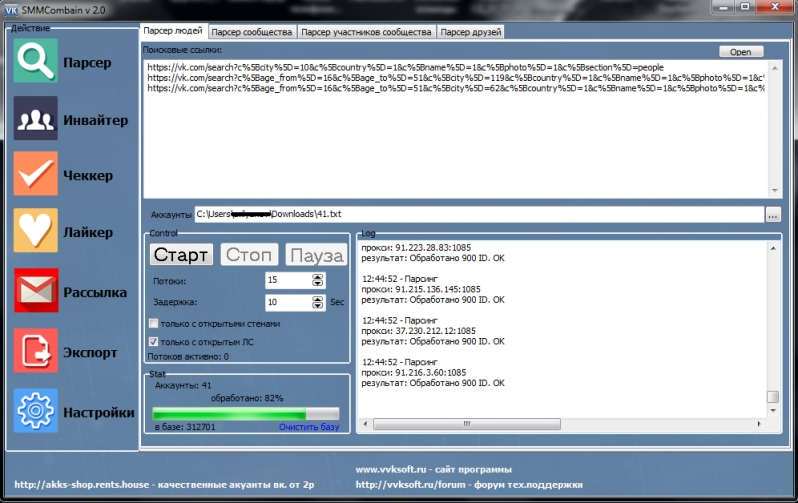 Кроме того, организации могут использовать свои человеческие ресурсы в другом месте для решения более важных задач.
Кроме того, организации могут использовать свои человеческие ресурсы в другом месте для решения более важных задач.
Когда в руках компаний находится масса данных, им приходится бороться с их использованием, извлечением, управлением, анализом и т. д.
Синтаксический анализ данных делает данные более доступными и увеличивает возможности поиска. Он создает файлы, которые в противном случае было бы трудно читать или компилировать на компьютерах компании, более доступные, чем раньше. Кроме того, когда эти файлы данных станут легко читаемыми, конечный продукт, предлагаемый бизнес-профессионалам, может стать более читабельным, чем раньше.
Модернизация ваших данных Данные, накопленные предприятиями, могут быть устаревшими и могут быть недоступны в текущем формате. Другими словами, может быть сложно использовать такие сохраненные данные. Однако эти данные могут быть чрезвычайно ценны для понимания развития компании или для любого другого использования.
Синтаксический анализ данных может быстро изменить формат этих данных и сделать их доступными для расшифровки и использования в соответствии с современными требованиями. И кто знает, какие данные станут палочкой-выручалочкой для вашей компании в будущем!
Хотите использовать роботизированную автоматизацию процессов? Ознакомьтесь с программным обеспечением для обработки документов на основе рабочего процесса Nanonets. Нет кода. Платформа без проблем.
Попробуйте Nanonets бесплатно
Варианты использования анализа данных
С точки зрения использования, анализаторы данных используются в различных отраслях для различных целей. Вот некоторые из их применений в различных сферах деятельности:
Оптимизация бизнес-процессов Парсеры данных помогают компаниям структурировать неструктурированные наборы данных и преобразовывать их в полезную информацию. Вот почему предприятия используют парсеры данных для оптимизации рабочих процессов извлечения данных.
Точно так же парсеры данных используются для инвестиционного анализа, маркетинга, управления социальными сетями и других бизнес-приложений. Аналитики данных, программисты, маркетологи и инвесторы могут наблюдать значительное повышение своей производительности с помощью парсеров данных.
Финансы и бухгалтерский учетБанки и NBFC используют анализ данных для очистки миллиардов данных о клиентах и извлечения соответствующей информации из приложений. Он также используется для анализа кредитных отчетов, инвестиционных портфелей, проверки доходов и получения точной информации о клиентах.
Финансовые фирмы также используют анализаторы данных для определения процентных ставок и сроков погашения кредита.
Судоходство и логистика Предприятия, которые продают онлайн-продукты или услуги, используют анализ данных для извлечения информации о счетах и доставке. Синтаксический анализ также используется для управления отгрузочными этикетками и проверки правильности формата данных.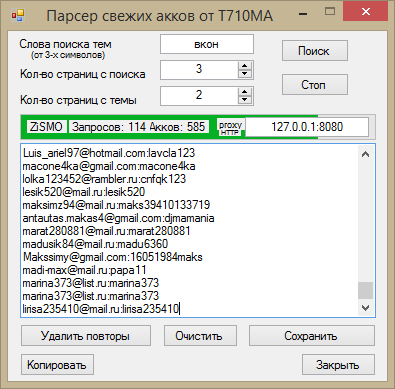
Риелторские компании используют технологии анализа данных для извлечения данных из электронных писем владельцев недвижимости и застройщиков или платформ CRM, а затем обрабатывают информацию для передачи агентам по недвижимости. Эти данные, такие как контактные данные, адреса собственности, данные о денежных потоках и источники потенциальных клиентов, очень прибыльны для компаний, занимающихся недвижимостью, и помогают им совершать покупки, аренду и продажи.
Инвестиционный анализУмные инвестиции требуют получения большого количества соответствующих данных, таких как исследования капитала, оценка стартапов, прогнозы доходов и конкурентный анализ. Сбор и анализ всех таких данных занимает много времени.
Использование инструментов веб-скрапинга вместе с парсером данных может упростить эти задачи, оптимизировать рабочий процесс и позволить вам направить ресурсы в другое место, предоставляя при этом более глубокий анализ.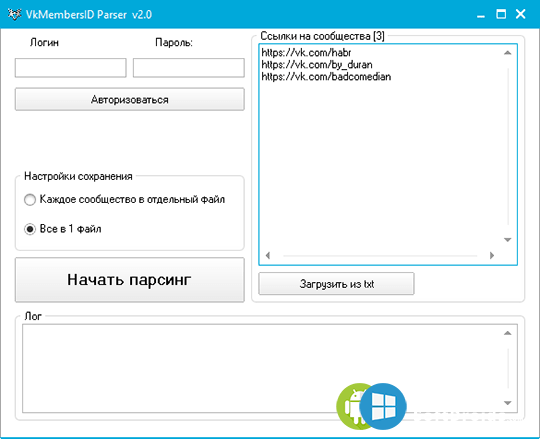
Кроме того, инструменты анализа данных могут предоставить инвесторам и аналитикам данных более полную информацию для принятия правильных бизнес-решений.
Вот почему крупные инвесторы, хедж-фонды и другие профессионалы в области инвестиций используют инструменты веб-скрапинга и анализа данных для оценки стартапов, прогнозирования доходов и даже для отслеживания социальных настроений и получения точной информации о рынке.
Работаете ли вы со счетами и квитанциями или беспокоитесь о проверке личности, воспользуйтесь парсером данных Nanonets для извлечения текста из PDF-документов бесплатно . Используется более чем 500 предприятиями для анализа более 30 миллионов документов.
Начать синтаксический анализ документов сейчас
Стоит ли создавать собственный анализатор данных?
Самый важный вопрос заключается в том, должна ли ваша организация создавать собственный анализатор данных или нет. Давайте выясним, сравнив плюсы и минусы создания вашего программного обеспечения для анализа данных.
Давайте выясним, сравнив плюсы и минусы создания вашего программного обеспечения для анализа данных.
- Настройка в соответствии с вашими потребностями — Наиболее значительным преимуществом создания программного обеспечения для анализа текста является то, что оно специально настраивается для вашей организации. Таким образом, это помогает внутренним командам выполнять специфические требования вашей компании к синтаксическому анализу.
- Дешевле — Обычно создание парсера обходится дешевле.
- Дает вам больше контроля — Когда вы разрабатываете собственный анализатор данных, вы лучше контролируете любые решения, которые должны принимать для обновления и обслуживания вашего анализатора данных.
- Обучение персонала — Основная проблема с технологией анализа данных заключается в том, что вы должны обучить весь свой персонал ее использованию.
- Дорого — Во-вторых, затраты на создание пользовательского программного обеспечения для синтаксического анализатора относительно высоки, поскольку для этого требуется много времени и ресурсов. Если вам нужно создать парсер, вам нужно будет нанять и обучить целую внутреннюю команду.
- Требуют много планирования и усилий- Такие виды интеллектуальных решений требуют тщательного планирования и собственных выделенных серверов для мгновенного анализа. Таким образом, вам может понадобиться купить или построить мощный сервер, достаточно быстрый для анализа информации.
- Миграция — Если вам необходимо мигрировать ваши системы, ваши синтаксические анализаторы могут быть несовместимы с новыми системами и потребуют обновления.
- Техническое обслуживание — Парсер нуждается в регулярном обслуживании, а это означает, что вам придется тратить больше денег и времени.
Таким образом, вам может понадобиться анализатор данных для удовлетворения ваших требований или повышения эффективности вашей организации. В этом случае вам следует выбрать парсер данных, совместимый с вашими устаревшими системами и предназначенный для различных вариантов использования.
В этом случае вам следует выбрать парсер данных, совместимый с вашими устаревшими системами и предназначенный для различных вариантов использования.
Автоматизируйте ручные процессы с помощью парсера документов Nanonets. Экономьте время, усилия и деньги, повышая эффективность! Начните бесплатный пробный период. Кредитная карта не требуется.
Попробуйте Nanonets бесплатно
Покупка анализатора данных: альтернатива созданию собственного анализатора данных
Теперь, если вы не хотите создавать собственный анализатор, другим вариантом является покупка инструмента, который анализирует данные за вас. Многие компании продают инструменты синтаксического анализа, которые можно настроить в соответствии со своими требованиями и внедрить в свои операции. Вам не нужно беспокоиться о том, чтобы тратить время и силы на создание парсера, чтобы пользоваться его преимуществами.
Вот плюсы покупки парсера данных
● Никаких затрат на человеческие ресурсы — Когда вы покупаете парсер, вам не нужно тратить ни копейки на человеческие ресурсы. Все будет сделано, включая обслуживание парсера и серверов.
Все будет сделано, включая обслуживание парсера и серверов.
● Более быстрое решение проблем — Если какие-либо проблемы возникнут на пути вашего парсера, вам не нужно беспокоиться, поскольку компания, у которой вы покупаете свои инструменты, будет иметь обширные знания о его обслуживании и быть ознакомленной с их технологиями.
● Меньше шансов на отказ или сбой — Парсеры, предназначенные для продажи, уже протестированы и усовершенствованы в соответствии с требованиями рынка. Таким образом, будет меньше шансов на сбой или проблемы в целом.
Однако покупка парсера имеет несколько недостатков. Начнем с того, что это будет немного дороже. Во-вторых, у вас не будет слишком много контроля над ним по сравнению с парсером, созданным вашей собственной командой. Поэтому вы должны взвесить все «за» и «против», а затем выбрать правильный подход для ваших требований к парсингу.
Правильный синтаксический анализатор для вас также зависит от ваших требований к синтаксическому анализу и объема работы по синтаксическому анализу, выполняемой вашей организацией. Например, если вам нужен простой синтаксический анализатор, опытный разработчик может сделать его за неделю. Однако, если он сложный, весь процесс разработки может занять месяцы.
Например, если вам нужен простой синтаксический анализатор, опытный разработчик может сделать его за неделю. Однако, если он сложный, весь процесс разработки может занять месяцы.
Nanonets для анализа данных
Nanonets — это платформа автоматизации документооборота. Nanonets можно использовать для анализа данных из любого документа: PDF, Word, отсканированного или цифрового документа. Наш инструмент анализа данных может извлекать данные с помощью 9Точность 5% при использовании нашего встроенного программного обеспечения OCR.
Вот некоторые особенности, которые делают Nanonets отличным выбором для анализа данных:
Попробуйте Nanonets бесплатно
Заключение Подводя итог, можно сказать, что синтаксический анализ данных является чрезвычайно полезной технологией для таких организаций, как управляющие фирмы, страховые компании и т. д., которая может сделать информацию более доступной и удобной, чем раньше. Эта интеллектуальная технология автоматизирует ручную работу по извлечению данных и делает бизнес-операции более гибкими и масштабируемыми. Преобразованные данные можно использовать для обмена информацией с клиентами, партнерами и командами.
д., которая может сделать информацию более доступной и удобной, чем раньше. Эта интеллектуальная технология автоматизирует ручную работу по извлечению данных и делает бизнес-операции более гибкими и масштабируемыми. Преобразованные данные можно использовать для обмена информацией с клиентами, партнерами и командами.
Поэтому, если вы еще не подумали о включении хорошего синтаксического анализатора, вам следует сделать это сегодня.
Часто задаваемые вопросы
Какие инструменты необходимы для анализа данных?Это ведущие инструменты извлечения данных, используемые для беспрепятственного извлечения данных.
● Нанонеты: интеллектуальная платформа автоматизации документов
● Scraper API
● Import.io
● Altair Monarch
Что такое проанализированный файл? Когда строка команд, обычно компьютерная программа, фрагментируется на легко обрабатываемые компоненты, а затем анализируется на правильность синтаксиса и становится легко читаемой, она называется проанализированным файлом документа.
Нажатие данных превращает сложные или даже непонятные файлы в простые, читаемые. Например, чтение данных в необработанном HTML может быть для вас сложным. Анализатор данных преобразует их в более читаемый формат, например, в обычный текст.
Как выполняется разбор данных?Подобно обычному синтаксическому анализу, когда мы берем предложение, разбиваем его на разные части речи, а затем определяем грамматические отношения между словами для интерпретации предложения, синтаксический анализ данных анализирует символы и структуры данных.
Он использует обработку естественного языка (NLP) и структурирует информацию из наборов данных, организуя ее и определяя ее значение.
Почему вы анализируете данные? Синтаксический анализ данных — это когда вы берете некоторые неструктурированные данные и преобразуете их в другие форматы файлов, такие как JSON и CSV, и добавляете дополнительную структуру к данной информации.